Post Syndicated from Ritesh Sinha original https://aws.amazon.com/blogs/big-data/automate-data-loading-from-your-database-into-amazon-redshift-using-aws-database-migration-service-dms-aws-step-functions-and-the-redshift-data-api/
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing ETL (extract, transform, and load), business intelligence (BI), and reporting tools. Tens of thousands of customers use Amazon Redshift to process exabytes of data per day and power analytics workloads such as BI, predictive analytics, and real-time streaming analytics.
As more and more data is being generated, collected, processed, and stored in many different systems, making the data available for end-users at the right place and right time is a very important aspect for data warehouse implementation. A fully automated and highly scalable ETL process helps minimize the operational effort that you must invest in managing the regular ETL pipelines. It also provides timely refreshes of data in your data warehouse.
You can approach the data integration process in two ways:
- Full load – This method involves completely reloading all the data within a specific data warehouse table or dataset
- Incremental load – This method focuses on updating or adding only the changed or new data to the existing dataset in a data warehouse
This post discusses how to automate ingestion of source data that changes completely and has no way to track the changes. This is useful for customers who want to use this data in Amazon Redshift; some examples of such data are products and bills of materials without tracking details at the source.
We show how to build an automatic extract and load process from various relational database systems into a data warehouse for full load only. A full load is performed from SQL Server to Amazon Redshift using AWS Database Migration Service (AWS DMS). When Amazon EventBridge receives a full load completion notification from AWS DMS, ETL processes are run on Amazon Redshift to process data. AWS Step Functions is used to orchestrate this ETL pipeline. Alternatively, you could use Amazon Managed Workflows for Apache Airflow (Amazon MWAA), a managed orchestration service for Apache Airflow that makes it straightforward to set up and operate end-to-end data pipelines in the cloud.
Solution overview
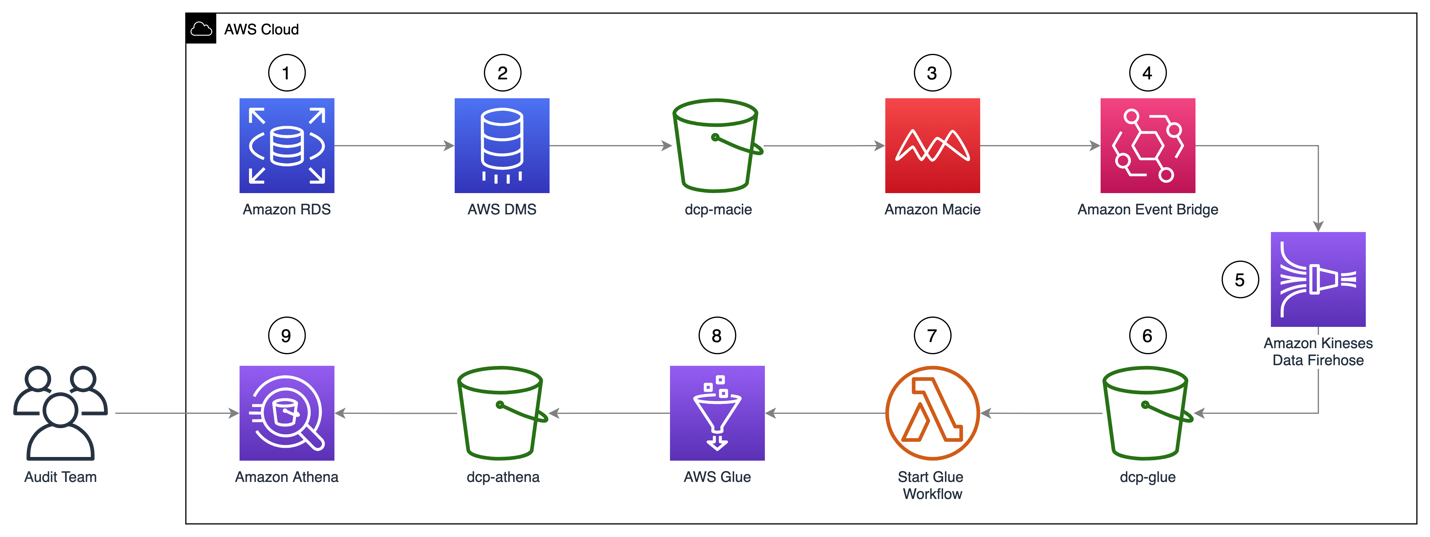
The workflow consists of the following steps:
- The solution uses an AWS DMS migration task that replicates the full load dataset from the configured SQL Server source to a target Redshift cluster in a staging area.
- AWS DMS publishes the replicationtaskstopped event to EventBridge when the replication task is complete, which invokes an EventBridge rule.
- EventBridge routes the event to a Step Functions state machine.
- The state machine calls a Redshift stored procedure through the Redshift Data API, which loads the dataset from the staging area to the target production tables. With this API, you can also access Redshift data with web-based service applications, including AWS Lambda.
The following architecture diagram highlights the end-to-end solution using AWS services.

In the following sections, we demonstrate how to create the full load AWS DMS task, configure the ETL orchestration on Amazon Redshift, create the EventBridge rule, and test the solution.
Prerequisites
To complete this walkthrough, you must have the following prerequisites:
- An AWS account
- A SQL Server database configured as a replication source for AWS DMS
- A Redshift cluster to serve as the target database
- An AWS DMS replication instance to migrate data from source to target
- A source endpoint pointing to the SQL Server database
- A target endpoint pointing to the Redshift cluster
Create the full load AWS DMS task
Complete the following steps to set up your migration task:
- On the AWS DMS console, choose Database migration tasks in the navigation pane.
- Choose Create task.
- For Task identifier, enter a name for your task, such as dms-full-dump-task.
- Choose your replication instance.
- Choose your source endpoint.
- Choose your target endpoint.
- For Migration type, choose Migrate existing data.

- In the Table mapping section, under Selection rules, choose Add new selection rule
- For Schema, choose Enter a schema.
- For Schema name, enter a name (for example,
dms_sample). - Keep the remaining settings as default and choose Create task.

The following screenshot shows your completed task on the AWS DMS console.

Create Redshift tables
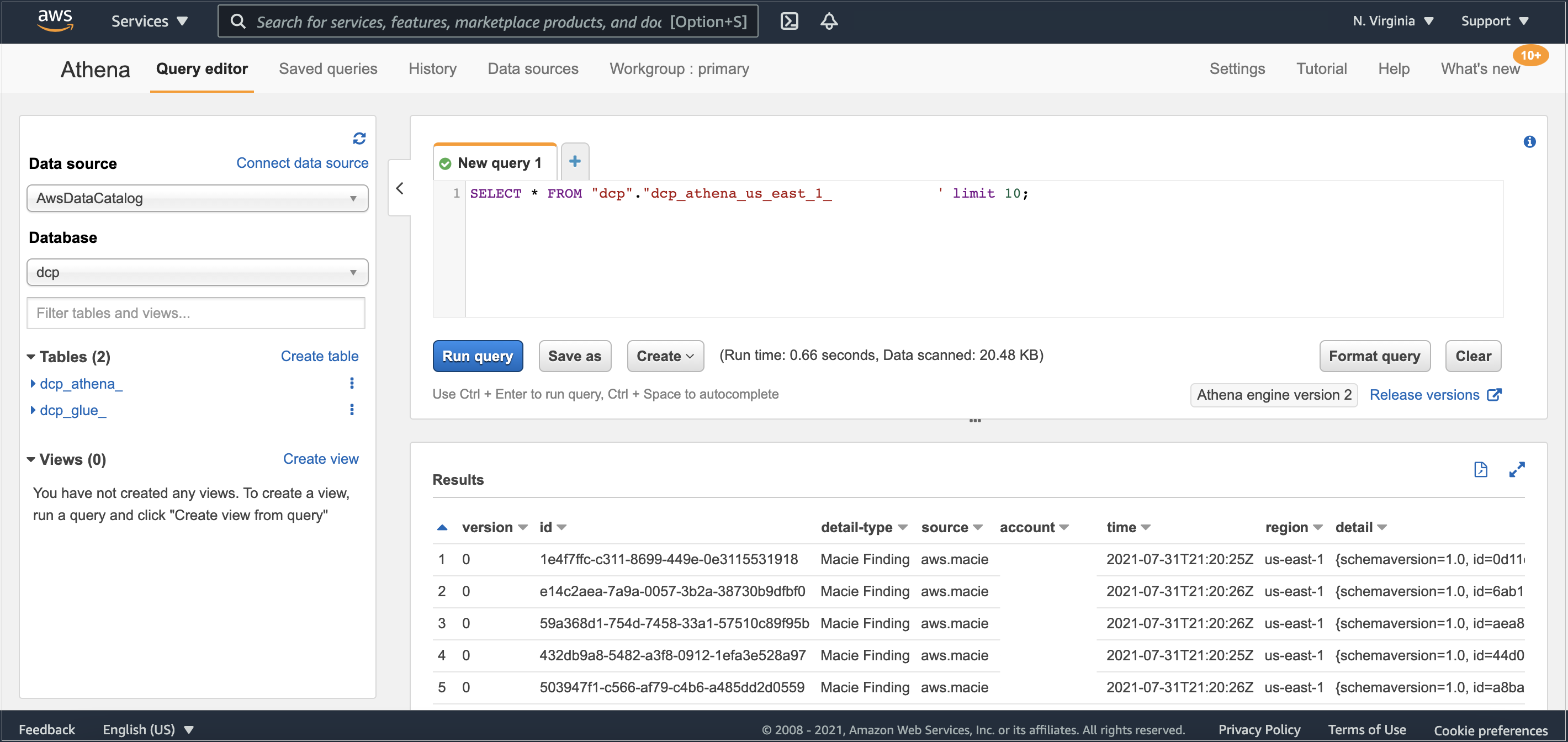
Create the following tables on the Redshift cluster using the Redshift query editor:
- dbo.dim_cust – Stores customer attributes:
- dbo.fact_sales – Stores customer sales transactions:
- dbo.fact_sales_stg – Stores daily customer incremental sales transactions:
Use the following INSERT statements to load sample data into the sales staging table:
Create the stored procedures
In the Redshift query editor, create the following stored procedures to process customer and sales transaction data:
- Sp_load_cust_dim() – This procedure compares the customer dimension with incremental customer data in staging and populates the customer dimension:
- sp_load_fact_sales() – This procedure does the transformation for incremental order data by joining with the date dimension and customer dimension and populates the primary keys from the respective dimension tables in the final sales fact table:
Create the Step Functions state machine
Complete the following steps to create the state machine redshift-elt-load-customer-sales. This state machine is invoked as soon as the AWS DMS full load task for the customer table is complete.
- On the Step Functions console, choose State machines in the navigation pane.
- Choose Create state machine.
- For Template, choose Blank.
- On the Actions dropdown menu, choose Import definition to import the workflow definition of the state machine.

- Open your preferred text editor and save the following code as an ASL file extension (for example,
redshift-elt-load-customer-sales.ASL). Provide your Redshift cluster ID and the secret ARN for your Redshift cluster.
- Choose Choose file and upload the ASL file to create a new state machine.

- For State machine name, enter a name for the state machine (for example,
redshift-elt-load-customer-sales). - Choose Create.

After the successful creation of the state machine, you can verify the details as shown in the following screenshot.

The following diagram illustrates the state machine workflow.

The state machine includes the following steps:
- Load_Customer_Dim – Performs the following actions:
- Passes the stored procedure
sp_load_cust_dimto the execute-statement API to run in the Redshift cluster to load the incremental data for the customer dimension - Sends data back the identifier of the SQL statement to the state machine
- Passes the stored procedure
- Wait_on_Load_Customer_Dim – Waits for at least 15 seconds
- Check_Status_Load_Customer_Dim – Invokes the Data API’s
describeStatementto get the status of the API call - is_run_Load_Customer_Dim_complete – Routes the next step of the ETL workflow depending on its status:
- FINISHED – Passes the stored procedure
Load_Sales_Factto the execute-statement API to run in the Redshift cluster, which loads the incremental data for fact sales and populates the corresponding keys from the customer and date dimensions - All other statuses – Goes back to the
wait_on_load_customer_dimstep to wait for the SQL statements to finish
- FINISHED – Passes the stored procedure
The state machine redshift-elt-load-customer-sales loads the dim_cust, fact_sales_stg, and fact_sales tables when invoked by the EventBridge rule.
As an optional step, you can set up event-based notifications on completion of the state machine to invoke any downstream actions, such as Amazon Simple Notification Service (Amazon SNS) or further ETL processes.
Create an EventBridge rule
EventBridge sends event notifications to the Step Functions state machine when the full load is complete. You can also turn event notifications on or off in EventBridge.
Complete the following steps to create the EventBridge rule:
- On the EventBridge console, in the navigation pane, choose Rules.
- Choose Create rule.
- For Name, enter a name (for example,
dms-test). - Optionally, enter a description for the rule.
- For Event bus, choose the event bus to associate with this rule. If you want this rule to match events that come from your account, select AWS default event bus. When an AWS service in your account emits an event, it always goes to your account’s default event bus.
- For Rule type, choose Rule with an event pattern.
- Choose Next.
- For Event source, choose AWS events or EventBridge partner events.
- For Method, select Use pattern form.
- For Event source, choose AWS services.
- For AWS service, choose Database Migration Service.
- For Event type, choose All Events.
- For Event pattern, enter the following JSON expression, which looks for the
REPLICATON_TASK_STOPPEDstatus for the AWS DMS task:

- For Target type, choose AWS service.
- For AWS service, choose Step Functions state machine.
- For State machine name, enter
redshift-elt-load-customer-sales. - Choose Create rule.
The following screenshot shows the details of the rule created for this post.

Test the solution
Run the task and wait for the workload to complete. This workflow moves the full volume data from the source database to the Redshift cluster.
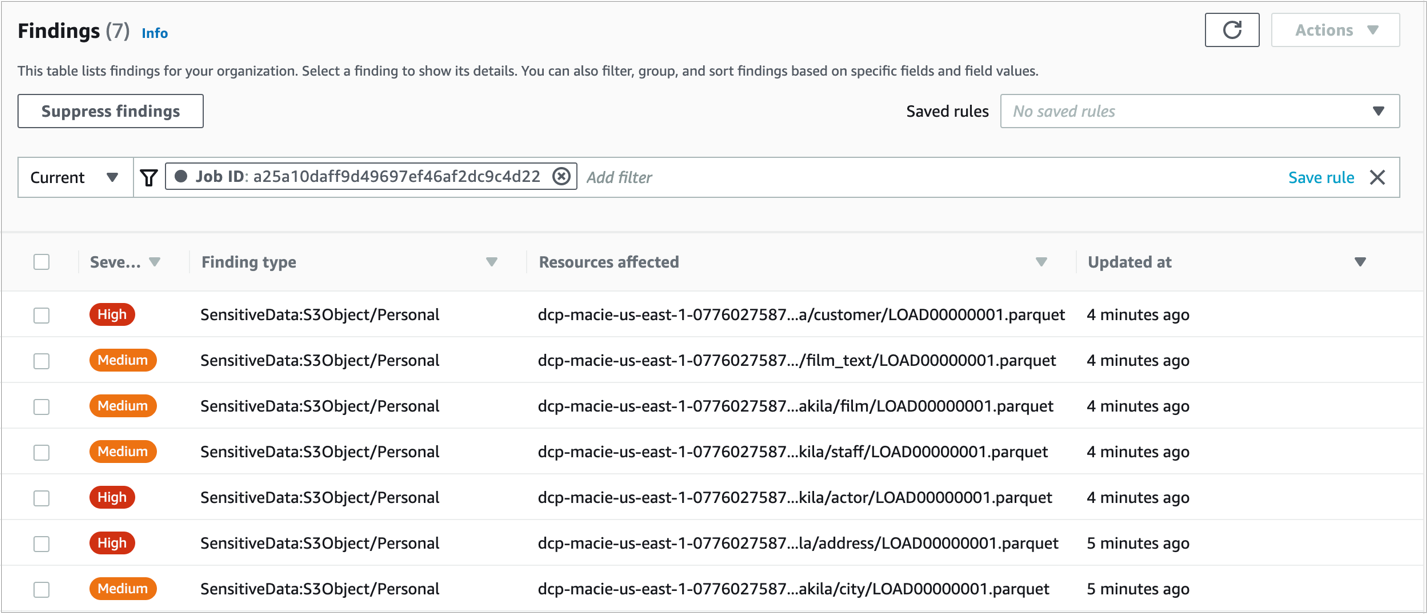
The following screenshot shows the load statistics for the customer table full load.

AWS DMS provides notifications when an AWS DMS event occurs, for example the completion of a full load or if a replication task has stopped.

After the full load is complete, AWS DMS sends events to the default event bus for your account. The following screenshot shows an example of invoking the target Step Functions state machine using the rule you created.

We configured the Step Functions state machine as a target in EventBridge. This enables EventBridge to invoke the Step Functions workflow in response to the completion of an AWS DMS full load task.

Validate the state machine orchestration
When the entire customer sales data pipeline is complete, you may go through the entire event history for the Step Functions state machine, as shown in the following screenshots.


Limitations
The Data API and Step Functions AWS SDK integration offers a robust mechanism to build highly distributed ETL applications within minimal developer overhead. Consider the following limitations when using the Data API and Step Functions:
Clean up
To avoid incurring future charges, delete the Redshift cluster, AWS DMS full load task, AWS DMS replication instance, and Step Functions state machine that you created as part of this post.
Conclusion
In this post, we demonstrated how to build an ETL orchestration for full loads from operational data stores using the Redshift Data API, EventBridge, Step Functions with AWS SDK integration, and Redshift stored procedures.
To learn more about the Data API, see Using the Amazon Redshift Data API to interact with Amazon Redshift clusters and Using the Amazon Redshift Data API.
About the authors
 Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga.
Ritesh Kumar Sinha is an Analytics Specialist Solutions Architect based out of San Francisco. He has helped customers build scalable data warehousing and big data solutions for over 16 years. He loves to design and build efficient end-to-end solutions on AWS. In his spare time, he loves reading, walking, and doing yoga.
 Praveen Kadipikonda is a Senior Analytics Specialist Solutions Architect at AWS based out of Dallas. He helps customers build efficient, performant, and scalable analytic solutions. He has worked with building databases and data warehouse solutions for over 15 years.
Praveen Kadipikonda is a Senior Analytics Specialist Solutions Architect at AWS based out of Dallas. He helps customers build efficient, performant, and scalable analytic solutions. He has worked with building databases and data warehouse solutions for over 15 years.
 Jagadish Kumar (Jag) is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He is deeply passionate about Data Architecture and helps customers build analytics solutions at scale on AWS.
Jagadish Kumar (Jag) is a Senior Specialist Solutions Architect at AWS focused on Amazon OpenSearch Service. He is deeply passionate about Data Architecture and helps customers build analytics solutions at scale on AWS.