Post Syndicated from Kunal Gautam original https://aws.amazon.com/blogs/big-data/new-features-from-apache-hudi-0-9-0-on-amazon-emr/
Apache Hudi is an open-source transactional data lake framework that greatly simplifies incremental data processing and data pipeline development. It does this by providing transaction support and record-level insert, update, and delete capabilities on data lakes on Amazon Simple Storage Service (Amazon S3) or Apache HDFS. Apache Hudi is integrated with open-source big data analytics frameworks, such as Apache Spark, Apache Hive, Presto, and Trino. Furthermore, Apache Hudi lets you maintain data in Amazon S3 or Apache HDFS in open formats such as Apache Parquet and Apache Avro.
Common use cases where we see customers use Apache Hudi are as follows:
- To simplify data ingestion pipelines that deal with late-arriving or updated records from streaming and batch data sources.
- To ingest data using Change Data Capture (CDC) from transactional systems.
- To implement data-deletion pipelines to comply with data privacy regulations, e.g., GDPR (General Data Protection Regulation) compliance. Conforming to GDPR is a necessity of today’s modern data architectures, which includes the features of “right to erasure” or “right to be forgotten”, and it can be implemented using Apache Hudi capabilities in place of deletes and updates.
We are excited to announce that Apache Hudi 0.9.0 is available on Amazon EMR 5.34 and EMR 6.5.0. This is a major release, which includes Spark SQL DML and DDL support as its highlight, along with several other writer/reader side improvements. The 3x query performance improvement that we observe over Hudi 0.6.0 is especially remarkable so if you are looking to implement a transactional data lake with record level upserts and deletes or are using an older version of Hudi, this is a great version to use. In this post, we’ll focus on the following new features and improvements that come with the 0.9.0 release:
- Spark SQL DML and DDL Support: Explore Spark SQL DML and DDL support.
- Performance Improvements: Explore the performance improvements and new performance related features introduced on the writer and query side.
- Additional Features: Explore additional useful features, such as Amazon DynamoDB-based locks for Optimistic Concurrency Control (OCC), delete partitions operation, etc.
Spark SQL DML and DDL support
The most exciting new feature is that Apache Hudi 0.9.0 adds support for DDL/DMLs using Spark SQL. This takes a huge step toward making Hudi more easily accessible, operable by all people (non-engineers, analysts, etc.). Moreover, it enables existing datasets to be easily migrated to Apache Hudi tables, and it takes a step closer to a low-code paradigm using Spark SQL DML and DDL hence eliminating the need to write scala/python code.
Users can now create tables using CREATE TABLE....USING HUDI and CREATE TABLE .. AS SELECT SQL statements to directly manage tables in AWS Glue catalog.
Then, users can use INSERT, UPDATE, MERGE INTO, and DELETE SQL statements to manipulate data. The INSERT OVERWRITE statement can be used to overwrite existing data in the table or partition for existing batch ETL pipelines.
Let’s run through a quick example where we create a Hudi table amazon_customer_review_hudi resembling the schema of Amazon Customer reviews Public Dataset and perform the following activities:
- Pre-requisite: Create Amazon Simple Storage Service (S3) Buckets
s3://EXAMPLE-BUCKET and s3://EXAMPLE-BUCKET-1
- Create a partitioned Hudi table
amazon_product_review_hudi
- Create a source Hudi table
amazon_customer_review_parquet_merge_source with contents that will be merged with the amazon_product_review_hudi table
- Insert data into
amazon_customer_review_parquet_merge_source and amazon_product_review_hudi as well as perform a merge operation by reading the data from
amazon_customer_review_parquet_merge_source and merging with the Hudi table amazon_product_review_hudi
- Perform a delete operation on
amazon_customer_review_hudi over the previously inserted records
Configure Spark Session
We use the following script via EMR studio notebook, to configure Spark Session to work with Apache Hudi DML and DDL support. The following examples demonstrate how to launch the interactive Spark shell, use Spark submit, or use Amazon EMR Notebooks to work with Hudi on Amazon EMR. We recommend launching your EMR cluster with the following Apache Livy configuration:
[
{
"Classification": "livy-conf",
"Properties": {
"livy.file.local-dir-whitelist": "/usr/lib/hudi"
}
}
]
The above configuration lets you directly refer to the local /usr/lib/hudi/hudi-spark-bundle.jar on the EMR leader node while configuring the Spark session. Alternatively, you can also copy /usr/lib/hudi/hudi-spark-bundle.jar over to an HDFS location and refer to that while initializing Spark session. Here is a command for initializing the Spark session from a notebook:
%%configure -f
{
"conf" : {
"spark.jars":"file:///usr/lib/hudi/hudi-spark-bundle.jar",
"spark.serializer":"org.apache.spark.serializer.KryoSerializer",
"spark.sql.extensions":"org.apache.spark.sql.hudi.HoodieSparkSessionExtension"
}
}
Create a Table
Let’s create the following Apache Hudi tables amazon_customer_review_hudi and amazon_customer_review_parquet_merge_source
amazon_customer_review_hudi and amazon_customer_review_parquet_merge_source
%%sql
/****************************
Create a HUDI table having schema same as of Amazon customer reviews table containing selected columns
*****************************/
-- Hudi 0.9.0 configuration https://hudi.apache.org/docs/configurations
-- Hudi configurations can be set in options block as hoodie.datasource.hive_sync.assume_date_partitioning = 'false',
create table if not exists amazon_customer_review_hudi
( marketplace string,
review_id string,
customer_id string,
product_title string,
star_rating int,
timestamp long ,
review_date date,
year string,
month string ,
day string
)
using hudi
location 's3://EXAMPLE-BUCKET/my-hudi-dataset/'
options (
type = 'cow',
primaryKey = 'review_id',
preCombineField = 'timestamp',
hoodie.datasource.write.hive_style_partitioning = 'true'
)
partitioned by (year,month,day);
-- Change Location 's3://EXAMPLE-BUCKET/my-hudi-dataset/' to appropriate S3 bucket you have created in your AWS account
%%sql
/****************************
Create amazon_customer_review_parquet_merge_source to be used as source for merging into amazon_customer_review_hudi.
The table contains deleteRecord column to track if deletion of record is needed
*****************************/
create table if not exists amazon_customer_review_parquet_merge_source
(
marketplace string,
review_id string,
customer_id string,
product_title string,
star_rating int,
review_date date,
deleteRecord string
)
STORED AS PARQUET
LOCATION 's3://EXAMPLE-BUCKET-1/toBeMergeData/'
-- Change Location (s3://EXAMPLE-BUCKET-1/toBeMergeData/') to appropriate S3 bucket you have created in your AWS account
For comparison if, amazon_customer_review_hudi was to be created using programmatic approach the PySpark sample code is as follows.
# Create a DataFrame
inputDF = spark.createDataFrame(
[
("Italy", "11", "1111", "table", 5, 1648126827, "2015/05/02", "2015", "05", "02"),
("Spain", "22", "2222", "chair", 5, 1648126827, "2015/05/02", "2015", "05", "02")
],
["marketplace", "review_id", "customer_id", "product_title", "star_rating", "timestamp", "review_date", "year", "month", "day" ]
)
# Print Schema of inputDF
inputDF.printSchema()
# Specify common DataSourceWriteOptions in the single hudiOptions variable
hudiOptions = {
"hoodie.table.name": "amazon_customer_review_hudi",
"hoodie.datasource.write.recordkey.field": "review_id",
"hoodie.datasource.write.partitionpath.field": "year,month,day",
"hoodie.datasource.write.precombine.field": "timestamp",
"hoodie.datasource.write.hive_style_partitioning": "true",
"hoodie.datasource.hive_sync.enable": "true",
"hoodie.datasource.hive_sync.table": " amazon_customer_review_hudi",
"hoodie.datasource.hive_sync.partition_fields": "year,month,day",
"hoodie.datasource.hive_sync.partition_extractor_class": "org.apache.hudi.hive.MultiPartKeysValueExtractor"
}
# Create Hudi table and insert data into my_hudi_table_1 hudi table at the S3 location specified
inputDF.write \
.format("org.apache.hudi")\
.option("hoodie.datasource.write.operation", "insert")\
.options(**hudiOptions)\
.mode("append")\
.save("s3://EXAMPLE-BUCKET/my-hudi-dataset/")
Insert data into the Hudi tables
Let’s insert records into the table amazon_customer_review_parquet_merge_source to be used for the merge operation. This includes inserting a row for fresh insert, update, and delete.
%%sql
/****************************
Insert a record into amazon_customer_review_parquet_merge_source for deletion
*****************************/
-- The record will be deleted from amazon_customer_review_hudi after merge as deleteRecord is set to yes
insert into amazon_customer_review_parquet_merge_source
select
'italy',
'11',
'1111',
'table',
5,
TO_DATE(CAST(UNIX_TIMESTAMP('2015/05/02', 'yyyy/MM/dd') AS TIMESTAMP)) as review_date,
'yes'
%%sql
/****************************
Insert a record into amazon_customer_review_parquet_merge_source used for update
*****************************/
-- The record will be updated from amazon_customer_review_hudi with new Star rating and product_title after merge
insert into amazon_customer_review_parquet_merge_source
select
'spain',
'22',
'2222',
'Relaxing chair',
4,
TO_DATE(CAST(UNIX_TIMESTAMP('2015/05/02', 'yyyy/MM/dd') AS TIMESTAMP)) as review_date,
'no'
%%sql
/****************************
Insert a record into amazon_customer_review_parquet_merge_source for insert
*****************************/
-- The record will be inserted into amazon_customer_review_hudi after merge
insert into amazon_customer_review_parquet_merge_source
select
'uk',
'33',
'3333',
'hanger',
3,
TO_DATE(CAST(UNIX_TIMESTAMP('2015/05/02', 'yyyy/MM/dd') AS TIMESTAMP)) as review_date,
'no'
Now let’s insert records into the amazon_customer_review_hudi table used as the destination table for the merge operation.
%%sql
/****************************
Insert a record into amazon_customer_review_hudi table for deletion after merge
*****************************/
-- Spark SQL date time functions https://spark.apache.org/docs/latest/api/sql/index.html#date_add
insert into amazon_customer_review_hudi
select
'italy',
'11',
'1111',
'table',
5,
unix_timestamp(current_timestamp()) as timestamp,
TO_DATE(CAST(UNIX_TIMESTAMP('2015/05/02', 'yyyy/MM/dd') AS TIMESTAMP)) as review_date,
date_format(date '2015-05-02', "yyyy") as year,
date_format(date '2015-05-02', "MM") as month,
date_format(date '2015-05-02', "dd") as day
%%sql
/****************************
Insert a record into amazon_customer_review_hudi table for update after merge
*****************************/
insert into amazon_customer_review_hudi
select
'spain',
'22',
'2222',
'chair ',
5,
unix_timestamp(current_timestamp()) as timestamp,
TO_DATE(CAST(UNIX_TIMESTAMP('2015/05/02', 'yyyy/MM/dd') AS TIMESTAMP)) as review_date,
date_format(date '2015-05-02', "yyyy") as year,
date_format(date '2015-05-02', "MM") as month,
date_format(date '2015-05-02', "dd") as day
Merge into
Let’s perform the merge from amazon_customer_review_parquet_merge_source into amazon_customer_review_hudi.
%%sql
/*************************************
MergeInto : Merge Source Into Traget
**************************************/
-- Source amazon_customer_review_parquet_merge_source
-- Taget amazon_customer_review_hudi
merge into amazon_customer_review_hudi as target
using (
select
marketplace,
review_id,
customer_id,
product_title,
star_rating,
review_date,
deleteRecord,
date_format(review_date, "yyyy") as year,
date_format(review_date, "MM") as month,
date_format(review_date, "dd") as day
from amazon_customer_review_parquet_merge_source ) source
on target.review_id = source.review_id
when matched and deleteRecord != 'yes' then
update set target.timestamp = unix_timestamp(current_timestamp()),
target.star_rating = source.star_rating,
target.product_title = source.product_title
when matched and deleteRecord = 'yes' then delete
when not matched then insert
( target.marketplace,
target.review_id,
target.customer_id,
target.product_title,
target.star_rating,
target.timestamp ,
target.review_date,
target.year ,
target.month ,
target.day
)
values
(
source.marketplace,
source.review_id,
source.customer_id,
source.product_title,
source.star_rating,
unix_timestamp(current_timestamp()),
source.review_date,
source.year ,
source.month ,
source.day
)
Considerations and Limitations
- The merge-on condition can only be applied on primary key as of now.
-- The merge condition is possible only on primary keys
on target.review_id = source.review_id
- Support for partial updates is supported for the Copy on Write (CoW) table, but it isn’t supported for the Merge on Read (MoR) tables.
- The target table’s fields cannot be the right-value of the update expression for the MoR table:
-- The update will result in an error as target columns are present on right hand side of the expression
update set target.star_rating = target.star_rating +1
Delete a Record
Now let’s delete the inserted record.
%%sql
/*************************************
Delete the inserted record from amazon_customer_review_hudi table
**************************************/
Delete from amazon_customer_review_hudi where review_id == '22'
%%sql
/*************************************
Query the deleted record from amazon_customer_review_hudi table
**************************************/
select * from amazon_customer_review_hudi where review_id == '22'
Schema Evolution
Hudi supports common schema evolution scenarios, such as adding a nullable field or promoting the datatype of a field. Let’s add a new column ssid (type int) to existing amazon_customer_review_hudi table, and insert a record with extra column. Hudi allows for querying both old and new data with the updated table schema.
%%sql
/*************************************
Adding a new column name ssid of type int to amazon_customer_review_hudi table
**************************************/
ALTER TABLE amazon_customer_review_hudi ADD COLUMNS (ssid int)
%%sql
/*************************************
Adding a new record to altered table amazon_customer_review_hudi
**************************************/
insert into amazon_customer_review_hudi
select
'germany',
'55',
'5555',
'car',
5,
unix_timestamp(current_timestamp()) as timestamp,
TO_DATE(CAST(UNIX_TIMESTAMP('2015/05/02', 'yyyy/MM/dd') AS TIMESTAMP)) as review_date,
10 as ssid,
date_format(date '2015-05-02', "yyyy") as year,
date_format(date '2015-05-02', "MM") as month,
date_format(date '2015-05-02', "dd") as day
%%sql
/*************************************
Promoting ssid type from int to long
**************************************/
ALTER TABLE amazon_customer_review_hudi CHANGE COLUMN ssid ssid long
%%sql
/*************************************
Querying data from amazon_customer_review_hudi table
**************************************/
select * from amazon_customer_review_hudi where review_id == '55'
Spark Performance Improvements
Query Side Improvements
Apache Hudi tables are now registered with the metastore as Spark Data Source tables. This enables Spark SQL queries on Hudi tables to use Spark’s native Parquet Reader in case of Copy on Write tables, and Hudi’s custom MergeOnReadSnapshotRelation in case of Merge on Read tables. Therefore, it no longer depends on Hive Input Format fallback within Spark, which isn’t as maintained and efficient as Spark’s native readers. This unlocks many optimizations, such as the use of Spark’s native parquet readers, and implementing Hudi’s own Spark FileIndex implementation. The File Index helps improve file listing performance via optimized caching, support for partition pruning, as well as the ability to list files via Hudi metadata table (instead of listing directly from Amazon S3). In addition, Hudi now supports time travel query via Spark data source, which lets you query snapshot of the dataset as of a historical time instant.
Other important things to note are:
- Configurations such as
spark.sql.hive.convertMetastoreParquet=false and mapreduce.input.pathFilter.class=org.apache.hudi.hadoop.HoodieROTablePathFilter are no longer needed while querying via Spark SQL.
- Now you can use a non-globbed query path when querying Hudi datasets via Data Source API. This lets you query the table via base path without having to specify
* in the query path.
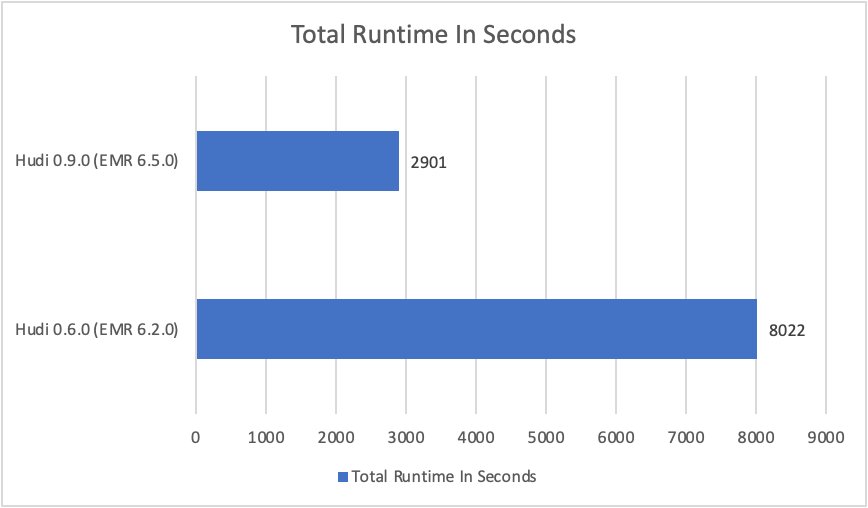
We ran a performance benchmark derived from the 3 TB scale TPC-DS benchmark to determine the query performance improvements for Hudi 0.9.0 on EMR 6.5.0, relative to Hudi 0.6.0 on EMR 6.2.0 (at the beginning of 2021) for Copy on Write tables. The queries were run on 5-node c5.9xlarge EMR clusters.
In terms of Geometric Mean, the queries with Hudi 0.9.0 are three times faster than they were with Hudi 0.6.0. The following graphs compare the total aggregate runtime and geometric mean of runtime for all of the queries in the TPC-DS 3 TB query dataset between the two Amazon EMR/Hudi releases (lower is better):


In terms of Geometric Mean the queries with Hudi 0.9.0 are 3 times faster than they were with Hudi 0.6.0.
Writer side improvements
Virtual Keys Support
Apache Hudi maintains metadata by adding additional columns to the datasets. This lets it support upsert/delete operations and various capabilities around it, such as incremental queries, compaction, etc. These metadata columns (namely _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, _hoodie_file_name and _hoodie_commit_seqno) let Hudi uniquely identify a record, the partition/file in which a record exists, and the latest commit that updated a record.
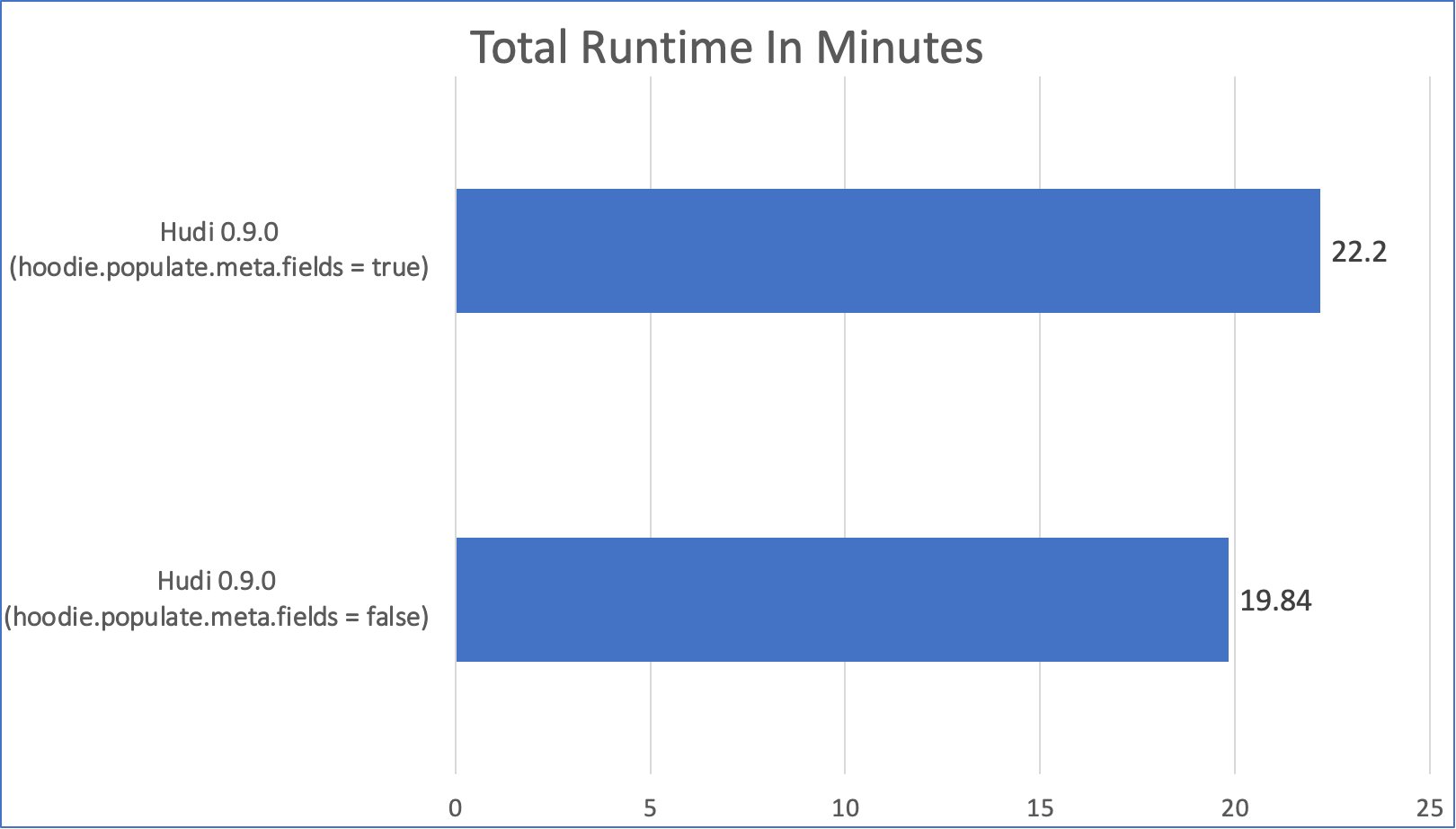
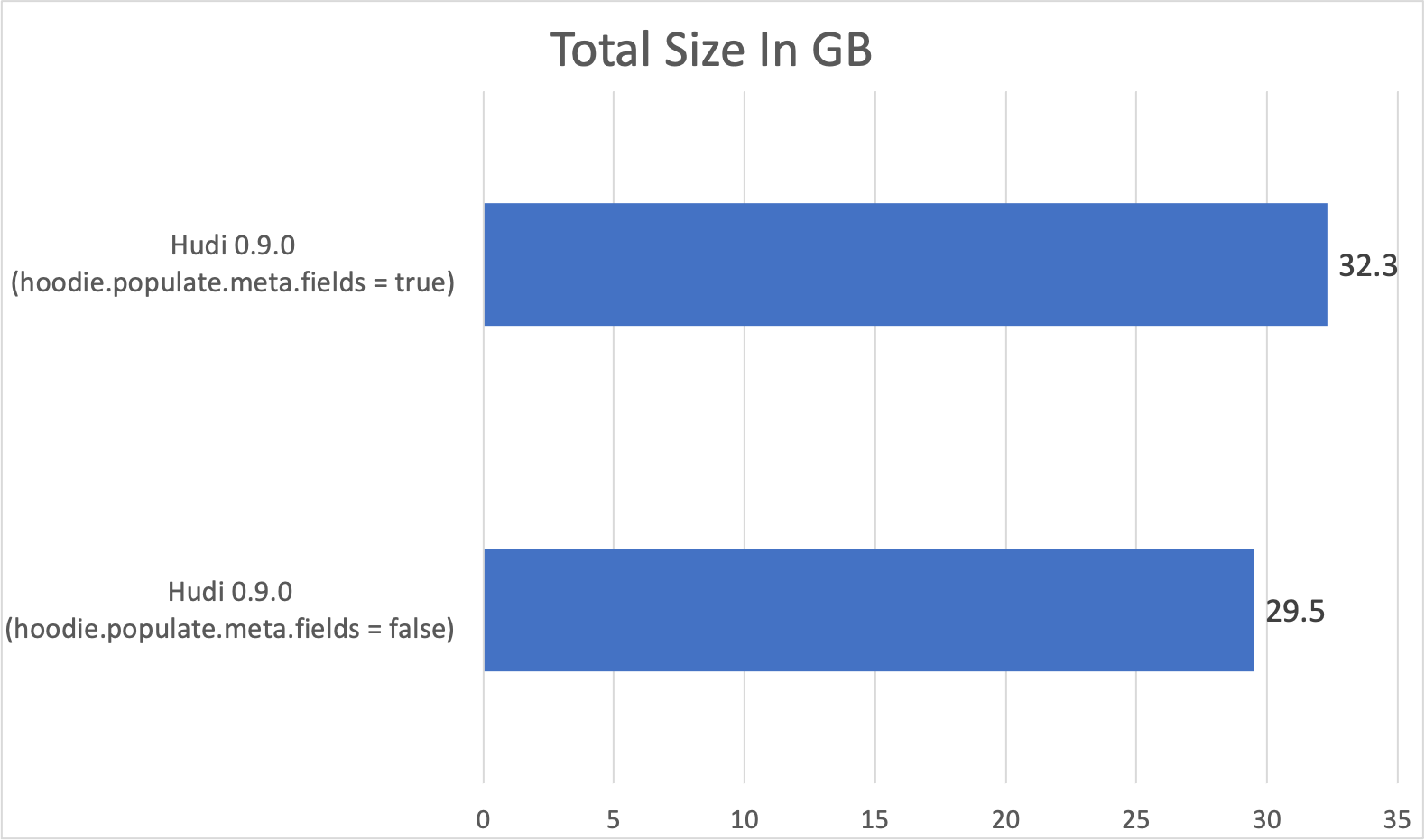
However, generating and maintaining these metadata columns increases the storage footprint for Hudi tables on disk. Some of these columns, such as _hoodie_record_key and _hoodie_partition_path, can be constructed from other data columns already stored in the datasets. Apache Hudi 0.9.0 has introduced support for Virtual Keys. This lets users disable the generation of these metadata columns, and instead depend on actual data columns to construct the record key/partition paths dynamically using appropriate key generators. This helps in reducing the storage footprint, as well as improving ingestion time. However, this feature comes with the following caveats:
- This is only meant to be used for Append Only / Immutable data. It can’t be used for use cases requiring upserts and deletes, which requires metadata columns such as
_hoodie_record_key and _hoodie_partition_path for bloom indexes to work.
- Incremental queries will not be supported, because they need
_hoodie_commit_time to filter records written/updated at a specific time.
- Once this feature is enabled, it can’t be turned off for an existing table.
The feature is turned off by default, and it can be enabled by setting hoodie.populate.meta.fields to false. We measured the write performance and storage footprint improvements using Bulk Insert with public Amazon Customer Reviews dataset. Here is the code snippet that we used:
import org.apache.hudi.DataSourceWriteOptions
import org.apache.hudi.config.HoodieWriteConfig
import org.apache.spark.sql.SaveMode
var srcPath = "s3://amazon-reviews-pds/parquet/"
var tableName = "amazon_reviews_table"
var tablePath = "s3://<bucket>/<prefix>/" + tableName
val inputDF = spark.read.format("parquet").load(srcPath)
inputDF.write.format("hudi")
.option(HoodieWriteConfig.TABLE_NAME, tableName)
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.BULK_INSERT_OPERATION_OPT_VAL)
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "review_id")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "product_category")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "review_date")
.option("hoodie.populate.meta.fields", "<true/false>")
.mode(SaveMode.Overwrite)
.save(tablePath)
The experiment was run on a four node c4.2xlarge EMR cluster (one leader, three core). We observed a 10.63% improvement in the write runtime performance, and a 8.67% reduction in storage footprint with virtual keys enabled. The following graph compares the bulk insert runtime and table size with and without virtual keys (lower is better):
Timeline Server-based Marker Mechanism
Apache Hudi supports the automatic cleaning up of uncommitted data written during write operations. This cleaning is supported by generating marker files corresponding to each data file, which serves as a method to track data files of interest rather than having to scan the entire table by listing all of the files. Although the existing marker mechanism is much more efficient than scanning the entire table for uncommitted data files, it can still have a performance impact for Amazon S3 data lakes. For example, writing a significant number of marker files (one per-data file) and then deleting them following a successful commit could take a non-trivial amount of time, sometimes in the order of several minutes. In addition, it has the potential to hit Amazon S3 throttling limits when a significant number of data/marker files are being written concurrently.
Apache Hudi 0.9.0 introduces a new timeline server based implementation of this marker mechanism. This makes it more efficient for Amazon S3 workloads by improving the overall write performance, as well as significantly decreasing the probability of hitting Amazon S3 throttle limits. The new mechanism uses Hudi’s timeline server component as a central place for processing all of the marker creation/deletion requests (from all executors), which allows for batching of these requests and reducing the number of requests to Amazon S3. Therefore, users with Amazon S3 data lakes can leverage this to improve write operations performance and avoid throttling due to marker files management. It would be especially impactful for scenarios where a significant number of data files (e.g., 10k or more) are being written.
This new mechanism is not enabled by default, and it can be enabled by setting hoodie.write.markers.type to timeline_server_based, for the write operation. For more details about the feature, refer to this blog post by the Apache Hudi community.
Additional Improvements
DynamoDB-based Locking
Optimistic Concurrency Control was one of the major features introduced with Apache Hudi 0.8.0 to allow multiple concurrent writers to ingest data into the same Hudi table. The feature requires acquiring locks for which either Zookeeper (default on EMR) or Hive Metastore could be used. However, these lock providers require all of the writers to be running on the same cluster on which the Zookeeper/Hive Metastore is running.
Apache Hudi 0.9.0 on Amazon EMR has introduced DynamoDB as a lock provider. This would let multiple writers running across different clusters ingest data into the same Hudi table. This feature was originally added to Hudi 0.9.0 on Amazon EMR, and it contributed back to open source Hudi in version 0.10.0. To configure this, the following properties should be set:
| Configuration |
Value |
Description |
Required |
| hoodie.write.lock.provider |
org.apache.hudi.client.
transaction.lock.
DynamoDBBasedLockProvider |
Lock Provider implementation to be used |
Yes |
hoodie.write.lock.dynamodb.
table |
<String> |
DynamoDB table name to be used for acquiring locks. If the table doesn’t exist, it will be created. The same table can be used across all of your Hudi jobs operating on the same or different tables |
Yes |
hoodie.write.lock.dynamodb.
partition_key |
<String> |
String Value to be used for the locks table partition key attribute. It must be a string that uniquely identifies a Hudi table, such as the Hudi table name |
No. Default: Hudi Table Name |
hoodie.write.lock.dynamodb.
region |
<String> |
AWS Region in which the DynamoDB locks table exists, or must be created. |
No. Default:
us-east-1
|
hoodie.write.lock.dynamodb.
billing_mode |
<String> |
DynamoDB billing mode to be used for the locks table while creating. If the table already exists, then this doesn’t have an effect |
No. Default:
PAY_PER_REQUEST |
hoodie.write.lock.dynamodb.
read_capacity |
<Integer> |
DynamoDB read capacity to be used for the locks table while creating. If the table already exists, then this doesn’t have an effect |
No. Default: 20 |
hoodie.write.lock.dynamodb.
write_capacity |
<Integer> |
DynamoDB write capacity to be used for the locks table while creating. If the table already exists, then this doesn’t have an effect |
No. Default: 10 |
Furthermore, Optimistic Concurrency Control must be enabled via the following:
hoodie.write.concurrency.mode = optimistic_concurrency_control
hoodie.cleaner.policy.failed.writes = LAZY
You can seamlessly configure these properties at the cluster level, using EMR Configurations API with hudi-defaults classification, to avoid having to configure it with every job.
Delete partitions
Apache Hudi 0.9.0 introduces a DELETE_PARTITION operation for its Spark Data Source API that can be leveraged to delete partitions. Here is a scala example of how to leverage this operation:
import org.apache.hudi.DataSourceWriteOptions
import org.apache.hudi.config.HoodieWriteConfig
import org.apache.spark.sql.SaveMode
val deletePartitionDF = spark.emptyDataFrame
deletePartitionDF.write.format("hudi")
.option(HoodieWriteConfig.TABLE_NAME, "<table name>")
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, DataSourceWriteOptions.DELETE_PARTITION_OPERATION_OPT_VAL)
.option(DataSourceWriteOptions.PARTITIONS_TO_DELETE.key(), "<partition_value1>,<partition_value2>")
.option(DataSourceWriteOptions.TABLE_TYPE_OPT_KEY, DataSourceWriteOptions.COW_TABLE_TYPE_OPT_VAL)
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "<record key(s)>")
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "<partition field(s)>")
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "<precombine key>")
.mode(SaveMode.Append)
.save("<table path>")
However, there is a known issue:
- Hive Sync fails when performed along with DELETE_PARTITION operation because of a bug. Hive Sync will succeed for any future insert/upsert/delete operation performed following the delete partition operation. This bug has been fixed in Hudi release 0.10.0.
Asynchronous Clustering
Apache Hudi 0.9.0 introduces support for asynchronous clustering via Spark structured streaming sink and Delta Streamer. This lets users continue ingesting data into the data lake, while the clustering service continues to run in the background to reorganize data for improved query performance and optimal file sizes. This is made possible with the Optimistic Concurrency Control feature introduced in Hudi 0.8.0. Currently, clustering can only be scheduled for partitions that aren’t receiving any concurrent updates. Additional details on how to get started with this feature can be found in this blog post.
Conclusion
In this post, we shared some of the new and exciting features in Hudi 0.9.0 available on Amazon EMR versions 5.34 and 6.5.0 and later. These new features enable the ability for data pipelines to be built solely with SQL statements, thereby making it easier to build transactional data lakes on Amazon S3.
As a next step, for a hands on experience on Hudi 0.9.0 on EMR, try out the notebook here on EMR Studio using Amazon EMR version 6.5.0 and let us know your feedback.
About the Authors
 Kunal Gautam is a Senior Big Data Architect at Amazon Web Services. Having experience in building his own Startup and working along with enterprises, he brings a unique perspective to get people, business and technology work in tandem for customers. He is passionate about helping customers in their digital transformation journey and enables them to build scalable data and advance analytics solutions to gain timely insights and make critical business decisions. In his spare time, Kunal enjoys Marathons, Tech Meetups and Meditation retreats.
Kunal Gautam is a Senior Big Data Architect at Amazon Web Services. Having experience in building his own Startup and working along with enterprises, he brings a unique perspective to get people, business and technology work in tandem for customers. He is passionate about helping customers in their digital transformation journey and enables them to build scalable data and advance analytics solutions to gain timely insights and make critical business decisions. In his spare time, Kunal enjoys Marathons, Tech Meetups and Meditation retreats.
 Gabriele Cacciola is a Senior Data Architect working for the Professional Service team with Amazon Web Services. Coming from a solid Startup experience, he currently helps enterprise customers across EMEA implement their ideas, innovate using the latest tech and build scalable data and analytics solutions to make critical business decisions. In his free time, Gabriele enjoys football and cooking.
Gabriele Cacciola is a Senior Data Architect working for the Professional Service team with Amazon Web Services. Coming from a solid Startup experience, he currently helps enterprise customers across EMEA implement their ideas, innovate using the latest tech and build scalable data and analytics solutions to make critical business decisions. In his free time, Gabriele enjoys football and cooking.
 Udit Mehrotra is a software development engineer at Amazon Web Services and an Apache Hudi PMC member/committer. He works on cutting-edge features of Amazon EMR and is also involved in open-source projects such as Apache Hudi, Apache Spark, Apache Hadoop, and Apache Hive. In his spare time, he likes to play guitar, travel, binge watch, and hang out with friends.
Udit Mehrotra is a software development engineer at Amazon Web Services and an Apache Hudi PMC member/committer. He works on cutting-edge features of Amazon EMR and is also involved in open-source projects such as Apache Hudi, Apache Spark, Apache Hadoop, and Apache Hive. In his spare time, he likes to play guitar, travel, binge watch, and hang out with friends.


 Nikolai Kolesnikov is a Senior Data Architect and helps AWS Professional Services customers build highly-scalable applications using Amazon Keyspaces. He also leads Amazon Keyspaces ProServe customer engagements.
Nikolai Kolesnikov is a Senior Data Architect and helps AWS Professional Services customers build highly-scalable applications using Amazon Keyspaces. He also leads Amazon Keyspaces ProServe customer engagements. Kunal Gautam is a Senior Big Data Architect at Amazon Web Services. Having experience in building his own Startup and working along with enterprises, he brings a unique perspective to get people, business and technology work in tandem for customers. He is passionate about helping customers in their digital transformation journey and enables them to build scalable data and advance analytics solutions to gain timely insights and make critical business decisions. In his spare time, Kunal enjoys Marathons, Tech Meetups and Meditation retreats.
Kunal Gautam is a Senior Big Data Architect at Amazon Web Services. Having experience in building his own Startup and working along with enterprises, he brings a unique perspective to get people, business and technology work in tandem for customers. He is passionate about helping customers in their digital transformation journey and enables them to build scalable data and advance analytics solutions to gain timely insights and make critical business decisions. In his spare time, Kunal enjoys Marathons, Tech Meetups and Meditation retreats.