Post Syndicated from Ankit Jhalaria original https://aws.amazon.com/blogs/big-data/how-godaddy-built-a-data-mesh-to-decentralize-data-ownership-using-aws-lake-formation/
This is a guest post co-written with Ankit Jhalaria from GoDaddy.
GoDaddy is empowering everyday entrepreneurs by providing all the help and tools to succeed online. With more than 20 million customers worldwide, GoDaddy is the place people come to name their idea, build a professional website, attract customers, and manage their work.
GoDaddy is a data-driven company, and getting meaningful insights from data helps them drive business decisions to delight their customers. In 2018, GoDaddy began a large infrastructure revamp and partnered with AWS to innovate faster than ever before to meet the needs of its customer growth around the world. As part of this revamp, the GoDaddy Data Platform team wanted to set the company up for long-term success by creating a well-defined data strategy and setting goals to decentralize the ownership and processing of data.
In this post, we discuss how GoDaddy uses AWS Lake Formation to simplify security management and data governance at scale, and enable data as a service (DaaS) supporting organization-wide data accessibility with cross-account data sharing using a data mesh architecture.
The challenge
In the vast ocean of data, deriving useful insights is an art. Prior to the AWS partnership, GoDaddy had a shared Hadoop cluster on premises that various teams used to create and share datasets with other analysts for collaboration. As the teams grew, copies of data started to grow in the Hadoop Distributed File System (HDFS). Several teams started to build tooling to manage this challenge independently, duplicating efforts. Managing permissions on these data assets became harder. Making data discoverable across a growing number of data catalogs and systems is something that had started to become a big challenge. Although the cost of storage these days is relatively inexpensive, when there are several copies of the same data asset available, it makes it harder for analysts to efficiently and reliably use the data available to them. Business analysts need robust pipelines on key datasets that they rely upon to make business decisions.
Solution overview
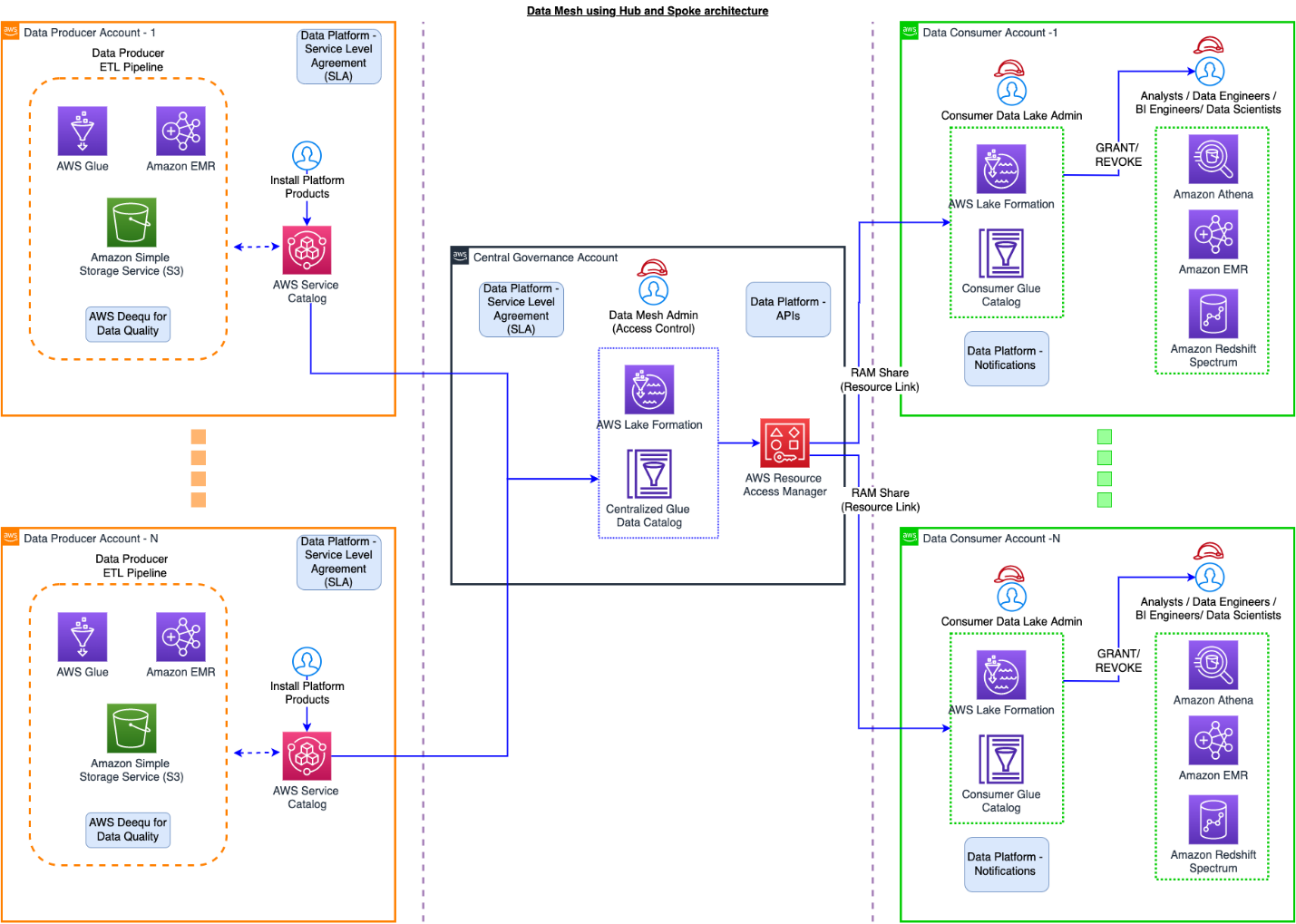
In GoDaddy’s data mesh hub and spoke model, a central data catalog contains information about all the data products that exist in the company. In AWS terminology, this is the AWS Glue Data Catalog. The data platform team provides APIs, SDKs, and Airflow Operators as components that different teams use to interact with the catalog. Activities such as updating the metastore to reflect a new partition for a given data product, and occasionally running MSCK repair operations, are all handled in the central governance account, and Lake Formation is used to secure access to the Data Catalog.
The data platform team introduced a layer of data governance that ensures best practices for building data products are followed throughout the company. We provide the tooling to support data engineers and business analysts while leaving the domain experts to run their data pipelines. With this approach, we have well-curated data products that are intuitive and easy to understand for our business analysts.
A data product refers to an entity that powers insights for analytical purposes. In simple terms, this could refer to an actual dataset pointing to a location in Amazon Simple Storage Service (Amazon S3). Data producers are responsible for the processing of data and creating new snapshots or partitions depending on the business needs. In some cases, data is refreshed every 24 hours, and other cases, every hour. Data consumers come to the data mesh to consume data, and permissions are managed in the central governance account through Lake Formation. Lake Formation uses AWS Resource Access Manager (AWS RAM) to send resource shares to different consumer accounts to be able to access the data from the central governance account. We go into details about this functionality later in the post.
The following diagram illustrates the solution architecture.
Defining metadata with the central schema repository
Data is only useful if end-users can derive meaningful insights from it—otherwise, it’s just noise. As part of onboarding with the data platform, a data producer registers their schema with the data platform along with relevant metadata. This is reviewed by the data governance team that ensures best practices for creating datasets are followed. We have automated some of the most common data governance review items. This is also the place where producers define a contract about reliable data deliveries, often referred to as Service Level Objective (SLO). After a contract is in place, the data platform team’s background processes monitor and send out alerts when data producers fail to meet their contract or SLO.
When managing permissions with Lake Formation, you register the Amazon S3 location of different S3 buckets. Lake Formation uses AWS RAM to share the named resource.
When managing resources with AWS RAM, the central governance account creates AWS RAM shares. The data platform provides a custom AWS Service Catalog product to accept AWS RAM shares in consumer accounts.
Having consistent schemas with meaningful names and descriptions makes the discovery of datasets easy. Every data producer who is a domain expert is responsible for creating well-defined schemas that business users use to generate insights to make key business decisions. Data producers register their schemas along with additional metadata with the data lake repository. Metadata includes information about the team responsible for the dataset, such as their SLO contract, description, and contact information. This information gets checked into a Git repository where automation kicks in and validates the request to make sure it conforms to standards and best practices. We use AWS CloudFormation templates to provision resources. The following code is a sample of what the registration metadata looks like.
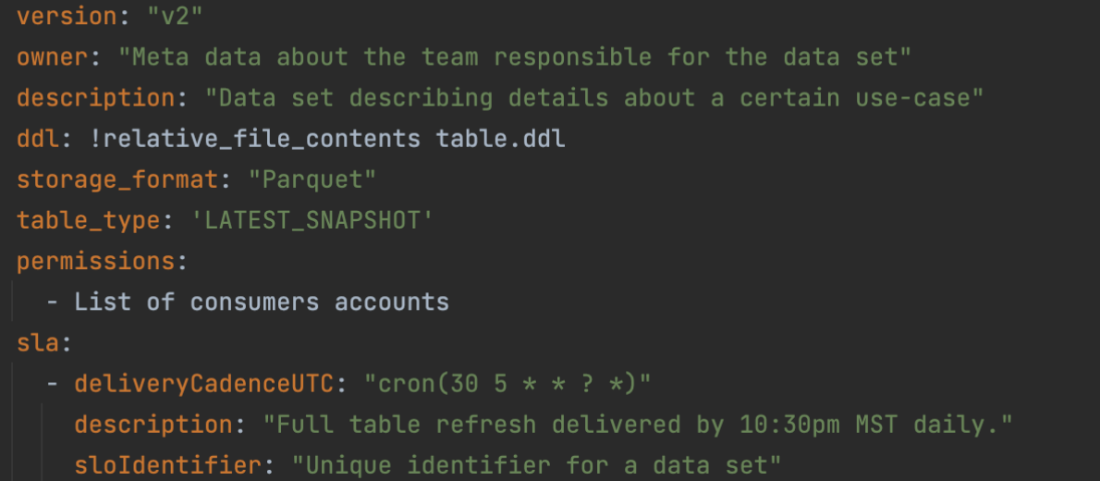
As part of the registration process, automation steps run in the background to take care of the following on behalf of the data producer:
- Register the producer’s Amazon S3 location of the data with Lake Formation – This allows us to use Lake Formation for fine-grained access to control the table in the AWS Glue Data Catalog that refers to this location as well as to the underlying data.
- Create the underlying AWS Glue database and table – Based on the schema specified by the data producer along with the metadata, we create the underlying AWS Glue database and table in the central governance account. As part of this, we also use table properties of AWS Glue to store additional metadata to use later for analysis.
- Define the SLO contract – Any business-critical dataset needs to have a well-defined SLO contract. As part of dataset registration, the data producer defines a contract with a cron expression that gets used by the data platform to create an event rule in Amazon EventBridge. This rule triggers an AWS Lambda function to watch for deliveries of the data and triggers an alert to the data producer’s Slack channel if they breach the contract.
Consuming data from the data mesh catalog
When a data consumer belonging to a given line of business (LOB) identifies the data product that they’re interested in, they submit a request to the central governance team containing their AWS account ID that they use to query the data. The data platform provides a portal to discover datasets across the company. After the request is approved, automation runs to create an AWS RAM share with the consumer account covering the AWS Glue database and tables mapped to the data product registered in the AWS Glue Data Catalog of the central governance account.
The following screenshot shows an example of a resource share.
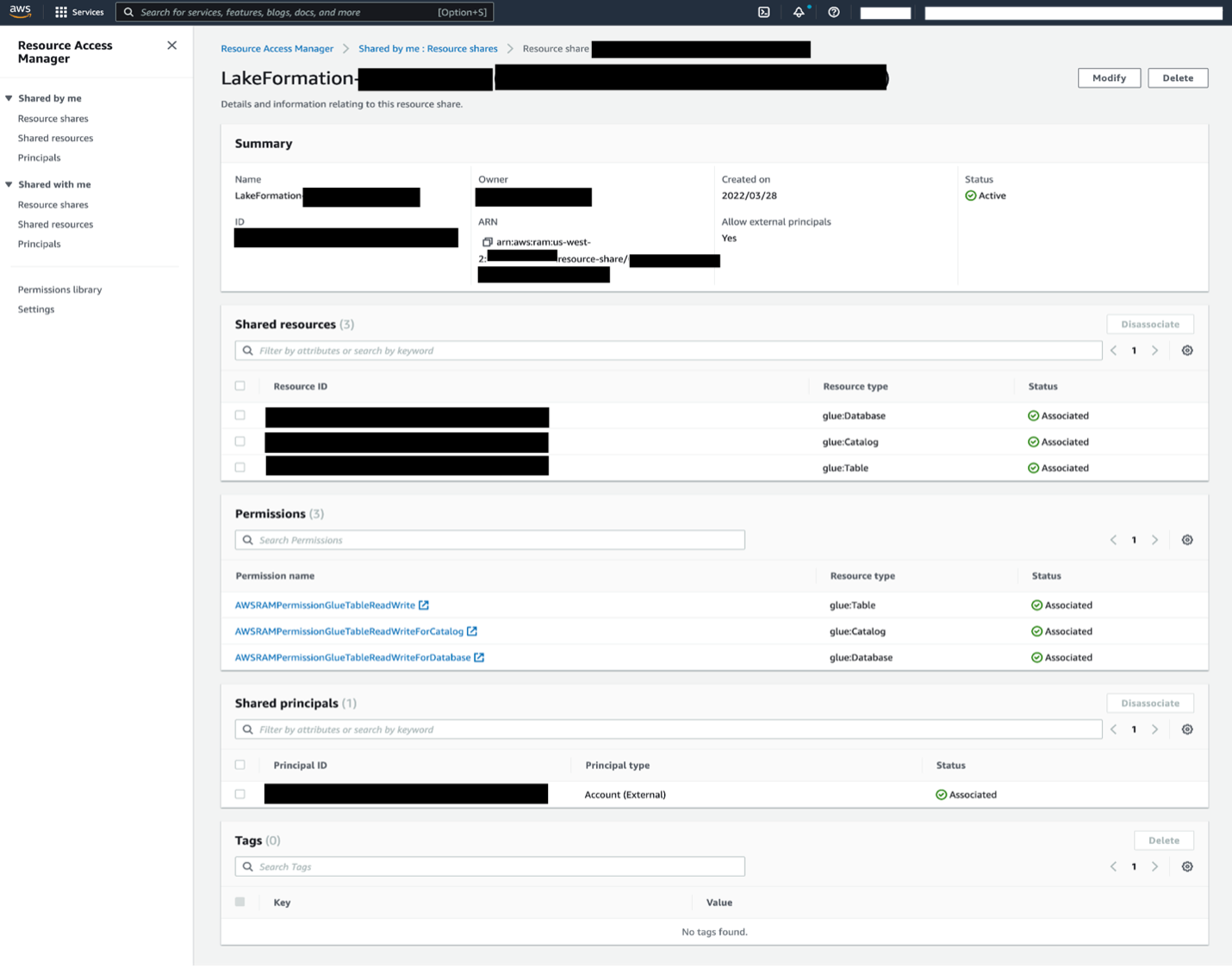
The consumer data lake admin needs to accept the AWS RAM share and create a resource link in Lake Formation to start querying the shared dataset within their account. We automated this process by building an AWS Service Catalog product that runs in the consumer’s account as a Lambda function that accepts shares on behalf of consumers.
When the resource linked datasets are available in the consumer account, the consumer data lake admin provides grants to IAM users and roles mapping to data consumers within the account. These consumers (application or user persona) can now query the datasets using AWS analytics services of their choice like Amazon Athena and Amazon EMR based on the access privileges granted by the consumer data lake admin.
Day-to-day operations and metrics
Managing permissions using Lake Formation is one part of the overall ecosystem. After permissions have been granted, data producers create new snapshots of the data at a certain cadence that can vary from every 15 minutes to a day. Data producers are integrated with the data platform APIs that informs the platform about any new refreshes of the data. The data platform automatically writes a 0-byte _SUCCESS file for every dataset that gets refreshed, and notifies the subscribed consumer account via an Amazon Simple Notification Service (Amazon SNS) topic in the central governance account. Consumers use this as a signal to trigger their data pipelines and processes to start processing newer version of the data utilizing an event-driven approach.
There are over 2,000 data products built on the GoDaddy data mesh on AWS. Every day, there are thousands of updates to the AWS Glue metastore in the central data governance account. There are hundreds of data producers generating data every hour in a wide array of S3 buckets, and thousands of data consumers consuming data across a wide array of tools, including Athena, Amazon EMR, and Tableau from different AWS accounts.
Business outcomes
With the move to AWS, GoDaddy’s Data Platform team laid the foundations to build a modern data platform that has increased our velocity of building data products and delighting our customers. The data platform has successfully transitioned from a monolithic platform to a model where ownership of data has been decentralized. We accelerated the data platform adoption to over 10 lines of business and over 300 teams globally, and are successfully managing multiple petabytes of data spread across hundreds of accounts to help our business derive insights faster.
Conclusion
GoDaddy’s hub and spoke data mesh architecture built using Lake Formation simplifies security management and data governance at scale, to deliver data as a service supporting company-wide data accessibility. Our data mesh manages multiple petabytes of data across hundreds of accounts, enabling decentralized ownership of well-defined datasets with automation in place, which helps the business discover data assets quicker and derive business insights faster.
This post illustrates the use of Lake Formation to build a data mesh architecture that enables a DaaS model for a modernized enterprise data platform. For more information, see Design a data mesh architecture using AWS Lake Formation and AWS Glue.
About the Authors
 Ankit Jhalaria is the Director Of Engineering on the Data Platform at GoDaddy. He has over 10 years of experience working in big data technologies. Outside of work, Ankit loves hiking, playing board games, building IoT projects, and contributing to open-source projects.
Ankit Jhalaria is the Director Of Engineering on the Data Platform at GoDaddy. He has over 10 years of experience working in big data technologies. Outside of work, Ankit loves hiking, playing board games, building IoT projects, and contributing to open-source projects.
 Harsh Vardhan is an AWS Solutions Architect, specializing in Analytics. He has over 6 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.
Harsh Vardhan is an AWS Solutions Architect, specializing in Analytics. He has over 6 years of experience working in the field of big data and data science. He is passionate about helping customers adopt best practices and discover insights from their data.
 Kyle Tedeschi is a Principal Solutions Architect at AWS. He enjoys helping customers innovate, transform, and become leaders in their respective domains. Outside of work, Kyle is an avid snowboarder, car enthusiast, and traveler.
Kyle Tedeschi is a Principal Solutions Architect at AWS. He enjoys helping customers innovate, transform, and become leaders in their respective domains. Outside of work, Kyle is an avid snowboarder, car enthusiast, and traveler.