Post Syndicated from Asser Moustafa original https://aws.amazon.com/blogs/big-data/how-comcast-uses-aws-to-rapidly-store-and-analyze-large-scale-telemetry-data/
This blog post is co-written by Russell Harlin from Comcast Corporation.
Comcast Corporation creates incredible technology and entertainment that connects millions of people to the moments and experiences that matter most. At the core of this is Comcast’s high-speed data network, providing tens of millions of customers across the country with reliable internet connectivity. This mission has become more important now than ever.
This post walks through how Comcast used AWS to rapidly store and analyze large-scale telemetry data.
Background
At Comcast, we’re constantly looking for ways to gain new insights into our network and improve the overall quality of service. Doing this effectively can involve scaling solutions to support analytics across our entire network footprint. For this particular project, we wanted an extensible and scalable solution that could process, store, and analyze telemetry reports, one per network device every 5 minutes. This data would then be used to help measure quality of experience and determine where network improvements could be made.
Scaling big data solutions is always challenging, but perhaps the biggest challenge of this project was the accelerated timeline. With 2 weeks to deliver a prototype and an additional month to scale it, we knew we couldn’t go through the traditional bake-off of different technologies, so we had to either go with technologies we were comfortable with or proven managed solutions.
For the data streaming pipeline, we already had the telemetry data coming in on an Apache Kafka topic, and had significant prior experience using Kafka combined with Apache Flink to implement and scale streaming pipelines, so we decided to go with what we knew. For the data storage and analytics, we needed a suite of solutions that could scale quickly, had plenty of support, and had an ecosystem of well-integrated tools to solve any problem that might arise. This is where AWS was able to meet our needs with technologies like Amazon Simple Storage Service (Amazon S3), AWS Glue, Amazon Athena, and Amazon Redshift.
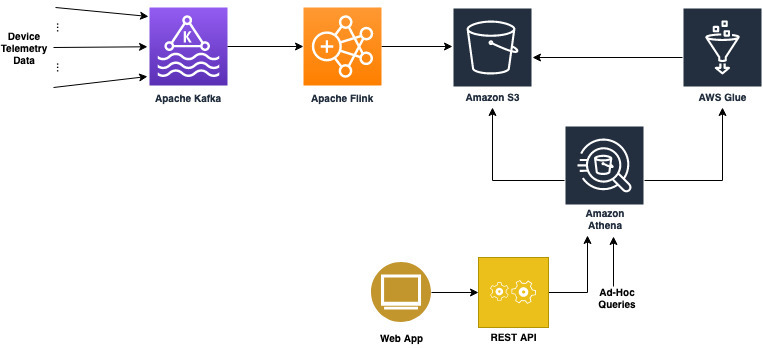
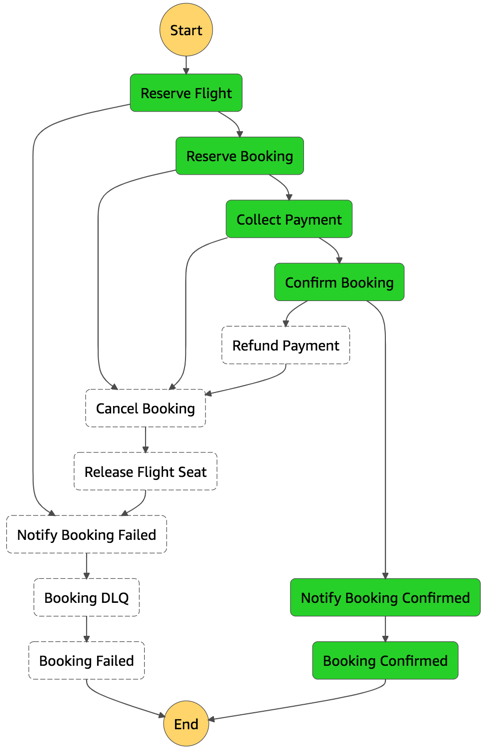
Initial architecture
Our initial prototype architecture for the data store needed to be fast and simple so that we could unblock the development of the other elements of the budding telemetry solution. We needed three key things out of it:
- The ability to easily fetch raw telemetry records and run more complex analytical queries
- The capacity to integrate seamlessly with the other pieces of the pipeline
- The possibility that it could serve as a springboard to a more scalable long-term solution
The first instinct was to explore solutions we used in the past. We had positive experiences with using nosql databases, like Cassandra, to store and serve raw data records, but it was clear these wouldn’t meet our need for running ad hoc analytical queries. Likewise, we had experience with more flexible RDBMs, like Postgres, for handling more complicated queries, but we knew that those wouldn’t scale to meet our requirement to store tens to hundreds of billions of rows. Therefore, any prototyping with one of these approaches would be considered throwaway work.
After moving on from these solutions, we quickly settled on using Amazon S3 with Athena. Amazon S3 provides low-cost storage with near-limitless scaling, so we knew we could store as much historical data as required and Athena would provide serverless, on-demand querying of our data. Additionally, Amazon S3 is known to be a launching pad to many other data store solutions both inside and outside the AWS ecosystem. This was perfect for the exploratory prototyping phase.
Integrating it into the rest of our pipeline would also prove simple. Writing the data to Amazon S3 from our Flink job was straightforward and could be done using the readily available Flink streaming file sink with an Amazon S3 bucket as the destination. When the data was available in Amazon S3, we ran AWS Glue to index our Parquet-formatted data and generate schemas in the AWS Glue metastore for searching using Athena with standard SQL.
The following diagram illustrates this architecture.

Using Amazon S3 and Athena allowed us to quickly unblock development of our Flink pipeline and ensure that the data being passed through was correct. Additionally, we used the AWS SDK to connect to Athena from our northbound Golang microservice and provide REST API access to our data for our custom web application. This allowed us to prove out an end-to-end solution with almost no upfront cost and very minimal infrastructure.
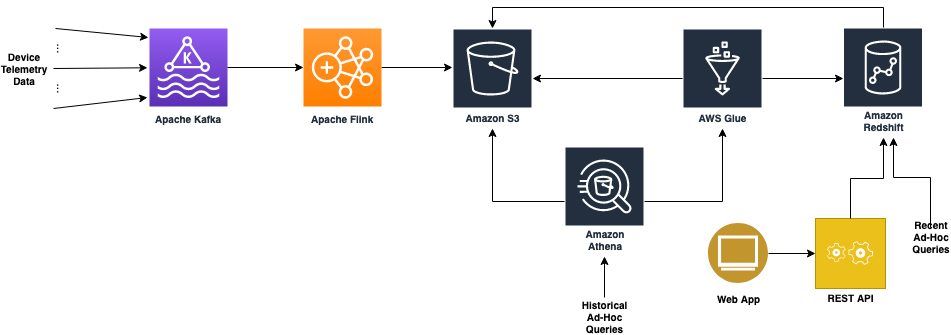
Updated architecture
As application and service development proceeded, it became apparent that Amazon Athena performed for developers running ad hoc queries, but wasn’t going to work as a long-term responsive backend for our microservices and user interface requirements.
One of the primary use cases of this solution was to look at device-level telemetry reports for a period of time and plot and track different aspects of their quality of experience. Because this most often involves solving problems happening in the now, we needed an improved data store for the most recent hot data.
This led us to Amazon Redshift. Amazon Redshift requires loading the data into a dedicated cluster and formulating a schema tuned for your use cases.
The following diagram illustrates this updated architecture.

Data loading and storage requirements
For loading and storing the data in Amazon Redshift, we had a few fundamental requirements:
- Because our Amazon Redshift solution would be for querying data to troubleshoot problems happening as recent as the current hour, we needed to minimize the latency of the data load and keep up with our scale while doing it. We couldn’t live with nightly loads.
- The pipeline had to be robust and recover from failures automatically.
There’s a lot of nuance that goes into making this happen, and we didn’t want to worry about handling these basic things ourselves, because this wasn’t where we were going to add value. Luckily, because we were already loading the data into Amazon S3, AWS Glue ETL satisfied these requirements and provided a fast, reliable, and scalable solution to do periodic loads from our Amazon S3 data store to our Amazon Redshift cluster.
A huge benefit of AWS Glue ETL is that it provides many opportunities to tune your ETL pipeline to meet your scaling needs. One of our biggest challenges was that we write multiple files to Amazon S3 from different regions every 5 minutes, which results in many small files. If you’re doing infrequent nightly loads, this may not pose a problem, but for our specific use case, we wanted to load data at least every hour and multiple times an hour if possible. This required some specific tuning of the default ETL job:
- Amazon S3 list implementation – This allows the Spark job to handle files in batches and optimizes reads for a large number of files, preventing out of memory issues.
- Pushdown predicates – This tells the load to skip listing any partitions in Amazon S3 that you know won’t be a part of the current run. For frequent loads, this can mean skipping a lot of unnecessary file listing during each job run.
- File grouping – This allows the read from Amazon S3 to group files together in batches when reading from Amazon S3. This greatly improves performance when reading from a large number of small files.
- AWS Glue 2.0 – When we were starting our development, only AWS Glue 1.0 was available, and we’d frequently see Spark cluster start times of over 10 minutes. This becomes problematic if you want to run the ETL job more frequently because you have to account for the cluster startup time in your trigger timings. When AWS Glue 2.0 came out, those start times consistently dropped to under 1 minute and they became a afterthought.
With these tunings, as well as increasing the parallelism of the job, we could meet our requirement of loading data multiple times an hour. This made relevant data available for analysis sooner.
Modeling, distributing, and sorting the data
Aside from getting the data into the Amazon Redshift cluster in a timely manner, the next consideration was how to model, distribute, and sort the data when it was in the cluster. For our data, we didn’t have a complex setup with tens of tables requiring extensive joins. We simply had two tables: one for the device-level telemetry records and one for records aggregated at a logical grouping.
The bulk of the initial query load would be centered around serving raw records from these tables to our web application. These types of raw record queries aren’t difficult to handle from a query standpoint, but do present challenges when dealing with tens of millions of unique devices and a report granularity of 5 minutes. So we knew we had to tune the database to handle these efficiently. Additionally, we also needed to be able to run more complex ad hoc queries, like getting daily summaries of each table so that higher-level problem areas could be more easily tracked and spotted in the network. These queries, however, were less time sensitive and could be run on an ad hoc, batch-like basis where responsiveness wasn’t as important.
The schema fields themselves were more or less one-to-one mappings from the respective Parquet schemas. The challenge came, however, in picking partition keys and sorting columns. For partition keys, we identified a logical device grouping column present in both our tables as the one column we were likely to join on. This seemed like a natural fit to partition on and had good enough cardinality that our distribution would be adequate.
For the sorting keys, we knew we’d be searching by the device identifier and the logical grouping; for the respective tables, and we knew we’d be searching temporally. So the primary identifier column of each table and the timestamp made sense to sort on. The documented sort key order suggestion was to use the timestamp column as the first value in the sort key, because it could provide dataset filtering on a specific time period. This initially worked well enough and we were able to get a performance improvement over Athena, but as we scaled and added more data, our raw record retrieval queries were rapidly slowing down. To help with this, we made two adjustments.
The first adjustment came with a change to the sort key. The first part of this involved swapping the order of the timestamp and the primary identifier column. This allowed us to filter down to the device and then search through the range of timestamps on just that device, skipping over all irrelevant devices. This provided significant performance gains and cut our raw record query times by several multiples. The second part of the sort key adjustment involved adding another column (a node-level identifier) to the beginning of the sort key. This allowed us to have one more level of data filtering, which further improved raw record query times.
One trade-off made while making these sort key adjustments was that our more complex aggregation queries had a noticeable decline in performance. This was because they were typically run across the entire footprint of devices and could no longer filter as easily based on time being the first column in the sort key. Fortunately, because these were less frequent and could be run offline if necessary, this performance trade-off was considered acceptable.
If the frequency of these workloads increases, we can use materialized views in Amazon Redshift, which can help avoid unnecessary reruns of the complex aggregations if minimal-to-no data changes in the underlying base tables have occurred since the last run.
The final adjustment was cluster scaling. We chose to use the Amazon Redshift next-generation RA3 nodes for a number of benefits, but three especially key benefits:
- RA3 clusters allow for practically unlimited storage in our cluster.
- The RA3 ability to scale storage and compute independently paired really well with our expectations and use cases. We fully expected our Amazon Redshift storage footprint to continue to grow, as well as the number, shape, and sizes of our use cases and users, but data and workloads wouldn’t necessarily grow in lockstep. Being able to scale the cluster’s compute power independent of storage (or vice versa) was a key technical requirement and cost-optimization for us.
- RA3 clusters come with Amazon Redshift managed storage, which places the burden on Amazon Redshift to automatically situate data based on its temperature for consistently peak performance. With managed storage, hot data was cached on a large local SSD cache in each node, and cold data was kept in the Amazon Redshift persistent store on Amazon S3.
After conducting performance benchmarks, we determined that our cluster was under-powered for the amount of data and workloads it was serving, and we would benefit from greater distribution and parallelism (compute power). We easily resized our Amazon Redshift cluster to double the number of nodes within minutes, and immediately saw a significant performance boost. With this, we were able to recognize that as our data and workloads scaled, so too should our cluster.
Looking forward, we expect that there will be a relatively small population of ad hoc and experimental workloads that will require access to additional datasets sitting in our data lake, outside of Amazon Redshift in our data lake—workloads similar to the Athena workloads we previously observed. To serve that small customer base, we can leverage Amazon Redshift Spectrum, which empowers users to run SQL queries on external tables in our data lake, similar to SQL queries on any other table within Amazon Redshift, while allowing us to keep costs as lean as possible.
This final architecture provided us with the solid foundation of price, performance, and flexibility for our current set of analytical use cases—and, just as important, the future use cases that haven’t shown themselves yet.
Summary
This post details how Comcast leveraged AWS data store technologies to prototype and scale the serving and analysis of large-scale telemetry data. We hope to continue to scale the solution as our customer base grows. We’re currently working on identifying more telemetry-related metrics to give us increased insight into our network and deliver the best quality of experience possible to our customers.
About the Authors
 Russell Harlin is a Senior Software Engineer at Comcast based out of the San Francisco Bay Area. He works in the Network and Communications Engineering group designing and implementing data streaming and analytics solutions.
Russell Harlin is a Senior Software Engineer at Comcast based out of the San Francisco Bay Area. He works in the Network and Communications Engineering group designing and implementing data streaming and analytics solutions.
 Asser Moustafa is an Analytics Specialist Solutions Architect at AWS based out of Dallas, Texas. He advises customers in the Americas on their Amazon Redshift and data lake architectures and migrations, starting from the POC stage to actual production deployment and maintenance
Asser Moustafa is an Analytics Specialist Solutions Architect at AWS based out of Dallas, Texas. He advises customers in the Americas on their Amazon Redshift and data lake architectures and migrations, starting from the POC stage to actual production deployment and maintenance
 Amit Kalawat is a Senior Solutions Architect at Amazon Web Services based out of New York. He works with enterprise customers as they transform their business and journey to the cloud.
Amit Kalawat is a Senior Solutions Architect at Amazon Web Services based out of New York. He works with enterprise customers as they transform their business and journey to the cloud.





























 Jignesh Gohel is a Technical Account Manager at AWS. In this role, he provides advocacy and strategic technical guidance to help plan and build solutions using best practices, and proactively keep customers’ AWS environments operationally healthy. He is passionate about building modular and scalable enterprise systems on AWS using serverless technologies. Besides work, Jignesh enjoys spending time with family and friends, traveling and exploring the latest technology trends.
Jignesh Gohel is a Technical Account Manager at AWS. In this role, he provides advocacy and strategic technical guidance to help plan and build solutions using best practices, and proactively keep customers’ AWS environments operationally healthy. He is passionate about building modular and scalable enterprise systems on AWS using serverless technologies. Besides work, Jignesh enjoys spending time with family and friends, traveling and exploring the latest technology trends. Suman Koduri is a Global Category Lead for Data & Analytics category in AWS Marketplace. He is focused towards business development activities to further expand the presence and success of Data & Analytics ISVs in AWS Marketplace. In this role, he leads the scaling, and evolution of new and existing ISVs, as well as field enablement and strategic customer advisement for the same. In his spare time, he loves running half marathon’s and riding his motorcycle.
Suman Koduri is a Global Category Lead for Data & Analytics category in AWS Marketplace. He is focused towards business development activities to further expand the presence and success of Data & Analytics ISVs in AWS Marketplace. In this role, he leads the scaling, and evolution of new and existing ISVs, as well as field enablement and strategic customer advisement for the same. In his spare time, he loves running half marathon’s and riding his motorcycle.