Post Syndicated from Aviv Yehezkel original https://aws.amazon.com/blogs/big-data/how-cynamics-built-a-high-scale-near-real-time-streaming-ai-inference-system-using-aws/
This post is co-authored by Dr. Yehezkel Aviv, Co-Founder and CTO of Cynamics and Sapir Kraus, Head of Engineering at Cynamics.
Cynamics provides a new paradigm of cybersecurity — predicting attacks long before they hit by collecting small network samples (less than 1%), inferring from them how the full network (100%) behaves, and predicting threats using unique AI breakthroughs. The sample approach allows Cynamics to be generic, agnostic, and work for any client’s network architecture, no matter how messy the mix between legacy, private, and public clouds. Furthermore, the solution is scalable and provides full cover to the client’s network, no matter how large it is in volume and size. Moreover, because any network gateway (physical or virtual, legacy or cloud) supports one of the standard sampling protocols and APIs, Cynamics doesn’t require any installation of appliances nor agents, as well as no network changes and modifications, and the onboarding usually takes less than an hour.
In the crowded cybersecurity market, Cynamics is the first-ever solution based on small network samples, which has been considered a hard and unsolved challenge in academia (our academic paper “Network anomaly detection using transfer learning based on auto-encoders loss normalization” was recently presented in ACM CCS AISec 2021) and industry to this day.
The problem Cynamics faced
Early in the process, with the growth of our customer base, we were required to seamlessly support the increased scale and network throughput by our unique AI algorithms. We faced a few different challenges:
- How can we perform near-real-time analysis on our streaming clients’ incoming data into our AI inference system to predict threats and attacks?
- How can we seamlessly auto scale our solution to be cost-efficient with no impact on the platform ingestion rate?
- Because many of our customers are from the public sector, how can we do this while supporting both AWS commercial and government environments (GovCloud)?
This post shows how we used AWS managed services and in particular Amazon Kinesis Data Streams and Amazon EMR to build a near-real-time streaming AI inference system serving hundreds of production customers in both AWS commercial and government environments, while seamlessly auto scaling.
Overview of solution
The following diagram illustrates our solution architecture:

To provide a cost-efficient, highly available solution that scales easily with user growth, while having no impact on near-real-time performance, we turned to Amazon EMR.
We currently process over 50 million records per day, which translates to just over 5 billion flows, and keeps growing on a daily basis. Using Amazon EMR along with Kinesis Data Streams provided the scalability we needed to achieve inference times of just a few seconds.
Although this technology was new to us, we minimized our learning curve by turning to the available guides from AWS for best practices on scale, partitioning, and resource management.
Workflow
Our workflow contains the following steps:
- Flow samples are sent by the client’s network devices directly to the Cynamics cloud. A network flow (or connection) is a set of packets with the same five-tuple ID:
source-IP-address,destination-IP-address,source-port,destination-port, andprotocol. - The samples are analyzed by Network Load Balancers, which forward them into an auto scaling group of stateless flow transformers running on Graviton-powered Amazon Elastic Compute Cloud (Amazon EC2) instances. With Graviton-based processors in the flow transformers, we reduced our operational costs by over 30%.
- The flows are transformed to the Cynamics data format and enriched with additional information from Cynamics’ databases and in-house sources such as IP resolutions, intelligence, and reputation.
The following figures show the network scale for a single flow transformer machine over a week. The first figure illustrates incoming network packets for a single flow transformer machine.
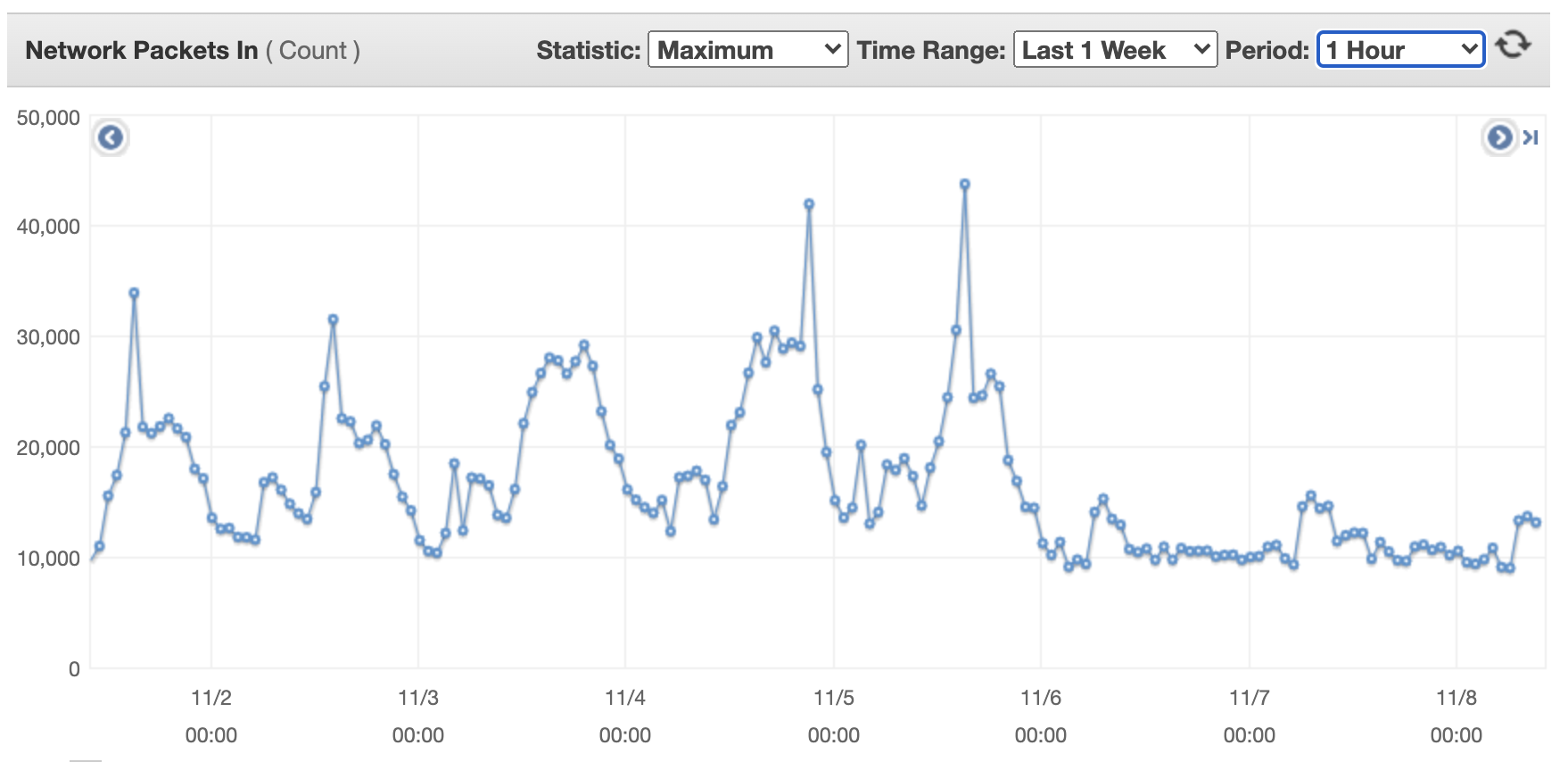
The following shows outcoming network packets for a single flow transformer machine.
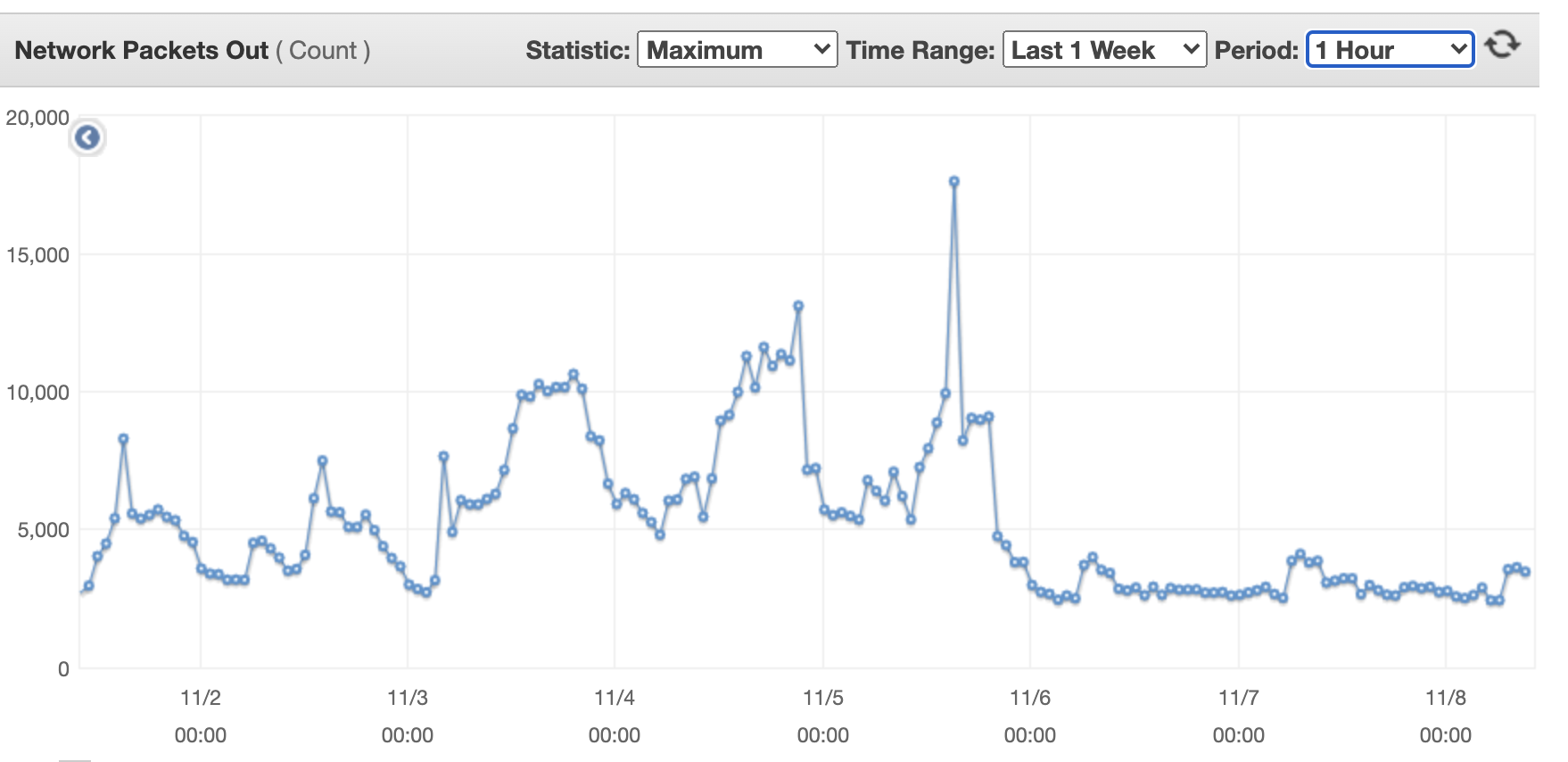
The following shows incoming network bytes for a single flow transformer machine.
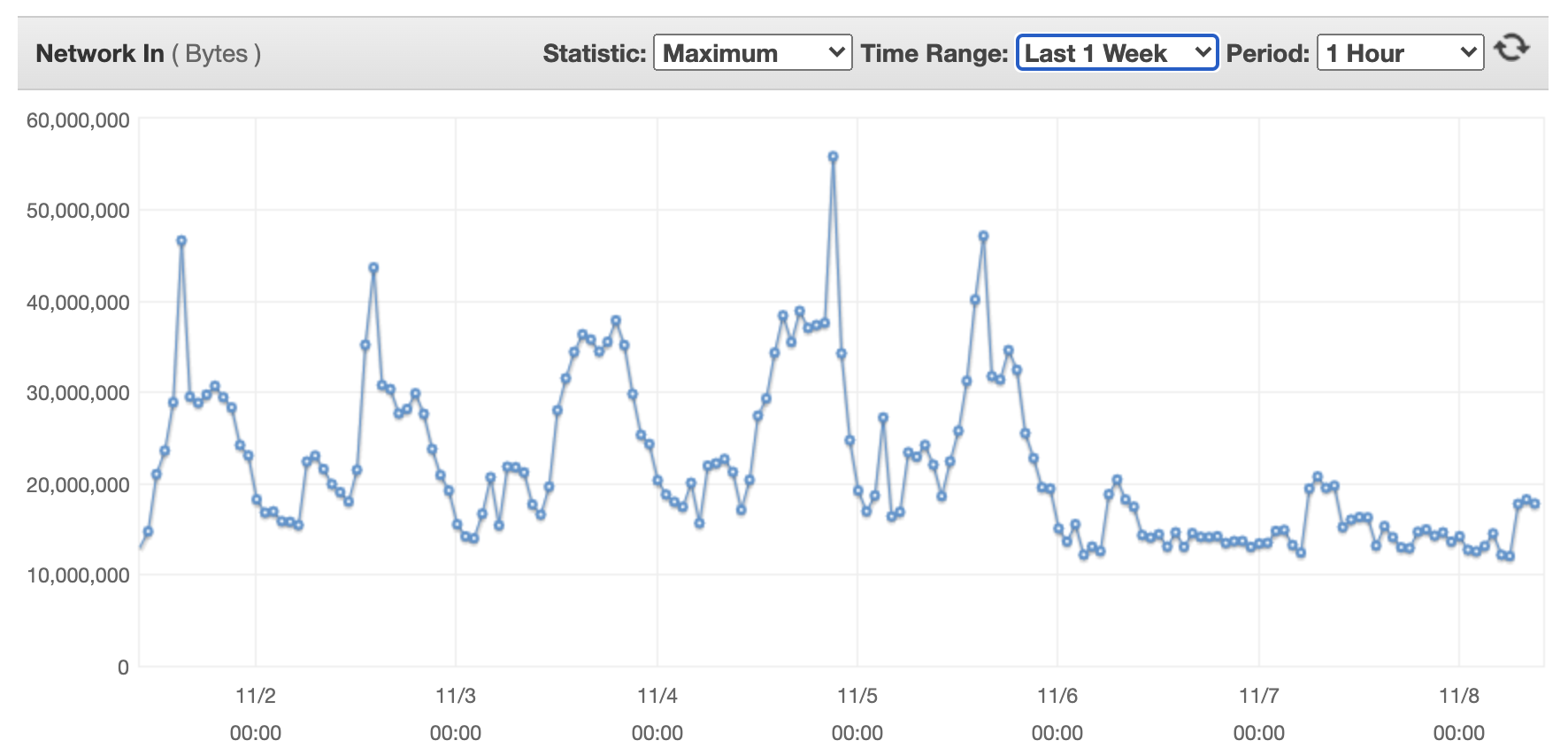
The following shows outcoming network bytes for a single flow transformer machine.
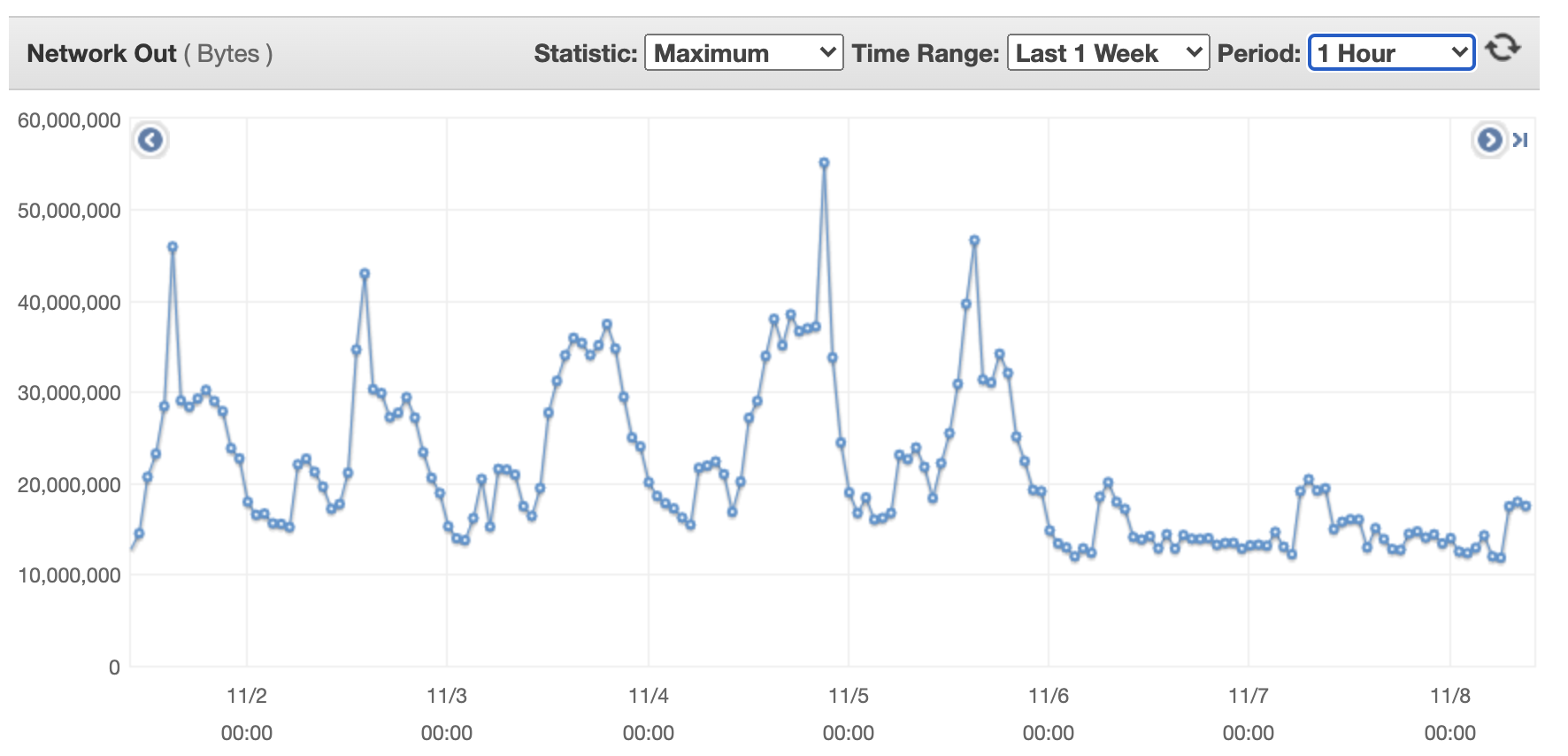
- The flows are sent using Kinesis Data Streams to the real-time analysis engine.
- The Amazon EMR-based real-time engine consumes records in a few seconds batches using Yarn/Spark. The sampling rate of each client is dynamically tuned according to its throughput to ensure a fixed incoming data rate for all clients. We achieved this using Amazon EMR Managed Scaling with a custom policy (available with Amazon EMR versions 5.30.1 and later), which allows us to scale EMR nodes in or out based on Amazon CloudWatch metrics, with two different rules for scale-out and scale-in. The metric we created is based on the Amazon EMR running time, because our real-time AI threat detection runs on a sliding window interval of a few seconds.
- The scale-out policy tracks the average running time over a period of 10 minutes, and scales the EMR nodes if it’s longer than 95% of the required interval. This allows us to prevent processing delays.
- Similarly, the scale-in policy uses the same metric but measures the average over a 30-minute period, and scales the cluster accordingly. This enables us to optimize cluster costs and reduce the number of EMR nodes in off-hours.
- To optimize and seamlessly scale our AI inference calls, these were made available through an ALB and another auto scaling group of servers (AI model-service).
- We use Amazon DynamoDB as a fast and highly available states table.
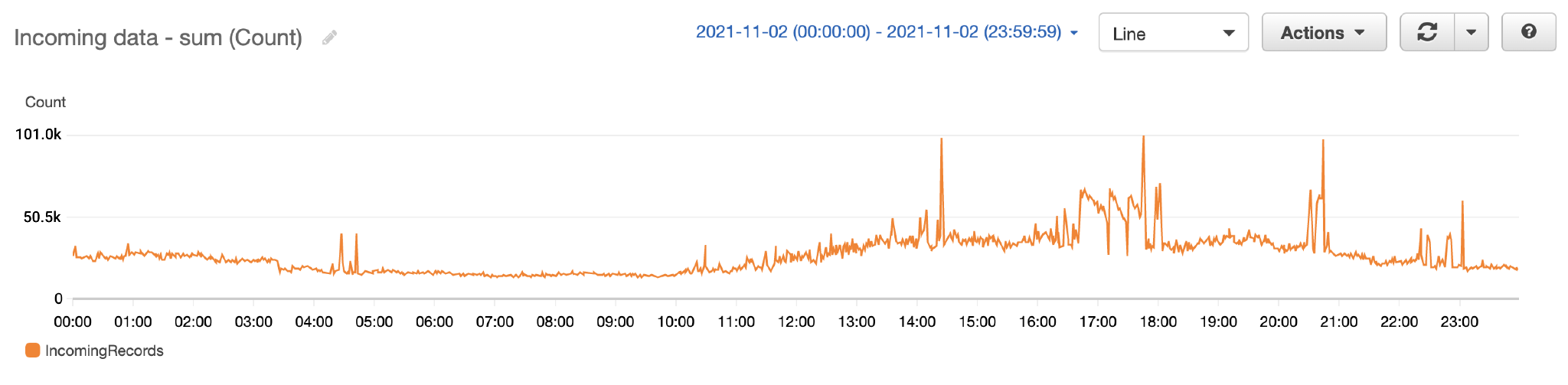
The following figure shows the number of records processed by the Kinesis data stream over a single day.

The following shows the Kinesis data streams records rate per minute.
AI predictions and threat detections are sent to continued processing and alerting, and are saved in Amazon DocumentDB (with MongoDB compatibility).
Conclusion
With the approach described in this post, Cynamics has been providing threat prediction based on near-real-time analysis of its unique AI algorithms for a constantly growing customer base in a seamless and automatically scalable way. Since first implementing the solution, we’ve managed to easily and linearly scale our architecture, and were able to further optimize our costs by transitioning to Graviton-based processors in the flow transformers, which reduced over 30% of our flow transformers costs.
We’re considering the following next steps:
- An automatic machine learning lifecycle using an Amazon SageMaker Studio pipeline, which includes the following steps:
- Shipping the pre-trained AI model.
- Inferring using Amazon SageMaker endpoints instead of the existing AI model service
- Monitoring the entire flow in Amazon SageMaker Debugger.
- Additional cost reduction by moving the EMR instances to be Graviton-based as well, which should yield an additional 20% reduction.
About the Authors
 Dr. Yehezkel Aviv is the co-founder and CTO of Cynamics, leading the company innovation and technology. Aviv holds a PhD in Computer Science from the Technion, specializing in cybersecurity, AI, and ML.
Dr. Yehezkel Aviv is the co-founder and CTO of Cynamics, leading the company innovation and technology. Aviv holds a PhD in Computer Science from the Technion, specializing in cybersecurity, AI, and ML.
 Sapir Kraus is Head of Engineering at Cynamics, where his core focus is managing the software development lifecycle. His responsibilities also include software architecture and providing technical guidance to team members. Outside of work, he enjoys roasting coffee and barbecuing.
Sapir Kraus is Head of Engineering at Cynamics, where his core focus is managing the software development lifecycle. His responsibilities also include software architecture and providing technical guidance to team members. Outside of work, he enjoys roasting coffee and barbecuing.
 Omer Haim is a Startup Solutions Architect at Amazon Web Services. He helps startups with their cloud journey, and is passionate about containers and ML. In his spare time, Omer likes to travel, and occasionally game with his son.
Omer Haim is a Startup Solutions Architect at Amazon Web Services. He helps startups with their cloud journey, and is passionate about containers and ML. In his spare time, Omer likes to travel, and occasionally game with his son.