Post Syndicated from Jeronimo De Leon original https://www.backblaze.com/blog/building-multimodal-ai-data-infrastructure-with-pixeltable/

We’re approaching a fascinating inflection point in AI development. Research from Epoch AI indicates that high-quality text data will be fully exhausted by 2026 to 2028. As recently as January, OpenAI co-founder Ilya Sutskever said at a conference that all the useful data online had already been used to train models. Over 35% of top websites now block AI scrapers. OpenAI is cutting deals with publishers like The Financial Times because freely available training data is running out.
So what comes next? Multimodal data: video, images, audio, sensor readings. Data that captures how the physical world actually operates, not just how we describe it in text.
Nvidia CEO Jensen Huang highlighted this shift when discussing Tesla’s AI advantage. He noted that the company has a “phenomenal position” because Tesla is collecting massive amounts of real-world data through its AI-enabled factories and autonomous vehicles.”
This real-world data, what some call “world data,” is multimodal at its core. It includes video from cameras capturing spatial relationships and motion, sensor telemetry recording physical interactions, images showing object states, and audio capturing environmental context. Video is particularly valuable because it captures temporal dynamics, depth perception, and how objects interact over time, insights that static text or images alone cannot provide.
Here’s the insight most organizations miss: you’re already generating this data.
Your organization is already producing multimodal data
Every single day, your organization produces massive amounts of multimodal data, including:
- Zoom calls with video, audio, and screen shares
- Security camera footage
- Customer service interactions combining chat logs, voice recordings, website screen recordings and product images
- Manufacturing sensors producing telemetry alongside quality inspection photos
- Marketing teams creating videos, graphics, and campaign documents
- Sales demos mixing presentations, product screenshots, and recorded conversations
And that’s just the short list.
The problem isn’t scarcity. It’s how multimodal data gets siloed, deleted, or stored in ways that make it unusable for AI applications. Video sits in one system and transcripts in another, with metadata scattered across databases. Most organizations treat this as operational exhaust rather than the strategic asset it represents.
Organizations that start systematically leveraging their multimodal data today will have capabilities tomorrow that generic models can never match.
The challenge: Multimodal infrastructure complexity
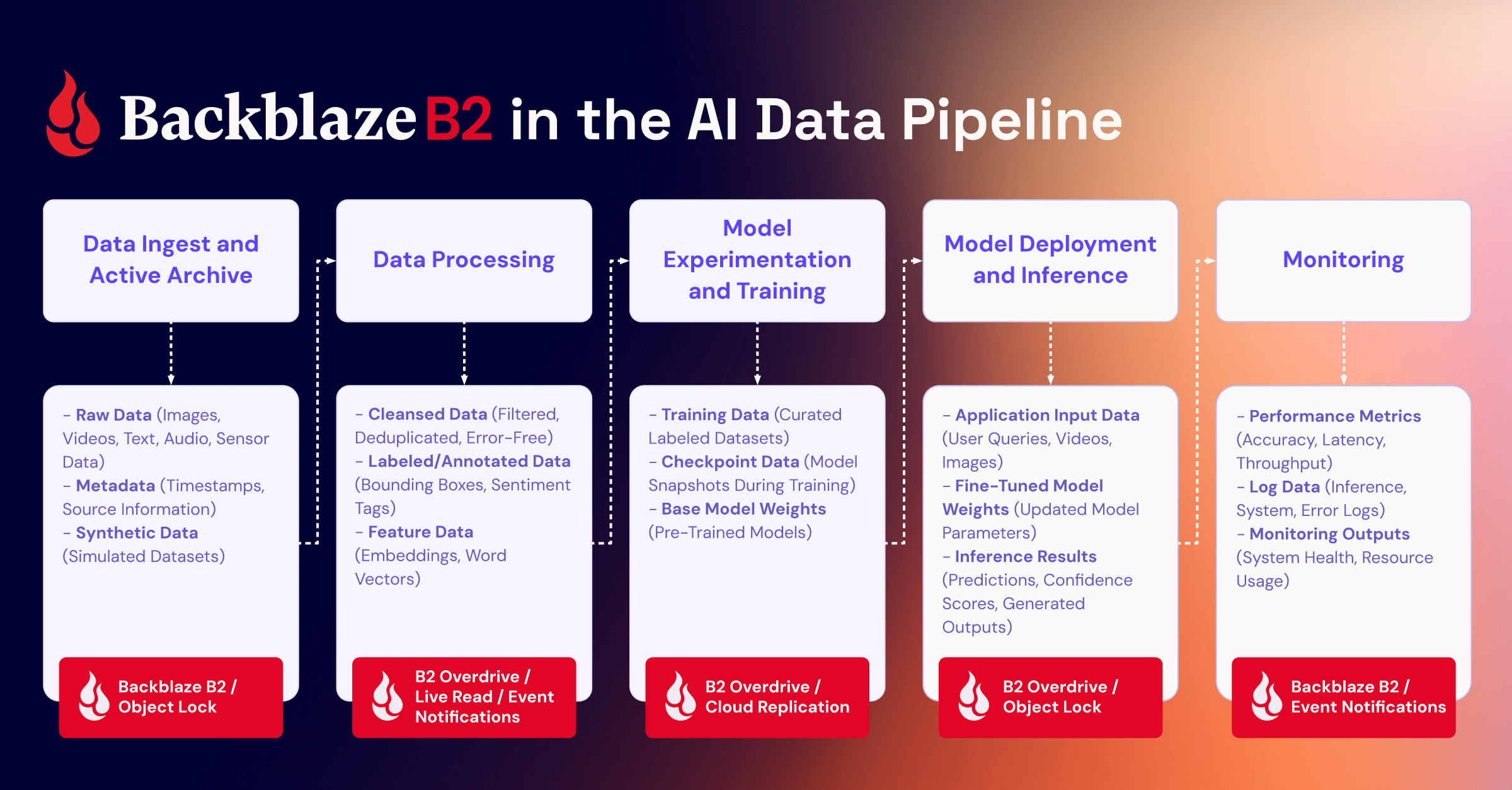
Building AI systems that work across images, video, audio, and text traditionally requires stitching together a fragmented technology stack. Videos live in object storage. Structured data sits in relational databases. Vector embeddings need specialized vector databases. Custom ETL pipelines handle transformations. Orchestration code coordinates everything. You need separate systems for caching, versioning, and lineage tracking.
This “data plumbing” consumes more engineering time than actual AI development. A straightforward workflow like building a searchable video archive with object detection and similarity search requires coordinating five or more systems and writing hundreds of lines of orchestration code.
The complexity creates a barrier that prevents most organizations from leveraging their multimodal data effectively, even when the underlying AI models are accessible through APIs. That’s the gap that Pixeltable solves.
How Pixeltable simplifies multimodal data workloads
Pixeltable replaces the fragmented multi-system architecture typically required for AI applications with a single declarative table interface. Instead of coordinating databases, file storage, vector databases, APIs, and orchestration tools separately, you work with tables where multimodal data lives alongside your transformations and AI operations.
The approach is straightforward. Store multimodal data in tables, define transformations as computed columns, and query everything together. Pixeltable handles the orchestration, caching, and model execution automatically.
Connect to data in-place
Point Pixeltable at your existing object stores like AWS S3 or Backblaze B2 Cloud Storage without moving or duplicating data. Your files stay where they are, organized into queryable, versioned tables. No separate databases or vector stores needed.
Define workflows declaratively
Transformations, model inference, and custom logic become Python computed columns. Extract frames from video, run object detection, generate embeddings, define it once and Pixeltable auto-orchestrates execution, manages dependencies, and handles incremental updates when new data arrives.
Query across everything
Leverage semantic search co-located with metadata. Raw data and AI-generated results in one interface. Build RAG systems with auto-synced embedding indexes that eliminate separate vector database management.
Focus on logic, not infrastructure
Full versioning for reproducibility. Automatic incremental processing means only necessary computations run when data changes. The same code works in development and production without rewrites.
For a practical example, explore our companion Github notebook Multimodal Data Processing with Pixeltable and Backblaze B2. It demonstrates how to extract and transform video frames using Pixeltable, then store the processed results in Backblaze B2 Cloud Storage with automatic URL generation.
Powering multimodal AI with Pixeltable and Backblaze B2
At Backblaze, we understand how essential multimodal data has become for AI development. Our collaboration with Pixeltable integrates B2 Cloud Storage directly into their open-source framework, giving organizations a simple and scalable foundation for managing complex AI workloads.
Pixeltable’s declarative design works seamlessly with Backblaze B2 across the entire AI data lifecycle. Whether you are processing video for model training, running inference on image streams, or building retrieval-augmented generation systems with multimodal embeddings, Backblaze B2 provides reliable S3 compatible storage that Pixeltable can reference directly without data duplication.
We are working closely with the Pixeltable team on a handful of initiatives to make multimodal workflows easier to deploy and scale. For those exploring this integration, we provide an example that demonstrates how Pixeltable and Backblaze B2 work together across the multimodal AI pipeline.
The data that fuels multimodal AI already exists across most organizations, from meeting recordings to customer interactions, video archives, and sensor logs. With Pixeltable and Backblaze B2, the infrastructure to harness that data effectively is now within reach.
Explore Pixeltable on GitHub or visit pixeltable.com to learn about declarative multimodal data infrastructure. For S3 compatible storage across your AI pipeline, check out Backblaze B2.
The post Building Multimodal AI Data Infrastructure with Pixeltable appeared first on Backblaze Blog | Cloud Storage & Cloud Backup