Post Syndicated from Lena Heimberger original https://blog.cloudflare.com/pq-anonymous-credentials/
The Internet is in the midst of one of the most complex transitions in its history: the migration to post-quantum (PQ) cryptography. Making a system safe against quantum attackers isn’t just a matter of replacing elliptic curves and RSA with PQ alternatives, such as ML-KEM and ML-DSA. These algorithms have higher costs than their classical counterparts, making them unsuitable as drop-in replacements in many situations.
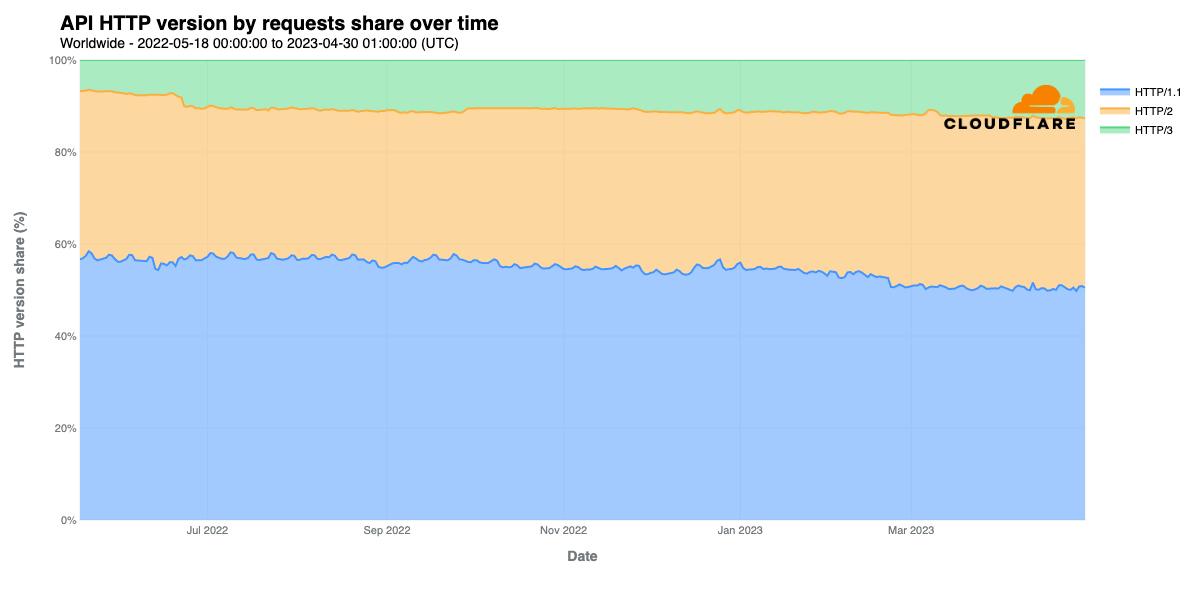
Nevertheless, we’re making steady progress on the most important systems. As of this writing, about 50% of TLS connections to Cloudflare’s edge are safe against store-now/harvest-later attacks. Quantum safe authentication is further out, as it will require more significant changes to how certificates work. Nevertheless, this year we’ve taken a major step towards making TLS deployable at scale with PQ certificates.
That said, TLS is only the lowest hanging fruit. There are many more ways we have come to rely on cryptography than key exchange and authentication and which aren’t as easy to migrate. In this blog post, we’ll take a look at Anonymous Credentials (ACs).
ACs solve a common privacy dilemma: how to prove a specific fact (for example that one has had a valid driver’s license for more than three years) without over-sharing personal information (like the place of birth)? Such problems are fundamental to a number of use cases, and ACs may provide the foundation we need to make these applications as private as possible.
Just like for TLS, the central question for ACs is whether there are drop-in, PQ replacements for its classical primitives that will work at the scale required, or will it be necessary to re-engineer the application to mitigate the cost of PQ.
We’ll take a stab at answering this question in this post. We’ll focus primarily on an emerging use case for ACs described in a concurrent post: rate-limiting requests from agentic AI platforms and users. This demanding, high-scale use case is the perfect lens through which to evaluate the practical readiness of today’s post-quantum research. We’ll use it as our guiding problem to measure each cryptographic approach.
We’ll first explore the current landscape of classical AC adoption across the tech industry and the public sector. Then, we’ll discuss what cryptographic researchers are currently looking into on the post-quantum side. Finally, we’ll take a look at what it’ll take to bridge the gap between theory and real-world applications.
While anonymous credentials are only seeing their first real-world deployments in recent years, it is critical to start thinking about the post-quantum challenge concurrently. This isn’t a theoretical, too-soon problem given the store-now decrypt-later threat. If we wait for mass adoption before solving post-quantum anonymous credentials, ACs risk being dead on arrival. Fortunately, our survey of the state of the art shows the field is close to a practical solution. Let’s start by reviewing real-world use-cases of ACs.
In 2026, the European Union is set to launch its digital identity wallet, a system that will allow EU citizens, residents and businesses to digitally attest to their personal attributes. This will enable them, for example, to display their driver’s license on their phone or perform age verification. Cloudflare’s use cases for ACs are a bit different and revolve around keeping our customers secure by, for example, rate limiting bots and humans as we currently do with Privacy Pass. The EU wallet is a massive undertaking in identity provisioning, and our work operates at a massive scale of traffic processing. Both initiatives are working to solve a shared fundamental problem: allowing an entity to prove a specific attribute about themselves without compromising their privacy by revealing more than they have to.
The EU’s goal is a fully mobile, secure, and user-friendly digital ID. The current technical plan is ambitious, as laid out in the Architecture Reference Framework (ARF). It defines the key privacy goals of unlinkability to guarantee that if a user presents attributes multiple times, the recipients cannot link these separate presentations to conclude that they concern the same user. However, currently proposed solutions fail to achieve this. The framework correctly identifies the core problem: attestations contain unique, fixed elements such as hash values, […], public keys, and signatures that colluding entities could store and compare to track individuals.
In its present form, the ARF’s recommendation to mitigate cross-session linkability is limited-time attestations. The framework acknowledges in the text that this would only partially mitigate Relying Party linkability. An alternative proposal that would mitigate linkability risks are single-use credentials. They are not considered at the moment due to complexity and management overhead. The framework therefore leans on organisational and enforcement measures to deter collusion instead of providing a stronger guarantee backed by cryptography.
This reliance on trust assumptions could become problematic, especially in the sensitive context of digital identity. When asked for feedback, cryptographic researchers agree that the proper solution would be to adopt anonymous credentials. However, this solution presents a long-term challenge. Well-studied methods for anonymous credentials, such as those based on BBS signatures, are vulnerable to quantum computers. While some anonymous schemes are PQ-unlinkable, meaning that user privacy is preserved even when cryptographically relevant quantum computers exist, new credentials could be forged. This may be an attractive target for, say, a nation state actor.
New cryptography also faces deployment challenges: in the EU, only approved cryptographic primitives, as listed in the SOG-IS catalogue, can be used. At the time of writing, this catalogue is limited to established algorithms such as RSA or ECDSA. But when it comes to post-quantum cryptography, SOG-IS is leaving the problem wide open.
The wallet’s first deployment will not be quantum-secure. However, with the transition to post-quantum algorithms being ahead of us, as soon as 2030 for high-risk use cases per the EU roadmap, research in a post-quantum compatible alternative for anonymous credentials is critical. This will encompass standardizing more cryptography.
Regarding existing large scale deployments, the US has allowed digital ID on smartphones since 2024. They can be used at TSA checkpoints for instance. The Department of Homeland Security lists funding for six privacy-preserving digital credential wallets and verifiers on their website. This early exploration and engagement is a positive sign, and highlights the need to plan for privacy-preserving presentations.
Finally, ongoing efforts at the Internet Engineering Task Force (IETF) aim to build a more private Internet by standardizing advanced cryptographic techniques. Active individual drafts (i.e., not yet adopted by a working group), such as Longfellow and Anonymous Credit Tokens (ACT), and adopted drafts like Anonymous Rate-limited Credentials (ARC), propose more flexible multi-show anonymous credentials that incorporate developments over the last several years. At IETF 117 in 2023, post-quantum anonymous credentials and deployable generic anonymous credentials were presented as a research opportunity. Check out our post on rate limiting agents for details.
Before we get into the state-of-the-art for PQ, allow us to try to crystalize a set of requirements for real world applications.
Given the diversity of use cases, adoption of ACs will be made easier by the fact that they can be built from a handful of powerful primitives. (More on this in our concurrent post.) As we’ll see in the next section, we don’t yet have drop-in, PQ alternatives for these kinds of primitives. The “building blocks” of PQ ACs are likely to look quite different, and we’re going to know something about what we’re building towards.
For our purposes, we can think of an anonymous credential as a kind of fancy blind signature. What’s that you ask? A blind signature scheme has two phases: issuance, in which the server signs a message chosen by the client; and presentation, in which the client reveals the message and the signature to the server. The scheme should be unlinkable in the sense that the server can’t link any message and signature to the run of the issuance protocol in which it was produced. It should also be unforgeable in the sense that no client can produce a valid signature without interacting with the server.
The key difference between ACs and blind signatures is that, during presentation of an AC, the client only presents part of the message in plaintext; the rest of the message is kept secret. Typically, the message has three components:
-
Private state, such as a counter that, for example, keeps track of the number of times the credential was presented. The client would prove to the server that the state is “valid”, for example, a counter with value $0 \leq C \leq N$, without revealing $C$. In many situations, it’s desirable to allow the server to update this state upon successful presentation, for example, by decrementing the counter. In the context of rate limiting, this is the number of how many requests are left for a credential.
-
A random value called the nullifier that is revealed to the server during presentation. In rate-limiting, the nullifier prevents a user from spending a credential with a given state more than once.
-
Public attributes known to both the client and server that bind the AC to some application context. For example, this might represent the window of time in which the credential is valid (without revealing the exact time it was issued).
Such ACs are well-suited for rate limiting requests made by the client. Here the idea is to prevent the client from making more than some maximum number of requests during the credential’s lifetime. For example, if the presentation limit is 1,000 and the validity window is one hour, then the clients can make up to 0.27 requests/second on average before it gets throttled.
It’s usually desirable to enforce rate limits on a per-origin basis. This means that if the presentation limit is 1,000, then the client can make at most 1,000 requests to any website that can verify the credential. Moreover, it can do so safely, i.e., without breaking unlinkability across these sites.
The current generation of ACs being considered for standardization at IETF are only privately verifiable, meaning the server issuing the credential (the issuer) must share a private key with the server verifying the credential (the origin). This will be sufficient for some deployment scenarios, but many will require public verifiability, where the origin only needs the issuer’s public key. This is possible with BBS-based credentials, for example.
Finally, let us say a few words about round complexity. An AC is round optimal if issuance and presentation both complete in a single HTTP request and response. In our survey of PQ ACs, we found a number of papers that discovered neat tricks that reduce bandwidth (the total number of bits transferred between the client and server) at the cost of additional rounds. However, for use cases like ours, round optimality is an absolute necessity, especially for presentation. Not only do multiple rounds have a high impact on latency, they also make the implementation far more complex.
Within these constraints, our goal is to develop PQ ACs that have as low communication cost (i.e., bandwidth consumption) and runtime as possible in the context of rate-limiting.
The academic community has produced a number of promising post-quantum ACs. In our survey of the state of the art, we evaluated several leading schemes, scoring them on their underlying primitives and performance to determine which are truly ready for the Internet. To understand the challenges, it is essential to first grasp the cryptographic building blocks used in ACs today. We’ll now discuss some of the core concepts that frequently appear in the field.
Zero-knowledge proofs (ZKPs) are a cryptographic protocol that allows a prover to convince a verifier that a statement is true without revealing the secret information, or witness. ZKPs play a central role in ACs: they allow proving statements of the secret part of the credential’s state without revealing the state itself. This is achieved by transforming the statement into a mathematical representation, such as a set of polynomial equations over a finite field. The prover then generates a proof by performing complex operations on this representation, which can only be completed correctly if they possess the valid witness.
General-purpose ZKP systems, like Scalable Transparent Arguments of Knowledge (STARKs), can prove the integrity of any computation up to a certain size. In a STARK-based system, the computational trace is represented as a set of polynomials. The prover then constructs a proof by evaluating these polynomials and committing to them using cryptographic hash functions. The verifier can then perform a quick probabilistic check on this proof to confirm that the original computation was executed correctly. Since the proof itself is just a collection of hashes and sampled polynomial values, it is secure against quantum computers, providing a statistically sound guarantee that the claimed result is valid.
Cut-and-choose is a cryptographic technique designed to ensure a prover’s honest behaviour by having a verifier check a random subset of their work. The prover first commits to multiple instances of a computation, after which the verifier randomly chooses a portion to be cut open by revealing the underlying secrets for inspection. If this revealed subset is correct, the verifier gains high statistical confidence that the remaining, un-opened instances are also correct.
This technique is important because while it is a generic tool used to build protocols secure against malicious adversaries, it also serves as a crucial case study. Its security is not trivial; for example, practical attacks on cut-and-choose schemes built with (post-quantum) homomorphic encryption have succeeded by attacking the algebraic structure of the encoding, not the encryption itself. This highlights that even generic constructions must be carefully analyzed in their specific implementation to prevent subtle vulnerabilities and information leaks.
Sigma protocols follow a more structured approach that does not require us to throw away any computations. The three-move protocol starts with a commitment phase where the prover generates some randomness, which is added to the input to generate the commitment, and sends the commitment to the verifier. Then, the verifier challenges the prover with an unpredictable challenge. To finish the proof, the prover provides a response in which they combine the initial randomness with the verifier’s challenge in a way that is only possible if the secret value, such as the solution to a discrete logarithm problem, is known.

Depiction of a Sigma protocol flow, where the prover commits to their witness $w$, the verifier challenges the prover to prove knowledge about $w$, and the prover responds with a mathematical statement that the verifier can either accept or reject.
In practice, the prover and verifier don’t run this interactive protocol. Instead, they make it non-interactive using a technique known as the Fiat-Shamir transformation. The idea is that the prover generates the challenge itself, by deriving it from its own commitment. It may sound a bit odd, but it works quite well. In fact, it’s the basis of signatures like ECDSA and even PQ signatures like ML-DSA.
Multi-party computation (MPC) is a cryptographic tool that allows multiple parties to jointly compute a function over their inputs without revealing their individual inputs to the other parties. MPC in the Head (MPCitH) is a technique to generate zero-knowledge proofs by simulating a multi-party protocol in the head of the prover.
The prover simulates the state and communication for each virtual party, commits to these simulations, and shows the commitments to the verifier. The verifier then challenges the prover to open a subset of these virtual parties. Since MPC protocols are secure even if a minority of parties are dishonest, revealing this subset doesn’t leak the secret, yet it convinces the verifier that the overall computation was correct.
This paradigm is particularly useful to us because it’s a flexible way to build post-quantum secure ZKPs. MPCitH constructions build their security from symmetric-key primitives (like hash functions). This approach is also transparent, requiring no trusted setup. While STARKs share these post-quantum and transparent properties, MPCitH often offers faster prover times for many computations. Its primary trade-off, however, is that its proofs scale linearly with the size of the circuit to prove, while STARKs are succinct, meaning their proof size grows much slower.
When a randomness source is biased or outputs numbers outside the desired range, rejection sampling can correct the distribution. For example, imagine you need a random number between 1 and 10, but your computer only gives you random numbers between 0 and 255. (Indeed, this is the case!) The rejection sampling algorithm calls the RNG until it outputs a number below 11 and above 0:

Calling the generator over and over again may seem a bit wasteful. An efficient implementation can be realized with an eXtendable Output Function (XOF). A XOF takes an input, for example a seed, and computes an arbitrarily-long output. An example is the SHAKE family (part of the SHA3 standard), and the recently proposed round-reduced version of SHAKE called TurboSHAKE.
Let’s imagine you want to have three numbers between 1 and 10. Instead of calling the XOF over and over, you can also ask the XOF for several bytes of output. Since each byte has a probability of 3.52% to be in range, asking the XOF for 174 bytes is enough to have a greater than 99% chance of finding at least three usable numbers. In fact, we can be even smarter than this: 10 fits in four bits, so we can split the output bytes into lower and higher nibbles. The probability of a nibble being in the desired range is now 56.4%:

Rejection sampling by batching queries.
Rejection sampling is a part of many cryptographic primitives, including many we’ll discuss in the schemes we look at below.
Classical anonymous credentials (ACs), such as ARC and ACT, are built from algebraic groups- specifically, elliptic curves, which are very efficient. Their security relies on the assumption that certain mathematical problems over these groups are computationally hard. The premise of post-quantum cryptography, however, is that quantum computers can solve these supposedly hard problems. The most intuitive solution is to replace elliptic curves with a post-quantum alternative. In fact, cryptographers have been working on a replacement for a number of years: CSIDH.
This raises the key question: can we simply adapt a scheme like ARC by replacing its elliptic curves with CSIDH? The short answer is no, due to a critical roadblock in constructing the necessary zero-knowledge proofs. While we can, in theory, build the required Sigma protocols or MPC-in-the-Head (MPCitH) proofs from CSIDH, they have a prerequisite that makes them unusable in practice: they require a trusted setup to ensure the prover cannot cheat. This requirement is a non-starter, as no algorithm for performing a trusted setup in CSIDH exists. The trusted setup for sigma protocols can be replaced by a combination of generic techniques from multi-party computation and cut-and-choose protocols, but that adds significant computation cost to the already computationally expensive isogeny operations.
This specific difficulty highlights a more general principle. The high efficiency of classical credentials like ARC is deeply tied to the rich algebraic structure of elliptic curves. Swapping this component for a post-quantum alternative, or moving to generic constructions, fundamentally alters the design and its trade-offs. We must therefore accept that post-quantum anonymous credentials cannot be a simple “lift-and-shift” of today’s schemes. They will require new designs built from different cryptographic primitives, such as lattices or hash functions.
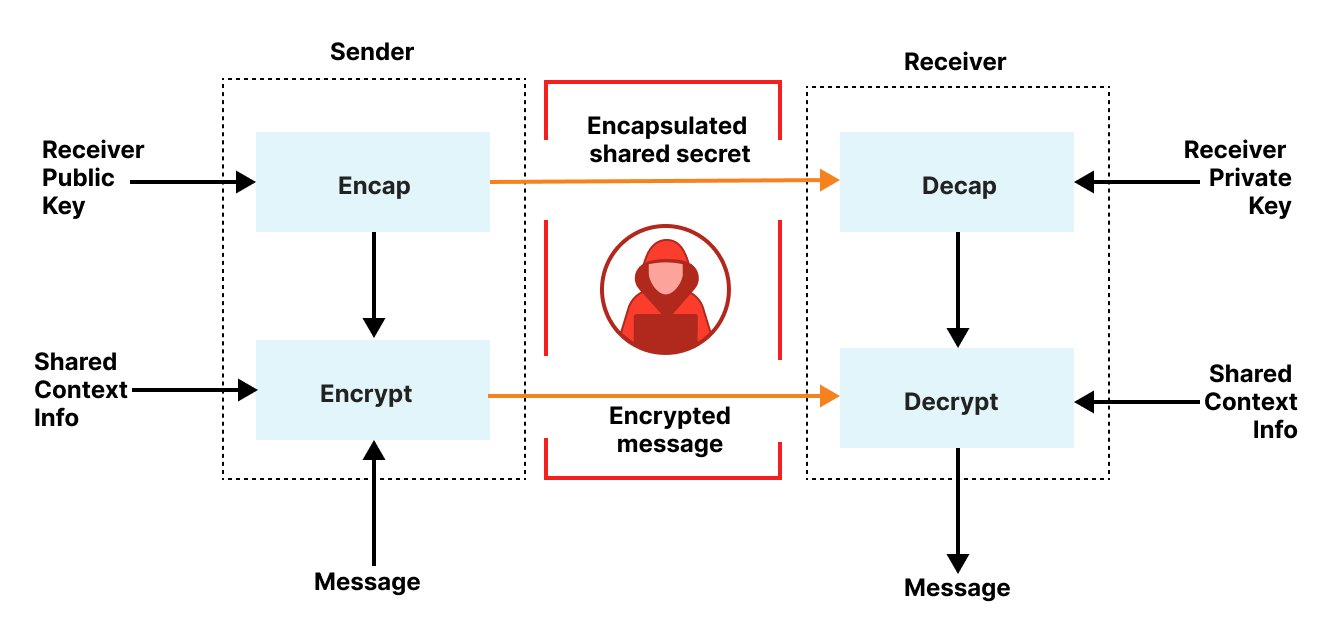
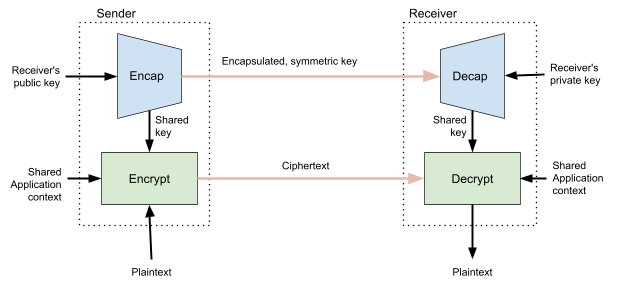
At Cloudflare, we explored a post-quantum privacy pass construction in 2023 that closely resembles the functionality needed for anonymous credentials. The main result is a generic construction that composes separate, quantum-secure building blocks: a digital signature scheme and a general-purpose ZKP system:

The figure shows a cryptographic protocol divided into two main phases: (1.) Issuance: The user commits to a message (without revealing it) and sends the commitment to the server. The server signs the commitment and returns this signed commitment, which serves as a token. The user verifies the server’s signature. (2.) Redemption: To use the token, the user presents it and constructs a proof. This proof demonstrates they have a valid signature on the commitment and opens the commitment to reveal the original message. If the server validates the proof, the user and server continue (e.g., to access a rate-limited origin).
The main appeal of this modular design is its flexibility. The experimental implementation uses a modified version of the signature ML-DSA signatures and STARKs, but the components can be easily swapped out. The design provides strong, composable security guarantees derived directly from the underlying parts. A significant speedup for the construction came from replacing the hash function SHA3 in ML-DSA with the zero-knowledge friendly Poseidon.
However, the modularity of our post-quantum Privacy Pass construction incurs a significant performance overhead demonstrated in a clear trade-off between proof generation time and size: a fast 300 ms proof generation requires a large 173 kB signature, while a 4.8s proof generation time cuts the size of the signature nearly in half. A balanced parameter set, which serves as a good benchmark for any dedicated solution to beat, took 660 ms to sign and resulted in a 112 kB signature. The implementation is currently a proof of concept, with perhaps some room for optimization. Alternatively, a different signature like FN-DSA could offer speed improvements: while its issuance is more complex, its verification is far more straightforward, boiling down to a simple hash-to-lattice computation and a norm check.
However, while this construction gives a functional baseline, these figures highlight the performance limitations for a real-time rate limiting system, where every millisecond counts. The 660 ms signing time strongly motivates the development of dedicated cryptographic constructions that trade some of the modularity for performance.
Lattices are a natural starting point when discussing potential post-quantum AC candidates. NIST standardized ML-DSA and ML-KEM as signature and KEM algorithms, both of which are based on lattices. So, are lattices the answer to post-quantum anonymous credentials?
The answer is a bit nuanced. While explicit anonymous credential schemes from lattices exist, they have shortcomings that prevent real-world deployment: for example, a recent scheme sacrifices round-optimality for smaller communication size, which is unacceptable for a service like Privacy Pass where every second counts. Given that our RTT is 100ms or less for the majority of users, each extra communication round adds tangible latency especially for those on slower Internet connections. When the final credential size is still over 100 kB, the trade-offs are hard to justify. So, our search continues. We expand our horizon by looking into blind signatures and whether we can adapt them for anonymous credentials.
A prominent paradigm in lattice-based signatures is the hash-and-sign construction. Here, the message is first hashed to a point in the lattice. Then, the signer uses their secret key, a lattice trapdoor, to generate a vector that, when multiplied with the private key, evaluates to the hashed point in the lattice. This is the core mechanism behind signature schemes like FN-DSA.

Adapting hash-and-sign for blind signatures is tricky, since the signer may not learn the message. This introduces a significant security challenge: If the user can request signatures on arbitrary points, they can mount an attack to extract the trapdoor by repeatedly requesting signatures for carefully chosen arbitrary points. These points can be used to reconstruct a short basis, which is equivalent to a key recovery.

The standard defense against this attack is to require the user to prove in zero-knowledge that the point they are asking to be signed is the blinded output of the specified hash function. However, proving hash preimages leads to the same problem as in the generic post-quantum privacy pass paper: proving a conventional hash function (like SHA3) inside a ZKP is computationally expensive and has a large communication complexity.
This difficult trade-off is at the heart of recent academic work. The state-of-the-art paper presents two lattice-based blind signature schemes with small signature sizes of 22 KB for a signature and 48 kB for a privately-verifiable protocol that may be more useful in a setting like anonymous credential. However, this focus on the final signature size comes at the cost of an impractical issuance. The user must provide ZKPs for the correct hash and lattice relations that, by the paper’s own analysis, can add to several hundred kilobytes and take 20 seconds to generate and 10 seconds to verify.
While these results are valuable for advancing the field, this trade-off is a significant barrier for any large-scale, practical system. For our use case, a protocol that increases the final signature size moderately in exchange for a more efficient and lightweight issuance process would be a more suitable and promising direction.
A promising technique for blind signatures combines the hash-and-sign paradigm with Fiat-Shamir with aborts, a method that relies on rejection sampling signatures. In this approach, the signer repeatedly attempts to generate a signature and aborts any result that may leak information about the secret key. This process ensures the final signature is statistically independent of the key and is used in modern signatures like ML-DSA. The Phoenix signature scheme uses hash-and-sign with aborts, where a message is first hashed into the lattice and signed, with rejection sampling employed to break the dependency between the signature and the private key.
Building on this foundation is an anonymous credential scheme for hash-and-sign with aborts. The main improvement over hash-and-sign anonymous credentials is that, instead of proving the validity of a hash, the user commits to their attributes, which avoids costly zero-knowledge proofs.
The scheme is fully implemented and credentials with attribute proofs just under 80 KB and signatures under 7 kB. The scheme takes less than 400 ms for issuance and 500 ms for showing the credential. The protocol also has a lot of features necessary for anonymous credentials, allowing users to prove relations between attributes and request pseudonyms for different instances.
This research presents a compelling step towards real-world deployability by combining state-of-the-art techniques to achieve a much healthier balance between performance and security. While the underlying mathematics are a bit more complex, the scheme is fully implemented and with a proof of knowledge of a signature at 40 kB and a prover time under a second, the scheme stands out as a great contender. However, for practical deployment, these figures would likely need a significant speedup to be usable in real-time systems. An improvement seems plausible, given recent advances in lattice samplers. Though the exact scale we can achieve is unclear. Still, we think it would be worthwhile to nudge the underlying design paradigm a little closer to our use cases.
While the lattice-based hash-and-sign with aborts scheme provides one path to post-quantum signatures, an alternative approach is emerging from the MPCitH variant VOLE-in-the-Head (VOLEitH).
This scheme builds on Vector Oblivious Linear Evaluation (VOLE), an interactive protocol where one party’s input vector is processed with another’s secret value delta, creating a correlation. This VOLE correlation is used as a cryptographic commitment to the prover’s input. The system provides a zero-knowledge proof because the prover is bound by this correlation and cannot forge a solution without knowing the secret delta. The verifier, in turn, just has to verify that the final equation holds when the commitment is opened. This system is linearly homomorphic, which means that two commitments can be combined. This property is ideal for the commit-and-prove paradigm, where the prover first commits to the witnesses and then proves the validity of the circuit gate by gate. The primary trade-off is that the proofs are linear in the size of the circuit, but they offer substantially better runtimes. We also use linear-sized proofs for ARC and ACT.

Example of evaluating a circuit gate by first committing to each wire and then proving the composition. This is easy for linear gates.
This commit-and-prove approach allows VOLEitH to efficiently prove the evaluation of symmetric ciphers, which are quantum-resistant. The transformation to a non-interactive protocol follows the standard MPCitH method: the prover commits to all secret values, a challenge is used to select a subset to reveal, and the prover proves consistency.
Efficient implementations operate over two mathematical fields (binary and prime) simultaneously, allowing these ZK circuits to handle both arithmetic and bitwise functions (like XORs) efficiently. Based on this foundation, a recent talk teased the potential for blind signatures from the multivariate quadratic signature scheme MAYO with sizes of just 7.5 kB and signing/verification times under 50 ms.
The VOLEitH approach, as a general-purpose solution system, represents a promising new direction for performant constructions. There are a number of competing in-the-head schemes in the NIST competition for additional signature schemes, including one based on VOLEitH. The current VOLEitH literature focuses on high-performance digital signatures, and an explicit construction for a full anonymous credential system has not yet been proposed. This means that features standard to ACs, such as multi-show unlinkability or the ability to prove relations between attributes, are not yet part of the design, whereas they are explicitly supported by the lattice construction. However, the preliminary results show great potential for performance, and it will be interesting to see the continued cryptanalysis and feature development from this line of VOLEitH in the area of anonymous credentials, especially since the general-purpose construction allows adding features easily.
|
Approach |
Pros |
Cons |
Practical Viability |
|
Flexible construction, strong security |
Large signatures (112 kB), slow (660 ms) |
Low: Performance is not great |
|
|
Potentially tiny signatures, lots of optimization potential |
Current implementation large and slow |
Low: Performance is not great |
|
|
Full AC system, good balance in communication |
Slow runtimes (1s) |
Medium: promising but performance would need to improve |
|
|
Excellent potential performance (<50ms, 7.5 kB) |
not a full AC system, not peer-reviewed |
Medium: promising research direction, no full solution available so far |
My (that is Lena’s) internship focused on a critical question: what should we look at next to build ACs for the Internet? For us, “the right direction” means developing protocols that can be integrated with real world applications, and developed collaboratively at the IETF. To make these a reality, we need researchers to look beyond blind signatures; we need a complete privacy-preserving protocol that combines blind signatures with efficient zero-knowledge proofs and properties like multi-show credentials that have an internal state. The issuance should also be sublinear in communication size with the number of presentations.
So, with the transition to post-quantum cryptography on the horizon, what are our thoughts on the current IETF proposals? A 2022 NIST presentation on the current state of anonymous credentials states that efficient post-quantum secure solutions are basically non-existent. We argue that the last three years show nice developments in lattices and MPCitH anonymous credentials, but efficient post-quantum protocols still need work. Moving protocols into a post-quantum world isn’t just a matter of swapping out old algorithms for new ones. A common approach on constructing post-quantum versions of classical protocols is swapping out the building blocks for their quantum-secure counterpart.
We believe this approach is essential, but not forward-looking. In addition to identifying how modern concerns can be accommodated on old cryptographic designs, we should be building new, post-quantum native protocols.
-
For ARC, the conceptual path to a post-quantum construction seems relatively straightforward. The underlying cryptography follows a similar structure as the lattice-based anonymous credentials, or, when accepting a protocol with fewer features, the generic post-quantum privacy-pass construction. However, we need to support per-origin rate-limiting, which allows us to transform a token at an origin without leaking us being able to link the redemption to redemptions at other origins, a feature that none of the post-quantum anonymous credential protocols or blind signatures support. Also, ARC is sublinear in communication size with respect to the number of tokens issued, which so far only the hash-and-sign with abort lattices achieve, although the notion of “limited shows” is not present in the current proposal. In addition, it would be great to gauge efficient implementations, especially for blind signatures, as well as looking into efficient zero-knowledge proofs.
-
For ACT, we need the protocols for ARC and an additional state. Even for the simplest counter, we need the ability to homomorphically subtract from that balance within the credential itself. This is a much more complex cryptographic requirement. It would also be interesting to see a post-quantum double-spend prevention that enforces the sequential nature of ACT.
Working on ACs and other privacy-preserving cryptography inevitably leads to a major bottleneck: efficient zero-knowledge proofs, or to be more exact, efficiently proving hash function evaluations. In a ZK circuit, multiplications are expensive. Each wire in the circuit that performs a multiplication requires a cryptographic commitment, which adds communication overhead. In contrast, other operations like XOR can be virtually “free.” This makes a huge difference in performance. For example, SHAKE (the primitive used in ML-DSA) can be orders of magnitude slower than arithmetization-friendly hash functions inside a ZKP. This is why researchers and implementers are already using Poseidon or Poseidon2 to make their protocols faster.
Currently, Ethereum is seriously considering migrating Ethereum to the Poseidon hash and calls for cryptanalysis, but there is no indication of standardization. This is a problem: papers increasingly use different instantiations of Poseidon to fit their use-case, and there are more and more zero–knowledge friendly hash functions coming out, tailored to different use-cases. We would like to see at least one XOF and one hash each for a prime field and for a binary field, ideally with some security levels. And also, is Poseidon the best or just the most well-known ZK friendly cipher? Is it always secure against quantum computers (like we believe AES to be), and are there other attacks like the recent attacks on round-reduced versions?
Looking at algebra and zero-knowledge brings us to a fundamental debate in modern cryptography. Imagine a line representing the spectrum of research: On one end, you have protocols built on very well-analyzed standard assumptions like the SIS problem on lattices or the collision resistance of SHA3. On the other end, you have protocols that gain massive efficiency by using more algebraic structure, which in turn relies on newer, stronger cryptographic assumptions. Breaking novel hash functions is somewhere in the middle.

The answer for the Internet can’t just be to relent and stay at the left end of our graph to be safe. For the ecosystem to move forward, we need to have confidence in both. We need more research to validate the security of ZK-friendly primitives like Poseidon, and we need more scrutiny on the stronger assumptions that enable efficient algebraic methods.
As we’ve explored, the cryptographic properties that make classical ACs efficient, particularly the rich structure of elliptic curves, do not have direct post-quantum equivalents. Our survey of the state of the art from generic compositions using STARKs, to various lattice-based schemes, and promising new directions like MPC-in-the-head, reveals a field full of potential but with no clear winner. The trade-offs between communication cost, computational cost, and protocol rounds remain a significant barrier to practical, large-scale deployment, especially in comparison to elliptic curve constructions.
To bridge this gap, we must move beyond simply building post-quantum blind signatures. We challenge our colleagues in academia and industry to develop complete, post-quantum native protocols that address real-world needs. This includes supporting essential features like the per-origin rate-limiting required for ARC or the complex stateful credentials needed for ACT.
A critical bottleneck for all these approaches is the lack of efficient, standardized, and well-analyzed zero-knowledge-friendly hash functions. We need to research zero-knowledge friendly primitives and build industry-wide confidence to enable efficient post-quantum privacy.
If you’re working on these problems, or you have experience in the management and deployment of classical credentials, now is the time to engage. The world is rapidly adopting credentials for everything from digital identity to bot management, and it is our collective responsibility to ensure these systems are private and secure for a post-quantum future. We can tell for certain that there are more discussions to be had, and if you’re interested in helping to build this more secure and private digital world, we’re hiring 1,111 interns over the course of next year, and have open positions!