Post Syndicated from Dorothy Li original https://aws.amazon.com/blogs/big-data/bringing-the-power-of-embedded-analytics-to-your-apps-and-services-with-amazon-quicksight/
In the world we live in today, companies need to quickly react to change—and to anticipate it. Customers tell us that their reliance on data has never been greater than what it is today. To improve your decision-making, you have two types of data transformation needs: data agility, the speed at which data turns into insights, and data transparency, the need to present insights to decision makers. Going forward, we expect data transformation projects to become a centerpiece in every organization, big or small.
Furthermore, applications are migrating to the cloud faster than ever. Applications need to scale quickly to potentially millions of users, have global availability, manage petabytes of data, and respond in milliseconds. Such modern applications are built with a combination of these new architecture patterns, operational models, and software delivery processes, and allow businesses to innovate faster while reducing risk, time-to-market, and total cost of ownership.
An emerging area from these two trends is to combine the power of application modernization with data transformation. This emerging trend is often called embedded analytics, and is the focus of this post.
The case for embedded analytics
Applications generate a high volume of structured and unstructured data. This could be clickstream data, sales data, data from IoT devices, social data, and more. Customers who are building these applications (such as software-as-a-service (SaaS) apps or enterprise portals) often tell us that their end-users find it challenging to derive meaning from this data because traditional business intelligence (BI) approaches don’t always work.
Traditional BI tools live in disparate systems and require data engineering teams to provide connectivity and continous integration with the application, adding to complexity and delays in the overall process. Even after the connectivity is built, you must switch back and forth between your application and the BI tool, causing frustration and decreasing the overall pace of decision-making. Customers tell us that their development teams are constantly looking for new ways to delight their users, and embedding the BI capability directly into their applications is one of the most requested asks from their end-users.
Given the strategic importance of this capability, you can use this to differentiate and up-sell as a new service in their applications. Gartner research demonstrates that 63% of CEOs expect to adopt a product-as-a-service model in the next two years, making this a major market opportunity. For example, if you provide financial services software, you can empower users to perform detailed analysis of portfolio performance trends. An HR solution might enable managers to visualize and predict turnover rates. A supply chain management solution could embed the ability to slice and dice KPIs and better understand the efficiency of logistics routes.
Comparing common approaches to embedded analytics
The approach to building an embedded analytics capability needs to deliver on the requirements of modern applications. It must be scalable, handle large amounts of data without compromising agility, and seamlessly integrate with the application’s user experience. Choosing the right methodology becomes especially important in the face of these needs.
You can build your own embedded analytics solution, but although this gives you maximum control, it has a number of disadvantages. You have to hire specialized resources (such as data engineers for building data connectivity and UX developers for building dashboards) and maintain dedicated infrastructure to manage the data processing needs of the application. This can be expensive, resource-intensive, and complex to build.
Embedding traditional BI solutions that are available in the market has limitations as well, because they’re not purpose-built for embedding use cases. Most solutions are server-based, meaning that they’re challenging to scale and require additional infrastructure setup and ongoing maintenance. These solutions also have restrictive, pay-per-server pricing, which doesn’t fully meet the needs of end-users that are consuming applications or portals via a session-based usage model.
A new approach to embedded analytics
At AWS re:Invent 2019, we launched new capabilities in Amazon QuickSight that make it easy to embed analytics into your applications and portals, empowering your customers to gain deeper insights into your application’s data. Unlike building your own analytics solution, which can be time-consuming and hard to scale, QuickSight allows you to quickly embed interactive dashboards and visualizations into your applications without compromising on the ability to personalize the look and feel of these new features.
QuickSight has a serverless architecture that automatically scales your applications from a few to hundreds of thousands of users without the need to build, set up, and manage your own analytics infrastructure. These capabilities allow you to deliver embedded analytics at hyperscale. So, why does hyperscale matter? Traditional BI tools run on a fixed amount of hardware resources, therefore more users, more concurrency, or more complex queries impact performance across all users, which requires you to add more capacity (leading to higher costs).
The following diagram illustrates a traditional architecture, which requires additional servers (and higher upfront cost) to scale.
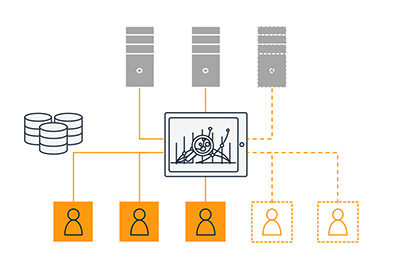
With QuickSight, you have access to the power and scale of the AWS Cloud. You get auto scaled, consistent performance no matter the concurrency or scale of the userbase, and a truly pay-per-use architecture, meaning you only pay when your users access the dashboards or reports. The following diagram illustrates how QuickSight scales seamlessly with its serverless architecture, powered by the AWS cloud.
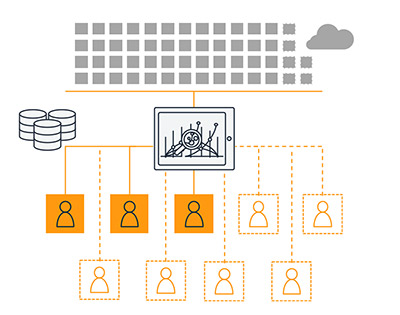
Furthermore, QuickSight enables your users to perform machine learning based insights such as anomaly detection, forecasting, and natural language queries. It also has a rich set of APIs that allow you to programmatically manage your analytics workflows, such as moving dashboards across accounts, automating deployments, and managing access for users with single sign-on (SSO).
New features in QuickSight Embedded Analytics
We recently announced the launch of additional embedding capabilities that allow you to do even more with QuickSight embedded analytics. QuickSight now allows you to embed dashboard authoring within applications (such as SaaS applications and enterprise portals), allowing you to empower your end-users to create their own visualizations and reports.
These ad hoc data analysis and self-service data exploration capabilities mean you don’t have to repeatedly create custom dashboards based on requests from your end-users, and can provide end-users with even greater agility and transparency with their data. This capability helps create product differentiation and up-sell opportunities within customer applications.
With this launch, QuickSight also provides namespaces, a multi-tenant capability that allows you to easily maintain data isolation while supporting multiple workloads within the same QuickSight account. For example, if you’re an independent software vendor (ISV), you can now assign dedicated namespaces to different customers within the same QuickSight account. This allows you to securely manage multiple customer workloads as users (authors or readers) within one namespace, and they can only discover and share content with other users within the same namespace, without exposing any data to other parties.
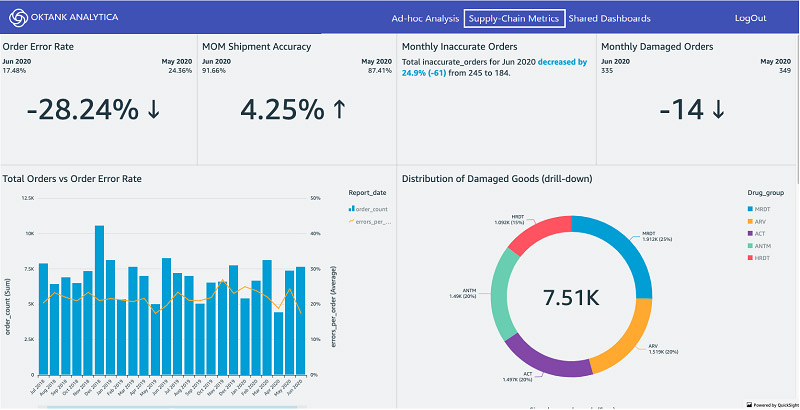
Without namespaces, you could set up your own embedded dashboards for hundreds of thousands of users with QuickSight. For example, see the following dashboard for our fictional company, Oktank Analytica.
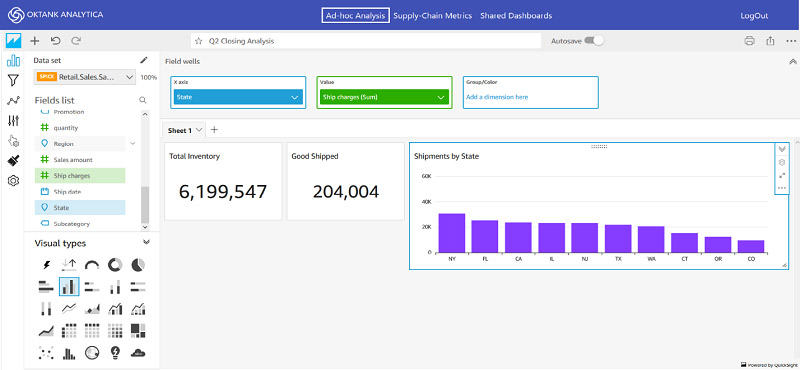
With namespaces in place, you can extend this to provide ad-hoc authoring capabilities using curated datasets specific to each customer, created and shared by the developer or ISV. See the following screenshot.
For more information about these new features, see Embed multi-tenant analytics in applications with Amazon QuickSight.
Customer success stories
Customers are already using embedded analytics in QuickSight to great success. In this section, we share the stories of a few customers.
Blackboard
Blackboard is a leading EdTech company, serving higher education, K-12, business, and government clients around the world.
“The recent wave in digital transformation in the global education community has made it clear that it’s time for a similar transformation in the education analytics tools that support that community,” says Rachel Scherer, Sr. Director of Data & Analytics at Blackboard. “We see a need to support learners, teachers, and leaders in education by helping to change their relationship with data and information—to reduce the distance between information and experience, between ‘informed’ and ‘acting.’
“A large part of this strategy involves embedding information directly where our users are collaborating, teaching, and learning—providing tools and insights that aid in assessment, draw attention to opportunities learners may be missing, and help strategic and academic leadership identify patterns and opportunities for intervention. We’re particularly interested in making the experience of being informed much more intuitive—favoring insight-informed workflows and/or embedded prose over traditional visualizations that require interpretation.
“By removing the step of interpretation, embedded visualizations make insights more useful and actionable. With QuickSight, we were able to deliver on our promise of embedding visualizations quickly, supporting the rapid iteration that we require, at the large scale needed to support our global user community.”
For more information about Blackboard’s QuickSight use case, see the AWS Online Tech Talk Embedding Analytics in your Applications with Amazon QuickSight at the 25:50 mark.
Comcast
Syndication Insights (SI) enables Comcast’s syndicated partners to access the same level of rich data insights that Comcast uses for platform and operational improvements.
“The SI platform enables partners to gain deeper business insights, such as early detection into anomalies for users, while ensuring a seamless experience through embedded, interactive reports,” says Ajay Gavagal, Sr. Manager of Software Development at Comcast. “From the start, scalability was a core requirement for us. We chose QuickSight as it is scalable, enabling SI to extend to multiple syndicated partners without having to provision or manage additional infrastructure. Furthermore, QuickSight provides interactive dashboards that can be easily embedded into an application. Lastly, QuickSight’s rich APIs abstract away a lot of functionality that would otherwise need to be custom built.”
For more information about how Comcast uses QuickSight, see the AWS Online Tech Talk Embedding Analytics in your Applications with Amazon QuickSight at the 38:05 mark.
Panasonic Avionics Corporation
Panasonic Avionics Corporation provides customized in-flight entertainment and communications systems to more than 300 airlines worldwide.
“Our cloud-based solutions collect large amounts of anonymized data that help us optimize the experience for both our airline partners and their passengers,” says Anand Desikan, Director of Cloud Operations at Panasonic Avionics Corporation. “We started using Amazon QuickSight to report on in-flight Wi-Fi performance, and with its rich APIs, pay-per-session pricing, and ability to scale, we quickly rolled out QuickSight dashboards to hundreds of users. The constant evolution of the platform has been impressive: ML-powered anomaly detection, Amazon SageMaker integration, embedding, theming, and cross-visual filtering. Our users consume insights via natural language narratives, which allows them to read all their information right off the dashboard with no complex interpretation needed.”
EHE Health
EHE Health is national preventive health and primary care Center of Excellence provider system.
“As a 106-year-old organization moving toward greater agility and marketplace nimbleness, we needed to drastically upgrade our ability to be transparent within our internal and external ecosystems,” says David Buza, Chief Technology Officer at EHE Health. “With QuickSight, we are not constrained by pre-built BI reports, and can easily customize and track the right operational metrics, such as product utilization, market penetration, and available inventory to gain a holistic view of our business. These inputs help us to understand current performance and future opportunity so that we can provide greater partnership to our clients, while delivering on our brand promise of creating healthier employee populations.
“QuickSight allowed our teams to seamlessly communicate with our clients—all viewing the same information, simultaneously. QuickSight’s embedding capabilities, along with its secure platform, intuitive design, and flexibility, allowed us to service all stakeholders—both internally and externally. This greater flexibility and customization allowed us to fit the client’s needs seamlessly.”
Conclusion
Where data agility and transparency are critical to business success, embedded analytics can open a universe of possibilities, and we are excited to see what our customers will do with these new capabilities.
Additional resources
For more resources, see the following:
- Amazon QuickSight Embedded Analytics Demo (Video)
- Amazon QuickSight Gallery (Embedded samples)
- Embedding the Full Functionality of the Amazon QuickSight Console (Documentation)
- Supporting Multitenancy with Isolated Namespaces (Documentation)
- Customizing Access to the Amazon QuickSight Console (Documentation)
- Embed Amazon QuickSight (Hands-on tutorial)
- Tools to Build on AWS (AWS SDK)
- Amazon QuickSight Embedding SDK (JavaScript SDK)
About the Author
 Dorothy Li is the Vice President and General Manager for Amazon QuickSight.
Dorothy Li is the Vice President and General Manager for Amazon QuickSight.
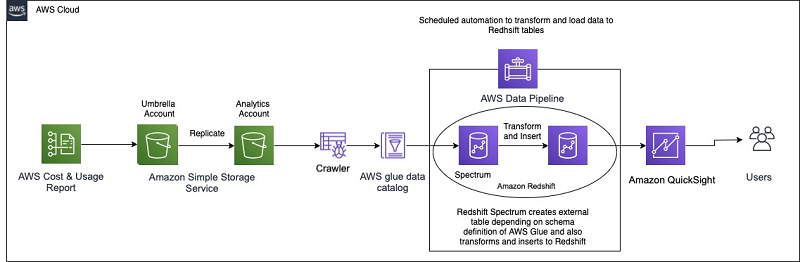
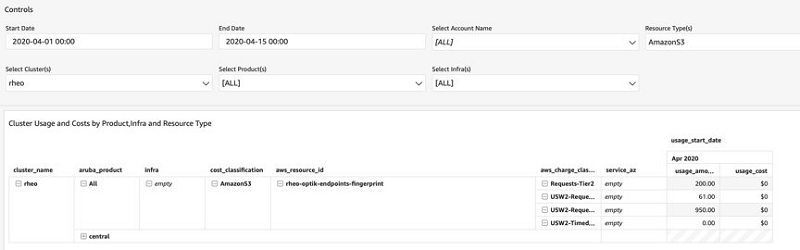


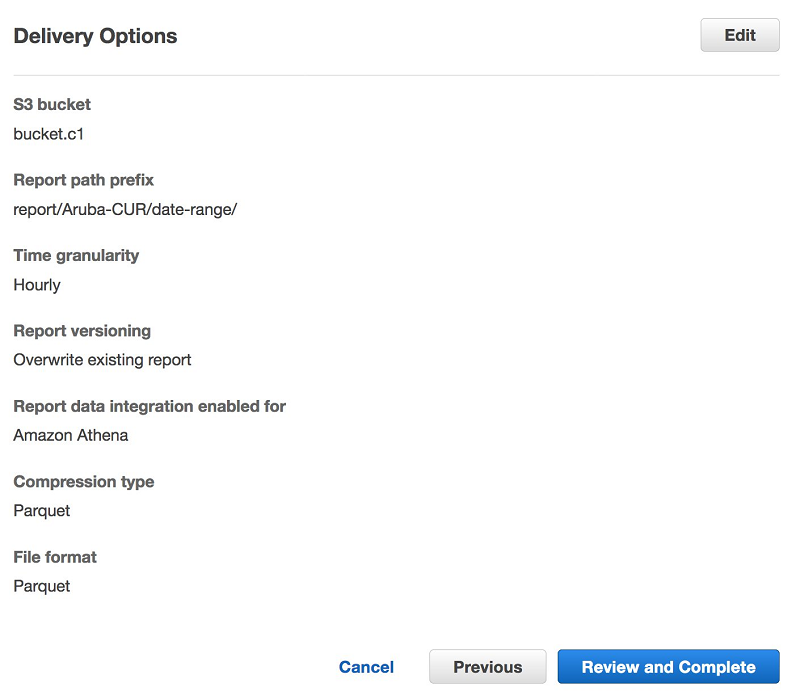



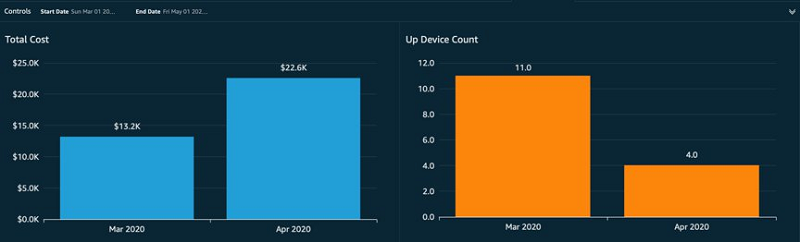


 Ritesh Chaman is a Technical Account Manager at Amazon Web Services. With 10 years of experience in the IT industry, Ritesh has a strong background in Data Analytics, Data Management, and Big Data systems. In his spare time, he loves cooking (spicy Indian food), watching sci-fi movies, and playing sports.
Ritesh Chaman is a Technical Account Manager at Amazon Web Services. With 10 years of experience in the IT industry, Ritesh has a strong background in Data Analytics, Data Management, and Big Data systems. In his spare time, he loves cooking (spicy Indian food), watching sci-fi movies, and playing sports. Kunal Ghosh is a Solutions Architect at AWS. His passion is to build efficient and effective solutions on the cloud, especially involving Analytics, AI, Data Science, and Machine Learning. Besides family time, he likes reading and watching movies, and is a foodie.
Kunal Ghosh is a Solutions Architect at AWS. His passion is to build efficient and effective solutions on the cloud, especially involving Analytics, AI, Data Science, and Machine Learning. Besides family time, he likes reading and watching movies, and is a foodie.











 Ginni Malik is an Associate Cloud Developer with AWS.
Ginni Malik is an Associate Cloud Developer with AWS. Rohan Jamadagni is a Solutions Architect with AWS.
Rohan Jamadagni is a Solutions Architect with AWS.