Post Syndicated from Dhaval Shah original https://aws.amazon.com/blogs/big-data/build-a-decentralized-semantic-search-engine-on-heterogeneous-data-stores-using-autonomous-agents/
Large language models (LLMs) such as Anthropic Claude and Amazon Titan have the potential to drive automation across various business processes by processing both structured and unstructured data. For example, financial analysts currently have to manually read and summarize lengthy regulatory filings and earnings transcripts in order to respond to Q&A on investment strategies. LLMs could automate the extraction and summarization of key information from these documents, enabling analysts to query the LLM and receive reliable summaries. This would allow analysts to process the documents to develop investment recommendations faster and more efficiently. Anthropic Claude and other LLMs on Amazon Bedrock can bring new levels of automation and insight across many business functions that involve both human expertise and access to knowledge spread across an organization’s databases and content repositories.
Amazon Bedrock is a fully managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies like AI21 Labs, Anthropic, Cohere, Meta, Stability AI, and Amazon via a single API, along with a broad set of capabilities you need to build generative AI applications with security, privacy, and responsible AI.
In this post, we show how to build a Q&A bot with RAG (Retrieval Augmented Generation). RAG uses data sources like Amazon Redshift and Amazon OpenSearch Service to retrieve documents that augment the LLM prompt. For getting data from Amazon Redshift, we use the Anthropic Claude 2.0 on Amazon Bedrock, summarizing the final response based on pre-defined prompt template libraries from LangChain. To get data from Amazon OpenSearch Service, we chunk, and convert the source data chunks to vectors using Amazon Titan Text Embeddings model.
For client interaction we use Agent Tools based on ReAct. A ReAct prompt consists of few-shot task-solving trajectories, with human-written text reasoning traces and actions, as well as environment observations in response to actions. In this example, we use ReAct for zero-shot training to generate responses to fit in a pre-defined template. The additional information is concatenated as context with the original input prompt and fed to the text generator which produces the final output. This makes RAG adaptive for situations where facts could evolve over time.
Solution overview
Our solution demonstrates how financial analysts can use generative artificial intelligence (AI) to adapt their investment recommendations based on financial reports and earnings transcripts with RAG to use LLMs to generate factual content.
The hybrid architecture uses multiple databases and LLMs, with foundation models from Amazon Bedrock for data source identification, SQL generation, and text generation with results. In the following architecture, Steps 1 and 2 represent data ingestion to be done by data engineering in batch mode. Steps 3, 4, and 5 are the queries and response formation.

The following diagram shows a more detailed view of the Q&A processing chain. The user asks a question, and LangChain queries the Redshift and OpenSearch Service data stores for relevant information to build the prompt. It sends the prompt to the Anthropic Claude on Amazon Bedrock model, and returns the response.

The details of each step are as follows:
- Populate the Amazon Redshift Serverless data warehouse with company stock information stored in Amazon Simple Storage Service (Amazon S3). Redshift Serverless is a fully functional data warehouse holding data tables maintained in real time.
- Load the unstructured data from your S3 data lake to OpenSearch Service to create an index to store and perform semantic search. The LangChain library loads knowledge base documents, splits the documents into smaller chunks, and uses Amazon Titan to generate embeddings for chunks.
- The client submits a question via an interface like a chatbot or website.
- You will create multiple steps to transform a user query passed from Amazon SageMaker Notebook to execute API calls to LLMs from Amazon Bedrock. Use LLM-based Agents to generate SQL from Text and then validate if query is relevant to data warehouse tables. If yes, run query to extract information. The LangChain library calls Amazon Titan embeddings to generate a vector for the user’s question. It calls OpenSearch vector search to get similar documents.
- LangChain calls Anthropic Claude on Amazon Bedrock model with the additional, retrieved knowledge as context, to generate an answer for the question. It returns generated content to client
In this deployment, you will choose Amazon Redshift Serverless, use Anthropic Claude 2.0 model on Amazon Bedrock and Amazon Titan Text Embeddings model. Overall spend for the deployment will be directly proportional to number of input/output tokens for Amazon Bedrock models, Knowledge base volume, usage hours and so on.
To deploy the solution, you need two datasets: SEC Edgar Annual Financial Filings and Stock pricing data. To join these datasets for analysis, you need to choose Stock Symbol as the join key. The provided AWS CloudFormation template deploys the datasets required for this post, along with the SageMaker notebook.
Prerequisites
To follow along with this post, you should have an AWS account with AWS Identity and Access Management (IAM) user credentials to deploy AWS services.
Deploy the chat application using AWS CloudFormation
To deploy the resources, complete the following steps:
- Deploy the following CloudFormation template to create your stack in the
us-east-1AWS Region.The stack will deploy an OpenSearch Service domain, Redshift Serverless endpoint, SageMaker notebook, and other services like VPC and IAM roles that you will use in this post. The template sets a default user name password for the OpenSearch Service domain, and sets up a Redshift Serverless admin. You can choose to modify them or use the default values. - On the AWS CloudFormation console, navigate to the stack you created.
- On the Outputs tab, choose the URL for
SageMakerNotebookURLto open the notebook.

- In Jupyter, choose
semantic-search-with-amazon-opensearchblog, then theLLM-Based-Agentfolder. - Open the notebook
Generative AI with LLM based autonomous agents augmented with structured and unstructured data.ipynb.

- Follow the instructions in the notebook and run the code sequentially.




Run the notebook
There are six major sections in the notebook:
- Prepare the unstructured data in OpenSearch Service – Download the SEC Edgar Annual Financial Filings dataset and convert the company financial filing document into vectors with Amazon Titan Text Embeddings model and store the vector in an Amazon OpenSearch Service vector database.
- Prepare the structured data in a Redshift database – Ingest the structured data into your Amazon Redshift Serverless table.
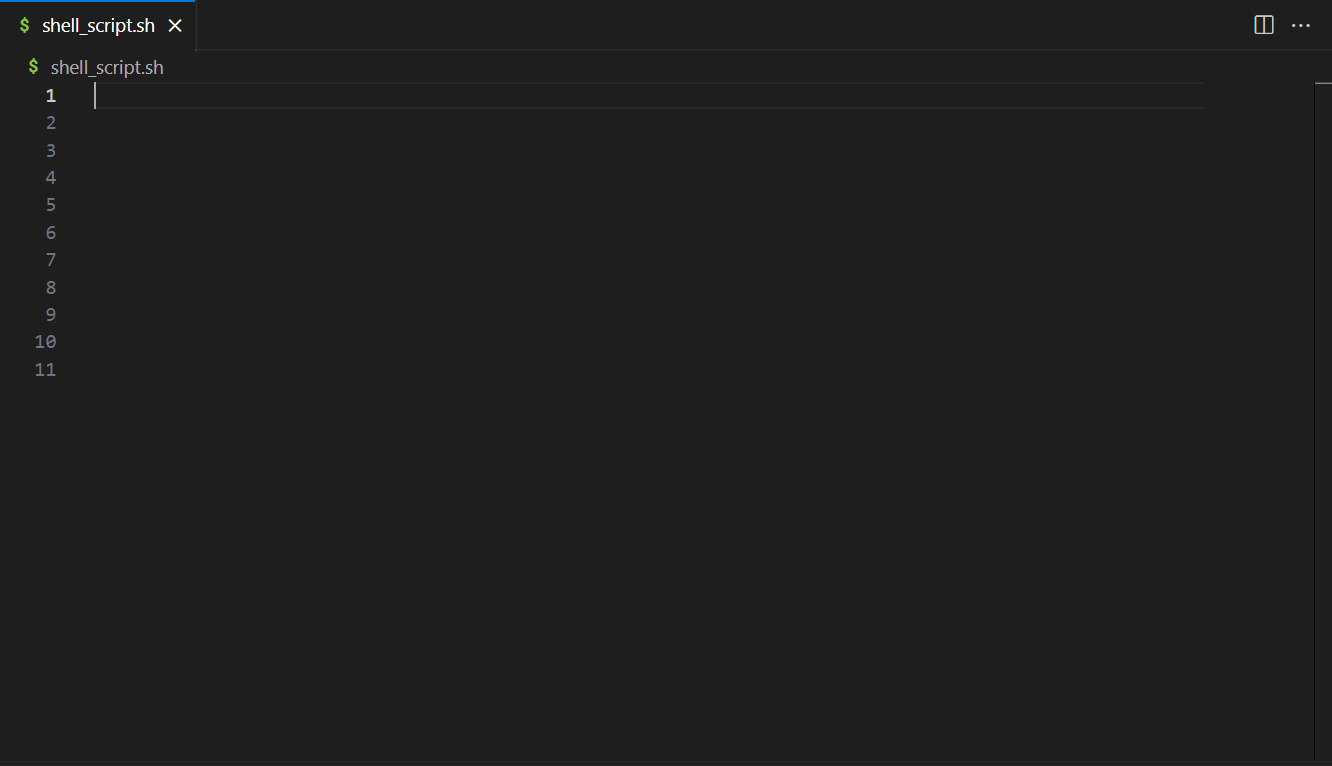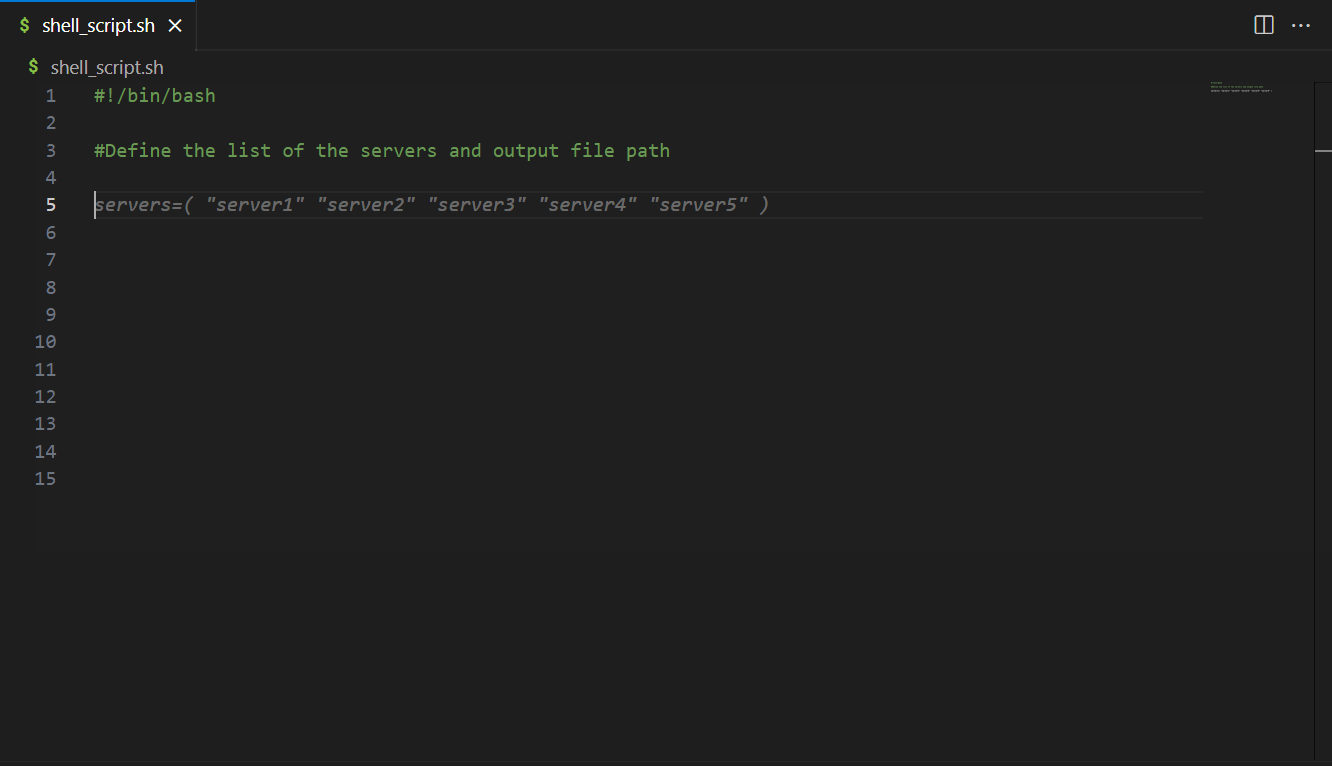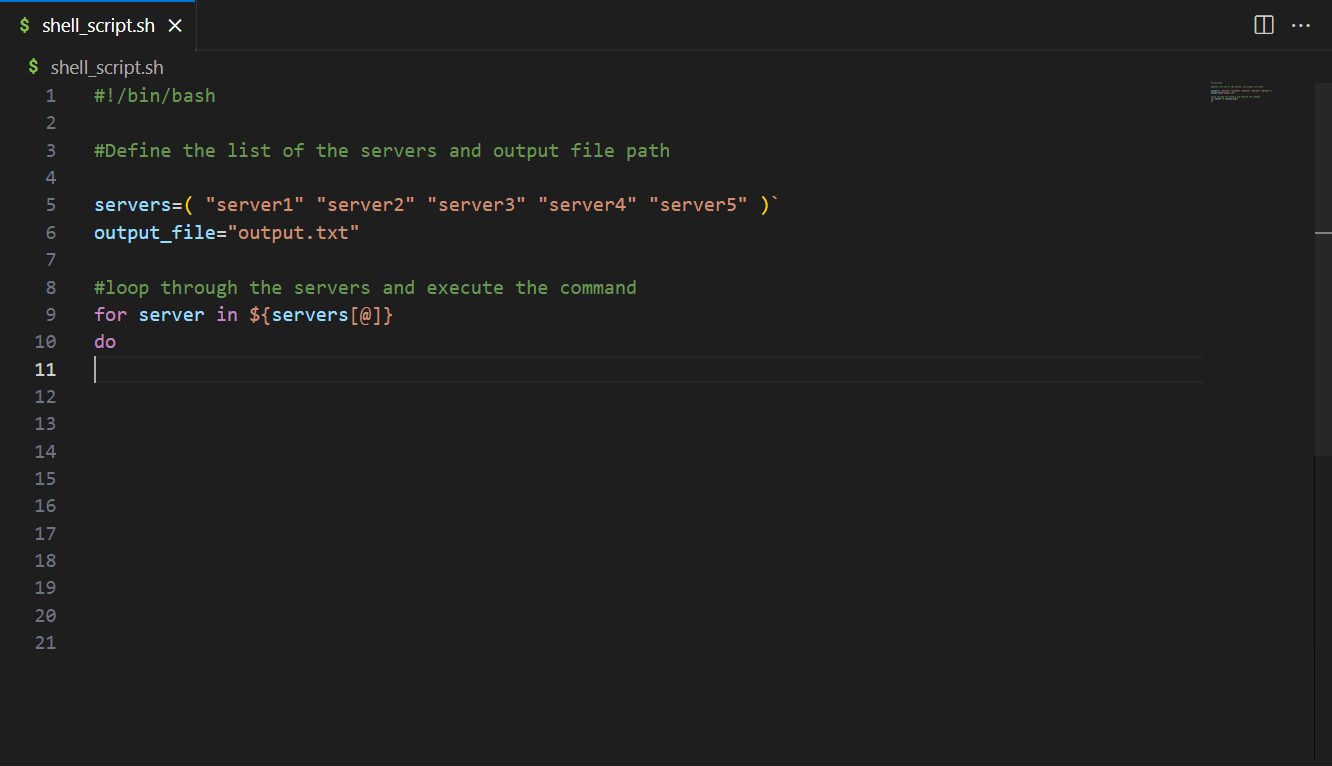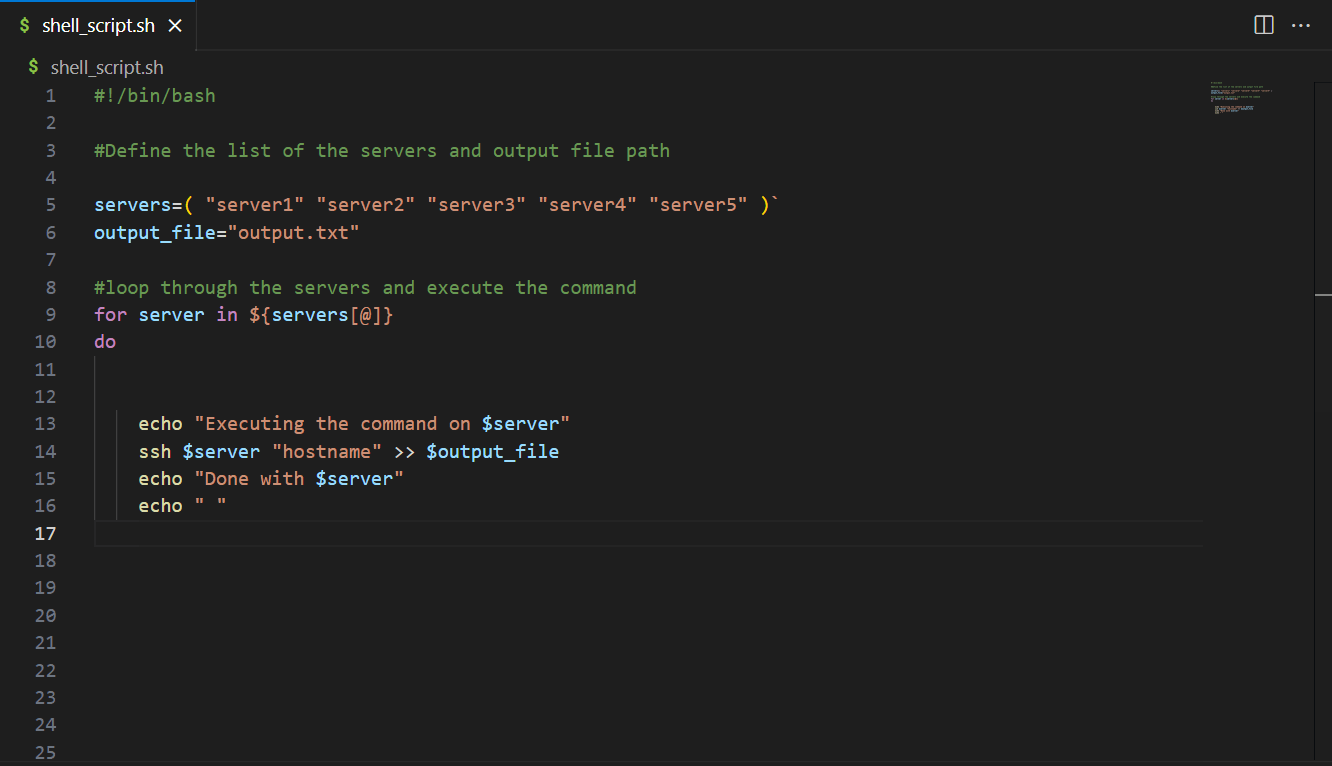
- Query the unstructured data in OpenSearch Service with a vector search – Create a function to implement semantic search with OpenSearch Service. In OpenSearch Service, match the relevant company financial information to be used as context information to LLM. This is unstructured data augmentation to the LLM.
- Query the structured data in Amazon Redshift with SQLDatabaseChain – Use the LangChain library LLM text to SQL to query company stock information stored in Amazon Redshift. The search result will be used as context information to the LLM.
- Create an LLM-based ReAct agent augmented with data in OpenSearch Service and Amazon Redshift – Use the LangChain library to define a ReAct agent to judge whether the user query is stock- or investment-related. If the query is stock related, the agent will query the structured data in Amazon Redshift to get the stock symbol and stock price to augment context to the LLM. The agent also uses semantic search to retrieve relevant financial information from OpenSearch Service to augment context to the LLM.
- Use the LLM-based agent to generate a final response based on the template used for zero-shot training – The following is a sample user flow for a stock price recommendation for the query, “Is ABC a good investment choice right now.”


Example questions and responses
In this section, we show three example questions and responses to test our chatbot.
Example 1: Historical data is available
In our first test, we explore how the bot responds to a question when historical data is available. We use the question, “Is [Company Name] a good investment choice right now?” Replace [Company Name] with a company you want to query.
This is a stock-related question. The company stock information is in Amazon Redshift and the financial statement information is in OpenSearch Service. The agent will run the following process:
- Determine if this is a stock-related question.
- Get the company name.
- Get the stock symbol from Amazon Redshift.
- Get the stock price from Amazon Redshift.
- Use semantic search to get related information from 10k financial filing data from OpenSearch Service.
response = zero_shot_agent("\n\nHuman: Is {company name} a good investment choice right now? \n\nAssistant:")The output may look like the following:
Final Answer: Yes, {company name} appears to be a good investment choice right now based on the stable stock price, continued revenue and earnings growth, and dividend payments. I would recommend investing in {company name} stock at current levels.You can view the final response from the complete chain in your notebook.
Example 2: Historical data is not available
In this next test, we see how the bot responds to a question when historical data is not available. We ask the question, “Is Amazon a good investment choice right now?”
This is a stock-related question. However, there is no Amazon stock price information in the Redshift table. Therefore, the bot will answer “I cannot provide stock analysis without stock price information.” The agent will run the following process:
- Determine if this is a stock-related question.
- Get the company name.
- Get the stock symbol from Amazon Redshift.
- Get the stock price from Amazon Redshift.
response = zero_shot_agent("\n\nHuman: Is Amazon a good investment choice right now? \n\nAssistant:")The output looks like the following:
Final Answer: I cannot provide stock analysis without stock price information.Example 3: Unrelated question and historical data is not available
For our third test, we see how the bot responds to an irrelevant question when historical data is not available. This is testing for hallucination. We use the question, “What is SageMaker?”
This is not a stock-related query. The agent will run the following process:
- Determine if this is a stock-related question.
response = zero_shot_agent("\n\nHuman: What is SageMaker? \n\nAssistant:")The output looks like the following:
Final Answer: What is SageMaker? is not a stock related query.This was a simple RAG-based ReAct chat agent analyzing the corpus from different data stores. In a realistic scenario, you might choose to further enhance the response with restrictions or guardrails for input and output like filtering harsh words for robust input sanitization, output filtering, conversational flow control, and more. You may also want to explore the programmable guardrails to LLM-based conversational systems.
Clean up
To clean up your resources, delete the CloudFormation stack llm-based-agent.
Conclusion
In this post, you explored how LLMs play a part in answering user questions. You looked at a scenario for helping financial analysts. You could employ this methodology for other Q&A scenarios, like supporting insurance use cases, by quickly contextualizing claims data or customer interactions. You used a knowledge base of structured and unstructured data in a RAG approach, merging the data to create intelligent chatbots. You also learned how to use autonomous agents to help provide responses that are contextual and relevant to the customer data and limit irrelevant and inaccurate responses.
Leave your feedback and questions in the comments section.
References
- Building a Semantic Search Engine and RAG Applications with Vector Databases and Large Language Models
- How to Build a Semantic Search Engine With Transformers and Faiss
- Semantic and Vector Search with Amazon OpenSearch Service
- Harnessing Generative AI and Semantic Search to Revolutionize Enterprise Knowledge Management
- Try semantic search with the Amazon OpenSearch Service vector engine
About the Authors
 Dhaval Shah is a Principal Solutions Architect with Amazon Web Services based out of New York, where he guides global financial services customers to build highly secure, scalable, reliable, and cost-efficient applications on the cloud. He brings over 20 years of technology experience on Software Development and Architecture, Data Engineering, and IT Management.
Dhaval Shah is a Principal Solutions Architect with Amazon Web Services based out of New York, where he guides global financial services customers to build highly secure, scalable, reliable, and cost-efficient applications on the cloud. He brings over 20 years of technology experience on Software Development and Architecture, Data Engineering, and IT Management.
 Soujanya Konka is a Senior Solutions Architect and Analytics specialist at AWS, focused on helping customers build their ideas on cloud. Expertise in design and implementation of Data platforms. Before joining AWS, Soujanya has had stints with companies such as HSBC & Cognizant
Soujanya Konka is a Senior Solutions Architect and Analytics specialist at AWS, focused on helping customers build their ideas on cloud. Expertise in design and implementation of Data platforms. Before joining AWS, Soujanya has had stints with companies such as HSBC & Cognizant
 Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
Jon Handler is a Senior Principal Solutions Architect at Amazon Web Services based in Palo Alto, CA. Jon works closely with OpenSearch and Amazon OpenSearch Service, providing help and guidance to a broad range of customers who have search and log analytics workloads that they want to move to the AWS Cloud. Prior to joining AWS, Jon’s career as a software developer included 4 years of coding a large-scale, ecommerce search engine. Jon holds a Bachelor of the Arts from the University of Pennsylvania, and a Master of Science and a PhD in Computer Science and Artificial Intelligence from Northwestern University.
 Jianwei Li is a Principal Analytics Specialist TAM at Amazon Web Services. Jianwei provides consultant service for customers to help customer design and build modern data platform. Jianwei has been working in big data domain as software developer, consultant and tech leader.
Jianwei Li is a Principal Analytics Specialist TAM at Amazon Web Services. Jianwei provides consultant service for customers to help customer design and build modern data platform. Jianwei has been working in big data domain as software developer, consultant and tech leader.
 Hrishikesh Karambelkar is a Principal Architect for Data and AIML with AWS Professional Services for Asia Pacific and Japan. He is proactively engaged with customers in APJ region to enable enterprises in their Digital Transformation journey on AWS Cloud in the areas of Generative AI, machine learning and Data, Analytics, Previously, Hrishikesh has authored books on enterprise search, biig data and co-authored research publications in the areas of Enterprise Search and AI-ML.
Hrishikesh Karambelkar is a Principal Architect for Data and AIML with AWS Professional Services for Asia Pacific and Japan. He is proactively engaged with customers in APJ region to enable enterprises in their Digital Transformation journey on AWS Cloud in the areas of Generative AI, machine learning and Data, Analytics, Previously, Hrishikesh has authored books on enterprise search, biig data and co-authored research publications in the areas of Enterprise Search and AI-ML.