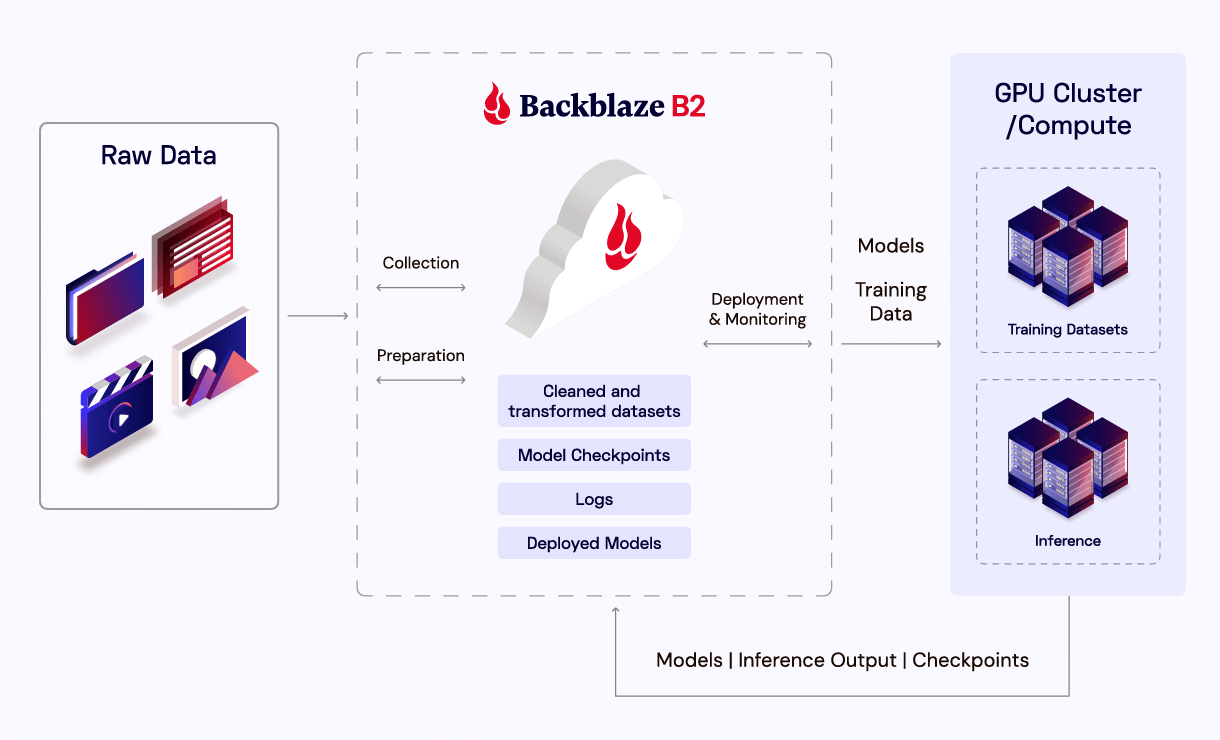
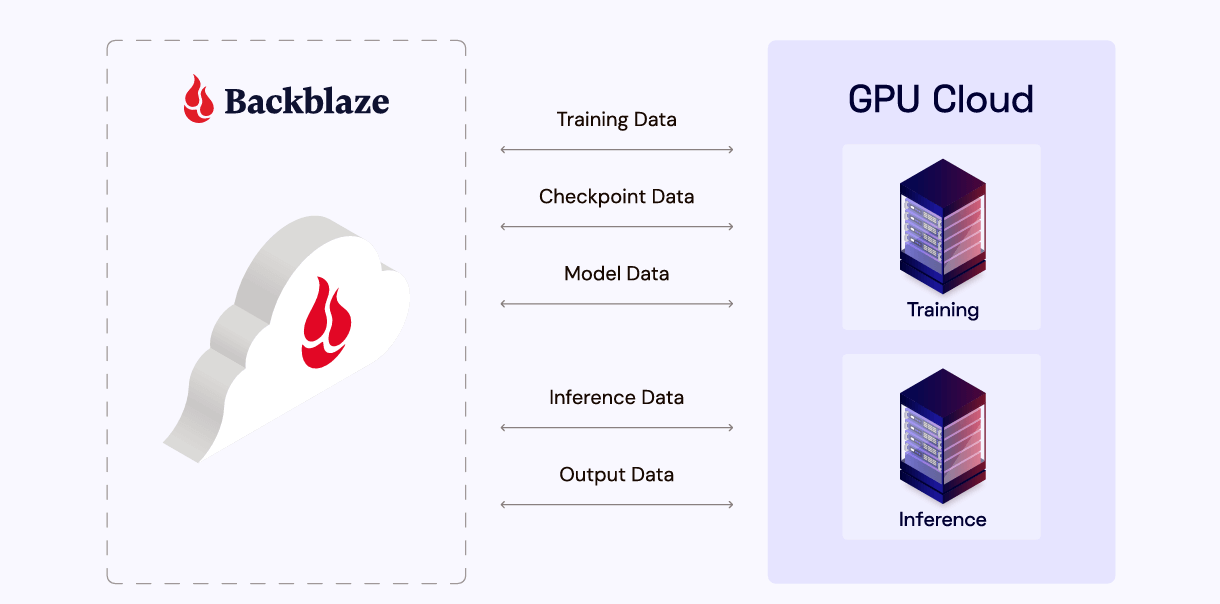
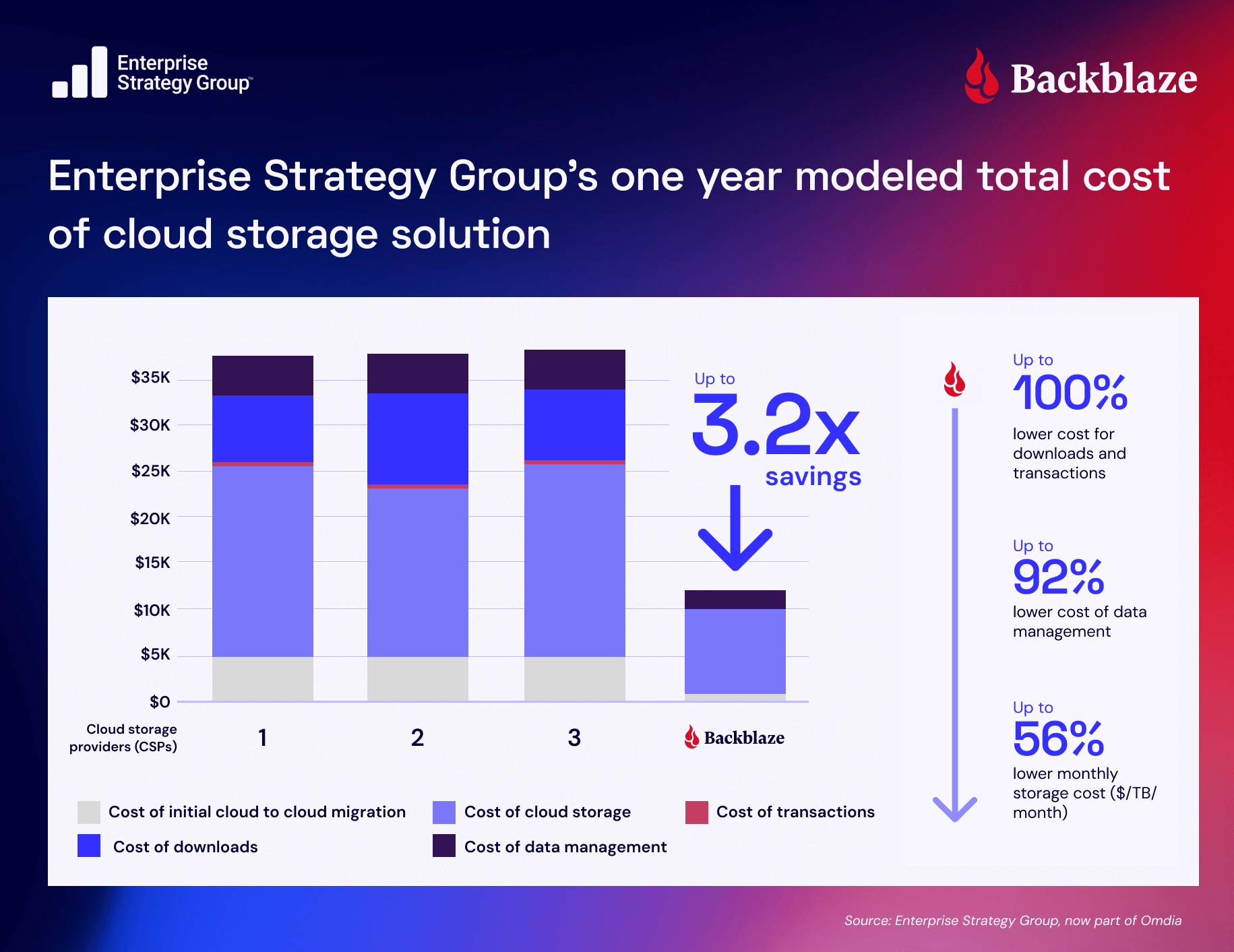
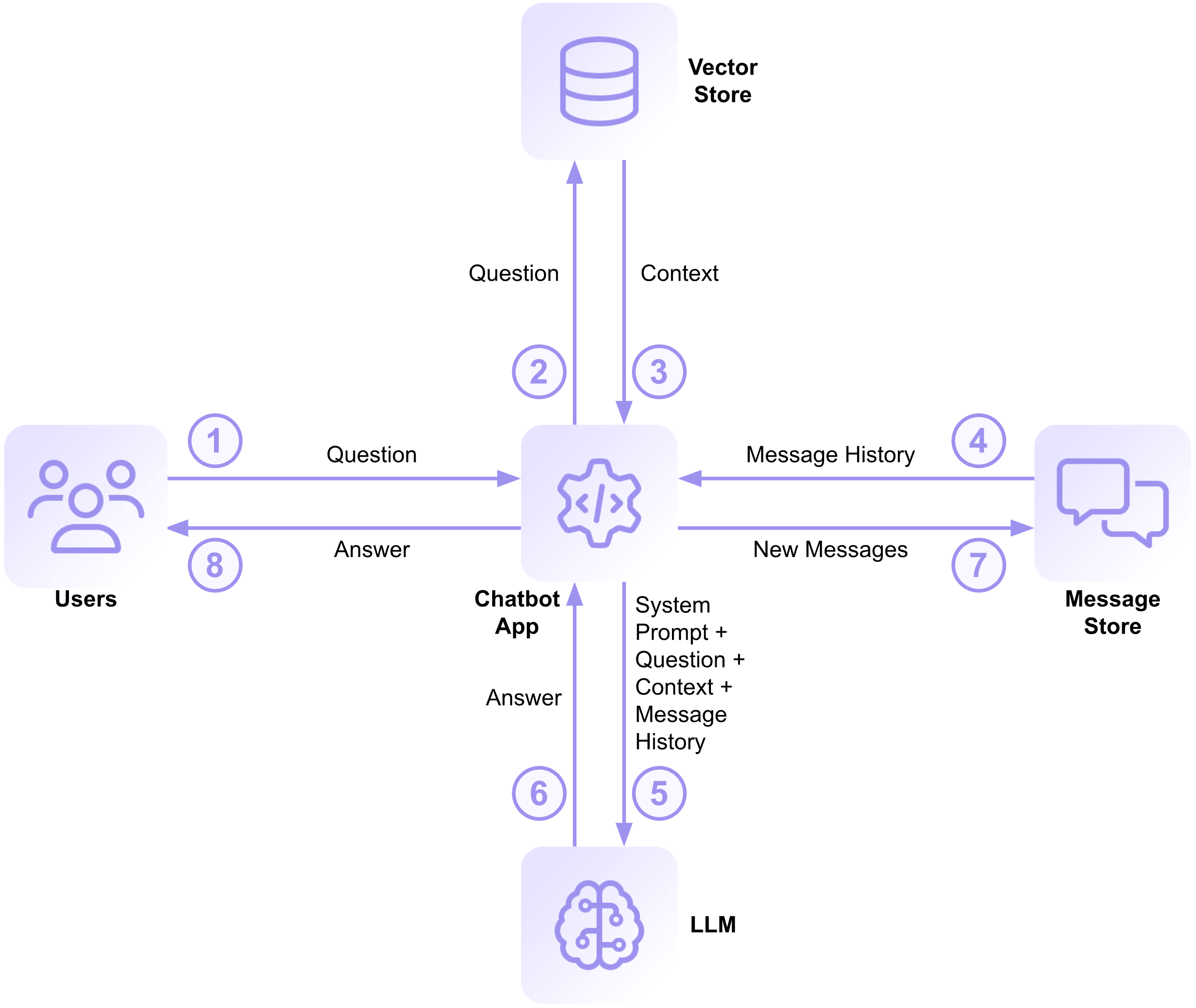
Post Syndicated from Maddie Presland original https://www.backblaze.com/blog/your-training-data-is-your-most-valuable-ip/

AI training data is now a company’s most valuable intellectual property—often worth more than the models themselves. Models can be replicated and architectures become public knowledge, but the datasets that capture your domain expertise and years of careful curation are irreplaceable.
Yet as AI workflows become increasingly distributed, that data moves constantly between environments, increasing exposure while reducing visibility. According to IBM, “Forty percent of breaches involved data stored across multiple environments… highlighting the challenge of tracking and safeguarding data, including shadow data, and data in AI workloads.” Meanwhile MIT Sloan researchers have documented that AI training datasets are often inconsistently documented and poorly understood, creating exposure that extends beyond technical vulnerabilities into operational and compliance failures.
Yet many organizations still treat training datasets as just another storage bucket. But protecting data at rest is both a compliance requirement and a competitive necessity. The integrity of your datasets now determines the integrity of your models.
Free resource: Understand why object storage is a strategic driver
Download our free ebook to learn how object storage supports every stage of the AI pipeline—from data collection to model deployment.

Why training data is the new target
The attack surface for AI systems has fundamentally shifted. Rather than targeting models in production, sophisticated adversaries now focus on the training pipeline itself.
Data poisoning has emerged as an insidious threat
Attackers inject subtle changes like biased samples, mislabeled data, or adversarial examples that skew model outcomes or introduce hidden backdoors. Recent research reveals that 26% of organizations surveyed in the US and UK have been victims of AI data poisoning in the last year. These poisoned models can quietly undermine fraud detection, weaken cyber defenses, and corrupt business-critical decisions.
Intellectual property theft takes on new dimensions
When adversaries steal training datasets, they’re stealing the accumulated expertise that gives your models their edge. Your training data represents thousands of hours of curation and annotation that encodes institutional knowledge about your customers and market. A competitor with your datasets can replicate your capabilities in weeks rather than years.
Silent corruption poses an equally serious but less visible threat
Infrastructure failures, human errors, or gradual drift in data pipelines can corrupt training datasets without triggering alerts. For organizations in regulated industries such as healthcare, financial services, or autonomous systems, this creates a reproducibility crisis. How do you prove your model was trained on authentic, unaltered data when you can’t verify the data’s provenance?
The NIST AI Risk Management Framework emphasizes that maintaining the provenance of training data and supporting attribution of AI system decisions to subsets of training data can assist with both transparency and accountability. Regulators and customers increasingly expect verifiable proof of data integrity throughout the training lifecycle.
The takeaway? The trustworthiness of every model begins with the trustworthiness of its data.
The principles of a secure AI data foundation
A strong protection model rests on three pillars—immutability, encryption, and regional control—each reinforcing long-term integrity.
1. Immutability: Protect against tampering or deletion
Immutability means write-once, read-many (WORM) protection that prevents modification or removal. Once data is written, it becomes locked—no one can modify, overwrite, or delete it for a defined retention period, but it remains fully accessible for reading. This technical guarantee prevents data poisoning attacks, stops accidental deletion, and enables verifiable reproducibility.
CISA advisories recommend immutable backups to guard against ransomware, but the benefits extend much further for AI systems. When you lock a dataset snapshot before training begins, you guarantee the ability to reproduce that exact model state, which is critical for debugging, regulatory audits, and forensic investigations when models fail.
Object Lock capabilities enforce immutability at the storage layer for set retention periods. Each dataset version becomes permanently immutable, creating an unalterable record of your training history that no administrator or attacker can modify.
Implementation tip: Enable Object Lock at the bucket level and integrate it with your data-ingestion scripts to automatically lock datasets as they’re created.
2. Encryption: Safeguard confidential data
Training datasets contain extraordinary value—customer information, proprietary annotations, competitive intelligence embedded in data selection. Server-side encryption protects this data both in transit and at rest, defending against unauthorized access even if other security layers fail. The EU’s recent NIS2 technical guidance explicitly prescribes cryptography as a required control measure for compliance.
The key to practical encryption is simplicity. Solutions should integrate seamlessly into existing workflows without requiring separate key-management infrastructure or introducing performance overhead that disrupts training pipelines.
Implementation tip: Look for server-side encryption options (like SSE-B2 or SSE-C) that remain transparent to your applications while providing the protection regulators require.
3. Regional control: Ensure data sovereignty and availability
Where your data physically resides matters for compliance, latency, and operational resilience. GDPR and similar regulations often require that sensitive data remain within specific jurisdictions. Beyond compliance, regional placement affects training performance—positioning data near compute resources or using high-performance delivery mechanisms can reduce transfer delays when moving large datasets.
The critical factor is transparency. You need explicit control over region selection and assurance that data won’t be replicated to secondary regions without your knowledge. Ambiguous “regional” configurations that might span continents create compliance risk.
Consider a U.S. biomedical AI startup working with patient-derived data. They need datasets stored exclusively in U.S. regions to satisfy HIPAA requirements, Object Lock enabled to prove data integrity for regulatory submissions, and encryption applied to protect sensitive patient information—all while maintaining the competitive advantage their proprietary data provides. Regional control with clear guarantees makes this achievable.
Implementation tip: Choose storage providers that let you explicitly select regions during bucket creation with clear guarantees about where data resides, including replication destinations.
Beyond security: Enabling trust and traceability
Immutable, encrypted, regionally contained object storage enables AI governance at a level traditional storage infrastructure cannot.
Each dataset snapshot becomes a verifiable record of model history. When a model behaves unexpectedly in production, you can trace back to the exact training data used to create it. This capability accelerates debugging and provides the evidence needed to explain model decisions to regulators, customers, or internal stakeholders.
Storage infrastructure with built-in immutability and access logging provides the verifiable evidence that auditors require. Instead of reconstructing data lineage from logs and documentation, you can demonstrate exactly what happened with cryptographic proof.
These capabilities transform storage from a passive repository into an active component of your AI governance framework.
Implementation snapshot: Putting it all together
Establishing these protections with Backblaze B2 follows a straightforward path:
- Create buckets in regions that match your compliance and latency requirements.
- Enable Object Lock and configure retention policies aligned with your model development lifecycle.
- Apply server-side encryption (SSE-B2 or SSE-C) to all training data buckets.
- Activate versioning to maintain a complete history of dataset evolution.
- Configure logging to track access patterns and enable lineage verification.
- Integrate with compute using standard S3 compatible tools.
For organizations running intensive training workloads, Backblaze B2 Overdrive provides high-throughput object storage with up to 1Tbps throughput speeds and unlimited free egress. This allows enterprises to perform large quantities of concurrent data operations without performance degradation, keeping compute resources—including expensive GPUs—from sitting idle while waiting for data transfers. B2 Overdrive maintains the same security and compliance capabilities as standard Backblaze B2 while enabling faster iteration on model development.
The bottom line: Trust begins with proven data
The datasets you’ve built represent years of institutional knowledge—far more difficult to replace than the models trained on them. Protecting that intellectual property requires more than access controls and perimeter security. You need to prove the integrity of your data to regulators who demand accountability, to customers who expect trustworthy AI, and to your own teams who need confidence in model reproducibility.
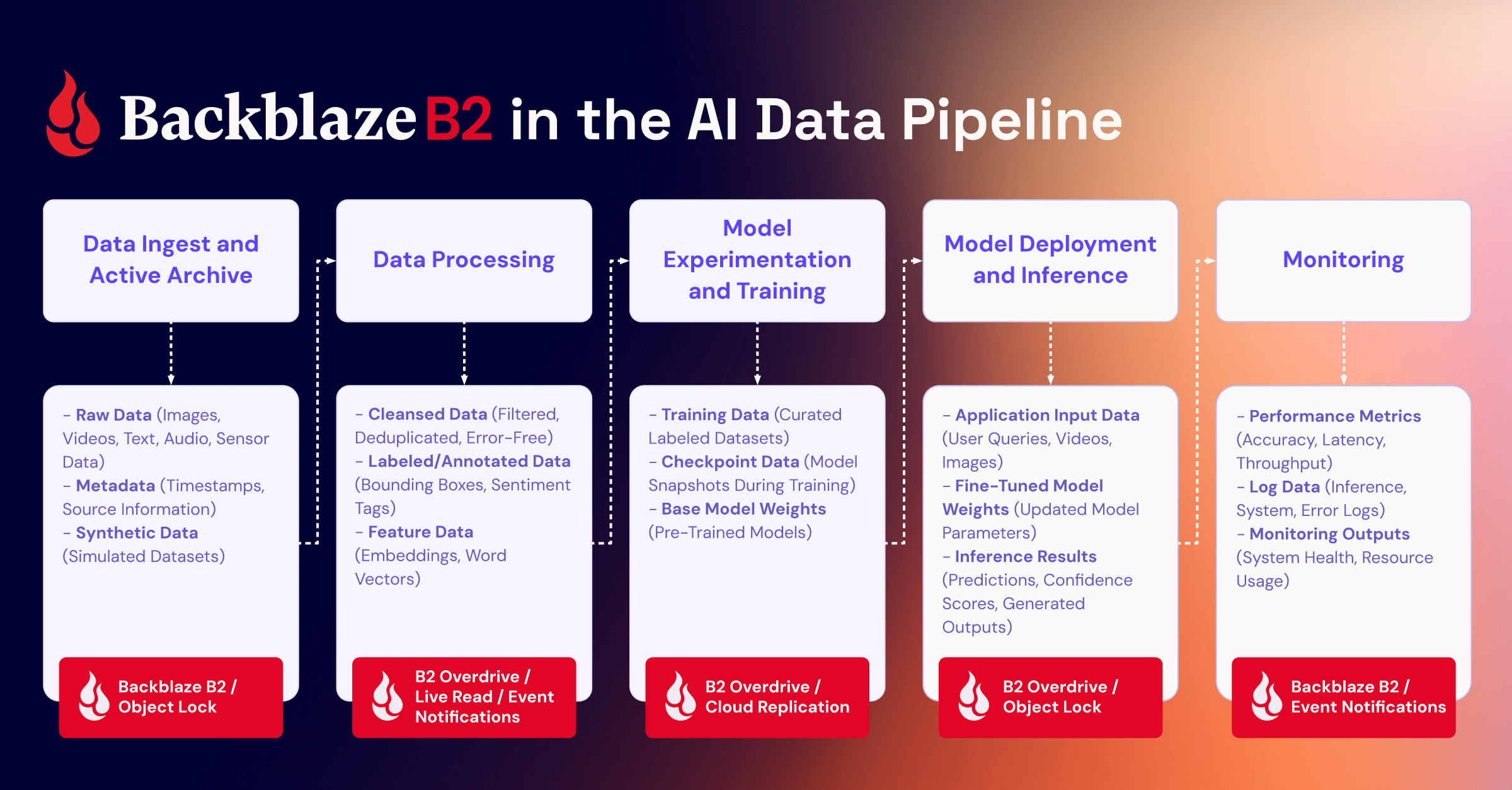
Immutability and encryption make that proof simple and reliable. With Backblaze B2, you gain a clear, verifiable foundation for protecting your training data with the same rigor you apply to your most critical assets. Learn more about where Backblaze B2 sits in the AI data pipeline, or talk to our cloud storage experts.
The post Your Training Data Is Your Most Valuable IP appeared first on Backblaze Blog | Cloud Storage & Cloud Backup
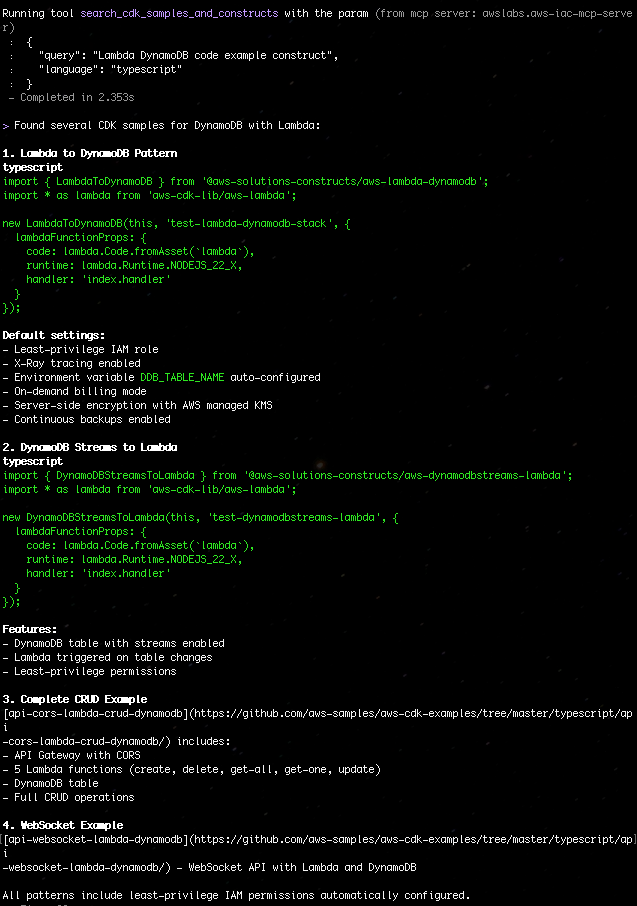
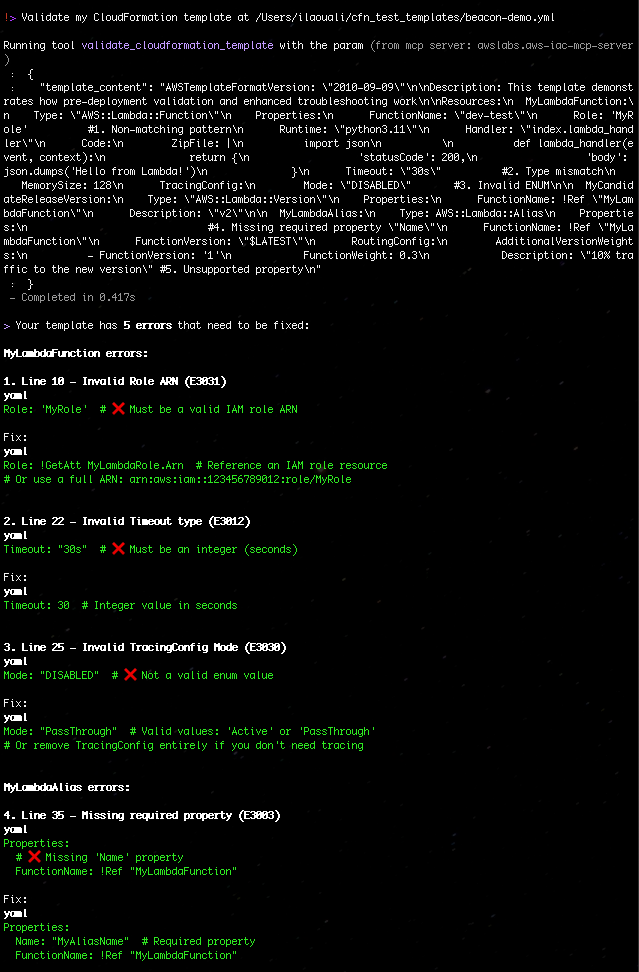
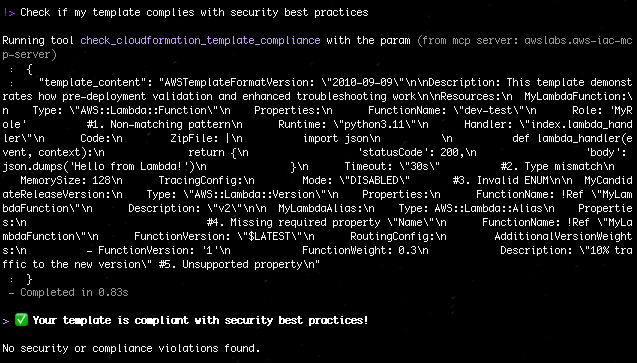














 Aaron Sempf is Next Gen Tech Lead for the AWS Partner Organization in Asia-Pacific and Japan. With over 20 years in distributed system engineering design and development, he focuses on solving for large scale complex integration and event driven systems. In his spare time, he can be found coding prototypes for autonomous robots, IoT devices, distributed solutions, and designing agentic architecture patterns for generative AI assisted business automation.
Aaron Sempf is Next Gen Tech Lead for the AWS Partner Organization in Asia-Pacific and Japan. With over 20 years in distributed system engineering design and development, he focuses on solving for large scale complex integration and event driven systems. In his spare time, he can be found coding prototypes for autonomous robots, IoT devices, distributed solutions, and designing agentic architecture patterns for generative AI assisted business automation. Joshua Toth is a Senior Prototyping Engineer with over a decade of experience in software engineering and distributed systems. He specializes in solving complex business challenges through technical prototypes, demonstrating the art of the possible. With deep expertise in proof of concept development, he focuses on bridging the gap between emerging technologies and practical business applications. In his spare time, he can be found developing next-generation interactive demonstrations and exploring cutting-edge technological innovations.
Joshua Toth is a Senior Prototyping Engineer with over a decade of experience in software engineering and distributed systems. He specializes in solving complex business challenges through technical prototypes, demonstrating the art of the possible. With deep expertise in proof of concept development, he focuses on bridging the gap between emerging technologies and practical business applications. In his spare time, he can be found developing next-generation interactive demonstrations and exploring cutting-edge technological innovations.