Post Syndicated from Behram Irani original https://aws.amazon.com/blogs/big-data/query-data-in-amazon-opensearch-service-using-sql-from-amazon-athena/
Amazon Athena is an interactive serverless query service to query data from Amazon Simple Storage Service (Amazon S3) in standard SQL. Amazon OpenSearch Service (successor to Amazon Elasticsearch Service) is a fully managed, open-source, distributed search and analytics suite derived from Elasticsearch, allowing you to run OpenSearch Service or Elasticsearch clusters at scale without having to manage hardware provisioning, software installation, patching, backups, and so on.
Although both services have their own use cases, there might be situations when you want to run queries that combine data in Amazon S3 with data in an Amazon OpenSearch Service Cluster. In such cases, federated queries in Athena are a good option—they provide the capability to combine data from multiple data sources and analyze them in a single query. The federated query feature works by using data source connectors that are built for different data sources. To allow Amazon OpenSearch Service to be one of the sources that Athena can query against, AWS has made available a data source connector for OpenSearch Service clusters to be queried from Athena.
This post demonstrates how to query data in Amazon OpenSearch Service and Amazon S3 in a single query. We use the data made available in the public COVID-19 data lake, documented as part of the post A public data lake for analysis of COVID-19 data.
In particular, we use the following two datasets:
alleninstitute_metadata: Metadata on papers pulled from the COVID-19 Open Research Dataset (CORD-19). Theshacolumn indicates the paper ID, which is the file name of the paper in the data lake. This dataset is stored in Amazon OpenSearch Service because it contains the column abstract, which you can search on.alleninstitute_comprehend_medical: Results containing annotations obtained by running the papers in the preceding dataset through Amazon Comprehend Medical. This is accessed from its public storage ats3://covid19-lake/alleninstitute/CORD19/comprehendmedical/comprehend_medical.json.
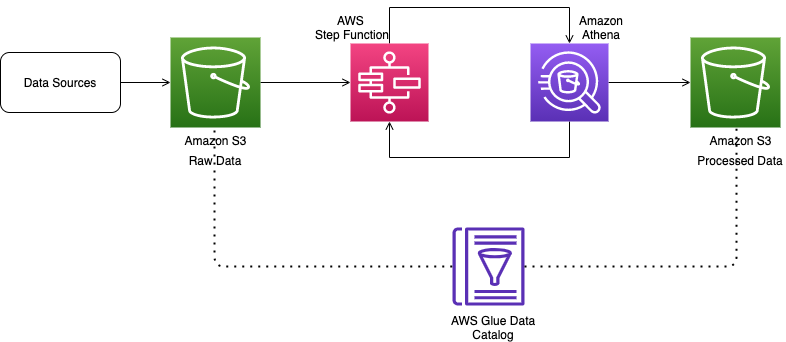
Data flow when combining data from Amazon OpenSearch Service and Amazon S3
The data source connectors are implemented as AWS Lambda functions. When a user issues a query that combines data from Amazon OpenSearch Service and Amazon S3, Athena refers to the AWS Glue Data Catalog metadata to look up the table definitions. For the table whose data is in Amazon S3, Athena fetches the data from Amazon S3. For the tables that are in Amazon OpenSearch Service, Athena invokes the Lambda function (part of the data source connector application) to read the data from Amazon OpenSearch Service. Depending on the amount of data, you can invoke this function multiple times in parallel for the same query to enable faster reads.
The following diagram illustrates this data flow.

Set up the two data sources using AWS CloudFormation
To prepare for querying both data sources, launch the AWS CloudFormation template using the “Launch Stack” button below. All you need to do is choose Create stack.
![]()
To run the CloudFormation stack, you need to be logged in to an AWS account with permissions to do the following:
- Create a CloudFormation stack
- Create an Identity and Access Management (IAM) role
- Create a Lambda function, assign an IAM role to it, and invoke it
- Launch an OpenSearch Service cluster
- Create AWS Glue databases and table
- Create an S3 bucket
For instructions on creating a CloudFormation stack, see Get started.
For more information about controlling permissions and access for these services, see the following resources:
- CloudFormation – Controlling access with AWS Identity and Access Management
- Lambda – AWS Lambda permissions
- Amazon OpenSearch Service – Identity and Access Management in Amazon OpenSearch Service
- AWS Glue – Managing Access Permissions for AWS Glue Resources
- Amazon S3 – Identity and access management in Amazon S3
The CloudFormation template creates the following:
- A table in the AWS Glue Data Catalog named
alleninstitute_comprehend_medicalthat points to the S3 locations3://covid19-lake/alleninstitute/CORD19/comprehendmedical/comprehend_medical.json. This contains the results extracted from the CORD-19 data using the natural language processing service Amazon Comprehend Medical. - An S3 bucket with the name
athena-es-connector-spill-bucket-followed by the first few characters from the stack ID to keep the bucket name unique. - An OpenSearch Service cluster with the name
es-alleninstitute-data, which has two instances configured to allow a role to access the cluster. - An IAM role to access the OpenSearch Service cluster.
- A Lambda function that contains a piece of Python code that reads all the metadata of the papers along with the abstract. This data is available as JSON at
s3://covid19-lake/alleninstitute/CORD19/json/metadata/. For this post, we load just one of the four JSON files available. - A custom resource that invokes the Lambda function to load the data into the OpenSearch Service cluster.
The stack can take 15–30 minutes to complete.
When the stack is fully deployed, navigate to the Outputs tab of the stack and note the name of the S3 bucket created (the value for SpillBucket).

For the rest of the steps, you need permissions to do the following:
- Deploy an application in the AWS Serverless Application Repository (for information about IAM access, see Identity and Access Management for the AWS Serverless Application Repository)
- Create a new data source and run queries in Athena (for information about IAM access, see Identity and Access Management in Athena)
Deploy the Amazon Athena OpenSearch connector
When the OpenSearch Service domain with an index containing the metadata related to the COVID-19 research papers and the AWS Glue table pointing to the Amazon Comprehend Medical output data is ready, you can deploy the Amazon Athena OpenSearch connector using the AWS Serverless Application Repository.
- On the AWS Serverless Application Repository console, choose Available applications.

- Search for
Athena Elasticsearchand select Show apps that create custom IAM roles or resource policies. - Choose AthenaElasticsearchConnector.

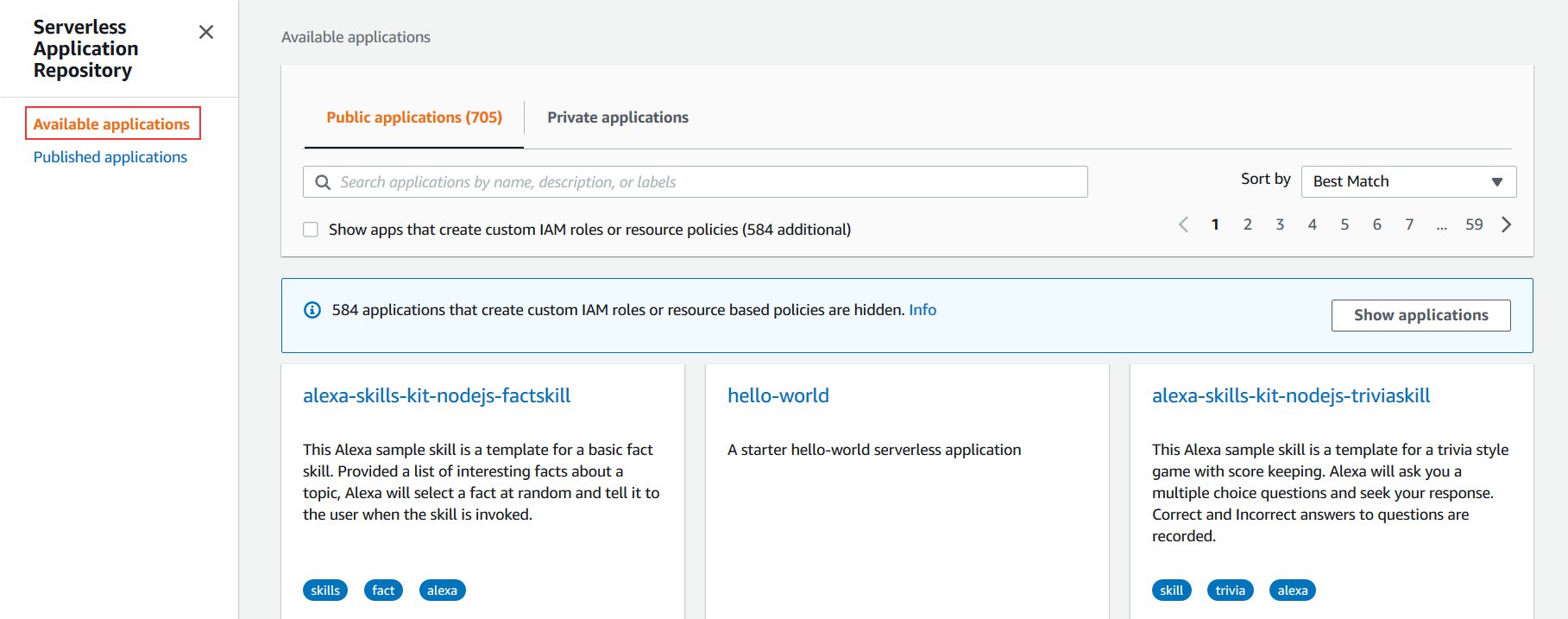
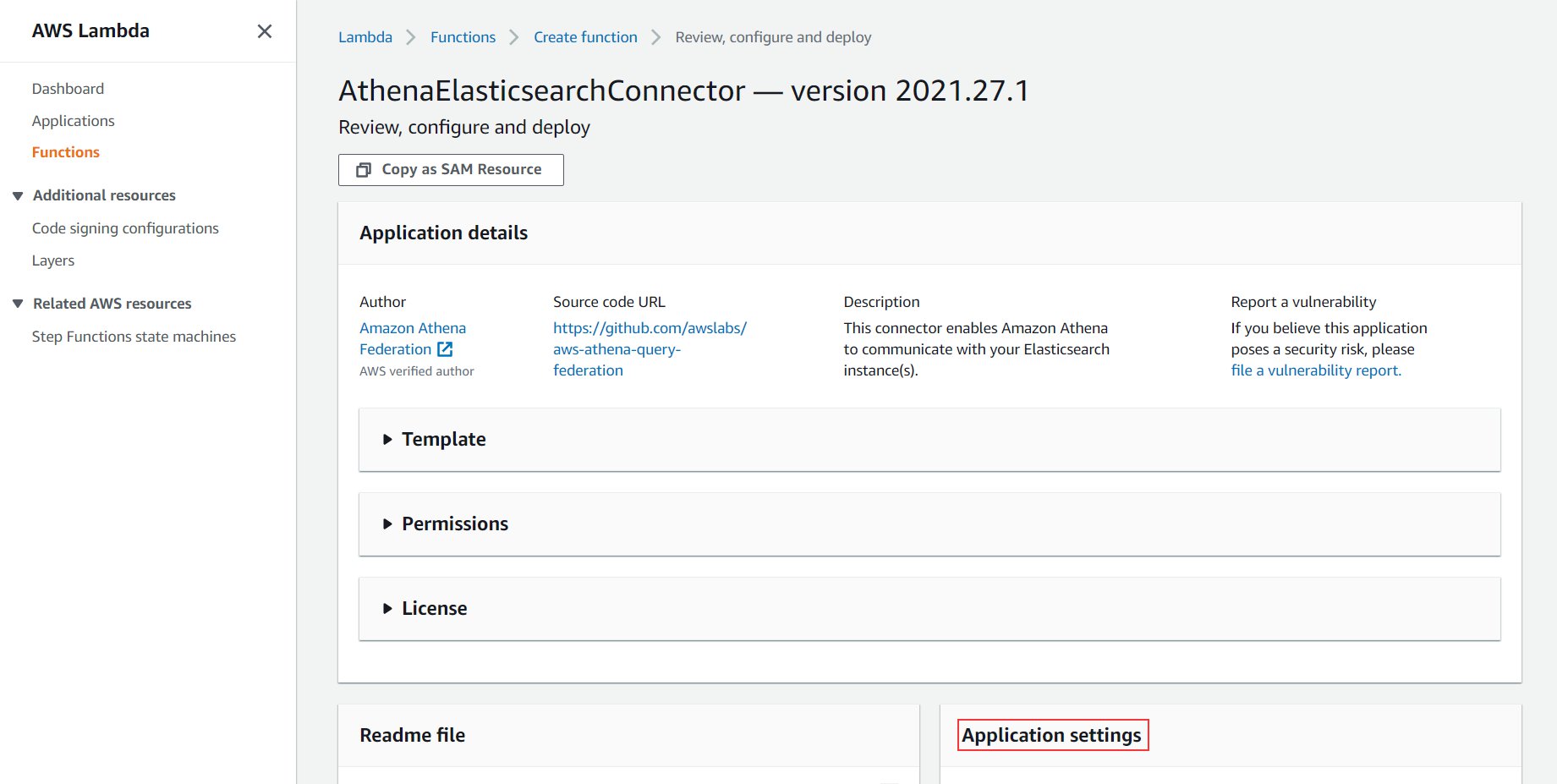
You’re redirected to the application screen.
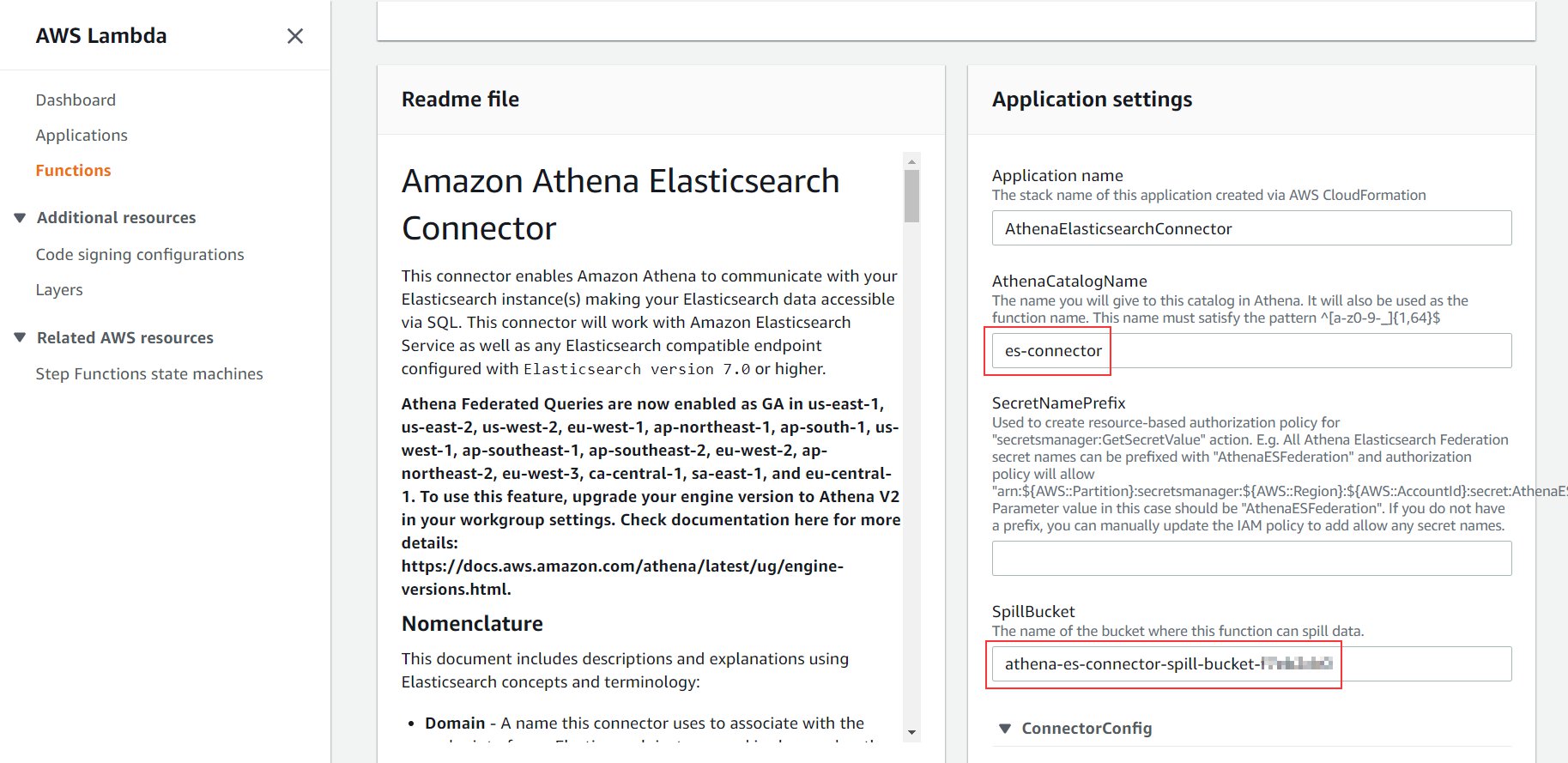
- Scroll down to the Application settings section.
- For AthenaCatalogName, enter a name (for this post, we use
es-connector).
This name is the name of the application and the Lambda function that connects to Amazon OpenSearch Service every time you run a query from Athena. For more details about all the parameters, refer to the connector’s GitHub page.
- For SpillBucket, enter the name you noted in the previous section when we deployed the CloudFormation stack (it begins with
athena-es-connector-spill-bucket).

- Leave all other settings as default.

- Select I acknowledge that this app creates custom IAM roles.
- Choose Deploy.


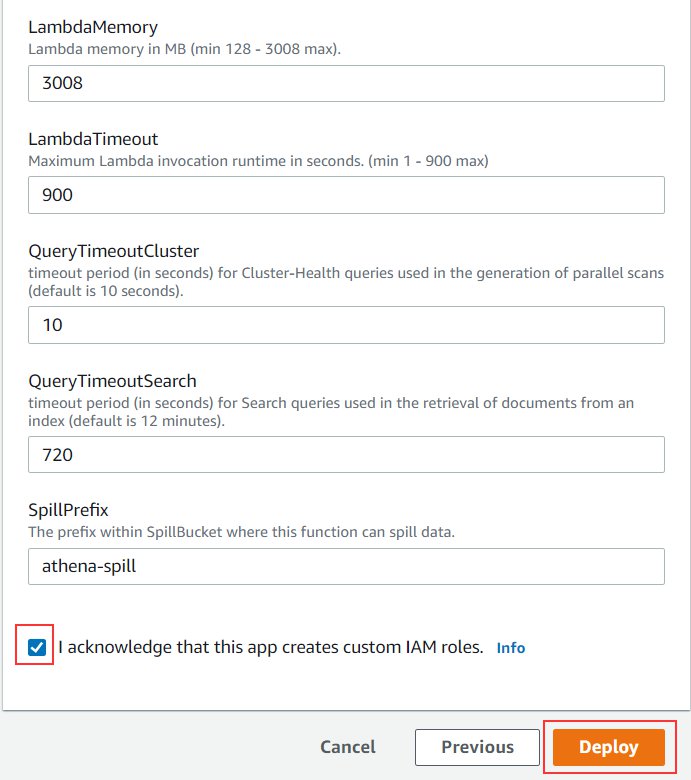
In a few seconds, you’re redirected to the Applications page. You can see the status of your deployment on the Deployments tab. The deployment takes 1–2 minutes to complete.

Create a new data source in Athena
Now that the connector application has been deployed, it’s time to set up the OpenSearch Service domain to show as a catalog on Athena.
- On the Athena console, navigate to the
cord19database.
The database contains the table alleninstitute_comprehend_medical, which was created as part of the CloudFormation template. This refers to the data sitting in Amazon S3 at s3://covid19-lake/alleninstitute/CORD19/comprehendmedical/.
- Choose Data sources in the navigation pane.

- Choose Connect data source.

- Select Custom data source.

- For Data source name, enter a name (for example,
es-cord19-catalog). - Select Use an existing Lambda function and choose es-connector on the drop-down menu.

- Choose Connect data source.

- Choose Next.
- For Lambda function, choose es-connector.
- Choose Connect.
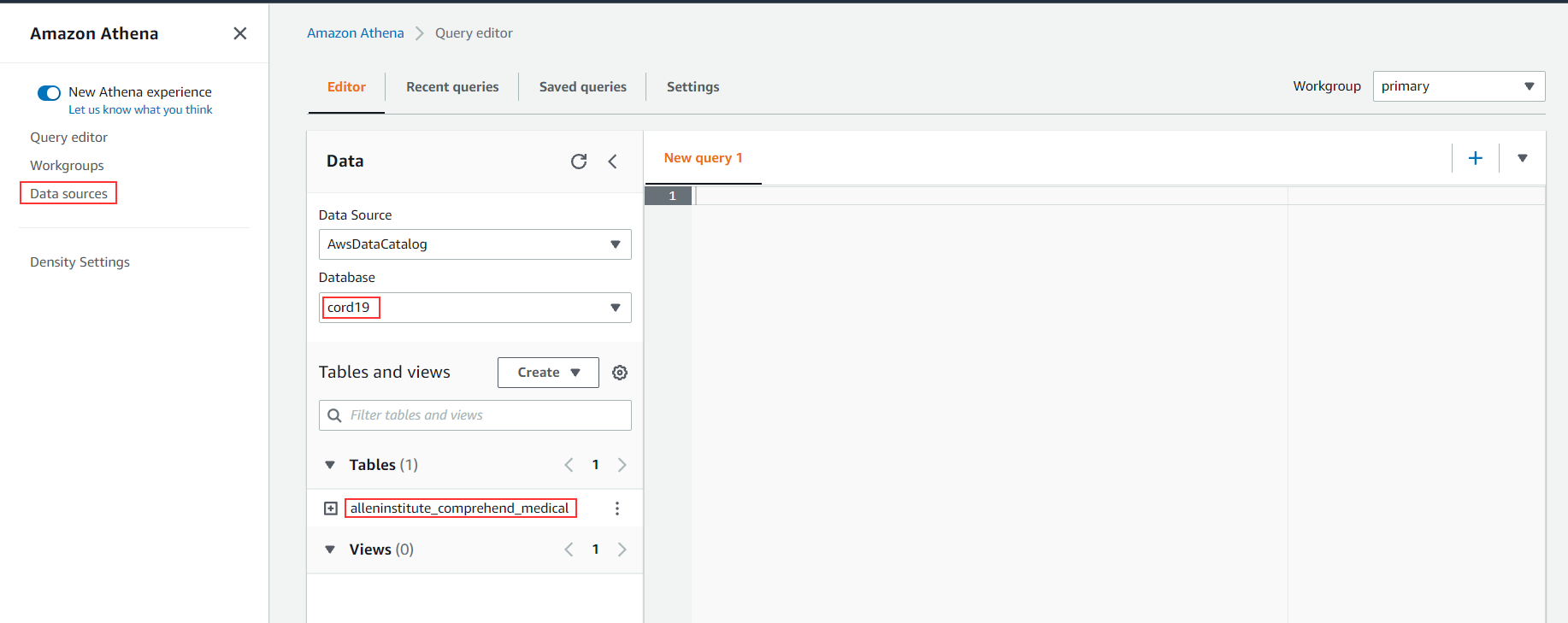




A new catalog es-cord19-catalog should now be available, as in the following screenshot.

- On the Query editor tab, for Data source, choose es-cord19-catalog.


You can now query this data source from Athena.
Query OpenSearch Service domains from Athena
When you choose the es-cord19-catalog data source, the Lambda function (which was part of the connector application that we deployed) gets invoked and fetches the details about the domain and the index. The OpenSearch Service domain shows up as a database, and the index is shown as a table. You can also query the table with the following query:

Now you can join data from both Amazon OpenSearch Service and Amazon S3 with queries, such as the following:
The preceding query gets the title and the URL of all the research papers where the diagnosis was related to infectious diseases.
The following screenshot shows the query results.

Clean up
To clean up the resources created as part of this post, complete the following steps:
- On the Amazon S3 console, locate and select your S3 bucket (the same bucket you noted from the CloudFormation stack).
- Choose Empty.


You can also achieve this by running the following command from a command line:
- On the AWS CloudFormation console, delete the stack you created.

- Delete the stack created for the Amazon Athena OpenSearch connector application. The default name is
serverlessrepo-AthenaElasticsearchConnector.

- On the Athena console, delete the
es-cord19-catalogdata source.




You can also delete the data source with the following command:
Conclusion
In this post, we saw how to combine data from OpenSearch Service clusters with other data sources like Amazon S3 to run federated queries. You can apply this solution to other use cases, such as combining AWS CloudTrail logs loaded into OpenSearch Service clusters with VPC flow logs data in Amazon S3 to analyze unusual network traffic, or combining product reviews data in Amazon OpenSearch Service with product data in Amazon S3 or other data sources. You can also pull data from Amazon OpenSearch Service and create an AWS Glue table out of it using a CTAS query in Athena.
To learn more about the Amazon Athena OpenSearch connector and its other configuration options, see the GitHub repo.
To learn more about query federation in Athena, refer to Using Amazon Athena Federated Query or Query any data source with Amazon Athena’s new federated query.
About the Authors
 Behram Irani, Sr Analytics Solutions Architect
Behram Irani, Sr Analytics Solutions Architect
 Madhav Vishnubhatta, Sr Technical Account Manager
Madhav Vishnubhatta, Sr Technical Account Manager