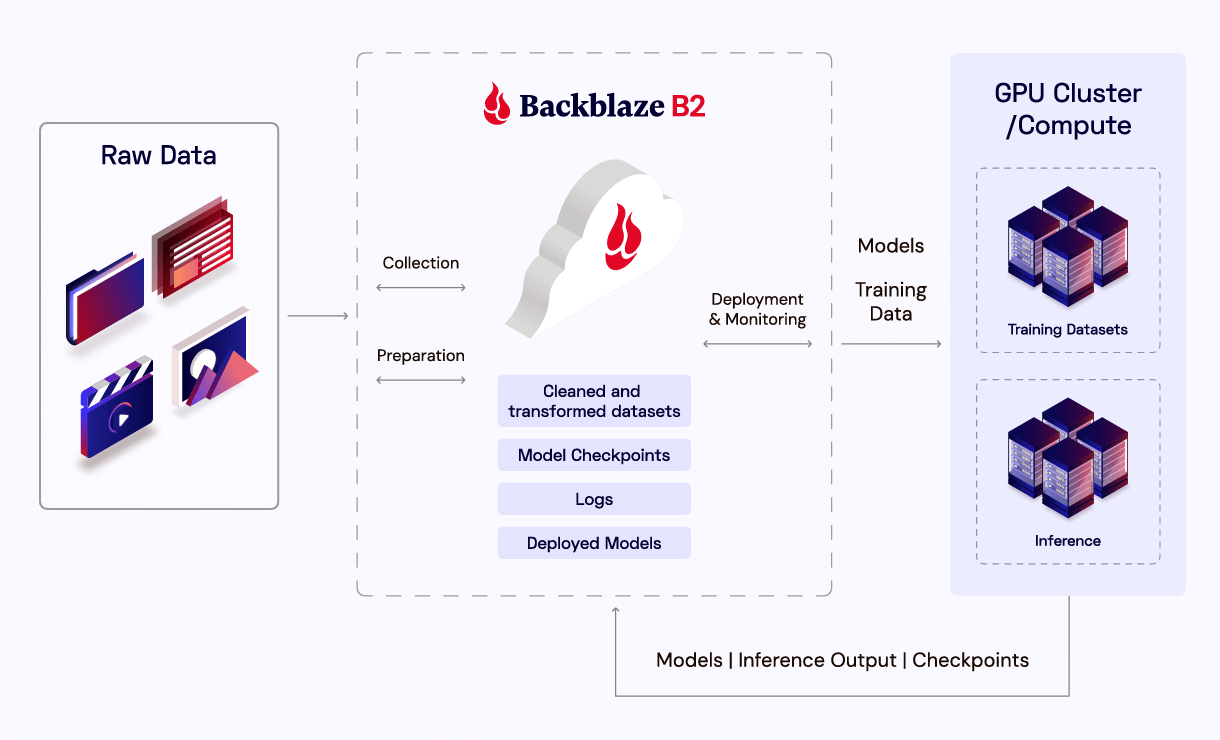
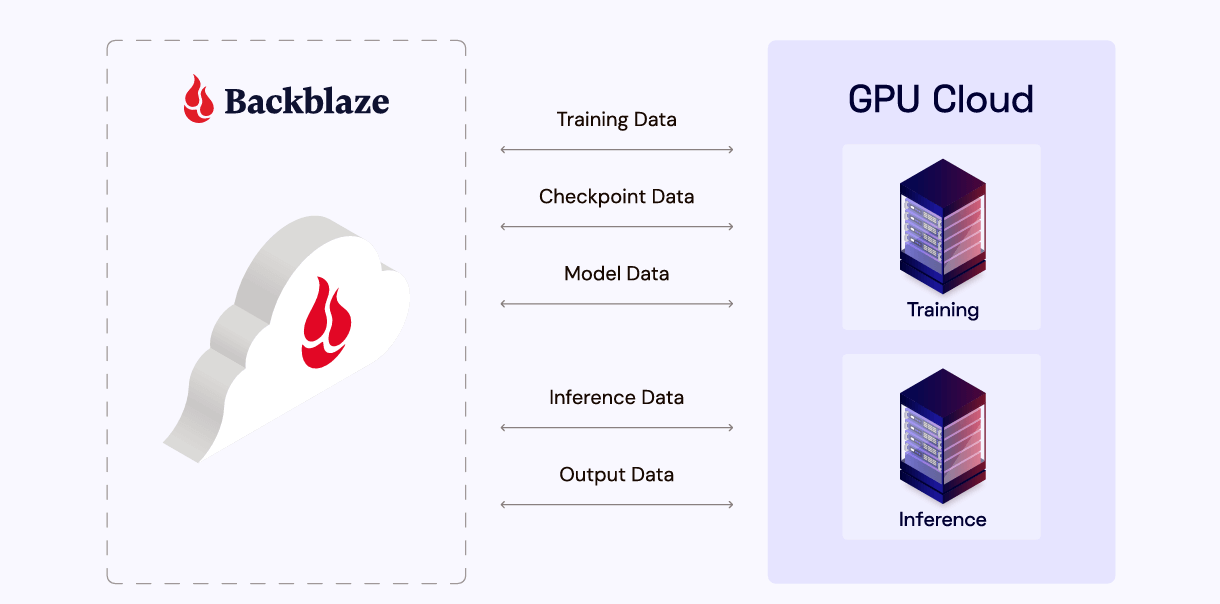
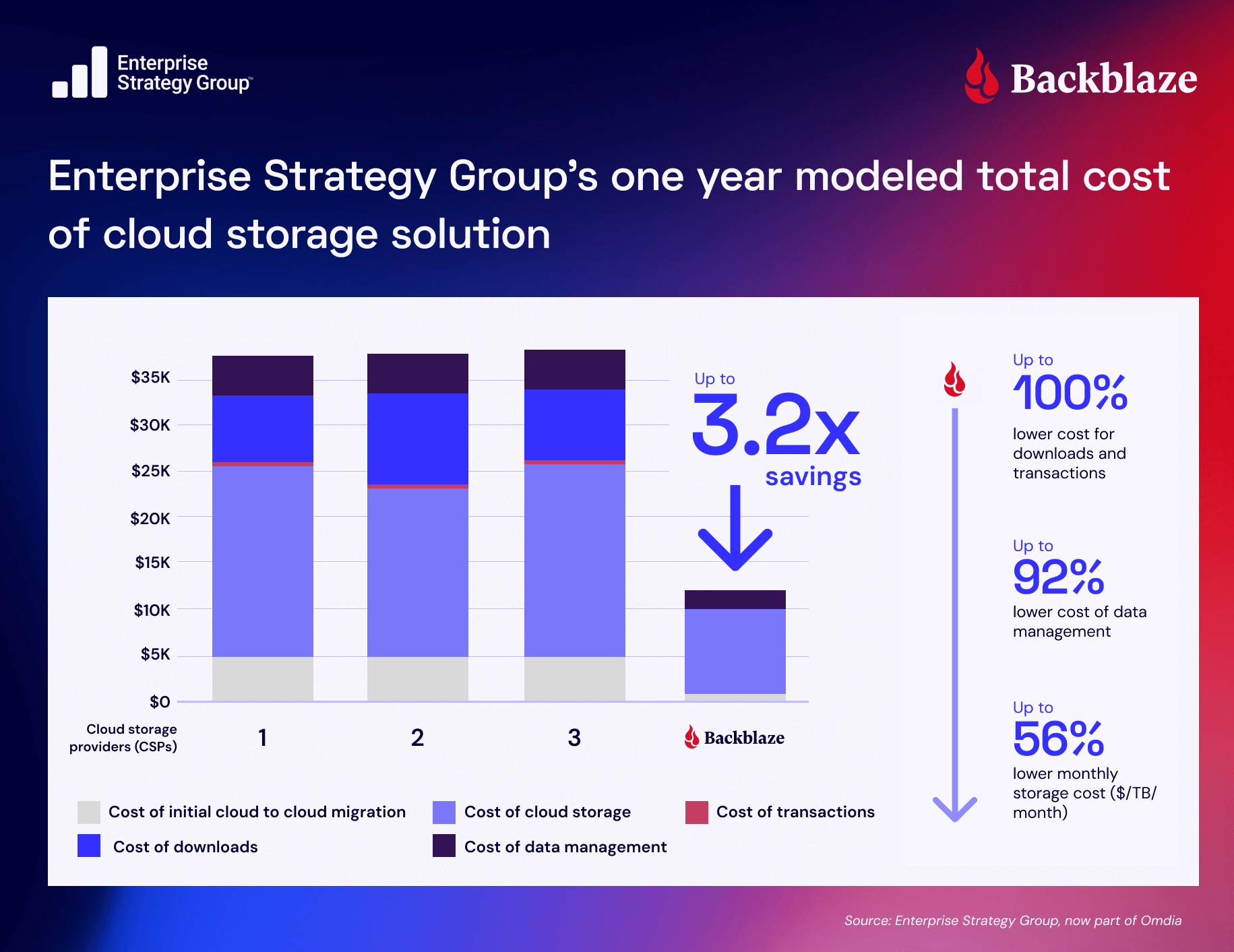
Post Syndicated from David Johnson original https://www.backblaze.com/blog/the-storage-fix-devops-has-been-waiting-for/

Developer operations (DevOps) engineers sit at the intersection of development and operations. Their job is to keep pipelines humming, environments consistent, and deployments on schedule, all while juggling uptime, costs, and compliance.
This balancing act leaves little tolerance for surprises. Unfortunately, storage from major cloud providers often delivers exactly that. Built to cover every use case from backups to analytics to streaming, general-purpose storage prioritizes breadth over focus. The result is complexity:
- Tiering rules that shift data unexpectedly
- Pricing models that change with every access pattern
- Dependencies that ripple across services
For DevOps, this type of one-size-fits-all system means hidden costs, shifting performance, and integration headaches right when predictability matters most.
The good news: you don’t need to overhaul your entire stack to regain control. Adding a specialized, always-hot storage layer can resolve DevOps engineers’ biggest storage headaches without forcing major workflow changes.
This post is the second in our three-part series on how specialized storage helps every member of a cloud-native team, including developers, DevOps engineers, and site reliability engineers (SREs). Today, we’ll focus on the payoffs for DevOps engineers.
Storage that works the way DevOps does
For DevOps engineers, storage issues often show up in the middle of critical workflows. A change meant to speed deployments triggers cascading adjustments. A spike in access patterns turns into sprawling invoices and finance tickets. A misaligned rule blocks data right when pipelines need it most.
In the sections below, we’ll dig into how these problems derail day-to-day operations, and how purpose-built cloud storage removes the friction so DevOps teams can stay focused on building and delivering.
Free ebook: Why object storage is essential for AI workloads
Unlock faster development and simpler workflows—without surprise costs. Get our free ebook “Cloud Storage for the Cloud-Native Era.”

Migration without migraines
Swapping a storage layer usually comes with the fear of broken pipelines, incompatible APIs, or weeks of retraining. And the big three cloud providers compound this by tying services together so tightly that even small changes can ripple through deployments.
That means a tweak meant to improve storage can unexpectedly force adjustments in compute, networking, or identity and access management (IAM). Now, you’re slowing down releases instead of speeding them up.
Specialized storage avoids this trap. With drop-in S3 compatibility and no tier juggling, adding it to your stack requires little more than updating an endpoint and credentials. Pipelines keep running, Terraform and Kubernetes scripts stay intact, and deployments continue smoothly, so storage upgrades feel like routine maintenance, not full migrations.
Invoices without inquisitions
Engineers shouldn’t have to be accountants. But with major cloud providers, storage costs often spike without warning when charges are tied to shifting access patterns, such as frequent reads, writes, or transfers.
The result is sprawling invoices packed with egress fees, API surcharges, and delete penalties. Finance teams see the bill and demand answers. DevOps teams could spend hours untangling storage math instead of improving automation or hardening pipelines. Every unexplained charge turns into a ticket, and every ticket drags engineers away from engineering.
Specialized storage removes this ordeal. Flat, transparent pricing and no hidden penalties make costs easy to predict and explain. That clarity keeps tickets low and escalations rare. DevOps teams can walk into finance reviews with confidence, backed by numbers that are simple to explain.
Engineering without entanglements
Major cloud provider environments come with a maze of tiers, lifecycle policies, IAM rules, and cross-service dependencies. Managing these isn’t a one-time task; it’s a cycle of effort that eats into engineering time:
- Writing: Defining lifecycle policies and IAM rules to control when data moves between tiers or who can access it.
- Testing: Validating every rule to make sure it doesn’t archive active data, block critical access, or violate compliance requirements.
- Maintaining: Updating policies as workloads evolve, with new buckets, new services, or shifting security mandates.
- Troubleshooting: Debugging typos, misaligned automations, or unexpected interactions that can lead to outages, delays, or surprise costs.
For DevOps, every new policy is another layer of overhead and another chance for something to break.
Specialized storage ends this cycle. With no lifecycle rules to script or tiers to monitor, you don’t have to spend hours debugging brittle policies. That reclaimed time goes back into what matters: strengthening automation, refining observability, and improving the pipelines your developers depend on.
Growth without gridlock
DevOps isn’t just about keeping today’s pipelines running; it’s also about ensuring infrastructure won’t collapse under tomorrow’s demands.
As organizations layer on AI/ML pipelines, streaming services, or analytics workloads, data volumes surge and access patterns become less predictable. General-purpose storage often struggles under these conditions, throttling performance and forcing DevOps engineers into troubleshooting slowdowns and capacity crunches whenever workloads outpace storage.
Specialized storage meets these challenges. Its high throughput and penalty-free design scale with demand, so performance holds steady even as workloads expand. Whether supporting AI training jobs or streaming analytics, your infrastructure grows without bottlenecks—and without turning DevOps into crisis management.
Rethink your storage, not your stack
The demands on DevOps engineers aren’t slowing down. They’re expected to deliver speed, reliability, and cost control, all at once. The wrong storage layer makes that harder; the right one makes it easier.
Backblaze B2 was built to make DevOps engineers’ lives easier:
- Minimal changes: S3-compatible APIs work with Terraform, Kubernetes, ArgoCD, and more.
- Predictable costs: Transparent pricing and little-to-no egress fees.
- Simplified operations: Always-hot access, no tier juggling, no lifecycle headaches.
- Future-ready: High throughput and AI-ready integrations.
You don’t have to rebuild your stack to gain these benefits. Just swap the storage endpoint, redeploy, and get back to engineering.
Tired of troubleshooting tiers or decoding invoices? There’s a simpler path forward. Explore how Backblaze B2 fits into your DevOps workflows, and how much smoother things run when storage isn’t slowing you down.
The post The Storage Fix DevOps Has Been Waiting For appeared first on Backblaze Blog | Cloud Storage & Cloud Backup