Post Syndicated from Nagarjuna Koduru original https://aws.amazon.com/blogs/big-data/best-practices-for-running-production-workloads-using-amazon-msk-tiered-storage/
In the second post of the series, we discussed some core concepts of the Amazon Managed Streaming for Apache Kafka (Amazon MSK) tiered storage feature and explained how read and write operations work in a tiered storage enabled cluster.
This post focuses on how to properly size your MSK tiered storage cluster, which metrics to monitor, and the best practices to consider when running a production workload.
Sizing a tiered storage cluster
Sizing and capacity planning are critical aspects of designing and operating a distributed system. It involves estimating the resources required to handle the expected workload and ensure the system can scale and perform efficiently. In the context of a distributed system like Kafka, sizing involves determining the number of brokers, the number of partitions, and the amount of storage and memory required for each broker. Capacity planning involves estimating the expected workload, including the number of producers, consumers, and the throughput requirements.
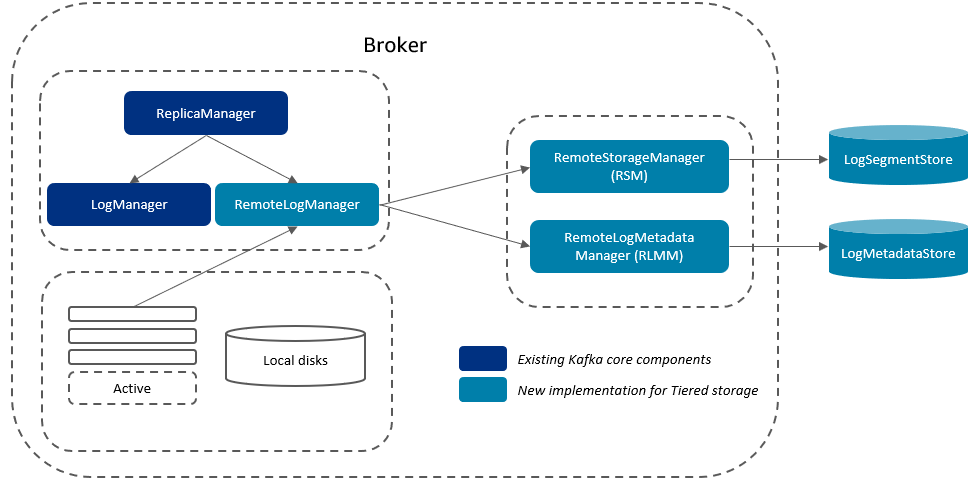
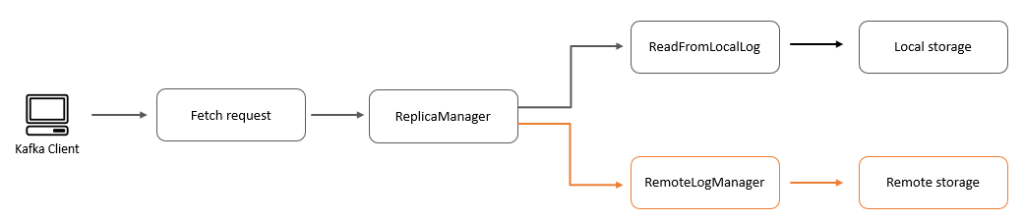
Let’s assume a scenario where the producers are evenly balancing the load between brokers, brokers host the same number of partitions, there are enough partitions to ingest the throughput, and consumers consume directly from the tip of the stream. The brokers are receiving the same load and doing the same work. We therefore just focus on Broker1 in the following diagram of a data flow within a cluster.

Theoretical sustained throughput with tiered storage
We derive the following formula for the theoretical sustained throughput limit tcluster given the infrastructure characteristics of a specific cluster with tiered storage enabled on all topics:
This formula contains the following values:
- tCluster – Total ingress produce throughput sent to the cluster
- tStorage – Storage volume throughput supported
- tNetworkAttachedStorage – Network attached storage to the Amazon Elastic Compute Cloud (Amazon EC2) instance network throughput
- tEC2network – EC2 instance network bandwidth
- non_tip_local_consumer_groups – Number of consumer groups reading from network attached storage at ingress rate
- tip_consumer_groups – Number of consumer groups reading from page cache at ingress rate
- remote_consumer_groups – Number of consumer groups reading from remote tier at ingress rate
- r – Replication factor of the Kafka topic
Note that in the first post , we didn’t differentiate between different types of consumer groups. With tiered storage, some consumer groups might be consuming from remote. These remote consumers might ultimately catch up and start reading from local storage and finally catch up to the tip. Therefore, we model these three different consumer groups in the equation to account for their impact on infrastructure usage. In the following sections, we provide derivations of this equation.
Derivation of throughput limit from network attached storage bottleneck
Because Amazon MSK uses network attached storage for local storage, both network attached storage throughput and bandwidth should be accounted for. Total throughput bandwidth requirement is a combination of ingress and egress from the network attached storage backend. The ingress throughput of the storage backend depends on the data that producers are sending directly to the broker plus the replication traffic the broker is receiving from its peers. With tiered storage, Amazon MSK also uses network attached storage to read and upload rolled segments to the remote tier. This doesn’t come from the page cache and needs to be accounted for at the rate of ingress. Any non-tip consumers at ingress rate also consume network attached storage throughput and are accounted for in the equation. Therefore, max throughput is bounded by network attached storage based on the following equation:
Derivation of throughput limit from EC2 network bottleneck
Unlike network attached storage, the network is full duplex, meaning that if the EC2 instance supports X MB/s network, it supports X MB/s in and X MB/s out. The network throughput requirement depends on the data that producers are sending directly to the broker plus the replication traffic the broker is receiving from its peers. It also includes the replication traffic out and consumers traffic out from this broker. With tiered storage, we need to reserve additional ingress rate for uploads to the remote tier and support reads from the remote tier for consumer groups reading from remote offset. Both of these add to the network out requirements, which is bounded by the following equation:
Combining the second and third equations provides the first formula, which determines the max throughput bound based on broker infrastructure limits.
How to apply this formula to size your cluster
With this formula, you can calculate the upper bound for throughput you can achieve for your workloads. In practice, the workloads may be bottlenecked by other broker resources like CPU, memory, and disk, so it’s important to do load tests. To simplify your sizing estimate, you can use the MSK Sizing and Pricing spreadsheet (for more information, refer to Best Practices).
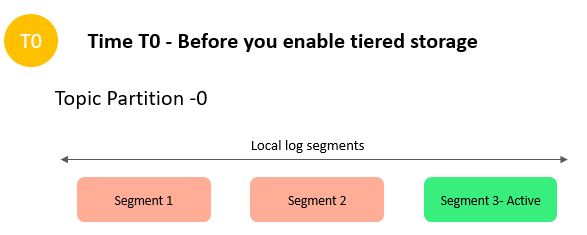
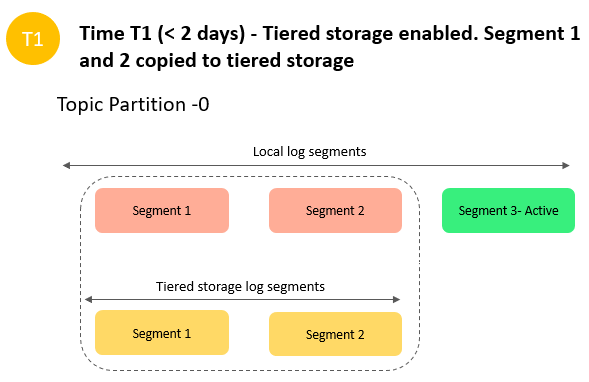
Let’s consider a workload where your ingress and egress rates are 20MB/s, with a replication factor of 3, and you want to retain data in your Kafka cluster for 7 days. This workload requires 6x m5.large brokers, with 34.6 TB local storage, which will cost $6,034.00 monthly (estimated). But if you use tiered storage for the same workload with local retention of 4 hours and overall data retention of 7 days, it requires 3x m5.large brokers, with 0.8 TB local storage and 12 TB of tiered storage, which will cost $1,958.00 monthly(estimated). If you want to read all the historic data one time, it will cost $17.00 ($0.0015 per GB retrieval cost). In this example with tiered storage, you save around 67.6% of your overall cost.
We recommend planning for Availability Zone redundancy in production workloads considering the broker safety factor in the calculation, which is 1 in this example. We also recommend running performance tests to ensure CPU is less than 70% on your brokers at the target throughput derived based on this formula or Excel calculation. In addition, you should also use the per-broker partition limit in your calculation to account for other bottlenecks based on the partition count.
The following figure shows an example of Amazon MSK sizing.

Monitoring and continuous optimization for a tiered storage enabled cluster
In previous sections, we emphasized the importance of determining the correct initial cluster size. However, it’s essential to recognize that sizing efforts shouldn’t cease after the initial setup. Continual monitoring and evaluation of your workload are necessary to ensure that the broker size remains appropriate. Amazon MSK offers metric monitoring and alarm capabilities to provide visibility into cluster performance. In the post Best practices for right-sizing your Apache Kafka clusters to optimize performance and cost, we discussed key metrics to focus on. In this post, we delve deeper into additional metrics related to tiered storage and other optimization considerations for a tiered storage enabled cluster:
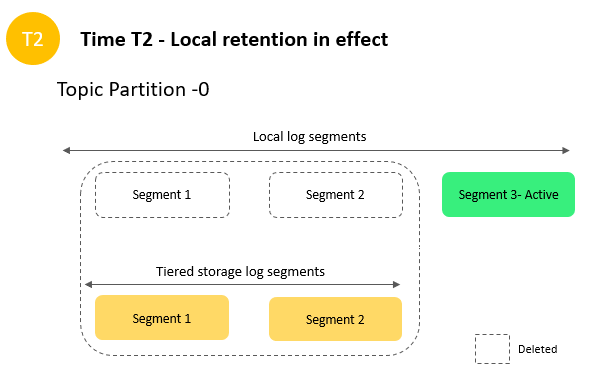
TotalTierBytesLagindicates the total number of bytes of the data that is eligible for tiering on the broker and hasn’t been transferred to the tiered storage yet. This metric shows the efficiency of upstream data transfer. As the lag increases, the amount of data that hasn’t yet persisted in the tiered storage increases. The impact is the network attached storage disk may fill up, which you should monitor. You should also monitor this metric and generate an alarm if the lag is continuously growing and you see increased network attached storage usage. If the tiering lag is too high, you can reduce ingress traffic to allow the tiered storage to catch up.- Although tiered storage provides on-demand, virtually unlimited storage capacity without provisioning any additional resources, you should still do proper capacity planning for your local storage, configure alerts for
KafkaDataLogsDiskUsedmetrics, and have a buffer on network attached storage capacity planning. Monitor this metric and generate an alarm if the metric reaches or exceeds 60%. For a tiered storage enabled topic, configure local retention accordingly to reduce network attached storage usage. - The theoretical max ingress we can achieve on an MSK cluster with tiered storage is 20–25% lower than a non-tiered storage enabled cluster due to additional network attached storage bandwidth required to transparently move data from the local to the remote tier. Plan for the capacity (brokers, storage, gp2 vs. gp3) using the formula we discussed to derive max ingress for your cluster based on the number of consumer groups and load test your workloads to identify the sustained throughput limit. Exercising excess ingress to the cluster or egress from the remote tier above the planned capacity can impact your tip produce or consume traffic.
- The gp3 volume type offers SSD-performance at a 20% lower cost per GB than gp2 volumes. Furthermore, by decoupling storage performance from capacity, you can easily provision higher IOPS and throughput without the need to provision additional block storage capacity. Therefore, we recommend using gp3 for a tiered storage enabled cluster by specifying provisioned throughput for larger instance types.
- If you specified a custom cluster configuration, check the
num.replica.fetchers,num.io.threads, andnum.network.threadsconfiguration parameters on your cluster. We recommend leaving it as the default Amazon MSK configuration unless you have specific use case.
This is only the most relevant guidance related to tiered storage. For further guidance on monitoring and best practices of your cluster, refer to Best practices.
Conclusion
You should now have a solid understanding of how Amazon MSK tiered storage works and the best practices to consider for your production workload when utilizing this cost-effective storage tier. With tiered storage, we remove the compute and storage coupling, which can benefit workloads that need larger disk capacity and are underutilizing compute just to provision storage.
We are eager to learn about your current approach in building real-time data streaming applications. If you’re starting your journey with Amazon MSK tiered storage, we suggest following the comprehensive Getting Started guide available in Tiered storage. This guide provides detailed instructions and practical steps to help you gain hands-on experience and effectively take advantage of the benefits of tiered storage for your streaming applications.
If you have any questions or feedback, please leave them in the comments section.
About the authors
 Nagarjuna Koduru is a Principal Engineer in AWS, currently working for AWS Managed Streaming For Kafka (MSK). He led the teams that built MSK Serverless and MSK Tiered storage products. He previously led the team in Amazon JustWalkOut (JWO) that is responsible for realtime tracking of shopper locations in the store. He played pivotal role in scaling the stateful stream processing infrastructure to support larger store formats and reducing the overall cost of the system. He has keen interest in stream processing, messaging and distributed storage infrastructure.
Nagarjuna Koduru is a Principal Engineer in AWS, currently working for AWS Managed Streaming For Kafka (MSK). He led the teams that built MSK Serverless and MSK Tiered storage products. He previously led the team in Amazon JustWalkOut (JWO) that is responsible for realtime tracking of shopper locations in the store. He played pivotal role in scaling the stateful stream processing infrastructure to support larger store formats and reducing the overall cost of the system. He has keen interest in stream processing, messaging and distributed storage infrastructure.
 Masudur Rahaman Sayem is a Streaming Data Architect at AWS. He works with AWS customers globally to design and build data streaming architectures to solve real-world business problems. He specializes in optimizing solutions that use streaming data services and NoSQL. Sayem is very passionate about distributed computing.
Masudur Rahaman Sayem is a Streaming Data Architect at AWS. He works with AWS customers globally to design and build data streaming architectures to solve real-world business problems. He specializes in optimizing solutions that use streaming data services and NoSQL. Sayem is very passionate about distributed computing.