Post Syndicated from Anubhav Awasthi original https://aws.amazon.com/blogs/big-data/run-apache-spark-structured-streaming-jobs-at-scale-on-amazon-emr-serverless/
As data is generated at an unprecedented rate, streaming solutions have become essential for businesses seeking to harness near real-time insights. Streaming data—from social media feeds, IoT devices, e-commerce transactions, and more—requires robust platforms that can process and analyze data as it arrives, enabling immediate decision-making and actions.
This is where Apache Spark Structured Streaming comes into play. It offers a high-level API that simplifies the complexities of streaming data, allowing developers to write streaming jobs as if they were batch jobs, but with the power to process data in near real time. Spark Structured Streaming integrates seamlessly with various data sources, such as Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Kinesis Data Streams, providing a unified solution that supports complex operations like windowed computations, event-time aggregation, and stateful processing. By using Spark’s fast, in-memory processing capabilities, businesses can run streaming workloads efficiently, scaling up or down as needed, to derive timely insights that drive strategic and critical decisions.
The setup of a computing infrastructure to support such streaming workloads poses its challenges. Here, Amazon EMR Serverless emerges as a pivotal solution for running streaming workloads, enabling the use of the latest open source frameworks like Spark without the need for configuration, optimization, security, or cluster management.
Starting with Amazon EMR 7.1, we introduced a new job --mode on EMR Serverless called Streaming. You can submit a streaming job from the EMR Studio console or the StartJobRun API:
In this post, we highlight some of the key enhancements introduced for streaming jobs.
Performance
The Amazon EMR runtime for Apache Spark delivers a high-performance runtime environment while maintaining 100% API compatibility with open source Spark. Additionally, we have introduced the following enhancements to provide improved support for streaming jobs.
Amazon Kinesis connector with Enhanced Fan-Out Support
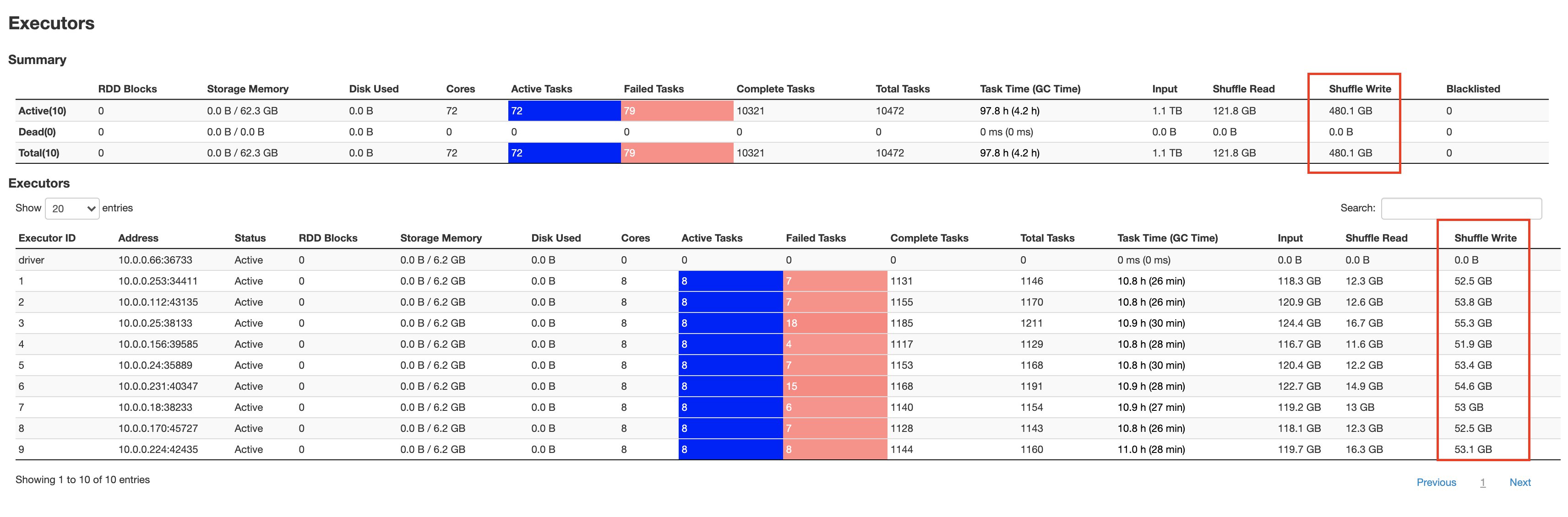
Traditional Spark streaming applications reading from Kinesis Data Streams often face throughput limitations due to shared shard-level read capacity, where multiple consumers compete for the default 2 MBps per shard throughput. This bottleneck becomes particularly challenging in scenarios requiring real-time processing across multiple consuming applications.
To address this challenge, we released the open source Amazon Kinesis Data Streams Connector for Spark Structured Streaming that supports enhanced fan-out for dedicated read throughput. Compatible with both provisioned and on-demand Kinesis Data Streams, enhanced fan-out provides each consumer with dedicated throughput of 2 MBps per shard. This enables streaming jobs to process data concurrently without the constraints of shared throughput, significantly reducing latency and facilitating near real-time processing of large data streams. By eliminating competition between consumers and enhancing parallelism, enhanced fan-out provides faster, more efficient data processing, which boosts the overall performance of streaming jobs on EMR Serverless. Starting with Amazon EMR 7.1, the connector comes pre-packaged on EMR Serverless, so you don’t need to build or download any packages.
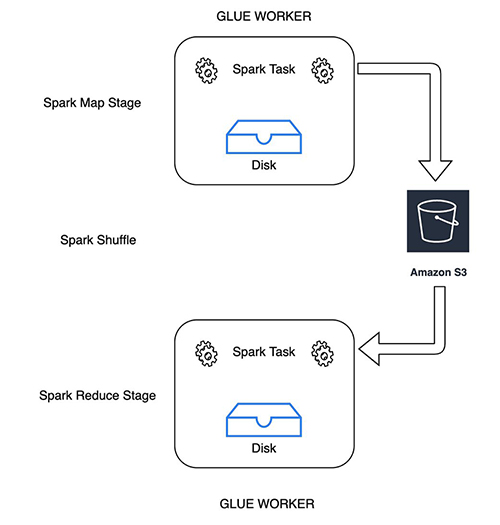
The following diagram illustrates the architecture using shared throughput.

The following diagram illustrates the architecture using enhanced fan-out and dedicated throughput.

Refer to Build Spark Structured Streaming applications with the open source connector for Amazon Kinesis Data Streams for additional details on this connector.
Cost optimization
EMR Serverless charges are based on the total vCPU, memory, and storage resources utilized during the time workers are active, from when they are ready to execute tasks until they stop. To optimize costs, it is crucial to scale streaming jobs effectively. We have introduced the following enhancements to improve scaling at both the task level and across multiple tasks.
Fine-Grained Scaling
In practical scenarios, data volumes can be unpredictable and exhibit sudden spikes, necessitating a platform capable of dynamically adjusting to workload changes. EMR Serverless eliminates the risks of over- or under-provisioning resources for your streaming workloads. EMR Serverless scaling uses Spark dynamic allocation to correctly scale the executors according to demand. The scalability of a streaming job is also influenced by its data source to make sure Kinesis shards or Kafka partitions are also scaled accordingly. Each Kinesis shard and Kafka partition corresponds to a single Spark executor core. To achieve optimal throughput, use a one-to-one ratio of Spark executor cores to Kinesis shards or Kafka partitions.
Streaming operates through a sequence of micro-batch processes. In cases of short-running tasks, overly aggressive scaling can lead to resource wastage due to the overhead of allocating executors. To mitigate this, consider modifying spark.dynamicAllocation.executorAllocationRatio. The scaling down process is shuffle aware, avoiding executors holding shuffle data. Although this shuffle data is usually subject to garbage collection, if it’s not being cleared fast enough, the spark.dynamicAllocation.shuffleTracking.timeout setting can be adjusted to determine when executors should be timed out and removed.
Let’s examine fine-grained scaling with an example of a spiky workload where data is periodically ingested, followed by idle intervals. The following graph illustrates an EMR Serverless streaming job processing data from an on-demand Kinesis data stream. Initially, the job handles 100 records per second. As tasks queue, dynamic allocation adds capacity, which is quickly released due to short task durations (adjustable using executorAllocationRatio). When we increase input data to 10,000 records per second, Kinesis adds shards, triggering EMR Serverless to provision more executors. Scaling down happens as executors complete processing and are released after the idle timeout (spark.dynamicAllocation.executorIdleTimeout, default 60 seconds), leaving only the Spark driver running during the idle window. (Full scale-down is source dependent. For example, a provisioned Kinesis data stream with a fixed number of shards may have limitations in fully scaling down even when shards are idle.) This pattern repeats as bursts of 10,000 records per second alternate with idle periods, allowing EMR Serverless to scale resources dynamically. This job uses the following configuration:

Resiliency
EMR Serverless ensures resiliency in streaming jobs by leveraging automatic recovery and fault-tolerant architectures
Built-in Availability Zone resiliency
Streaming applications drive critical business operations like fraud detection, real-time analytics, and monitoring systems, making any downtime particularly costly. Infrastructure failures at the Availability Zone level can cause significant disruptions to distributed streaming applications, potentially leading to extended downtime and data processing delays.
Amazon EMR Serverless now addresses this challenge with built-in Availability Zone failover capabilities: jobs are initially provisioned in a randomly selected Availability Zone, and, in the event of an Availability Zone failure, the service automatically retries the job in a healthy Availability Zone, minimizing interruptions to processing. Although this feature greatly enhances application reliability, achieving full resiliency requires input data sources that also support Availability Zone failover. Additionally, if you’re using a custom virtual private cloud (VPC) configuration, it is recommended to configure EMR Serverless to operate across multiple Availability Zones to optimize fault tolerance.
The following diagram illustrates a sample architecture.

Auto retry
Streaming applications are susceptible to various runtime failures caused by transient issues such as network connectivity problems, memory pressure, or resource constraints. Without proper retry mechanisms, these temporary failures can lead to permanently stopping jobs, requiring manual intervention to restart the jobs. This not only increases operational overhead but also risks data loss and processing gaps, especially in continuous data processing scenarios where maintaining data consistency is crucial.
EMR Serverless streamlines this process by automatically retrying failed jobs. Streaming jobs use checkpointing to periodically save the computation state to Amazon Simple Storage Service (Amazon S3), allowing failed jobs to restart from the last checkpoint, minimizing data loss and reprocessing time. Although there is no cap on the total number of retries, a thrash prevention mechanism allows you to configure the number of retry attempts per hour, ranging from 1–10, with the default being set to five attempts per hour.
See the following example code:
Observability
EMR Serverless provides robust log management and enhanced monitoring, enabling users to efficiently troubleshoot issues and optimize the performance of streaming jobs.
Event log rotation and compression
Spark streaming applications continuously process data and generate substantial amounts of event log data. The accumulation of these logs can consume significant disk space, potentially leading to degraded performance or even system failures due to disk space exhaustion.
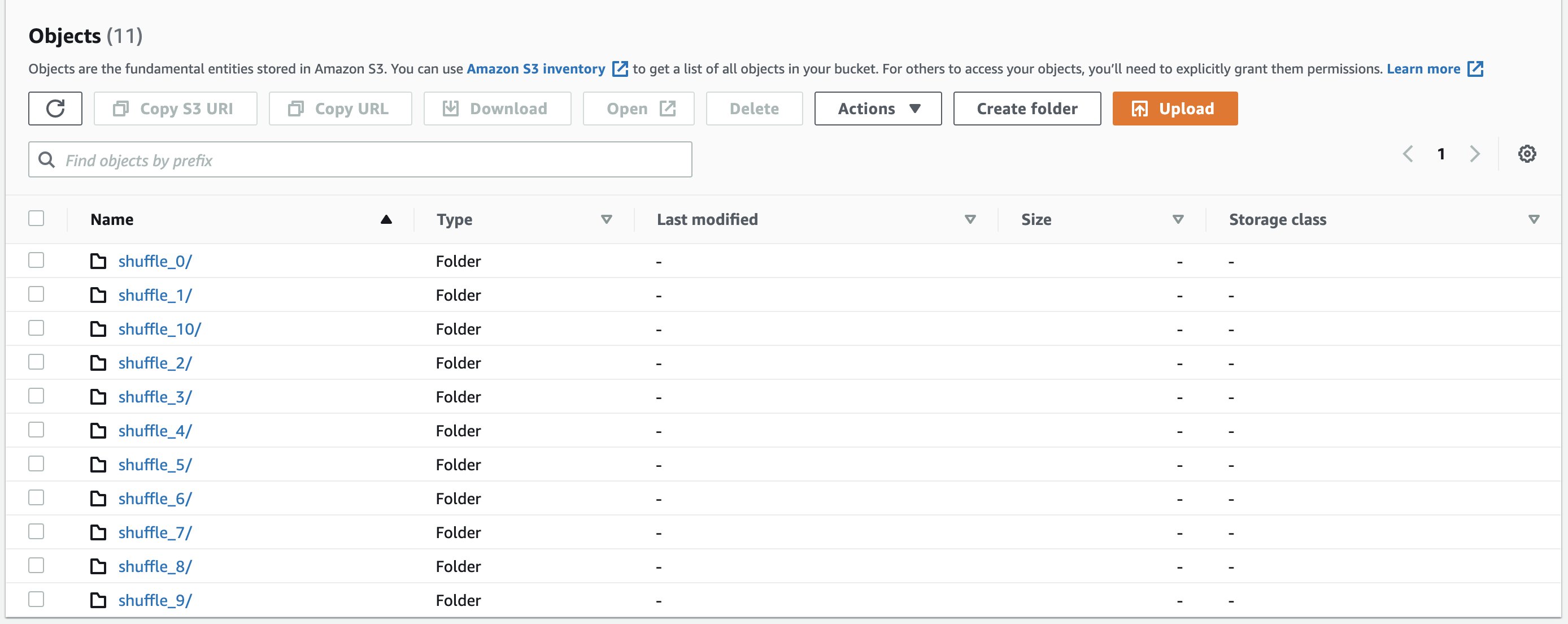
Log rotation mitigates these risks by periodically archiving old logs and creating new ones, thereby maintaining a manageable size of active log files. Event log rotation is enabled by default for both batch as well as streaming jobs and can’t be disabled. Rotating logs doesn’t affect the logs uploaded to the S3 bucket. However, they will be compressed using zstd standard. You can find rotated event logs under the following S3 folder:
The following table summarizes key configurations that govern event log rotation.
| Configuration | Value | Comment |
| spark.eventLog.rotation.enabled | TRUE | |
| spark.eventLog.rotation.interval | 300 seconds | Specifies time interval for the log rotation |
| spark.eventLog.rotation.maxFilesToRetain | 2 | Specifies how many rotated log files to keep during cleanup |
| spark.eventLog.rotation.minFileSize | 1 MB | Specifies a minimum file size to rotate the log file |
Application log rotation and compression
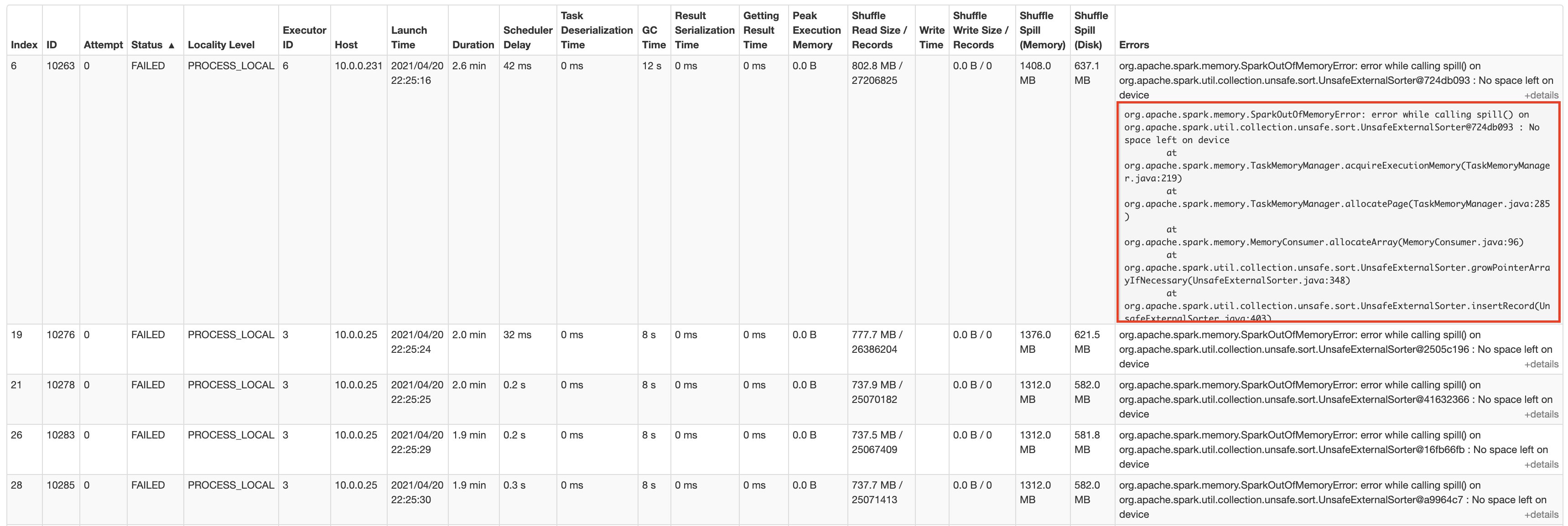
One of the most common errors in Spark streaming applications is the no space left on disk errors, primarily caused by the rapid accumulation of application logs during continuous data processing. These Spark streaming application logs from drivers and executors can grow exponentially, quickly consuming available disk space.
To address this, EMR Serverless has introduced rotation and compression for driver and executor stderr and stdout logs. Log files are refreshed every 15 seconds and can range from 0–128 MB. You can find the latest log files at the following Amazon S3 locations:
Rotated application logs are pushed to archive available under the following Amazon S3 locations:
Enhanced monitoring
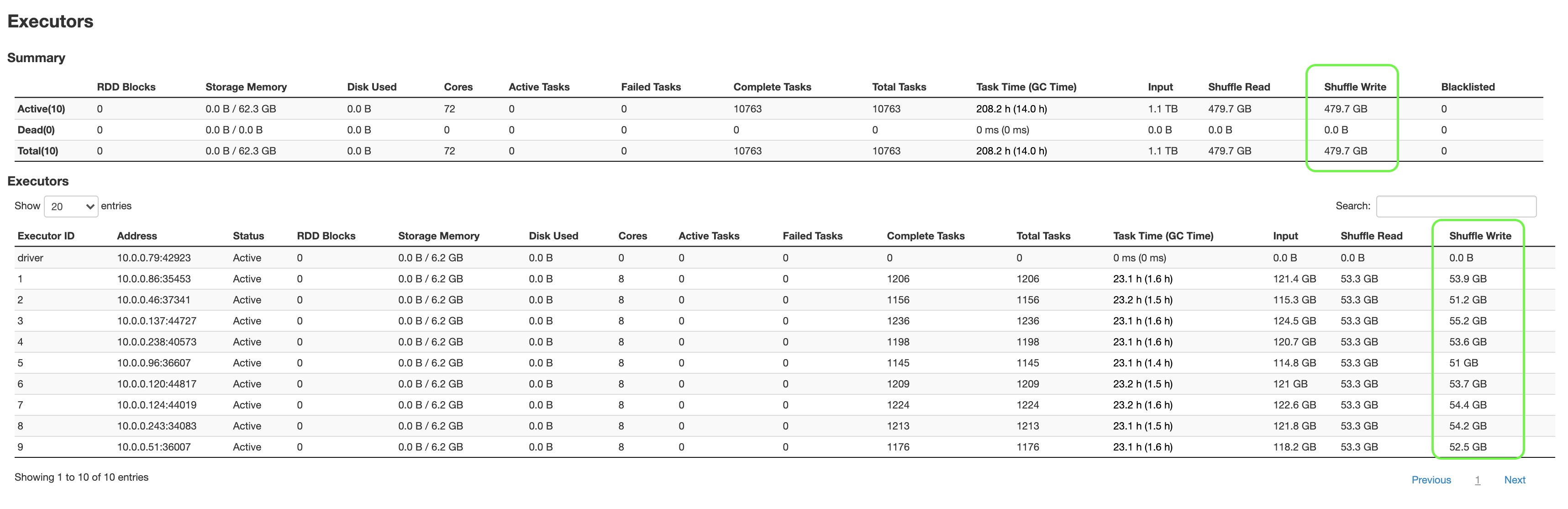
Spark provides comprehensive performance metrics for drivers and executors, including JVM heap memory, garbage collection, and shuffle data, which are valuable for troubleshooting performance and analyzing workloads. Starting with Amazon EMR 7.1, EMR Serverless integrates with Amazon Managed Service for Prometheus, enabling you to monitor, analyze, and optimize your jobs using detailed engine metrics, such as Spark event timelines, stages, tasks, and executors. This integration is available when submitting jobs or creating applications. For setup details, refer to Monitor Spark metrics with Amazon Managed Service for Prometheus. To enable metrics for Structured Streaming queries, set the Spark property --conf spark.sql.streaming.metricsEnabled=true
You can also monitor and debug jobs using the Spark UI. The web UI presents a visual interface with detailed information about your running and completed jobs. You can dive into job-specific metrics and information about event timelines, stages, tasks, and executors for each job.
Service integrations
Organizations often struggle with integrating multiple streaming data sources into their data processing pipelines. Managing different connectors, dealing with varying protocols, and providing compatibility across diverse streaming platforms can be complex and time-consuming.
EMR Serverless supports Kinesis Data Streams, Amazon MSK, and self-managed Apache Kafka clusters as input data sources to read and process data in near real time.
Whereas the Kinesis Data Streams connector is natively available on Amazon EMR, the Kafka connector is an open source connector from the Spark community and is available in a Maven repository.
The following diagram illustrates a sample architecture for each connector.

Refer to Supported streaming connectors to learn more about using these connectors.
Additionally, you can refer to the aws-samples GitHub repo to set up a streaming job reading data from a Kinesis data stream. It uses the Amazon Kinesis Data Generator to generate test data.
Conclusion
Running Spark Structured Streaming on EMR Serverless offers a robust and scalable solution for real-time data processing. By taking advantage of the seamless integration with AWS services like Kinesis Data Streams, you can efficiently handle streaming data with ease. The platform’s advanced monitoring tools and automated resiliency features provide high availability and reliability, minimizing downtime and data loss. Furthermore, the performance optimizations and cost-effective serverless model make it an ideal choice for organizations looking to harness the power of near real-time analytics without the complexities of managing infrastructure.
Try out using Spark Structured Streaming on EMR Serverless for your own use case, and share your questions in the comments.
About the Authors
 Anubhav Awasthi is a Sr. Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.
Anubhav Awasthi is a Sr. Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.
 Kshitija Dound is an Associate Specialist Solutions Architect at AWS based in New York City, focusing on data and AI. She collaborates with customers to transform their ideas into cloud solutions, using AWS big data and AI services. In her spare time, Kshitija enjoys exploring museums, indulging in art, and embracing NYC’s outdoor scene.
Kshitija Dound is an Associate Specialist Solutions Architect at AWS based in New York City, focusing on data and AI. She collaborates with customers to transform their ideas into cloud solutions, using AWS big data and AI services. In her spare time, Kshitija enjoys exploring museums, indulging in art, and embracing NYC’s outdoor scene.
 Paul Min is a Solutions Architect at AWS, where he works with customers to advance their mission and accelerate their cloud adoption. He is passionate about helping customers reimagine what’s possible with AWS. Outside of work, Paul enjoys spending time with his wife and golfing.
Paul Min is a Solutions Architect at AWS, where he works with customers to advance their mission and accelerate their cloud adoption. He is passionate about helping customers reimagine what’s possible with AWS. Outside of work, Paul enjoys spending time with his wife and golfing.





















 Anubhav Awasthi is a Sr. Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.
Anubhav Awasthi is a Sr. Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation. Nishchai JM is an Analytics Specialist Solutions Architect at Amazon Web services. He specializes in building Big-data applications and help customer to modernize their applications on Cloud. He thinks Data is new oil and spends most of his time in deriving insights out of the Data.
Nishchai JM is an Analytics Specialist Solutions Architect at Amazon Web services. He specializes in building Big-data applications and help customer to modernize their applications on Cloud. He thinks Data is new oil and spends most of his time in deriving insights out of the Data.











 Anubhav Awasthi is a Sr. Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.
Anubhav Awasthi is a Sr. Big Data Specialist Solutions Architect at AWS. He works with customers to provide architectural guidance for running analytics solutions on Amazon EMR, Amazon Athena, AWS Glue, and AWS Lake Formation.