Post Syndicated from Nihar Sheth original https://aws.amazon.com/blogs/big-data/retaining-data-streams-up-to-one-year-with-amazon-kinesis-data-streams/
Streaming data is used extensively for use cases like sharing data between applications, streaming ETL (extract, transform, and load), real-time analytics, processing data from internet of things (IoT) devices, application monitoring, fraud detection, live leaderboards, and more. Typically, data streams are stored for short durations of time before being loaded into a permanent data store like a data lake or analytics service.
Additional use cases are becoming more prevalent that may require you retain data in streams for longer periods of time. For example, compliance programs like HIPAA and FedRAMP may require you to store raw data for more than a few days or weeks, or you may want to backtest machine learning (ML) algorithms with historical data that may be several months old.
A challenge arises when you want to process historical data and newly arriving data streams. This requires complex logic to access your data lake and your data stream store, or two sets of code—one to process data from your data lake and one to process your new data streams.
Amazon Kinesis Data Streams solves this challenge by storing your data streams up to 1 year with long-term retention. You can use the same Kinesis Data Streams code base to process both historical and newly arriving data streams, and continue to use features like enhanced fan-out to read large data volumes at very high throughput.
In this post, we describe how long-term retention enables new use cases by bridging real-time and historical data processing. We also demonstrate how you can reduce the time to retrieve 30 days of data from a data stream by an order of magnitude using Kinesis Data Streams enhanced fan-out.
Simple setup, no resource provisioning
Kinesis Data Streams durably stores all data stream records in a shard, an append-only log ordered by arrival time. The time period from when a record is added to when it’s no longer accessible is called the retention period. A Kinesis data stream stores records for 24 hours by default, up to 365 days (8,760 hours). Applications can start reading data at any point in the retention period in the exact order in which the data stream is stored. Shards enable these applications to process data in parallel and at low-latency.
You can select a preset retention period or define a custom retention period in days or hours using the Kinesis Data Streams console, as in the following screenshot.
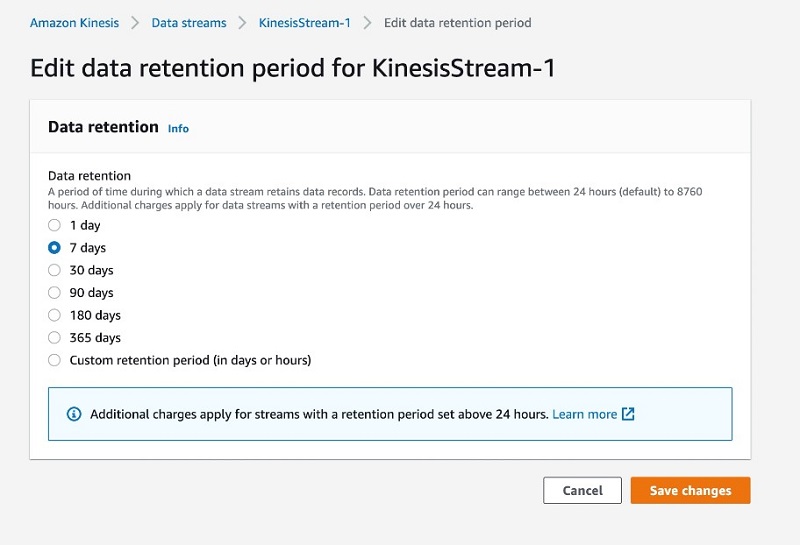
The default retention period is 24 hours and covers scenarios where intermittent lags in processing need to catch up with the real-time data. You can extend retention up to 7 days to reprocess slightly aged data to resolve potential downstream data losses. You can also use long-term retention to store data for more than 7 days and up to 365 days to reprocess historical data for use cases like algorithm backtesting, data store backfills, and auditing. For more information, see Changing the Data Retention Period.
Similarly, you can use the following AWS Command Line Interface (AWS CLI) command to set the retention period in hours (the following code sets it to 9 days, or 216 hours):
Read new and historical data, no code changes necessary
All the data captured in the stream is stored in a durable, encrypted, and secure manner for the specified retention period up to a maximum of 1 year. You can store any amount of data, retrieve it by specifying a start position, and read sequentially using the familiar getRecords and SubscribeToShard APIs. The start position can be the sequence number of a data record in a shard or a timestamp. This enables you to use the same code to process older data. You can set up multiple consuming applications to start processing data at different points in the data stream.
Speed up data reads using enhanced fan-out consumers
Kinesis Data Streams provides two types of models to consume data: shared throughput consumer and enhanced fan-out (EFO) consumer. In the shared throughput consumer model, all the consuming applications share 2 MB/s per shard read throughput and a 5 transactions per second (TPS) quota. In the enhanced fan-out model, each consumer gets a dedicated read throughput of 2MB/s per shard. Because it uses an HTTP/2 data retrieval API, there is no longer a limit of 5 TPS. You can attach up to 20 EFO consumers to a single stream and read data at a total rate of 40MB/s per shard. Because each consumer gets dedicated read throughput, processing one doesn’t impact another. So you can attach new consumers to process old data without worrying about the performance of the existing consumer processing real-time data. For example, you can retrain an ML model in an ad hoc fashion without impacting real-time workflows.
You can add and remove EFO consumers at any time and avoid paying for over-provisioned resources. For example, when backtesting, you can register EFO consumers before the test and remove them after completion. You’re only charged for resources used during the test. Also, you can use EFO consumers to accelerate the speed of processing. Each consuming application can process different parts of streams across the retention period to process all the data in parallel, thereby dramatically reducing the total processing time.
Clickstream pipeline use case
Let’s look at a clickstream use case to see how this works for an existing streaming pipeline like the one in the following diagram.
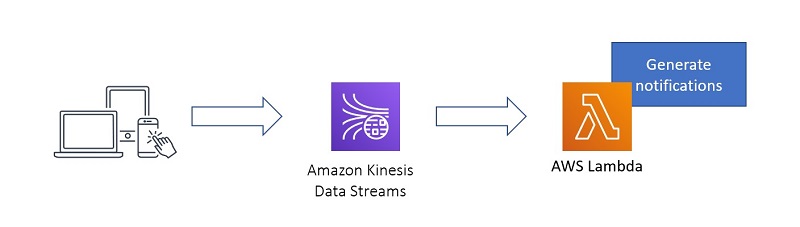
This pipeline takes clickstream data and creates an alert every time a user leaves your ecommerce site without purchasing the items in their cart. A simple pipeline like this is a great way to start with stream processing, but soon you may want to implement a recommendation system based on user activity on your website and mobile app. To do this, you need to gather historical data in your existing data stream and send it to Amazon Simple Storage Service (Amazon S3) so it can be used for training a recommendation ML model. This scenario illustrates a key benefit of enabling long-term retention: it gives you the flexibility to “go back in time” and replay the existing data in your stream to generate new analytics that you may not have considered when you initially set up the streaming pipeline.
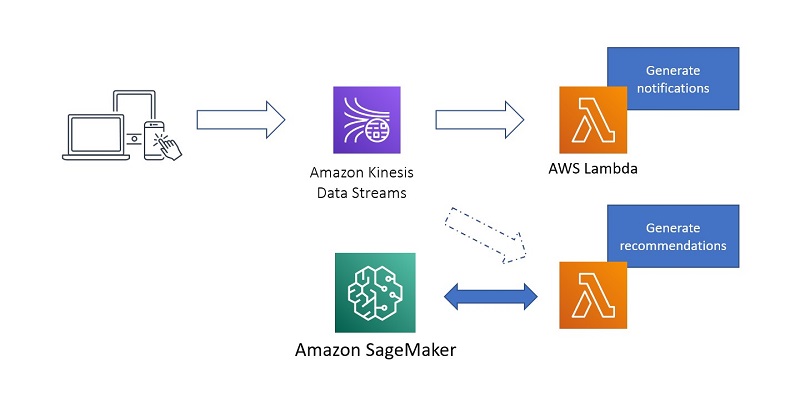
Let’s say you enabled 30 days of retention on your Kinesis data stream. After you train your ML model, you can set up a new streaming pipeline that generates recommendations by calling an inference endpoint hosted on Amazon SageMaker based on the trained ML model. The following diagram illustrates the final state of this architecture.
You can efficiently and quickly consume the existing data in the stream and write it to Amazon S3 so it can be used for training your ML model. The following diagram illustrates the architecture of this intermediate pipeline to generate training data.
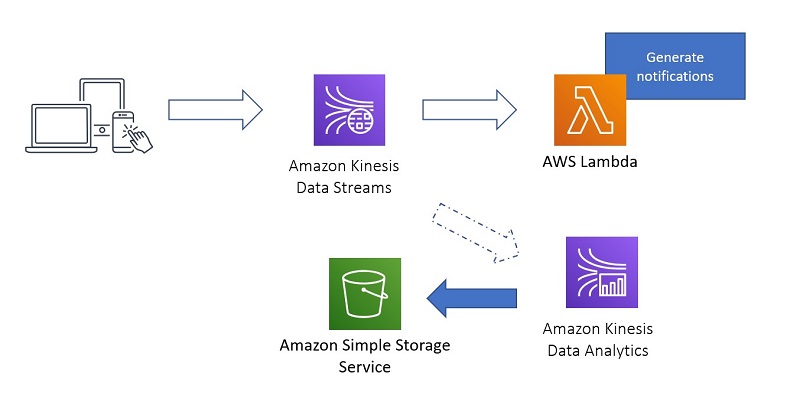
You may wonder, why read from Kinesis Data Streams and write to Amazon S3? Why not write to Amazon S3 directly without enabling long-term retention? First, ingesting into Kinesis Data Streams with long-term retention enabled gives you the flexibility to generate additional streaming analytics as time passes. Second, this gives you the flexibility to filter and transform the data being read from Kinesis Data Streams before generating analytics or writing to Amazon S3. Lastly, you can use this approach to render analytics onto other systems besides Amazon S3, such as Amazon Elasticsearch Service (Amazon ES) using the Elasticsearch sink for Apache Flink.
Keep in mind that we only use this pipeline to bootstrap our second, long-lived pipeline that does recommendations, but this is an important step and we need a way to do this efficiently. Although there are multiple options for consuming data from Kinesis Data Streams, Amazon Kinesis Data Analytics for Apache Flink provides an elegant way to attach multiple EFO consumers in the same consuming application.
You can find more information at the official Apache Flink website, and about Kinesis Data Analytics for Apache Flink in the Kinesis Data Analytics developer guide. Apache Flink has a number of connectors, like the recently released FlinkKinesisConsumer, which supports enhanced fan-out for consuming from Kinesis Data Streams, or the Streaming File Sink to write to Amazon S3 from your Apache Flink application.
Accelerating data consumption
For the sake of simplicity, let’s use just one shard in our data stream, ingest data at the maximum rate of 1MB/s, and specify a retention period of 30 days. To bootstrap our new analytics, reading the full amount of data over 30 days with one EFO consumer at 2MB/s could potentially take up to 15 days to load this data into Amazon S3. However, you can accelerate this to 20 times faster using 20 EFO consumers at the same time, each reading from different points in the stream at 2 MB/s. The following diagram illustrates the architecture of multiple EFO consumers reading from multiple time slices.
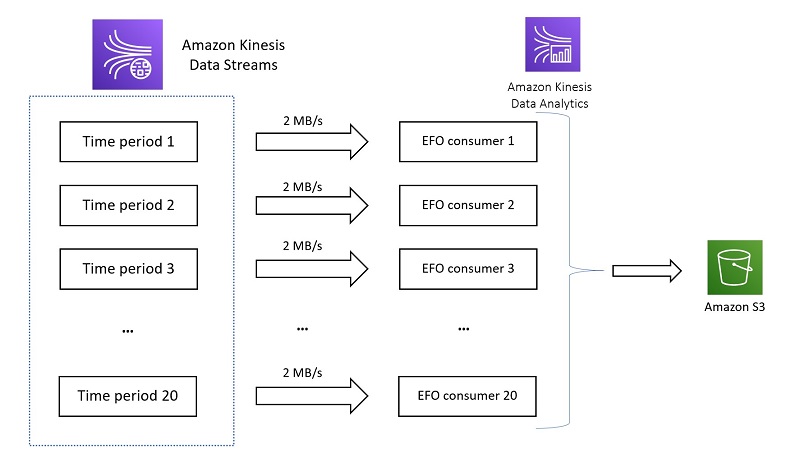
This gives us a total of 40MB/s in consumption capacity as opposed to 2MB/s per shard with just one EFO consumer, reducing the overall time by 95%. In most use cases, this combination of Kinesis Data Analytics and EFO allows you to process 30 days of data in hours, instead of days.
A point of clarification regarding our approach: When all 20 consumers are finished reading past their respective endpoints in the stream, we stop the Apache Flink application. You can do this by raising an exception when all 20 consumers finish reading their respective time slices—effectively stopping the application. The following diagram illustrates the time savings we get from using 20 EFO consumers.

For more information about implementing this approach, see the GitHub repo.
Pricing
An additional cost is associated with long-term retention (from 7–365 days) and EFO consumers. For more information, see Amazon Kinesis Data Streams pricing. Because you can register EFO consumers on demand, you pay only for the limited time you used all 20 consumers to load data, resulting in faster loads. It’s important to point out that you pay roughly the same amount to consume a fixed volume of data from the stream with 20 EFO consumers as you do with 1 EFO consumer because of the shorter duration required when using 20 consumers.
Summary
In this post, we discussed long-term retention use cases of Kinesis Data Streams, how to increase the retention of a data stream, and related feature enhancements with Kinesis Data Streams APIs and KCL. We took a deep dive into the Apache Flink-based enhanced-fan out consumer approach to replay long-term data quickly. We shared open-source code based on this approach so you can easily implement your use cases using Kinesis Data Streams long-term retention.
You should use long-term retention if you’re planning to develop ML systems, generate customer behavior insights, or have compliance requirements for retaining raw data for more than 7 days. We would love to hear about your use cases with the long-term retention feature. Please submit your feedback to [email protected].
About the Authors
 Nihar Sheth is a Senior Product Manager on the Amazon Kinesis Data Streams team at Amazon Web Services. He is passionate about developing intuitive product experiences that solve complex customer problems and enables customers to achieve their business goals. Outside of work, he is focusing on hiking 200 miles of beautiful PNW trails with his son in 2021.
Nihar Sheth is a Senior Product Manager on the Amazon Kinesis Data Streams team at Amazon Web Services. He is passionate about developing intuitive product experiences that solve complex customer problems and enables customers to achieve their business goals. Outside of work, he is focusing on hiking 200 miles of beautiful PNW trails with his son in 2021.
 Karthi Thyagarajan is a Solutions Architect on the Amazon Kinesis Team focusing on all things streaming and he enjoys helping customers tackle distributed systems challenges.
Karthi Thyagarajan is a Solutions Architect on the Amazon Kinesis Team focusing on all things streaming and he enjoys helping customers tackle distributed systems challenges.
 Sai Maddali is a Sr. Product Manager – Tech at Amazon Web Services where he works on Amazon Kinesis Data Streams . He is passionate about understanding customer needs, and using technology to deliver services that empowers customers to build innovative applications. Besides work, he enjoys traveling, cooking, and running.
Sai Maddali is a Sr. Product Manager – Tech at Amazon Web Services where he works on Amazon Kinesis Data Streams . He is passionate about understanding customer needs, and using technology to deliver services that empowers customers to build innovative applications. Besides work, he enjoys traveling, cooking, and running.
 Larry Heathcote is a Senior Product Marketing Manager at Amazon Web Services for data streaming and analytics. Larry is passionate about seeing the results of data-driven insights on business outcomes. He enjoys walking his Samoyed Sasha in the mornings so she can look for squirrels to bark at.
Larry Heathcote is a Senior Product Marketing Manager at Amazon Web Services for data streaming and analytics. Larry is passionate about seeing the results of data-driven insights on business outcomes. He enjoys walking his Samoyed Sasha in the mornings so she can look for squirrels to bark at.