Post Syndicated from Chris Branch original https://blog.cloudflare.com/so-long-and-thanks-for-all-the-fish-how-to-escape-the-linux-networking-stack/
There is a theory which states that if ever anyone discovers exactly what the Linux networking stack does and why it does it, it will instantly disappear and be replaced by something even more bizarre and inexplicable.
There is another theory which states that Git was created to track how many times this has already happened.
Many products at Cloudflare aren’t possible without pushing the limits of network hardware and software to deliver improved performance, increased efficiency, or novel capabilities such as soft-unicast, our method for sharing IP subnets across data centers. Happily, most people do not need to know the intricacies of how your operating system handles network and Internet access in general. Yes, even most people within Cloudflare.
But sometimes we try to push well beyond the design intentions of Linux’s networking stack. This is a story about one of those attempts.
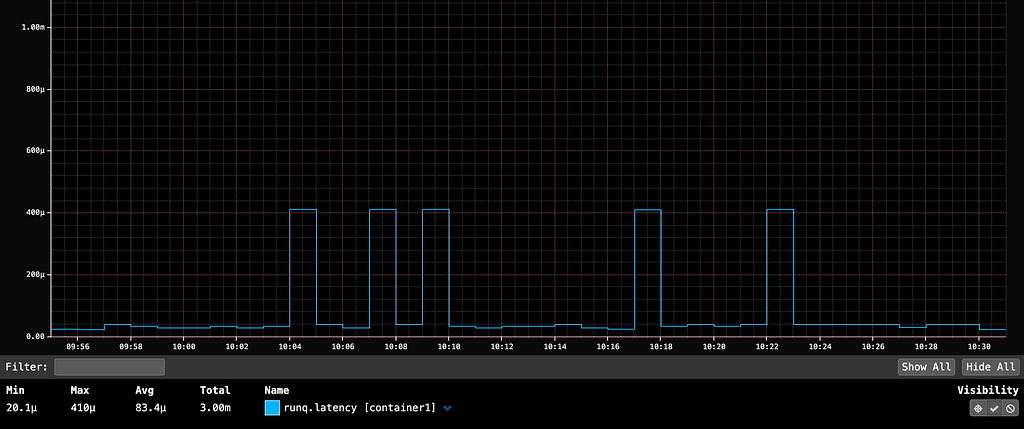
My previous blog post about the Linux networking stack teased a problem matching the ideal model of soft-unicast with the basic reality of IP packet forwarding rules. Soft-unicast is the name given to our method of sharing IP addresses between machines. You may learn about all the cool things we do with it, but as far as a single machine is concerned, it has dozens to hundreds of combinations of IP address and source-port range, any of which may be chosen for use by outgoing connections.

The SNAT target in iptables supports a source-port range option to restrict the ports selected during NAT. In theory, we could continue to use iptables for this purpose, and to support multiple IP/port combinations we could use separate packet marks or multiple TUN devices. In actual deployment we would have to overcome challenges such as managing large numbers of iptables rules and possibly network devices, interference with other uses of packet marks, and deployment and reallocation of existing IP ranges.
Rather than increase the workload on our firewall, we wrote a single-purpose service dedicated to egressing IP packets on soft-unicast address space. For reasons lost in the mists of time, we named it SLATFATF, or “fish” for short. This service’s sole responsibility is to proxy IP packets using soft-unicast address space and manage the lease of those addresses.
WARP is not the only user of soft-unicast IP space in our network. Many Cloudflare products and services make use of the soft-unicast capability, and many of them use it in scenarios where we create a TCP socket in order to proxy or carry HTTP connections and other TCP-based protocols. Fish therefore needs to lease addresses that are not used by open sockets, and ensure that sockets cannot be opened to addresses leased by fish.
Our first attempt was to use distinct per-client addresses in fish and continue to let Netfilter/conntrack apply SNAT rules. However, we discovered an unfortunate interaction between Linux’s socket subsystem and the Netfilter conntrack module that reveals itself starkly when you use packet rewriting.
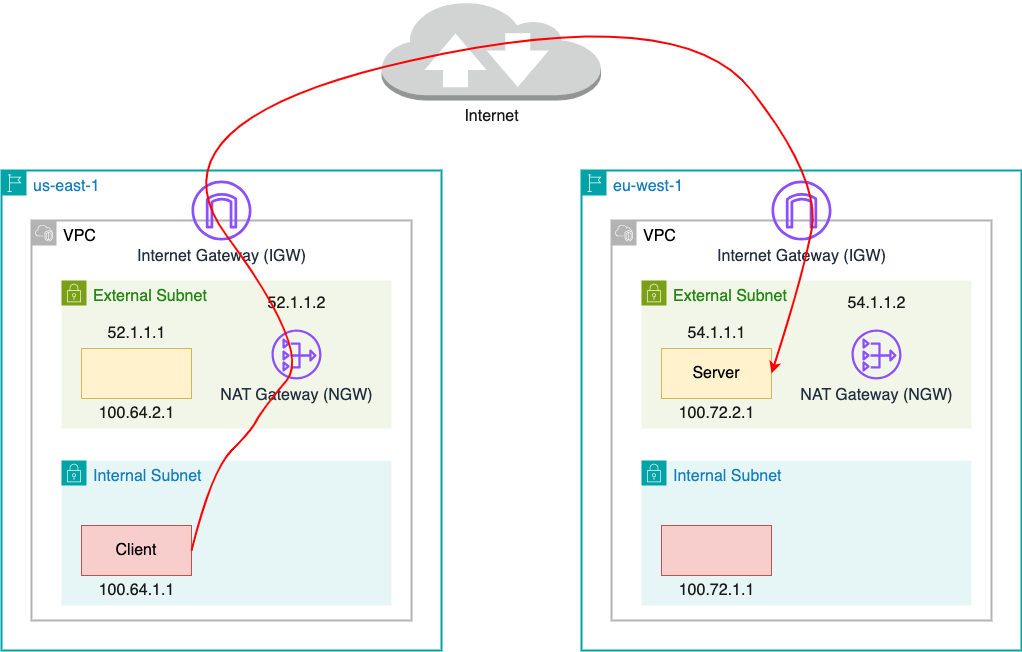
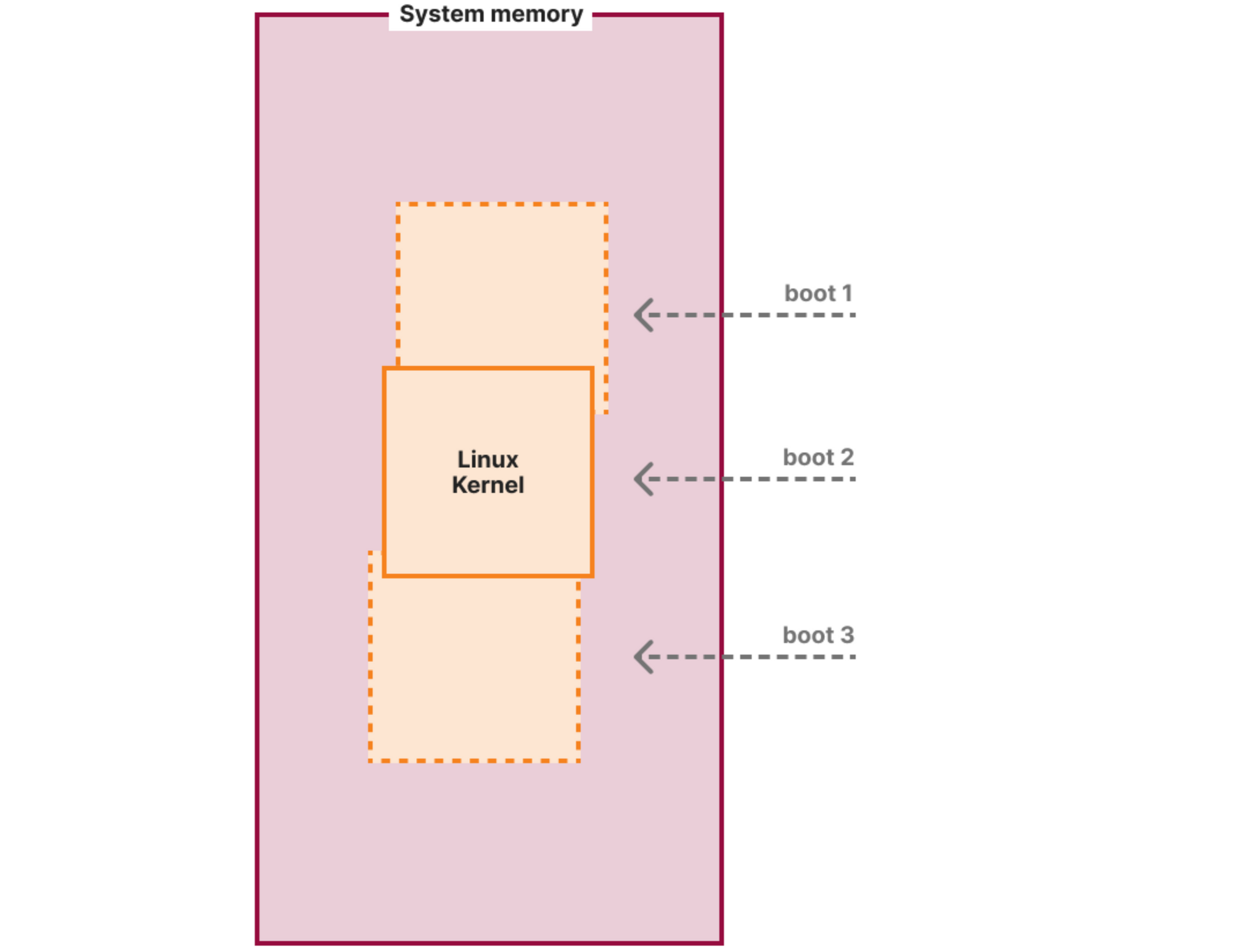
Suppose we have a soft-unicast address slice, 198.51.100.10:9000-9009. Then, suppose we have two separate processes that want to bind a TCP socket at 198.51.100.10:9000 and connect it to 203.0.113.1:443. The first process can do this successfully, but the second process will receive an error when it attempts to connect, because there is already a socket matching the requested 5-tuple.

Instead of creating sockets, what happens when we emit packets on a TUN device with the same destination IP but a unique source IP, and use source NAT to rewrite those packets to an address in this range?
If we add an nftables “snat” rule that rewrites the source address to 198.51.100.10:9000-9009, Netfilter will create an entry in the conntrack table for each new connection seen on fishtun, mapping the new source address to the original one. If we try to forward more connections on that TUN device to the same destination IP, new source ports will be selected in the requested range, until all ten available ports have been allocated; once this happens, new connections will be dropped until an existing connection expires, freeing an entry in the conntrack table.
Unlike when binding a socket, Netfilter will simply pick the first free space in the conntrack table. However, if you use up all the possible entries in the table you will get an EPERM error when writing an IP packet. Either way, whether you bind kernel sockets or you rewrite packets with conntrack, errors will indicate when there isn’t a free entry matching your requirements.
Now suppose that you combine the two approaches: a first process emits an IP packet on the TUN device that is rewritten to a packet on our soft-unicast port range. Then, a second process binds and connects a TCP socket with the same addresses as that IP packet:

The first problem is that there is no way for the second process to know that there is an active connection from 198.51.100.10:9000 to 203.0.113.1:443, at the time the connect() call is made. The second problem is that the connection is successful from the point of view of that second process.
It should not be possible for two connections to share the same 5-tuple. Indeed, they don’t. Instead, the source address of the TCP socket is silently rewritten to the next free port.

This behaviour is present even if you use conntrack without either SNAT or MASQUERADE rules. It usually happens that the lifetime of conntrack entries matches the lifetime of the sockets they’re related to, but this is not guaranteed, and you cannot depend on the source address of your socket matching the source address of the generated IP packets.
Crucially for soft-unicast, it means conntrack may rewrite our connection to have a source port outside of the port slice assigned to our machine. This will silently break the connection, causing unnecessary delays and false reports of connection timeouts. We need another solution.
For WARP, the solution we chose was to stop rewriting and forwarding IP packets, instead to terminate all TCP connections within the server and proxy them to a locally-created TCP socket with the correct soft-unicast address. This was an easy and viable solution that we already employed for a portion of our connections, such as those directed at the CDN, or intercepted as part of the Zero Trust Secure Web Gateway. However, it does introduce additional resource usage and potentially increased latency compared to the status quo. We wanted to find another way (to) forward.
If you want to use both packet rewriting and bound sockets, you need to decide on a single source of truth. Netfilter is not aware of the socket subsystem, but most of the code that uses sockets and is also aware of soft-unicast is code that Cloudflare wrote and controls. A slightly younger version of myself therefore thought it made sense to change our code to work correctly in the face of Netfilter’s design.
Our first attempt was to use the Netlink interface to the conntrack module, to inspect and manipulate the connection tracking tables before sockets were created. Netlink is an extensible interface to various Linux subsystems and is used by many command-line tools like ip and, in our case, conntrack-tools. By creating the conntrack entry for the socket we are about to bind, we can guarantee that conntrack won’t rewrite the connection to an invalid port number, and ensure success every time. Likewise, if creating the entry fails, then we can try another valid address. This approach works regardless of whether we are binding a socket or forwarding IP packets.
There is one problem with this — it’s not terribly efficient. Netlink is slow compared to the bind/connect socket dance, and when creating conntrack entries you have to specify a timeout for the flow and delete the entry if your connection attempt fails, to ensure that the connection table doesn’t fill up too quickly for a given 5-tuple. In other words, you have to manually reimplement tcp_tw_reuse option to support high-traffic destinations with limited resources. In addition, a stray RST packet can erase your connection tracking entry. At our scale, anything like this that can happen, will happen. It is not a place for fragile solutions.
Instead of creating conntrack entries, we can abuse kernel features for our own benefit. Some time ago Linux added the TCP_REPAIR socket option, ostensibly to support connection migration between servers e.g. to relocate a VM. The scope of this feature allows you to create a new TCP socket and specify its entire connection state by hand.
An alternative use of this is to create a “connected” socket that never performed the TCP three-way handshake needed to establish that connection. At least, the kernel didn’t do that — if you are forwarding the IP packet containing a TCP SYN, you have more certainty about the expected state of the world.
However, the introduction of TCP Fast Open provides an even simpler way to do this: you can create a “connected” socket that doesn’t perform the traditional three-way handshake, on the assumption that the SYN packet — when sent with its initial payload — contains a valid cookie to immediately establish the connection. However, as nothing is sent until you write to the socket, this serves our needs perfectly.
You can try this yourself:
TCP_FASTOPEN_CONNECT = 30
TCP_FASTOPEN_NO_COOKIE = 34
s = socket(AF_INET, SOCK_STREAM)
s.setsockopt(SOL_TCP, TCP_FASTOPEN_CONNECT, 1)
s.setsockopt(SOL_TCP, TCP_FASTOPEN_NO_COOKIE, 1)
s.bind(('198.51.100.10', 9000))
s.connect(('1.1.1.1', 53))Binding a “connected” socket that nevertheless corresponds to no actual socket has one important feature: if other processes attempt to bind to the same addresses as the socket, they will fail to do so. This satisfies the problem we had at the beginning to make packet forwarding coexist with socket usage.
While this solves one problem, it creates another. By default, you can’t use an IP address for both locally-originated packets and forwarded packets.
For example, we assign the IP address 198.51.100.10 to a TUN device. This allows any program to create a TCP socket using the address 198.51.100.10:9000. We can also write packets to that TUN device with the address 198.51.100.10:9001, and Linux can be configured to forward those packets to a gateway, following the same route as the TCP socket. So far, so good.
On the inbound path, TCP packets addressed to 198.51.100.10:9000 will be accepted and data put into the TCP socket. TCP packets addressed to 198.51.100.10:9001, however, will be dropped. They are not forwarded to the TUN device at all.
Why is this the case? Local routing is special. If packets are received to a local address, they are treated as “input” and not forwarded, regardless of any routing you think should apply. Behold the default routing rules:
cbranch@linux:~$ ip rule
cbranch@linux:~$ ip rule
0: from all lookup local
32766: from all lookup main
32767: from all lookup default
The rule priority is a nonnegative integer, the smallest priority value is evaluated first. This requires some slightly awkward rule manipulation to “insert” a lookup rule at the beginning that redirects marked packets to the packet forwarding service’s TUN device; you have to delete the existing rule, then create new rules in the right order. However, you don’t want to leave the routing rules without any route to the “local” table, in case you lose a packet while manipulating these rules. In the end, the result looks something like this:
ip rule add fwmark 42 table 100 priority 10
ip rule add lookup local priority 11
ip rule del priority 0
ip route add 0.0.0.0/0 proto static dev fishtun table 100
As with WARP, we simplify connection management by assigning a mark to packets coming from the “fishtun” interface, which we can use to route them back there. To prevent locally-originated TCP sockets from having this same mark applied, we assign the IP to the loopback interface instead of fishtun, leaving fishtun with no assigned address. But it doesn’t need one, as we have explicit routing rules now.
While testing this last fix, I ran into an unfortunate problem. It did not work in our production environment.
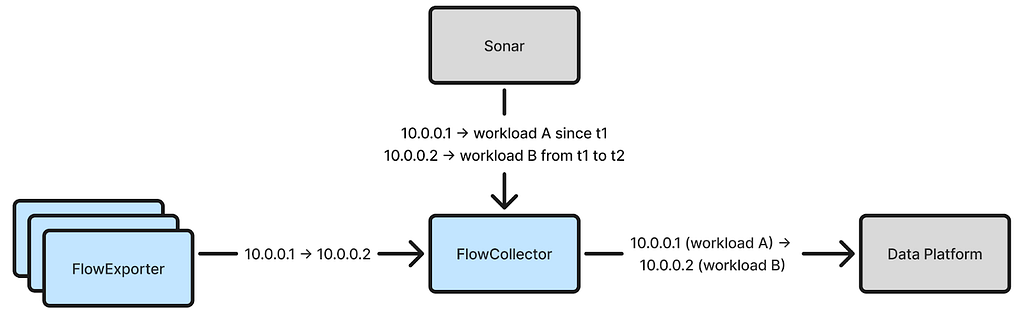
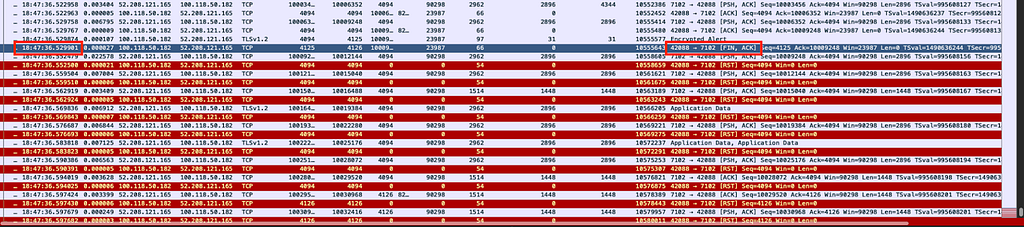
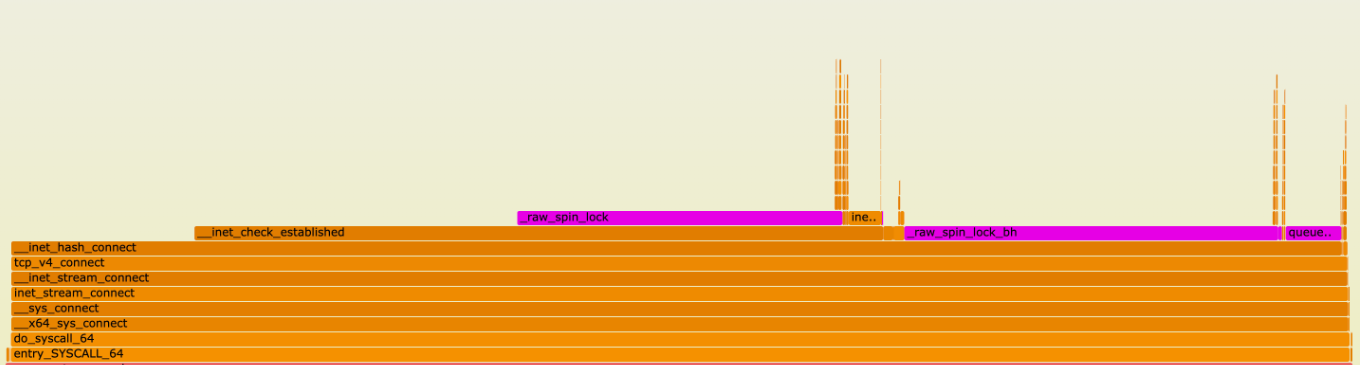
It is not simple to debug the path of a packet through Linux’s networking stack. There are a few tools you can use, such as setting nftrace in nftables or applying the LOG/TRACE targets in iptables, which help you understand which rules and tables are applied for a given packet.

Schematic for the packet flow paths through Linux networking and *tables by Jan Engelhardt
Our expectation is that the packet will pass the prerouting hook, a routing decision is made to send the packet to our TUN device, then the packet will traverse the forward table. By tracing packets originating from the IP of a test host, we could see the packets enter the prerouting phase, but disappear after the ‘routing decision’ block.
While there is a block in the diagram for “socket lookup”, this occurs after processing the input table. Our packet doesn’t ever enter the input table; the only change we made was to create a local socket. If we stop creating the socket, the packet passes to the forward table as before.
It turns out that part of the ‘routing decision’ involves some protocol-specific processing. For IP packets, routing decisions can be cached, and some basic address validation is performed. In 2012, an additional feature was added: early demux. The rationale being, at this point in packet processing we are already looking up something, and the majority of packets received are expected to be for local sockets, rather than an unknown packet or one that needs to be forwarded somewhere. In this case, why not look up the socket directly here and save yourself an extra route lookup?
Unfortunately for us, we just created a socket and didn’t want it to receive packets. Our adjustment to the routing table is ignored, because that routing lookup is skipped entirely when the socket is found. Raw sockets avoid this by receiving all packets regardless of the routing decision, but the packet rate is too high for this to be efficient. The only way around this is disabling the early demux feature. According to the patch’s claims, though, this feature improves performance: how far will performance regress on our existing workloads if we disable it?
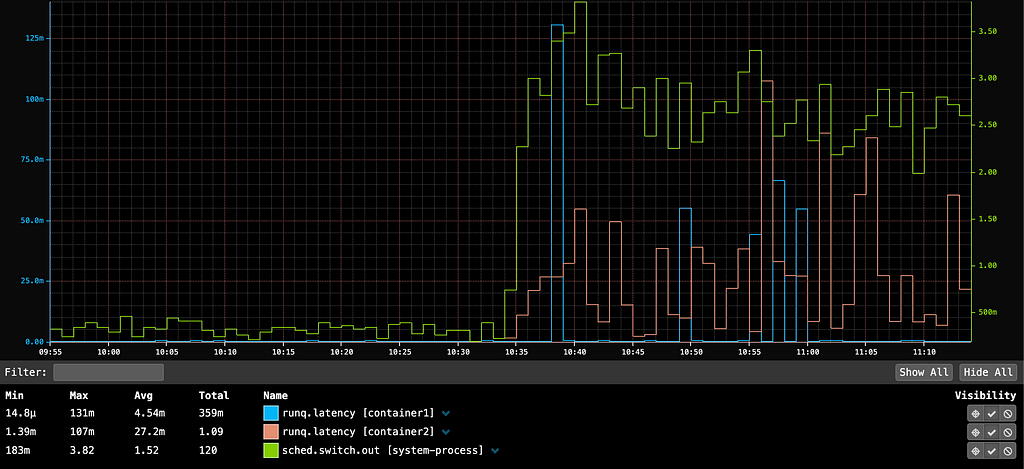
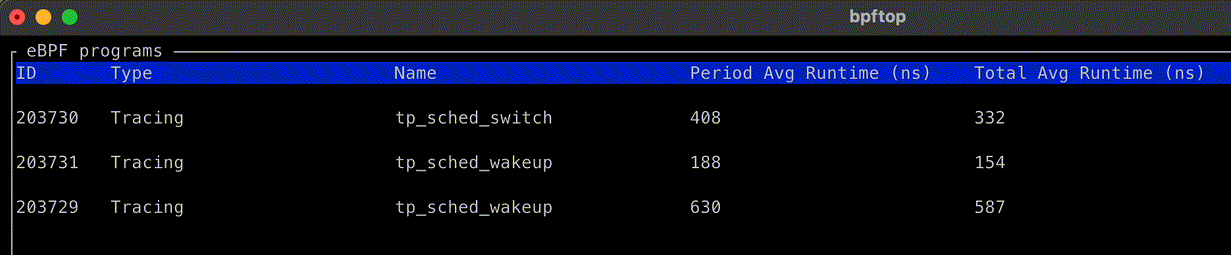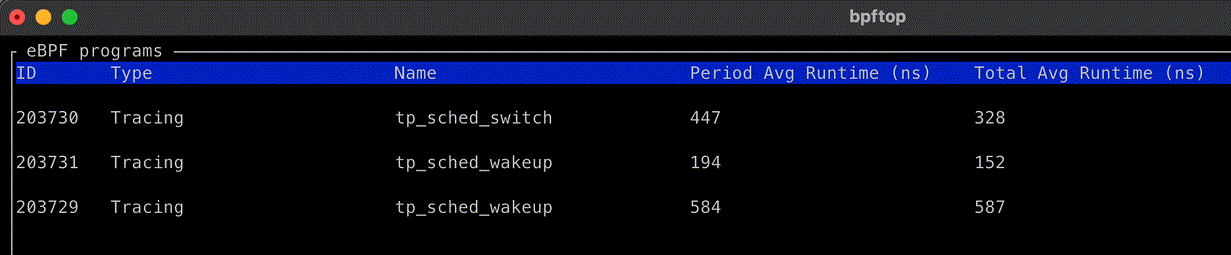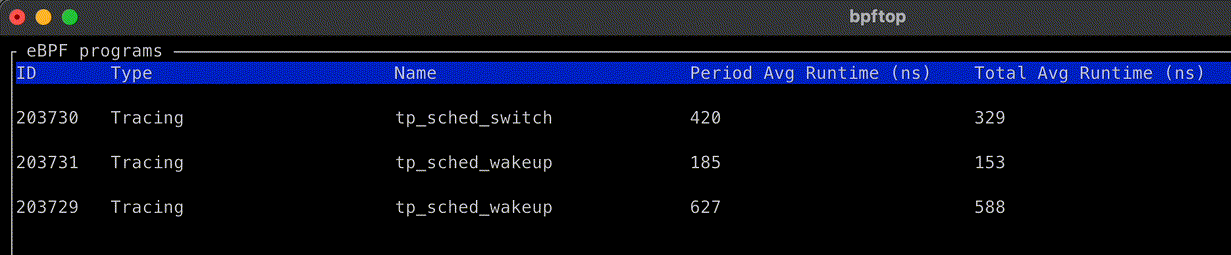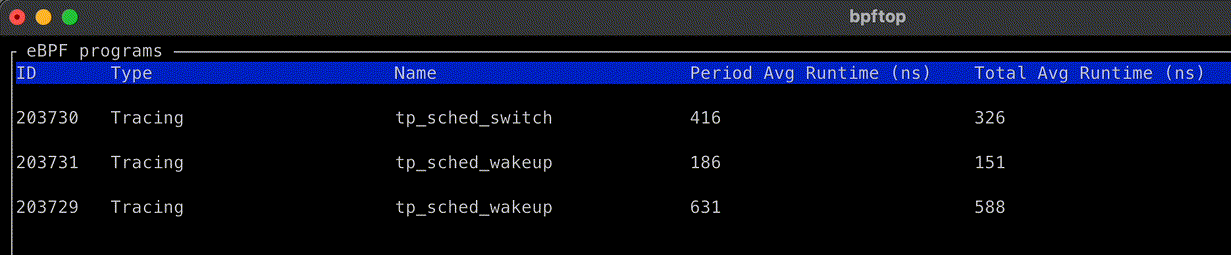
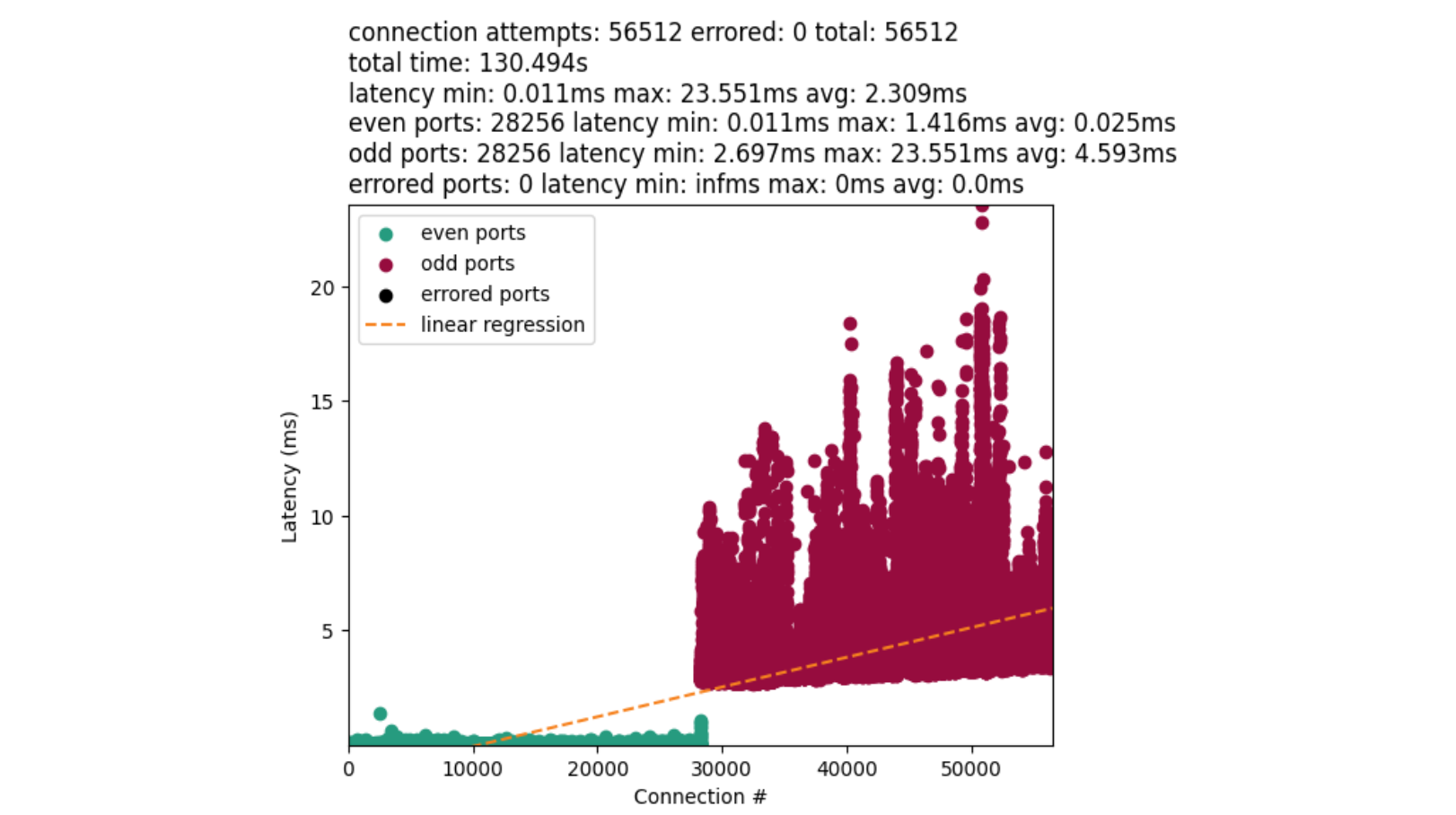
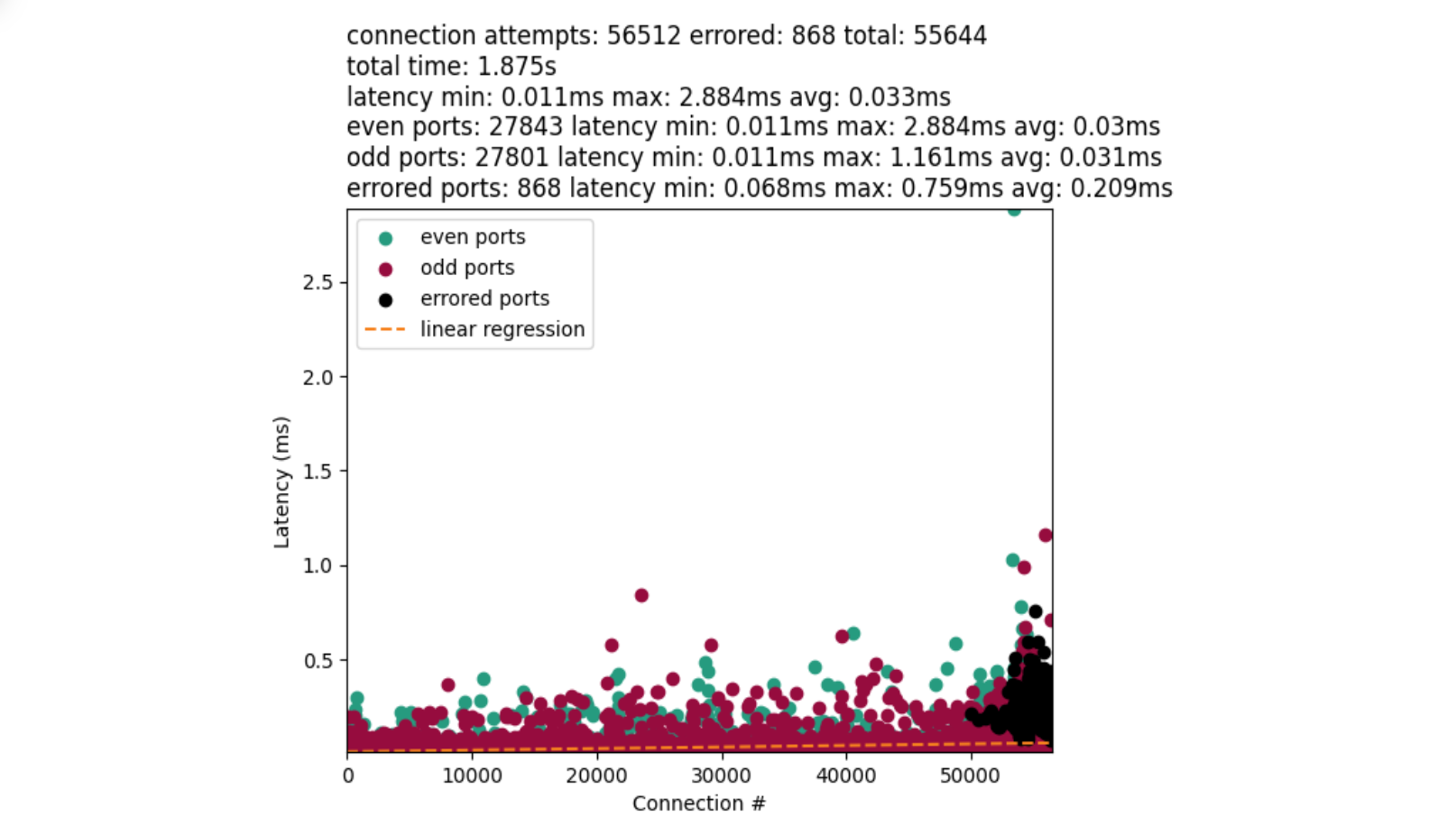
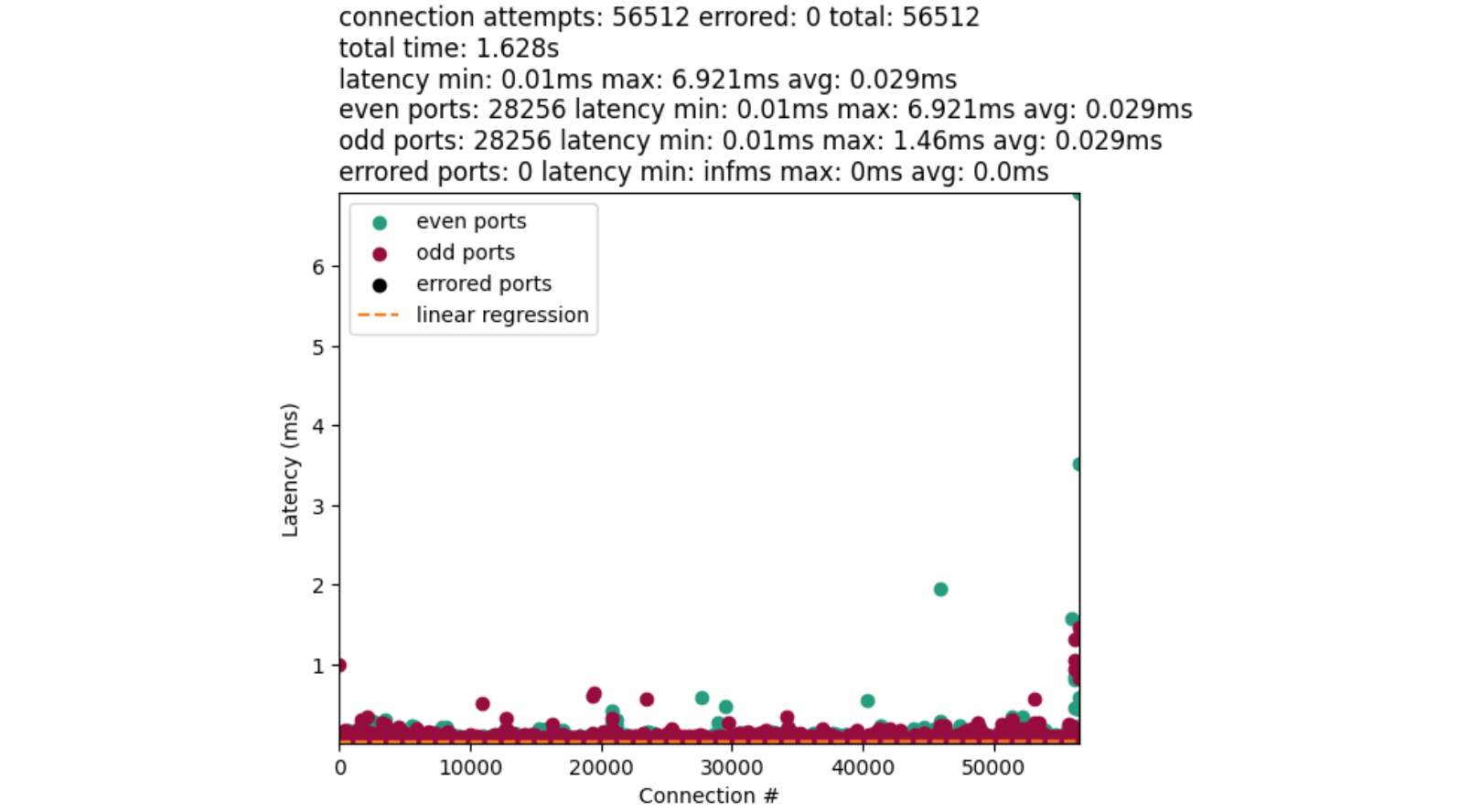
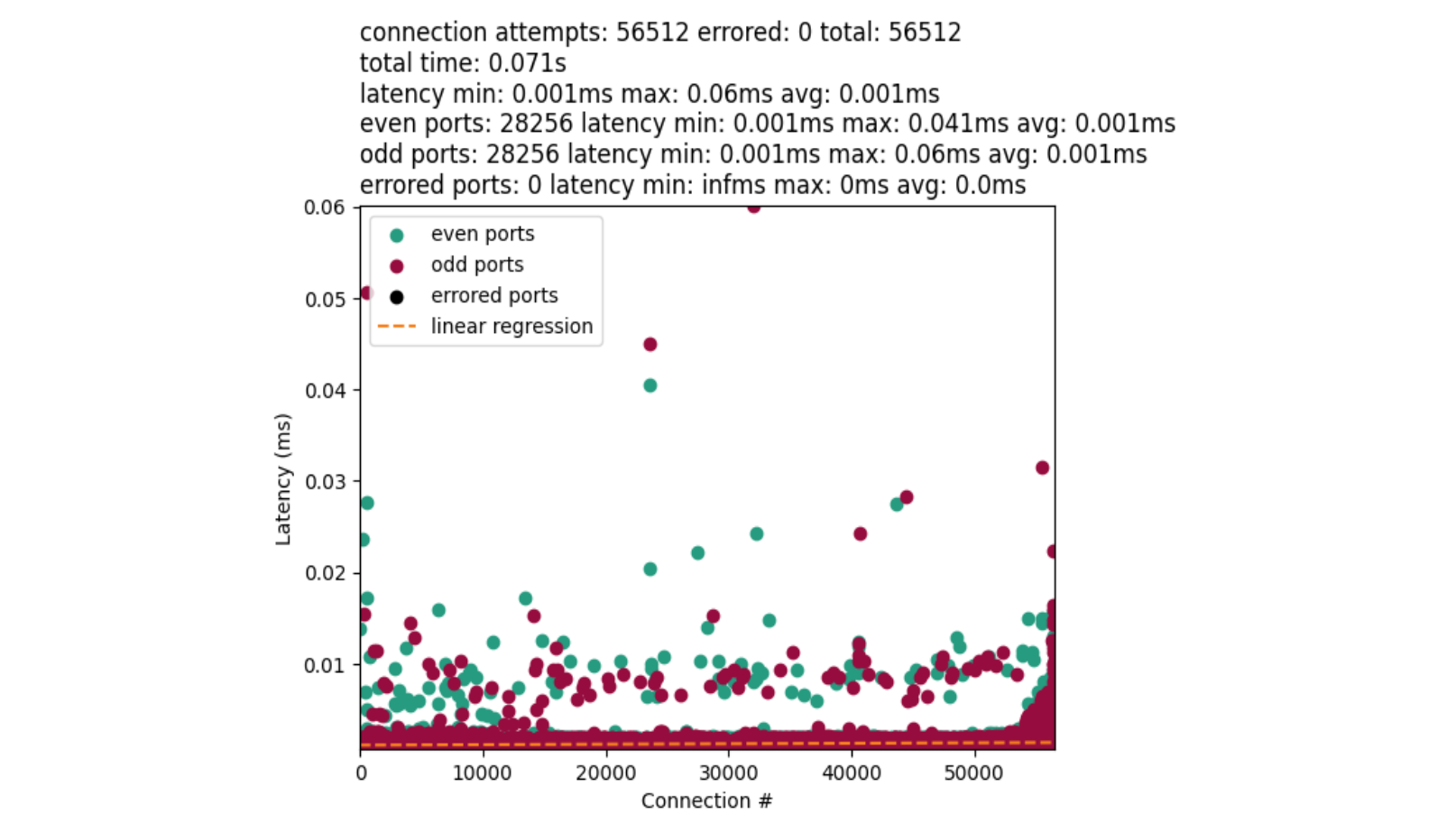
This calls for a simple experiment: set the net.ipv4.tcp_early_demux syscall to 0 on some machines in a datacenter, let it run for a while, then compare the CPU usage with machines using default settings and the same hardware configuration as the machines under test.



The key metrics are CPU usage from /proc/stat. If there is a performance degradation, we would expect to see higher CPU usage allocated to “softirq” — the context in which Linux network processing occurs — with little change to either userspace (top) or kernel time (bottom). The observed difference is slight, and mostly appears to reduce efficiency during off-peak hours.
While we tested different solutions to IP packet forwarding, we continued to terminate TCP connections on our network. Despite our initial concerns, the performance impact was small, and the benefits of increased visibility into origin reachability, fast internal routing within our network, and simpler observability of soft-unicast address usage flipped the burden of proof: was it worth trying to implement pure IP forwarding and supporting two different layers of egress?
So far, the answer is no. Fish runs on our network today, but with the much smaller responsibility of handling ICMP packets. However, when we decide to tunnel all IP packets, we know exactly how to do it.
A typical engineering role at Cloudflare involves solving many strange and difficult problems at scale. If you are the kind of goal-focused engineer willing to try novel approaches and explore the capabilities of the Linux kernel despite minimal documentation, look at our open positions — we would love to hear from you!































{kind=link}