Post Syndicated from James Beswick original https://aws.amazon.com/blogs/compute/getting-started-with-rpa-using-aws-step-functions-and-amazon-textract/
This post is courtesy of Joe Tringali, Solutions Architect.
Many organizations are using robotic process automation (RPA) to automate workflow, back-office processes that are labor-intensive. RPA, as software bots, can often handle many of these activities. Often RPA workflows contain repetitive manual tasks that must be done by humans, such as viewing invoices to find payment details.
AWS Step Functions is a serverless function orchestrator and workflow automation tool. Amazon Textract is a fully managed machine learning service that automatically extracts text and data from scanned documents. Combining these services, you can create an RPA bot to automate the workflow and enable employees to handle more complex tasks.
In this post, I show how you can use Step Functions and Amazon Textract to build a workflow that enables the processing of invoices. Download the code for this solution from https://github.com/aws-samples/aws-step-functions-rpa.
Overview
The following serverless architecture can process scanned invoices in PDF or image formats for submitting payment information to a database.
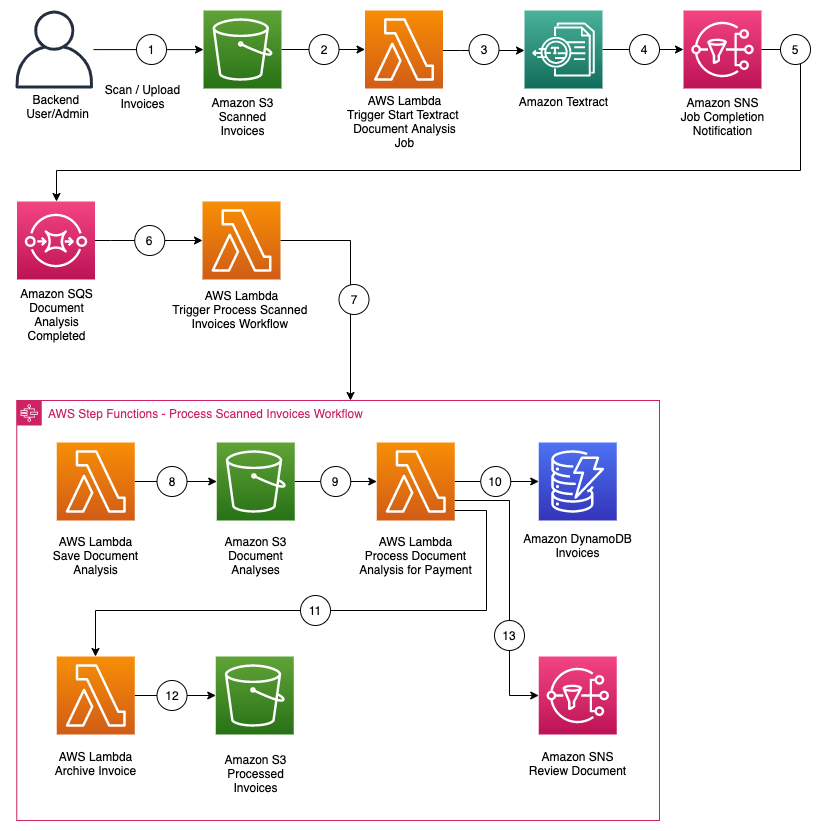
To implement this architecture, I use single-purpose Lambda functions and Step Functions to build the workflow:
- Invoices are scanned and loaded into an Amazon Simple Storage Service (S3) bucket.
- The loading of an invoice into Amazon S3 triggers an AWS Lambda function to be invoked.
- The Lambda function starts an asynchronous Amazon Textract job to analyze the text and data of the scanned invoice.
- The Amazon Textract job publishes a completion notification message with a status of “SUCCEEDED” or “FAILED” to an Amazon Simple Notification Service (SNS) topic.
- SNS sends the message to an Amazon Simple Queue Service (SQS) queue that is subscribed to the SNS topic.
- The message in the SQS queue triggers another Lambda function.
- The Lambda function initiates a Step Functions state machine to process the results of the Amazon Textract job.
- For an Amazon Textract job that completes successfully, a Lambda function saves the document analysis into an Amazon S3 bucket.
- The loading of the document analysis to Amazon S3 triggers another Lambda function.
- The Lambda function retrieves the text and data of the scanned invoice to find the payment information. It writes an item to an Amazon DynamoDB table with a status indicating if the invoice can be processed.
- If the DynamoDB item contains the payment information, another Lambda function is invoked.
- The Lambda function archives the processed invoice into another S3 bucket.
- If the DynamoDB item does not contain the payment information, a message is published to an Amazon SNS topic requesting that the invoice be reviewed.
Amazon Textract can extract information from the various invoice images and associate labels with the data. You must then handle the various labels that different invoices may associate with the payee name, due date, and payment amount.
Determining payee name, due date and payment amount
After the document analysis has been saved to S3, a Lambda function retrieves the text and data of the scanned invoice to find the information needed for payment. However, invoices can use a variety of labels for the same piece of data, such a payment’s due date.
In the example invoices included with this blog, the payment’s due date is associated with the labels “Pay On or Before”, “Payment Due Date” and “Payment Due”. Payment amounts can also have different labels, such as “Total Due”, “New Balance Total”, “Total Current Charges”, and “Please Pay”. To address this, I use a series of helper functions in the app.py file in the process_document_analysis folder of the GitHub repo.
In app.py, there is the following get_ky_map helper function:
def get_kv_map(blocks):
key_map = {}
value_map = {}
block_map = {}
for block in blocks:
block_id = block['Id']
block_map[block_id] = block
if block['BlockType'] == "KEY_VALUE_SET":
if 'KEY' in block['EntityTypes']:
key_map[block_id] = block
else:
value_map[block_id] = block
return key_map, value_map, block_map
The get_kv_map function is invoked by the Lambda function handler. It iterates over the “Blocks” element of the document analysis produced by Amazon Textract to create dictionaries of keys (labels) and values (data) associated with each block identified by Amazon Textract. It then invokes the following get_kv_relationship helper function:
def get_kv_relationship(key_map, value_map, block_map):
kvs = {}
for block_id, key_block in key_map.items():
value_block = find_value_block(key_block, value_map)
key = get_text(key_block, block_map)
val = get_text(value_block, block_map)
kvs[key] = val
return kvs
The get_kv_relationship function merges the key and value dictionaries produced by the get_kv_map function to create a single Python key value dictionary where labels are the keys to the dictionary and the invoice’s data are the values. The handler then invokes the following get_line_list helper function:
def get_line_list(blocks):
line_list = []
for block in blocks:
if block['BlockType'] == "LINE":
if 'Text' in block:
line_list.append(block["Text"])
return line_list
Extracting payee names is more complex because the data may not be labeled. The payee may often differ from the entity sending the invoice. With the Amazon Textract analysis in a format more easily consumable by Python, I use the following get_payee_name helper function to parse and extract the payee:
def get_payee_name(lines):
payee_name = ""
payable_to = "payable to"
payee_lines = [line for line in lines if payable_to in line.lower()]
if len(payee_lines) > 0:
payee_line = payee_lines[0]
payee_line = payee_line.strip()
pos = payee_line.lower().find(payable_to)
if pos > -1:
payee_line = payee_line[pos + len(payable_to):]
if payee_line[0:1] == ':':
payee_line = payee_line[1:]
payee_name = payee_line.strip()
return payee_name
The get_amount helper function searches the key value dictionary produced by the get_kv_relationship function to retrieve the payment amount:
def get_amount(kvs, lines):
amount = None
amounts = [search_value(kvs, amount_tag) for amount_tag in amount_tags if search_value(kvs, amount_tag) is not None]
if len(amounts) > 0:
amount = amounts[0]
else:
for idx, line in enumerate(lines):
if line.lower() in amount_tags:
amount = lines[idx + 1]
break
if amount is not None:
amount = amount.strip()
if amount[0:1] == '$':
amount = amount[1:]
return amount
The amount_tags variable contains a list of possible labels associated with the payment amount:
amount_tags = ["total due", "new balance total", "total current charges", "please pay"]
Similarly, the get_due_date helper function searches the key value dictionary produced by the get_kv_relationship function to retrieve the payment due date:
def get_due_date(kvs):
due_date = None
due_dates = [search_value(kvs, due_date_tag) for due_date_tag in due_date_tags if search_value(kvs, due_date_tag) is not None]
if len(due_dates) > 0:
due_date = due_dates[0]
if due_date is not None:
date_parts = due_date.split('/')
if len(date_parts) == 3:
due_date = datetime(int(date_parts[2]), int(date_parts[0]), int(date_parts[1])).isoformat()
else:
date_parts = [date_part for date_part in re.split("\s+|,", due_date) if len(date_part) > 0]
if len(date_parts) == 3:
datetime_object = datetime.strptime(date_parts[0], "%b")
month_number = datetime_object.month
due_date = datetime(int(date_parts[2]), int(month_number), int(date_parts[1])).isoformat()
else:
due_date = datetime.now().isoformat()
return due_date
The due_date_tag contains a list of possible labels associated with the payment due:
due_date_tags = ["pay on or before", "payment due date", "payment due"]
If all required elements needed to issue a payment are found, it adds an item to the DynamoDB table with a status attribute of “Approved for Payment”. If the Lambda function cannot determine the value of one or more required elements, it adds an item to the DynamoDB table with a status attribute of “Pending Review”.
Payment Processing
If the item in the DynamoDB table is marked “Approved for Payment”, the processed invoice is archived. If the item’s status attribute is marked “Pending Review”, an SNS message is published to an SNS Pending Review topic. You can subscribe to this topic so that you can add additional labels to the Python code for determining payment due dates and payment amounts.
Note that the Lambda functions are single-purpose functions, and all workflow logic is contained in the Step Functions state machine. This diagram shows the various tasks (states) of a successful workflow.

For more information about this solution, download the code from the GitHub repo (https://github.com/aws-samples/aws-step-functions-rpa).
Prerequisites
Before deploying the solution, you must install the following prerequisites:
- Python.
- AWS Command Line Interface (AWS CLI) – for instructions, see Installing the AWS CLI.
- AWS Serverless Application Model Command Line Interface (AWS SAM CLI) – for instructions, see Installing the AWS SAM CLI.
Deploying the solution
The solution creates the following S3 buckets with names suffixed by your AWS account ID to prevent a global namespace collision of your S3 bucket names:
- scanned-invoices-<YOUR AWS ACCOUNT ID>
- invoice-analyses-<YOUR AWS ACCOUNT ID>
- processed-invoices-<YOUR AWS ACCOUNT ID>
The following steps deploy the example solution in your AWS account. The solution deploys several components including a Step Functions state machine, Lambda functions, S3 buckets, a DynamoDB table for payment information, and SNS topics.
AWS CloudFormation requires an S3 bucket and stack name for deploying the solution. To deploy:
- Download code from GitHub repo (https://github.com/aws-samples/aws-step-functions-rpa).
- Run the following command to build the artifacts locally on your workstation:
sam build - Run the following command to create a CloudFormation stack and deploy your resources:
sam deploy --guided --capabilities CAPABILITY_NAMED_IAM
Monitor the progress and wait for the completion of the stack creation process from the AWS CloudFormation console before proceeding.
Testing the solution
To test the solution, upload the PDF test invoices to the S3 bucket named scanned-invoices-<YOUR AWS ACCOUNT ID>.
A Step Functions state machine with the name <YOUR STACK NAME>-ProcessedScannedInvoiceWorkflow runs the workflow. Amazon Textract document analyses are stored in the S3 bucket named invoice-analyses-<YOUR AWS ACCOUNT ID>, and processed invoices are stored in the S3 bucket named processed-invoices-<YOUR AWS ACCOUNT ID>. Processed payments are found in the DynamoDB table named <YOUR STACK NAME>-invoices.
You can monitor the status of the workflows from the Step Functions console. Upon completion of the workflow executions, review the items added to DynamoDB from the Amazon DynamoDB console.
Cleanup
To avoid ongoing charges for any resources you created in this blog post, delete the stack:
- Empty the three S3 buckets created during deployment using the S3 console:
– scanned-invoices-<YOUR AWS ACCOUNT ID>
– invoice-analyses-<YOUR AWS ACCOUNT ID>
– processed-invoices-<YOUR AWS ACCOUNT ID> - Delete the CloudFormation stack created during deployment using the CloudFormation console.
Conclusion
In this post, I showed you how to use a Step Functions state machine and Amazon Textract to automatically extract data from a scanned invoice. This eliminates the need for a person to perform the manual step of reviewing an invoice to find payment information to be fed into a backend system. By replacing the manual steps of a workflow with automation, an organization can free up their human workforce to handle more value-added tasks.
To learn more, visit AWS Step Functions and Amazon Textract for more information. For more serverless learning resources, visit https://serverlessland.com.