Post Syndicated from David Ernst original https://aws.amazon.com/blogs/devops/exploring-telemetry-events-in-amazon-q-developer/
As organizations increasingly adopt Amazon Q Developer, understanding how developers use it is essential. Diving into specific telemetry events and user-level data clarifies how users interact with Amazon Q Developer, offering insights into feature usage and developer behaviors. This granular view, accessible through logs, is vital for identifying trends, optimizing performance, and enhancing the overall developer experience. This blog is intended to give visibility to key telemetry events logged by Amazon Q Developer and how to explore this data to gain insights.
To help you get started, the following sections will walk through several practical examples that showcase how to extract meaningful insights from AWS CloudTrail. By reviewing the logs, organizations can track usage patterns, identify top users, and empower them to train and mentor other developers, ultimately fostering broader adoption and engagement across teams.
Although the examples here focus on Amazon Athena for querying logs, the methods can be adapted to integrate with other tools like Splunk or Datadog for further analysis. Through this exploration, readers will learn how to query the log data to understand better how Amazon Q Developer is used within your organization.
Solution Overview
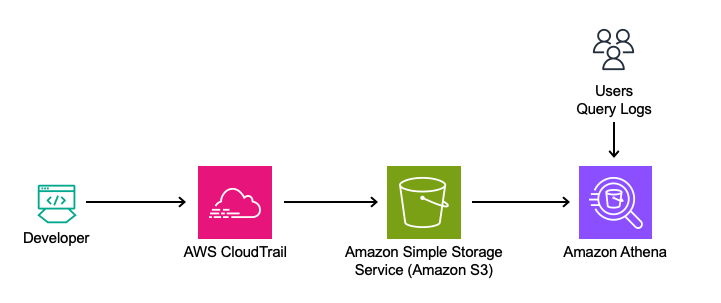
This solution leverages Amazon Q Developer’s logs from the Integrated Development Environment (IDE) and terminal, captured in AWS CloudTrail. The logs will be queried directly using Amazon Athena from Amazon Simple Storage Service (Amazon S3) to analyze feature usage, such as in-line code suggestions, chat interactions, and security scanning events.
Analyzing Telemetry Events in Amazon Q Developer
Amazon Athena is used to query the CloudTrail logs directly to analyze this data. By utilizing Athena, queries can be run on existing CloudTrail records, making it simple to extract insights from the data in its current format.
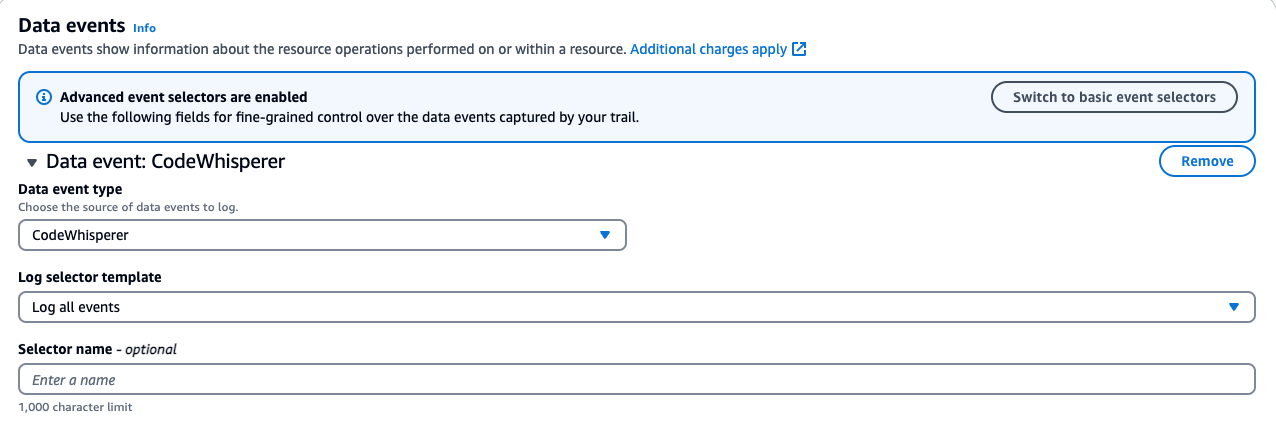
Ensuring CloudTrail is set up to log the data events.
- Navigate to the AWS CloudTrail Console.
- Edit an Existing Trail:
- If you have a trail, verify it is configured to log data events for Amazon CodeWhisperer.
- Note: As of 4/30/24, CodeWhisperer has been renamed to Amazon Q Developer. All the functionality previously provided by CodeWhisperer is now part of Amazon Q Developer. However, for consistency, the original API names have been retained.
- Click on your existing trail in CloudTrail. Find the Data Events section and click edit.
- For CodeWhisperer:
- Data event type: CodeWhisperer
- Log selector template: Log all events
- For CodeWhisperer:
- Save your changes.
- Note your “Trail log location.” This S3 bucket will be used in our Athena setup.
If you don’t have an existing trail, follow the instructions in the AWS CloudTrail User Guide to set up a new trail.
Below is a screenshot of the data events addition:
Steps to Create an Athena Table from CloudTrail Logs: This step aims to turn CloudTrail events into a queryable Athena table.
1. Navigate to the AWS Management Console > Athena > Editor.
2. Click on the plus to create a query tab.
3. Run the following query to create a database and table. Note to update the location to your S3 bucket.
-- Step 1: Create a new database (if it doesn't exist)
CREATE DATABASE IF NOT EXISTS amazon_q_metrics;
-- Step 2: Create the external table explicitly within the new database
CREATE EXTERNAL TABLE amazon_q_metrics.cloudtrail_logs (
userIdentity STRUCT<
accountId: STRING,
onBehalfOf: STRUCT<
userId: STRING,
identityStoreArn: STRING
>
>,
eventTime STRING,
eventSource STRING,
eventName STRING,
requestParameters STRING,
requestId STRING,
eventId STRING,
resources ARRAY<STRUCT<
arn: STRING,
accountId: STRING,
type: STRING
>>,
recipientAccountId STRING
)
ROW FORMAT SERDE 'org.apache.hive.hcatalog.data.JsonSerDe'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://{Insert Bucket Name from CloudTrail}/'
TBLPROPERTIES ('classification'='cloudtrail');
4. Click Run
5. Run a quick query to view the data.
SELECT
eventTime,
userIdentity.onBehalfOf.userId AS user_id,
eventName,
requestParameters
FROM
amazon_q_metrics.cloudtrail_logs AS logs
WHERE
eventName = 'SendTelemetryEvent'
LIMIT 10;In this section, the significance of the telemetry events captured in the requestParameters field will be explained. The query begins by displaying key fields and their data, offering insights into how users interact with various features of Amazon Q Developer.
Query Breakdown:
- eventTime: This field captures the time the event was recorded, providing insights into when specific user interactions took place.
- userIdentity.onBehalfOf.userId: This extracts the
userIdof the user. This is critical for attributing interactions to the correct user, which will be covered in more detail later in the blog. - eventName: The query is filtered on
SendTelemetryEvent. Telemetry events are triggered when the user interacts with particular features or when a developer uses the service. - requestParameters: The
requestParametersfield is crucial because it holds the details of the telemetry events. This field contains a rich set of information depending on the type of interaction and feature the developer uses, which programming languages are used, completion types, or code modifications.
In the context of the SendTelemetryEvent, various telemetry events are captured in the requestParameters field of CloudTrail logs. These events provide insights into user interactions, overall usage, and the effectiveness of Amazon Q Developer’s suggestions. Here are the key telemetry events along with their descriptions:
- UserTriggerDecisionEvent
- Description: This event is triggered when a user interacts with a suggestion made by Amazon Q Developer. It captures whether the suggestion was accepted or rejected, along with relevant metadata.
- Key Fields:
- completionType: Whether the completion was a block or a line.
- suggestionState: Whether the user accepted, rejected, or discarded the suggestion.
- programmingLanguage: The programming language associated with the suggestion.
- generatedLine: The number of lines generated by the suggestion.
- CodeScanEvent
- Description: This event is logged when a code scan is performed. It helps track the scope and result of the scan, providing insights into security and code quality checks.
- Key Fields:
- codeAnalysisScope: Whether the scan was performed at the file level or the project level.
- programmingLanguage: The language being scanned.
- CodeScanRemediationsEvent
- Description: This event captures user interactions with Amazon Q Developer’s remediation suggestions, such as applying fixes or viewing issue details.
- Key Fields:
- CodeScanRemediationsEventType: The type of remediation action taken (e.g., viewing details or applying a fix).
- includesFix: A boolean indicating whether the user applied a fix.
- ChatAddMessageEvent
- Description: This event is triggered when a new message is added to an ongoing chat conversation. It captures the user’s intent which refers to the purpose or goal the user is trying to achieve with the chat message. The intent can include various actions, such as suggesting alternate implementations of the code, applying common best practices, improving the quality or performance of the code.
- Key Fields:
- conversationId: The unique identifier for the conversation.
- messageId: The unique identifier for the chat message.
- userIntent: The user’s intent, such as improving code or explaining code.
- programmingLanguage: The language related to the chat message.
- ChatInteractWithMessageEvent
- Description: This event captures when users interact with chat messages, such as copying code snippets, clicking links, or hovering over references.
- Key Fields:
- interactionType: The type of interaction (e.g., copy, hover, click).
- interactionTarget: The target of the interaction (e.g., a code snippet or a link).
- acceptedCharacterCount: The number of characters from the message that were accepted.
- acceptedSnippetHasReference: A boolean indicating if the accepted snippet included a reference.
- TerminalUserInteractionEvent
- Description: This event logs user interactions with terminal commands or completions in the terminal environment.
- Key Fields:
- terminalUserInteractionEventType: The type of interaction (e.g., terminal translation or code completion).
- isCompletionAccepted: A boolean indicating whether the completion was accepted by the user.
- terminal: The terminal environment in which the interaction occurred.
- shell: The shell used for the interaction (e.g., Bash, Zsh).
For a full exploration of all event types and their detailed fields, you can refer to the official schema reference for Amazon Q Developer.
Telemetry events are key to understanding how users engage with Amazon Q Developer. They track interactions such as code completion, security scans, and chat-based suggestions. Analyzing the data in the requestParameters field helps reveal usage patterns and behaviors that offer valuable insights.
By exploring events such as UserTriggerDecisionEvent, ChatAddMessageEvent, TerminalUserInteractionEvent, and others in the schema, organizations can assess the effectiveness of Amazon Q Developer and identify areas for improvement.
Example Queries for Analyzing Developer Engagement
To gain deeper insights into how developers interact with Amazon Q Developer, the following queries can help analyze key telemetry data from CloudTrail logs. These queries track in-line code suggestions, chat interactions, and code-scanning activities. By running these queries, you can uncover valuable metrics such as the frequency of accepted suggestions, the types of chat interactions, and the programming languages most frequently scanned. This analysis helps paint a clear picture of developer engagement and usage patterns, guiding efforts to enhance productivity.
These four examples only cover a sample set of the available telemetry events, but they serve as a starting point for further exploration of Amazon Q Developer’s capabilities.
Query 1: Analyzing Accepted In-Line Code Suggestions
SELECT
eventTime,
userIdentity.onBehalfOf.userId AS user_id,
eventName,
json_extract_scalar(requestParameters, '$.telemetryEvent.userTriggerDecisionEvent.suggestionState') AS suggestionState,
json_extract_scalar(requestParameters, '$.telemetryEvent.userTriggerDecisionEvent.completionType') AS completionType
FROM
amazon_q_metrics.cloudtrail_logs
WHERE
eventName = 'SendTelemetryEvent'
AND json_extract(requestParameters, '$.telemetryEvent.userTriggerDecisionEvent') IS NOT NULL
AND json_extract_scalar(requestParameters, '$.telemetryEvent.userTriggerDecisionEvent.suggestionState') = 'ACCEPT';Use Case:This use case focuses on how developers interact with in-line code suggestions by analyzing accepted snippets. It helps identify which users are accepting suggestions, the type of snippets being accepted (blocks or lines), and the programming languages involved. Understanding these patterns can reveal how well Amazon Q Developer aligns with the developers’ expectations.
Query Explanation: The query retrieves the event time, user ID, event name, suggestion state (filtered to show only ACCEPT), and completion type. TotalGeneratedLinesBlockAccept and totalGeneratedLinesLineAccept or discarded suggestions are not included, but this gives an idea of the developers using the service for in-line code suggestions and the lines or blocks they have accepted. Additionally, the programming language field can be extracted to see which languages are used during these interactions.
Query 2: Analyzing Chat Interactions
SELECT
userIdentity.onBehalfOf.userId AS userId,
json_extract_scalar(requestParameters, '$.telemetryEvent.chatInteractWithMessageEvent.interactionType') AS interactionType,
COUNT(*) AS eventCount
FROM
amazon_q_metrics.cloudtrail_logs
WHERE
eventName = 'SendTelemetryEvent'
AND json_extract(requestParameters, '$.telemetryEvent.chatInteractWithMessageEvent') IS NOT NULL
GROUP BY
userIdentity.onBehalfOf.userId,
json_extract_scalar(requestParameters, '$.telemetryEvent.chatInteractWithMessageEvent.interactionType')
ORDER BY
eventCount DESC;Use Case: This use case looks at how developers use chat options like upvoting, downvoting, and copying code snippets. Understanding the chat usage patterns shows which interactions are most used and how developers engage with Amazon Q Developer chat. As an organization, this insight can help support other developers in successfully leveraging this feature.
Query Explanation: The query provides insights into chat interactions within Amazon Q Developer by retrieving user IDs, interaction types, and event counts. This query aggregates data based on the interactionType field within chatInteractWithMessageEvent, showcasing various user actions such as UPVOTE, DOWNVOTE, INSERT_AT_CURSOR, COPY_SNIPPET, COPY, CLICK_LINK, CLICK_BODY_LINK, CLICK_FOLLOW_UP, and HOVER_REFERENCE.
This analysis highlights how users engage with the chat feature and the interactions, offering a view of interaction patterns. By focusing on the interactionType field, you can better understand how developers interact with the chat feature of Amazon Q Developer.
Query 3: Analyzing Code Scanning Jobs Across Programming Languages
SELECT
userIdentity.onBehalfOf.userId AS userId,
json_extract_scalar(requestParameters, '$.telemetryEvent.codeScanEvent.programmingLanguage.languageName') AS programmingLanguage,
COUNT(json_extract_scalar(requestParameters, '$.telemetryEvent.codeScanEvent.codeScanJobId')) AS jobCount
FROM
amazon_q_metrics.cloudtrail_logs
WHERE
eventName = 'SendTelemetryEvent'
AND json_extract(requestParameters, '$.telemetryEvent.codeScanEvent') IS NOT NULL
GROUP BY
userIdentity.onBehalfOf.userId,
json_extract_scalar(requestParameters, '$.telemetryEvent.codeScanEvent.programmingLanguage.languageName')
ORDER BY
jobCount DESC;Use Case: Amazon Q Developer includes security scanning, and this section helps determine how the security scanning feature is being used across different users and programming languages within the organization. Understanding these trends provides valuable insights into which users actively perform security scans and the specific languages targeted for these scans.
Query Explanation: The query provides insights into the distribution of code scanning jobs across different programming languages in Amazon Q Developer. It retrieves user IDs and the count of code-scanning jobs by programming language. This analysis focuses on the CodeScanEvent, aggregating data to show the total number of jobs executed per language.
By summing up the number of code scanning jobs per programming language, this query helps to understand which languages are most frequently analyzed. It provides a view of how users are leveraging the code-scanning feature. This can be useful for identifying trends in language usage and optimizing code-scanning practices.
Query 4: Analyzing User Activity across features.
SELECT
userIdentity.onBehalfOf.userId AS user_id,
COUNT(DISTINCT CASE
WHEN json_extract(requestParameters, '$.telemetryEvent.userTriggerDecisionEvent') IS NOT NULL
THEN eventId END) AS inline_suggestions_count,
COUNT(DISTINCT CASE
WHEN json_extract(requestParameters, '$.telemetryEvent.chatInteractWithMessageEvent') IS NOT NULL
THEN eventId END) AS chat_interactions_count,
COUNT(DISTINCT CASE
WHEN json_extract(requestParameters, '$.telemetryEvent.codeScanEvent') IS NOT NULL
THEN eventId END) AS security_scans_count,
COUNT(DISTINCT CASE
WHEN json_extract(requestParameters, '$.telemetryEvent.terminalUserInteractionEvent') IS NOT NULL
THEN eventId END) AS terminal_interactions_count
FROM
amazon_q_metrics.cloudtrail_logs
WHERE
eventName = 'SendTelemetryEvent'
GROUP BY
userIdentity.onBehalfOf.userIdUse Case:This use case looks at how developers use Amazon Q Developer across different features: in-line code suggestions, chat interactions, security scans, and terminal interactions. By tracking usage, organizations can see overall engagement and identify areas where developers may need more support or training. This helps optimize the use of Amazon Q Developer and helps teams get the most out of the tool.
Query Explanation: Let’s take the other events from the prior queries and additional events to get more detail overall and tie it all together. This expanded query provides a comprehensive view of user activity within Amazon Q Developer by tracking the number of in-line code suggestions, chat interactions, security scans, and terminal interactions performed by each user. By analyzing these events, organizations can gain a better understanding of how developers are using these key features.
By summing up the interactions for each feature, this query helps identify which users are most active in each category, offering insights into usage patterns and areas where additional training or support may be needed.
Enhancing Metrics with Display Names and Usernames
The previous queries had userid as a field; however, many customers would prefer to see a user alias (such as username or display name). The following section illustrates enhancing these metrics by augmenting user IDs with display names and usernames from the AWS IAM Identity Center. This will provide more human-readable user names.
In this example, the export is run locally to enhance user metrics with IAM Identity Center for simplicity. This method works well for demonstrating how to access and work with the data, but it provides a static snapshot of the users at the time of export. In a production environment, an automated solution would be preferable to capture newly added users continuously. For the purposes of this blog, this straightforward approach is used to focus on data access.
To proceed, install Python 3.8+ and Boto3, and configure AWS credentials via the CLI. Then, run the following Python script locally to export the data:
import boto3, csv
# replace this with the region of your IDC instance
RegionName='us-east-1'
# client creation
idstoreclient = boto3.client('identitystore', RegionName)
ssoadminclient = boto3.client('sso-admin', RegionName)
Instances= (ssoadminclient.list_instances()).get('Instances')
InstanceARN=Instances[0].get('InstanceArn')
IdentityStoreId=Instances[0].get('IdentityStoreId')
# query
UserDigestList = []
ListUserResponse = idstoreclient.list_users(IdentityStoreId=IdentityStoreId)
UserDigestList.extend([[user['DisplayName'], user['UserName'], user['UserId']] for user in ListUserResponse['Users']])
NextToken = None
if 'NextToken' in ListUserResponse.keys(): NextToken = ListUserResponse['NextToken']
while NextToken is not None:
ListUserResponse = idstoreclient.list_users(IdentityStoreId=IdentityStoreId, NextToken=NextToken)
UserDigestList.extend([[user['DisplayName'], user['UserName'], user['UserId']] for user in ListUserResponse['Users']])
if 'NextToken' in ListUserResponse.keys(): NextToken = ListUserResponse['NextToken']
else: NextToken = None
# write the query results to IDCUserInfo.csv
with open('IDCUserInfo.csv', 'w') as CSVFile:
CSVWriter = csv.writer(CSVFile, quoting=csv.QUOTE_ALL)
HeaderRow = ['DisplayName', 'UserName', 'UserId']
CSVWriter.writerow(HeaderRow)
for UserRow in UserDigestList:
CSVWriter.writerow(UserRow)This script will query the IAM Identity Center for all users and write the results to a CSV file, including DisplayName, UserName, and UserId. After generating the CSV file, upload it to an S3 bucket. Please make note of this S3 location.
Steps to Create an Athena Table from the above CSV output: Create a table in Athena to join the existing table with the user details.
1. Navigate to the AWS Management Console > Athena > Editor.
2. Click on the plus to create a query tab.
3. Run the following query to create our table. Note to update the location to your S3 bucket.
CREATE EXTERNAL TABLE amazon_q_metrics.user_data (
DisplayName STRING,
UserName STRING,
UserId STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
'separatorChar' = ',',
'quoteChar' = '"'
)
STORED AS TEXTFILE
LOCATION 's3://{Update to your S3 object location}/' -- Path containing CSV file
TBLPROPERTIES ('skip.header.line.count'='1');
4. Click Run
5. Now, let’s run a quick query to verify the data in the new table.
SELECT * FROM amazon_q_metrics.user_data limit 10; The first query creates an external table in Athena from user data stored in a CSV file in S3. The user_data table has three fields: DisplayName, UserName, and UserId. To specify the correct parsing of the CSV, separatorChar is specified as a comma and quoteChar as a double quote. Additionally, the TBLPROPERTIES
(‘skip.header.line.count’=’1’) flag skips the header row in the CSV file, ensuring that column names aren’t treated as data.
The user_data table holds key details: DisplayName (full name), UserName (username), and UserId (unique identifier). This table will be joined with the cloudtrail_q_metrics table using the userId field from the onBehalfOf struct, enriching the interaction logs with human-readable user names and display names instead of user IDs.
In the previous analysis of in-line code suggestions, the focus was on retrieving key metrics related to user interactions with Amazon Q Developer. The query below follows a similar structure but now includes a join with the user_data table to enrich insights with additional user details such as DisplayName and Username.
To include a join with the user_data table in the query, it is necessary to define a shared key between the cloudtrail_logs_amazon_q and user_data tables. For this example, user_id will be used.
SELECT
logs.eventTime,
user_data.displayname, -- Additional field from user_data table
user_data.username, -- Additional field from user_data table
json_extract_scalar(logs.requestParameters, '$.telemetryEvent.userTriggerDecisionEvent.suggestionState') AS suggestionState,
json_extract_scalar(logs.requestParameters, '$.telemetryEvent.userTriggerDecisionEvent.completionType') AS completionType
FROM
amazon_q_metrics.cloudtrail_logs AS logs -- Specified database for cloudtrail_logs
JOIN
amazon_q_metrics.user_data -- Specified database for user_data
ON
logs.userIdentity.onBehalfOf.userId = user_data.userid
WHERE
logs.eventName = 'SendTelemetryEvent'
AND json_extract_scalar(logs.requestParameters, '$.telemetryEvent.userTriggerDecisionEvent.suggestionState') = 'ACCEPT';
This approach allows for a deeper analysis by integrating user-specific information with the telemetry data, helping you better understand how different user roles interact with the in-line suggestions and other features of Amazon Q Developer.
Cleanup
If you have been following along with this workflow, it is important to clean up the resources to avoid unnecessary charges. You can perform the cleanup by running the following query in the Amazon Athena console:
-- Step 1: Drop the tables
DROP TABLE IF EXISTS amazon_q_metrics.cloudtrail_logs;
DROP TABLE IF EXISTS amazon_q_metrics.user_data;
-- Step 2: Drop the database after the tables are removed
DROP DATABASE IF EXISTS amazon_q_metrics CASCADE;This query removes both the cloudtrail_logs and user_data tables, followed by the amazon_q_metrics database.
Remove the S3 objects used to store the CloudTrail logs and user data by navigating to the S3 console, selecting the relevant buckets or objects, and choosing “Delete.”
If a new CloudTrail trail was created, consider deleting it to stop further logging. For instructions, see Deleting a Trail. If an existing trail was used, remove the CodeWhisperer data events to prevent continued logging of those events.
Conclusion
By tapping into Amazon Q Developer’s logging capabilities, organizations can unlock detailed insights that drive better decision-making and boost developer productivity. The ability to analyze user-level interactions provides a deeper understanding of how the service is used.
Now that you have these insights, the next step is leveraging them to drive improvements. For example, organizations can use this data to identify opportunities for Proof of Concepts (PoCs) and pilot programs that further demonstrate the value of Amazon Q Developer. By focusing on areas where engagement is high, you can support the most engaged developers as champions to advocate for the tool across the organization, driving broader adoption.
The true potential of these insights lies in the “art of the possible.” With the data provided, it is up to you to explore how to query or visualize it further. Whether you’re examining metrics for in-line code suggestions, interactions, or security scanning, this foundational analysis is just the beginning.
As Amazon Q Developer continues to evolve, staying updated with emerging telemetry events is crucial for maintaining visibility into the available metrics. You can do this by regularly visiting the official Amazon Q Developer documentation and the Amazon Q Developer’s Changelog to stay up-to-date latest information and insights.
About the authors: