Post Syndicated from Jonatan Selsing original https://aws.amazon.com/blogs/big-data/how-novo-nordisk-built-a-modern-data-architecture-on-aws/
Novo Nordisk is a leading global pharmaceutical company, responsible for producing life-saving medicines that reach more than 34 million patients each day. They do this following their triple bottom line—that they must strive to be environmentally sustainable, socially sustainable, and financially sustainable. The combination of using AWS and data supports all these targets.
Data is pervasive throughout the entire value chain of Novo Nordisk. From foundational research, manufacturing lines, sales and marketing, clinical trials, pharmacovigilance, through patient-facing data-driven applications. Therefore, getting the foundation around how data is stored, safeguarded, and used in a way that provides the most value is one of the central drivers of improved business outcomes.
Together with AWS Professional Services, we’re building a data and analytics solution using a modern data architecture. The collaboration between Novo Nordisk and AWS Professional Services is a strategic and long-term close engagement, where developers from both organizations have worked together closely for years. The data and analytics environments are built around of the core tenets of the data mesh—decentralized domain ownership of data, data as a product, self-service data infrastructure, and federated computational governance. This enables the users of the environment to work with data in the way that drives the best business outcomes. We have combined this with elements from evolutionary architectures that will allow us to adapt different functionalities as AWS continuously develops new services and capabilities.
In this series of posts, you will learn how Novo Nordisk and AWS Professional Services built a data and analytics ecosystem to speed up innovation at petabyte scale:
- In this first post, you will learn how the overall design has enabled the individual components to come together in a modular way. We dive deep into how we built a data management solution based on the data mesh architecture.
- The second post discusses how we built a trust network between the systems that comprise the entire solution. We show how we use event-driven architectures, coupled with the use of attribute-based access controls, to ensure permission boundaries are respected at scale.
- In the third post, we show how end-users can consume data from their tool of choice, without compromising data governance. This includes how to configure Okta, AWS Lake Formation, and Microsoft Power BI to enable SAML-based federated use of Amazon Athena for an enterprise business intelligence (BI) activity.
Pharma-compliant environment
As a pharmaceutical industry, GxP compliance is a mandate for Novo Nordisk. GxP is a general abbreviation for the “Good x Practice” quality guidelines and regulations defined by regulators such as European Medicines Agency, U.S. Food and Drug Administration, and others. These guidelines are designed to ensure that medicinal products are safe and effective for their intended use. In the context of a data environment, GxP compliance involves implementing integrity controls for data used to in decision making and processes and is used to guide how change management processes are implemented to continuously ensure compliance over time.
Because this data environment supports teams across the whole organization, each individual data owner must retain accountability on their data. Features were designed to provide data owners autonomy and transparency when managing their data, enabling them to take this responsibility. This includes the capability to handle personally identifiable information (PII) data and other sensitive workloads. To provide traceability on the environment, audit capabilities were added, which we describe more in this post.
Solution overview
The full solution is a sprawling landscape of independent services that work together to enable data and analytics with a decentralized data governance model at petabyte scale. Schematically, it can be represented as in the following figure.
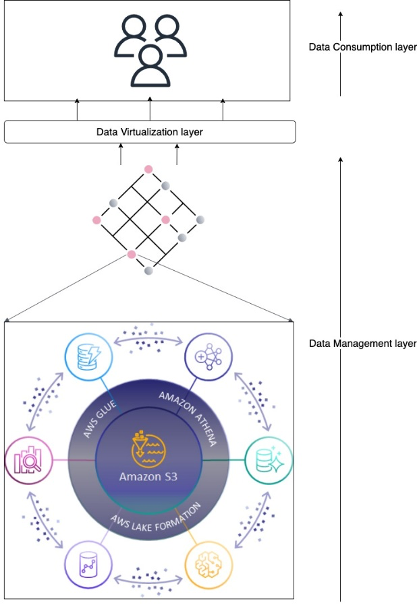
The architecture is split into three independent layers: data management, virtualization, and consumption. The end-user sits in the consumption layer and works with their tool of choice. It’s meant to abstract as much of the AWS-native resources to application primitives. The consumption layer is integrated into the virtualization layer, which abstracts the access to data. The purpose of the virtualization layer is to translate between data consumption and data management solutions. The access to data is managed by what we refer to as data management solutions. We discuss one of our versatile data management solutions later in this post. Each layer in this architecture is independent of each other and instead only relies on well-defined interfaces.
Central to this architecture is that access is encapsulated in an AWS Identity and Access Management (IAM) role session. The data management layer focuses on providing the IAM role with the right permissions and governance, the virtualization layer provides access to the role, and the consumption layer abstracts the use of the roles in the tools of choice.
Technical architecture
Each of the three layers in the overall architecture has a distinct responsibility, but no singular implementation. Think of them as abstract classes. They can be implemented in concrete classes, and in our case they rely on foundational AWS services and capabilities. Let’s go through each of the three layers.
Data management layer
The data management layer is responsible for providing access to and governance of data. As illustrated in the following diagram, a minimal construct in the data management layer is the combination of an Amazon Simple Storage Service (Amazon S3) bucket and an IAM role that gives access to the S3 bucket. This construct can be expanded to include granular permission with Lake Formation, auditing with AWS CloudTrail, and security response capabilities from AWS Security Hub. The following diagram also shows that a single data management solution has no singular span. It can cross many AWS accounts and be comprised of any number of IAM role combinations.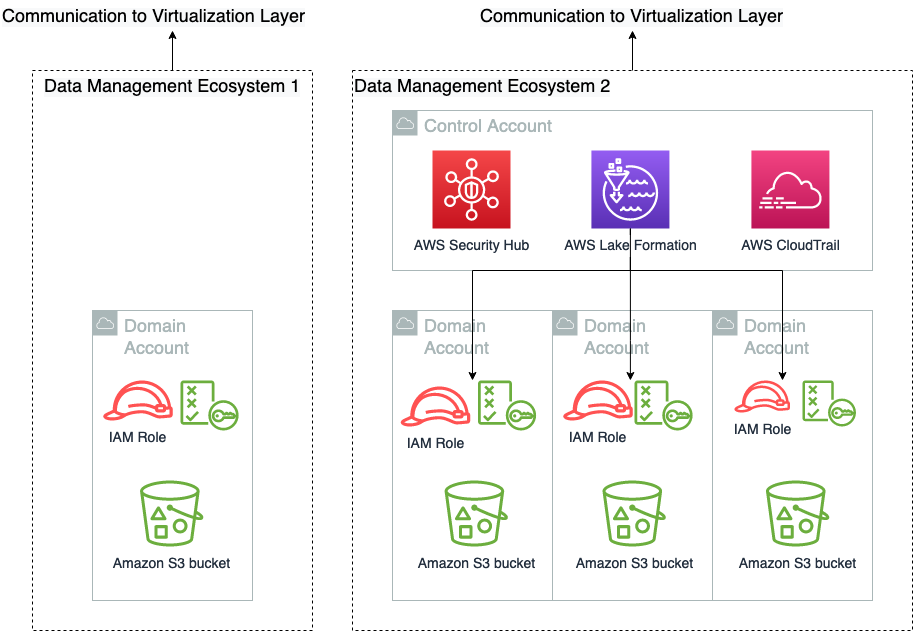
We have purposely not illustrated the trust policy of these roles in this figure, because those are a collaborative responsibility between the virtualization layer and the data management layer. We go into detail of how that works in the next post in this series. Data engineering professionals often interface directly with the data management layer, where they curate and prepare data for consumption.
Virtualization layer
The purpose of the virtualization layer is to keep track of who can do what. It doesn’t have any capabilities in itself, but translates the requirements from the data management ecosystems to the consumption layers and vice versa. It enables end-users on the consumption layer to access and manipulate data on one or more data management ecosystems, according to their permissions. This layer abstracts from end-users the technical details on data access, such as permission model, role assumptions, and storage location. It owns the interfaces to the other layers and enforces the logic of the abstraction. In the context of hexagonal architectures (see Developing evolutionary architecture with AWS Lambda), the interface layer plays the role of the domain logic, ports, and adapters. The other two layers are actors. The data management layer communicates the state of the layer to the virtualization layer and conversely receives information about the service landscape to trust. The virtualization layer architecture is shown in the following diagram.
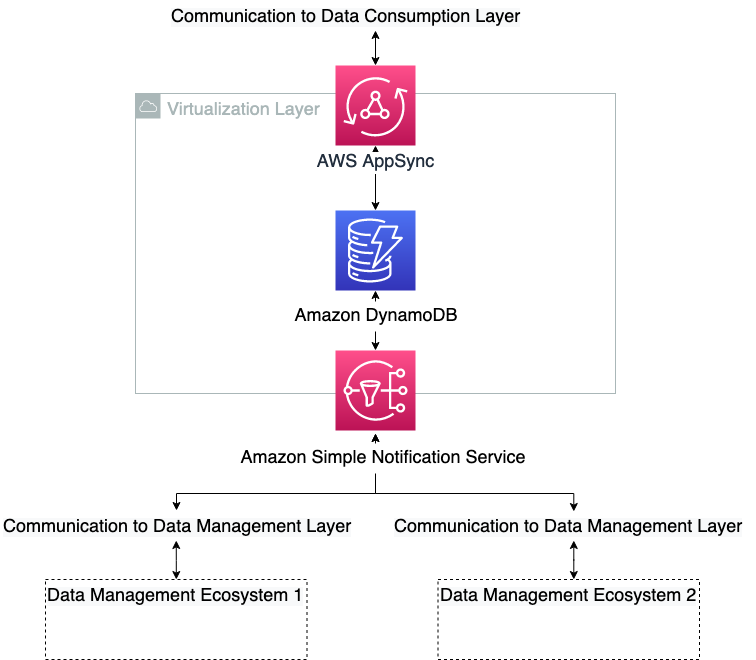
Consumption layer
The consumption layer is where the end-users of the data products are sitting. This can be data scientists, business intelligence analysts, or any third party that generates value from consuming the data. It’s important for this type of architecture that the consumption layer has a hook-based sign-in flow, where the authorization into the application can be modified at sign-in time. This is to translate the AWS-specific requirement into the target applications. After the session in the client-side application has successfully been started, it’s up to the application itself to instrument for data layer abstraction, because this will be application specific. And this is an additional important decoupling, where some responsibility is pushed to the decentralized units. Many modern software as a service (SaaS) applications support these built-in mechanisms, such as Databricks or Domino Data Lab, whereas more traditional client-side applications like RStudio Server have more limited native support for this. In the case where native support is missing, a translation down to the OS user session can be done to enable the abstraction. The consumption layer is shown schematically in the following diagram.
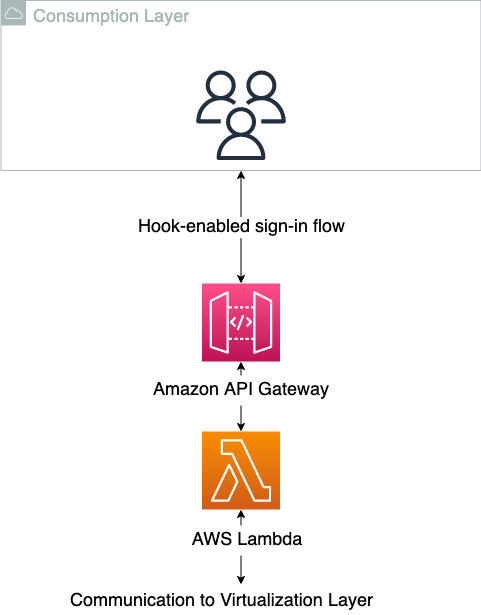
When using the consumption layer as intended, the users don’t know that the virtualization layer exists. The following diagram illustrates the data access patterns.
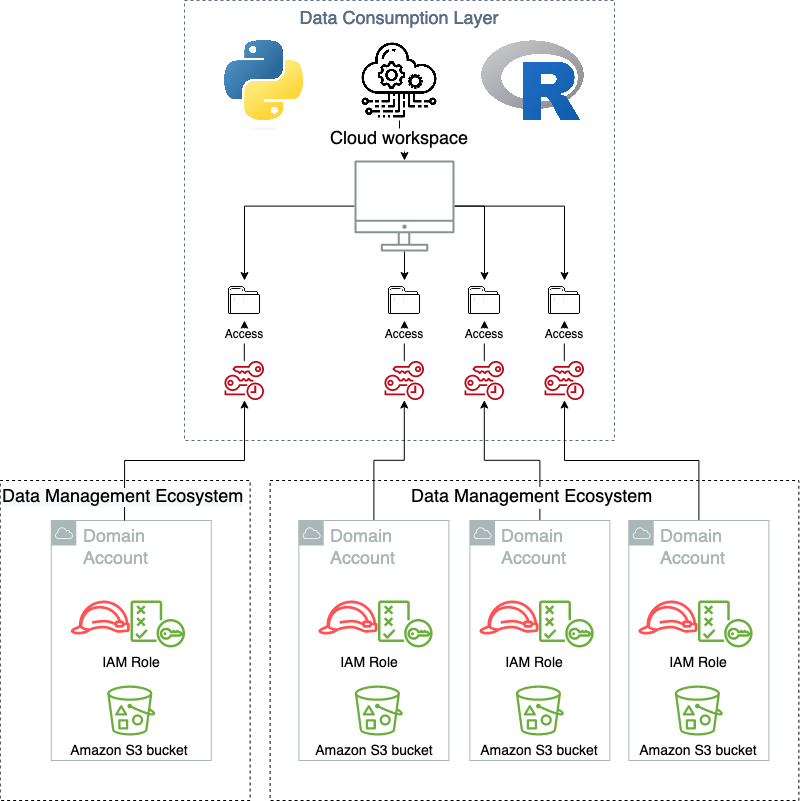
Modularity
One of the main advantages of adopting the hexagonal architecture pattern, and delegating both the consuming layer and the data management layer to primary and secondary actors, means that they can be changed or replaced as new functionalities are released that require new solutions. This gives a hub-and-spoke type pattern, where many different types of producer/consumer type systems can be connected and work simultaneously in union. An example of this is that the current solution running in Novo Nordisk supports multiple, simultaneous data management solutions and are exposed in a homogenous way in the consuming layer. This includes both a data lake, the data mesh solution presented in this post, and several independent data management solutions. And these are exposed to multiple types of consuming applications, from custom managed, self-hosted applications, to SaaS offerings.
Data management ecosystem
To scale the usage of the data and increase the freedom, Novo Nordisk, jointly with AWS Professional Services, built a data management and governance environment, named Novo Nordisk Enterprise DataHub (NNEDH). NNEDH implements a decentralized distributed data architecture, and data management capabilities such as an enterprise business data catalog and data sharing workflow. NNEDH is an example of a data management ecosystem in the conceptual framework introduced earlier.
Decentralized architecture: From a centralized data lake to a distributed architecture
Novo Nordisk’s centralized data lake consists of 2.3 PB of data from more than 30 business data domains worldwide serving over 2000+ internal users throughout the value chain. It has been running successfully for several years. It is one of the data management ecosystems currently supported.
Within the centralized data architecture, data from each data domain is copied, stored, and processed in one central location: a central data lake hosted in one data storage. This pattern has challenges at scale because it retains the data ownership with the central team. At scale, this model slows down the journey toward a data-driven organization, because ownership of the data isn’t sufficiently anchored with the professionals closest to the domain.
The monolithic data lake architecture is shown in the following diagram.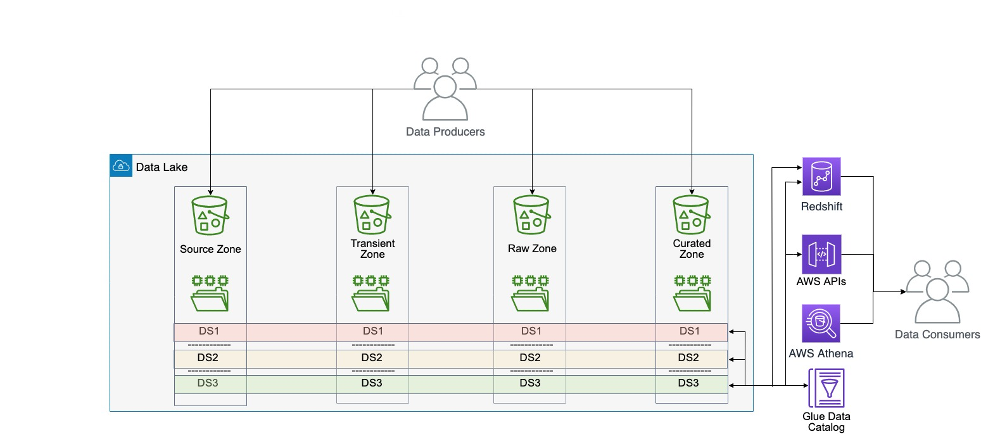
Within the decentralized distributed data architecture, the data from each domain is kept within the domain on its own data storage and compute account. In this case, the data is kept close to domain experts, because they’re the ones who know their own data best and are ultimately the owner of any data products built around their data. They often work closely with business analysts to build the data product and therefore know what good data means to consumers of their data products. In this case, the data responsibility is also decentralized, where each domain has its own data owner, putting the accountability onto the true owners of the data. Nevertheless, this model might not work at small scale, for example an organization with only one business unit and tens of users, because it would introduce more overhead on the IT team to manage the organization data. It better suits large organizations, or small and medium ones that would like to grow and scale.
The Novo Nordisk data mesh architecture is shown in the following diagram.
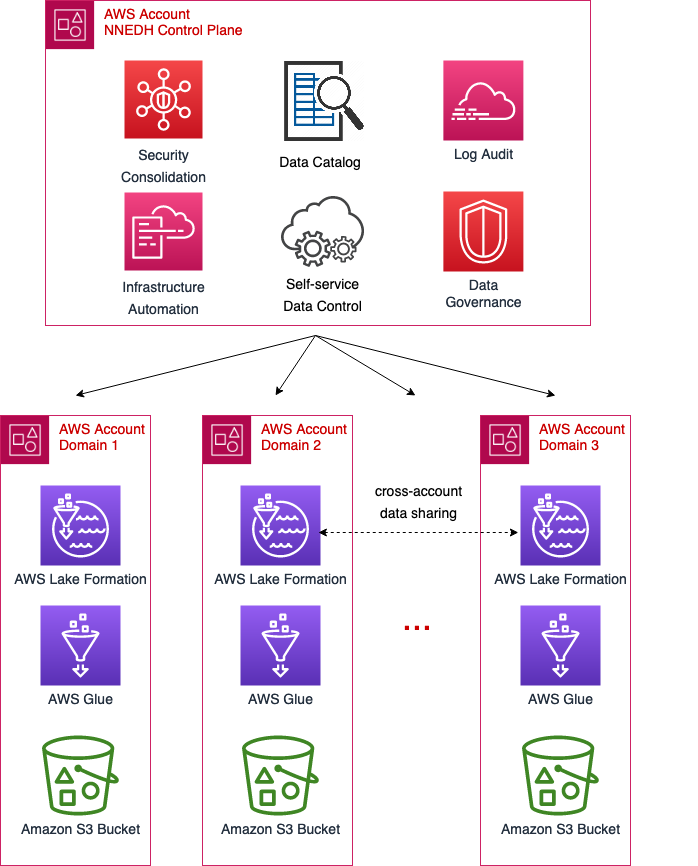
Data domains and data assets
To enable the scalability of data domains across the organization, it’s mandatory to have a standard permission model and data access pattern. This standard must not be too restrictive in such a way that it may be a blocker for specific use cases, but it should be standardized in such a way to use the same interface between the data management and virtualization layers.
The data domains on NNEDH are implemented by a construct called an environment. An environment is composed of at least one AWS account and one AWS Region. It’s a workplace where data domain teams can work and collaborate to build data products. It links the NNEDH control plane to the AWS accounts where the data and compute of the domain reside. The data access permissions are also defined at the environment level, managed by the owner of the data domain. The environments have three main components: a data management and governance layer, data assets, and optional blueprints for data processing.
For data management and governance, the data domains rely on Lake Formation, AWS Glue, and CloudTrail. The deployment method and setup of these components is standardized across data domains. This way, the NNEDH control plane can provide connectivity and management to data domains in a standardized way.
The data assets of each domain residing in an environment are organized in a dataset, which is a collection of related data used for building a data product. It includes technical metadata such as data format, size, and creation time, and business metadata such as the producer, data classification, and business definition. A data product can use one or several datasets. It is implemented through managed S3 buckets and the AWS Glue Data Catalog.
Data processing can be implemented in different ways. NNEDH provides blueprints for data pipelines with predefined connectivity to data assets to speed up the delivery of data products. Data domain users have the freedom to use any other compute capability on their domain, for example using AWS services not predefined on the blueprints or accessing the datasets from other analytics tools implemented in the consumption layer, as mentioned earlier in this post.
Data domain personas and roles
On NNEDH, the permission levels on data domains are managed through predefined personas, for example data owner, data stewards, developers, and readers. Each persona is associated with an IAM role that has a predefined permission level. These permissions are based on the typical needs of users on these roles. Nevertheless, to give more flexibility to data domains, these permissions can be customized and extended as needed.
The permissions associated with each persona are related only to actions allowed on the AWS account of the data domain. For the accountability on data assets, the data access to the assets is managed by specific resource policies instead of IAM roles. Only the owner of each dataset, or data stewards delegated by the owner, can grant or revoke data access.
On the dataset level, a required persona is the data owner. Typically, they work closely with one or many data stewards as data products managers. The data steward is the data subject matter expert of the data product domain, responsible for interpreting collected data and metadata to derive deep business insights and build the product. The data steward bridges between business users and technical teams on each data domain.
Enterprise business data catalog
To enable freedom and make the organization data assets discoverable, a web-based portal data catalog is implemented. It indexes in a single repository metadata from datasets built on data domains, breaking data silos across the organization. The data catalog enables data search and discovery across different domains, as well as automation and governance on data sharing.
The business data catalog implements data governance processes within the organization. It ensures the data ownership—someone in the organization is responsible for the data origin, definition, business attributes, relationships, and dependencies.
The central construct of a business data catalog is a dataset. It’s the search unit within the business catalog, having both technical and business metadata. To collect technical metadata from structured data, it relies on AWS Glue crawlers to recognize and extract data structures from the most popular data formats, including CSV, JSON, Avro, and Apache Parquet. It provides information such as data type, creation date, and format. The metadata can be enriched by business users by adding a description of the business context, tags, and data classification.
The dataset definition and related metadata are stored in an Amazon Aurora Serverless database and Amazon OpenSearch Service, enabling you to run textual queries on the data catalog.
Data sharing
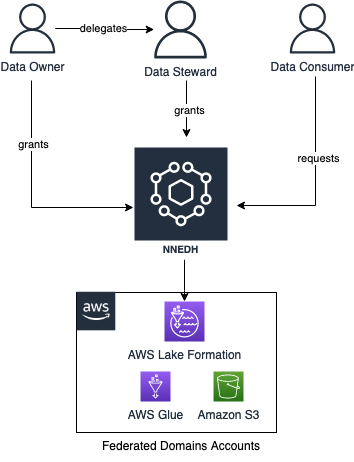
NNEDH implements a data sharing workflow, enabling peer-to-peer data sharing across AWS accounts using Lake Formation. The workflow is as follows:
- A data consumer requests access to the dataset.
- The data owner grants access by approving the access request. They can delegate the approval of access requests to the data steward.
- Upon the approval of an access request, a new permission is added to the specific dataset in Lake Formation of the producer account.
The data sharing workflow is shown schematically in the following figure.
Security and audit
The data in the Novo Nordisk data mesh lies in AWS accounts owned by Novo Nordisk business accounts. The configuration and the states of the data mesh are stored in Amazon Relational Database Service (Amazon RDS). The Novo Nordisk security architecture is shown in the following figure.
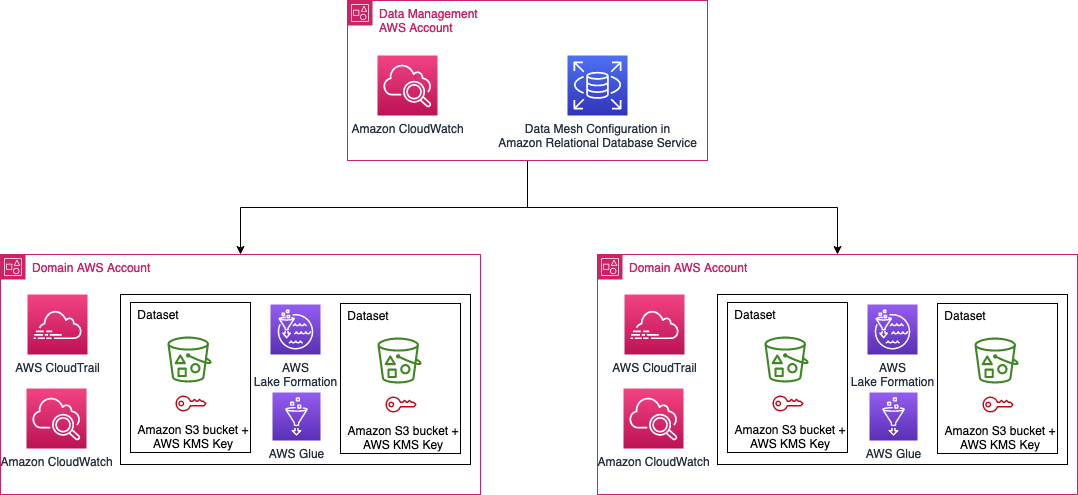
Access and edits to the data in NNEDH needs to be logged for audit purposes. We need to be able to tell who modified data, when the modification happened, and what modifications were applied. In addition, we need to be able to answer why the modification was allowed by that person at that time.
To meet these requirements, we use the following components:
- CloudTrail to log API calls. We specifically enable CloudTrail data event logging for S3 buckets and objects. By activating the logging, we can trace back any modification to any files in the data lake to the person who made the modification. We enforce usage of source identity for IAM role sessions to ensure user traceability.
- We use Amazon RDS to store the configuration of the data mesh. We log queries against the RDS database. Together with CloudTrail, this log allows us to answer the question of why a modification to a file in Amazon S3 at a specific time by a specific person is possible.
- Amazon CloudWatch to log activities across the mesh.
In addition to those logging mechanisms, the S3 buckets are created using the following properties:
- The bucket is encrypted using server-side encryption with AWS Key Management Service (AWS KMS) and customer managed keys
- Amazon S3 versioning is activated by default
Access to the data in NNEDH is controlled at the group level instead of individual users. The group corresponds to the group defined in the Novo Nordisk directory group. To keep track of the person who modified the data in the data lakes, we use the source identity mechanism explained in the post How to relate IAM role activity to corporate identity.
Conclusion
In this post, we showed how Novo Nordisk built a modern data architecture to speed up the delivery of data-driven use cases. It includes a distributed data architecture, to scale the usage to petabyte scale for over 2,000 internal users throughout the value chain, as well as a distributed security and audit architecture handling data accountability and traceability on the environment to meet their compliance requirements.
The next post in this series describes the implementation of distributed data governance and control at scale of Novo Nordisk’s modern data architecture.
About the Authors
 Jonatan Selsing is former research scientist with a PhD in astrophysics that has turned to the cloud. He is currently the Lead Cloud Engineer at Novo Nordisk, where he enables data and analytics workloads at scale. With an emphasis on reducing the total cost of ownership of cloud-based workloads, while giving full benefit of the advantages of cloud, he designs, builds, and maintains solutions that enable research for future medicines.
Jonatan Selsing is former research scientist with a PhD in astrophysics that has turned to the cloud. He is currently the Lead Cloud Engineer at Novo Nordisk, where he enables data and analytics workloads at scale. With an emphasis on reducing the total cost of ownership of cloud-based workloads, while giving full benefit of the advantages of cloud, he designs, builds, and maintains solutions that enable research for future medicines.
 Hassen Riahi is a Sr. Data Architect at AWS Professional Services. He holds a PhD in Mathematics & Computer Science on large-scale data management. He works with AWS customers on building data-driven solutions.
Hassen Riahi is a Sr. Data Architect at AWS Professional Services. He holds a PhD in Mathematics & Computer Science on large-scale data management. He works with AWS customers on building data-driven solutions.
 Anwar Rizal is a Senior Machine Learning consultant based in Paris. He works with AWS customers to develop data and AI solutions to sustainably grow their business.
Anwar Rizal is a Senior Machine Learning consultant based in Paris. He works with AWS customers to develop data and AI solutions to sustainably grow their business.
 Moses Arthur comes from a mathematics and computational research background and holds a PhD in Computational Intelligence specialized in Graph Mining. He is currently a Cloud Product Engineer at Novo Nordisk building GxP-compliant enterprise data lakes and analytics platforms for Novo Nordisk global factories producing digitalized medical products.
Moses Arthur comes from a mathematics and computational research background and holds a PhD in Computational Intelligence specialized in Graph Mining. He is currently a Cloud Product Engineer at Novo Nordisk building GxP-compliant enterprise data lakes and analytics platforms for Novo Nordisk global factories producing digitalized medical products.
 Alessandro Fior is a Sr. Data Architect at AWS Professional Services. With over 10 years of experience delivering data and analytics solutions, he is passionate about designing and building modern and scalable data platforms that accelerate companies to get value from their data.
Alessandro Fior is a Sr. Data Architect at AWS Professional Services. With over 10 years of experience delivering data and analytics solutions, he is passionate about designing and building modern and scalable data platforms that accelerate companies to get value from their data.
 Kumari Ramar is an Agile certified and PMP certified Senior Engagement Manager at AWS Professional Services. She delivers data and AI/ML solutions that speed up cross-system analytics and machine learning models, which enable enterprises to make data-driven decisions and drive new innovations.
Kumari Ramar is an Agile certified and PMP certified Senior Engagement Manager at AWS Professional Services. She delivers data and AI/ML solutions that speed up cross-system analytics and machine learning models, which enable enterprises to make data-driven decisions and drive new innovations.