Post Syndicated from Lorenzo Nicora original https://aws.amazon.com/blogs/big-data/achieve-full-control-over-your-data-encryption-using-customer-managed-keys-in-amazon-managed-service-for-apache-flink/
Encryption of both data at rest and in transit is a non-negotiable feature for most organizations. Furthermore, organizations operating in highly regulated and security-sensitive environments—such as those in the financial sector—often require full control over the cryptographic keys used for their workloads.
Amazon Managed Service for Apache Flink makes it straightforward to process real-time data streams with robust security features, including encryption by default to help protect your data in transit and at rest. The service removes the complexity of managing the key lifecycle and controlling access to the cryptographic material.
If you need to retain full control over your key lifecycle and access, Managed Service for Apache Flink now supports the use of customer managed keys (CMKs) stored in AWS Key Management Service (AWS KMS) for encrypting application data.
This feature helps you manage your own encryption keys and key policies, so you can meet strict compliance requirements and maintain complete control over sensitive data. With CMK integration, you can take advantage of the scalability and ease of use that Managed Service for Apache Flink offers, while meeting your organization’s security and compliance policies.
In this post, we explore how the CMK functionality works with Managed Service for Apache Flink applications, the use cases it unlocks, and key considerations for implementation.
Data encryption in Managed Service for Apache Flink
In Managed Service for Apache Flink, there are multiple aspects where data should be encrypted:
- Data at rest directly managed by the service – Durable application storage (checkpoints and snapshots) and running application state storage (disk volumes used by RocksDB state backend) are automatically encrypted
- Data in transit internal to the Flink cluster – Automatically encrypted using TLS/HTTPS
- Data in transit to and at rest in external systems that your Flink application accesses – For example, an Amazon Managed Streaming for Apache Kafka (Amazon MSK) topic through the Kafka connector or calling an endpoint through a custom AsyncIO); encryption depends on the external service, user settings, and code
For data at rest managed by the service, checkpoints, snapshots, and running application state storage are encrypted by default using AWS owned keys. If your security requirements require you to directly control the encryption keys, you can use the CMK held in AWS KMS.
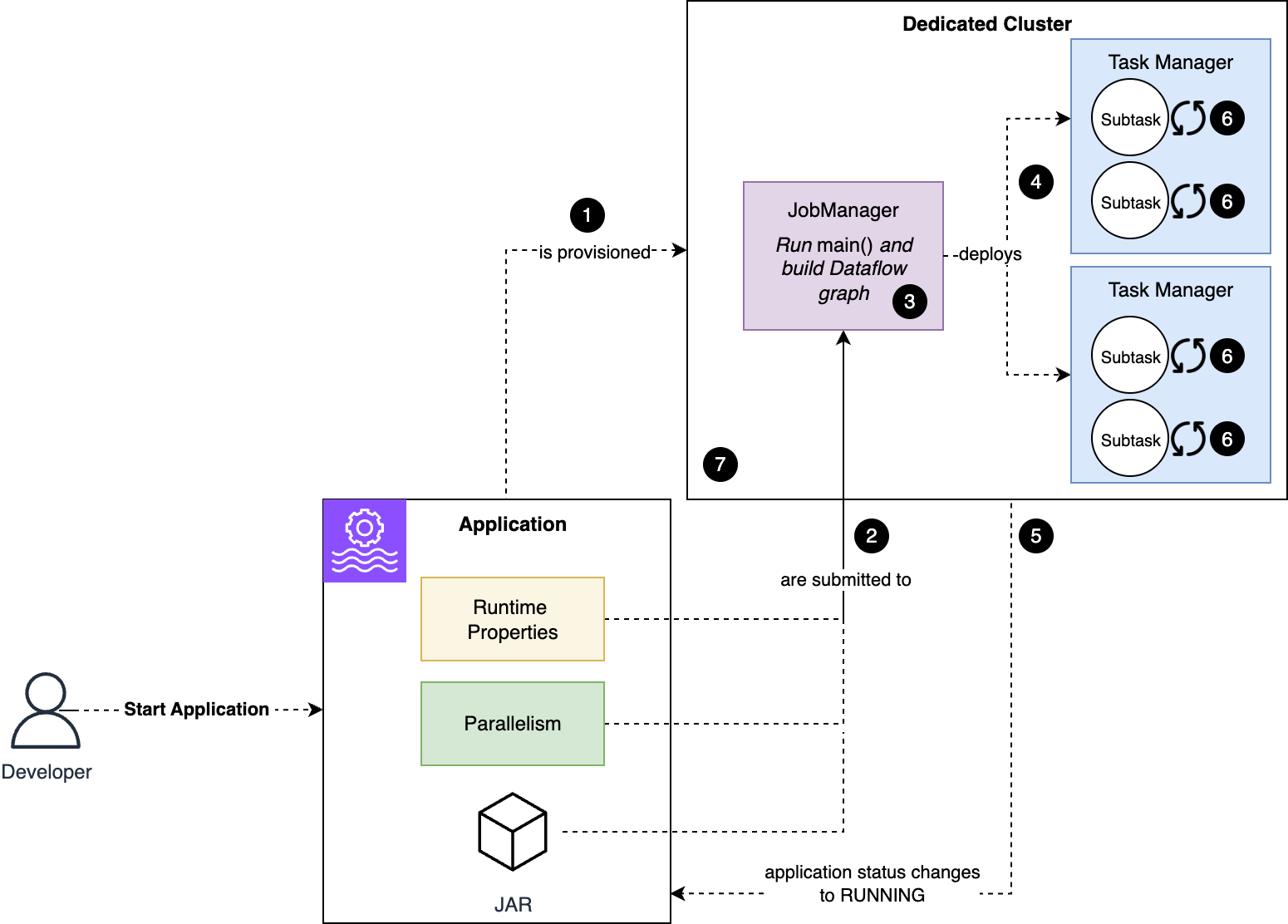
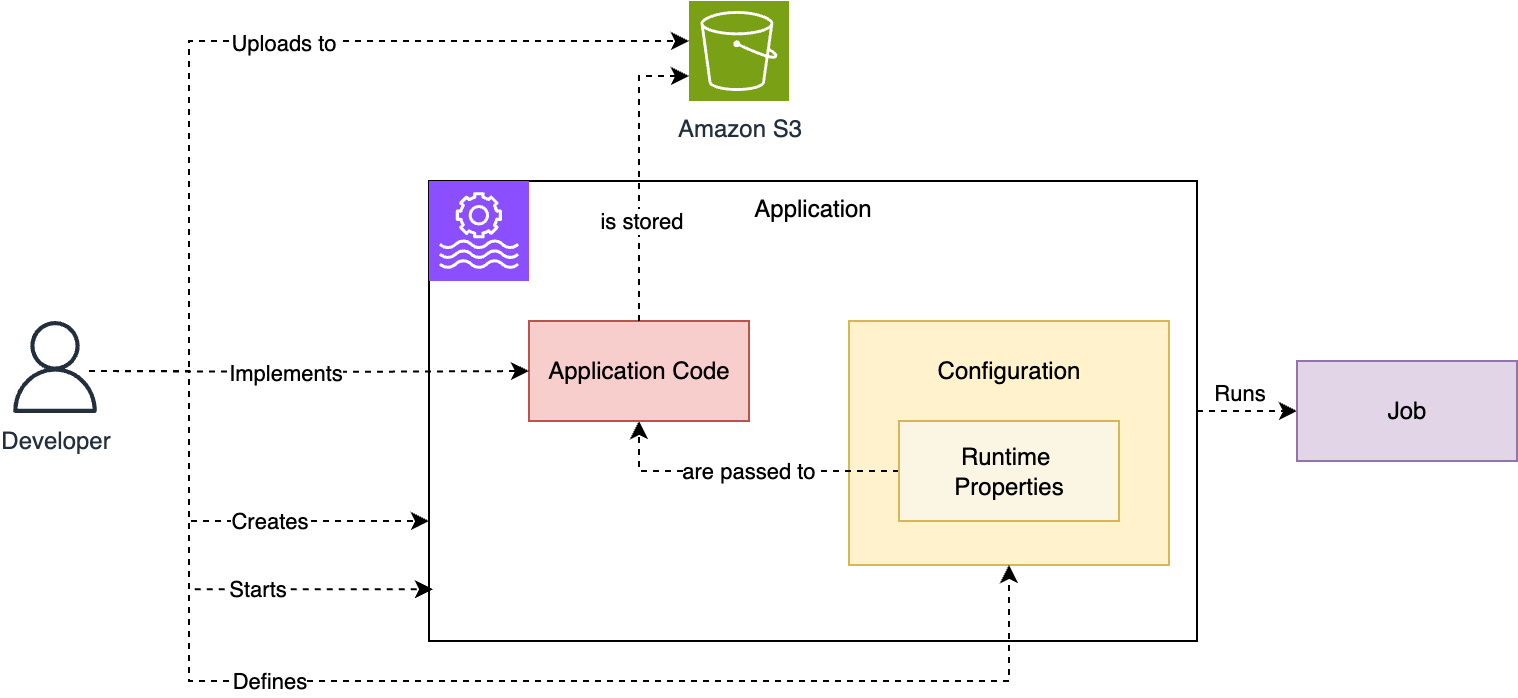
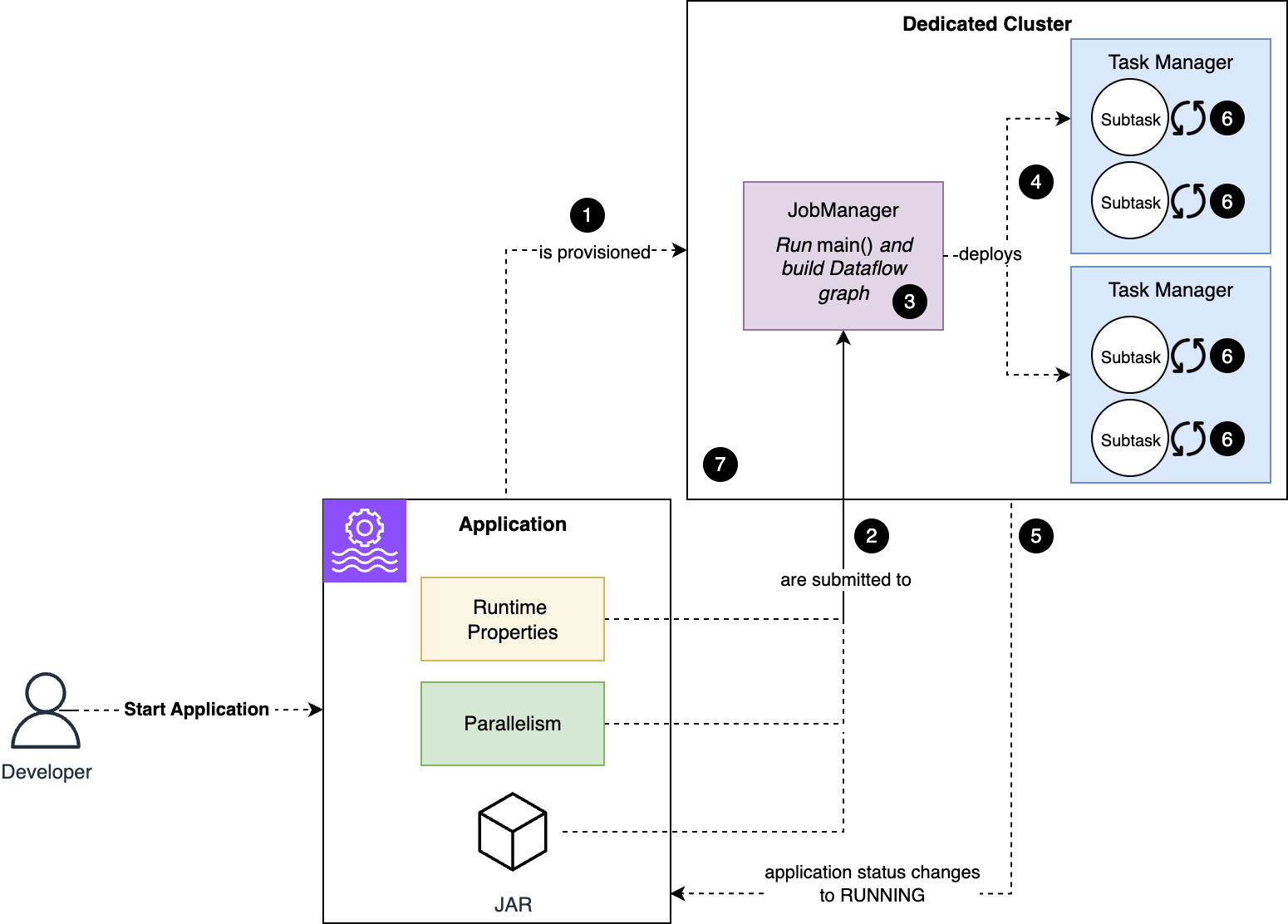
Key components and roles
To understand how CMKs work in Managed Service for Apache Flink, we first need to introduce the components and roles involved in managing and running an application using CMK encryption:
- Customer managed key (CMK):
- Resides in AWS KMS within the same AWS account as your application
- Has an attached key policy that defines access permissions and usage rights to other components and roles
- Encrypts both durable application storage (checkpoints and snapshots) and running application state storage
- Managed Service for Apache Flink application:
- The application whose storage you want to encrypt using the CMK
- Has an attached AWS Identity and Access Management (IAM) execution role that grants permissions to access external services
- The execution role doesn’t have to provide any specific permissions to use the CMK for encryption operations
- Key administrator:
- Manages the CMK lifecycle (creation, rotation, policy updates, and so on)
- Can be an IAM user or IAM role, and used by a human operator or by automation
- Requires administrative access to the CMK
- Permissions are defined by the attached IAM policies and the key policy
- Application operator:
- Manages the application lifecycle (start/stop, configuration updates, snapshot management, and so on)
- Can be an IAM User or IAM role, and used by a human operator or by automation
- Requires permissions to manage the Flink application and use the CMK for encryption operations
- Permissions are defined by the attached IAM policies and the key policy
The following diagram illustrates the solution architecture.
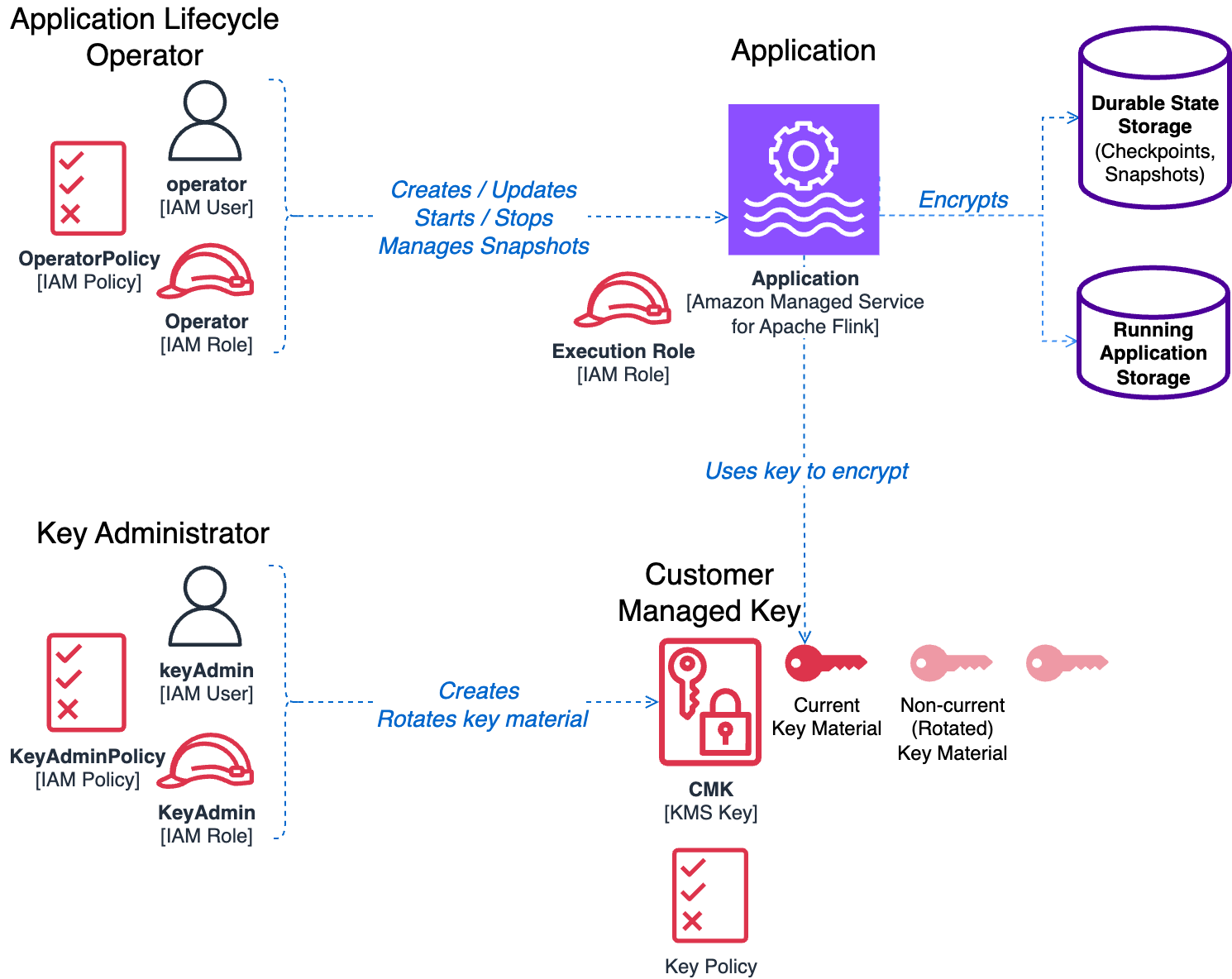
Enabling CMK following the principle of least privilege
When deploying applications in production environments or handling sensitive data, you should follow the principle of least privilege. CMK support in Managed Service for Apache Flink has been designed with this principle in mind, so each component receives only the minimum permissions necessary to function.
For detailed information about the permissions required by the application operator and key policy configurations, refer to Key management in Amazon Managed Service for Apache Flink. Although these policies might appear complex at first glance, this complexity is intentional and necessary. For more details about the requirements for implementing the most restrictive key management possible while maintaining functionality, refer to Least-privilege permissions.
For this post, we highlight some important points about CMK permissions:
- Application execution role – Requires no additional permissions to use a CMK. You don’t need to change the permissions of an existing application; the service handles CMK operations transparently during runtime.
- Application operator permissions – The operator is the user or role who controls the application lifecycle. For the permissions required to operate an application that uses CMK encryption, refer to Key management in Amazon Managed Service for Apache Flink. In addition to these permissions, an operator normally has permissions on actions with the
kinesisanalyticsprefix. It is a best practice to restrict these permissions to a specific application defining theResource. The operator must also have theiam:PassRolepermission to pass the service execution role to the application.
To simplify managing the permissions of the operator, we recommend creating two separate IAM policies, to be attached to the operator’s role or user:
- A base operator policy defining the basic permissions to operate the application lifecycle without a CMK
- An additional CMK operator policy that adds permissions to operate the application with a CMK
The following IAM policy example illustrates the permissions that should be included in the base operator policy:
Refer to Application lifecycle operator (API caller) permissions for the permissions to be included with the additional CMK operator policy.
Separating these two policies has an additional benefit of simplifying the process of setting up an application for the CMK, due to the dependencies we illustrate in the following section.
Dependencies between the key policy and CMK operator policy
If you carefully observe the operator’s permissions and the key policy explained in Create a KMS key policy, you will notice some interdependencies, illustrated by the following diagram.
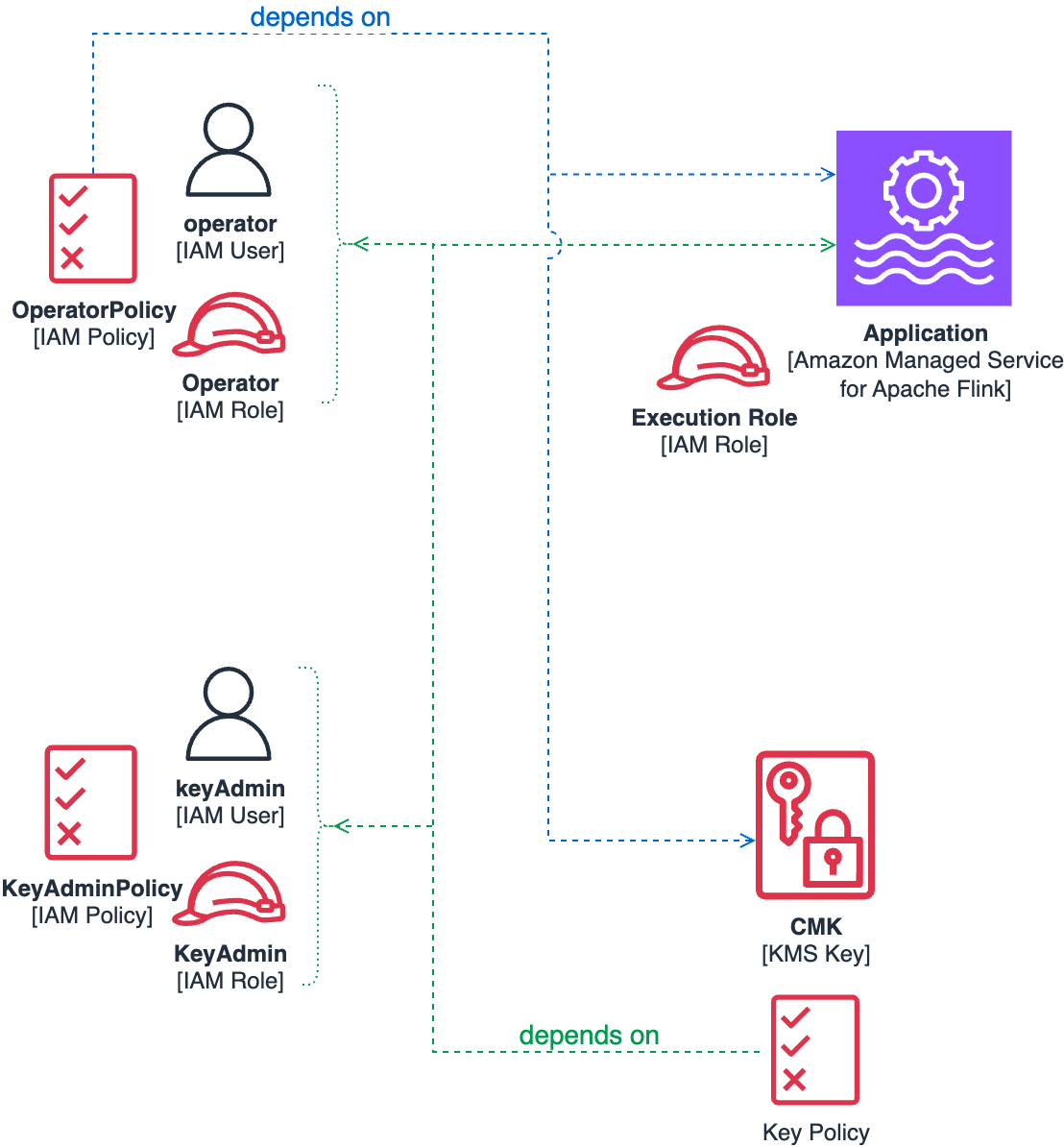
In particular, we highlight the following:
- CMK key policy dependencies – The CMK policy requires references to both the application Amazon Resource Name (ARN) and the key administrator or operator IAM roles or users. This policy must be defined at key creation time by the key administrator.
- IAM policy dependencies – The operator’s IAM policy must reference both the application ARN and the CMK key itself. The operator role is responsible for various tasks, including configuring the application to use the CMK.
To properly follow the principle of least privilege, each component requires the others to exist before it can be correctly configured. This necessitates a carefully orchestrated deployment sequence.
In the following section, we demonstrate the precise order required to resolve these dependencies while maintaining security best practices.
Sequence of operations to create a new application with a CMK
When deploying a new application that uses CMK encryption, we recommend following this sequenced approach to resolve dependency conflicts while maintaining security best practices:
- Create the operator IAM role or user with a base policy that includes application lifecycle permissions. Do not include CMK permissions at this stage, because the key doesn’t exist yet.
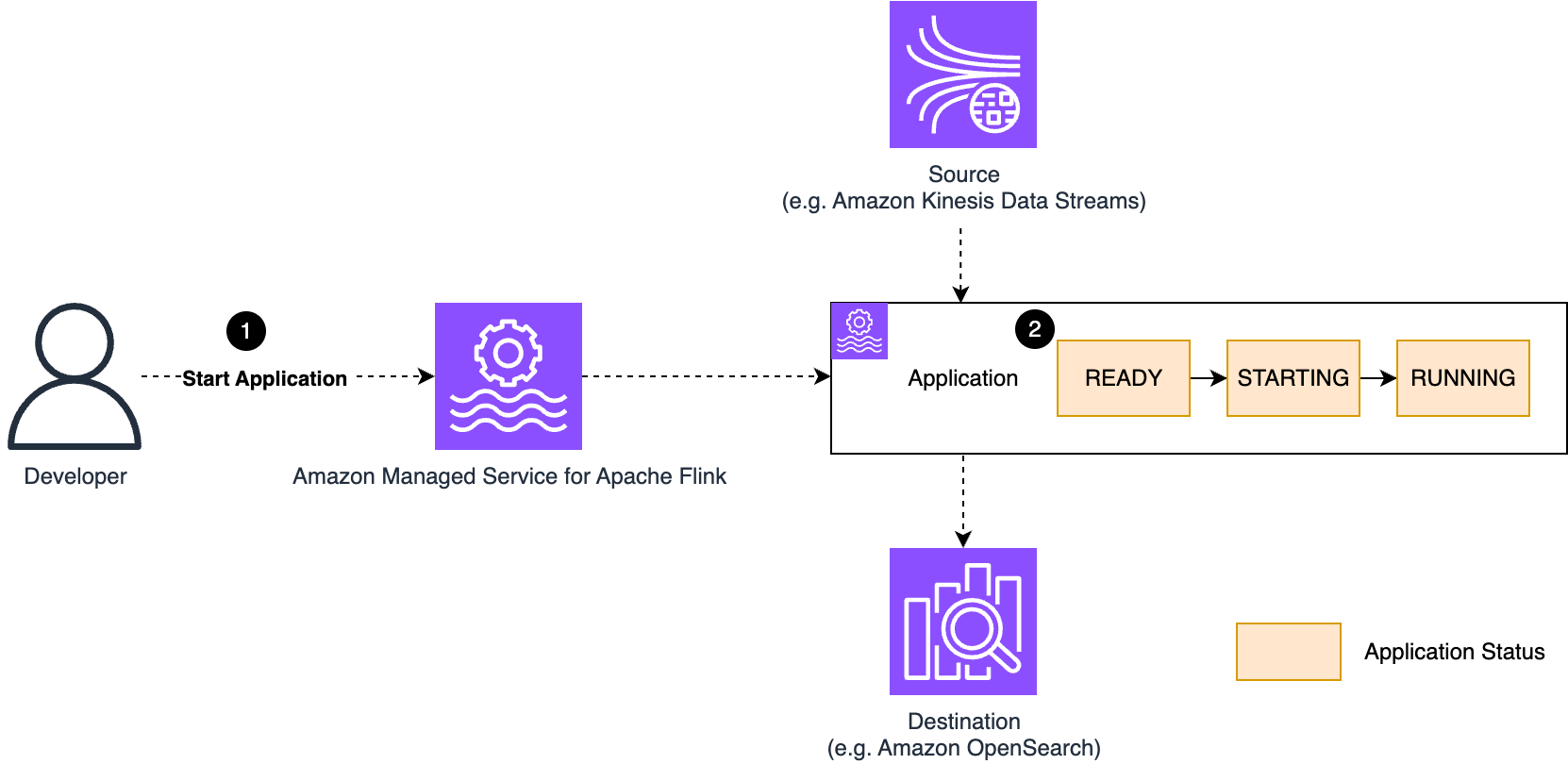
- The operator creates the application using the default AWS owned key. Keep the application in a stopped state to prevent data creation—there should be no data at rest to encrypt during this phase.
- Create the key administrator IAM role or user, if not already available, with permissions to create and manage KMS keys. Refer to Using IAM policies with AWS KMS for detailed permission requirements.
- The key administrator creates the CMK in AWS KMS. At this point, you have the required components for the key policy: application ARN, operator IAM role or user ARN, and key administrator IAM role or user ARN.
- Create and attach to the operator an additional IAM policy that includes the CMK-specific permissions. See Application lifecycle operator (API caller) permissions for the complete operator policy definition.
- The operator can now modify the application configuration using the
UpdateApplicationaction, to enable CMK encryption, as illustrated in the following section. - The application is now ready to run with all data at rest encrypted using your CMK.
Enable the CMK with UpdateApplication
You can configure a Managed Service for Apache Flink application to use a CMK using the AWS Management Console, the AWS API, AWS Command Line Interface (AWS CLI), or infrastructure as code (IaC) tools like the AWS Cloud Development Kit (AWS CDK) or AWS CloudFormation templates.
When setting up CMK encryption in a production environment, you will probably use an automation tool rather than the console. These tools eventually use the AWS API under the hood, and the UpdateApplication action of the kinesisanalyticsv2 API in particular. In this post, we analyze the additions to the API that you can use to control the encryption configuration.
An additional top-level block ApplicationEncryptionConfigurationUpdate has been added to the UpdateApplication request payload. With this block, you can enable and disable the CMK.
You must add the following block to the UpdateApplication request:
The KeyIdUpdate value can be the key ARN, key ID, key alias name, or key alias ARN.
Disable the CMK
Similarly, the following requests disable the CMK, switching back to the default AWS owned key:
Enable the CMK with CreateApplication
Theoretically, you can enable the CMK directly when you first create the application using the CreateApplication action.
A top-level block ApplicationEncryptionConfiguration has been added to the CreateApplication request payload, with a syntax similar to UpdateApplication.
However, due to the interdependencies described in the previous section, you will most often create an application with the default AWS owned key and later use UpdateApplication to enable the CMK.
If you omit ApplicationEncryptionConfiguration when you create the application, the default behavior is using the AWS owned key, for backward compatibility.
Sample CloudFormation templates to create IAM roles and the KMS key
The process you use to create the roles and key and configure the application to use the CMK will vary, depending on the automation you use and your approval and security processes. Any automation example we can provide will likely not fit your processes or tooling.
However, the following GitHub repository provides some example CloudFormation templates to generate some of the IAM policies and the KMS key with the correct key policy:
- IAM policy for the key administrator – Allows managing the key
- Base IAM policy for the operator – Allows managing the normal application lifecycle operations without the CMK
- CMK IAM policy for the operator – Provides additional permissions required to manage the application lifecycle when the CMK is enabled
- KMS key policy – Allows the application to encrypt and decrypt the application state and the operator to manage the application operations
CMK operations
We have described the process of creating a new Managed Service for Apache Flink application with CMK. Let’s now examine other common operations you can perform.
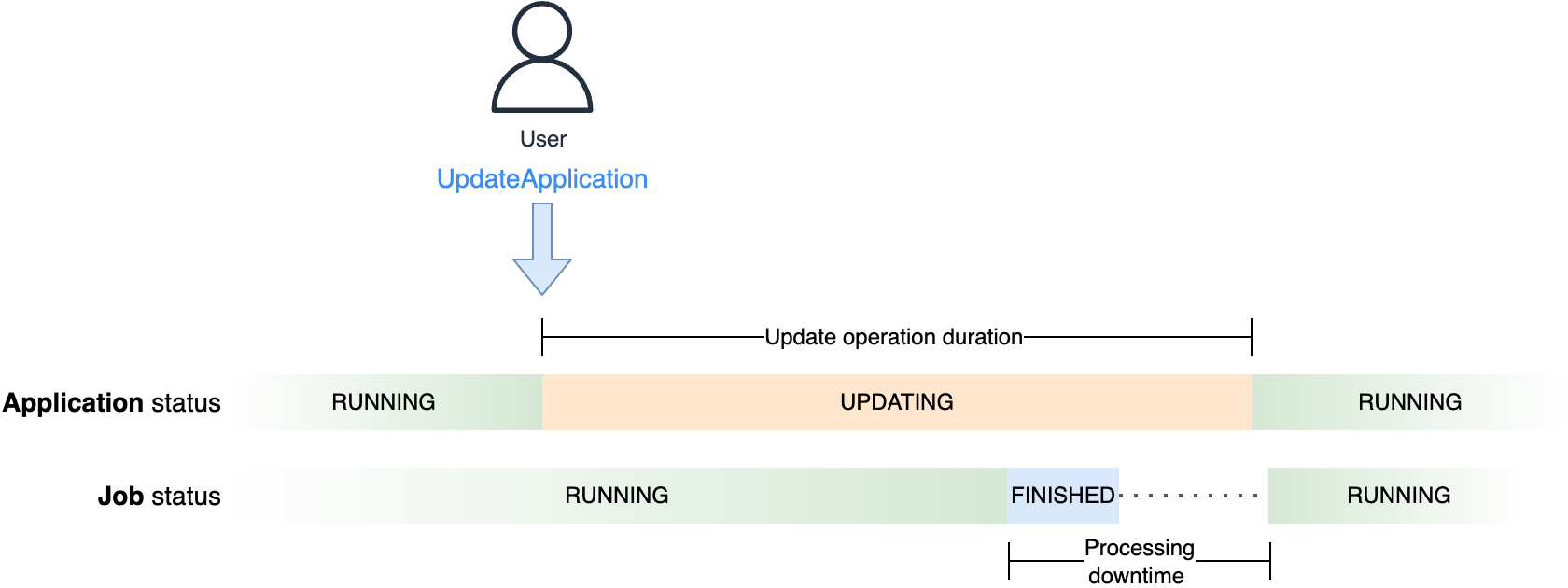
Changes to the encryption key become effective when the application is restarted. If you update the configuration of a running application, this causes the application to restart and the new key to be used immediately. Conversely, if you change the key of a READY (not running) application, the new key is not actually used until the application is restarted.
Enable a CMK on an existing application
If you have an application running with an AWS owned key, the process is similar to what we described for creating new applications. In this case, you already have a running application state and older snapshots that are encrypted using the AWS owned key.
Also, if you have a running application, you probably already have an operator role with an IAM policy that you can use to control the operator lifecycle.
The sequence of steps to enable a CMK on an existing and running application is as follows:
- If you don’t already have one, create a key administrator IAM role or user with permissions to create and manage keys in AWS KMS. See Using IAM policies with AWS KMS for more details about the permissions required to manage keys.
- The key administrator creates the CMK. The key policy references the application ARN, the operator’s ARN, and the key administrator’s role or user ARN.
- Create an additional IAM policy that allows the use of the CMK and attach this policy to the operator. Alternatively, modify the operator’s existing IAM policy by adding these permissions.
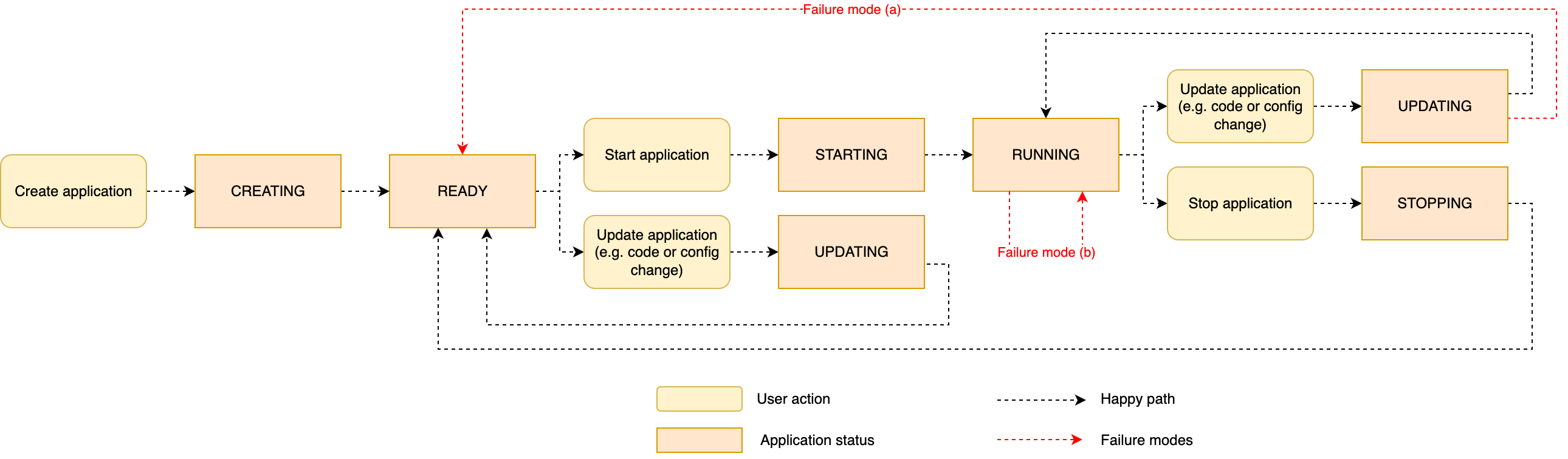
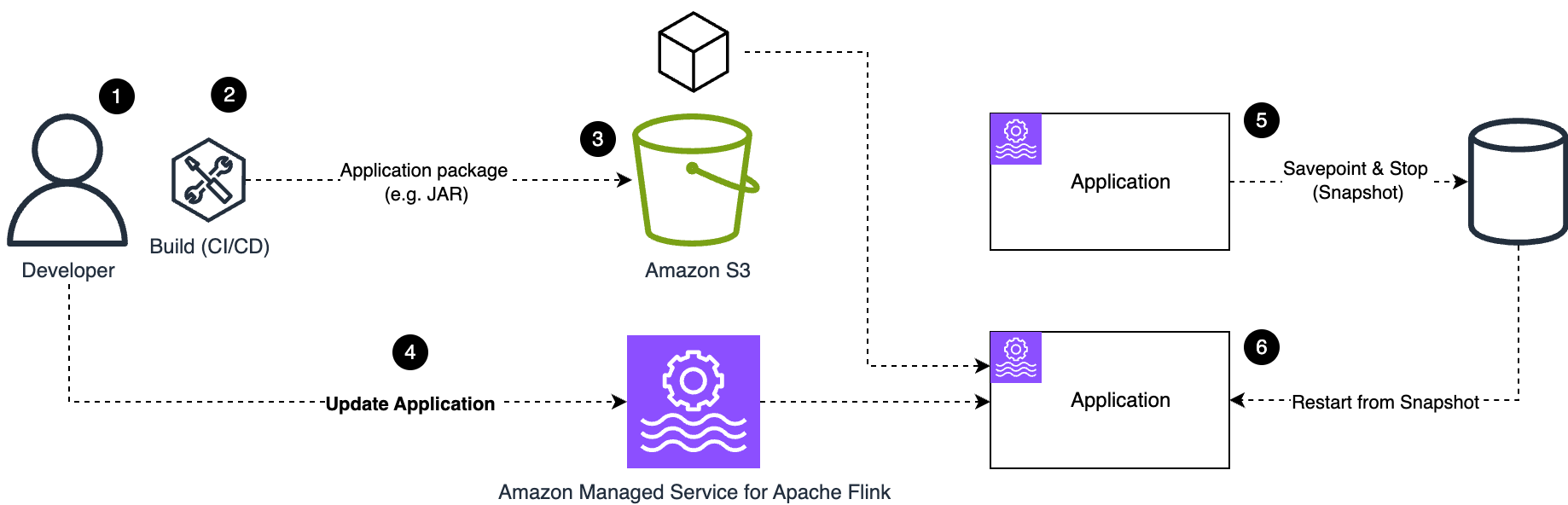
- Finally, the operator can update the application and enable the CMK.The following diagram illustrates the process that occurs when you execute an
UpdateApplicationaction on the running application to enable a CMK.
The workflow consists of the following steps:
- When you update the application to set up the CMK, the following happens:
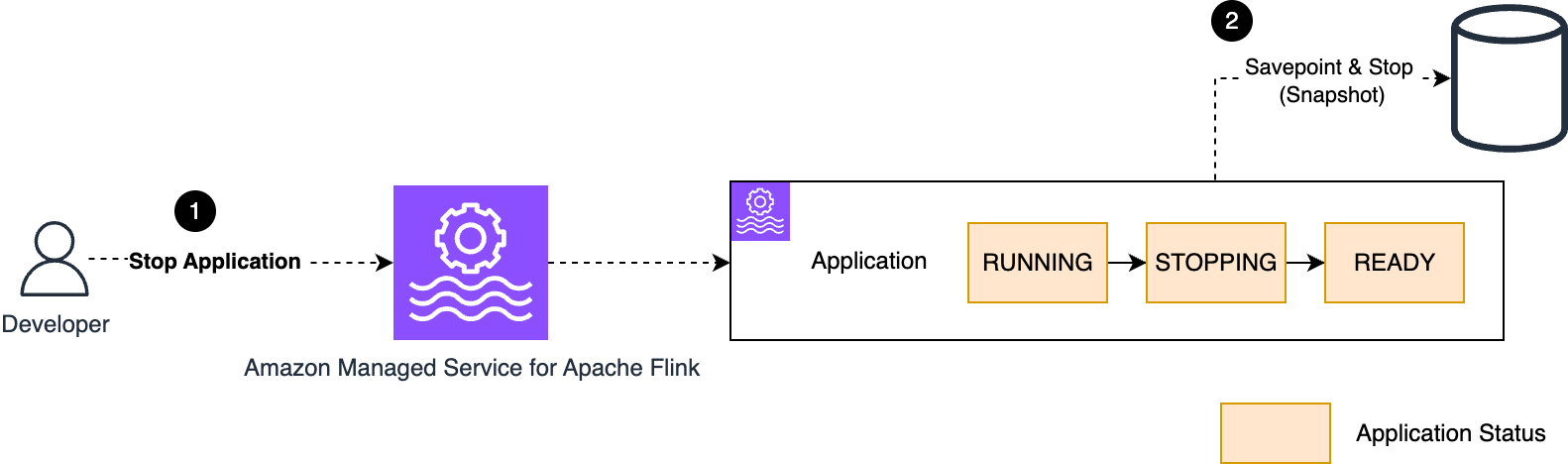
- The application running state, at the moment it is encrypted with the AWS owned key, is saved in a snapshot while the application is stopped. This snapshot is encrypted with the default AWS owned key. The running application state storage is volatile and destroyed when the application is stopped.
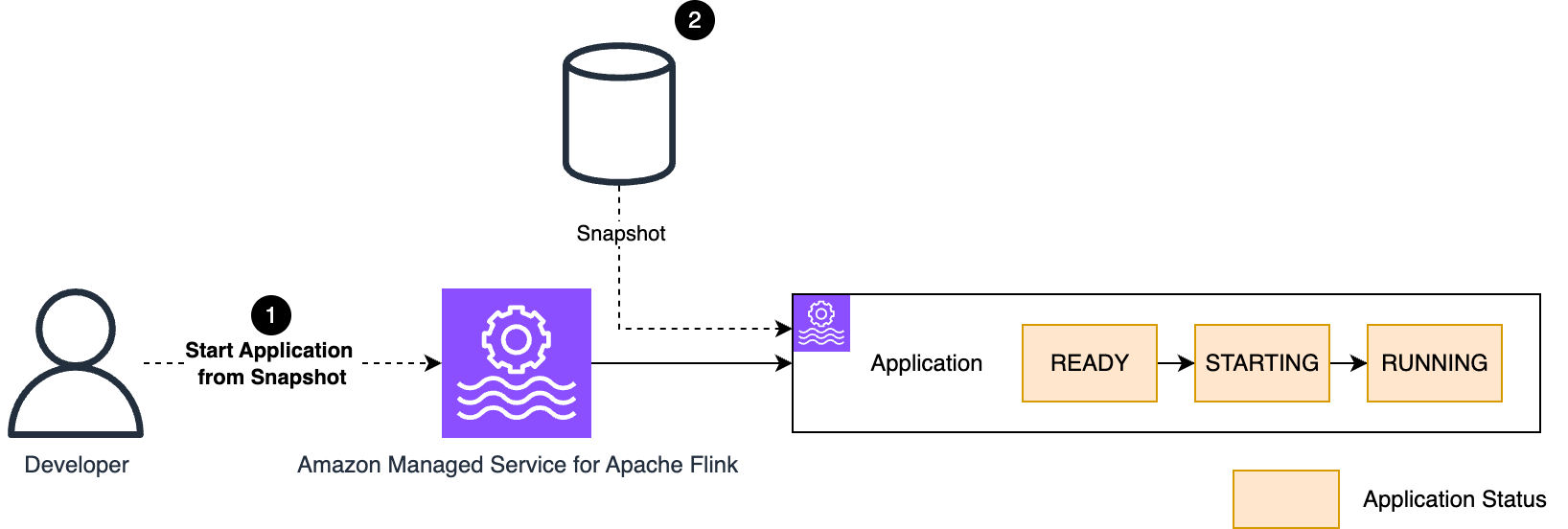
- The application is redeployed, restoring the snapshot into the running application state.
- The running application state storage is now encrypted with the CMK.
- New snapshots created from this point on are encrypted using the CMK.
- You will probably want to delete all the old snapshots, including the one created automatically by the
UpdateApplicationthat enabled the CMK, because they are all encrypted using the AWS owned key.
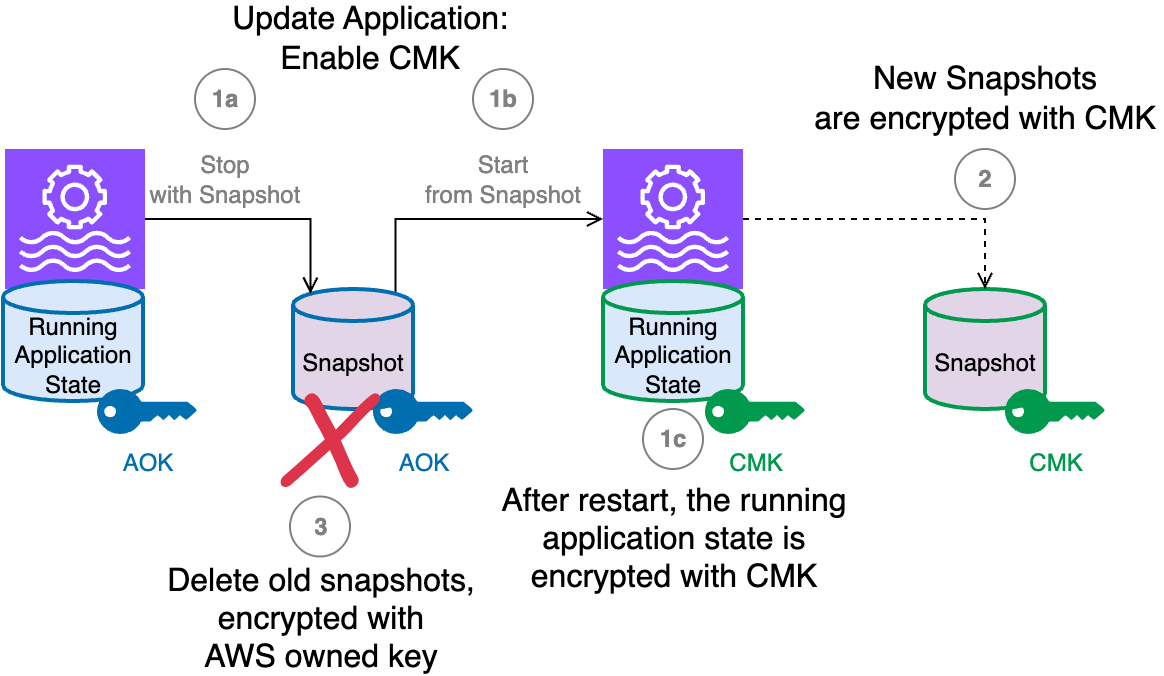
Rotate the encryption key
As with any cryptographic key, it’s a best practice to rotate the key periodically for enhanced security. Managed Service for Apache Flink does not support AWS KMS automatic key rotation, so you have two primary options for rotating your CMK.
Option 1: Create a new CMK and update the application
The first approach involves creating an entirely new KMS key and then updating your application configuration to use the new key. This method provides a clean separation between the old and new encryption keys, making it easier to track which data was encrypted with which key version.
Let’s assume you have a running application using CMK#1 (the current key) and want to rotate to CMK#2 (the new key) for enhanced security:
- Prerequisites and preparation – Before initiating the key rotation process, you must update the operator’s IAM policy to include permissions for both CMK#1 and CMK#2. This dual-key access supports uninterrupted operation during the transition period. After the application configuration has been successfully updated and verified, you can safely remove all permissions to CMK#1.
- Application update process – The
UpdateApplicationoperation used to configure CMK#2 automatically triggers an application restart. This restart mechanism makes sure both the application’s running state and any newly created snapshots are encrypted using the new CMK#2, providing immediate security benefits from the updated encryption key. - Important security considerations – Existing snapshots, including the automatic snapshot created during the CMK update process, remain encrypted with the original CMK#1. For complete security hygiene and to minimize your cryptographic footprint, consider deleting these older snapshots after verifying that your application is functioning correctly with the new encryption key.
This approach provides a clean separation between old and new encrypted data while maintaining application availability throughout the key rotation process.
Option 2: Rotate the key material of the existing CMK
The second option is to rotate the cryptographic material within your existing KMS key. For a CMK used for Managed Service for Apache Flink, we recommend using on-demand key material rotation.
The benefit of this approach is simplicity: no change is required to the application configuration nor to the operator’s IAM permissions.
Important security considerations
The new encryption key is used by the Managed Service for Apache Flink application only after the next application restart. To make the new key material effective, immediately after the rotation, you need to stop and start using snapshots to preserve the application state or execute an UpdateApplication, which also forces a stop-and-restart. After the restart, you should consider deleting the old snapshots, including the one taken automatically in the last stop-and-restart.
Switch back to the AWS owned key
At any time, you can decide to switch back to using an AWS owned key. The application state is still encrypted, but using the AWS owned key instead of your CMK.
If you are using the UpdateApplication API or AWS CLI command to switch back to CMK, you must explicitly pass ApplicationEncryptionConfigurationUpdate, setting the key type to AWS_OWNED_KEY as shown in the following snippet:
When you execute UpdateApplication to switch off the CMK, the operator must still have permissions on the CMK. After the application is successfully running using the AWS owned key, you can safely remove any CMK-related permissions from the operator’s IAM policy.
Test the CMK in development environments
In a production environment—or an environment containing sensitive data—you should follow the principle of least privilege and apply the restrictive permissions described so far.
However, if you want to experiment with CMKs in a development setting, such as using the console, strictly following the production process might become cumbersome. In these environments, the roles of key administrator and operator are often filled by the same person.
For testing purposes in development environments, you might want to use a permissive key policy like the following, so you can freely experiment with CMK encryption:
This policy must never be used in an environment containing sensitive data, and especially not in production.
Common caveats and pitfalls
As discussed earlier, this feature is designed to maximize security and promote best practices such as the principle of least privilege. However, this focus can introduce some corner cases you should be aware of.
The CMK must be enabled for the service to encrypt and decrypt snapshots and running state
With AWS KMS, you can disable one key at any time. If you disable the CMK while the application is running, it might cause unpredictable failures. For example, an application will not be able to restore a snapshot if the CMK used to encrypt that snapshot has been disabled. For example, if you attempt to roll back an UpdateApplication that changed the CMK, and the previous key has since been disabled, you might not be able to restore from an old snapshot. Similarly, you might not be able to restart the application from an older snapshot if the corresponding CMK is disabled.
If you encounter these scenarios, the solution is to reenable the required key and retry the operation.
The operator requires permissions to all keys involved
To perform an action on the application (such as Start, Stop, UpdateApplication, or CreateApplicationSnapshot), the operator must have permissions for all CMKs involved in that operation. AWS owned keys don’t require explicit permission.
Some operations implicitly involve two CMKs—for example, when switching from one CMK to another, or when switching from a CMK to an AWS owned key by disabling the CMK. In these cases, the operator must have permissions for both keys for the operation to succeed.
The same rule applies when rolling back an UpdateApplication action that involved multiple CMKs.
A new encryption key takes effect only after restart
A new encryption key is only used after the application is restarted. This is important when you rotate the key material for a CMK. Rotating the key material in AWS KMS doesn’t require updating the Managed Flink application’s configuration. However, you must restart the application as a separate step after rotating the key. If you don’t restart the application, it will continue to use the old encryption key for its running state and snapshots until the next restart.
For this reason, it is recommended not to enable automatic key rotation for the CMK. When automatic rotation is enabled, AWS KMS might rotate the key material at any time, but your application will not start using the new key until it is next restarted.
CMKs are only supported with Flink runtime 1.20 or later
CMKs are only supported when you are using the Flink runtime 1.20 or later. If your application is currently using an older runtime, you should upgrade to Flink 1.20 first. Managed Service for Apache Flink makes it straightforward to upgrade your existing application using the in-place version upgrade.
Conclusion
Managed Service for Apache Flink provides robust security by enabling encryption by default, protecting both the running state and persistently saved state of your applications. For organizations that require full control over their encryption keys (often due to regulatory or internal policy needs), the ability to use a CMK integrated with AWS KMS offers a new level of assurance.
By using CMKs, you can tailor encryption controls to your specific compliance requirements. However, this flexibility comes with the need for careful planning: the CMK feature is intentionally designed to enforce the principle of least privilege and strong role separation, which can introduce complexity around permissions and operational processes.
In this post, we reviewed the key steps for enabling CMKs on existing applications, creating new applications with a CMK, and managing key rotation. Each of these processes gives you greater control over your data security but also requires attention to access management and operational best practices.
To get started with CMKs and for more comprehensive guidance, refer to Key management in Amazon Managed Service for Apache Flink.









 Lorenzo Nicora works as Senior Streaming Solution Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open-source technologies extensively and contributed to several projects, including Apache Flink, and is the maintainer of the Flink Prometheus connector.
Lorenzo Nicora works as Senior Streaming Solution Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open-source technologies extensively and contributed to several projects, including Apache Flink, and is the maintainer of the Flink Prometheus connector. Francisco Morillo is a Senior Streaming Solutions Architect at AWS. Francisco works with AWS customers, helping them design real-time analytics architectures using AWS services, supporting Amazon MSK and Amazon Managed Service for Apache Flink. He is also a main contributor to the Flink Prometheus connector.
Francisco Morillo is a Senior Streaming Solutions Architect at AWS. Francisco works with AWS customers, helping them design real-time analytics architectures using AWS services, supporting Amazon MSK and Amazon Managed Service for Apache Flink. He is also a main contributor to the Flink Prometheus connector.


 Lorenzo Nicora works as a Senior Streaming Solutions Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open source technologies extensively and contributed to several projects, including Apache Flink.
Lorenzo Nicora works as a Senior Streaming Solutions Architect at AWS, helping customers across EMEA. He has been building cloud-centered, data-intensive systems for over 25 years, working across industries both through consultancies and product companies. He has used open source technologies extensively and contributed to several projects, including Apache Flink. Lorenzo Nicora works as Senior Streaming Solution Architect at AWS, helping customers across EMEA. He has been building cloud-native, data-intensive systems for over 25 years, working in the finance industry both through consultancies and for FinTech product companies. He has leveraged open-source technologies extensively and contributed to several projects, including Apache Flink.
Lorenzo Nicora works as Senior Streaming Solution Architect at AWS, helping customers across EMEA. He has been building cloud-native, data-intensive systems for over 25 years, working in the finance industry both through consultancies and for FinTech product companies. He has leveraged open-source technologies extensively and contributed to several projects, including Apache Flink.