Amazon Web Services (AWS) is introducing guidelines for network scanning of customer workloads. By following these guidelines, conforming scanners will collect more accurate data, minimize abuse reports, and help improve the security of the internet for everyone.
Network scanning is a practice in modern IT environments that can be used for either legitimate security needs or abused for malicious activity. On the legitimate side, organizations conduct network scans to maintain accurate inventories of their assets, verify security configurations, and identify potential vulnerabilities or outdated software versions that require attention. Security teams, system administrators, and authorized third-party security researchers use scanning in their standard toolkit for collecting security posture data. However, scanning is also performed by threat actors attempting to enumerate systems, discover weaknesses, or gather intelligence for attacks. Distinguishing between legitimate scanning activity and potentially harmful reconnaissance is a constant challenge for security operations.
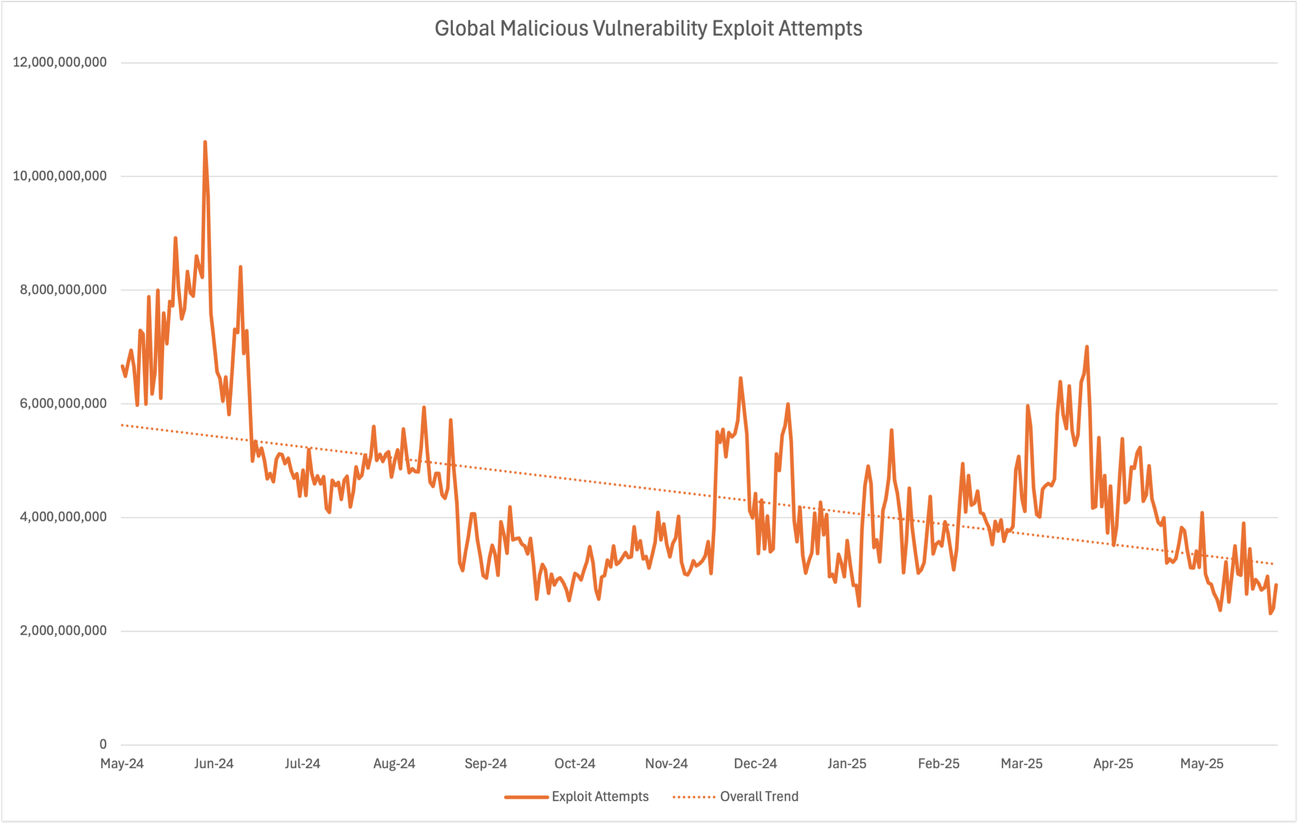
When software vulnerabilities are found through scanning a given system, it’s particularly important that the scanner is well-intentioned. If a software vulnerability is discovered and attacked by a threat actor, it could allow unauthorized access to an organization’s IT systems. Organizations must effectively manage their software vulnerabilities to protect themselves from ransomware, data theft, operational issues, and regulatory penalties. At the same time, the scale of known vulnerabilities is growing rapidly, at a rate of 21% per year for the past 10 years as reported in the NIST National Vulnerability Database.
With these factors at play, network scanners need to scan and manage the collected security data with care. There are a variety of parties interested in security data, and each group uses the data differently. If security data is discovered and abused by threat actors, then system compromises, ransomware, and denial of service can create disruption and costs for system owners. With the exponential growth of data centers and connected software workloads providing critical services across energy, manufacturing, healthcare, government, education, finance, and transportation sectors, the impact of security data in the wrong hands can have significant real-world consequences.
Multiple parties
Multiple parties have vested interests in security data, including at least the following groups:
Organizations want to understand their asset inventories and patch vulnerabilities quickly to protect their assets.
Program auditors want evidence that organizations have robust controls in place to manage their infrastructure.
Cyber insurance providers want risk evaluations of organizational security posture.
Investors performing due diligence want to understand the cyber risk profile of an organization.
Security researchers want to identify risks and notify organizations to take action.
Threat actors want to exploit unpatched vulnerabilities and weaknesses for unauthorized access.
The sensitive nature of security data creates a complex ecosystem of competing interests, where an organization must maintain different levels of data access for different parties.
Motivation for the guidelines
We’ve described both the legitimate and malicious uses of network scanning, and the different parties that have an interest in the resulting data. We’re introducing these guidelines because we need to protect our networks and our customers; and telling the difference between these parties is challenging. There’s no single standard for the identification of network scanners on the internet. As such, system owners and defenders often don’t know who is scanning their systems. Each system owner is independently responsible for managing identification of these different parties. Network scanners might use unique methods to identify themselves, such as reverse DNS, custom user agents, or dedicated network ranges. In the case of malicious actors, they might attempt to evade identification altogether. This degree of identity variance makes it difficult for system owners to know the motivation ofparties performing network scanning.
To address this challenge, we’re introducing behavioral guidelines for network scanning. AWS seeks to provide network security for every customer; our goal is to screen out abusive scanning that doesn’t meet these guidelines. Parties that broadly network scan can follow these guidelines to receive more reliable data from AWS IP space. Organizations running on AWS receive a higher degree of assurance in their risk management.
When network scanning is managed according to these guidelines, it helps system owners strengthen their defenses and improve visibility across their digital ecosystem. For example, Amazon Inspector can detect software vulnerabilities and prioritize remediation efforts while conforming to these guidelines. Similarly, partners in AWS Marketplace use these guidelines to collect internet-wide signals and help organizations understand and manage cyber risk.
“When organizations have clear, data-driven visibility into their own security posture and that of their third parties, they can make faster, smarter decisions to reduce cyber risk across the ecosystem.” – Dave Casion, CTO, Bitsight
Of course, security works better together, so AWS customers can report abusive scanning to our Trust & Safety Center as type Network Activity > Port Scanning and Intrusion Attempts. Each report helps improve the collective protection against malicious use of security data.
The guidelines
To help ensure that legitimate network scanners can clearly differentiate themselves from threat actors, AWS offers the following guidance for scanning customer workloads. This guidance on network scanning complements the policies on penetration testing and vulnerability reporting. AWS reserves the right to limit or block traffic that appears non-compliant with these guidelines. A conforming scanner adheres to the following practices:
Observational
Perform no actions that attempt to create, modify, or delete resources or data on discovered endpoints.
Respect the integrity of targeted systems. Scans cause no degradation to system function and cause no change in system configuration.
Examples of non-mutating scanning include:
Initiating and completing a TCP handshake
Retrieving the banner from an SSH service
Identifiable
Provide transparency by publishing sources of scanning activity.
Implement a verifiable process for confirming the authenticity of scanning activities.
Examples of identifiable scanning include:
Supporting reverse DNS lookups to one of your organization’s public DNS zones for scanning Ips.
Publishing scanning IP ranges, organized by types of requests (such as service existence, vulnerability checks).
If HTTP scanning, have meaningful content in user agent strings (such as names from your public DNS zones, URL for opt-out)
Cooperative
Limit scan rates to minimize impact on target systems.
Provide an opt-out mechanism for verified resource owners to request cessation of scanning activity.
Honor opt-out requests within a reasonable response period.
Examples of cooperative scanning include:
Limit scanning to one service transaction per second per destination service.
Respect site settings as expressed in robots.txt and security.txt and other such industry standards for expressing site owner intent.
Confidential
Maintain secure infrastructure and data handling practices as reflected by industry-standard certifications such as SOC2.
Ensure no unauthenticated or unauthorized access to collected scan data.
Implement user identification and verification processes.
As more network scanners follow this guidance, system owners will benefit from reduced risk to their confidentiality, integrity, and availability. Legitimate network scanners will send a clear signal of their intention and improve their visibility quality. With the constantly changing state of networking, we expect that this guidance will evolve along with technical controls over time. We look forward to input from customers, system owners, network scanners and others to continue improving security posture across AWS and the internet.
If you have feedback about this post, submit comments in the Comments section below or contact AWS Support.
As generative AI became mainstream, Amazon Web Services (AWS) launched the Generative AI Security Scoping Matrix to help organizations understand and address the unique security challenges of foundation model (FM)-based applications. This framework has been adopted not only by AWS customers across the globe, but also widely referenced by organizations such as OWASP, CoSAI, and other industry standards bodies, partners, systems integrators (SIs), analysts, auditors, and more. Now, as long-running, function-calling agentic AI systems emerge with capabilities for autonomous decision-making, we’re creating an additional framework to address an entirely new set of security challenges.
Agentic AI systems can autonomously execute multi-step tasks, make decisions, and interact with infrastructure and data. This is a paradigm shift, and organizations must adapt to it. Unlike traditional FMs that operate in stateless request-response patterns, agentic AI systems introduce autonomous capabilities, persistent memory, tool orchestration, identity and agency challenges, and external system integration, expanding the risks that organizations must address.
Working with customers deploying these systems, we’ve observed that traditional AI security frameworks don’t always extend into the agentic space. The autonomous nature of agentic systems requires fundamentally different security approaches. To address this gap, we’ve developed the Agentic AI Security Scoping Matrix, a mental model and framework that categorizes four distinct agentic architectures based on connectivity and autonomy levels, mapping critical security controls across each.
Understanding the agentic paradigm shift
FM-powered applications operate in a now well-understood, predictable pattern even though the responses that an FM produces are non-deterministic and stateless. These applications, in their most basic form receive a prompt or instruction, generate a response, then terminate the session. Security and safety controls focus on basic measures such as input validation, output filtering, and content moderation guardrails, while governance focuses on the overall risk profiles and the resilience of models. This model works because security failures have limited scope: a compromised interaction affects only that specific request and response, without persisting or propagating to other systems or users.
Agentic AI systems fundamentally change this security model through several key capabilities:
Autonomous execution and agency: Agents initiate actions based on goals and environmental triggers that might, or might not, require human prompts or approval. This creates risks of unauthorized actions, runaway processes, and decisions that exceed intended boundaries when agents misinterpret objectives or operate on compromised instructions.
When AI agents are given instructions or permissions to act based on the data, parameters, instructions, and responses given to them, the boundaries of independence or autonomy they are permitted to act within are important to define. In discussing agentic AI systems, it’s important to clarify the distinction between agency and autonomy, because these related but different concepts inform our security approach.
Agency refers to the scope of actions an AI system is permitted and enabled to take within the operating environment, and how much a human bounds an agent’s actions or capabilities. This includes what systems it can interact with, what operations it can perform, and what resources it can modify. Agency is fundamentally about capabilities and permissions—what the system is allowed to do within its operational environment. For example, an AI agent with no agency would be guided by human-defined workflow, process, tools, or orchestration compared to an AI agent with full agency that can self-determine how to accomplish a human-defined goal.
Autonomy, in contrast, refers to the degree of independent decision-making and action the system can take without human intervention. This includes when it operates, how it chooses between available actions, and whether it requires human approval for execution. Autonomy is about independence in decision-making and execution—how freely the system can act within its granted agency. For example, an AI agent might have high agency (able to perform many actions) but low autonomy (requiring human approval for each action), or vice versa.
Understanding this distinction is crucial for implementing appropriate security controls. Agency requires boundaries and permission systems, while autonomy requires oversight mechanisms and behavioral controls. Both dimensions must be carefully managed to create secure agentic AI systems.
It’s important to determine how much agency and autonomy you want to permit and grant your AI agents to act within. After you have determined the appropriate level that any given agent should operate within, you can then evaluate the appropriate security controls to put in place to restrict the agency to a permissible risk tolerance for your agentic-based application and your organization.
Persistent memory: Agents often benefit from maintaining context and learned behaviors across sessions, building knowledge bases that inform future decisions in the form of short- and long-term memory. This data persistence introduces additional data protection requirements and can add new risk vectors such as memory poisoning attacks where adversaries inject false information that corrupts decision-making across multiple interactions and users.
Tool orchestration: Agents directly integrate via functions with connections to databases, APIs, services, and potentially other agents or orchestration components to execute complex tasks autonomously depending on the tool abstraction level. This expanded attack surface creates risks of cascading compromises where a single agent breach can propagate through connected systems, multi-agent workflows, and downstream services and data stores.
External connectivity: Agents operate across network boundaries, accessing internet resources, third-party APIs, and enterprise systems. Like traditional non-agentic systems, expanded connectivity can help unlock new business value, but this access should be designed with security controls that limit risks such as data exfiltration, lateral movement, and external manipulation. Threat modeling your agentic AI applications should be a high priority and can help directly align security controls that assist your implementation of zero-trust principles into your strategy.
Self-directed behavior: Advanced agents can initiate activities based on environmental monitoring, scheduling, or learned patterns without human instantiation or review, depending on configuration. This self-direction introduces risks of uncontrolled operations, explainability, and auditability, and makes it difficult to maintain predictable security boundaries.
These capabilities transform security from a boundary problem to a continuous monitoring and control challenge. A compromised agent doesn’t just leak information—it could autonomously execute unauthorized transactions, modify critical infrastructure, or operate maliciously for extended periods without detection.
The Agentic AI Security Scoping Matrix
Working with customers and the community, we’ve identified four architectural scopes that represent the evolution of agentic AI systems based on two critical dimensions: level of human oversight compared with autonomy and the level of agency the AI system is permitted to act within. Each scope introduces new capabilities—and corresponding security requirements—that organizations must prioritize when addressing agentic AI risk. Figure 1 shows the Agentic AI Security Scoping Matrix.
Figure 1 – The Agentic AI Security Scoping Matrix
Scope 1: No agency
In this most basic scope, systems operate with human-initiated processes and no autonomous or even human-approved change capabilities through the agent itself. The agents are, essentially, read-only. These systems follow predefined execution paths and operate under strict human-triggered workflows, which are usually predefined and follow discrete steps, but could be augmented with non-deterministic outputs from an FM. Security focuses primarily on process integrity and boundary enforcement, helping operations remain within predetermined limits and agents are highly controlled and prohibited from change execution and unbounded actions.
Key characteristics:
Agents can’t directly execute change in the environment
Fixed step-by-step execution following predetermined paths
Generative AI components process data within individual workflow nodes
Conditional branching only where explicitly designed into the workflow
No dynamic planning or autonomous goal-seeking behavior
State persistence limited to workflow execution context
Tool access restricted to specific predefined workflow steps
Security focus: Protecting data integrity within the environment and restricting agents to not exceed their boundaries, especially limits around environment and data modification. Primary concerns include securing state transitions between steps, validating data passed between workflow nodes, and preventing AI components from modifying the orchestration logic or escaping their designated boundaries within the workflow.
Example: We will use a very simplistic example, across all four scopes, of a use case for an agent that is designed to help you create calendar invites. Let’s say you need to book a meeting with another colleague. In Scope 1, you might have an agent that you instantiate through a workflow or prompt to look at your calendar and your colleague’s calendar for available meeting times. In this case, you initiate the request, and the agent executes a contextual search using a Model Context Protocol (MCP) server connected to your enterprise calendaring application. The agent is only allowed to look at available times, analyze the best times to meet, and provide a response back, which a human can then use to manually set up a meeting. In this example, the human defines specific workflows and orchestrations (no agency) and reviews and approves the actions taken (no autonomous change).
Scope 2: Prescribed agency
Moving up in agency and risk, Scope 2 systems also are instantiated by a human, but now have the potential to perform actions—limited agency—that could change the environment. However, all actions taken by an agent require explicit human approval for all actions of consequence—commonly referred to as human in the loop or HITL. These systems can gather information, analyze data, and prepare recommendations, but cannot execute actions that modify external systems or access sensitive resources without human authorization. Agents can also request human input to clarify ambiguities, provide missing context, or optimize their approach before presenting recommendations.
Key characteristics:
Agents can execute change in the environment with human review and approval
Real-time human oversight with approval workflows
Bidirectional human interaction—agents can query humans for context
Limited autonomous actions restricted to read-only operations (such as, querying data, running analysis jobs, and so on)
Agent-initiated requests for clarification or additional information
Audit trails of all human approval decisions and context exchanges
Security focus: Implementing robust approval workflows and preventing agents from bypassing human authorization controls. Key concerns include preventing privilege escalation, enforcing appropriate identity contexts, securing the approval process itself, validating human-provided context to prevent injection attacks, and maintaining visibility into all agent recommendations and their rationale.
Example: In our calendaring example, a Scope 2 agentic system is instantiated by a human. The agent then looks up the stakeholders’ calendar availability, does its analysis, returns a recommendation for a meeting time to the user, and asks the user if they want the agent to send the invitation out on their behalf. The user looks at the response and recommendation of the agent, validates that it meets their requirements, and then acknowledges and approves the agent’s request to modify the calendars and send the invitation. In this example, the human orchestrates a structured workflow, but the agent now can instantiate human reviewed change through bounded actions (limited agency and limited autonomy).
Scope 3: Supervised agency
In Scope 3, we expand the agency to allow for a greater sense of agentic autonomy—high agency—in execution. These are AI systems that execute complex autonomous tasks that are initiated by humans (or at least from an upstream human-managed workflow), with the ability to make decisions and take actions to connected systems without further approval or HITL mechanisms. Humans define the objectives and trigger execution, but agents operate independently to achieve goals through dynamic planning and tool usage. During execution, agents can request human guidance to optimize trajectory or handle edge cases, though they can continue operating without it.
Key characteristics:
Agents can execute change in the environment, with no (or optional) human interaction or review
Human-triggered execution with autonomous task completion
Dynamic planning and decision-making during execution
Optional human intervention points for trajectory optimization
Human ability to adjust parameters or provide context mid-execution
Direct access to external APIs and systems for task completion
Persistent memory across extended execution sessions
Autonomous tool selection and orchestration within defined boundaries
Security focus: Implementing comprehensive monitoring of agent actions during autonomous execution phases and establishing clear agency boundaries for agent operations—the bounds you’re willing to let the agents operate within, and actions that would be out of bounds and must be prevented. Critical concerns include securing the human intervention channel to prevent unauthorized modifications, preventing scope creep during task execution, implementing trusted identity propagation constructs, monitoring for behavioral anomalies, and validating that agents remain aligned with original human intent throughout extended operations even when trajectory adjustments are made.
Example: In our calendaring example, a Scope 3 agentic system can still be instantiated by a human. The agent then looks up the stakeholders’ calendar availability, does its analysis, and returns a recommendation for a meeting time to the user; however, it’s within the agent’s bounds to act upon its own recommendation on behalf of the user to automatically book the best available slot. The user is not prompted or expected to give the agent permission to do so prior to its actions. The result is that all stakeholders have a calendar entry added to their calendar in the context of the calling human user. In this example, the human defines an outcome but with more freedom for the agent to determine how to achieve that goal, and the agent now can take autonomous action without human review (high agency and high autonomy).
Scope 4: Full agency
Scope 4 includes fully autonomous AI systems that can initiate their own activities based on environmental monitoring, learned patterns, or predefined conditions, and execute complex tasks without human intervention. These systems represent the highest level of AI agency, operating continuously and making independent decisions about when and how to act. It’s key to note that AI systems within Scope 4 could have full agency when executing within their designed bounds; therefore, it’s critical that humans maintain supervisory oversight with the ability to provide strategic guidance, course corrections, or interventions when needed. Continuous compliance, auditing, and full-lifecycle management mechanisms, both human and automated reviews, which could also be aided by AI, are critical to successfully securing and governing Scope 4 agentic AI systems while limiting risk.
Key characteristics:
Self-directed activity initiation based on environmental triggers
Continuous operation with minimal human oversight or HITL processes during execution
Human ability to inject strategic guidance without disrupting operations
High to full degrees of autonomy in goal setting, planning, and execution
Dynamic interaction with multiple external systems and agents
Capability for recursive self-improvement and capability expansion
Security focus: Implementing advanced guardrails for behavioral monitoring, anomaly detection, scope-based tool access controls, and fail-safe mechanisms to prevent runaway operations. Primary concerns include maintaining alignment with organizational objectives, securing human intervention channels against adversarial manipulation, preventing unauthorized capability expansion, preventing human oversight mechanisms from being disabled by the agent, and enabling graceful degradation when agents encounter unexpected situations.
Example: Let’s look at how we might deploy our AI calendaring example in Scope 4. Let’s say you have implemented a generative AI meeting summarizer. This agent is automatically enabled when you host a web conference. At the conclusion of the meeting, the calendaring agent sees a new meeting occurred from the meeting summarizer agent. It looks at the action items that were summarized and determines that six people agreed to a whiteboard session on Friday. The calendaring agent might either have a statically defined API configuration or leverage dynamic discovery on MCP servers to help with calendaring. It then finds availability for the six identified resources and books the best available slot. It then uses the appropriate identity context of the user who is asking for the meeting to book the meeting autonomously. At no point does a user directly instantiate the request for calendaring; it is fully automated and driven off environment changes that the agent is instructed to look for (full agency and full autonomy).
Scope comparison across the scopes
In the context of the security scoping matrix, let’s compare how autonomy and agency characteristics shift depending on the scope:
Table 1 – Scope impacts on agency and autonomy levels
Critical security dimensions
Scope
Agency level
Agency characteristics
Autonomy level
Autonomy characteristics
Scope 1: No agency
None
Read-only operations
Fixed workflow paths
None
Human-initiated only
Predefined execution steps
Scope 2: Prescribed agency
Limited
Can modify systems
Access to multiple tools
Limited
Requires human approval for actions
HITL for all changes
Scope 3: Supervised agency
High
Can modify multiple systems
Dynamic tool selection
High
Autonomous execution after human initiation
Optional human guidance
Scope 4: Full agency
Full
Comprehensive system access
Multi-system orchestration
Self-adaptive
Full
Self-initiated actions
Continuous autonomous operation
Strategic human oversight
Each architectural scope requires specific security controls and considerations across six critical dimensions. Table 2 illustrates how security requirements escalate with increasing agency and autonomy:
Security dimension
Scope 1: No agency
Scope 2: Prescribed agency
Scope 3: Supervised agency
Scope 4: Full agency
Identity context (authN and authZ)
User authentication
Service authentication
Limited system permissions (read-only)
Limited system access (only necessary, known systems needed for the workflow)
User authentication
Service authentication
Human identity verification for approvals
User authentication
Service authentication
Agent authentication
Identity delegation for autonomous actions
Dynamic identity lifecycle
Federated authentication
Continuous identity verification
Agent identity attestation
Data, memory, and state protection
Local resource permissions
File system access controls
Role-based access control
Human approval workflows
Read-mostly permissions for agents
Context-aware authorization
Just-in-time privilege elevation
Dynamic permission boundaries
Behavioral authorization
Adaptive access controls
Continuous authorization validation
Audit and logging
Local activity logs
Change tracking
Integrity monitoring
Policy enforcement
Human decision audit trails
Agent recommendation logging
Approval process tracking
Comprehensive action logging
Reasoning chain capture
Extended session tracking
Continuous behavioral logging
Pattern analysis
Predictive monitoring
Automated incident correlation
Agent and FM controls
Process isolation
Input/output validations
Guardrails
Approval gateway enforcement
Extended session monitoring
Container isolation
Long-running process management
Tool invocation sandboxing
Behavioral analysis
Anomaly detection
Automated containment
Self-healing security
Agency perimeters and policies
Fixed execution boundaries
Predefined action limits
Static resource quotas
Hard-coded constraints
Approval-based boundary modification
Human-validated constraint changes
Time-bound elevated access
Multi-step validation
Dynamic boundary adjustment
Runtime constraint evaluation
Resource scaling limits
Automated safety checks
Self-adjusting boundaries
Context-aware constraints
Cross-system resource management
Autonomous limit adaptation
Orchestration
Simple workflow orchestration
Fixed execution paths
Single or limited system integration points
Multi-step workflow orchestration
Approval-gated tool access
Human-validated tool chains
Dynamic tool orchestration
Parallel execution paths
Cross-system integration
Autonomous multi-agent orchestration
Cross-session learning
Dynamic service discovery
Table 2 — Critical security dimensions per scope
Security implementation by scope
Now that we’ve outlined each of the scopes and the associated levels of agency and autonomy, let’s discuss some primary security challenges per scope and key considerations that should be taken to address the associated risks.
Scope 1: No agency Primary security challenges: Protecting workflow integrity, preventing prompt injection from breaking predetermined flows, and maintaining isolation between workflow executions.
Implementation considerations:
Comprehensive monitoring with anomaly detection
Strict data validation and integrity checking
Input validation at each workflow step boundary
Immutable workflow definitions with version control
State encryption and validation between workflow nodes
Monitoring for attempts to escape workflow boundaries
Segregation between different workflow executions
Fixed timeout and resource limits per workflow step
Audit trails showing actual compared to expected execution paths
Scope 2: Prescribed agency Primary security challenges: Securing approval workflows, preventing human authorization bypass, and maintaining oversight effectiveness.
Implementation considerations:
Multi-factor authentication for all human approvers
Cryptographically signed approval decisions
Securing bidirectional human-agent communication channels
Time-bounded approval tokens with automatic expiration
Comprehensive logging of all approval interactions
Regular training for human approvers on agent capabilities and risks
Scope 3: Supervised agency Primary security challenges: Maintaining control during autonomous execution, scope management, explainability and auditability, and behavioral monitoring.
Implementation considerations:
Clear execution boundaries defined at initiation
Real-time monitoring of agent actions during execution
Automated kill switches for runaway processes
Non-blocking intervention mechanisms
Behavioral baselines for normal agent operations
Regular validation of agent alignment with original objectives
Scope 4: Full agency Primary security challenges: Continuous behavioral validation, enforcing agency boundaries, preventing capability drift, and maintaining organizational alignment.
Implementation considerations:
Advanced AI safety techniques including reward modeling
Continuous monitoring with machine learning-based anomaly detection
Automated response systems for behavioral deviations
Regular alignment validation through systematic testing
Tamper-proof human override mechanisms
Failsafe mechanisms that can halt operations when confidence drops
Key architectural patterns
Successful agentic deployments share common patterns that balance autonomy with control.
Progressive autonomy deployment: Start with Scope 1 or 2 implementations and gradually advance through the scopes as organizational confidence and security capabilities mature. This approach minimizes risk while building operational experience. Be cautious and selective when analyzing use cases and bounding controls for Scope 4 implementations and review your ability to address risks at the lower scopes and how risks increase as you move further up the levels.
Layered security architecture: Implement defense-in-depth with security controls at multiple levels—network, application, agent, and data layers—to safeguard that compromise at one level doesn’t lead to complete system failure. Although the combination of these controls is what enables a high security bar, be sure to spend considerable efforts on making sure that identity and authorization concerns are addressed—for both machines and humans. This helps prevent issues such as the confused deputy problem—when a human or service with lesser permissions is able to elevate permissions through agents that might themselves have more entitlements and privileges.
Continuous validation loops: Establish automated systems that continuously verify agent behavior against expected patterns, and that have escalation procedures for when deviations are detected. Auditability and explainability are key requirements to confirm that agents are performing within the bounds intended and to help you determine control effectiveness, adjust parameters, and validate your orchestration workflows.
Human oversight integration: Even in highly autonomous systems, maintain meaningful human oversight through strategic checkpoints, behavioral reporting, and manual override capabilities. It might be reasonable to assume that human oversight reduces when moving from Scope 1 to Scope 4 agency, but the truth is that it simply shifts focus. For example, the human requirement to instantiate, review, and approve certain agentic actions is higher in Scopes 1 and 2 and lower in Scopes 3 and 4; however, the human requirement to audit, assess, validate, and implement more complex security and operational controls is much higher in Scopes 4 and 3 than they are in Scopes 2 and 1.
Graceful degradation: Design systems to automatically reduce autonomy levels when security events are detected, allowing operations to continue safely while human operators investigate. If your agents start to act in ways that go beyond the intended bounds of their design, anomalous behavior is detected, or they begin to perform actions deemed particularly risky or sensitive to your business, then consider having detective controls that will automatically inject tighter restrictions such as requiring more HITL or reducing the actions an agent can take. You might do this as incremental degradation or, you might choose to disable the agent if it’s acting in ways that negatively impact the environment. These agentic safety mechanisms that can implement additional restrictions or even disable an agent should be considered when building or deploying agents.
Conclusion
The Agentic AI Security Scoping Matrix provides a structured mental model and framework for understanding and addressing the security challenges of autonomous agentic AI systems across four distinct scopes. By accurately assessing your current scope and implementing appropriate controls across all six security dimensions, organizations can confidently deploy agentic AI while managing the landscape of associated risks.
The progression from basic and highly constrained agents to fully autonomous and even self-directing agents represents a fundamental shift in how we approach AI security. Each scope requires specific security capabilities, and organizations must build these capabilities systematically to support their agentic ambitions safely.
Next steps
To implement the Agentic AI Security Scoping Matrix in your organization:
Assess your current agentic use cases and maturity against the four scopes to understand your security requirements and associated risks. Integrate it into your procurement and SDLC processes.
Identify capability gaps across the six security dimensions for your target scope.
Develop a progressive deployment strategy that builds security capabilities as you advance through scopes.
Implement continuous monitoring and behavioral analysis appropriate for your scope level.
Establish governance processes for scope progression and security validation.
Train your teams on the unique security challenges of each scope.
The line between cyber warfare and traditional kinetic operations is rapidly blurring. Recent investigations by Amazon threat intelligence teams have uncovered a new trend that they’re calling cyber-enabled kinetic targeting in which nation-state threat actors systematically use cyber operations to enable and enhance physical operations. Traditional cybersecurity frameworks often treat digital and physical threats as separate domains. However, research by Amazon demonstrates that this separation is increasingly artificial. Multiple nation-state threat groups are pioneering a new operational model where cyber reconnaissance directly enables kinetic targeting.
We’re seeing a fundamental shift in how nation-state actors approach warfare. These aren’t just cyber attacks that happen to cause physical damage; they are coordinated campaigns where digital operations are specifically designed to support physical military objectives.
Unique visibility at Amazon
The ability of Amazon Threat Intelligence to identify these campaigns stems from their unique position in the global threat landscape:
Threat intelligence telemetry: Amazon global cloud operations provide visibility into threats across diverse environments, including intelligence from Amazon MadPot honeypot systems, which enable the detection of suspicious patterns, actor infrastructure, and the network pathways used in these cyber-enabled kinetic targeting campaigns.
Opt-in customer data: Real-world data about attempted threat actor activities provided on an opt-in basis from enterprise environments.
Industry partner collaboration: Threat intelligence sharing with leading security organizations and government agencies provides additional context and validation for observed activities.
Through this multi-source approach, Amazon can connect dots that might otherwise remain invisible to individual organizations or even government agencies operating in isolation.
Case study 1: Imperial Kitten’s maritime campaign
The first case study involves Imperial Kitten, a threat group suspected of operating on behalf of Iran’s Islamic Revolutionary Guard Corps (IRGC). The timeline reveals the progression from digital reconnaissance to physical attack:
December 4, 2021: Imperial Kitten compromises a maritime vessel’s Automatic Identification System (AIS) platform, gaining access to critical shipping infrastructure. The Amazon Threat Intelligence team identifies the compromise and works with the affected organization to remediate the security event.
August 14, 2022: The threat actor expands their maritime targeting of additional vessel platforms. In one incident, they gained access to CCTV cameras aboard a maritime vessel, which provided real-time visual intelligence.
January 27, 2024: Imperial Kitten conducts targeted searches for AIS location data for a specific shipping vessel. This represents a clear shift from broad reconnaissance to targeted intelligence gathering.
February 1, 2024: US Central Command reports a missile strike by Houthi forces against the exact vessel that Imperial Kitten had been tracking. While the missile strike was ultimately ineffective, the correlation between the cyber reconnaissance and kinetic strike is unmistakable.
This case demonstrates how cyber operations can provide adversaries with the precise intelligence needed to conduct targeted physical attacks against maritime infrastructure—a critical component of global commerce and military logistics.
Case study 2: MuddyWater’s Jerusalem operations
The second case study involves MuddyWater, a threat group attributed by the US government to Rana Intelligence Computer Company, operating at the behest of Iran’s Ministry of Intelligence and Security (MOIS). This case reveals an even more direct connection between cyber operations and kinetic targeting.
May 13, 2025: MuddyWater provisions a server specifically for cyber network operations, establishing the infrastructure needed for their campaign.
June 17, 2025: The threat actor uses their server infrastructure to access another compromised server containing live CCTV streams from Jerusalem. This provides real-time visual intelligence of potential targets within the city.
June 23, 2025: Iran launches widespread missile attacks against Jerusalem. On the same day, Israeli authorities report that Iranian forces were exploiting compromised security cameras to gather real-time intelligence and adjust missile targeting.
The timing is not coincidental. As reported by The Record, Israeli officials urged citizens to disconnect internet-connected security cameras, warning that Iran was exploiting them to “gather real-time intelligence and adjust missile targeting.”
Technical infrastructure and methods
Research by Amazon reveals the sophisticated technical infrastructure supporting these operations. The threat actors employ a multi-layered approach:
Anonymizing VPN networks: Threat actors route their traffic through anonymizing VPN services to obscure their true origins and make attribution more difficult.
Actor-controlled servers: Dedicated infrastructure provides persistent access and command-and-control capabilities for ongoing operations.
Compromised enterprise systems: The ultimate targets—enterprise servers hosting critical infrastructure like CCTV systems, maritime platforms, and other intelligence-rich environments.
Real-time data streaming: Live feeds from compromised cameras and sensors provide actionable intelligence that can be used to adjust targeting in near real time.
Defining a new category of warfare
The research team proposes new terminology to describe these hybrid operations. Traditional frameworks fall short:
Cyber-kinetic operations typically refer to cyber attacks that cause physical damage to systems
Hybrid warfare is too broad, encompassing multiple types of warfare without specific focus on the cyber-physical integration
Amazon researchers suggest cyber-enabled kinetic targeting as a more precise term for campaigns where cyber operations are specifically designed to enable and enhance kinetic military operations.
Implications for defenders
For the cybersecurity community, this research serves as both a warning and a call to action. Defenders must adapt their strategies to address threats that span both digital and physical domains. Organizations that historically believed they weren’t of interest to threat actors could now be targeted for tactical intelligence. We must expand our threat models, enhance our intelligence sharing, and develop new defensive strategies that account for the reality of cyber-enabled kinetic targeting across diverse adversaries.
Expanded threat modeling: Organizations must consider not just the direct impact of cyberattacks, but how compromised systems might be used to support physical attacks against themselves or others.
Critical infrastructure protection: Operators of maritime systems, urban surveillance networks, and other infrastructure must recognize that their systems might be valuable not just for espionage, but as targeting aids for kinetic operations.
Intelligence sharing: The cases demonstrate the critical importance of threat intelligence sharing between private sector organizations, government agencies, and international partners.
Attribution challenges: When cyber operations directly enable kinetic attacks, the attribution and response frameworks become more complex, potentially requiring coordination between cybersecurity, military, and diplomatic channels.
Looking forward
We believe that cyber-enabled kinetic targeting will become increasingly common across multiple adversaries. Nation-state actors are recognizing the force multiplier effect of combining digital reconnaissance with physical attacks. This trend represents a fundamental evolution in warfare, where the traditional boundaries between cyber and kinetic operations are dissolving.
Indicators of Compromise
IOC Value, IOC Type, First Seen, Last Seen, Annotation 18[.]219.14.54, IPv4, 2025-05-13, 2025-06-17, MuddyWater Command and Control IP address 85[.]239.63.179, IPv4, 2023-08-13, 2025-09-19, Imperial Kitten proxy IP address 37[.]120.233.84, IPv4, 2021-01-01, 2022-11-01, Imperial Kitten proxy IP address 95[.]179.207.105, IPv4, 2020-11-11, 2022-04-09, Imperial Kitten proxy IP address
This blog post is based on research presented at CYBERWARCON by David Magnotti, Principal Engineer, and Dlshad Othman, Senior Threat Intelligence Engineer, both of Amazon Threat Intelligence. The authors thank US Central Command for their transparency in reporting military activities and acknowledge the ongoing support of customers and partners in these critical investigations.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
As generative AI becomes foundational across industries—powering everything from conversational agents to real-time media synthesis—it simultaneously creates new opportunities for bad actors to exploit. The complex architectures behind generative AI applications expose a large surface area including public-facing APIs, inference services, custom web applications, and integrations with cloud infrastructure. These systems are not immune to classic or emerging external threats. We have introduced a series of posts on securing generative AI, starting with Securing generative AI: An introduction to the Generative AI Security Scoping Matrix, which establishes a model for the risk and security implications based on the type of generative AI workload you are deploying and lays the foundation for the rest of our series.
This post continues the series, and provides guidance on how to build secure, scalable network architectures for generative AI applications on Amazon Web Services (AWS) through a defense-in-depth approach. You’ll learn how to protect your AI workloads while maintaining performance and reliability. We cover multiple security layers including virtual private cloud (VPC) isolation, network firewalls, application protection, and edge security controls that you can use to create a comprehensive defense strategy for generative AI workloads.
Common generative AI external threats
In this section, we review some of the most common external threats facing generative AI applications today.
Network level DDoS attacks (layer 4)
Network level distributed denial-of-service (DDoS) or volumetric attacks such as SYN floods, UDP floods, and ICMP floods, target the network layer by sending a flood of layer 4 requests to a server. The aim is to exhaust the server’s resources by initiating multiple half-open layer 4 connections, ultimately rendering the system unresponsive to legitimate users. For generative AI applications, which often require sustained sessions and low-latency responses, such exploits can severely disrupt availability and user experience. Another type of volumetric attack is reflection attacks, where threat actors exploit services such as DNS to amplify the volume of traffic sent to a target. A small request sent to a vulnerable third-party server is reflected and expanded into a large response directed at the victim. This technique is particularly dangerous when generative AI APIs are exposed to the public internet, because it can flood the endpoints with unexpected traffic, causing service degradation.
Web request flood (layer 7)
These sophisticated exploits on layer 7 mimic legitimate traffic patterns to evade traditional security filters. By overwhelming application endpoints with excessive HTTP requests, bad actors can cause compute exhaustion, especially in inference-heavy AI workloads. Unlike volumetric DDoS, these requests are often hard to distinguish from real users, making mitigation more complex.
Application-specific exploits
Bad actors increasingly focus on exploiting vulnerabilities in application-specific code or the systems on which the code runs—such as Apache, Nginx, or Tomcat. For generative AI applications, which often involve custom APIs and orchestration layers, even a small misconfiguration or unpatched component can open the door to unauthorized access, data leakage, or system compromise.
SQL injection
By injecting malicious SQL code through input fields or query parameters, bad actors can manipulate backend databases to exfiltrate or corrupt data. Generative AI apps that log prompts or store user interactions are especially susceptible if input sanitization is not enforced rigorously.
Cross-site scripting
Cross-site scripting (XSS) attacks involve injecting malicious scripts into trusted web pages. When unsuspecting users interact with these scripts, bad actors can hijack sessions, steal data, or redirect users to malicious sites. Frontend interfaces for AI services, especially dashboards or prompt consoles, are particularly vulnerable.
OWASP top application security risks
The OWASP Top 10 serves as a critical framework for identifying common security risks in web applications. These include issues such as broken access control, security misconfigurations, and insufficient logging and monitoring. Generative AI solutions must adhere to OWASP guidelines to mitigate the broader landscape of web application threats.
Common vulnerabilities and exposures
Security professionals must remain vigilant to known common vulnerabilities and exposures (CVEs) impacting AI stack components—ranging from open-source libraries to model-serving infrastructure. Ignoring CVEs can lead to exploits that compromise sensitive model outputs, internal APIs, or user data.
Malicious bots and crawlers
Malicious bots increasingly target AI applications to scrape content such as generated text, pricing data, proprietary models, or images behind paywalls. These bots can masquerade as legitimate crawlers or scanners but are designed to harvest content at scale, potentially violating terms of service and impacting infrastructure costs.
Content scrapers and probing tools
Automated tools that crawl, scrape, or scan generative AI systems are often used for competitive intelligence, model inversion, or discovering exposed endpoints. These tools can weaken privacy guarantees and expose AI behavior to unintended third parties.
Securing your generative AI applications
Here are some of the common strategies that you can use to help secure your generative AI applications using AWS services.
Private networking with Amazon Bedrock
Amazon Bedrock is a fully managed service provided by AWS that offers developers access to foundation models (FMs) and the tools to customize them for specific applications. Developers can use it to build and scale generative AI applications using FMs through an API, without managing infrastructure. A typical set of environments is shown in Figure 1. It has the following network components:
The Amazon Bedrock service accounts, which hold the service components and exposes its API endpoint within the same AWS Region as the customer’s account.
The customer’s AWS account, from which the application needs to use Amazon Bedrock and invokes the Amazon Bedrock API with the query request.
The customer’s corporate network within the existing data center, which is external to the AWS global network, and holds the customer’s application that also needs to use Amazon Bedrock and can involve the Amazon Bedrock API request. AWS Direct Connect provides a dedicated network connection between an on-premises network and AWS, bypassing the public internet.
Figure 1 – Private networking architecture with Amazon Bedrock
You can use AWS PrivateLink to establish private connectivity between the FMs and the generative AI applications running in on-premises networks or your Amazon Virtual Private Cloud (Amazon VPC), without exposing your traffic to the public internet. In the case of Amazon VPC, the application running on the private subnet instance invokes the Amazon Bedrock API call. The API call is routed to the Amazon Bedrock VPC endpoint that is associated to the VPC endpoint policy and then to Amazon Bedrock APIs. The Amazon Bedrock service API endpoint receives the API request over PrivateLink without traversing the public internet. You also have the option of connecting to the Amazon Bedrock service API through the NAT Gateway. Note that in this case, the traffic goes over the AWS network backbone without being exposed to the public internet.
You can also privately access Amazon Bedrock APIs over the VPC endpoint from your corporate network through an AWS Direct Connect gateway. In case you don’t have Direct Connect, you can connect to the Amazon Bedrock service API over public internet (shown by the lower arrow in figure 1). In each of these cases, traffic to the API endpoint for Amazon Bedrock is encrypted in flight using TLS 1.2 or later, and traffic within the Amazon Bedrock service is also encrypted in flight to at least this standard. Customer content processed by Amazon Bedrock is encrypted and stored at rest in the Region where you are using Amazon Bedrock.
Minimize layer 7 generative AI threats with AWS WAF
As generative AI systems become integral to content creation, customer service, and decision-making processes, they are increasingly targeted by malicious bot threats. These exploits can distort outputs, flood models with biased or harmful training data (data poisoning), exploit vulnerabilities for prompt injection, or overwhelm systems through automated abuse. The consequences include degraded model performance, spread of misinformation, compromised data privacy, and erosion of user trust. To mitigate these threats, safeguards such as user authentication, input validation, anomaly detection, and continuous monitoring must be embedded into generative AI pipelines. AWS WAF is a web application firewall that helps protect applications (OSI Layer 7) from bot exploits by using intelligent detection and rule-based defenses. Its Bot Control feature identifies and filters out harmful bots while allowing legitimate ones. Through rate limiting, custom rules, and anomaly detection, AWS WAF can block scraping, credential stuffing, and distributed denial-of-service attempts (DDoS). Anti-DDoS rule group—targeted specifically at automatic mitigation of application exploits that involve HTTP request floods—is available as a Managed Rules group through AWS WAF. It removes the complexity associated with managing various AWS WAF rules and ACLs to handle these increasingly agile threats.
AWS WAF can be enabled on Amazon CloudFront, Amazon API Gateway, Application Load Balancer (ALB) and is deployed alongside these services (Figure 2). These AWS services terminate the TCP/TLS connection, process incoming HTTP requests, and then forward the request to AWS WAF for inspection and filtering. There is no need for reverse proxy, DNS setup, or TLS certification.
Figure 2 – Architecture using AWS WAF to minimize layer 7 generative AI threats
Mitigate DDoS at the edge for generative AI applications
DDoS attacks pose a serious threat to generative AI applications by overwhelming servers with massive traffic, leading to latency, degraded performance, or complete outages. Because generative AI workloads are often resource-intensive and operate in real time (for example, chatbots, image generators, and coding assistants), even brief disruptions can impact user experience and trust. Moreover, DDoS attacks can be used as a smokescreen for other exploits, such as data exfiltration or prompt injection. Protecting generative AI systems with scalable defenses such as rate limiting, traffic filtering, and auto-scaling infrastructure is crucial to help maintain availability and service continuity.
AWS Shield safeguards generative AI applications from DDoS attacks by providing always-on detection and automated mitigation. The standard tier, AWS Shield Standard, defends against common volumetric and state-exhaustion attacks with no additional cost. For advanced protection, AWS Shield Advanced offers real-time threat intelligence, adaptive rate limiting, and 24/7 access to the AWS Shield Response Team (SRT). To use the services of the SRT, you must be subscribed to the Business Support plan or the Enterprise Support plan. This helps makes sure that generative AI services—often reliant on high availability and low latency—remain resilient under threat, maintaining performance and uptime even during large-scale traffic surges. Integration with services like Amazon CloudFront and Elastic Load Balancing further enhances scalability and protection (Figure 3).
Figure 3 – Help protect your applications from DDoS attack by using AWS Shield Advance at the edge
Perimeter firewall for generative AI applications
AWS Network Firewall is a managed network security service that you can use to deploy stateful and stateless packet inspection, intrusion prevention (IPS), and domain filtering capabilities directly into your Amazon VPCs. It helps inspect and filter both inbound and outbound traffic at the subnet level. For generative AI applications, this means enforcing fine-grained traffic controls without the complexity of managing your own appliances or proxies. You can use AWS Network Firewall to create custom stateless or stateful rules to block specific payloads, known signatures, or unusual traffic patterns. In multi-model or multi-tenant environments, the firewall can help enforce east-west segmentation, so that a compromised microservice cannot laterally access other AI components or sensitive services. Network Firewall can also be effective in collecting hostnames of the specific sites that are being accessed by your generative AI application. This process is called egress filtering and is specifically helpful in case an adversary compromises the generative AI workload and tries to establish a connection to an external command and control system. Network Firewall can be used to help secure outbound traffic by blocking packets that fail to meet certain security requirements.
Monitor for malicious activity
Monitoring for malicious activity is essential to protect generative AI applications from evolving security threats. These applications process unpredictable user inputs and generate dynamic outputs, making them particularly vulnerable to exploitation. Continuous monitoring enables early detection of unusual traffic patterns, excessive API usage, or anomalous input behavior, symptoms which might indicate potential exploits. It also helps prevent misuse of AI models through prompt injection, adversarial inputs, or attempts to extract sensitive information from model responses. In addition, monitoring plays a critical role in identifying DDoS attempts and resource abuse, which could otherwise disrupt the availability of AI services. By observing and analyzing real-time activity, organizations can take proactive steps to block malicious actors, adjust security controls, and maintain the integrity and reliability of their generative AI applications. Amazon GuardDuty, a threat detection service, continuously analyzes AWS account activity, network flow logs, and DNS queries to uncover potential compromises or malicious behaviors targeting your environment. GuardDuty identifies suspicious activity such as AWS credential exfiltration and suspicious user API usage in Amazon SageMaker APIs. Additionally, GuardDuty offers protection plans for Amazon Simple Storage Service (Amazon S3), Amazon Relational Database Service (Amazon RDS), Amazon Elastic Kubernetes Service (Amazon EKS), EKS Runtime Monitoring, Runtime Monitoring for Amazon ECS and Amazon EC2, Malware Protection for Amazon EC2 and S3, and AWS Lambda Protection. Amazon Inspector is an automated vulnerability management service that continually scans AWS workloads for software vulnerabilities and unintended network exposure. Amazon Detective simplifies the investigative process and helps security teams conduct faster and more effective forensic investigations.
Network defense in depth for generative AI
Like other modern applications, a defense-in-depth approach is recommended when designing network architectures for generative AI applications. A complete reference architecture of a generative AI application showing defense in depth protection using AWS services is shown in Figure 4.
Figure 4 – Workflow for generative AI network defense in depth
The workflow shown in Figure 4 is as follows:
A client makes a request to your application. DNS directs the client to a CloudFront location, where AWS WAF and Shield are deployed.
CloudFront sends the request through an AWS WAF rule to determine whether to block, monitor, or allow the traffic. Shield can mitigate a wide range of known DDoS attack vectors and zero-day attack vectors. Depending on the configuration, Shield Advanced and AWS WAF work together to rate-limit traffic coming from individual IP addresses. If AWS WAF or Shield Advanced don’t block the traffic, the services will send it to the CloudFront routing rules.
CloudFront sends the traffic to the ALB. However, before reaching the ALB, the traffic is inspected through a Network Firewall endpoint. Network Firewall supports deep packet inspection to decrypt, inspect, and re-encrypt inbound and outbound TLS traffic destined for the Internet, another VPC, or another subnet to help protect data. You can limit access to threat actors at this stage with additional safeguards. If you are not expecting traffic from high risk countries, it is advisable to restrict access through geographic blocking or you could at least put a strict rate limit for those countries where you don’t expect traffic through AWS WAF rules on ingress and Network Firewall on egress.
Note: If you use Amazon CloudFront geographic restrictions to block a country’s access to your content, then CloudFront blocks every request from that country. CloudFront doesn’t forward the requests to AWS WAF. To use AWS WAF criteria to allow or block requests based on geography, use an AWS WAF geographic match rule statement instead.
The ALB is in a public subnet. To keep the instances that run your app isolated from the rest of the world using the ALB, you can additionally, help protect from common layer 7 exploits with AWS WAF.
The ALB has target groups in the form of instances that are running the generative AI application running in a private subnet. You can help protect the instances and their network interfaces with the foundational VPC constructs like security groups, network ACLs (NACLs), and segmentation.
The application calls the Amazon Bedrock API. You can use PrivateLink to create a private connection between your VPC and Amazon Bedrock. You can then access Amazon Bedrock as if it were in your VPC, without the use of an internet gateway, NAT device, VPN connection, or Direct Connect connection. Instances in your VPC don’t need public IP addresses to access Amazon Bedrock. You establish this private connection by creating an interface endpoint, powered by PrivateLink. You create an endpoint network interface in each subnet that you enable for the interface endpoint. These are requester-managed network interfaces that serve as the entry point for traffic destined for Amazon Bedrock.
Create an interface endpoint for Amazon Bedrock using either the Amazon VPC console or the AWS Command Line Interface (AWS CLI). Create an interface endpoint for Amazon Bedrock using the following service name: com.amazonaws.region.bedrock-runtime
Create an endpoint policy for your interface endpoint. An endpoint policy is an AWS Identity and Access Management (IAM) resource that you can attach to an interface endpoint. The default endpoint policy allows full access to Amazon Bedrock through the interface endpoint. To control the access allowed to Amazon Bedrock from your VPC, attach a custom endpoint policy to the interface endpoint. An example of a custom endpoint policy is shown in Figure 4. When you attach this policy to your interface endpoint, it grants access to the listed Amazon Bedrock actions for all principals on all resources.
This solution uses Amazon CloudWatch to collect operational metrics from various services to generate custom dashboards that you can use to monitor the deployment’s performance and operational health.
The return flow of the traffic traverses the same path in reverse direction.
Conclusion
In this post, we reviewed the secure network design principles that provide a robust foundation for deploying generative AI applications on AWS while maintaining strong security controls. By implementing the patterns described in this post, you can confidently use AI capabilities while protecting sensitive data and infrastructure.
Want to dive deeper into additional areas of generative AI security? Check out the other posts in the Securing generative AI series:
Part 1 – Securing generative AI: An introduction to the generative AI Security Scoping Matrix
Part 2 – Designing generative AI workloads for resilience
Part 3 – Securing generative AI: Applying relevant security controls
Part 4 – Securing generative AI: data, compliance, and privacy considerations
Part 5 – Build secure network architectures for generative AI applications using AWS services (this post)
In Part 1 of this series, we explored the fundamental risks and governance considerations. In this part, we examine practical strategies for adapting your enterprise risk management framework (ERMF) to harness generative AI’s power while maintaining robust controls.
This part covers:
Adapting your ERMF for the cloud
Adapting your ERMF for generative AI
Sustainable Risk Management
By the end of this post, you’ll have a roadmap for scaling generative AI adoption securely and responsibly.
Adapting your ERMF for the cloud
Before diving into generative AI-specific controls, it’s crucial to understand the fundamental infrastructure that enables these technologies. Cloud computing is the foundational infrastructure that has made generative AI possible and accessible at scale. The development and deployment of large language models and other generative AI systems require massive computational resources, vast amounts of data storage, and sophisticated distributed processing capabilities that cloud systems can efficiently provide.
Cloud technology differs from on-premises IT solutions, and the relationship between financial institutions and cloud service providers is also different from the relationship with a traditional outsourcing provider.
These differences change the nature of many risks that financial institutions face and how they manage them. However, if cloud technology is implemented in the right way, it can reduce risk and provide tools to help Chief Risk Officers (CROs) to manage risk too.
Organizations adopting generative AI can use their enterprise risk management framework to realize business value while maintaining appropriate controls. This approach allows you to build on existing risk management practices while addressing generative AI’s unique characteristics.
When it comes to model management and the AI system lifecycle, customers can consult ISO42001 AI Management, Section A6. This section encompasses capturing the objective and processes for the responsible design and development of AI systems, including criteria and requirements for each stage of the AI system life cycle. This guidance can help organizations verify that their model management practices align with industry standards for responsible AI development.
From a business leader’s perspective, incorporating generative AI considerations into your ERMF helps establish documented good practices, implement effective controls, and maintain transparency about usage across the enterprise. This enables both responsible innovation and prudent risk management. Here’s how organizations are approaching this:
Generative AI policy and governance foundations in ERMF
In the field of generative AI, organizations establish both guardrails for innovation and clear accountability for risk management. The three lines of defense model provides the structure for implementing these foundational elements:
Acceptable use framework for your organization: Clear direction on appropriate generative AI use helps organizations manage risks while enabling innovation. The range of use cases for generative AI is large and likely to expand over the years, making it essential to have clear guidance on what applications are permitted and under what conditions. As organizations explore these opportunities, their framework can evolve with their experience and maturity.
Risk accountability: The generative AI lifecycle—from use case selection through implementation and ongoing monitoring—requires clear ownership across business and control functions. While organizations can establish specific generative AI oversight mechanisms, these should integrate with existing governance structures. Risk reporting and accountability for generative AI initiatives should flow through established enterprise risk committees and governance boards, helping to facilitate consistent risk management across the organization rather than creating isolated pockets of oversight.
Implementation approach for generative AI: Putting principles into practice
Building on the three lines of defense model discussed earlier, organizations can adapt their risk management practices to address the unique characteristics of generative AI while using industry best practices and frameworks. This often involves evolving existing controls and introducing new ones specific to generative AI. AWS services have built-in capabilities that support these enhanced governance, risk management, and compliance requirements, helping organizations to implement controlled and responsible generative AI solutions. This includes, for example, Amazon Bedrock Guardrails, among many others.
Building on the risk areas we outlined earlier, we now explore how organizations can implement controls for each of these areas. For each, we describe the principle and the practical implementation considerations. While organizations might prioritize these areas differently based on their use cases and risk appetite, together they provide a framework for responsible generative AI adoption through ERMF.
While we explore high-level control principles that follow, technical teams can review the AWS Well-Architected Framework – Generative AI Lens for detailed architectural guidance that supports these governance objectives.
Fairness
Generative AI systems can deliver equitable outcomes across different stakeholder groups, helping organizations build trust and meet expectations. Organizations can support this by setting up clear fairness metrics for specific use cases, regularly assessing training data for bias, and closely monitoring performance across different groups. For high-stakes applications, additional checks can help facilitate fair treatment across diverse populations.
Amazon Bedrock Guardrails provides configurable safeguards to help maintain fair and unbiased outputs, with customizable thresholds to match different use case requirements. Amazon Bedrock provides comprehensive model evaluation tools including model cards with detailed bias metrics, to assess bias across demographic groups. Amazon Bedrock includes built-in prompt datasets like the Bias in Open-ended Language Generation Dataset (BOLD), which automatically evaluates fairness across key areas such as profession, gender, race, and various ideologies. These capabilities integrate with Amazon SageMaker Clarify for comprehensive bias detection and mitigation, supported by built-in bias metrics and reporting.
Explainability
Generative AI systems can provide understanding of their decision-making processes, supporting accountability and effective oversight. Explainability is essential for all generative AI systems—whether using custom-built or pre-built models, particularly for complex models like transformer networks.
Organizations can implement practical controls by establishing clear explainability thresholds based on use case risk levels. This remains an active industry challenge, with ongoing research and evolving approaches. For critical business applications, tailoring explanations to different stakeholders while maintaining accuracy can improve understanding and trust.
Amazon Bedrock provides tools that help identify which factors influenced the generative AI’s decisions, while maintaining detailed records of system inputs and outputs. For complex workflows, Chain-of-Thought (CoT) reasoning traces are available through Amazon Bedrock Agents, showing the step-by-step logic behind each decision. Organizations can monitor how responses are generated in real time. For Retrieval-Augmented Generation (RAG) applications, which optimize AI outputs by referencing specific knowledge bases, Amazon Bedrock Knowledge Bases automatically includes references and links to source materials used in generating responses.
Privacy and security
Generative AI systems benefit from strong privacy and security measures to protect sensitive information and help prevent unauthorized access or data exposure. These systems can potentially generate content or unintentionally reveal confidential data, which organizations can proactively manage.
Organizations can set up multi-layered protection strategies, including access controls, content filtering, and data privacy safeguards. This can involve creating company-wide standards for prompt engineering to help prevent harmful outputs, using techniques like RAG to control information sources, and using automated systems to detect and protect personal information. Regular testing and validation, especially to comply with regulations like GDPR, can be part of the development and deployment process.
Amazon Bedrock implements multiple security layers including private endpoints with Amazon Virtual Private Cloud (Amazon VPC) support, fine-grained AWS Identity and Access Management (IAM) access control, and end-to-end encryption. Importantly, it maintains no persistent storage of prompt or completion data and helps preserve model provider isolation.
Amazon Bedrock Guardrails provides sensitive information filters that can detect and protect personally identifiable information (PII) through automated input rejection, response redaction, and configurable regex patterns, supporting various use cases while maintaining data privacy. Organizations like Genesys demonstrate these capabilities at scale, maintaining GDPR compliance while processing 1.5 billion monthly customer interactions through Amazon Bedrock.
For detailed security considerations, see Generative AI Security Scoping Matrix, which provides a comprehensive framework for assessing and addressing generative AI security risks.
Safety
Generative AI systems can be designed and operated with safeguards to avoid harm to individuals, and communities. This includes addressing risks of generating dangerous, illegal, or abusive content, and helping to prevent system misuse.
Organizations can implement specific safety measures through predeployment content filtering, real-time safety boundaries with prompt constraints, and output classification systems to detect and block dangerous content. Context-aware content moderation considers the specific application domain, while automated detection can identify potential safety violations before content generation. Ongoing monitoring and updating of these controls help address evolving capabilities and potential risks of generative AI systems.
Amazon Bedrock Guardrails delivers industry-leading safety protections across text and images, blocking up to 85 percent more harmful content on top of native protections provided by foundation models (FMs). Additional safety controls include token limits to avoid excessive responses, rate limiting against misuse, and moderation endpoints for content screening.
Organizations can maintain appropriate control over generative AI systems to make sure that they work as intended and can be adjusted or stopped if issues arise. This helps manage risks and maintain system reliability.
A multi-layered approach to control includes implementing technical safeguards and operational processes. Organizations can control model behaviour by adjusting parameters such as temperature (controlling output randomness), and sampling methods like top-k or top-p (managing output diversity). Clear operational boundaries define the system’s scope of action, while human-in-the-loop validation provides oversight for critical applications.
For effective control, organizations can establish parameter thresholds tailored to different use cases, implement rapid adjustment mechanisms, and create clear escalation procedures. Amazon Bedrock enhances control through customizable agent prompts and reasoning techniques, and the ability to break complex tasks into smaller, manageable components. Organizations can choose between structured workflows or flexible agent-based approaches. Regular comparison of outputs against established benchmarks helps maintain system reliability.
This balanced approach supports creative AI outputs while helping to facilitate consistent performance within defined quality limits. This helps prevent service degradation and business disruption while minimizing inefficiencies.
Control capabilities are further enhanced through Amazon CloudWatch monitoring integration and robust knowledge base version control. The capabilities of Amazon Bedrock, including LLM-as-a-judge features, help organizations assess and optimize their generative AI applications efficiently.
Veracity and robustness
Generative AI systems can produce reliable and accurate outputs, even when faced with unexpected or challenging inputs. This helps maintain trust and helps maintain the system’s usefulness across various applications.
Organizations can implement a combination of technical and procedural controls to enhance both system robustness and output reliability. This includes establishing clear parameter thresholds for different use cases, implementing human-in-the-loop validation for critical applications, and regularly comparing outputs against established ground truths. The framework specifies when and how these controls are applied based on the use case criticality and required level of accuracy.
Amazon Bedrock Guardrails improves veracity by helping to prevent factual errors through automated reasoning checks that deliver up to 99 percent accuracy in detecting correct responses from models, using mathematical logic and formal verification techniques. This capability supports processing of large documents up to 80,000 tokens and includes automated scenario generation for comprehensive testing.
Amazon Bedrock also includes sophisticated input sanitization features and supports adversarial testing through AWS testing tools integration.
Governance
Effective governance of generative AI systems helps manage risks, maintain accountability, and align AI use with organizational values and regulations. This covers the entire AI lifecycle, from development to deployment and ongoing operation.
Organizations can create clear governance structures, including defined roles for AI oversight, regular risk assessments, and ways to engage with stakeholders. This involves integrating AI governance into existing risk management practices and making sure of compliance with relevant laws and standards. Because AI technology is evolving rapidly, regular reviews and updates to governance practices are essential to address new capabilities, emerging risks, and changing regulatory requirements. This includes providing appropriate training and skill development for system users.
AWS has achieved of ISO/IEC 42001 certification, demonstrating our commitment to systematic governance approaches in AI implementation. Governance features in Amazon Bedrock include comprehensive model provenance tracking, detailed AWS CloudTrail audit logging, and streamlined model deployment approval workflows integrated with AWS Organizations. AWS Audit Manager provides pre-built frameworks to assess generative AI implementation against best practices.
Transparency
Generative AI systems can operate transparently, helping stakeholders understand system capabilities, limitations, and the context of AI-generated outputs. This builds trust and enables informed decision-making by users and affected parties.
Organizations can implement specific transparency measures including comprehensive model documentation detailing intended use cases, known limitations, and performance boundaries. Clear AI disclosure practices should describe when and how AI is being used and what data is being processed. Regular performance reporting can include accuracy rates, error patterns, and bias assessments.
For customer-facing applications, transparency includes providing clear indicators of AI-generated content, documenting how decisions are made, and establishing processes for users to question or challenge outputs. Maintaining detailed version histories of model updates and changes in system behavior helps track the evolution of AI capabilities and their impacts over time.
From the AWS side of the Shared Responsibility Model, transparency is supported through AWS AI Service Cards and detailed documentation of model characteristics. Amazon Bedrock enhances this with comprehensive logging and monitoring capabilities to track model behavior and performance metrics.
Unified risk management
These eight areas are interconnected and mutually reinforcing within the enterprise risk management framework. While organizations might prioritize them differently based on their use cases and risk appetite, together they provide a comprehensive approach to responsible generative AI adoption. For detailed technical guidance, standards, and compliance requirements, see the AWS guidance documents in Resources for technical implementation, at the end of this blog post, that support implementation across these areas.
AI risk management in practice: Building organizational capability
Successful implementation of generative AI systems involves integrating risk management practices across the organization. This includes establishing processes for measuring outcomes and risks and preparing the organization to adapt as technology evolves. Effective risk management depends on building appropriate knowledge and skills at all levels of the organization.
Organizations can create clear pathways from proof of concept to production by aligning with the three lines of defense model. The ERMF provides broad parameters for reliability, safety, and privacy, which business units can adapt for their specific use cases.
To build and maintain lasting capability for both current and future generative AI adoption, organizations can focus on:
Developing incident response plans for AI-specific scenarios
Building expertise through training and certification programs
Regular review and updates of risk management practices
These elements, when woven into the organization’s operating fabric, create sustainable practices that evolve with advancing technology and emerging risks.
Sustainable risk management: Making your ERMF generative AI-ready
Governance, risk, and compliance (GRC) leaders, Chief Risk Officers (CROs), and Chief Internal Auditors (CIAs) can provide sustained executive sponsorship for generative AI adoption. Long-term capability building extends beyond technology and innovation hubs to encompass business and control functions. Clear direction from leadership helps organizations balance generative AI opportunities with appropriate risk management.
Organizations benefit from viewing generative AI as a transformative capability that touches many functions rather than as isolated initiatives. This approach supports sustainable integration of enterprise-wide governance approaches for generative AI, avoiding the limitations of short-term projects with restricted scope and impact.
Organizations can successfully implement generative AI while maintaining their risk management obligations through controlled, well-defined use cases. TP ICAP’s Parameta division demonstrates this approach in their regulatory compliance implementation. By focusing initially on a highly regulated area, maintaining clear governance controls, and making sure there was human oversight in the compliance review process, they established a framework for responsible AI adoption. This led to creating dedicated oversight roles for AI initiatives, strengthening their governance structure for future AI implementations.
Similarly, Rocket Mortgage’s implementation of AWS services for their AI tool Rocket Logic – Synopsis demonstrates how organizations can use Amazon Bedrock for responsible AI integration at scale. This approach enabled them to maintain stringent data security and compliance measures while saving 40,000 team hours annually through automated processes.
Action checklist for sustainable generative AI implementation:
ERMF foundations: Assess and enhance your risk framework’s readiness for generative AI, including acceptable use guidelines and clear accountabilities
Technical controls: Begin with core controls such as Amazon Bedrock Guardrails and expand based on specific use cases and risk profiles
Organizational capability: Develop broad expertise through training and oversight mechanisms across business and control functions
Monitoring and measurement: Create dashboards for key risk indicators and maintain regular reviews
Integration strategy: Align generative AI controls with existing processes and organizational strategy
Conclusion
This two-part series has explored the critical importance of integrating generative AI governance into enterprise risk management frameworks. In Part 1, we introduced the unique risks and governance considerations associated with generative AI adoption. Part 2 has provided a comprehensive guide for adapting your ERMF to address these challenges effectively.
We’ve outlined practical strategies for scaling generative AI adoption securely and responsibly, covering key areas such as fairness, explainability, privacy and security, safety, controllability, veracity and robustness, governance, and transparency. By implementing these strategies and following the action checklist provided, organizations can build sustainable practices that evolve with advancing technology and emerging risks.
Organizations that integrate generative AI governance into their ERMF as described in this post are better positioned to accelerate innovation and operational efficiency while protecting against key risks such as data exposure, model hallucinations, and regulatory non-compliance. This balanced approach enables organizations to capture the transformative potential of generative AI while maintaining the robust controls essential for financial services institutions.
For foundational concepts and risk considerations, see Part 1.
According to BCG research, 84% of executives view responsible AI as a top management responsibility, yet only 25% of them have programs that fully address it. Responsible AI can be achieved through effective governance, and with the rapid adoption of generative AI, this governance has become a business imperative, not just an IT concern. By implementing systematic governance approaches at the enterprise level, organizations can balance innovation with control, effectively managing the risks while harnessing the transformative potential of generative AI.
While generative AI technologies offer compelling capabilities, they also introduce new types of risks that need business oversight and management. Financial institutions face real challenges—AI-driven financial analysis tools could make investment recommendations based on biased data, leading to significant losses, while generative AI-powered customer service systems might inadvertently expose confidential customer information. The unprecedented scale and speed at which generative AI operates makes robust business controls essential. However, with the right governance approach and strategic oversight, these risks are manageable.
Part 1 of this two-part blog post guides business leaders, Chief Risk Officers (CROs), and Chief Internal Auditors (CIAs) through three critical questions:
What specific or unique risks does generative AI introduce and how can they be managed?
How should your enterprise risk management framework (ERMF) evolve to support generative AI adoption?
How can you build sustainable generative AI governance in an ever-changing world—what should be on your checklist?
To address these questions, organizations can use established frameworks and standards including:
ISO/IEC 42001 AI Management System standard – outlining best practices and controls for responsible development, deployment, and operation of AI systems. AWS is the first major cloud provider to achieve accredited certification for this standard.
These frameworks provide valuable guidance for organizations looking to implement responsible and governed AI practices.
Role of GRC leaders, CROs, and CIAs
Governance, risk and control (GRC) functions led by business leaders, CROs and CIAs are well-positioned to advance generative AI innovation in financial services institutions. These functions have successfully managed complex risks in banks for years, and their existing expertise, proven approaches, and established risk frameworks provide a strong foundation for guiding generative AI adoption. They collaborate across the three lines of defense: business leaders making implementation decisions and managing associated risks (first line), risk and compliance functions providing frameworks and oversight (second line), and internal audit providing independent assurance (third line).
If generative AI risks, both perceived and real, are managed through enterprise-wide governance practices rather than isolated project-by-project approaches, organizations can use the advantages offered by generative AI over the long term. This requires integration with the ERMF, with some practices fitting into existing structures while others need deliberate adjustments to ERMF itself to address generative AI’s unique characteristics.
New frontiers in generative AI risk management
The traditional risk landscape at the enterprise level was based on a paradigm in which risks are predicted from past exposures. Preventive controls help stop unwanted things from happening, detective controls discover when bad things slip through the preventive controls, and corrective controls take remediation actions.
Much of this paradigm is still valid in the world of generative AI. For example, access to generative AI applications needs to be managed carefully to avoid unauthorized use. All three types of the preceding controls should help prevent unauthorized use, identify potential breaches, and remedy unauthorized access when detected.
However, additional focus and attention are required in the following areas when implementing generative AI solutions:
Non-deterministic outputs – The non-deterministic nature of generative AI outputs poses a specific challenge. While the probabilistic nature of these systems is often useful, the risk of inaccurate output from the black box can have serious business implications, and organizations need to take conscious actions to address these risks. Organizations can address this through Amazon Bedrock GuardrailsAutomated Reasoning checks, which use mathematically sound verification to help prevent factual errors and hallucinations.
Deepfake threat – Generative AI’s ability to create authentic-looking images and documents extends beyond traditional fraudulent activities. It elevates the threat to an entirely new level, creating eerily realistic content with unprecedented ease—hence the term deepfake. This poses significant challenges for organizations in verifying document authenticity, particularly in processes like Know Your Customer (KYC).
Layered opacity – While enterprises are learning about generative AI, they must address risks from multi-layered AI systems where each layer generates content and makes decisions based on potentially unexplainable models, hampering traceability. For example, consider generative AI outputs from a third-party system serving as inputs to internal AI systems, creating a chain of interdependent decisions. This lack of transparency in critical decisions affecting organizational performance and customer treatment could have profound implications for enterprise trustworthiness, brand reputation, and regulatory compliance.
The following table outlines key generative AI risk areas and their potential business impacts. In Part 2, we explain how organizations can address these risks through their ERMF. Effectively managing these risks through enterprise-wide governance not only protects the organization but also forms the foundation for responsible AI adoption. Robust risk management and governance are essential prerequisites for achieving responsible AI outcomes.
For a comprehensive foundation in responsible AI implementation, see the AWS Responsible Use of AI Guide, which aligns with the governance principles that we discuss throughout this article.
Risk area
Description
Potential risk impact
Fairness
Are the underlying data and algorithms fair and unbiased? Are the outputs leading to fair outcomes for different groups of stakeholders?
Discrimination lawsuits
Loss of trust
Business loss because of exclusion of segments
Explainability
Can stakeholders understand the black box behavior and evaluate system outputs?
Legal liabilities and regulatory sanctions due to inability to explain decisions
Incorrect business decisions
Privacy and security
Are the systems aligned with privacy regulations and security requirements?
Fines arising from data breaches
Loss of trust
Damage because of security incidents
Safety
Are there controls to help prevent harmful system output and misuse?
Harmful content generation
Customer harm
Reputational damage
Controllability
Are there mechanisms to monitor and steer AI system behaviour, including detection of model and data drifts?
Undetected degradation of service
Business disruption because of unreliable decisions
Customer harm
Inefficiencies arising from remediation
Veracity and robustness
Can the system maintain correct outputs even with unexpected or adversarial inputs?
Incorrect business decisions
System failures under stress
Loss of operational reliability
Governance
Are there documented accountabilities across the AI supply chain including model providers and deployers? Are users adequately trained to use systems?
Confusion in crisis management
Personal liability for executives
Regulatory censure for governance failures
System misuse by untrained staff
Transparency
Can stakeholders make informed choices about their engagement with the AI system?
Loss of customer trust
Regulatory non-compliance
Stakeholder dissatisfaction
Remitly’s implementation of Amazon Bedrock Guardrails to protect customer personally identifiable information (PII) data and reduce hallucinations demonstrates how financial institutions can effectively manage privacy and veracity risks in generative AI applications, addressing several of the risk areas outlined above.
Conclusion
In this post, we introduced the critical importance of responsible AI governance for enterprises adopting generative AI at scale. We explored the unique risks that generative AI presents, including non-deterministic outputs, deepfake threats, and layered opacity. We outlined key risk areas such as fairness, explainability, privacy and security, safety, controllability, veracity and robustness, governance, and transparency. These risks underscore the need for a robust enterprise risk management framework tailored to the challenges of generative AI.
We emphasized the crucial role of GRC leaders, CROs, and CIAs in advancing generative AI innovation while managing associated risks. By using established frameworks like the AWS Cloud Adoption Framework for AI, ISO/IEC 42001, and the NIST AI Risk Management Framework, organizations can implement responsible and governed AI practices.
In Part 2 of this series, we explore how organizations can adapt their enterprise risk management framework to address these risks effectively, including specific considerations for cloud and generative AI implementation. We’ll provide detailed guidance on making your ERMF generative AI-ready and outline practical steps for sustainable risk management.
We are excited to share that AWS has been named a Leader in the 2025 Gartner Magic Quadrant for AI Code Assistants for the second year in row. This recognition highlights for us Amazon Q Developer’s commitment to innovation and delivering exceptional customer experiences. We believe this Leader placement showcases our rapid pace of innovation, which makes the whole software development lifecycle easier and increases developer productivity with enterprise-grade access controls and security. We are honored to be recognized by Gartner and are committed to continuing to innovate on behalf of our customers.
The Gartner Magic Quadrant evaluated AI code assistant providers based on their Ability to Execute and Completeness of Vision. Our innovations throughout the software life cycle (SDLC) include code generation, troubleshooting, transformation, cost optimization, and vulnerability scanning.
Leaders in this Magic Quadrant for AI Code Assistants continue to set the benchmark for end-to-end developer enablement through advanced AI capabilities. They consistently integrate cutting-edge models into robust, agentic workflows that enhance productivity, code quality, and security across the SDLC. These vendors exhibit a sharp understanding of enterprise needs, translating customer feedback into iterative improvements and differentiated innovation — such as long-context reasoning, hybrid deployment flexibility, and seamless integration across IDEs and DevSecOps platforms. Leaders also stand out through their operational maturity, supporting global enterprises with scalable infrastructure, regulatory compliance, and strong service-level reliability. Their growing ecosystems, deepening product integration, and strategic clarity ensure sustained influence across diverse developer and enterprise environments.
I joined Amazon Web Services (AWS) as a principal security engineer 3 years ago and my first project was leading security for PL/Rust on Amazon Relational Database Service (Amazon RDS). This is an extension that lets you write custom functions for PostgreSQL in Rust, which are then compiled to native machine code. These functions can be quite performant and offer a lot of advantages to customers.
From my perspective as a security engineer, “compiled to native machine code” was a flashing neon sign that said, “Start work here” with a big arrow pointing to the Rust toolchain and that’s exactly where I dove in.
The pieces of the system
postgrestd is the Rust standard library at the heart of PL/Rust. The design of this library includes prevention for database escapes. However, at the time, it was fairly new and hadn’t yet been hardened to the realities of production environments at scale. Adding to the challenge, PL/Rust compiles extensions on the database instance itself. This requires a full toolchain to be available locally.
If the extension has a full toolchain available, the potential risk increases. Poorly constructed extensions can cause issues for the database or the host instances. Attackers can use a variety of techniques to try to get around the security controls put in place or break the write xor execute (W^X) model for the container.To support PL/Rust and provide this functionality to customers safely, we needed to add a series of mitigations to address these new risks.
Challenging our approach
Behind the scenes in AWS, we obsess over how we operate our systems. We focus on automation and resilience to help make sure that we meet our commitment to our customers. We’ve learned time and time again that simpler is often a better choice. Operating at scale is complicated enough, don’t add to the problem!
SELinux was—and continues to be—a long debated option for a number of solutions. For those unfamiliar, SELinux is a set of kernel features and tools that enforce mandatory access control on Linux subsystems. Using SELinux policies, you can be extremely specific about what is allowed on a system. You can mandate that a process cannot write to a specific file, even if the ownership of that process permits that actor.
In simpler terms, SELinux mandatory access control is another layer of protection that can be added to the existing authorization system. If a process has permissions to a file, SELinux can block those permissions if a policy is configured for that action. It’s a deterministic way of making sure that specific actions don’t happen.
This approach can greatly increase the security of the operating system. The trade off? Reduced flexibility when it comes to operating that system and the effort required to configure mandatory access control to meet your security requirements. Like any security control, you need to understand the benefit and compare it to the potential downside.
When it came to the PL/Rust case, the benefits of SELinux outweighed the downside. This functionality would allow us to provide the ability to enable PL/Rust to customers in a safe and secure manner.
As simple as it is to write that out, the reality was representative of the culture at AWS. As a brand new team member, I brought the idea up and our senior leaders took the time to listen. The discussions were tough as we all deeply questioned the idea and its implementation. One aspect of our culture is that we try to peek around corners and try to anticipate issues before they occur.
This type of discussion and push back on ideas helps make sure that we’re making the right call for our customers. It’s not always easy, but it is worth it. As a result of these discussions, we agreed to try the SELinux approach for this feature.
Building a complete solution
Our builders and operators built the SELinux environment, and we created appropriate policies for enforcement. This was an important first step, but not the most interesting part of the story.
We configured the mandatory access control policies to send denial messages to our telemetry systems. AWS systems generate a lot of telemetry and we regularly use this information to learn about the state of our systems and improve how we operate and design them.
Using this infrastructure, we started to build a process that would allow us to respond and investigate the denial messages generated. Working with our blue team, we developed playbooks for incident response specifically for our Amazon RDS team. We started running game days every quarter, where we have our red team stage exploits on the system and we would respond.
Afterwards, all our teams came together to measure and analyze the responses. We worked to identify bottlenecks or areas where we could improve. This regular effort helped to mature our response quickly.
At this point, we had a strong solution to reduce the risks of enabling PL/Rust, deep monitoring of our systems, and a well-tested incident response process that helped improve the entire setup.
In action
With the feature in production, we use our monitoring system to automatically cut a high severity ticket to our service team for every SELinux denial message. This level of follow-up helps us make sure that the controls are working as expected and it provides valuable insights in the reality of potential risks to the system.
This process for tracking and investigating possible issues helps our team make sure that we’re providing the level of service our customers expect. As PostgreSQL or Rust releases new features, or when customers have a new data analysis need, we want our security controls to support that work, not block it needlessly.
The feedback loop we’ve created with the investigation of the mandatory access control log messages helps our team to stay aware of what activities are being attempted in the environment. This not only helps catch issues that could affect intended uses, but also acts as an intrusion detection system.
An example of this use recently became public. In October, our team was assigned a high severity ticket that was automatically generated based on an SELinux denial message.
After a quick check to make sure that we hadn’t failed to update our monitoring criteria after recent changes to PL/Rust, our red team, blue team, and AWS security sprang into action. Remember, this activity was kicked off in response to unsuccessful access attempts! It was initiated by a message from the system letting us know it had stopped an activity, but—as is our practice—we wanted to understand what had been attempted.
We verified that the SELinux policy was correctly enforced and had blocked the activity in question. That taken care of, we continued to chase down this issue. As an aside, you might be asking yourself why we would continue to work on this case. That’s a valid question, and the answer is straightforward: we’re constantly looking to see if we can improve our systems to be more effective or more efficient.
Finding the root cause of the signal and learning more about it helps to tune our approach. Depending on the situation, we might be able to avoid a potential risk entirely and reduce the volume of alerts. Or we might see an opportunity to roll out a new feature that helps customers achieve their goals without reducing the security of the system.
In this case, our investigation determined that the detected activity was initiated by the research team at Varonis Threat Labs. We reached out to them and let them know that we had detected their activity, offering to work with them because collaboration with the research community often leads to security improvements that benefit our customers.
In this situation, the initial block and detection validated our security approach. Our policies worked as expected and prevented the activity the researchers were attempting to complete.
The research team, Tal Peleg and Coby Abrams at Varonis Threat Labs, recently spoke about this case at BlackHat 2025. They’ve published the details of their work on the Varonis blog.
As a security engineer, this is quite validating. While we test and validate the controls we put in place, to see a concrete example of how that work can benefit our customers is deeply rewarding.
If you have feedback about this post, submit comments in the Comments section below.
Today, I’m happy to share recent Magic Quadrant reports that named AWS as a Leader in more cloud technology markets: Cloud-Native Application Platforms (aka Cloud Application Platforms) and Container Management.
2025 Gartner Magic Quadrant for Cloud-Native Application Platforms AWS has been named a Leader in the Gartner Magic Quadrant for Cloud-Native Application Platforms for 2 consecutive years. AWS was positioned highest on “Ability to Execute”. Gartner defines cloud-native application platforms as those that provide managed application runtime environments for applications and integrated capabilities to manage the lifecycle of an application or application component in the cloud environment.
The following image is the graphical representation of the 2025 Magic Quadrant for Cloud-Native Application Platforms.
Our comprehensive cloud-native application portfolio—AWS Lambda, AWS App Runner, AWS Amplify, and AWS Elastic Beanstalk—offers flexible options for building modern applications with strong AI capabilities, demonstrated through continued innovation and deep integration across our broader AWS service portfolio.
You can simplify the service selection through comprehensive documentation, reference architectures, and prescriptive guidance available in the AWS Solutions Library, along with AI-powered, contextual recommendations from Amazon Q based on your specific requirements. While AWS Lambda is optimized for AWS to provide the best possible serverless experience, it follows industry standards for serverless computing and supports common programming languages and frameworks. You can find all necessary capabilities within AWS, including advanced features for AI/ML, edge computing, and enterprise integration.
2025 Gartner Magic Quadrant for Container Management In the 2025 Gartner Magic Quadrant for Container Management, AWS has been named as a Leader for three years and was positioned furthest for “Completeness of Vision”. Gartner defines container management as offerings that support the deployment and operation of containerized workloads. This process involves orchestrating and overseeing the entire lifecycle of containers, covering deployment, scaling, and operations, to ensure their efficient and consistent performance across different environments.
The following image is the graphical representation of the 2025 Magic Quadrant for Container Management.
AWS container services offer fully managed container orchestration with AWS native solutions and open-source technologies to focus on providing a wide range of deployment options, from Kubernetes to our native orchestrator.
You can connect on-premises and edge infrastructure back to AWS container services with EKS Hybrid Nodes and ECS Anywhere, or use EKS Anywhere for a fully disconnected Kubernetes experience supported by AWS. With flexible compute and deployment options, you can reduce operational overhead and focus on innovation and drive business value faster.
Gartner does not endorse any vendor, product or service depicted in its research publications and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER is a registered trademark and service mark of Gartner and Magic Quadrant is a registered trademark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.
Amazon’s threat intelligence team has identified and disrupted a watering hole campaign conducted by APT29 (also known as Midnight Blizzard), a threat actor associated with Russia’s Foreign Intelligence Service (SVR). Our investigation uncovered an opportunistic watering hole campaign using compromised websites to redirect visitors to malicious infrastructure designed to trick users into authorizing attacker-controlled devices through Microsoft’s device code authentication flow. This opportunistic approach illustrates APT29’s continued evolution in scaling their operations to cast a wider net in their intelligence collection efforts.
The evolving tactics of APT29
This campaign follows a pattern of activity we’ve previously observed from APT29. In October 2024, Amazon disrupted APT29’s attempt to use domains impersonating AWS to phish users with Remote Desktop Protocol files pointed to actor-controlled resources. Also, in June 2025, Google’s Threat Intelligence Group reported on APT29’s phishing campaigns targeting academics and critics of Russia using application-specific passwords (ASPs). The current campaign shows their continued focus on credential harvesting and intelligence collection, with refinements to their technical approach, and demonstrates an evolution in APT29’s tradecraft through their ability to:
Compromise legitimate websites and initially inject obfuscated JavaScript
Rapidly adapt infrastructure when faced with disruption
On new infrastructure, adjust from use of JavaScript redirects to server-side redirects
Technical details
Amazon identified the activity through an analytic it created for APT29 infrastructure, which led to the discovery of the actor-controlled domain names. Through further investigation, Amazon identified the actor compromised various legitimate websites and injected JavaScript that redirected approximately 10% of visitors to these actor-controlled domains. These domains, including findcloudflare[.]com, mimicked Cloudflare verification pages to appear legitimate. The campaign’s ultimate target was Microsoft’s device code authentication flow. There was no compromise of AWS systems, nor was there a direct impact observed on AWS services or infrastructure.
Analysis of the code revealed evasion techniques, including:
Using randomization to only redirect a small percentage of visitors
Employing base64 encoding to hide malicious code
Setting cookies to prevent repeated redirects of the same visitor
Pivoting to new infrastructure when blocked
Image of compromised page, with domain name removed.
Amazon’s disruption efforts
Amazon remains committed to protecting the security of the internet by actively hunting for and disrupting sophisticated threat actors. We will continue working with industry partners and the security community to share intelligence and mitigate threats. Upon discovering this campaign, Amazon worked quickly to isolate affected EC2 instances, partner with Cloudflare and other providers to disrupt the actor’s domains, and share relevant information with Microsoft.
Despite the actor’s attempts to migrate to new infrastructure, including a move off AWS to another cloud provider, our team continued tracking and disrupting their operations. After our intervention, we observed the actor register additional domains such as cloudflare[.]redirectpartners[.]com, which again attempted to lure victims into Microsoft device code authentication workflows.
Protecting users and organizations
We recommend organizations implement the following protective measures:
For end users:
Be vigilant for suspicious redirect chains, particularly those masquerading as security verification pages.
Always verify the authenticity of device authorization requests before approving them.
Enable multi-factor authentication (MFA) on all accounts, similar to how AWS now requires MFA for root accounts.
Be wary of web pages asking you to copy and paste commands or perform actions in Windows Run dialog (Win+R).
This matches the recently documented “ClickFix” technique where attackers trick users into running malicious commands.
For IT administrators:
Follow Microsoft’s security guidance on device authentication flows and consider disabling this feature if not required.
Enforce conditional access policies that restrict authentication based on device compliance, location, and risk factors.
Implement robust logging and monitoring for authentication events, particularly those involving new device authorizations.
Indicators of compromise (IOCs)
findcloudflare[.]com
cloudflare[.]redirectpartners[.]com
Sample JavaScript code
Decoded JavaScript code, with compromised site removed: “[removed_domain]”
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
This post is co-written with Nazariy Popov, Volodymyr Konchuk, and Andrii Davydenko from EPAM
Legacy code modernization presents significant challenges for organizations looking to stay competitive in today’s rapidly evolving digital landscape. Organizations face the dual challenge of maintaining business continuity while modernizing their legacy systems for cloud environments. This transformation requires organizations to carefully navigate between preserving essential business logic and implementing modern architectural patterns. This is where AI-powered development tools can make a transformative impact, as demonstrated in EPAM’s recent legacy modernization project using Amazon Q Developer.
Amazon Q Developer, an AI code assistant, seamlessly integrates into the development pipeline to address these challenges. This innovative AI code assistant helps teams tackle various tasks, from generating new features, automating language upgrades, and refactoring legacy code to fixing bugs and automating deployments. By providing detailed explanations for its code suggestions while maintaining high quality standards, Amazon Q Developer significantly improves developer efficiency across the entire software development lifecycle, resulting in substantial time and effort savings.
EPAM, an AWS Premier Partner, collaborated with one of their customers to modernize their legacy applications to AWS Cloud. The modernization initiative focused on multiple business-critical applications, primarily built in Java 8 with Oracle Database backend.
In this post, you’ll learn how Amazon Q Developer helped EPAM engineers transform these complex legacy systems into modern cloud-native architectures on AWS. The tool enabled the team to autonomously perform a range of tasks—from implementing new microservices and documenting code to testing, reviewing, and refactoring Java code, as well as performing critical platform upgrades.
Before diving into the details, here’s an overview of how Amazon Q Developer helped EPAM across various aspects of the modernization project:
Summary of Amazon Q Developer Use Cases in EPAM’s Modernization Journey:
Let’s explore each of these areas in detail.
Enhancing developer efficiency (Estimated time savings: 60-70%)
Amazon Q Developer played a crucial role in boosting EPAM’s development productivity. By automating routine tasks and providing intelligent code suggestions, the tool enabled developers to focus on more strategic aspects of the modernization project. Let’s explore how EPAM leveraged these capabilities.
Use Case 1: Generating New API Endpoints
Creating new API endpoints traditionally requires developers to invest 1-2 days per endpoint, involving multiple steps from designing the API contract to writing unit tests and documentation. Using Amazon Q Developer, the team dramatically accelerated this process for three new API endpoints in an existing microservice. Q Developer efficiently generated the initial code implementation along with comprehensive unit test coverage, requiring only minor modifications such as renaming variables, enhancing error handling, and refining test cases. The unit tests generated proved remarkably reliable with minimal adjustments needed. Along with this, Q Developer also generated comprehensive comments/documentation of the code improving the maintainability. This reduced the total development time to just 4 hours for all three endpoints – a 70% time saving compared to the traditional approach, allowing developers to focus on fine-tuning business logic rather than writing boilerplate code.
Use Case 2: Integrating Legacy Systems
Integrating a legacy monolith application with modern microservices traditionally requires developers to manually write extensive integration code, taking 1-2 weeks per integration point. Amazon Q Developer accelerated this process by automatically generating REST API client code in the monolith to consume microservice endpoints, along with data transfer objects (DTOs), error handling, and retry logic with integration test templates. While developers still needed to validate business rules and fine-tune error scenarios, Q Developer’s ability to understand both the legacy monolith’s structure and modern microservice patterns reduced the integration time to 2-3 days per integration point – a 70% time saving. This significantly streamlined the integration process while maintaining the robustness required for production systems.
Use Case 3: Generating and Refactoring JPA Entity Classes
During the modernization effort, new database tables were required to support additional business functionality in both the monolith and microservices. Instead of manually coding the data access layer, Amazon Q Developer automated the process by generating Spring JPA Entity classes from SQL DDL statements. Amazon Q Developer maintained consistency with existing data models by following established naming conventions, applying standard annotations, and implementing required interfaces from the existing codebase. What stood out was Q Developer’s ability to provide detailed explanations for its implementation choices, such as why specific annotations were used or how the new entities aligned with existing persistence patterns, enabling the team to quickly validate the generated code against their architectural standards. Amazon Q Developer generated the complete Java Spring entity class with all the fields. Additionally, Amazon Q Developer refactored the Entity class as well.
Use Case 4: Streamlining Project Documentation
Creating and maintaining up-to-date project documentation is often a time-consuming task for developers. Amazon Q Developer simplified this process by assisting in the generation of README files for the team’s projects. By analyzing the project structure, dependencies, and key components, Q Developer produced initial drafts of README files that included project overviews, setup instructions, and API documentation. This allowed developers to quickly review and refine the documentation, ensuring it met team standards while saving significant time compared to writing everything from scratch.
Use Case 5: Enhancing Jira Ticket Descriptions
Writing detailed, informative Jira ticket descriptions can be a challenge, especially for complex features or bug fixes. Amazon Q Developer aided the team by suggesting detailed descriptions for Jira tickets based on the context of the code changes and related discussions. For example, when creating a ticket for a new feature, Q Developer could propose a description that included the feature’s purpose, key implementation details, and potential impact on other system components. While developers still needed to review and adjust these descriptions, the AI-generated starting point significantly reduced the time spent on ticket management, allowing the team to focus more on actual development work.
Transforming workloads (Estimated time savings: 65-75%)
Moving legacy applications to the cloud requires careful planning and execution. EPAM utilized Amazon Q Developer’s Java upgrade capabilities to streamline the transformation of monolithic applications into modern, cloud-native architectures. Here’s how the Amazon Q Developer facilitated this process.
Use Case 6: Modernizing and upgrading Java applications
Amazon Q Developer assisted in upgrading older Java applications to Java 21 to leverage modern features like Java Streams API and adapting it for Spring Boot tech stack. It not only upgraded the code, but also updated deprecated code components, dependencies and libraries as well. This modernization improved the code’s performance and also aligned it with the current best practices adopted by the development teams. For large monolithic applications, breaking/decomposing the monolith into logical groups while identifying and separating common modules as shared dependencies helped break down the problem into manageable pieces for the agent to do a better job, resulting in a more maintainable and modular structure for the transformation process. This modular approach significantly enhanced Q Developer’s ability to analyze and transform the codebase while reducing the complexity of the modernization effort.
Refactoring Code, Improving Code Quality and Readability (Estimated time savings: 60-75%)
One of the most challenging aspects of modernization is refactoring legacy code and maintaining high code quality standards. Amazon Q Developer assisted EPAM’s team in analyzing complex codebases and suggesting improvements, optimizing the code while preserving business logic and ensuring consistent code quality. The following examples demonstrate this capability in action.
Use Case 7: Refactoring Complex Methods
Legacy code often includes methods with high cyclomatic complexity, making them difficult to maintain. Amazon Q Developer helped the development team refactor large, complex methods into smaller, more readable, and better-structured methods. It also provided a detailed explanation of the changes, highlighting how the refactored code improved maintainability and readability.
Use Case 8: Renaming Across the Repository
When tasked with renaming ‘YTD Tax Report‘ to ‘Withholding Tax Report‘ across the entire repository, Amazon Q Developer demonstrated capabilities beyond simple search and replace functionality found in traditional IDEs. It performed context-aware renaming, distinguishing between instances where ‘YTD Tax Report‘ was part of larger phrases or variable names, while simultaneously updating related components including unit tests, integration tests, and logging statements. The tool intelligently refactored method signatures where the report name was part of method names or parameters, analyzed and updated database queries, and maintained consistency across different file types including Java, XML, and properties files. What set Q Developer apart was its ability to provide detailed change logs explaining each modification and the rationale behind more complex refactoring decisions, significantly reducing the risk of missed references or inconsistencies that often occur with manual search-and-replace operations.
Use Case 9: Code Review and fixes
The code review capabilities of Amazon Q Developer, seamlessly integrated into the IDE, enabled the development team to detect potential issues spanning multiple classes. Beyond merely identifying problems, Q Developer provided actionable fix recommendations that could be easily reviewed and implemented. This proactive approach to code quality allowed the team to address issues during the early stages of development, significantly reducing the likelihood of defects making their way to production environments.
Diagnosing and troubleshooting errors (Estimated time savings: 40-60%)
Quick error resolution is crucial for maintaining development momentum. Amazon Q Developer’s advanced error analysis capabilities helped EPAM’s team identify and fix issues efficiently, reducing debugging time significantly. Here are some examples of how this worked in practice.
Use Case 10: Root Cause Analysis and Fix
During the development phase, the team encountered an unexpected error in one of the Java services: java.lang.IllegalArgumentException: Property 'http://javax.xml.XMLConstants/property/accessExternalDTD' is not recognized. Q Developer conducted a deeper analysis based on the context provided and suggested a more targeted fix and generated the necessary Java code changes, provided unit tests to verify the fix, and outlined potential security implications of the change. This comprehensive solution not only resolved the immediate error but also improved the overall security posture of the XML processing in the application. The team was able to implement and verify the fix within minutes, significantly reducing development.
Use Case 11: Fixing Database Connection Issues
While troubleshooting an issue where the application became unresponsive due to JDBC connection problems, Amazon Q Developer analyzed the project code and identified the missing connection pool configuration. Q Developer suggested implementing essential connection pool parameters like 'maximumPoolSize=20' and 'connectionTimeout=30000' based on the application’s traffic patterns and code. After implementing its suggested configuration, the issue was resolved, significantly improving the application’s stability.
Use Case 12: Complex SQL Query Analysis
Debugging complex SQL queries constructed dynamically in Java code can be challenging. Amazon Q Developer analyzed such queries, broke them down into their component parts, and provided descriptions for query parameters. For instance, when presented with a complex query involving multiple joins and subqueries, Q Developer dissected it into logical blocks, explaining how each part contributed to the overall result set. This made it easier for the team to understand and debug the queries.
Testing and Deployment: Test data generation and Automating Infrastructure Setup (Estimated time savings: 30-50%)
Use Case 13: Generating JSON Request Bodies
When testing new APIs, Amazon Q Developer generated JSON request bodies based on the corresponding Java classes. It provided detailed descriptions of each field and suggested realistic and meaningful default values, making it easier to validate API functionality with real-world scenarios.
Use Case 14: Generating SQL Test Data
Amazon Q Developer generated SQL insert statements with test data based on our existing Java Entity classes. This automation saved us a significant amount of time in creating realistic test data for database validation and integration testing.
Use Case 15: Generating Deployment Files
Amazon Q Developer helped the development team generate essential deployment artifacts, including a Docker file, a startup shell script that was used as an entry point, and a Kubernetes deployment file for a new service. Automating this process not only saves time but also improves consistency across environments.
Ready to transform your developer experience?
EPAM’s experience with Amazon Q Developer has been transformative, significantly accelerating their application modernization efforts while maintaining high code quality. By leveraging Amazon Q Developer, EPAM reduced development time by approximately 70% and improved code quality metrics across the client’s portfolio. This efficiency gains not only accelerated the client’s cloud migration timeline but also resulted in substantial cost savings and faster time-to-market for new features.
Now, it’s your turn to explore Amazon Q Developer:
Schedule a demo: Experience firsthand how Amazon Q Developer can accelerate your development lifecycle. Connect with our team for a personalized demonstration tailored to your specific use case.
Start Your Proof of Concept: Begin your journey with Amazon Q Developer today through a proof of concept. See how it can enhance your team’s productivity and code quality, just as it did for EPAM.
Connect with EPAM: Learn more about EPAM’s success story and best practices for implementing Amazon Q Developer in your organization’s development workflow.
Take the next step in revolutionizing your development process. Visit Amazon Q Developer website or contact your AWS account team to get started.
Authors
EPAM
Nazariy Popov, Delivery Head of GenAI Engineering and Modernization Practice Delivery management professional and technology leader with over 15 years of experience in the IT industry. At EPAM, he drives large-scale transformation programs, focusing on enterprise software development, cloud solutions, and AI assisted engineering and modernization.
Volodymyr Konchuk, Lead Software Engineer Java engineer with more than 11 years of production experience in Java-based web and enterprise applications. Has experience in building ecommerce and retail business applications using Java, Spring tech stack, and Amazon Web Services.
Andrii Davydenko, Delivery Manager Seasoned delivery lead with over 7 years of experience managing ecommerce modernization projects with a focus on application performance optimization.
AWS
Venugopalan Vasudevan (Venu) is a Senior Specialist Solutions Architect focusing on Next Generation Developer Experience and AWS Generative AI services. In this role, Venu, helps organizations optimize their development processes and accelerate their digital transformation journeys using Amazon Q Developer and other AWS Generative AI Services. Also, Venu partners with enterprises to architect and implement Generative AI solutions while establishing robust development practices.
Arun Chandapillai is a Senior Engineering Architect with a strong history of leading cross-functional teams and collaborating with executive stakeholders. He is passionate about helping customers accelerate IT modernization through business-first cloud adoption strategies, with a focus on leveraging generative AI and MLOps. Outside of technology, he is an automotive enthusiast who loves the thrill of the open road, an engaging public speaker, and a philanthropist who lives by the motto ‘you get (back) what you give’.
Jasmine Rasheed Syed is a Senior Customer Solutions manager, focused in accelerating time to value for the customers in their in cloud journey by adopting best practices and mechanisms to transform their business at scale. Jasmine is a seasoned, result oriented leader with 20+ years of progressive experience in Insurance, Retail & CPG with exemplary track record spanning across Business Development, Cloud/Digital Transformation, Delivery, Operational & Process Excellence and Executive Management.
Oscar Hernandez is a Senior Account Executive, helping global organizations drive digital and AI transformation at scale. He works closely with executive teams to integrate cloud and AI-driven solutions that address complex business challenges and deliver measurable enterprise-wide impact. With over 15 years of experience across IT, telecom, financial services, retail, and HR technology, he focuses on enabling innovation, optimizing operations, and maximizing the value of emerging technologies.
On August 4, 2025, Gartner published its Gartner Magic Quadrant for Strategic Cloud Platform Services (SCPS). Amazon Web Services (AWS) is the longest-running Magic Quadrant Leader, with Gartner naming AWS a Leader for the fifteenth consecutive year.
In the report, Gartner once again placed AWS highest on the “Ability to Execute” axis. We believe this reflects our ongoing commitment to giving customers the broadest and deepest set of capabilities to accelerate innovation as well as unparalleled security, reliability, and performance they can trust for their most critical applications.
Here is the graphical representation of the 2025 Magic Quadrant for Strategic Cloud Platform Services.
Gartner recognized AWS strengths as:
Largest cloud community – AWS has built a strong global community of cloud professionals, providing significant opportunities for learning and engagement.
Cloud-inspired silicon – AWS has used its cloud computing experience to develop custom silicon designs, including AWS Graviton, AWS Inferentia, and AWS Trainium, which enable tighter integration between hardware and software, improved power efficiency, and greater control over supply chains.
Global scale and operational execution – AWS’s significant share of global cloud market revenue has enabled it to build a larger and more robust network of integration partners than some other providers in this analysis, which in turn helps organizations successfully adopt cloud.
The most common feedback I hear from customers is that AWS has the largest and most dynamic cloud community, making it easy to ask questions and learn from millions of active customers and tens of thousands of partners globally. We recently launched our community hub, AWS Builder Center to connect directly with AWS Heroes and AWS Community Builders. You can also explore and join AWS User Groups and AWS Cloud Clubs in a city near you.
We have also focused on facilitating the digital transformation of enterprise customers through a number of enterprise programs, such as the AWS Migration Acceleration Program. Using generative AI on migration and modernization, we introduced AWS Transform, the first agentic AI service developed to accelerate enterprise modernization of mission-critical business workloads such as .NET, mainframe, and VMware.
Access the complete full Gartner report to learn more. It outlines the methodology and evaluation criteria used to develop their assessments of each cloud service provider included in the report. This report can serve as a guide when choosing a cloud provider that helps you innovate on behalf of your customers.
Gartner does not endorse any vendor, product or service depicted in its research publications and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER is a registered trademark and service mark of Gartner and Magic Quadrant is a registered trademark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved.
Ten years ago, we announced the general availability of Amazon Aurora, a database that combined the speed and availability of high-end commercial databases with the simplicity and cost-effectiveness of open source databases.
As Jeff described it in its launch blog post: “With storage replicated both within and across three Availability Zones, along with an update model driven by quorum writes, Amazon Aurora is designed to deliver high performance and 99.99% availability while easily and efficiently scaling to up to 64 TiB of storage.”
When we started developing Aurora over a decade ago, we made a fundamental architectural decision that would change the database landscape forever: we decoupled storage from compute. This novel approach enabled Aurora to deliver the performance and availability of commercial databases at one-tenth the cost.
This is one of the reasons why hundreds of thousands of AWS customers choose Aurora as their relational database.
A brief look back at the past Throughout the evolution of Aurora, we’ve focused on four core innovation themes: security as our top priority, scalability to meet growing workloads, predictable pricing for better cost management, and multi-Region capabilities for global applications. Let me walk you through some key milestones in the Aurora journey.
The journey continued with the serverless preview in November 2017, which became generally available in August 2018. Global Database launched in November 2018 for cross-Region disaster recovery. We introduced blue/green deployments to simplify database updates, and optimized read instances to improve query performance.
In 2023, we added vector capabilities with pgvector for similarity search for Aurora PostgreSQL, and Aurora I/O-Optimized to provide predictable pricing with up to 40 percent cost savings for I/O-intensive applications. We launched Aurora zero-ETL integration with Amazon Redshift which enables near real-time analytics and ML using Amazon Redshift on petabytes of transactional data from Aurora by removing the need for you to build and maintain complex data pipelines that perform extract, transform, and load (ETL) operations. This year we added Aurora MySQL zero-ETL integration with Amazon Sagemaker, enabling near real-time access of your data in the lakehouse architecture of SageMaker to run a broad range of analytics.
To simplify scaling for customers, we also increased the maximum storage to 128 TiB in September 2020, allowing many applications to operate within a single instance. Last month, we’ve further simplified scaling by doubling the maximum storage to 256 TiB, with no upfront provisioning required and pay-as-you-go pricing based on actual storage used. This enables even more customers to run their growing workloads without the complexity of managing multiple instances while maintaining cost efficiency.
Most recently, at re:Invent 2024, we announced Amazon Aurora DSQL, which became generally available in May 2025. Aurora DSQL represents our latest innovation in distributed SQL databases, offering active-active high availability and multi-Region strong consistency. It’s the fastest serverless distributed SQL database for always available applications, effortlessly scaling to meet any workload demand with zero infrastructure management.
Aurora DSQL builds on our original architectural principles of separation of storage and compute, taking them further with independent scaling of reads, writes, compute, and storage. It provides 99.99% single-Region and 99.999% multi-Region availability, with strong consistency across all Regional endpoints.
Let’s celebrate 10 years of innovation By attending the August 21 livestream event, you’ll hear from Aurora technical leaders and founders, including Swami Sivasubramanian, Ganapathy (G2) Krishnamoorthy, Yan Leshinsky, Grant McAlister, and Raman Mittal. You’ll learn directly from the architects who pioneered the separation of compute and storage in cloud databases, with technical insights into Aurora architecture and scaling capabilities. You’ll also get a glimpse into the future of database technology as Aurora engineers share their vision and discuss the complex challenges they’re working to solve on behalf of customers.
The event also offers practical demonstrations that show you how to implement key features. You’ll see how to build AI-powered applications using pgvector, understand cost optimization with the new Aurora DSQL pricing model, and learn how to achieve multi-Region strong consistency for global applications.
The interactive format includes Q&A opportunities with Aurora experts, so you’ll be able to get your specific technical questions answered. You can also receive AWS credits to test new Aurora capabilities.
If you’re interested in agentic AI, you’ll particularly benefit from the sessions on MCP servers, Strands Agents, and how to integrate Strands Agents with Aurora DSQL, which demonstrate how to safely integrate AI capabilities with your Aurora databases while maintaining control over database access.
Whether you’re running mission-critical workloads or building new applications, these sessions will help you understand how to use the latest Aurora features.
Register today to secure your spot and be part of this celebration of database innovation.
The guest data of AWS customers running on the AWS Nitro System and Nitro Hypervisor is not at risk from a new attack dubbed “L1TF Reloaded.” No additional action is required by AWS customers; however, AWS continues to recommend that customers isolate their workloads using instance, enclave, or function boundaries as described in AWS public documentation. The AWS Nitro System and Nitro Hypervisor are designed to help protect against this class of attacks.
The Nitro Hypervisor’s protection against L1TF Reloaded is not the result of a specific patch or reactive mitigation, but rather due to the proactive approach to security at AWS. The fundamental security design principles of the Nitro Hypervisor—particularly the implementation of secret hiding through an extensive use of the eXclusive Page Frame Ownership (XFPO) concept (in some contexts referred to as process-localmemory)—provides robust protection against this class of attacks. L1TF Reloaded represents an innovative approach to transient execution attacks, showing how threat actors can combine seemingly mitigated vulnerabilities to create new attacks that are more than the sum of their parts. The research is impressive and constructs a multilayer end-to-end exploit with real-world applicability. AWS sponsored a portion of this work and would like to thank the researchers for their collaboration and coordinated disclosure. The remainder of this post is a deeper dive into the published research.
The Nitro Hypervisor: Purpose-built for security
The Nitro Hypervisor is a foundational component of the AWS Nitro System, designed from the ground up with security as a primary consideration. Unlike traditional hypervisors that evolved from general-purpose operating systems, the Nitro Hypervisor, which is based on Linux/Kernel-based Virtual Machine (KVM), has been intentionally minimized and purpose-built with only the capabilities needed to perform its assigned functions.
The Nitro Hypervisor’s responsibilities are deliberately constrained: it receives virtual machine (VM) management requests from the Nitro Controller, partitions memory and CPU resources using hardware virtualization features, and assigns PCIe devices, including both Physical (PF) and Single Root I/O Virtualization (SR-IOV) Virtual Functions (VF) provided by Nitro hardware (such as NVMe for EBS and instance storage, and Elastic Network Adapter for networking) and third party devices (GPUs), to VMs. Critically, the Nitro Hypervisor excludes entire categories of functionality that exist in conventional hypervisors. There is no networking stack, no general-purpose file system implementations, no peripheral device-driver support, no shell, and no interactive access mode. This meticulous exclusion of non-essential features helps avoid entire classes of issues and attack vectors that can impact other hypervisors, such as remote networking attacks or driver-based privilege escalations.
Understanding transient execution vulnerabilities
To understand why the Nitro Hypervisor’s defenses are effective against L1TF Reloaded, it is important to first understand the fundamentals of transient execution vulnerabilities that emerged in 2018. Modern CPUs implement out-of-order and prediction-based speculative execution to optimize performance by executing operations before they are needed or before the CPU knows whether it should perform them at all. When predictions are wrong, or the CPU encounters execution faults, the CPU will eventually detect these errors and roll back all speculatively computed changes to the architectural state. However, traces of these “transient executions” remain detectable in the microarchitectural state, such as data that was speculatively loaded into CPU caches, creating opportunities for data leakage through side-channel attacks.
Half-Spectre gadgets: Incomplete but dangerous code patterns
While traditional Spectre attacks require complete “gadgets” that both access secret data and transmit it through side channels, researchers have identified a weaker class of gadgets called “half-Spectre gadgets.” These are incomplete Spectre-like code patterns that perform speculative out-of-bounds memory accesses, but lack the transmission component that would make them immediately exploitable.
A classic Spectre v1 gadget contains two key elements: first, a speculative access that loads secret data (such as x = A[index] where index is out of bounds), and second, a transmission mechanism that leaks the data through a side channel (such as y = B[64 * x] that creates cache patterns based on the secret value). Half-Spectre gadgets contain only the first element—the speculative access—without the transmission component.
Because half-Spectre gadgets appear harmless in isolation, they are commonly found throughout software, including hypervisors. These gadgets typically arise from array-indexing operations where bounds checking occurs, but the transient execution window allows out-of-bounds access before the bounds check resolves. The gadgets can be either absolute (directly providing the address to access) or relative (controlling an offset from a base address), with relative gadgets being more common due to typical array indexing patterns. The key insight of L1TF Reloaded is that half-Spectre gadgets, while harmless alone, become dangerous when combined with other vulnerabilities like L1TF. A threat actor can trigger a half-Spectre gadget in the hypervisor to speculatively load arbitrary data into the L1 data cache and then use L1TF to extract that cached data—effectively turning the “harmless” half-Spectre gadget into a complete gadget.
L1 Terminal Fault (L1TF), discovered in January 2018 and disclosed in August 2018, represents a significant type of transient execution vulnerability that affects Intel processors up to Coffee Lake. These processors are used in some 5th generation EC2 instance families and all older instance types. L1TF leverages faulty address translations during transient execution when accessing invalid page table entries. Under normal operation, when a CPU encounters a Page Table Entry (PTE) with the present bit cleared or reserved bits set, address translation should halt immediately. However, during transient execution, Intel processors affected by L1TF ignore these invalid page table states and utilize a partially translated address. If the target data exists in the L1 data cache, the CPU will speculatively load it and make it available to subsequent instructions, even though the access should be blocked. This behavior is particularly problematic in virtualized environments. A malicious guest operating system can deliberately clear present bits in its own page tables to trigger terminal faults. When this happens, the CPU skips the normal host address translation process and passes the guest physical address directly to the L1 data cache. This allows the threat actor to potentially read any cached physical memory on the system, regardless of ownership or privilege boundaries. For affected processors, comprehensive software mitigation requires expensive measures, like disabling Simultaneous Multi-Threading (SMT), flushing the L1 data cache on every context switch, or disabling Extended Page Tables (EPT) entirely—performance costs so significant that many systems implement only partial mitigations.
The L1TF Reloaded attack: Exploiting mitigation gaps using Spectre
The research paper demonstrates how threat actors can combine half-Spectre gadgets with L1TF to create a powerful attack vector against hypervisors that lack complete implementation of the previously outlined mitigations. The attack shows that vulnerabilities considered individually mitigated can still be leveraged if combined in novel ways. L1TF Reloaded works by leveraging the fact that while L1TF mitigations like L1 data cache flushing and core scheduling help prevent guest-to-guest attacks, they do not fully mitigate guest-to-host attacks. The attack operates across logical cores that share the L1 data cache in an SMT core. On one logical core, the threat actor triggers a half-Spectre gadget. By mistraining the branch predictor, the threat actor causes the hypervisor to speculatively access out-of-bounds memory, loading sensitive data into the shared L1 data cache. Simultaneously, on the other logical core, the threat actor uses L1TF to extract the cached data. While other research papers have demonstrated L1TF exploitation, this research paper has successfully demonstrated a multilayer end-to-end attack on upstream Linux/KVM and other cloud providers. The authors were able to use an existing half-Spectre gadget, break host Kernel Address Space Layout Randomization (KASLR), gain host address translation capability, find all the processes running on the host, identify the victim VM, break guest KASLR, gain guest address translation capability, identify the init process in the victim VM, enumerate the child processes of the init process, identify the nginx webserver process, locate the private TLS certificate in the guest process heap, and finally leak the private TLS certificate. However, when they attempted the same attack on AWS instances, they encountered a critical limitation: while they could leak some non-sensitive host data, they were unable to access guest data due to what they described as “an undocumented defense in the hypervisor that unmaps victim data from it. This “undocumented defense” is the Nitro Hypervisor’s implementation of secret hiding—a fundamental architectural decision that prevented this type of attack.
Traditional hypervisor designs follow a hierarchical privilege model where each higher level of privilege is granted access to all lower level memory. In conventional systems, the hypervisor running at the highest privilege level can access all VM memory, ostensibly for legitimate management purposes. However, this design creates a vulnerability: if a threat actor can trick the hypervisor into speculatively accessing guest data, that data becomes available for extraction through side-channel attacks. The Nitro Hypervisor takes a fundamentally different approach through a technique called secret hiding. Instead of following the traditional model where the hypervisor has access to all VM memory (Figure 1), the Nitro Hypervisor makes sure that guest data is not present in the hypervisor’s virtual address space. By removing VM memory pages from the hypervisor’s virtual address space (Figure 2), we avoid the possibility of transient execution attacks accessing guest data, even if a threat actor successfully triggers gadgets within the hypervisor.
Figure 1: Memory view of the hypervisor without mitigations in the context of VM1
Figure 2: Memory view of the Nitro Hypervisor in the context of VM1. While no guest memory is mapped, only the state of the active guest can be accessed with other guest states remaining inaccessible.
This architectural decision means that when transient execution occurs in the Nitro Hypervisor—whether through L1TF, half-Spectre gadgets, or other transient execution vulnerabilities—there is simply no guest data available to be leaked, creating a barrier against this class of vulnerabilities. The Nitro Hypervisor retains access only to its own data, but guest data remain isolated and inaccessible. While we could not anticipate L1TF Reloaded exactly, we knew transient execution vulnerabilities would continue to be discovered and built defense-in-depth mechanisms which blocked extraction of guest data on AWS instances. This design decision was made proactively during the Nitro Hypervisor development, based on our threat model that explicitly includes guest-to-host attacks that exploit the hypervisor. By assuming that threat actors might find ways to trigger transient execution vulnerabilities within the Nitro Hypervisor—whether through known vulnerabilities like L1TF or future unknown attack vectors—we designed the system to limit the scope of such attacks from the outset.
Beyond memory: Protecting guest CPU context
When VMs are scheduled and context-switched, guest CPU context information such as general-purpose and floating-point register content must be saved and restored. Guest CPU context can contain highly sensitive information. Registers might contain cryptographic keys, memory addresses that could defeat Address Space Layout Randomization (ASLR), or other secrets that applications rely on for security. In traditional hypervisors, guest CPU context is often stored in memory accessible to the hypervisor, creating another potential target for transient execution attacks. The original XPFO (eXclusive Page Frame Ownership) implementation makes sure that either user space or the kernel—but not both—can access a memory page and does not protect guest CPU context since it is exclusively owned by the kernel. The Nitro Hypervisor extends the XPFO concept to guest CPU context by saving it in memory—also known as process-local memory—that is solely mapped by process-specific kernel Page Table Entries (PTEs), as is shown in Figure 2 above. This memory is specifically designed to be only accessible from the Nitro Hypervisor in the context of the process it belongs to. This makes sure that even if a threat actor successfully triggers transient execution vulnerabilities within the Nitro Hypervisor, they cannot access the guest CPU context from other guests. The researchers confirmed this protection, noting that the AWS threat model accounts for guest-to-host attacks and that secret hiding, combined with existing L1 data cache flushing and core scheduling, prevented them from leaking guest data. This comprehensive approach to secret hiding demonstrates the defense-in-depth philosophy of the Nitro System: rather than protecting only known attack vectors, AWS systematically identifies and protects potential sources of guest data leakage, including both VM memory and guest CPU context.
Applying secret hiding principles to Xen
Most AWS Xen instances are now running on the AWS Nitro System and hence enjoy the benefits of the Nitro Hypervisor thanks to Xen-on-Nitro. For our portfolio of instance families running on the AWS Xen Hypervisor, we have implemented similar secrethiding principles to provide protection against transient execution attacks.
Defense in depth: The Nitro Hypervisor’s proven security model
L1TF Reloaded represents an important advancement in our understanding of how seemingly mitigated vulnerabilities can be combined to create new attack vectors. The researchers of the Rain paper demonstrated how L1TF and half-Spectre gadgets can work together to leak guest data from hypervisors. We are pleased to support their work and collaborate with them. The Nitro Hypervisor’s protection against L1TF Reloaded is not the result of a specific patch or reactive mitigation, but rather due to AWS deeply investing in securing multi-tenant cloud environments against sophisticated adversaries. This research reinforces our confidence in the Nitro System’s security model against both known and unknown attack vectors. The proactive security approach of AWS includes designing systems with defense-in-depth principles from the ground up. The threat landscape will continue to evolve, and at the same time, the defense-in-depth mechanisms built into the Nitro Hypervisor and our other products and services will continue to help protect AWS customers from sophisticated attacks, while maintaining the performance and functionality they depend on.
At Amazon Web Services (AWS), customer privacy and security are our top priority. We provide our customers with industry-leading privacy and security when they use the AWS Cloud anywhere in the world. In recent months, we’ve noticed an increase in inquiries about how we manage government requests for data. While many of the questions center around a 2018 U.S. law known as the Clarifying Lawful Overseas Use of Data Act (CLOUD Act), the CLOUD Act in fact did not give the U.S. government any new authority to compel data from providers and provides critical legal guardrails to protect content.
To put this whole issue in context—there have been no data requests to AWS that resulted in disclosure to the U.S. government of enterprise or government content data stored outside the U.S. since we started reporting the statistic in 2020. Our commitment to protecting customer data is underpinned by several layers of legal, technical, and operational protection. For example, AWS has designed its core products and services to prevent anyone but the customer and those authorized by the customer from accessing the customer’s content. And in these instances, any government that wants access to the customer’s content would have to seek that data directly from the customer. Additionally, U.S. law itself provides numerous statutory protections that help lower the risk that AWS could be required to disclose enterprise or government content data, and the U.S. Department of Justice (DOJ) has implemented additional operational protections over the past eight years.
With that in mind, we want to address some common misconceptions about the CLOUD Act and provide some clarity about how this law impacts—or doesn’t impact—AWS customers worldwide. We’re also expanding our FAQs on the CLOUD Act to help our customers and partners better navigate this topic.
Fact 1: The CLOUD Act does not give the U.S. government unfettered or automatic access to data stored in the cloud
The CLOUD Act was passed to address challenges law enforcement faced in obtaining data stored abroad in cross-border investigations involving serious crimes, ranging from terrorism and violent crime to sexual exploitation of children and cybercrime. The CLOUD Act primarily enabled the U.S. to enter into reciprocal executive agreements with trusted foreign partners to obtain access to electronic evidence for investigations of serious crimes, wherever the evidence happens to be located, by lifting blocking statutes under U.S. law. Many governments rely on domestic laws to require providers within their jurisdiction to disclose electronic data under the companies’ control, regardless of where the data is stored. Similarly, The CLOUD Act clarified that U.S. law enforcement can use existing authorities such as a court-approved search warrant to compel data within a provider’s control, regardless of where the data is stored; the executive agreements enable the effectiveness of these reciprocal laws, supported by strong procedural and substantive safeguards.
Access to data under U.S. law is far from unfettered or automatic, and law enforcement must meet strict legal standards. Under U.S. law, providers are actually prohibited from disclosing data to the U.S. government absent a legal exception. To compel a provider to disclose content data, law enforcement must convince an independent federal judge that probable cause exists related to a particular crime, and that evidence of the crime will be found in the place to be searched (that is, a specific electronic account such as an email account). This legal standard must be established through specific and trustworthy facts. Each search warrant must pass this stringent probable cause determination using credible facts, particularity, and legality, must receive approval from an independent judge, and must meet requirements regarding scope and jurisdiction. In May 2023, the DOJ also issued a policy that prosecutors seeking evidence known to be located abroad must obtain approval from Department’s Office of International Affairs (OIA) prior to obtaining an order for such evidence. The DOJ policy on evidence abroad notes that every nation enacts laws to protect its sovereignty; OIA works to address these issues and assist prosecutors in selecting an appropriate mechanism to secure evidence.
Fact 2: AWS has not disclosed any enterprise or government customer content data under the CLOUD Act since we started tracking the statistic
AWS has rigorous procedures in place for handling law enforcement requests from any country to validate legitimacy and verify that they comply with applicable law. AWS recognizes the legitimate needs of law enforcement agencies in investigating criminal and terrorist activity, but they must observe legal safeguards for conducting such investigations. We do not disclose customer data in response to any government request unless we are obligated to do so by a legally valid and binding order. We have publicly committed to this in our legal terms. Additionally, we will challenge government requests that conflict with the law, are overbroad, or are otherwise inappropriate (for example, if such a request would violate individuals’ fundamental rights). When we receive such requests for enterprise customer content, we make every reasonable effort to redirect law enforcement to the customer and notify the customer when legally permitted. If we are required to disclose customer content, we notify customers before disclosure to provide them an opportunity to seek protection from disclosure unless prohibited by law. If after exhausting these steps, AWS remains compelled to disclose customer data, and we have the technical ability to do so (which, as described above, in many instances we do not), we disclose only the minimum necessary to satisfy the legal process.
Consistent with our policy to redirect law enforcement to customers, the DOJ’s Computer Crime and Intellectual Property Section has also issued guidance advising prosecutors to generally seek data directly from an enterprise, such as a company that stores data with a cloud provider, rather than from the provider.
A clear measure of the effectiveness of our measures and the rigorous legal requirements embodied in law is the fact that since we began reporting this statistic in 2020, AWS has not disclosed any enterprise or government customer content data stored outside the U.S. to the U.S. government. This record reflects the technical safeguards AWS offers, the robust legal protections within U.S. law, policies implemented by the DOJ, and the nature of law enforcement investigations which primarily focus on collecting electronic evidence from consumer accounts.
Fact 3: The CLOUD Act does not only apply to U.S.-headquartered companies—it applies to all providers that do business in the United States
The CLOUD Act applies to all electronic communication service or remote computing service providers that operate or have a legal presence in the U.S.—regardless of where their headquarters are located. For example, European-headquartered cloud providers with U.S. operations are also subject to the Act’s requirements. OVHcloud, a French headquartered cloud service provider that operates in the U.S., notes in its CLOUD Act FAQ page that “OVHcloud will comply with lawful requests from public authorities. Under the CLOUD Act, that could include data stored outside of the United States.” Similarly, other cloud providers headquartered in the E.U. and elsewhere, also have operations in the U.S.
Fact 4: The principles in the CLOUD Act are consistent with international law and the laws of other countries
The CLOUD Act did not introduce a new legal concept regarding the scope of electronic data that must be disclosed as part of legitimate criminal investigations. Many countries require disclosure of customer data wherever it’s stored in response to legal process involving serious crimes. The United Kingdom’s (U.K.’s) Crime (Overseas Production Orders) Act, for instance, allows U.K. law enforcement agencies to obtain stored electronic data located outside of the U.K. in connection to a criminal investigation. According to a 2024 filing by the U.S. DOJ, the laws of several European Union member states, including Belgium, Denmark, France, Ireland, and Spain, have similar requirements. In fact, since 2023, most law enforcement requests that AWS receives come from authorities outside of the United States.
This concept is also enshrined within the Budapest Convention on Cybercrime, which was the first international treaty aimed at improving cooperation in investigations of cybercrimes. Additionally, the EU’s e-Evidence Regulation, 2023/1543, adopted in August 2023, authorizes Member States to “order a service provider…to produce or preserve electronic evidence regardless of the location of data.” The GDPR also allows for transfers of personal data in response to compelled disclosure requests from third countries, provided that the relevant party can cite an appropriate legal basis and transfer mechanism or derogation (see EDPB’s recent Guidelines 02/2024 on Article 48).
AWS is advocating for governments to conclude reciprocal executive agreements under the CLOUD Act, including between the U.S. and the European Union, and the U.S. and Canada. We believe these agreements are important to definitively resolve potential conflicts of law and enable effective investigation of serious crimes to advance public safety, while recognizing the strong substantive and procedural safeguards that already exist under U.S. law.
Fact 5: The CLOUD Act does not limit the technical measures and operational controls AWS offers to customers to prevent unauthorized access to customer data
We can only respond to legal requests for data where we have the technical ability to do so. AWS has a number of products and services designed to make sure that no one—not even AWS operators—can access customer content. AWS customers also have a range of additional technical measures and operational controls to prevent access to data. For example, many of the AWS core systems and services are designed with zero operator access, meaning the services don’t have any technical means for AWS operators to access customer data in response to a legal request.
The AWS Nitro System, which is the foundation of AWS computing services, uses specialized hardware and software to protect data from outside access during processing on Amazon Elastic Compute Cloud (Amazon EC2). By providing a strong physical and logical security boundary, Nitro is designed so that no unauthorized person—not even AWS operators—can access customer workloads on EC2. The design of the Nitro System has been validated by the NCC Group, an independent cybersecurity firm. The controls that help prevent operator access are so fundamental to the Nitro System that we’ve added them in our AWS Service Terms to provide an additional contractual assurance to all of our customers.
We also give customers features and controls to encrypt data, whether in transit, at rest, or in memory. All AWS services already support encryption, with most also supporting encryption with customer managed keys that are inaccessible to AWS. AWS Key Management Service (AWS KMS) is the first highly scalable, cloud-native key management system with FIPS 140-3 Security Level 3 certification. In plain English, this means AWS offers encryption that is super strong and where our customers control who gets a key.
Continuing our customer obsession
At AWS, our customer-first approach drives everything we do—from how we design our services to how we protect your data. We understand that your trust is earned through transparency, strong technical controls, and unwavering advocacy for your interests. That’s why we’ve been clear about how we handle government requests for data, including the impact of the CLOUD Act, and the multiple layers of protection—legal, operational, and technical—to safeguard your data.
We encourage you to learn more about this important topic by reviewing our expanded CLOUD Act FAQ. We will continue to innovate on your behalf, building new features and services that put you in control of your data, and maintaining our commitment to the highest standards of privacy and security.
French version
CLOUD Act : cinq points clés pour comprendre son fonctionnement réel
Chez Amazon Web Services (AWS), la confidentialité et la sécurité des clients constituent notre priorité absolue. Nous mettons à leur disposition une confidentialité et une sécurité à la pointe de l’industrie lorsqu’ils utilisent le Cloud AWS, partout dans le monde. Ces derniers mois, nous avons constaté une augmentation des questions concernant notre gestion des demandes d’accès aux données émanant d’autorités gouvernementales. Si de nombreuses interrogations portent sur une loi américaine de 2018 connue sous le nom de Clarifying Lawful Overseas Use of Data Act (CLOUD Act), cette loi n’a en réalité octroyé aucune nouvelle prérogative au gouvernement américain pour contraindre les fournisseurs à divulguer des données. Elle prévoit des garde-fous juridiques essentiels pour protéger les données des utilisateurs.
Replaçons cette question en perspective : depuis que nous avons commencé à publier des rapports sur les demandes d’informations en 2020, aucune demande n’a abouti à la divulgation auprès du gouvernement américain, de données d’entreprises ou de gouvernements stockées hors des États-Unis. Notre engagement à protéger les données de nos clients repose sur plusieurs niveaux de protection juridique, technique et opérationnelle. A titre d’exemple, les principaux produits et services d’AWS ont été conçus by design de manière à empêcher quiconque, hormis le client et les personnes autorisées par celui-ci, d’accéder à ses données. Ainsi, toute autorité gouvernementale souhaitant accéder aux données d’un client doit en faire la demande directement auprès de celui-ci. En outre, la législation américaine prévoit elle-même de nombreuses protections statutaires qui limitent la possibilité qu’AWS soit contrainte de divulguer des données d’entreprises ou de gouvernements. Le Département de la Justice américain (DOJ) a mis en place des mesures de protections supplémentaires au cours des huit dernières années d’un point de vue opérationnel.
Dans ce contexte, nous souhaitons revenir sur certaines idées reçues courantes à propos du CLOUD Act et apporter des éclaircissements sur l’impact – ou l’absence d’impact – de cette loi sur les clients d’AWS dans le monde entier. Afin d’aider nos clients et partenaires à mieux appréhender ce sujet, nous avons également complété notre FAQ sur le CLOUD Act.
Fait n°1 : Le CLOUD Act n’accorde pas au gouvernement américain un accès illimité ou automatique aux données stockées dans le cloud
Le CLOUD Act a été adopté pour répondre aux défis rencontrés par les autorités judiciaires dans l’obtention des données stockées à l’étranger dans le cadre d’enquêtes transfrontalières sur des crimes graves, allant du terrorisme et des crimes violents à l’exploitation sexuelle d’enfants et à la cybercriminalité. Le CLOUD Act a principalement permis aux États-Unis de conclure des accords exécutifs réciproques avec des partenaires étrangers de confiance. Ces accords visent à faciliter l’accès aux preuves électroniques dans le cadre d’enquêtes sur des crimes graves, indépendamment de la localisation de ces preuves. Pour ce faire, le CLOUD Act lève certaines restrictions prévues par la législation américaine.
De nombreux gouvernements s’appuient sur leurs lois nationales pour exiger des fournisseurs assujettis à ces lois qu’ils divulguent des données électroniques sous leur contrôle, indépendamment du lieu de stockage de ces données. De même, le CLOUD Act a clarifié que les autorités judiciaires américaines pouvaient s’appuyer sur les dispositifs légaux existants, tel qu’un mandat de perquisition autorisé par un tribunal, pour exiger d’un fournisseur la divulgation de données sous son contrôle, indépendamment de leur localisation. Les accords exécutifs bilatéraux permettent la mise en œuvre effective de ces accords de réciprocité, encadrée par des garanties procédurales et juridiques rigoureuses.
L’accès à des données en vertu de la loi américaine est loin d’être illimité ou automatique, et les autorités judiciaires doivent respecter des conditions juridiques strictes. En vertu de la loi américaine, il est de fait interdit aux fournisseurs de divulguer des données au gouvernement américain, sauf exception spécifique. Pour contraindre un fournisseur à la divulgation de données, les autorités judiciaires doivent démontrer devant un juge fédéral indépendant qu’il existe des indices graves et concordants relatifs à un crime et qu’il est probable que des éléments de preuve de ce crime se trouvent dans le périmètre visé par la perquisition (par exemple, un compte électronique spécifique tel qu’une messagerie). La mise en œuvre de cette exception doit s’appuyer sur des éléments factuels précis et vérifiables.
Chaque mandat de perquisition est soumis à cette évaluation stricte de la présence d’indices graves et concordants, qui doit reposer sur des faits crédibles, respecter les critères de spécificité et de légalité, être autorisé par un juge indépendant et satisfaire aux conditions de compétence matérielle et juridictionnelle. En mai 2023, le DOJ a par ailleurs publié des directives imposant aux procureurs qui recherchent des preuves localisées à l’étranger d’obtenir préalablement l’autorisation du Bureau des Affaires Internationales (OIA) avant d’obtenir toute ordonnance. La politique du DOJ concernant les preuves situées à l’étranger reconnaît que chaque État adopte des lois pour protéger sa souveraineté. L’OIA intervient pour traiter ces questions et accompagner les procureurs dans l’identification des mécanismes appropriés d’obtention des preuves.
Fait n°2 : Depuis la mise en place du suivi statistique, AWS n’a divulgué aucune donnée d’entreprise ou de gouvernement en vertu du CLOUD Act
AWS applique des procédures strictes pour traiter les demandes des autorités judiciaires de tout pays, en vérifiant leur légitimité et leur conformité à la réglementation applicable. Si AWS reconnaît les besoins légitimes des autorités judiciaires dans leurs enquêtes sur les activités criminelles et terroristes, les autorités doivent respecter les mesures de protection juridiques encadrant ces enquêtes. En effet, notre politique est claire : nous ne divulguons pas les données des clients en réponse à une demande gouvernementale, sauf si nous en sommes contraints par une ordonnance juridiquement valide et contraignante. Nous avons pris cet engagement publiquement dans nos conditions juridiques.
Nous contestons les demandes gouvernementales qui s’avèrent illégales, disproportionnées ou inappropriées (notamment celles qui porteraient atteintes aux droits fondamentaux des individus). Pour les demandes concernant les données d’entreprises clientes, nous mettons tout en œuvre pour rediriger les autorités judiciaires vers le client et l’informer lorsque la loi le permet. En cas d’obligation de divulgation des données d’un client, nous l’en informons au préalable pour lui permettre de se prémunir contre cette divulgation, sauf interdiction par la loi. Si, après ces étapes, AWS reste contrainte de divulguer des données client et dispose de la capacité technique de le faire (ce qui, comme mentionné précédemment, est rarement le cas), nous limitons la divulgation au strict minimum requis par la procédure judiciaire.
Conformément à notre politique de redirection des autorités judiciaires vers les clients, le département des crimes informatiques et de la propriété intellectuelle du DOJ américain a également émis des lignes directrices recommandant aux procureurs de privilégier l’obtention des données directement auprès de l’entreprise concernée, plutôt qu’auprès du fournisseur cloud hébergeant ces données.
Une preuve tangible de l’efficacité de nos mesures et des exigences juridiques rigoureuses inscrites dans la loi : depuis le début du suivi de cette statistique en 2020, AWS n’a divulgué au gouvernement américain aucune donnée de client d’entreprise ou de gouvernement stockée hors des États-Unis. Ce bilan résulte des garanties techniques offertes par AWS, des conditions juridiques strictes prévues par la législation américaine, des politiques mises en œuvre par le DOJ, et de la nature des enquêtes des autorités judiciaires qui ciblent principalement la collecte de preuves électroniques issues de comptes de particuliers.
Fait n°3 : Le CLOUD Act ne s’applique pas uniquement aux entreprises dont le siège est situé aux États-Unis, mais à toute entreprise exerçant une activité commerciale aux États-Unis
Le CLOUD Act s’applique à l’ensemble des fournisseurs de services de communication électronique ou de services informatiques à distance qui exercent une activité ou disposent d’une présence juridique aux États-Unis, indépendamment de la localisation de leur siège social. Par conséquent, les fournisseurs de services cloud européens ayant des activités aux États-Unis sont également assujettis aux dispositions de cette loi. À titre d’exemple, OVHcloud, entreprise française de services cloud présente aux États-Unis, précise dans sa FAQ relative au CLOUD Act qu’”OVHcloud se conformera aux demandes légales des autorités publiques. En vertu du CLOUD Act, cela pourrait inclure des données stockées en dehors des États-Unis.” De même, d’autres fournisseurs de cloud dont le siège est situé dans l’Union européenne ou ailleurs exercent également des activités aux États-Unis.
Fait n°4 : Les principes du CLOUD Act s’inscrivent dans le cadre du droit international et des législations nationales
Le CLOUD Act n’a pas introduit de nouveau concept juridique concernant l’accès aux données électroniques dans le cadre d’enquêtes pénales. De nombreux États exigent la divulgation de données clients quel que soit leur lieu de stockage en réponse à des procédures judiciaires impliquant des crimes graves. La loi britannique Crime (Overseas Production Orders) Act, par exemple, permet aux autorités judiciaires britanniques d’obtenir des données électroniques stockées hors du Royaume-Uni dans le cadre d’une enquête pénale. Selon un document du DOJ américain publié en 2024, plusieurs États membres de l’Union européenne, dont la Belgique, le Danemark, la France, l’Irlande et l’Espagne, disposent d’exigences similaires. En réalité, depuis 2023, la majorité des demandes d’accès aux données reçues par AWS émanent d’autorités situées en dehors des États-Unis.
Ce principe est également inscrit dans la Convention de Budapest sur la cybercriminalité, premier traité international visant à renforcer la coopération en matière d’enquêtes sur la cybercriminalité. Par ailleurs, le Règlement européen e-Evidence (2023/1543), adopté en août 2023, habilite les États membres à “ordonner à un fournisseur de services de produire ou de conserver des preuves électroniques, quelle que soit la localisation des données.” Le RGPD prévoit également la possibilité de transferts de données personnelles en réponse aux demandes contraignantes de pays tiers, sous réserve d’une base juridique appropriée et d’un mécanisme de transfert ou d’une dérogation (voir les Lignes directrices 02/2024 du Comité européen de la protection des données sur l’Article 48).
AWS soutient la conclusion d’accords de coopération bilatéraux dans le cadre du CLOUD Act, notamment entre les États-Unis et l’Union européenne, ainsi qu’entre les États-Unis et le Canada. Ces accords sont essentiels pour résoudre les conflits potentiels de lois et permettre des enquêtes efficaces sur les crimes graves afin d’améliorer la sécurité publique, tout en s’appuyant sur les garanties procédurales et juridiques substantielles déjà prévues par la législation américaine.
Fait n°5 : Le CLOUD Act n’a pas d’impact sur les dispositifs techniques et les mesures de contrôle qu’AWS met à disposition de ses clients pour prévenir tout accès non autorisé à leurs données
AWS ne peut répondre aux demandes judiciaires de communication de données que lorsqu’elle dispose de la capacité technique de le faire. Or, AWS a développé de nombreux produits et services garantissant qu’aucun tiers – y compris ses propres employés – ne peut accéder aux données des clients. Les clients d’AWS ont également à leur disposition un ensemble de dispositifs techniques et de mesures de contrôle complémentaires pour protéger leurs données. À titre d’exemple, la plupart des principaux systèmes et services d’AWS sont conçus sans aucune possibilité d’accès technique, selon le principe d’absence d’accès pour les opérateurs (zero operator access). Cela signifie que les services ne disposent d’aucun moyen technique permettant aux opérateurs d’AWS d’accéder aux données des clients en réponse à une demande judiciaire.
Le système AWS Nitro, qui est à la base des services informatiques AWS, utilise des composants matériels et logiciels spécifiques pour protéger les données de tout accès externe lors de leur traitement sur Amazon Elastic Compute Cloud (Amazon EC2). En établissant une barrière physique et logique renforcée, le système Nitro est conçu de sorte qu’aucune personne non autorisée – y compris les opérateurs d’AWS – ne peut accéder aux charges de travail des clients sur EC2. L’architecture du système Nitro a été certifiée par NCC Group, organisme indépendant en cybersécurité. Ces dispositifs de contrôle empêchant tout accès de nos opérateurs sont si essentiels au système Nitro que nous les avons intégrés dans nos Conditions de Service AWS, offrant ainsi une garantie contractuelle supplémentaire à l’ensemble de nos clients.
Nous proposons également à nos clients des fonctionnalités et des mécanismes de chiffrement des données, qu’elles soient en transit, au repos ou en mémoire. L’ensemble des services AWS intègrent le chiffrement, la majorité permettant également le chiffrement via des clés gérées par le client et inaccessibles à AWS. AWS Key Management Service (AWS KMS) est le premier système de gestion de clés natif au cloud, hautement évolutif, à obtenir la certification FIPS 140-3 Niveau 3. Concrètement, AWS propose un chiffrement de niveau supérieur où les clients conservent le contrôle exclusif de l’accès aux clés.
Poursuivre notre obsession client
Chez AWS, notre approche centrée sur le client guide l’ensemble de nos actions, de la conception de nos services à la protection de vos données. La confiance que vous nous accordez repose sur notre transparence, la robustesse de nos dispositifs techniques de contrôle et notre détermination à défendre vos intérêts.
C’est dans cet esprit que nous avons établi une communication claire et transparente sur notre traitement des demandes d’accès aux données émanant des autorités, notamment concernant l’application du CLOUD Act, ainsi que sur les différents niveaux de protection – juridiques, opérationnels et techniques – mis en œuvre pour sécuriser vos données.
Nous vous invitons à approfondir vos connaissances de ce sujet en consultant notre FAQ détaillée sur le CLOUD Act.
Nous poursuivrons nos efforts d’innovation, à votre service, en développant de nouvelles fonctionnalités et de nouveaux services vous garantissant la maîtrise de vos données, tout en maintenant nos engagements en matière de confidentialité et de sécurité.
A propos de l’auteur
Bob Kimball occupe le poste de Chief Regulatory Officer après avoir été General Counsel d’AWS. Dans ses fonctions actuelles, il pilote les questions réglementaires mondiales d’AWS, travaillant en étroite collaboration avec les régulateurs et les clients sur des enjeux tels que l’IA, la souveraineté numérique, l’énergie et d’autres sujets clés liés à l’exploitation des infrastructures et services cloud.
German version
Fünf Fakten zur tatsächlichen Funktionsweise des CLOUD Act
Bei Amazon Web Services (AWS) haben Kundendatenschutz und -sicherheit höchste Priorität. Wir bieten unseren Kunden branchenführenden Datenschutz und erstklassige Sicherheit bei der Nutzung der AWS Cloud – weltweit. In den vergangenen Monaten haben wir ein gestiegenes Interesse zum Umgang mit behördlichen Datenanfragen festgestellt. Viele dieser Fragen beziehen sich auf ein US-amerikanisches Gesetz aus dem Jahr 2018, den Clarifying Lawful Overseas Use of Data Act (CLOUD Act). Tatsächlich hat der CLOUD Act der US-Regierung keinerlei neue Befugnisse eingeräumt, Daten von Anbietern anzufordern, sondern schafft vielmehr wichtige rechtliche Leitplanken zum Schutz von Inhalten.
Um diese Thematik in den richtigen Kontext zu setzen: Seit wir 2020 mit der statistischen Erfassung begonnen haben, gab es keine Datenanfragen an AWS, die zur Offenlegung von außerhalb der USA gespeicherten Kundeninhalten von Unternehmens- oder Regierungsdaten gegenüber der US-Regierung geführt haben. Unser Engagement zum Schutz von Kundendaten wird durch mehrere Ebenen rechtlichen, technischen und operativen Schutzes untermauert. AWS hat beispielsweise seine Kernprodukte und -services so konzipiert, dass nur Kunden selbst und die von ihnen autorisierten Personen auf die Kundeninhalte zugreifen können. In diesen Fällen müsste jede Regierung, die Zugriff auf Kundeninhalte wünscht, diese Daten direkt beim Kunden anfragen. Darüber hinaus bietet das US-Recht selbst zahlreiche gesetzliche Schutzmaßnahmen, die das Risiko verringern, dass AWS zur Offenlegung von Unternehmens- oder Regierungsdaten verpflichtet werden könnte. Das US-Justizministerium (DOJ) hat in den letzten acht Jahren zusätzliche operative Schutzmaßnahmen implementiert.
Vor diesem Hintergrund möchten wir einige häufige Missverständnisse über den CLOUD Act ansprechen und Klarheit darüber schaffen, wie sich dieses Gesetz auf AWS Kunden weltweit auswirkt – oder eben nicht auswirkt. Außerdem erweitern wir unsere FAQ zum CLOUD Act, um unseren Kunden und Partnern den Umgang mit diesem Thema zu erleichtern.
Fakt 1: Der CLOUD Act gewährt der US-Regierung keinen uneingeschränkten oder automatischen Zugriff auf in der Cloud gespeicherte Daten
Der CLOUD Act wurde verabschiedet, um Herausforderungen zu bewältigen, denen Strafverfolgungsbehörden bei der Beschaffung von im Ausland gespeicherten Daten in grenzüberschreitenden Ermittlungen zu schweren Straftaten begegneten. Dazu gehören Terrorismus und Gewaltverbrechen bis hin zu sexueller Ausbeutung von Kindern und Cyberkriminalität. Der CLOUD Act ermöglicht es den USA in erster Linie, gegenseitige Vollzugsvereinbarungen mit vertrauenswürdigen ausländischen Partnern zu schließen, um Zugang zu elektronischen Beweismitteln für Ermittlungen bei schweren Straftaten zu erhalten, unabhängig vom Speicherort der Beweise, indem Sperrgesetze nach US-Recht aufgehoben wurden. Viele Regierungen stützen sich auf nationale Gesetze, um von Anbietern innerhalb ihres Zuständigkeitsbereichs die Offenlegung elektronischer Daten unter der Kontrolle der Unternehmen zu verlangen, unabhängig davon, wo die Daten gespeichert sind. In ähnlicher Weise stellte der CLOUD Act klar, dass US-Strafverfolgungsbehörden bestehende Befugnisse wie einen gerichtlich genehmigten Durchsuchungsbeschluss nutzen können, um Daten unter der Kontrolle eines Anbieters anzufordern, unabhängig vom Speicherort der Daten; die Vollzugsvereinbarungen ermöglichen die Wirksamkeit dieser gegenseitigen Gesetze, unterstützt durch strenge verfahrensrechtliche und materielle Schutzmaßnahmen.
Der Zugriff auf Daten nach US-Recht ist bei weitem nicht uneingeschränkt oder automatisch möglich, und Strafverfolgungsbehörden müssen strenge rechtliche Standards erfüllen. Nach US-Recht ist es Anbietern sogar untersagt, Daten ohne rechtliche Ausnahmeregelung an die US-Regierung weiterzugeben. Um einen Anbieter zur Offenlegung von Inhaltsdaten zu verpflichten, muss die Strafverfolgungsbehörde einen unabhängigen Bundesrichter davon überzeugen, dass ein hinreichender Verdacht bezüglich einer bestimmten Straftat besteht und dass Beweise für diese Straftat am zu durchsuchenden Ort gefunden werden (das heißt in einem bestimmten elektronischen Konto wie einem E-Mail-Account). Dieser Rechtsstandard muss durch konkrete und vertrauenswürdige Fakten belegt werden. Jeder Durchsuchungsbeschluss muss diese strenge Prüfung des hinreichenden Verdachts anhand glaubwürdiger Fakten, Spezifität und Rechtmäßigkeit bestehen, muss von einem unabhängigen Richter genehmigt werden und muss die Anforderungen hinsichtlich Umfang und Zuständigkeit erfüllen. Im Mai 2023 hat das DOJ außerdem eine Richtlinie erlassen, wonach Staatsanwälte, die nachweislich im Ausland gespeicherte Beweismittel anfordern, vor Erhalt einer entsprechenden Anordnung die Genehmigung des Office of International Affairs (OIA) des Ministeriums einholen müssen. Die DOJ-Richtlinie zu Beweismitteln im Ausland weist darauf hin, dass jede Nation Gesetze zum Schutz ihrer Souveränität erlässt; das OIA arbeitet daran, diesbezügliche Fragen zu klären und Staatsanwälte bei der Auswahl eines geeigneten Mechanismus zur Sicherung von Beweismitteln zu unterstützen.
Fakt 2: AWS hat seit Beginn der statistischen Erfassung keine Kundeninhalte von Unternehmens- oder Regierungskundendaten aufgrund des CLOUD Act offengelegt
AWS verfügt über strenge Verfahren zur Bearbeitung von Anfragen von Strafverfolgungsbehörden aus allen Ländern, um deren Legitimität zu prüfen und sicherzustellen, dass sie geltendem Recht entsprechen. AWS erkennt die legitimen Bedürfnisse von Strafverfolgungsbehörden bei der Untersuchung krimineller und terroristischer Aktivitäten an, aber diese müssen die rechtlichen Schutzmaßnahmen für solche Ermittlungen beachten. Wir geben Kundendaten auf keinerlei behördliche Anfragen heraus, es sei denn, wir sind dazu durch eine rechtlich gültige und verbindliche Anordnung verpflichtet. Dies haben wir in unseren rechtlichen Bedingungen öffentlich zugesichert. Darüber hinaus werden wir behördliche Anfragen anfechten, die gegen das Gesetz verstoßen, zu weitreichend oder anderweitig unangemessen sind (beispielsweise, wenn eine solche Anfrage die Grundrechte von Personen verletzen würde). Wenn wir solche Anfragen nach Inhalten von Unternehmenskunden erhalten, unternehmen wir alle angemessenen Anstrengungen, um Strafverfolgungsbehörden an den Kunden zu verweisen und den Kunden zu benachrichtigen, wenn dies rechtlich zulässig ist. Wenn wir zur Offenlegung von Kundeninhalten verpflichtet sind, benachrichtigen wir die Kunden vor der Offenlegung, um ihnen die Möglichkeit zu geben, sich gegen die Offenlegung zu schützen, sofern dies nicht gesetzlich untersagt ist. Wenn AWS nach Ausschöpfung dieser Schritte weiterhin zur Offenlegung von Kundendaten verpflichtet ist und wir die technische Möglichkeit dazu haben (was, wie oben beschrieben, in vielen Fällen nicht der Fall ist), legen wir nur das zur Erfüllung des rechtlichen Verfahrens unbedingt Notwendige offen.
In Übereinstimmung mit unserer Richtlinie, Strafverfolgungsbehörden an die Kunden zu verweisen, hat auch die Computer Crime and Intellectual Property Section des DOJ Leitlinien herausgegeben, die Staatsanwälte anweisen, Daten grundsätzlich direkt von einem Unternehmen anzufordern, wie beispielsweise von einem Unternehmen, das Daten bei einem Cloud-Anbieter speichert, und nicht vom Anbieter selbst.
Ein deutlicher Beleg für die Wirksamkeit unserer Maßnahmen und der strengen gesetzlichen Anforderungen ist die Tatsache, dass AWS seit Beginn der statistischen Erfassung im Jahr 2020 keine außerhalb der USA gespeicherten Kundeninhalte von Unternehmens- oder Regierungskundendaten an die US-Regierung weitergegeben hat. Diese Bilanz spiegelt die technischen Schutzmaßnahmen von AWS, die robusten rechtlichen Schutzmaßnahmen im US-Recht, die vom DOJ umgesetzten Richtlinien und die Art der strafrechtlichen Ermittlungen wider, die sich hauptsächlich auf die Sammlung elektronischer Beweise aus Verbraucherkonten konzentrieren.
Fakt 3: Der CLOUD Act gilt nicht nur für Unternehmen mit Hauptsitz in den USA – er gilt für alle Anbieter, die Geschäfte in den Vereinigten Staaten tätigen
Der CLOUD Act gilt für alle Anbieter von elektronischen Kommunikationsdiensten oder Remote-Computing-Diensten, die in den USA tätig sind oder dort eine rechtliche Präsenz haben – unabhängig vom Standort ihres Hauptsitzes. Beispielsweise unterliegen auch Cloud-Anbieter mit Hauptsitz in Europa, die Geschäfte in den USA tätigen, den Anforderungen des Gesetzes. OVHcloud, ein Cloud-Service-Anbieter mit Hauptsitz in Frankreich, der in den USA tätig ist, vermerkt auf seiner CLOUD Act FAQ-Seite, dass “OVHcloud rechtmäßigen Anfragen von Behörden nachkommen wird. Im Rahmen des CLOUD Act könnte dies auch Daten einschließen, die außerhalb der Vereinigten Staaten gespeichert sind.” Ähnlich verhält es sich mit anderen Cloud-Anbietern mit Hauptsitz in der EU und anderswo, die ebenfalls in den USA tätig sind.
Fakt 4: Die Grundsätze des CLOUD Act stehen im Einklang mit internationalem Recht und den Gesetzen anderer Länder
Der CLOUD Act hat keine neue Rechtsposition bezüglich des Umfangs elektronischer Daten eingeführt, die im Rahmen legitimer strafrechtlicher Ermittlungen offengelegt werden müssen. Viele Länder verlangen die Offenlegung von Kundendaten, unabhängig vom Speicherort, als Reaktion auf rechtliche Verfahren im Zusammenhang mit schweren Straftaten. Der britische Crime (Overseas Production Orders) Act beispielsweise ermöglicht es britischen Strafverfolgungsbehörden, im Zusammenhang mit strafrechtlichen Ermittlungen auf außerhalb des Vereinigten Königreichs gespeicherte elektronische Daten zuzugreifen. Laut einer Einreichung des US-DOJ von 2024 haben mehrere EU-Mitgliedstaaten, darunter Belgien, Dänemark, Frankreich, Irland und Spanien, ähnliche Anforderungen. Tatsächlich kommt seit 2023 die Mehrheit der Strafverfolgungsanfragen, die AWS erhält, von Behörden außerhalb der Vereinigten Staaten.
Dieses Konzept ist auch in der Budapest-Konvention zur Cyberkriminalität verankert, dem ersten internationalen Vertrag zur Verbesserung der Zusammenarbeit bei der Untersuchung von Cyberkriminalität. Darüber hinaus ermächtigt die EU-Verordnung e-Evidence, 2023/1543, die im August 2023 verabschiedet wurde, die Mitgliedstaaten dazu, “einen Dienstanbieter anzuweisen, elektronische Beweismittel unabhängig vom Standort der Daten zu erstellen oder zu sichern”. Die DSGVO erlaubt ebenfalls die Übermittlung personenbezogener Daten als Reaktion auf verpflichtende Offenlegungsanfragen aus Drittländern – vorausgesetzt, die betreffende Partei kann sich auf eine geeignete Rechtsgrundlage und ein Übertragungsinstrument oder eine Ausnahmeregelung berufen (siehe die aktuellen EDSA Leitlinien 02/2024 zu Artikel 48).
AWS setzt sich dafür ein, dass Regierungen gegenseitige Vollzugsvereinbarungen im Rahmen des CLOUD Act abschließen, einschließlich zwischen den USA und der Europäischen Union sowie den USA und Kanada. Wir glauben, dass diese Vereinbarungen wichtig sind, um potenzielle Gesetzeskonflikte endgültig zu lösen und eine effektive Untersuchung schwerer Straftaten zur Förderung der öffentlichen Sicherheit zu ermöglichen. Dabei werden die bereits bestehenden starken materiell- und verfahrensrechtlichen Schutzmaßnahmen nach US-Recht anerkannt.
Fakt 5: Der CLOUD Act beschränkt nicht die technischen Maßnahmen und operativen Kontrollen, die AWS seinen Kunden zum Schutz vor unbefugtem Zugriff auf Kundendaten anbietet
Wir können auf rechtliche Datenanfragen nur dann reagieren, wenn wir die technische Möglichkeit dazu haben. AWS verfügt über eine Reihe von Produkten und Services, die sicherstellen, dass niemand – nicht einmal Mitarbeiter:innen von AWS – auf Kundeninhalte zugreifen können. AWS Kunden verfügen auch über eine Reihe zusätzlicher technischer Maßnahmen und operativer Kontrollen, um den Zugriff auf Daten zu verhindern. Beispielsweise sind viele der AWS Kernsysteme und Services mit Zero-Operator-Zugriff konzipiert, was bedeutet, dass die Services keine technischen Möglichkeiten für AWS Mitarbeiter:innen bieten, auf Kundendaten als Reaktion auf eine rechtliche Anfrage zuzugreifen.
Das AWS Nitro System, das die Grundlage der AWS Rechendienstleistungen bildet, verwendet spezialisierte Hardware und Software, um Daten während der Verarbeitung auf Amazon Elastic Compute Cloud (Amazon EC2) vor externem Zugriff zu schützen. Durch eine starke physische und logische Sicherheitsgrenze ist Nitro so konzipiert, dass keine unbefugte Person – nicht einmal AWS Mitarbeiter:innen – auf Workloads von Kunden auf EC2 zugreifen kann. Das Design des Nitro Systems wurde von der NCC Group, einem unabhängigen Cybersicherheitsunternehmen, validiert. Die Kontrollen, die den Betreiberzugriff verhindern, sind für das Nitro System so grundlegend, dass wir sie in unsere AWS Servicebedingungen aufgenommen haben, um allen unseren Kunden eine zusätzliche vertragliche Zusicherung zu geben.
Wir bieten Kunden auch Funktionen und Kontrollen zur Verschlüsselung von Daten, sei es während der Übertragung, im Ruhezustand oder im Arbeitsspeicher. Alle AWS Services unterstützen bereits Verschlüsselung, wobei die meisten auch die Verschlüsselung mit kundenverwalteten Schlüsseln unterstützen, die für AWS nicht zugänglich sind. Der AWS Key Management Service (AWS KMS) ist das erste hochskalierbare, Cloud-native Schlüsselverwaltungssystem mit FIPS 140-3 Level 3-Zertifizierung. Vereinfacht ausgedrückt bedeutet dies, dass AWS eine äußerst starke Verschlüsselung anbietet, bei der unsere Kunden kontrollieren, wer einen Schlüssel erhält.
Fortsetzung unserer Kundenorientierung
Bei AWS bestimmt unser kundenorientierter Ansatz alles, was wir tun – von der Gestaltung unserer Services bis zum Schutz Ihrer Daten. Wir verstehen, dass Ihr Vertrauen durch Transparenz, starke technische Kontrollen und unermüdlichen Einsatz für Ihre Interessen verdient wird. Deshalb haben wir klar kommuniziert, wie wir mit behördlichen Datenanfragen umgehen, einschließlich der Auswirkungen des CLOUD Act, und der mehrschichtigen Schutzmaßnahmen – rechtlich, operativ und technisch – zum Schutz Ihrer Daten.
Wir ermutigen Sie, mehr über dieses wichtige Thema zu in unseren erweiterten CLOUD Act FAQs zu lesen. Wir werden weiterhin in Ihrem Interesse innovativ sein, neue Funktionen und Services entwickeln, die Ihnen die Kontrolle über Ihre Daten geben, und unser Engagement für höchste Datenschutz- und Sicherheitsstandards aufrechterhalten.
Über den Autor
Bob Kimball ist Chief Regulatory Officer und ehemaliger General Counsel bei AWS. In seiner aktuellen Position ist Bob ein AWS-Experte für globale regulatorische Fragen und arbeitet eng mit Aufsichtsbehörden und Kunden zu Themen wie KI, digitale Souveränität, Energie und anderen Schlüsselthemen zusammen, die den Betrieb von Cloud-Infrastruktur und -Services betreffen.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Last month, we announced new sovereign controls and governance structure for the AWS European Sovereign Cloud. The AWS European Sovereign Cloud is a new, independent cloud for Europe, designed to help customers meet their evolving sovereignty needs, including stringent data residency, operational autonomy, and resiliency requirements. Launching by the end of 2025, the AWS European Sovereign Cloud will be entirely located within the European Union (EU) and operate as an independent cloud for Europe. Last month, we announced plans to launch a dedicated European certificate authority (CA), or trust service provider, to support autonomous trust service operations within the AWS European Sovereign Cloud.
We are actively building out the first AWS Region of the AWS European Sovereign Cloud in the state of Brandenburg, Germany. We are on track for launch and AWS services are being deployed, configured, and tested for autonomous operations in the AWS European Sovereign Cloud. The AWS European Sovereign Cloud infrastructure will be physically and logically separate from other Regions. We designed the AWS European Sovereign Cloud to have no critical dependencies on non-EU infrastructure. Everything needed to operate the AWS European Sovereign Cloud is in the EU: the talent, the technology, the infrastructure, and the leadership. In addition to independent infrastructure, there will be zero operational control outside of EU borders. Only AWS employees, residing in the EU, will control day-to-day operations, including access to data centers, technical support, and customer service for the AWS European Sovereign Cloud.
For the first time, we will provide a dedicated sovereign European trust service provider (EU-TSP). This EU-TSP will autonomously operate its own CA key materials and perform certificate issuance functions within the AWS European Sovereign Cloud. A trust service provider is an entity that manages the policies and operations for a set of root and subordinate certificate authorities. A root CA is a cryptographic building block and root of trust upon which end entity certificates can be issued. It represents a private key for signing (issuing) certificates and a root certificate that identifies the root CA and binds the private key to the name of the CA. In short, the EU-TSP is an autonomous trust service provider in Europe, for Europe.
The EU-TSP will be the public root of trust for the AWS European Sovereign Cloud, helping to maintain the confidentiality and integrity of network communications. The EU-TSP will provide the default CA used by AWS service endpoints, AWS Certificate Manager (ACM), and ACM integrated services. For AWS European Sovereign Cloud customers, this means that even in the event of a material loss of connectivity outside of the EU, the EU-TSP will continue to provide trust services autonomously.
We recently completed the cryptographic key signing ceremony for our EU-TSP at a secure EU location, witnessed by external, third-party auditors. The resulting root CAs have been submitted for inclusion to popular web browsers used by AWS customers. This EU-TSP will be operated in accordance with the requirements of the Certificate Authority/Browser Forum. All the key material for the EU-TSP is located within EU borders, and only EU residents have the ability to operate, control, or reconfigure the EU-TSP.
To maintain verifiable trust, we will engage independent EU-based auditors to assure the EU-TSP controls are designed appropriately, operate effectively, and can help customers satisfy their compliance obligations. We will make the audit reports publicly available.
The EU-TSP will be active and providing autonomous trust services when the AWS European Sovereign Cloud launches at the end of 2025. To learn more, visit AWS European Sovereign Cloud.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Stifel Financial Corp. is an American multinational independent investment bank and financial services company, founded in 1890 and headquartered in downtown St. Louis, Missouri. Stifel offers securities-related financial services in the United States and Europe through several wholly owned subsidiaries. Stifel provides both equity and fixed income research and is the largest provider of US equity research.
In this post, we show you how Stifel implemented a modern data platform using AWS services and open data standards, building an event-driven architecture for domain data products while centralizing the metadata to facilitate discovery and sharing of data products.
Stifel’s modern data platform use case
Stifel envisioned a data platform that delivers accurate, timely, and properly governed data, providing consistency throughout the organization whenever users access the information. This approach showed limitations as the data complexity increased, data volumes grew, and demand for quick, business-driven insights rose. These challenges are encountered by financial institutions worldwide, leading to a reassessment of traditional data management practices. Under the federated governance model, Stifel developed a modern data strategy based on the following objectives:
Managing ingestion and metadata
Creating source-aligned data products complying with Stifel business streams
Integrating source-aligned data products from other domains (Stifel business units)
Producing consumer-aligned data products for specific business purposes
Publishing data products to a centralized data catalog
Some of the Stifel challenges highlighted in the preceding list required building a data platform that can:
Boost agility by democratizing data, thus reducing time to market and enhancing the customer experience
Improve data quality and trust in the data
Standardize tools and eliminate the shadow information technology (IT) culture to increase scalability, reduce risk, and minimize operational inefficiencies
Following the federated governance model, Stifel has organized its domain structure to provide autonomy to various functional teams while preserving the core values of data mesh. The following diagram depicts a high-level architecture of the data mesh implementation at Stifel.
Each data domain has the flexibility to create data products that can be published to the centralized catalog, while maintaining the autonomy for teams to develop data products that are exclusively accessible to teams within the domain. These products aren’t available to others until they are deemed ready for broader enterprise use. Domains have the freedom to decide which data they want to share. They can either:
Make their data products visible to everyone through the central catalog
Keep their data products visible only within their own domain
By implementing an event-driven domain architecture, organizations can achieve significant business advantages while positioning themselves for future growth and innovation. Stifel data products refreshes were dependent on data assets with variable cadence. Event-driven architecture enables real-time or near real-time updates by allowing data products to automatically respond to changes in underlying data assets as they occur, rather than relying on fixed batch schedules that might miss critical updates or waste resources on unnecessary refreshes. The key is to carefully plan the implementation and make sure of alignment with business objectives while considering both technical and organizational factors. This architecture style particularly suits organizations that:
Need real-time processing capabilities
Have complex domain interactions
Require high scalability
Want to improve business agility
Need better system integration
Are pursuing digital transformation
The following are some of the key AWS Services that helped Stifel to build their modern data platform.
AWS Glue is a serverless data integration service that’s used for data processing to build data assets and data products in the domains. Data is also cataloged in AWS Glue Catalog, making it straightforward to discover and query with supported engines.
Amazon EventBridge provides a scalable and flexible serverless event bus that facilitates seamless communication between different domains and services. By using EventBridge, Stifel was able to implement a publish-subscribe model where domain events can be emitted, filtered, and routed to appropriate consumers based on configurable rules. EventBridge supports custom event buses for domain-specific events, enabling clear separation of concerns and improved manageability.
AWS Lake Formation helped in providing centralized security, governance, and catalog capabilities while preserving domain autonomy in data product creation and management. With Lake Formation, data domains were able to maintain their independent data products within a federated structure while enforcing consistent access controls, data quality standards, and metadata management across the organization.
The following diagram illustrates the data mesh architecture that Stifel uses to build a domain-driven architecture. In this system, various domains create data products and share them with other domains through a central governance account that uses Lake Formation.
Let’s look at some of the key design components that are being used to enable and implement data mesh and event driven design
Data ingestion framework
The data ingestion framework consists of several processor modules that are built using several AWS services and metadata driven architecture. The following diagram shows the architecture of the raw data ingestion framework.
The framework gets raw data files from both internal Stifel systems and third-party data sources. These files are processed and stored in a raw data ingestion account on Amazon S3 in open table format Apache Hudi. This stored data is then shared with different parts of the organization, called data domains. Each domain can use this shared data to create their own data products.
As a file (in CSV, XML, JSON and custom formats) lands into the landing bucket, an Amazon S3 event notification is created and placed in an Amazon Simple Queue Service (Amazon SQS)queue. The Amazon SQS queue triggers an AWS Lambda function and saves the metadata (such as the name of the file, date and time the file was received, and the file size) to a file audit data store (Amazon Aurora PostgreSQL-Compatible Edition).
An EventBridge time scheduler invokes an AWS Step Functions workflow at pre-determined intervals. The Step Functions workflow orchestrates the batch ingestion from raw to staging layer.
The Step Functions workflow orchestrates a set of Lambda functions to get the list of unprocessed raw files from the audit data store and create batches of raw files to process them in parallel. The Step Functions workflow then triggers parallel AWS Glue jobs that process each batch of raw files.
Each raw file is validated for any data quality checks and the data is saved to staging tables in Hudi format. Any errors encountered are logged into an audit table and a notification is generated for support team. For all successfully processed raw files, the file status is updated to PROCESSED and logged into an audit table.
After the Hudi table is updated, a data refresh event is sent to EventBridge and then passed to the Central Mesh Account. The Central Mesh Account forwards these events to the data domains to notify them that the raw tables are refreshed, allowing the data domains to use this data for creating their own data products.
Event driven data product refresh
The Stifel data lake is based on a data mesh architecture where several data producers share data across data domains. A mechanism is needed to alert consumers who depend on other data producers’ data products when those source data products are refreshed, so that the consumers can update their own data products accordingly. The following diagram describes the technical architecture of event-based data processing. The central governance account acts as the central event bus, which receives all data refresh events from all data producers. The central event bus forwards the events to consumer accounts. The consumer accounts filter the events consumers are interested in from data producers for their data processing needs.
Orchestration design
Stifel designed and implemented an event-based data pipeline orchestration system that triggers data pipelines when specific events occur. This system processes data immediately after receiving all required dependency events, enabling efficient workflow management.
The following diagram describes the logical architecture of the domain data pipeline orchestration framework.
The orchestration framework includes the components described in the following list. The data dependencies and data pipeline state management metadata are hosted in an Aurora PostgreSQL database.
Data refresh processor: Receives data refresh events from central mesh and local data domain and evaluates if the domain data products data dependencies are met
Data product dependency processor: Retrieves metadata for the product, kicks off a corresponding data domain AWS Glue job, and updates metadata with the job information
Data pipeline state change processor: Monitors the domain data jobs and takes actions based on the job’s final status (SUCCEED or FAILED) and then creates incident tickets for failed jobs
Conclusion
Stifel has improved its data management and reduced data silos by adopting a data product approach. This strategy has positioned Stifel to become a data-driven, customer-centric organization. The company combines federated platform practices with AWS and open standards. As a result, Stifel is achieving its decentralization objectives through a scalable data platform. This platform empowers domain teams to make informed decisions, drive innovation, and maintain a competitive edge. Here are the some of the advantages Stifel got from an event-driven domain architecture (EDDA):
Business agility: Rapid market response, new business capability integration, scalable domains, quicker feature deployment, and flexible process modification
Customer experience: Real-time processing, responsive interactions, personalized services, consistent omnichannel presence, and enhanced service availability
Operational efficiency: Reduced system coupling, optimal resource use, scalable systems, lower maintenance overhead, and efficient data processing
Cost benefits: Lower development costs, reduced infrastructure expenses, decreased maintenance costs, efficient resource usage, and a better ROI on technology investments
In this post, we demonstrated how Stifel is building a modern data platform by recognizing the critical importance of data in today’s financial landscape. This strategic approach not only enhances operational efficiency but also positions Stifel at the forefront of technological innovation in the financial services industry. To learn more and get started, see the following resources:
Amit Maindola is a Senior Data Architect focused on data engineering, analytics, and AI/ML at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.
Srinivas Kandi is a Senior Architect at Stifel focusing on delivering the next generation of cloud data platform on AWS. Prior to joining Stifel, Srini was a delivery specialist in cloud data analytics at AWS helping several customers in their transformational journey into AWS cloud. In his free time, Srini likes to explore cooking, travel and learn new trends and innovations in AI and cloud computing.
Hossein Johari is a seasoned data and analytics leader with over 25 years of experience architecting enterprise-scale platforms. As Lead and Senior Architect at Stifel Financial Corp. in St. Louis, Missouri, he spearheads initiatives in Data Platforms and Strategic Solutions, driving the design and implementation of innovative frameworks that support enterprise-wide analytics, strategic decision-making, and digital transformation. Known for aligning technical vision with business objectives, he works closely with cross-functional teams to deliver scalable, forward-looking solutions that advance organizational agility and performance.
Ahmad Rawashdeh is a Senior Architect at Stifel Financial. He supports Stifel and its clients in designing, implementing, and building scalable and reliable data architectures on Amazon Web Services (AWS), with a strong focus on data lake strategies, database services, and efficient data ingestion and transformation pipelines.
Lei Meng is a data architect at Stifel. His focus is working in designing and implementing scalable and secure data solutions on the AWS and helping Stifel’s cloud migration from on-premises systems.
Amazon Web Services (AWS) has been recognized as a Leader in The Forrester Wave: Serverless Development Platforms, Q2 2025, achieving the highest ranking in both the Current Offering and Strategy categories.
The Forrester Wave evaluation provides business leaders with rigorous, fact-based analysis for technology purchasing decisions. Through transparent criteria spanning current offering, strategy, and customer feedback, Forrester evaluates vendors to identify Leaders, Strong Performers, and Contenders. The AWS serverless portfolio unifies traditional and AI-driven development, enabling teams to build intelligent, adaptive systems with minimal infrastructure and code overhead. The evaluation analyzed across key services, including AWS Lambda for serverless compute, AWS Step Functions and Amazon EventBridge for application integration, and AWS Fargate with Amazon Elastic Container Service (Amazon ECS) for serverless containers.
Serverless beyond function-as-a-service
The serverless operating model has evolved beyond function-as-a-service approaches. It has become a comprehensive cloud-based software development model that abstracts away underlying cloud infrastructure, complex server configurations, runtime characteristics, and deployment patterns from the development process. Forrester defines key characteristics of serverless development platforms as supporting the deployment of arbitrary business logic, decoupled state from the underlying compute, autonomous scale by demand (often back to zero), flexible consumption-based billing, abstraction of the underlying cloud infrastructure, and event-driven communication.
According to the Forrester report, “AWS provides a mature foundation for event-driven application development with extensive integrations across the AWS ecosystem. AWS continues to evolve its serverless portfolio for market demands including the growing influence of AI workloads. AWS’s platform completeness and integration depth are notable, making it well-suited for organizations seeking to build production-grade event-driven applications at scale with granularity and control.”
AWS capabilities recognized in the report
AWS’s recognition as a Leader in this report underscores, for us, our commitment to providing best-in-class innovation and developer experiences in serverless application development. Findings from AWS’s vendor profile in the report include:
Strategy – AWS has a clear and cohesive vision that aligns serverless capabilities across its expansive cloud portfolio. Its innovation strategy is tightly coupled with customer feedback and reinforced through sustained R&D investment.
Capabilities – AWS offers strong capabilities across developer experiences, tools, and service integrations. Developers benefit from mature software development kits (SDKs), command line interface (CLI) tools, and infrastructure as code (IaC) options. Its APIs and event-driven integrations are among the best, enabling complex, scalable architectures and workflows.
Evolving serverless developer experience on AWS
AWS has made significant investments to streamline the developer onboarding experience through comprehensive resources and tools. As generative AI infuses every step of software development and transforms the technology landscape, organizations must adapt quickly to maintain their competitive edge. Many are building distributed architectures that use specific large language models (LLMs) based on unique requirements, and the serverless operating model is ideal for these AI-powered applications. Serverless enables organizations to start small and scale seamlessly while handling distributed, event-driven workflows securely at scale.
The newly launched AWS Serverless Model Context Protocol (MCP) server provides AI-powered, contextual guidance throughout the serverless development lifecycle, so developers can receive real-time assistance with service selection, best practices, and implementation patterns while building applications with Lambda. The developer-first approach also includes the Amazon Q Developer plugin for AI-assisted development (including code generation, debugging, and architectural guidance), enhanced AWS SAM CLI capabilities for improved local testing and debugging, the integration with Serverless Land for direct blueprint access on the Lambda console, extensive documentation with practical examples, interactive tutorials, and integration with familiar development environments. AWS has also enhanced the getting started experience through simplified deployment workflows, IaC templates, and automated best practices enforcement. Furthermore, the broad ecosystem of AWS partners, developer advocates, and community contributors provides additional support through workshops, sample applications, and reference architectures. These comprehensive improvements demonstrate our commitment to accelerating serverless adoption by making development more intuitive, efficient, and accessible for teams at any stage of their cloud journey.
Conclusion
AWS has been recognized as a Leader in the Forrester Wave: Serverless Development Platforms, Q2 2025, receiving top scores in Current Offering and Strategy categories, which, in our opinion, underscores our commitment to innovation and excellence in serverless computing. As the serverless landscape continues to evolve, AWS remains at the forefront, providing a comprehensive suite of services that enable developers to build scalable, efficient, and intelligent applications.As we look to the future, AWS will continue to invest in serverless technologies, pushing the boundaries of what’s possible in cloud computing. Whether you’re building AI-powered applications, modernizing legacy systems, or creating entirely new digital experiences, AWS serverless offerings provide the agility, scalability, and innovation you need to stay ahead in a rapidly evolving digital landscape.
Read the full report to learn why Forrester positioned AWS as a Leader in the Forrester Wave: Serverless Development Platforms, Q2 2025.
Forrester does not endorse any company, product, brand, or service included in its research publications and does not advise any person to select the products or services of any company or brand based on the ratings included in such publications. Information is based on the best available resources. Opinions reflect judgment at the time and are subject to change. For more information, read about Forrester’s objectivity here .
When I began my career in security, most people accepted as fact that protecting systems came at the expense of productivity. That didn’t have to be true then, and it’s definitely not true now. The cloud, and specifically the AWS Cloud, is a big reason why. But as technology evolves and systems become more complex, operating at scale demands a fresh approach to security. We take our customers’ security seriously, and that means building guardrails that give organizations the confidence to innovate boldly and scale rapidly.
In my new role as AWS CISO, I see this playing out daily. As I meet with customers, their excitement about technologies like generative AI comes hand in hand with questions about securing complex environments and managing new types of risk. They’re excited about innovation, but they need confidence that their security foundations can keep pace with their ambitions. They want to move fast without compromising security.
Today at re:Inforce, I shared how AWS is working backward from these needs to fundamentally transform how security scales in the cloud. It all starts with a security foundation built on four key pillars: identity and access management, data and network security, monitoring and incident response, and the continuous work of migration, modernization, and patching. Organizations with mature security models across these pillars are the ones moving fastest. Across each of these areas, we’re focused on delivering security capabilities that help customers adopt new technologies and experiment with confidence.
Scaling identity for the cloud
As our customers rapidly scale their cloud operations, they’ve told us that managing identity and access across complex environments becomes increasingly challenging. They need solutions that can grow with their business while maintaining strong security. Identity and access management underpins every aspect of cloud security, and success in this area requires both rigorous authentication controls and comprehensive visibility into access permissions.
I was excited to announce new internal access findings for AWS IAM Access Analyzer today. This capability transforms how organizations manage access to sensitive data at scale, addressing the complexities our customers face as they grow. Using automated reasoning technology, it analyzes complex permission layers across diverse policy types, giving security teams comprehensive visibility into who within their organizations has access to what resources. With daily monitoring and notifications of new access granted, we’re helping teams implement least-privilege access with confidence in even the most complex environments. This provides our customers visibility to strengthen access controls on their critical resources while maintaining the agility their business demands as they scale in the cloud.
Empowering transformation through data and network security
Our customers are eager to transform their businesses, but they need confidence that their security can keep pace with rapid innovation. This is especially true when it comes to protecting their networks and data at scale. During the keynote, Noopur Davis, CISO of Comcast, shared how her organization protects their vast network and customer data while enabling rapid innovation. With millions of customers relying on their services, Comcast’s approach resonated with me: security shouldn’t just defend, it should enable transformation.
We’re delivering on this vision with new capabilities that simplify security at scale. Today, I announced that AWS Certificate Manager now allows you to export ACM-issued public certificates and their private keys for use inside or outside of AWS, giving you automated certificate management with the flexibility to help secure your workloads. We’re also expanding AWS Shield with enhanced network and application protection that performs a network security analysis to identify configuration issues and provides remediation recommendations. You can even use AWS generative AI powered assistant Amazon Q Developer to gain actionable insights using simple natural language. These innovations help teams protect their data and stay ahead of evolving threats even as their environments grow more complex.
Elevating threat detection and response
Our customers have shared their challenges in keeping pace with the evolving threat landscape, especially as they scale their cloud operations. While traditional automation helps manage growing complexity, AI represents an even more powerful opportunity to transform security operations. When implemented thoughtfully, AI dramatically improves our ability to spot complex attack patterns, reduce false positives, and automate responses at massive scale.
Today at re:Inforce, I announced two key security innovations: expanded capabilities in Amazon GuardDuty Extended Threat Detection and enhanced AWS Security Hub that directly address these needs. Together, these services help simplify security at scale. GuardDuty uses AWS-trained AI and machine learning (AI/ML) models to detect sophisticated multi-stage threats and provide actionable insights, while Security Hub prioritizes critical security issues by automatically analyzing and correlating security signals into clear, prioritized actions. This approach gives teams the confidence to scale their operations, knowing they can detect and respond to security risks efficiently across their entire AWS environment.
Accelerating the journey to better security
While advanced capabilities like AI and automation help strengthen security operations, the foundation matters most. Moving to the cloud represents a transformative opportunity to build on a fundamentally stronger security foundation than most organizations can ever hope to achieve with on-premises environments. When migrating to AWS, you reduce the need to manage physical infrastructure security while gaining access to built-in protections that are continuously updated and maintained.
Successful cloud adoption means going beyond simple lift-and-shift. Modernization is key to realizing these benefits. By moving solutions further up the stack to use managed services like AWS Lambda, Amazon Simple Storage Service (Amazon S3), or AWS Key Management Service (AWS KMS), you benefit from security controls that are built in rather than bolted on. These services are continuously patched and maintained by AWS, freeing your teams to focus on innovating for your customers. After all, the fastest path to better security is the one where core protections are already built in.
Partnering for security success
Security transformation isn’t a journey organizations need to take alone. Throughout my career, I’ve seen how the right partnerships can accelerate success, bringing fresh perspectives and deep expertise to complex challenges. Our security partners help customers across the four pillars we discussed today, from implementing identity solutions to modernizing security operations. They understand both the technical complexities and the business realities of scaling security in the cloud, often bringing valuable industry-specific experience that helps organizations move faster with confidence.
Looking ahead
As you scale your operations in the cloud, our goal is to give you the confidence to move quickly while maintaining strong security controls. When security scales naturally with your business, teams can focus on building what’s next instead of managing infrastructure.
To dive deeper into how AWS designs, builds, and operates security at unprecedented scale, I encourage you to join our Innovation Talks at re:Inforce. These hour-long sessions explore the key pillars of modern cloud security: secure foundations, resilient architectures, AI-powered innovations, and large-scale threat intelligence.
As I step into my role as AWS CISO, I’m energized by the opportunity ahead. For nearly 20 years, AWS has maintained a unique culture of security that enables us to innovate rapidly while shipping securely. As we navigate the landscape of generative AI and rapid technological change, earning your trust means not just keeping pace with innovation, but helping to make it even more successful. I couldn’t be more excited to carry this mission forward.
If you have feedback about this post, submit comments in the Comments section below.
At AWS, security is the top priority, and today we’re excited to share work we’ve been doing towards our goal to make AWS the safest place to run any workload. In earlier posts on this blog, we shared details of our internal active defense systems, like MadPot (global honeypots), Mithra (domain graph neural network), and Sonaris (network mitigations). We’re still inventing new ways to improve the effectiveness of threat intelligence and automated response to detect and help prevent attacks. Today we’ll share advancements in active defense related to malware, software vulnerabilities, and AWS resource misconfigurations. Like the other posts we linked to, these are constantly improving capabilities that our customers get just for being on the AWS network. We’ll discuss these topics in more depth at re:inforce 2025 during Innovation Talk SEC302.
Stopping malware from spreading
Financially motivated threat actors try to gain access to a wide array of networked assets. The more resources they control, the more places they can hide, and the longer they can profit from their abusive operations. As such, threat actor malware often contains modules to scan for new targets, replicate binaries over the network, and then repeat. If left unchecked, such rapidly spreading behavior can lead to network congestion, service availability loss, and data destruction. We want to help prevent this behavior to the greatest degree possible.
One effective strategy we employ is identifying the threat actor’s key infrastructure where malware is centrally controlled. We use a variety of techniques to identify, verify, track, and disrupt threat infrastructure. Using network traffic logs, honeypot interactions, and malware samples from an array of sensor positions, we mitigate botnets, abusive proxies, and peer-to-peer malware. Over the past 12 months, AWS helped prevent over 4 million malware infection attempts across 315 thousand distinct Amazon Elastic Compute Cloud (Amazon EC2) instances. By protecting workloads from these malware infections, we not only protect our network and our customers, but also the broader internet from further malware expansion.
Advancements in threat hunting and mitigating software vulnerabilities
At Amazon, we’re proud to support software vulnerability research with programs for bug bounty, vulnerability disclosure, and open source contribution. We’ve also become a more active participant in the CVE process by becoming a CVE Numbering Authority (CNA) for the software and services provided by Amazon. Thanks to the public CVE database, we see vulnerability research accelerating as reported CVEs have grown by 21 percent year-over-year since 2013, with over 40 thousand CVEs published in 2024. This virtuous cycle of finding and resolving vulnerabilities improves cyber security over time, but AWS sees threat actors searching for unresolved vulnerabilities to gain unauthorized access to resources.
We’ve expanded MadPot and Sonaris to identify and stop a broader range of malicious vulnerability scanning and exploitation activity, protecting every AWS customer from vulnerability exposure. We’ve added hundreds of new detections and MadPot service emulations to identify real attacks. As we’ve expanded our visibility, we’ve continued blocking hundreds of millions of CVE exploit attempts daily across the AWS network.
As we’ve made these active defense systems better at stopping CVE exploit attacks, the total number of attacks has gone down by over 55 percent in the last 12 months, as shown in Figure 1. There are many factors outside our control in this observation, but we’re happy to see fewer CVE exploit attacks. This trend coincides with the detection, regionalization, latency, and guardrail improvements we’ve made in 2025. No system can block everything, so fewer exploit attempts mean less risk across a wide range of workloads.
Figure 1: Chart showing the decrease in global malicious vulnerability exploit attempts
This work to identify known exploits in the wild directly benefits users of vulnerability intelligence in Amazon Inspector, which provides an Amazon Inspector score for customers to prioritize where to spend security hardening resources. This includes the most recent date of observed exploitation attempts, the MITRE ATT&CK techniques associated with the exploit activity, and the industries targeted.
Protecting architectures built on AWS
AWS actively defends compute and network resources for our customers; we also defend the distinct AWS-native resources that customers rely on. AWS access key credentials are a critical resource that allow access to customer accounts. The AWS Identity and Access Management best practices share proven techniques for customers to keep their credentials from being abused. Through active defense, we do even more to help customers who haven’t yet adopted these best practices.
Each day, AWS helps prevent an average of 167 million malicious scanning connections seeking unintentionally exposed AWS access key pairs. In case access keys are discovered through other means, we’ve expanded our protection of customer-managed IAM credentials. When our threat intelligence analytics show that a customer-managed credential is known by a threat actor, we put mitigations in place to restrict access to highly privileged operations. We also send customized notifications to help customers identify how the credential was exposed. These efforts are paying off for our customers every day; the following response is a good example of what we hear regularly:
This is a key that we already rotated a few weeks ago based on another alarm from you. It turned out that the new rotated key happened to be in your second alarm to us. So it meant that the app that the key was linked to was still leaking it.
So on Monday we sat down with the dev team, found where the app was leaking some secrets from, we patched it, I rotated all the exposed secrets (it was more than the IAM key) and we plugged in the extra security in the app.
So thanks again for those alerts, they are very precious. – AWS Customer
In a specific case of threat activity in November and December of 2024, customers reported ransomware activity against their objects in Amazon Simple Storage Service (Amazon S3) storage. We saw that these ransom threats were highly correlated with exposed customer-managed IAM keys. We applied quarantines to the exposed keys, taking care to make sure that normal customer operations could continue safely. We re-sent our proactive notifications to customers about keys that were likely exposed, because the risk of an attack was elevated. During this period, we worked together with customers to deactivate over 30 thousand exposed credentials. Since this threat activity began, AWS has helped prevent over 943 million malicious attempts to encrypt customer Amazon S3 objects.
These credential exposure detections flow into Amazon GuardDuty Extended Threat Detection, simplifying threat detection and response operations for modern cloud environments.
Better together
The approach AWS takes to active defense shows how security can be improved by layering protections across the infrastructure stack and using threat intelligence to drive risk reduction. By building active defense into our services at no extra cost, AWS helps our customers stay protected from a wide range of threats.
While we continue to constantly improve our protections for our customers, some of our work is by nature probabilistic, because we never see inside customer workloads. We don’t apply active defense in situations where the detection is ambiguous, because that might impact our customers’ production systems. To stay secure, customers should never let down their own defenses. AWS security services like AWS Identity and Access Management (IAM), AWS Shield Advanced, AWS WAF, AWS Network Firewall, Amazon GuardDuty, and Amazon Inspector provide prevention, detection, and response that customers can configure for their unique needs. The good news is that by working together, we’re making the internet safer for everyone.
If you have feedback about this post, submit comments in the Comments section below.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
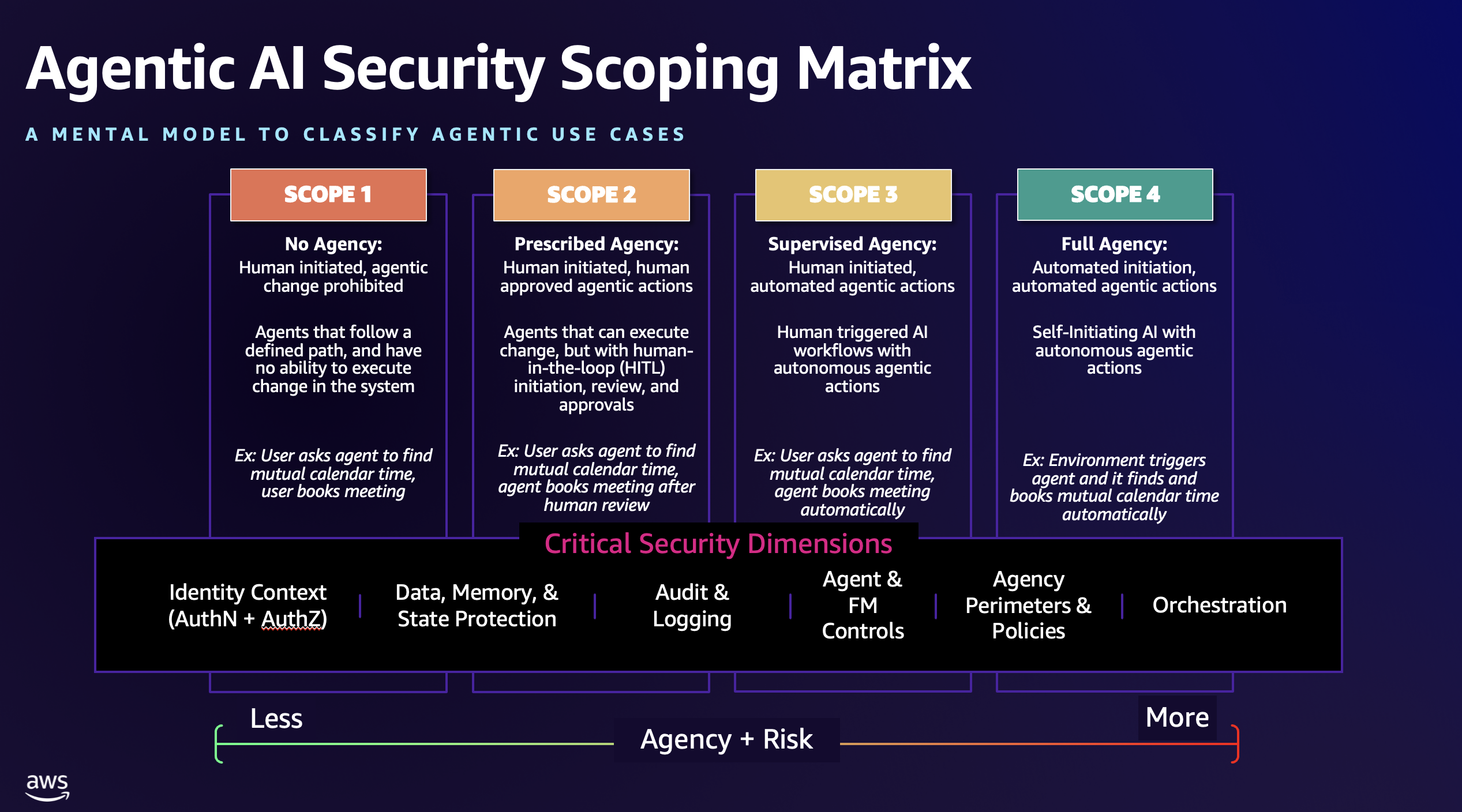
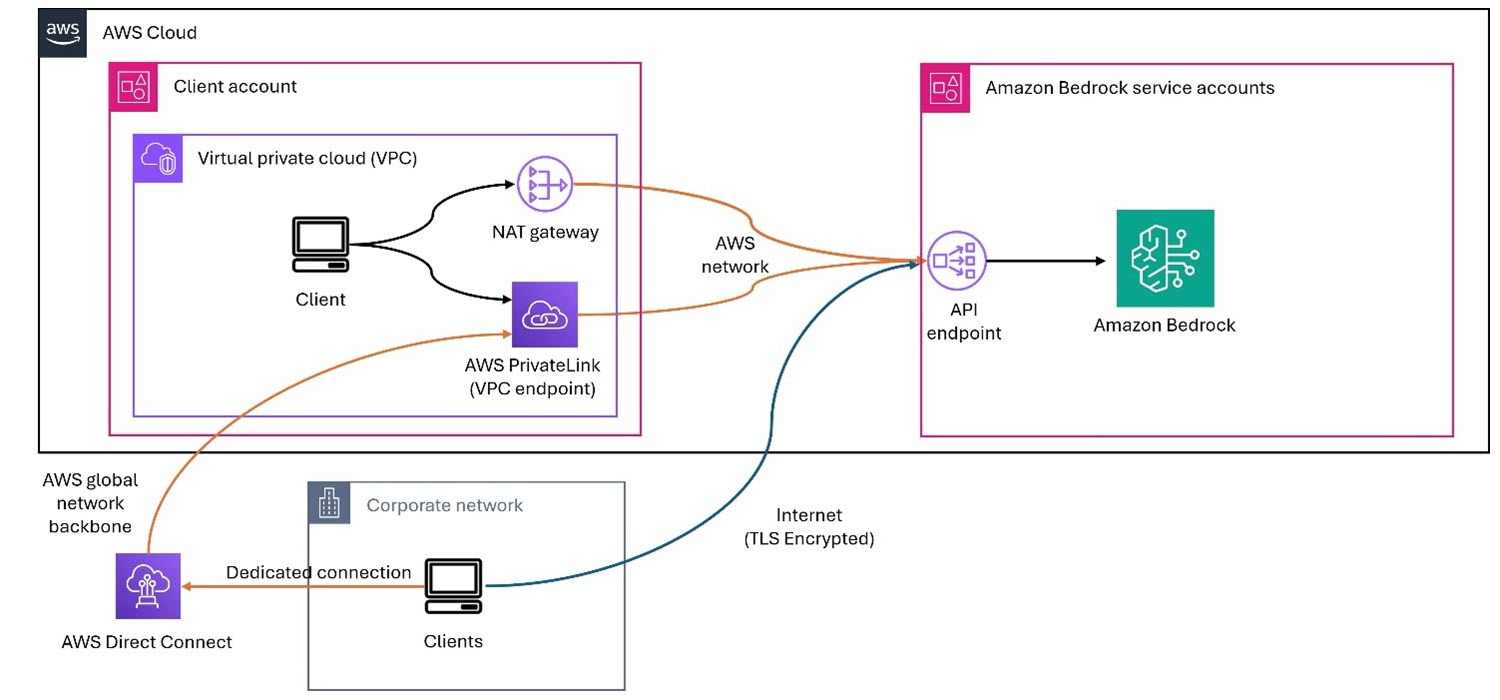
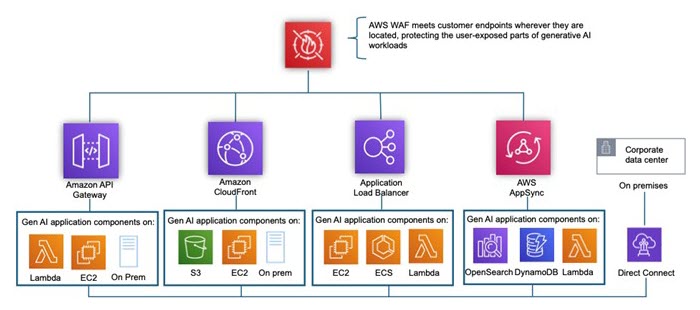
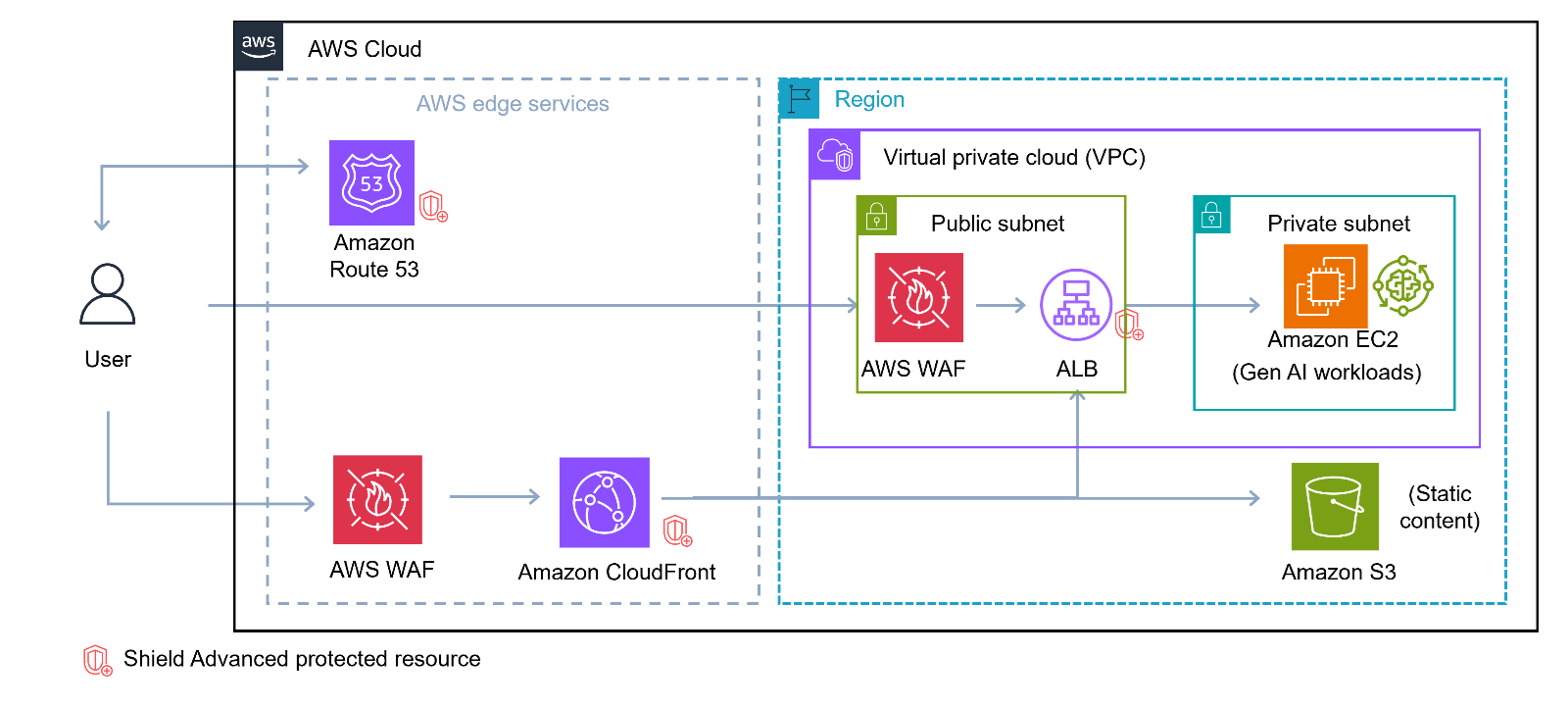
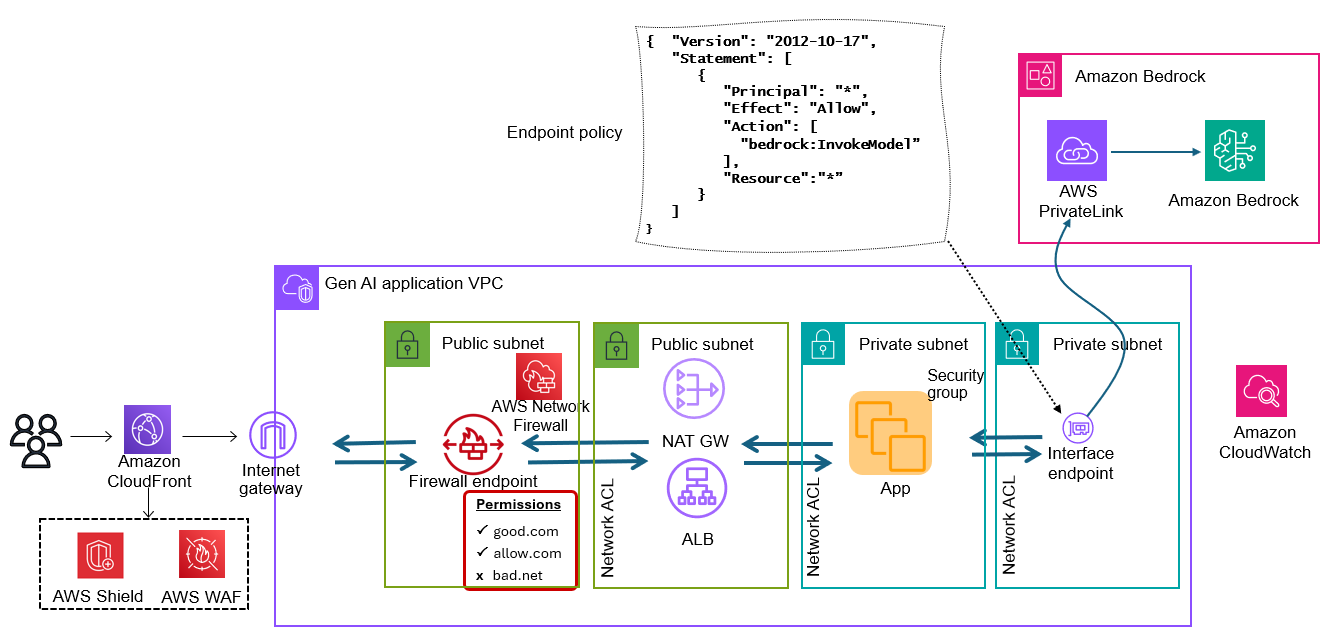

![Decoded JavaScript code, with compromised site removed: "[removed_domain]"](https://d2908q01vomqb2.cloudfront.net/22d200f8670dbdb3e253a90eee5098477c95c23d/2025/08/29/img2-1.png)















 Amit Maindola is a Senior Data Architect focused on data engineering, analytics, and AI/ML at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions.
Amit Maindola is a Senior Data Architect focused on data engineering, analytics, and AI/ML at Amazon Web Services. He helps customers in their digital transformation journey and enables them to build highly scalable, robust, and secure cloud-based analytical solutions on AWS to gain timely insights and make critical business decisions. Srinivas Kandi is a Senior Architect at Stifel focusing on delivering the next generation of cloud data platform on AWS. Prior to joining Stifel, Srini was a delivery specialist in cloud data analytics at AWS helping several customers in their transformational journey into AWS cloud. In his free time, Srini likes to explore cooking, travel and learn new trends and innovations in AI and cloud computing.
Srinivas Kandi is a Senior Architect at Stifel focusing on delivering the next generation of cloud data platform on AWS. Prior to joining Stifel, Srini was a delivery specialist in cloud data analytics at AWS helping several customers in their transformational journey into AWS cloud. In his free time, Srini likes to explore cooking, travel and learn new trends and innovations in AI and cloud computing. Hossein Johari is a seasoned data and analytics leader with over 25 years of experience architecting enterprise-scale platforms. As Lead and Senior Architect at Stifel Financial Corp. in St. Louis, Missouri, he spearheads initiatives in Data Platforms and Strategic Solutions, driving the design and implementation of innovative frameworks that support enterprise-wide analytics, strategic decision-making, and digital transformation. Known for aligning technical vision with business objectives, he works closely with cross-functional teams to deliver scalable, forward-looking solutions that advance organizational agility and performance.
Hossein Johari is a seasoned data and analytics leader with over 25 years of experience architecting enterprise-scale platforms. As Lead and Senior Architect at Stifel Financial Corp. in St. Louis, Missouri, he spearheads initiatives in Data Platforms and Strategic Solutions, driving the design and implementation of innovative frameworks that support enterprise-wide analytics, strategic decision-making, and digital transformation. Known for aligning technical vision with business objectives, he works closely with cross-functional teams to deliver scalable, forward-looking solutions that advance organizational agility and performance. Ahmad Rawashdeh is a Senior Architect at Stifel Financial. He supports Stifel and its clients in designing, implementing, and building scalable and reliable data architectures on Amazon Web Services (AWS), with a strong focus on data lake strategies, database services, and efficient data ingestion and transformation pipelines.
Ahmad Rawashdeh is a Senior Architect at Stifel Financial. He supports Stifel and its clients in designing, implementing, and building scalable and reliable data architectures on Amazon Web Services (AWS), with a strong focus on data lake strategies, database services, and efficient data ingestion and transformation pipelines. Lei Meng is a data architect at Stifel. His focus is working in designing and implementing scalable and secure data solutions on the AWS and helping Stifel’s cloud migration from on-premises systems.
Lei Meng is a data architect at Stifel. His focus is working in designing and implementing scalable and secure data solutions on the AWS and helping Stifel’s cloud migration from on-premises systems.