Post Syndicated from Rajesh Francis original https://aws.amazon.com/blogs/big-data/implementing-multi-tenant-patterns-in-amazon-redshift-using-data-sharing/
Software service providers offer subscription-based analytics capabilities in the cloud with Analytics as a Service (AaaS), and increasingly customers are turning to AaaS for business insights. A multi-tenant storage strategy allows the service providers to build a cost-effective architecture to meet increasing demand.
Multi-tenancy means a single instance of software and its supporting infrastructure is shared to serve multiple customers. For example, a software service provider could generate data that is housed in a single data warehouse cluster, but accessed securely by multiple customers. This storage strategy offers an opportunity to centralize management of data, simplify ETL processes, and optimize costs. However, service providers have to constantly balance between cost and providing a better user experience for their customers.
With the new data sharing feature, you can use Amazon Redshift to scale and meet both objectives of managing costs by simplifying storage and ETL pipelines while still providing consistent performance to customers. You can ingest data into a cluster designated as a producer cluster, and share this live data with one or more consumer clusters. Clusters accessing this shared data are isolated from each other, therefore performance of a producer cluster isn’t impacted by workloads on consumer clusters. This enables consuming clusters to get consistent performance based on individual compute capacity.
In this post, we focus on various AaaS patterns, and discuss how you can use data sharing in a multi-tenant architecture to scale for virtually unlimited users. We discuss detailed steps to use data sharing with different storage strategies.
Multi-tenant storage patterns
Multi-tenant storage patterns help simplify the architecture and long-term maintenance of the analytics platform. In a multi-tenant strategy, data is stored centrally in a single cluster for all tenants, enabling simplification of the ETL ingestion pipeline and data management. In the previously published whitepaper SaaS Storage Strategies, various models of storage and benefits are covered for a single cluster scenario.
The three strategies you can choose from are:
- Pool model – Data is stored in a single database schema for all tenants, and a new column (
tenant_id) is used to scope and control access to individual tenant data. Access to the multi-tenant data is controlled using views built on the tables.
- Bridge model – Storage and access to data for each tenant is controlled at individual schema level in the same database.
- Silo model – Storage and access control to data for each tenant is maintained in separate databases
The following diagram illustrates the architecture of these multi-tenant storage strategies.

In the following sections, we will discuss how these multi-tenant strategies can be implemented using Amazon Redshift data sharing feature with a multi-cluster architecture.
Scaling your multi-tenant architecture using data sharing
AaaS providers implementing multi-tenant architectures were previously limited to resources of a single cluster to meet the compute and concurrency requirements of users across all the tenants. As the number of tenants increased, you could either turn on concurrency scaling or create additional clusters. However, the addition of new clusters means additional ingestion pipelines and increased operational overhead.
With data sharing in Amazon Redshift, you can easily and securely share data across clusters. Data ingested into the producer cluster is shared with one or more consumer clusters, which allows total separation of ETL and BI workloads. Several consumer clusters can read data from the managed storage of a producer cluster. This enables instant, granular, and high-performance access without data copies and movement. Workloads accessing shared data are isolated from each other and the producer. You can distribute workloads across multiple clusters while simplifying and consolidating the ETL ingestion pipeline into one main producer cluster, providing optimal price for performance.
Consumer clusters can in turn be producers for the data sets they own. Customers can optimize costs even further by collocating multiple tenants on the same consumer cluster. For instance, you can group low volume tier 3 tenants into a single consumer cluster to provider a lower cost offering, while high volume tier 1 tenants get their own isolated compute clusters. Consumer clusters can be created in the same account as producer or in a different AWS account. With this you can have separate billing for the consumer clusters, where you can chargeback to the business group that uses the consumer cluster or even allow your customers to use their own Redshift cluster in their account, so they pay for usage of the consumer cluster. The following diagram shows the difference in ETL and consumer access patterns in a multi-tenant architecture using data sharing versus a single cluster approach without data sharing.

Multi-tenant architecture with data sharing compared to single cluster approach
Creating a multi-tenant architecture for an AaaS solution
For this post, we use a simple data model with a fact and a dimension table to demonstrate how to leverage data sharing to design a scalable multi-tenant AaaS solution. We cover detailed steps involved for each storage strategy using this data model. The tables are as follows:
Customer – dimension table containing customer detailsSales – fact table containing sales transactions
We use two Amazon Redshift ra3.4xl clusters, with 2 nodes each, and designate one cluster as producer and other as consumer.
The high-level steps involved in enabling data sharing across clusters are as follows:
- Create a data share in the producer cluster and assign database objects to the data share.
- From the producer cluster, grant usage on the data share to consumer clusters, identified by namespace or AWS account.
- From the consumer cluster, create an external database using the data share from the producer
- Query the tables in the data share through the external shared database in the consumer cluster. Grant access to other users to access this shared database and objects.
Creating producer and consumer Amazon Redshift clusters
Let us start by creating two Amazon Redshift ra3.4xl clusters with 2-nodes each, one for the producer and other for consumer.
- On the Amazon Redshift cluster, create two clusters of RA3 instance type, and name them
ds-producer and ds-consumer-c1, respectively.
- Next, log in to Amazon Redshift using the query editor. You can also use a SQL client tool like DBeaver, SQL Workbench, or Aginity Workbench. For configuration information, see Connecting to an Amazon Redshift cluster using SQL client tools.
Get the cluster namespace of the producer and consumer clusters from the console. We will use the namespaces to create the tenant table and to create and access the data shares. You can also get the cluster namespaces by logging into each of the clusters and executing the SELECT CURRENT_NAMESPACE statement in the query editor.
Please note to replace the corresponding namespaces in the code sections wherever producercluster_namespace, consumercluster1_namespace, and consumercluster_namespace is referenced.
The following screenshot shows the namespace on the Amazon Redshift console.

Now that we have the clusters created, we will go through the detailed steps for the three models. First, we will cover the Pool model, followed by Bridge model and finally the Silo model.
Pool model
The pool model represents an all-in, multi-tenant model where all tenants share the same storage constructs and provides the most benefit in simplifying the AaaS solution.
With this model, data storage is centralized in one cluster database, and data is stored for all tenants in the same set of data models. To scope and control access to tenant data, we introduce a column (tenant_id) that serves as a unique identifier for each tenant.
Security management to prevent cross-tenant access is one of the main aspects to address with the pool model. We can implement row-level security and provide secure access to the data by creating database views and set application-level policies by creating groups with specific access and assigning users to the groups. The following diagram illustrates the pool model architecture.

To create a multi-tenant solution using the pool model, you create data shares for the pool model in the producer cluster, and share data with the consumer cluster. We provide more detail on these steps in the following sections.
Creating data shares for the pool model in the producer cluster
To create data shares for the pool model in the producer cluster, complete the following steps:
- Log in to the producer cluster as an admin user and run the following script.
Note that we have a tenant table to store unique identifiers for each tenant or consumer (tenant).
We add a column (tenant_id) to the sales and customer tables to uniquely identify tenant data. This tenant_id references the tenant_id in the tenant table to uniquely identify the tenant and consumer records. See the following code:
/**********************************************/
/* datasharing datasetup pool model */
/**********************************************/
-- Create Schema
create schema sales;
CREATE TABLE IF NOT EXISTS sales.tenant (
t_tenantid int8 not null,
t_name varchar(50) not null,
t_namespace varchar(50),
t_account varchar(16)
)
DISTSTYLE AUTO
SORTKEY AUTO;
-- Create tables for multi-tenant sales schema
drop table sales.customer;
CREATE TABLE IF NOT EXISTS sales.customer(
c_tenantid int8 not null,
c_custid int8 not null,
c_name varchar(25) not null,
c_region varchar(40) not null,
Primary Key(c_tenantid, c_custid)
)
DISTSTYLE AUTO
SORTKEY AUTO;
CREATE TABLE IF NOT EXISTS sales.sales (
s_tenantid int8 not null,
s_orderid int8 not null,
s_custid int8 not null,
s_totalprice numeric(12,2) not null,
s_orderdate date not null,
Primary Key(s_tenantid, s_orderid)
)
DISTSTYLE AUTO
SORTKEY AUTO;
- Set up the tenant table with the details for each consumer cluster, and ingest data into the customer dimension and sales fact tables. Using the COPY command is the recommended way to ingest data into Amazon Redshift, but for illustration purposes, we use INSERT statements:
-- Ingest data
insert into sales.tenant values
(0, 'primary', '<producercluster_namespace>',''),
(1, 'tenant1', '<consumercluster1_namespace>',''),
(2, 'tenant2', '<consumercluster2_namespace>','');
insert into sales.customer values
(1, 1, 'Customer 1', 'NorthEast'),
(1, 2, 'Customer 2', 'SouthEast'),
(2, 1, 'Customer 3', 'NorthWest'),
(2, 2, 'Customer 4', 'SouthEast');
truncate table sales.sales;
insert into sales.sales values
(1, 1, 1, 2434.33, '2020-11-21'),
(1, 2, 2, 54.90, '2020-5-5'),
(1, 3, 2, 9678.99, '2020-3-8'),
(2, 1, 2, 452.24, '2020-1-23'),
(2, 2, 1, 76523.10, '2020-11-3'),
(2, 3, 1, 6745.20, '2020-10-01');
select count(*) from sales.tenant;
select count(*) from sales.customer;
select count(*) from sales.sales;
Securing data on the producer cluster by restricting access
In the pool model, no external user has direct access to underlying tables. All access is restricted using views.
- Create a view for each of the fact and dimension tables to include a condition to filter records from the consumer tenant’s namespace. In our example, we create
v_customersales to combine sales fact and customer dimension tables with a restrictive filter for tenant.namespace = current_namespace. See the following code:
/**********************************************/
/* We will create late binding views */
/* but materialized views could also be used */
/**********************************************/
create or replace view sales.v_customer as
select *
from sales.customer c, sales.tenant t
where c.c_tenantid = t.t_tenantid
and t.t_namespace = current_namespace;
create or replace view sales.v_sales as
select *
from sales.sales s, sales.tenant t
where s.s_tenantid = t.t_tenantid
and t.t_namespace = current_namespace;
create or replace view sales.v_customersales as
select c_tenantid, c_name, c_region,
date_part(w, to_date(s_orderdate,'YYYY-MM-DD')) as "week",
date_part(mon, to_date(s_orderdate,'YYYY-MM-DD')) as "month",
date_part(dow, to_date(s_orderdate,'YYYY-MM-DD')) as "dow",
date_part(yr, to_date(s_orderdate,'YYYY-MM-DD')) as "year",
date_part(d, to_date(s_orderdate,'YYYY-MM-DD')) as "dom",
t.t_namespace
from sales.tenant t, sales.customer c, sales.sales s
where t.t_tenantid = c.c_tenantid
and c.c_tenantid = s.s_tenantid
and c.c_custid = s.s_custid
and t.t_namespace = current_namespace
WITH NO SCHEMA BINDING;
select * from sales.v_customersales;
Now that we have database objects created in the producer cluster, we can share the data with the consumer clusters.
Sharing data with the consumer cluster
To share data with the consumer cluster, complete the following steps:
- Create a data share for the sales data:
/***************************************************/
/* Create Datashare and add objects to the share */
/****************************************************/
CREATE DATASHARE salesshare;
- Enter the following code to alter the data share, add the sales schema to be shared with the consumer clusters, and add all tables in the sales schema to be shared with the consumer cluster:
/************************************************************/
/* Add objects at desired granularities: schemas, tables, */
/* views include materialized, and SQL UDFs */
/************************************************************/
ALTER DATASHARE salesshare ADD SCHEMA sales; -- New addition to create SCHEMA first
/*For pool model, we share only the views and not tables */
ALTER DATASHARE SalesShare ADD TABLE sales.v_customer;
ALTER DATASHARE SalesShare ADD TABLE sales.v_customersales;
For the pool model, we share only the views with the consumer cluster and not the tables. The ALTER statement ADD TABLE is used to add both views and tables.
- Grant usage on the sales data share to the namespace of the BI consumer cluster. You can get the namespace of the BI cluster from the console or using the
SELECT CURRENT_NAMESPACE statement in the BI cluster. See the following code:
/********************************************************************/
/* Grant access to consumer clusters */
/* login to Consumer BI Cluster and get the Namespace from */
/* the Redshift console or using SELECT CURRENT_NAMESPACE */
/********************************************************************/
SELECT CURRENT_NAMESPACE;
--Namespace refers to the namespace GUID of the consumer cluster in the account
GRANT USAGE ON DATASHARE salesshare TO NAMESPACE '<consumercluster1_namespace>'
--Account numbers are 12 digit long
GRANT USAGE ON DATASHARE salesshare TO ACCOUNT 'Consumer_AWSAccount';
- View data shares that are shared from the producer cluster:
SELECT * FROM SVV_DATASHARES;
The following screenshot shows the output.

You can also see the data shares and their detailed objects and consumers using the following commands:
SHOW DATASHARES;
DESC DATASHARE salesshare;
select * from SVV_DATASHARE_OBJECTS;
select * from SVV_DATASHARE_CONSUMERS;
Viewing and querying data shares for the pool model from the consumer cluster
To view and query data shares from the consumer cluster, complete the following steps:
- Log in to the consumer cluster as an admin user and view the data share objects:
/**********************************************************/
/* Login to Consumer cluster as awsuser: */
/* View datashares and create local database for querying */
/**********************************************************/
select * from SVV_DATASHARE_OBJECTS;
The following screenshot shows the results.

- Create a new database from the data share of the producer cluster:
/**********************************************************/
/* Create a local database and schema reference */
/**********************************************************/
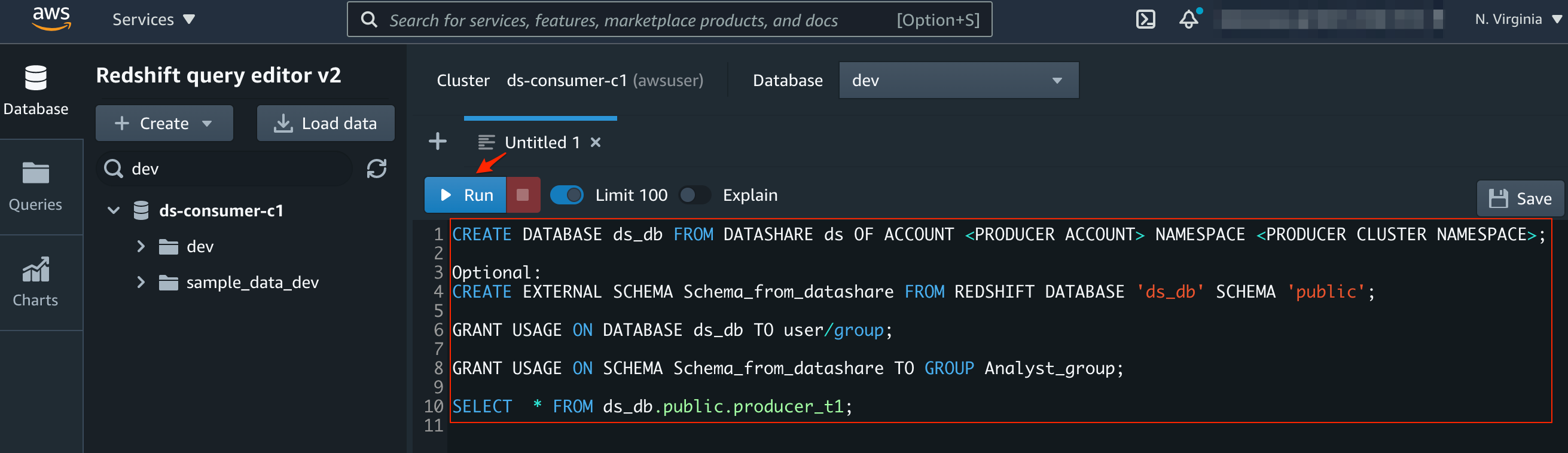
CREATE DATABASE sales_db FROM DATASHARE salesshare
OF NAMESPACE '<producercluster_namespace>';
- Optionally, you can create an external schema in the consumer cluster pointing to the schema in the database of the producer cluster.
Creating a local external schema in the consumer cluster allows schema-level access controls within the consumer cluster, and uses a two-part notation when referencing shared data objects (localschema.table; vs. external_db.producerschema.table). See the following code:
/*********************************************************/
/* Create External Schema - Optional */
/* reason for schema: give specific access to schema */
/* using shared alias get access to a secondary database */
/*********************************************************/
CREATE EXTERNAL SCHEMA sales_schema
FROM REDSHIFT DATABASE 'sales_db' SCHEMA 'sales';
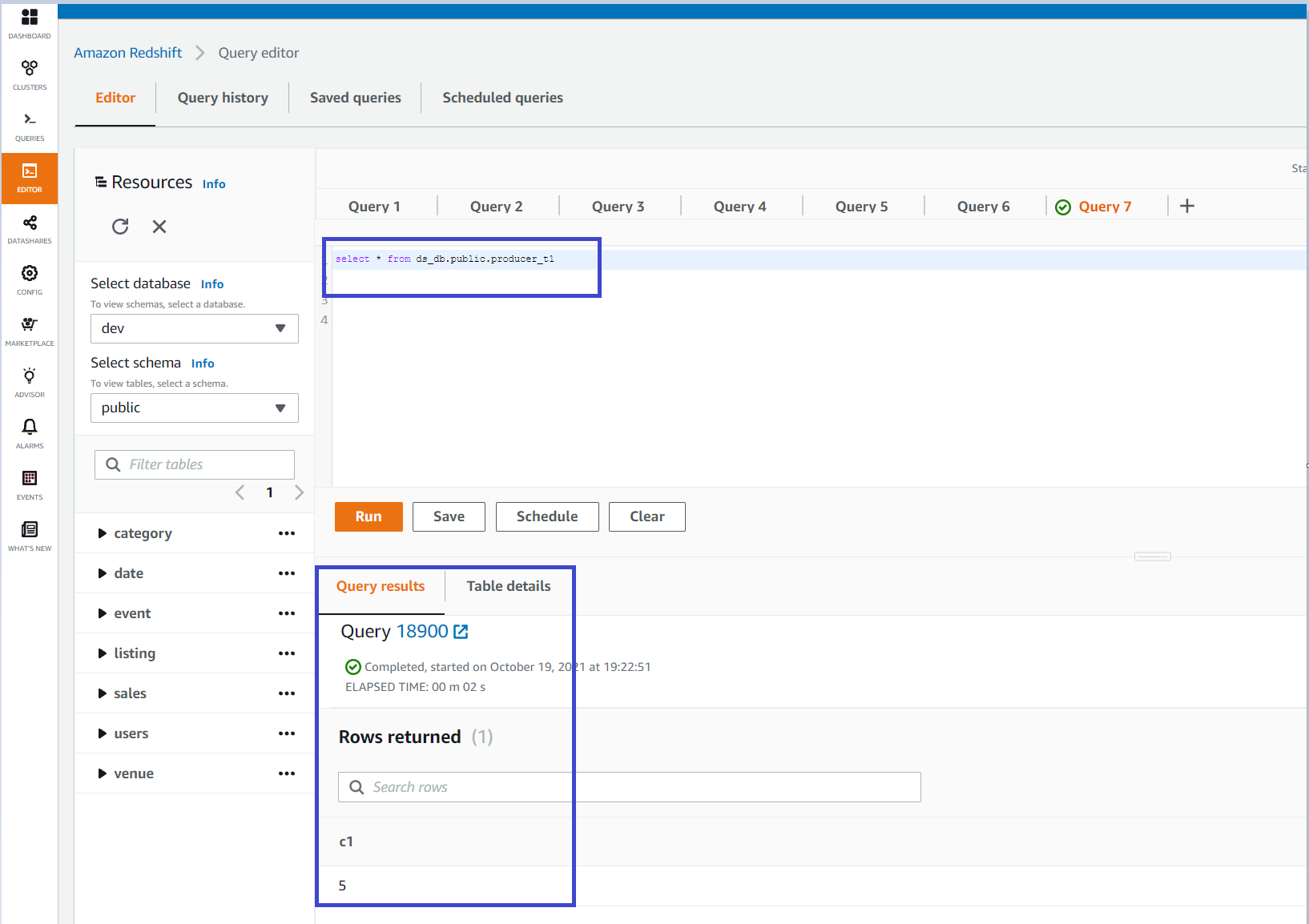
- Now you can query the shared data from the producer cluster by using the syntax
tenant.schema.table:
select * from sales_db.sales.customer;
select * from sales_db.sales.v_customersales;
- From the
tenant1 consumer cluster, you can view the databases and the tenants that are accessible to tenant1. tenant1_schema is as follows:
select * from SVV_REDSHIFT_DATABASES;
The following screenshot shows the results.

Creating local consumer users and controlling access
You can control access to users in your consumer cluster by creating users and groups, and assigning access to the data share objects.
- Log in as an admin user on consumer cluster 1 and enter the following code to create
tenant1_group, grant usage on the local database sales_db and schema sales_schema to the group, and assign the user tenant1_user to the tenant1_group:
/********************************************************/
/* Consumers can create own users and assign privileges */
/* Create tenant1_group and assign privileges to read */
/* sales_db and the sales_schema */
/* Create tenant1_user in tenant1_group */
/********************************************************/
create group tenant1_group;
create user tenant1_user password 'Redshift#123!' in group tenant1_group;
GRANT USAGE ON DATABASE sales_db TO tenant1_group;
GRANT USAGE ON SCHEMA sales_schema TO GROUP tenant1_group;
- Now, login as
tenant1_user to consumer cluster 1 and select data from the views v_customer and v_customersales:
/*******************************************************/
/* select from view returns only sales records related */
/* to Consumer A namespace */
/*******************************************************/
select * from sales_db.sales.v_customer;
select * from sales_db.sales.v_customersales;
You should see only the data relevant to tenant 1 and not the data that is associated with tenant 2.

Create Materialized views to optimize performance
Consumer clusters can have their own database objects which are local to the consumer. You can also create materialized views on the datashare objects and control when to refresh the dataset for your consumers. This provides another level of isolation from the producer cluster, and will ensure the consumer clusters go against their local dataset.
- Log in as an admin user on consumer cluster 1 and enter the following code to create a materialized view for customersales. This will create a local view that can be periodically refreshed from the consumer cluster.
/*******************************************************/
/* Create materialized view in consumer cluster */
/*******************************************************/
create MATERIALIZED view tenant1_sales.mv_customersales as
select c_tenantid, c_name, c_region,
date_part(w, to_date(s_orderdate,'YYYY-MM-DD')) as "week",
date_part(mon, to_date(s_orderdate,'YYYY-MM-DD')) as "month",
date_part(dow, to_date(s_orderdate,'YYYY-MM-DD')) as "dow",
date_part(yr, to_date(s_orderdate,'YYYY-MM-DD')) as "year",
date_part(d, to_date(s_orderdate,'YYYY-MM-DD')) as "dom",
t.t_namespace
from sales_db.tenant t, sales_db.customer c, sales_db.sales s
where t.t_tenantid = c.c_tenantid
and c.c_tenantid = s.s_tenantid
and c.c_custid = s.s_custid
and t.t_namespace = current_namespace;
select * from tenant1_sales.mv_customersales top 100;
REFRESH MATERIALIZED VIEW tenant1_sales.mv_customersales;
With the preceding steps, we have demonstrated how you can control access to the tenant data in the same datastore using views. We also reviewed how data shares help efficiently share data between producer and consumer clusters with transaction consistency. We also saw how a local materialized view can be created to further isolate your BI workloads for your customers and provide a consistent, performant user experience. In the next section we will discuss the Bridge model.
Bridge model
In the bridge model, data for each tenant is stored in its own schema in a database and contains a similar set of tables. Data shares are created for each schema and shared with the corresponded consumer. This is an appealing balance between silo and pool model, providing both data isolation and ETL consolidation. With Amazon Redshift, you can create up to 9,900 schemas. For more information, see Quotas and limits in Amazon Redshift.
With data sharing, separate consumer clusters can be provisioned to use the same managed storage from producer cluster. Consumer clusters have all the capabilities of a producer cluster, and can in turn be producer clusters for data objects they own. Consumers can’t share data that is already shared with them. Without data sharing, queries from all customers are directed to a single cluster. The following diagram illustrates the bridge model.

To create a multi-tenant architecture using bridge model, complete the steps in the following sections.
Creating database schemas and tables for the bridge model in the producer cluster
As we did in the pool model, the first step is to create the database schema and tables. We log in to the producer cluster as an admin user and create separate schemas for each tenant. For our post, we create two schemas, tenant1 and tenant2, to store data for two tenants.
- Log in to the producer cluster as the admin user.
- Use the script below to create two schemas,
tenant1 and tenant2, and create tables for customer dimension and sales facts under each of the two schemas. See the following code:
/****************************************/
/* Bridge - Data Model */
/****************************************/
-- Create schemas tenant1 and tenant2
create schema tenant1;
create schema tenant2;
-- Create tables for tenant1
CREATE TABLE IF NOT EXISTS tenant1.customer (
c_custid int8 not null ,
c_name varchar(25) not null,
c_region varchar(40) not null,
Primary Key(c_custid)
) diststyle ALL sortkey(c_custid);
CREATE TABLE IF NOT EXISTS tenant1.sales (
s_orderid int8 not null,
s_custid int8 not null,
s_totalprice numeric(12,2) not null,
s_orderdate date not null,
Primary Key(s_orderid)
) distkey(s_orderid) sortkey(s_orderdate, s_orderid) ;
-- Create tables for tenant2
CREATE TABLE IF NOT EXISTS tenant2.customer (
c_custid int8 not null ,
c_name varchar(25) not null,
c_region varchar(40) not null,
Primary Key(c_custid)
) diststyle ALL sortkey(c_custid);
CREATE TABLE IF NOT EXISTS tenant2.sales (
s_orderid int8 not null,
s_custid int8 not null,
s_totalprice numeric(12,2) not null,
s_orderdate date not null,
Primary Key(s_orderid)
) distkey(s_orderid) sortkey(s_orderdate, s_orderid) ;
- Ingest data into the customer dimension and sales fact tables. Using the COPY command is the recommended way to ingest data into Amazon Redshift, but for illustration purposes, we use the INSERT statement:
-- ingest data for tenant1
-- ingest customer data
insert into tenant1.customer values
(1, 'Customer 1', 'NorthEast'),
(2, 'Customer 2', 'SouthEast');
-- ingest sales data
insert into tenant1.sales values
(1, 1, 2434.33, '2020-11-21'),
(2, 2, 54.90, '2020-5-5'),
(3, 2, 9678.99, '2020-3-8');
select count(*) from tenant1.customer;
select count(*) from tenant1.sales;
-- ingest data for tenant2
-- ingest customer data
insert into tenant2.customer values
(1, 'Customer 3', 'NorthWest'),
(2, 'Customer 4', 'SouthEast');
-- ingest sales data
truncate table tenant2.sales;
insert into tenant2.sales values
(1, 2, 452.24, '2020-1-23'),
(2, 1, 76523.10, '2020-11-3'),
(3, 1, 6745.20, '2020-10-01');
select count(*) from tenant2.customer;
select count(*) from tenant2.sales;
Creating data shares and granting usage to the consumer cluster
In the following code, we create two data shares, tenant1share and tenant2share, to share the database objects under the two schemas to the respective consumer clusters.
- Create two datashares tenant1share and tenant2share to share the database objects under the two schemas to the respective consumer clusters.
/******************************************************************/
/* Create Datashare and add database objects to the datashare */
/******************************************************************/
CREATE DATASHARE tenant1share;
CREATE DATASHARE tenant2share;
- Alter the datashare and add the schema(s) for respective tenants to be shared with the consumer cluster
ALTER DATASHARE tenant1share ADD SCHEMA tenant1;
ALTER DATASHARE tenant2share ADD SCHEMA tenant2;
- Alter the datashare and add all tables in the schema(s) to be shared with the consumer cluster
ALTER DATASHARE tenant1share ADD ALL TABLES IN SCHEMA tenant1;
ALTER DATASHARE tenant2share ADD ALL TABLES IN SCHEMA tenant2;
Getting the namespace of the first consumer cluster
- Log in to the consumer cluster and get the namespace from the console or by running the select
current_namespace command:
/* Grant access to tenant1 schema for Tenant1 BI Cluster */
/* login to tenant1 BI Cluster and get the Namespace
* or get the Namespace from the Redshift console */
SELECT CURRENT_NAMESPACE;
- Grant usage on the data share for the first tenant to the namespace of the BI cluster. You can get the namespace of the BI cluster from the console or using the
SELECT CURRENT_NAMESPACE statement in the BI cluster:
-- Grant usage on the datashare to the first consumer cluster
-- Namespace refers to the namespace GUID of the consumer cluster
GRANT USAGE ON DATASHARE tenant1share TO NAMESPACE '<consumercluster1_namespace>'
--Account numbers are 12 digit long (optional)
--GRANT USAGE ON DATASHARE tenant1share TO ACCOUNT '<Consumer_AWSAccount>';
Getting the namespace of the second consumer cluster
- Log in to the second consumer cluster and get the namespace from the console or by running the select
current_namespace command:
/* Grant access to tenant2 schema for Tenant2 BI Cluster */
/*login to tenant1 BI Cluster and get the Namespace */
SELECT CURRENT_NAMESPACE;
- Grant usage on the data share for the second tenant to the namespace of the second consumer cluster you just got from the previous step:
-- Grant usage on the datashare to the second consumer cluster
GRANT USAGE ON DATASHARE tenant2share TO NAMESPACE '<consumercluster2_namespace>'
--Account numbers are 12 digit long (optional)
--GRANT USAGE ON DATASHARE tenant2share TO ACCOUNT '<Consumer_AWSAccount>';
- To view data shares from the producer cluster, enter the following code:
/******************************************************************/
/* View Datashares created, Datashare objects and consumers */
/******************************************************************/
select * from SVV_DATASHARES;
select * from SVV_DATASHARE_OBJECTS;
select * from SVV_DATASHARE_CONSUMERS;
The following screenshot shows the commands in the query editor.

The following screenshot shows the query results.

Accessing data using the consumer cluster from the data share
To access data using the consumer cluster, complete the following steps:
- Log in to the first consumer cluster
ds-consumer-c1, as an admin user.
- View data share objects from the
SVV_DATASHARE_OBJECTS system view:
/*****************************************************/
/* Consumer cluster as adminuser
/* List the shares available and review contents for each
/********************************************************/
-- You can view datashare objects associated with the cluster
-- using either of the two commands
SHOW DATASHARES;
select * from SVV_DATASHARES;
The following screenshot shows the query results.

--View objects shared in inbound share for consumer
select * from SVV_DATASHARE_OBJECTS;
The following screenshot shows the query results.

--View namespace or clusters granted usage to a datashare
select * from svv_datashare_consumers;
- Create a local database in the first consumer cluster, and an external schema to be able to provide controlled access to the specific schema to the consumer clusters:
/*******************************************************/
/* Create a local database and schema reference */
/* to the share objects */
/*******************************************************/
CREATE DATABASE tenant1_db FROM DATASHARE tenant1share
OF NAMESPACE '<producercluster_namespace>';
- Query the database tables using the three-part notation
db.tenant.table:
select * from tenant1_db.tenant1.customer;
select * from tenant1_db.tenant1.sales;
- Optionally, you can create an external schema.
There are two reasons to create an external schema: either to enable two-part notation access to the tables from the consumer cluster, or to provide restricted access to the specific schemas for selected users, when multiple schemas are shared from the producer cluster. See the following code for our external schema:
/* Create External Schema */
CREATE EXTERNAL SCHEMA tenant1_schema FROM REDSHIFT DATABASE 'tenant1_db' SCHEMA 'tenant1';
- If you created the local schemas, you can use the following two-part notation to query the database tables:
select * from tenant1_schema.customer;
select * from tenant1_schema.sales;
- You can view the shared databases by querying the
SVV_REDSHIFT_DATABASES table:
select * from SVV_REDSHIFT_DATABASES;
The following screenshot shows the query results.

Creating consumer users for managing access
Still logged in as an admin user to the consumer cluster, you can create other users who have access to the database objects.
- Create users and groups, and assign users and object privileges to the groups with the following code:
/*******************************************************/
/* Consumer can create own users and assign privileges */
/* Create tenant1_user and assign privileges to */
/* read datashare from tenant1 schema */
/*******************************************************/
create group tenant1_group;
create user tenant1_user password 'Redshift#123!' in group tenant1_group;
GRANT USAGE ON DATABASE tenant1_db TO tenant1_user;
GRANT USAGE ON SCHEMA tenant1_schema TO GROUP tenant1_group;
Now tenant1_user can log in and query the shared tables from tenant schema.
- Log in to the consumer cluster as
tenant1_user and query the tables:
/************************************************************/
/* Consumer cluster as tenant1_user - As a consumer cluster */
/* administrator, you must follow these steps: */
/************************************************************/
select * from tenant1_db.tenant1.customer;
select * from tenant1_db.tenant1.sales;
/************************************************************/
/* If you have created and External Schema */
/* you can use the two-part notation to query tables. */
/************************************************************/
select * from tenant1_schema.customer;
select * from tenant1_schema.sales;
Revoking access to a data share (optional)
- At any point, if you want to revoke access to the data share, you can the
REVOKE USAGE command:
/*************************************************************/
/* To revoke access at any time use the REVOKE USAGE command */
/*************************************************************/
--Namespace refers to the namespace GUID of the consumer cluster in the account
REVOKE USAGE ON DATASHARE Salesshare FROM NAMESPACE '<consumercluster1_namespace>'
--Account numbers are 12 digit long
REVOKE USAGE ON DATASHARE Salesshare FROM ACCOUNT '<Consumer_AWSAccount>';
Silo model
The third option is to store data for each tenant in separate databases within a cluster. If you need your data isolated from other tenants, you can use the silo model and each database may have distinct data models, monitoring, management, and security footprints.
Amazon Redshift supports cross-database queries across databases, which allow you to simplify data organization. You can store common or granular datasets used across all tenants in a centralized database, and use the cross-database query capability to join relevant data for each tenant.
The steps to create a data share in a silo model is similar to a bridge model; however, unlike a bridge model (where data share is for each schema), the silo model has a data share created for each database. The following diagram illustrates the architecture of the silo model.

Creating data shares for the silo model in the producer cluster
To create data shares for the silo model in the producer cluster, complete the following steps:
- Log in to the producer cluster as an admin user and create separate databases for each tenant:
/*****************************************************/
/** Silo Model – Create databases for the 2 tenants **/
/*****************************************************/
create database tenant1_silodb;
create database tenant2_silodb;
- Log in again to the producer cluster with the database name and user ID for the database that you want to share (
tenant1_silodb) and create the schema and tables:
/***********************************************************/
/* login to tenant1_db and create schema tenant1 and tables*/
/***********************************************************/
create schema tenant1_siloschema;
-- Create tables for tenant1
CREATE TABLE IF NOT EXISTS tenant1_silodb.tenant1_siloschema.customer (
c_custid int8 not null ,
c_name varchar(25) not null,
c_region varchar(40) not null,
Primary Key(c_custid)
) diststyle ALL sortkey(c_custid);
CREATE TABLE IF NOT EXISTS tenant1_silodb.tenant1_siloschema.sales (
s_orderid int8 not null,
s_custid int8 not null,
s_totalprice numeric(12,2) not null,
s_orderdate date not null,
Primary Key(s_orderid)
) distkey(s_orderid) sortkey(s_orderdate, s_orderid) ;
insert into tenant1_siloschema.customer values
(1, 'Customer 1', 'NorthEast'),
(2, 'Customer 2', 'SouthEast');
truncate table tenant1_siloschema.sales;
insert into tenant1.sales values
(1, 1, 2434.33, '2020-11-21'),
(2, 2, 54.90, '2020-5-5'),
(3, 2, 9678.99, '2020-3-8');
- Create a data share with a name for the first tenant (for example,
tenant1dbshare):
/******************************************************************/
/* Create datashare and add database objects to the datashare */
/******************************************************************/
CREATE DATASHARE tenant1_silodbshare;
- Run
Alter datashare commands to add the schemas to be shared with the consumer cluster and add all tables in the schemas to be shared with the consumer cluster:
ALTER DATASHARE tenant1_silodbshare ADD SCHEMA tenant1_siloschema;
ALTER DATASHARE tenant1_silodbshare ADD ALL TABLES IN SCHEMA tenant1_siloschema;
- Grant usage on the data share for first tenant to the namespace of the BI cluster. You can get the namespace of the BI cluster from the console or using the
SELECT CURRENT_NAMESPACE statement in the BI cluster:
--Namespace refers to the namespace GUID of the consumer cluster in the account
GRANT USAGE ON DATASHARE tenant1_silodbshare TO NAMESPACE ‘<consumercluster1_namespace>’
--Account numbers are 12 digit long (optional)
--GRANT USAGE ON DATASHARE tenant1_silodbshare TO ACCOUNT '<AWS-Account>';
Viewing and querying data shares for the silo model from the consumer cluster
To view and query your data shares, complete the following steps:
- Log in to the consumer cluster as an admin user.
- Create a new database from the data share of the producer cluster:
CREATE DATABASE tenant1_silodb FROM DATASHARE tenant1_silodbshare
OF NAMESPACE ‘<producercluster_namespace>’;
Now you can start querying the shared data from the producer cluster by using the syntax – tenant.schema.table. If you created an external schema, then you can also use the two-part notation to query the tables.
- Query the data with the following code:
select * from tenant1_silodb.tenant1.customer;
select * from tenant1_silodb.tenant1.sales;
- Optionally, you can create an external schema pointing to the schema in the database of the producer cluster. This allows you query shared tables using a two-part notation. See the following code:
CREATE EXTERNAL SCHEMA tenant1_siloschema FROM REDSHIFT DATABASE 'tenant1_silodb' SCHEMA 'tenant1';
--With this Schema, you can access using two-part notation to select from data share tables
select * from tenant1_siloschema.customer;
select * from tenant1_siloschema.sales;
- You can repeat the same steps for
tenant2 to share the tenant2 database with tenant2 You can also control access to users in your consumer cluster by creating users and groups, and assigning access to the data share objects.
System views to view data shares
We have introduced new system tables and views to easily identify the data shares and related objects. You can use three different groups of system views to view the data share objects:
- Views starting with SVV_DATASHARES – has detail of datashares and objects in a datashare.
| View Name |
Purpose |
| SVV_DATASHARES |
View a list of data shares created on the cluster and data shares shared with the cluster |
| SVV_DATASHARE_OBJECTS |
View a list of objects in all data shares created on the cluster or shared with the cluster |
| SVV_DATASHARE_CONSUMERS |
View a list of consumers for data share created on the cluster |
- Views starting with SVV_REDSHIFT – contains details on both local and remote Redshift databases.
| View Name |
Purpose |
| SVV_REDSHIFT_DATABASES |
List of all databases that a user has access to |
| SVV_REDSHIFT_SCHEMAS |
List of all schemas that user has access to |
| SVV_REDSHIFT_TABLES |
List of all tables that a user has access to |
| SVV_REDSHIFT_COLUMNS |
List of all columns that a user has access to |
| SVV_REDSHIFT_FUNCTIONS |
List of all functions that user has access to |
- Views starting with SVV_ALL– contain local and remote databases, external schemas including spectrum and federated query, and external schema references to shared data. If you create external schemas in consumer cluster, you need to use the SVV_ALL views to look at the objects.
| View Name |
Purpose |
| SVV_ ALL _SCHEMAS |
Union of list of all schemas from SVV_REDSHIFT_SCHEMA view and consolidated list of all external tables and schemas that user has access to |
| SVV_ ALL _TABLES |
List of all tables that a user has access to |
| SVV_ ALL _COLUMNS |
List of all columns that a user has access to |
| SVV_ ALL _FUNCTIONS |
List of all functions that user has access to |
Considerations for choosing a storage strategy
You can adopt a storage strategy or choose a hybrid approach based on business, technical, and operational requirements. Before deciding on a strategy, consider the quotas and limits for various objects in Amazon Redshift, and the number of databases per cluster or number of schemas per database to check if it meets your requirements. The following table summarizes these considerations.
| |
Pool |
Bridge |
Silo |
| Separation of tenant data |
Views |
Schema |
Database |
| ETL pipeline complexity |
Low |
Low |
Medium |
| Limits |
100,000 tables (RA3 – 4x, 16x large clusters) |
9,900 schemas per database |
60 databases per cluster |
| Chargeback to consumer accounts |
Yes |
Yes |
Yes |
| Scalability |
High |
High |
High |
Conclusion
In this post, we discussed how you can use the new data sharing feature of Amazon Redshift to implement an AaaS solution with a multi-tenant architecture while meeting SLAs for consumers using separate Amazon Redshift clusters. We demonstrated three types of models providing various levels of isolation for the tenant data. We compared and contrasted the models and provided guidance on when to choose an implementation model. We encourage you to try the data sharing feature to build your AaaS or software as a service (SaaS) solutions.
About the Authors
 Rajesh Francis is a Sr. Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build scalable Analytic solutions.
Rajesh Francis is a Sr. Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build scalable Analytic solutions.
 Neeraja Rentachintala is a Principal Product Manager with Amazon Redshift. Neeraja is a seasoned Product Management and GTM leader, bringing over 20 years of experience in product vision, strategy and leadership roles in data products and platforms. Neeraja delivered products in analytics, databases, data Integration, application integration, AI/Machine Learning, large scale distributed systems across On-Premise and Cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica and Expedia.com.
Neeraja Rentachintala is a Principal Product Manager with Amazon Redshift. Neeraja is a seasoned Product Management and GTM leader, bringing over 20 years of experience in product vision, strategy and leadership roles in data products and platforms. Neeraja delivered products in analytics, databases, data Integration, application integration, AI/Machine Learning, large scale distributed systems across On-Premise and Cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica and Expedia.com.
Jeetesh Srivastva is a Sr. Analytics specialist solutions architect at AWS. He specializes in Amazon Redshift and works with customers to implement scalable solutions leveraging Redshift and other AWS Analytic services. He has worked to deliver on premises and cloud based analytic solutions for customers in banking & finance and hospitality industry verticals.


































 Vaibhav Agrawal is an Analytics Specialist Solutions Architect at AWS. Throughout his career, he has focused on helping customers design and build well-architected analytics and decision support platforms.
Vaibhav Agrawal is an Analytics Specialist Solutions Architect at AWS. Throughout his career, he has focused on helping customers design and build well-architected analytics and decision support platforms. Jason Pedreza is an Analytics Specialist Solutions Architect at AWS with over 13 years of data warehousing experience. Prior to AWS, he built data warehouse solutions at Amazon.com. He specializes in Amazon Redshift and helps customers build scalable analytic solutions.
Jason Pedreza is an Analytics Specialist Solutions Architect at AWS with over 13 years of data warehousing experience. Prior to AWS, he built data warehouse solutions at Amazon.com. He specializes in Amazon Redshift and helps customers build scalable analytic solutions. Rajesh Francis is a Senior Analytics Customer Experience Specialist at AWS. He specializes in Amazon Redshift and focuses on helping to drive AWS market and technical strategy for data warehousing and analytics services. Rajesh works closely with large strategic customers to help them adopt our new services and features, develop long-term partnerships, and feed customer requirements back to our product development teams to guide our product roadmap.
Rajesh Francis is a Senior Analytics Customer Experience Specialist at AWS. He specializes in Amazon Redshift and focuses on helping to drive AWS market and technical strategy for data warehousing and analytics services. Rajesh works closely with large strategic customers to help them adopt our new services and features, develop long-term partnerships, and feed customer requirements back to our product development teams to guide our product roadmap.




























 Neeraja Rentachintala is a Principal Product Manager with Amazon Redshift. Neeraja is a seasoned Product Management and GTM leader, bringing over 20 years of experience in product vision, strategy and leadership roles in data products and platforms. Neeraja delivered products in analytics, databases, data Integration, application integration, AI/Machine Learning, large scale distributed systems across On-Premise and Cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica and Expedia.com.
Neeraja Rentachintala is a Principal Product Manager with Amazon Redshift. Neeraja is a seasoned Product Management and GTM leader, bringing over 20 years of experience in product vision, strategy and leadership roles in data products and platforms. Neeraja delivered products in analytics, databases, data Integration, application integration, AI/Machine Learning, large scale distributed systems across On-Premise and Cloud, serving Fortune 500 companies as part of ventures including MapR (acquired by HPE), Microsoft SQL Server, Oracle, Informatica and Expedia.com. Jeetesh Srivastva is a Sr. Analytics specialist solutions architect at AWS. He specializes in Amazon Redshift and works with customers to implement scalable solutions leveraging Redshift and other AWS Analytic services. He has worked to deliver on premises and cloud based analytic solutions for customers in banking & finance and hospitality industry verticals.
Jeetesh Srivastva is a Sr. Analytics specialist solutions architect at AWS. He specializes in Amazon Redshift and works with customers to implement scalable solutions leveraging Redshift and other AWS Analytic services. He has worked to deliver on premises and cloud based analytic solutions for customers in banking & finance and hospitality industry verticals.


























 Rajesh Francis is a Sr. Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build scalable Analytic solutions.
Rajesh Francis is a Sr. Analytics Specialist Solutions Architect at AWS. He specializes in Amazon Redshift and works with customers to build scalable Analytic solutions.