Post Syndicated from Lorenz Bauer original https://blog.cloudflare.com/tubular-fixing-the-socket-api-with-ebpf/


As we develop new products, we often push our operating system – Linux – beyond what is commonly possible. A common theme has been relying on eBPF to build technology that would otherwise have required modifying the kernel. For example, we’ve built DDoS mitigation and a load balancer and use it to monitor our fleet of servers.
This software usually consists of a small-ish eBPF program written in C, executed in the context of the kernel, and a larger user space component that loads the eBPF into the kernel and manages its lifecycle. We’ve found that the ratio of eBPF code to userspace code differs by an order of magnitude or more. We want to shed some light on the issues that a developer has to tackle when dealing with eBPF and present our solutions for building rock-solid production ready applications which contain eBPF.
For this purpose we are open sourcing the production tooling we’ve built for the sk_lookup hook we contributed to the Linux kernel, called tubular. It exists because we’ve outgrown the BSD sockets API. To deliver some products we need features that are just not possible using the standard API.
- Our services are available on millions of IPs.
- Multiple services using the same port on different addresses have to coexist, e.g. 1.1.1.1 resolver and our authoritative DNS.
- Our Spectrum product needs to listen on all 2^16 ports.
The source code for tubular is at https://github.com/cloudflare/tubular, and it allows you to do all the things mentioned above. Maybe the most interesting feature is that you can change the addresses of a service on the fly:
How tubular works
tubular sits at a critical point in the Cloudflare stack, since it has to inspect every connection terminated by a server and decide which application should receive it.
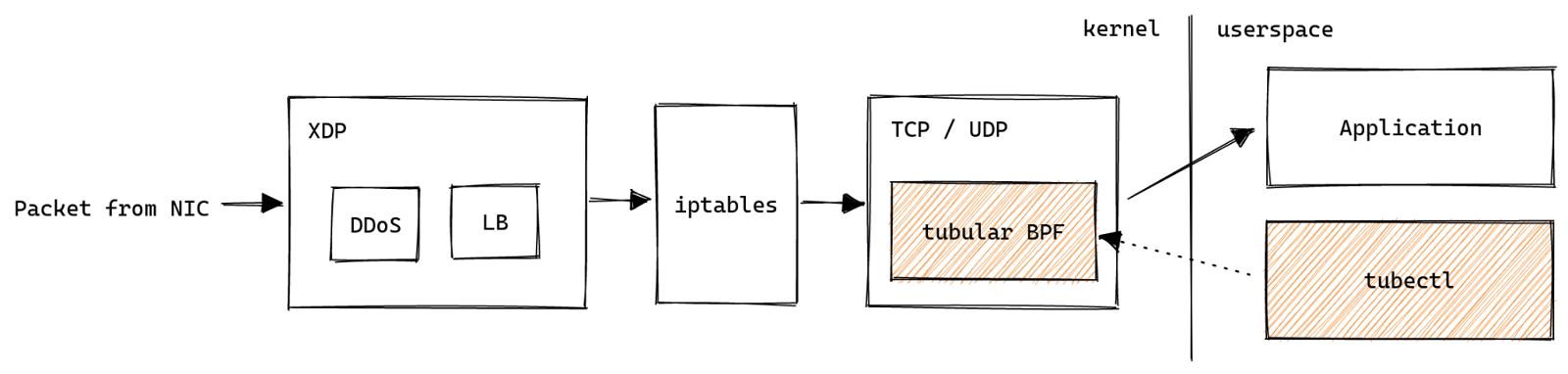
Failure to do so will drop or misdirect connections hundreds of times per second. So it has to be incredibly robust during day to day operations. We had the following goals for tubular:
- Releases must be unattended and happen online
tubular runs on thousands of machines, so we can’t babysit the process or take servers out of production. - Releases must fail safely
A failure in the process must leave the previous version of tubular running, otherwise we may drop connections. - Reduce the impact of (userspace) crashes
When the inevitable bug comes along we want to minimise the blast radius.
In the past we had built a proof-of-concept control plane for sk_lookup called inet-tool, which proved that we could get away without a persistent service managing the eBPF. Similarly, tubular has tubectl: short-lived invocations make the necessary changes and persisting state is handled by the kernel in the form of eBPF maps. Following this design gave us crash resiliency by default, but left us with the task of mapping the user interface we wanted to the tools available in the eBPF ecosystem.
The tubular user interface
tubular consists of a BPF program that attaches to the sk_lookup hook in the kernel and userspace Go code which manages the BPF program. The tubectl command wraps both in a way that is easy to distribute.
tubectl manages two kinds of objects: bindings and sockets. A binding encodes a rule against which an incoming packet is matched. A socket is a reference to a TCP or UDP socket that can accept new connections or packets.
Bindings and sockets are “glued” together via arbitrary strings called labels. Conceptually, a binding assigns a label to some traffic. The label is then used to find the correct socket.

Adding bindings
To create a binding that steers port 80 (aka HTTP) traffic destined for 127.0.0.1 to the label “foo” we use tubectl bind:
$ sudo tubectl bind "foo" tcp 127.0.0.1 80
Due to the power of sk_lookup we can have much more powerful constructs than the BSD API. For example, we can redirect connections to all IPs in 127.0.0.0/24 to a single socket:
$ sudo tubectl bind "bar" tcp 127.0.0.0/24 80
A side effect of this power is that it’s possible to create bindings that “overlap”:
1: tcp 127.0.0.1/32 80 -> "foo"
2: tcp 127.0.0.0/24 80 -> "bar"
The first binding says that HTTP traffic to localhost should go to “foo”, while the second asserts that HTTP traffic in the localhost subnet should go to “bar”. This creates a contradiction, which binding should we choose? tubular resolves this by defining precedence rules for bindings:
- A prefix with a longer mask is more specific, e.g. 127.0.0.1/32 wins over 127.0.0.0/24.
- A port is more specific than the port wildcard, e.g. port 80 wins over “all ports” (0).
Applying this to our example, HTTP traffic to all IPs in 127.0.0.0/24 will be directed to foo, except for 127.0.0.1 which goes to bar.
Getting ahold of sockets
sk_lookup needs a reference to a TCP or a UDP socket to redirect traffic to it. However, a socket is usually accessible only by the process which created it with the socket syscall. For example, an HTTP server creates a TCP listening socket bound to port 80. How can we gain access to the listening socket?
A fairly well known solution is to make processes cooperate by passing socket file descriptors via SCM_RIGHTS messages to a tubular daemon. That daemon can then take the necessary steps to hook up the socket with sk_lookup. This approach has several drawbacks:
- Requires modifying processes to send SCM_RIGHTS
- Requires a tubular daemon, which may crash
There is another way of getting at sockets by using systemd, provided socket activation is used. It works by creating an additional service unit with the correct Sockets setting. In other words: we can leverage systemd oneshot action executed on creation of a systemd socket service, registering the socket into tubular. For example:
[Unit]
Requisite=foo.socket
[Service]
Type=oneshot
Sockets=foo.socket
ExecStart=tubectl register "foo"
Since we can rely on systemd to execute tubectl at the correct times we don’t need a daemon of any kind. However, the reality is that a lot of popular software doesn’t use systemd socket activation. Dealing with systemd sockets is complicated and doesn’t invite experimentation. Which brings us to the final trick: pidfd_getfd:
The
pidfd_getfd()system call allocates a new file descriptor in the calling process. This new file descriptor is a duplicate of an existing file descriptor, targetfd, in the process referred to by the PID file descriptor pidfd.
We can use it to iterate all file descriptors of a foreign process, and pick the socket we are interested in. To return to our example, we can use the following command to find the TCP socket bound to 127.0.0.1 port 8080 in the httpd process and register it under the “foo” label:
$ sudo tubectl register-pid "foo" $(pidof httpd) tcp 127.0.0.1 8080
It’s easy to wire this up using systemd’s ExecStartPost if the need arises.
[Service]
Type=forking # or notify
ExecStart=/path/to/some/command
ExecStartPost=tubectl register-pid $MAINPID foo tcp 127.0.0.1 8080
Storing state in eBPF maps
As mentioned previously, tubular relies on the kernel to store state, using BPF key / value data structures also known as maps. Using the BPF_OBJ_PIN syscall we can persist them in /sys/fs/bpf:
/sys/fs/bpf/4026532024_dispatcher
├── bindings
├── destination_metrics
├── destinations
├── sockets
└── ...
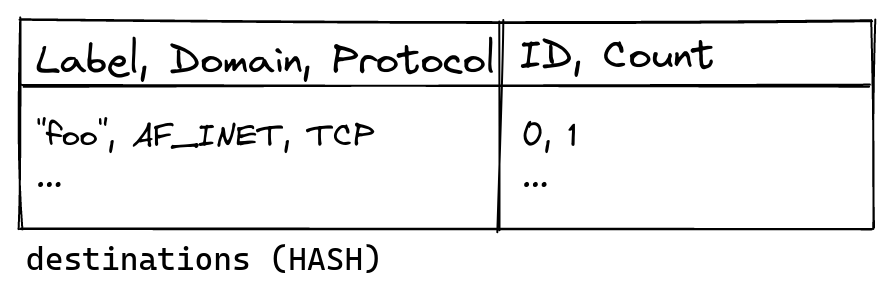
The way the state is structured differs from how the command line interface presents it to users. Labels like “foo” are convenient for humans, but they are of variable length. Dealing with variable length data in BPF is cumbersome and slow, so the BPF program never references labels at all. Instead, the user space code allocates numeric IDs, which are then used in the BPF. Each ID represents a (label, domain, protocol) tuple, internally called destination.
For example, adding a binding for “foo” tcp 127.0.0.1 … allocates an ID for (“foo“, AF_INET, TCP). Including domain and protocol in the destination allows simpler data structures in the BPF. Each allocation also tracks how many bindings reference a destination so that we can recycle unused IDs. This data is persisted into the destinations hash table, which is keyed by (Label, Domain, Protocol) and contains (ID, Count). Metrics for each destination are tracked in destination_metrics in the form of per-CPU counters.
bindings is a longest prefix match (LPM) trie which stores a mapping from (protocol, port, prefix) to (ID, prefix length). The ID is used as a key to the sockets map which contains pointers to kernel socket structures. IDs are allocated in a way that makes them suitable as an array index, which allows using the simpler BPF sockmap (an array) instead of a socket hash table. The prefix length is duplicated in the value to work around shortcomings in the BPF API.

Encoding the precedence of bindings
As discussed, bindings have a precedence associated with them. To repeat the earlier example:
1: tcp 127.0.0.1/32 80 -> "foo"
2: tcp 127.0.0.0/24 80 -> "bar"
The first binding should be matched before the second one. We need to encode this in the BPF somehow. One idea is to generate some code that executes the bindings in order of specificity, a technique we’ve used to great effect in l4drop:
1: if (mask(ip, 32) == 127.0.0.1) return "foo"
2: if (mask(ip, 24) == 127.0.0.0) return "bar"
...
This has the downside that the program gets longer the more bindings are added, which slows down execution. It’s also difficult to introspect and debug such long programs. Instead, we use a specialised BPF longest prefix match (LPM) map to do the hard work. This allows inspecting the contents from user space to figure out which bindings are active, which is very difficult if we had compiled bindings into BPF. The LPM map uses a trie behind the scenes, so lookup has complexity proportional to the length of the key instead of linear complexity for the “naive” solution.
However, using a map requires a trick for encoding the precedence of bindings into a key that we can look up. Here is a simplified version of this encoding, which ignores IPv6 and uses labels instead of IDs. To insert the binding tcp 127.0.0.0/24 80 into a trie we first convert the IP address into a number.
127.0.0.0 = 0x7f 00 00 00
Since we’re only interested in the first 24 bits of the address we, can write the whole prefix as
127.0.0.0/24 = 0x7f 00 00 ??
where “?” means that the value is not specified. We choose the number 0x01 to represent TCP and prepend it and the port number (80 decimal is 0x50 hex) to create the full key:
tcp 127.0.0.0/24 80 = 0x01 50 7f 00 00 ??
Converting tcp 127.0.0.1/32 80 happens in exactly the same way. Once the converted values are inserted into the trie, the LPM trie conceptually contains the following keys and values.
LPM trie:
0x01 50 7f 00 00 ?? = "bar"
0x01 50 7f 00 00 01 = "foo"
To find the binding for a TCP packet destined for 127.0.0.1:80, we again encode a key and perform a lookup.
input: 0x01 50 7f 00 00 01 TCP packet to 127.0.0.1:80
---------------------------
LPM trie:
0x01 50 7f 00 00 ?? = "bar"
y y y y y
0x01 50 7f 00 00 01 = "foo"
y y y y y y
---------------------------
result: "foo"
y = byte matches
The trie returns “foo” since its key shares the longest prefix with the input. Note that we stop comparing keys once we reach unspecified “?” bytes, but conceptually “bar” is still a valid result. The distinction becomes clear when looking up the binding for a TCP packet to 127.0.0.255:80.
input: 0x01 50 7f 00 00 ff TCP packet to 127.0.0.255:80
---------------------------
LPM trie:
0x01 50 7f 00 00 ?? = "bar"
y y y y y
0x01 50 7f 00 00 01 = "foo"
y y y y y n
---------------------------
result: "bar"
n = byte doesn't match
In this case “foo” is discarded since the last byte doesn’t match the input. However, “bar” is returned since its last byte is unspecified and therefore considered to be a valid match.
Observability with minimal privileges
Linux has the powerful ss tool (part of iproute2) available to inspect socket state:
$ ss -tl src 127.0.0.1
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.1:ipp 0.0.0.0:*
With tubular in the picture this output is not accurate anymore. tubectl bindings makes up for this shortcoming:
$ sudo tubectl bindings tcp 127.0.0.1
Bindings:
protocol prefix port label
tcp 127.0.0.1/32 80 foo
Running this command requires super-user privileges, despite in theory being safe for any user to run. While this is acceptable for casual inspection by a human operator, it’s a dealbreaker for observability via pull-based monitoring systems like Prometheus. The usual approach is to expose metrics via an HTTP server, which would have to run with elevated privileges and be accessible to the Prometheus server somehow. Instead, BPF gives us the tools to enable read-only access to tubular state with minimal privileges.
The key is to carefully set file ownership and mode for state in /sys/fs/bpf. Creating and opening files in /sys/fs/bpf uses BPF_OBJ_PIN and BPF_OBJ_GET. Calling BPF_OBJ_GET with BPF_F_RDONLY is roughly equivalent to open(O_RDONLY) and allows accessing state in a read-only fashion, provided the file permissions are correct. tubular gives the owner full access but restricts read-only access to the group:
$ sudo ls -l /sys/fs/bpf/4026532024_dispatcher | head -n 3
total 0
-rw-r----- 1 root root 0 Feb 2 13:19 bindings
-rw-r----- 1 root root 0 Feb 2 13:19 destination_metrics
It’s easy to choose which user and group should own state when loading tubular:
$ sudo -u root -g tubular tubectl load
created dispatcher in /sys/fs/bpf/4026532024_dispatcher
loaded dispatcher into /proc/self/ns/net
$ sudo ls -l /sys/fs/bpf/4026532024_dispatcher | head -n 3
total 0
-rw-r----- 1 root tubular 0 Feb 2 13:42 bindings
-rw-r----- 1 root tubular 0 Feb 2 13:42 destination_metrics
There is one more obstacle, systemd mounts /sys/fs/bpf in a way that makes it inaccessible to anyone but root. Adding the executable bit to the directory fixes this.
$ sudo chmod -v o+x /sys/fs/bpf
mode of '/sys/fs/bpf' changed from 0700 (rwx------) to 0701 (rwx-----x)
Finally, we can export metrics without privileges:
$ sudo -u nobody -g tubular tubectl metrics 127.0.0.1 8080
Listening on 127.0.0.1:8080
^C
There is a caveat, unfortunately: truly unprivileged access requires unprivileged BPF to be enabled. Many distros have taken to disabling it via the unprivileged_bpf_disabled sysctl, in which case scraping metrics does require CAP_BPF.
Safe releases
tubular is distributed as a single binary, but really consists of two pieces of code with widely differing lifetimes. The BPF program is loaded into the kernel once and then may be active for weeks or months, until it is explicitly replaced. In fact, a reference to the program (and link, see below) is persisted into /sys/fs/bpf:
/sys/fs/bpf/4026532024_dispatcher
├── link
├── program
└── ...
The user space code is executed for seconds at a time and is replaced whenever the binary on disk changes. This means that user space has to be able to deal with an “old” BPF program in the kernel somehow. The simplest way to achieve this is to compare what is loaded into the kernel with the BPF shipped as part of tubectl. If the two don’t match we return an error:
$ sudo tubectl bind foo tcp 127.0.0.1 80
Error: bind: can't open dispatcher: loaded program #158 has differing tag: "938c70b5a8956ff2" doesn't match "e007bfbbf37171f0"
tag is the truncated hash of the instructions making up a BPF program, which the kernel makes available for every loaded program:
$ sudo bpftool prog list id 158
158: sk_lookup name dispatcher tag 938c70b5a8956ff2
...
By comparing the tag tubular asserts that it is dealing with a supported version of the BPF program. Of course, just returning an error isn’t enough. There needs to be a way to update the kernel program so that it’s once again safe to make changes. This is where the persisted link in /sys/fs/bpf comes into play. bpf_links are used to attach programs to various BPF hooks. “Enabling” a BPF program is a two-step process: first, load the BPF program, next attach it to a hook using a bpf_link. Afterwards the program will execute the next time the hook is executed. By updating the link we can change the program on the fly, in an atomic manner.
$ sudo tubectl upgrade
Upgraded dispatcher to 2022.1.0-dev, program ID #159
$ sudo bpftool prog list id 159
159: sk_lookup name dispatcher tag e007bfbbf37171f0
…
$ sudo tubectl bind foo tcp 127.0.0.1 80
bound foo#tcp:[127.0.0.1/32]:80
Behind the scenes the upgrade procedure is slightly more complicated, since we have to update the pinned program reference in addition to the link. We pin the new program into /sys/fs/bpf:
/sys/fs/bpf/4026532024_dispatcher
├── link
├── program
├── program-upgrade
└── ...
Once the link is updated we atomically rename program-upgrade to replace program. In the future we may be able to use RENAME_EXCHANGE to make upgrades even safer.
Preventing state corruption
So far we’ve completely neglected the fact that multiple invocations of tubectl could modify the state in /sys/fs/bpf at the same time. It’s very hard to reason about what would happen in this case, so in general it’s best to prevent this from ever occurring. A common solution to this is advisory file locks. Unfortunately it seems like BPF maps don’t support locking.
$ sudo flock /sys/fs/bpf/4026532024_dispatcher/bindings echo works!
flock: cannot open lock file /sys/fs/bpf/4026532024_dispatcher/bindings: Input/output error
This led to a bit of head scratching on our part. Luckily it is possible to flock the directory instead of individual maps:
$ sudo flock --exclusive /sys/fs/bpf/foo echo works!
works!
Each tubectl invocation likewise invokes flock(), thereby guaranteeing that only ever a single process is making changes.
Conclusion
tubular is in production at Cloudflare today and has simplified the deployment of Spectrum and our authoritative DNS. It allowed us to leave behind limitations of the BSD socket API. However, its most powerful feature is that the addresses a service is available on can be changed on the fly. In fact, we have built tooling that automates this process across our global network. Need to listen on another million IPs on thousands of machines? No problem, it’s just an HTTP POST away.
Interested in working on tubular and our L4 load balancer unimog? We are hiring in our European offices.