Post Syndicated from Jakub Sitnicki original https://blog.cloudflare.com/assembly-within-bpf-tail-calls-on-x86-and-arm/
Early on when we learn to program, we get introduced to the concept of recursion. And that it is handy for computing, among other things, sequences defined in terms of recurrences. Such as the famous Fibonnaci numbers – Fn = Fn-1 + Fn-2.
Later on, perhaps when diving into multithreaded programming, we come to terms with the fact that the stack space for call frames is finite. And that there is an “okay” way and a “cool” way to calculate the Fibonacci numbers using recursion:
// fib_okay.c
#include <stdint.h>
uint64_t fib(uint64_t n)
{
if (n == 0 || n == 1)
return 1;
return fib(n - 1) + fib(n - 2);
}
Listing 1. An okay Fibonacci number generator implementation
// fib_cool.c
#include <stdint.h>
static uint64_t fib_tail(uint64_t n, uint64_t a, uint64_t b)
{
if (n == 0)
return a;
if (n == 1)
return b;
return fib_tail(n - 1, b, a + b);
}
uint64_t fib(uint64_t n)
{
return fib_tail(n, 1, 1);
}
Listing 2. A better version of the same
If we take a look at the machine code the compiler produces, the “cool” variant translates to a nice and tight sequence of instructions:
⚠ DISCLAIMER: This blog post is assembly-heavy. We will be looking at assembly code for x86-64, arm64 and BPF architectures. If you need an introduction or a refresher, I can recommend “Low-Level Programming” by Igor Zhirkov for x86-64, and “Programming with 64-Bit ARM Assembly Language” by Stephen Smith for arm64. For BPF, see the Linux kernel documentation.
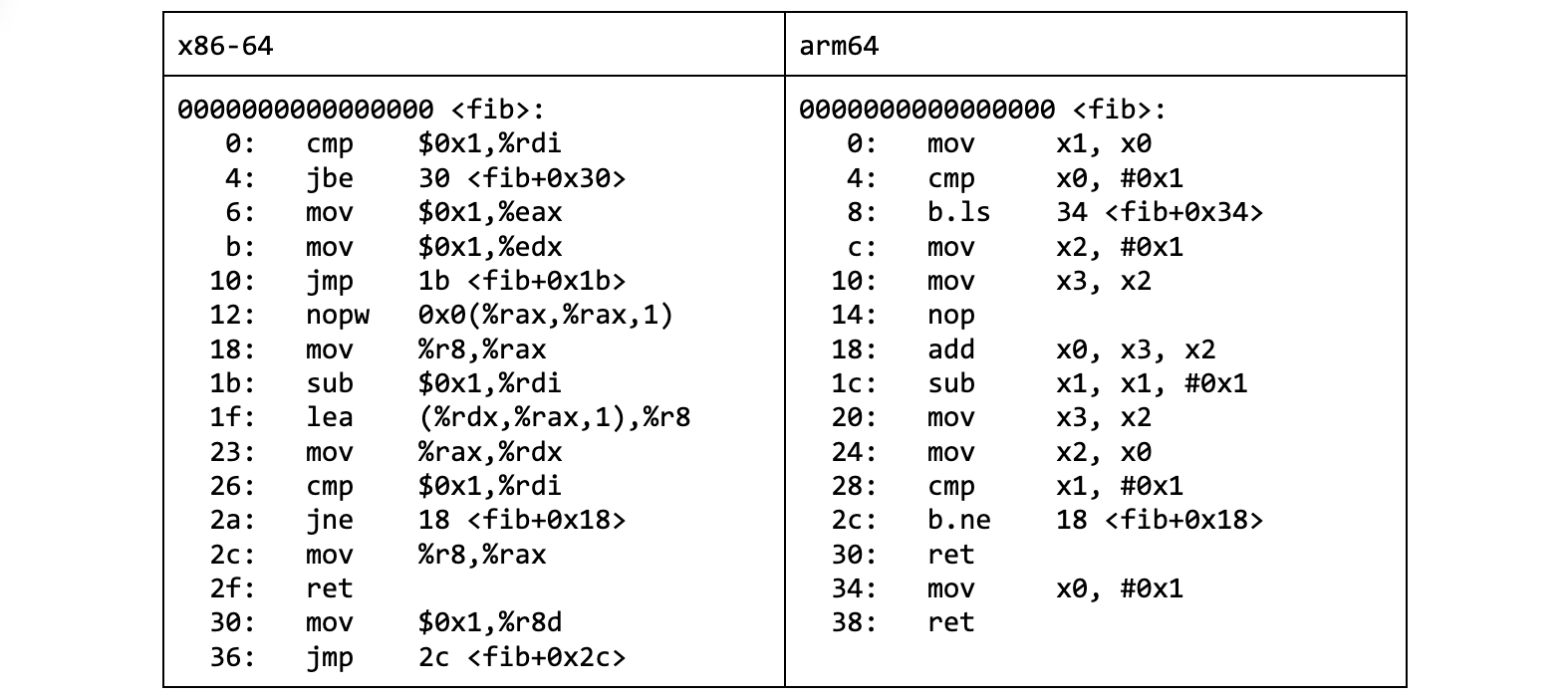
Listing 3. fib_cool.c compiled for x86-64 and arm64
The “okay” variant, disappointingly, leads to more instructions than a listing can fit. It is a spaghetti of basic blocks.

But more importantly, it is not free of x86 call instructions.
$ objdump -d fib_okay.o | grep call
10c: e8 00 00 00 00 call 111 <fib+0x111>
$ objdump -d fib_cool.o | grep call
$
This has an important consequence – as fib recursively calls itself, the stacks keep growing. We can observe it with a bit of help from the debugger.
$ gdb --quiet --batch --command=trace_rsp.gdb --args ./fib_okay 6
Breakpoint 1 at 0x401188: file fib_okay.c, line 3.
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
n = 6, %rsp = 0xffffd920
n = 5, %rsp = 0xffffd900
n = 4, %rsp = 0xffffd8e0
n = 3, %rsp = 0xffffd8c0
n = 2, %rsp = 0xffffd8a0
n = 1, %rsp = 0xffffd880
n = 1, %rsp = 0xffffd8c0
n = 2, %rsp = 0xffffd8e0
n = 1, %rsp = 0xffffd8c0
n = 3, %rsp = 0xffffd900
n = 2, %rsp = 0xffffd8e0
n = 1, %rsp = 0xffffd8c0
n = 1, %rsp = 0xffffd900
13
[Inferior 1 (process 50904) exited normally]
$
While the “cool” variant makes no use of the stack.
$ gdb --quiet --batch --command=trace_rsp.gdb --args ./fib_cool 6
Breakpoint 1 at 0x40118a: file fib_cool.c, line 13.
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib64/libthread_db.so.1".
n = 6, %rsp = 0xffffd938
13
[Inferior 1 (process 50949) exited normally]
$
Where did the calls go?
The smart compiler turned the last function call in the body into a regular jump. Why was it allowed to do that?
It is the last instruction in the function body we are talking about. The caller stack frame is going to be destroyed right after we return anyway. So why keep it around when we can reuse it for the callee’s stack frame?
This optimization, known as tail call elimination, leaves us with no function calls in the “cool” variant of our fib implementation. There was only one call to eliminate – right at the end.
Once applied, the call becomes a jump (loop). If assembly is not your second language, decompiling the fib_cool.o object file with Ghidra helps see the transformation:
long fib(ulong param_1)
{
long lVar1;
long lVar2;
long lVar3;
if (param_1 < 2) {
lVar3 = 1;
}
else {
lVar3 = 1;
lVar2 = 1;
do {
lVar1 = lVar3;
param_1 = param_1 - 1;
lVar3 = lVar2 + lVar1;
lVar2 = lVar1;
} while (param_1 != 1);
}
return lVar3;
}
Listing 4. fib_cool.o decompiled by Ghidra
This is very much desired. Not only is the generated machine code much shorter. It is also way faster due to lack of calls, which pop up on the profile for fib_okay.
But I am no performance ninja and this blog post is not about compiler optimizations. So why am I telling you about it?

{kind=link}
Tail calls in BPF
The concept of tail call elimination made its way into the BPF world. Although not in the way you might expect. Yes, the LLVM compiler does get rid of the trailing function calls when building for -target bpf. The transformation happens at the intermediate representation level, so it is backend agnostic. This can save you some BPF-to-BPF function calls, which you can spot by looking for call -N instructions in the BPF assembly.
However, when we talk about tail calls in the BPF context, we usually have something else in mind. And that is a mechanism, built into the BPF JIT compiler, for chaining BPF programs.
We first adopted BPF tail calls when building our XDP-based packet processing pipeline. Thanks to it, we were able to divide the processing logic into several XDP programs. Each responsible for doing one thing.
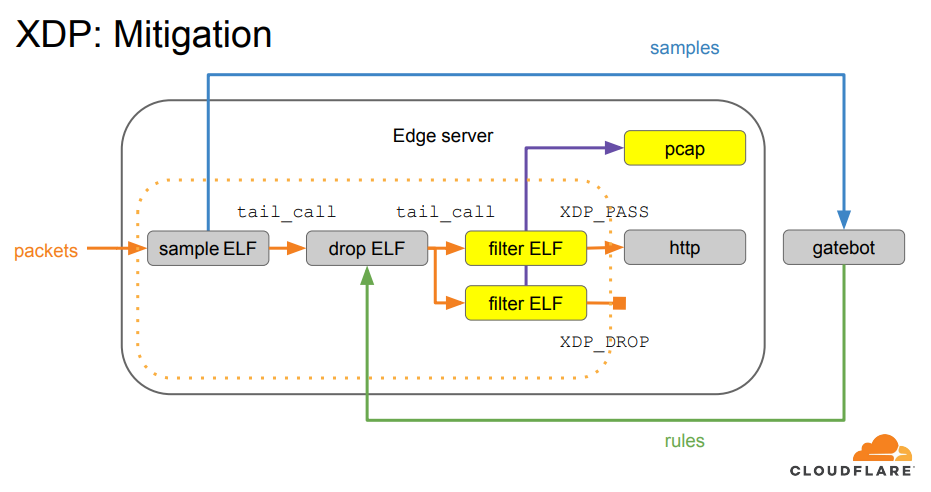
BPF tail calls have served us well since then. But they do have their caveats. Until recently it was impossible to have both BPF tails calls and BPF-to-BPF function calls in the same XDP program on arm64, which is one of the supported architectures for us.
Why? Before we get to that, we have to clarify what a BPF tail call actually does.
A tail call is a tail call is a tail call
BPF exposes the tail call mechanism through the bpf_tail_call helper, which we can invoke from our BPF code. We don’t directly point out which BPF program we would like to call. Instead, we pass it a BPF map (a container) capable of holding references to BPF programs (BPF_MAP_TYPE_PROG_ARRAY), and an index into the map.
long bpf_tail_call(void *ctx, struct bpf_map *prog_array_map, u32 index)
Description
This special helper is used to trigger a "tail call", or
in other words, to jump into another eBPF program. The
same stack frame is used (but values on stack and in reg‐
isters for the caller are not accessible to the callee).
This mechanism allows for program chaining, either for
raising the maximum number of available eBPF instructions,
or to execute given programs in conditional blocks. For
security reasons, there is an upper limit to the number of
successive tail calls that can be performed.
At first glance, this looks somewhat similar to the execve(2) syscall. It is easy to mistake it for a way to execute a new program from the current program context. To quote the excellent BPF and XDP Reference Guide from the Cilium project documentation:
Tail calls can be seen as a mechanism that allows one BPF program to call another, without returning to the old program. Such a call has minimal overhead as unlike function calls, it is implemented as a long jump, reusing the same stack frame.
But once we add BPF function calls into the mix, it becomes clear that the BPF tail call mechanism is indeed an implementation of tail call elimination, rather than a way to replace one program with another:
Tail calls, before the actual jump to the target program, will unwind only its current stack frame. As we can see in the example above, if a tail call occurs from within the sub-function, the function’s (func1) stack frame will be present on the stack when a program execution is at func2. Once the final function (func3) function terminates, all the previous stack frames will be unwinded and control will get back to the caller of BPF program caller.
Alas, one with sometimes slightly surprising semantics. Consider the code like below, where a BPF function calls the bpf_tail_call() helper:
struct {
__uint(type, BPF_MAP_TYPE_PROG_ARRAY);
__uint(max_entries, 1);
__uint(key_size, sizeof(__u32));
__uint(value_size, sizeof(__u32));
} bar SEC(".maps");
SEC("tc")
int serve_drink(struct __sk_buff *skb __unused)
{
return 0xcafe;
}
static __noinline
int bring_order(struct __sk_buff *skb)
{
bpf_tail_call(skb, &bar, 0);
return 0xf00d;
}
SEC("tc")
int server1(struct __sk_buff *skb)
{
return bring_order(skb);
}
SEC("tc")
int server2(struct __sk_buff *skb)
{
__attribute__((musttail)) return bring_order(skb);
}
We have two seemingly not so different BPF programs – server1() and server2(). They both call the same BPF function bring_order(). The function tail calls into the serve_drink() program, if the bar[0] map entry points to it (let’s assume that).
Do both server1 and server2 return the same value? Turns out that – no, they don’t. We get a hex 🍔 from server1, and a ☕ from server2. How so?
First thing to notice is that a BPF tail call unwinds just the current function stack frame. Code past the bpf_tail_call() invocation in the function body never executes, providing the tail call is successful (the map entry was set, and the tail call limit has not been reached).
When the tail call finishes, control returns to the caller of the function which made the tail call. Applying this to our example, the control flow is serverX() --> bring_order() --> bpf_tail_call() --> serve_drink() -return-> serverX() for both programs.
The second thing to keep in mind is that the compiler does not know that the bpf_tail_call() helper changes the control flow. Hence, the unsuspecting compiler optimizes the code as if the execution would continue past the BPF tail call.

server1() and server2() is the same, but the return value differs due to build time optimizations.In our case, the compiler thinks it is okay to propagate the constant which bring_order() returns to server1(). Possibly catching us by surprise, if we didn’t check the generated BPF assembly.
We can prevent it by forcing the compiler to make a tail call to bring_order(). This way we ensure that whatever bring_order() returns will be used as the server2() program result.
🛈 General rule – for least surprising results, use musttail attribute when calling a function that contain a BPF tail call.
How does the bpf_tail_call() work underneath then? And why the BPF verifier wouldn’t let us mix the function calls with tail calls on arm64? Time to dig deeper.

BPF tail call on x86-64
What does a bpf_tail_call() helper call translate to after BPF JIT for x86-64 has compiled it? How does the implementation guarantee that we don’t end up in a tail call loop forever?
To find out we will need to piece together a few things.
First, there is the BPF JIT compiler source code, which lives in arch/x86/net/bpf_jit_comp.c. Its code is annotated with helpful comments. We will focus our attention on the following call chain within the JIT:
do_jit() 🔗
emit_prologue() 🔗
push_callee_regs() 🔗
for (i = 1; i <= insn_cnt; i++, insn++) {
switch (insn->code) {
case BPF_JMP | BPF_CALL:
/* emit function call */ 🔗
case BPF_JMP | BPF_TAIL_CALL:
emit_bpf_tail_call_direct() 🔗
case BPF_JMP | BPF_EXIT:
/* emit epilogue */ 🔗
}
}
It is sometimes hard to visualize the generated instruction stream just from reading the compiler code. Hence, we will also want to inspect the input – BPF instructions – and the output – x86-64 instructions – of the JIT compiler.
To inspect BPF and x86-64 instructions of a loaded BPF program, we can use bpftool prog dump. However, first we must populate the BPF map used as the tail call jump table. Otherwise, we might not be able to see the tail call jump!
This is due to optimizations that use instruction patching when the index into the program array is known at load time.
# bpftool prog loadall ./tail_call_ex1.o /sys/fs/bpf pinmaps /sys/fs/bpf
# bpftool map update pinned /sys/fs/bpf/jmp_table key 0 0 0 0 value pinned /sys/fs/bpf/target_prog
# bpftool prog dump xlated pinned /sys/fs/bpf/entry_prog
int entry_prog(struct __sk_buff * skb):
; bpf_tail_call(skb, &jmp_table, 0);
0: (18) r2 = map[id:24]
2: (b7) r3 = 0
3: (85) call bpf_tail_call#12
; return 0xf00d;
4: (b7) r0 = 61453
5: (95) exit
# bpftool prog dump jited pinned /sys/fs/bpf/entry_prog
int entry_prog(struct __sk_buff * skb):
bpf_prog_4f697d723aa87765_entry_prog:
; bpf_tail_call(skb, &jmp_table, 0);
0: nopl 0x0(%rax,%rax,1)
5: xor %eax,%eax
7: push %rbp
8: mov %rsp,%rbp
b: push %rax
c: movabs $0xffff888102764800,%rsi
16: xor %edx,%edx
18: mov -0x4(%rbp),%eax
1e: cmp $0x21,%eax
21: jae 0x0000000000000037
23: add $0x1,%eax
26: mov %eax,-0x4(%rbp)
2c: nopl 0x0(%rax,%rax,1)
31: pop %rax
32: jmp 0xffffffffffffffe3 // bug? 🤔
; return 0xf00d;
37: mov $0xf00d,%eax
3c: leave
3d: ret
There is a caveat. The target addresses for tail call jumps in bpftool prog dump jited output will not make any sense. To discover the real jump targets, we have to peek into the kernel memory. That can be done with gdb after we find the address of our JIT’ed BPF programs in /proc/kallsyms:
# tail -2 /proc/kallsyms
ffffffffa0000720 t bpf_prog_f85b2547b00cbbe9_target_prog [bpf]
ffffffffa0000748 t bpf_prog_4f697d723aa87765_entry_prog [bpf]
# gdb -q -c /proc/kcore -ex 'x/18i 0xffffffffa0000748' -ex 'quit'
[New process 1]
Core was generated by `earlyprintk=serial,ttyS0,115200 console=ttyS0 psmouse.proto=exps "virtme_stty_c'.
#0 0x0000000000000000 in ?? ()
0xffffffffa0000748: nopl 0x0(%rax,%rax,1)
0xffffffffa000074d: xor %eax,%eax
0xffffffffa000074f: push %rbp
0xffffffffa0000750: mov %rsp,%rbp
0xffffffffa0000753: push %rax
0xffffffffa0000754: movabs $0xffff888102764800,%rsi
0xffffffffa000075e: xor %edx,%edx
0xffffffffa0000760: mov -0x4(%rbp),%eax
0xffffffffa0000766: cmp $0x21,%eax
0xffffffffa0000769: jae 0xffffffffa000077f
0xffffffffa000076b: add $0x1,%eax
0xffffffffa000076e: mov %eax,-0x4(%rbp)
0xffffffffa0000774: nopl 0x0(%rax,%rax,1)
0xffffffffa0000779: pop %rax
0xffffffffa000077a: jmp 0xffffffffa000072b
0xffffffffa000077f: mov $0xf00d,%eax
0xffffffffa0000784: leave
0xffffffffa0000785: ret
# gdb -q -c /proc/kcore -ex 'x/7i 0xffffffffa0000720' -ex 'quit'
[New process 1]
Core was generated by `earlyprintk=serial,ttyS0,115200 console=ttyS0 psmouse.proto=exps "virtme_stty_c'.
#0 0x0000000000000000 in ?? ()
0xffffffffa0000720: nopl 0x0(%rax,%rax,1)
0xffffffffa0000725: xchg %ax,%ax
0xffffffffa0000727: push %rbp
0xffffffffa0000728: mov %rsp,%rbp
0xffffffffa000072b: mov $0xcafe,%eax
0xffffffffa0000730: leave
0xffffffffa0000731: ret
#
Lastly, it will be handy to have a cheat sheet of mapping between BPF registers (r0, r1, …) to hardware registers (rax, rdi, …) that the JIT compiler uses.
| BPF | x86-64 |
|---|---|
| r0 | rax |
| r1 | rdi |
| r2 | rsi |
| r3 | rdx |
| r4 | rcx |
| r5 | r8 |
| r6 | rbx |
| r7 | r13 |
| r8 | r14 |
| r9 | r15 |
| r10 | rbp |
| internal | r9-r12 |
Now we are prepared to work out what happens when we use a BPF tail call.

In essence, bpf_tail_call() emits a jump into another function, reusing the current stack frame. It is just like a regular optimized tail call, but with a twist.
Because of the BPF security guarantees – execution terminates, no stack overflows – there is a limit on the number of tail calls we can have (MAX_TAIL_CALL_CNT = 33).
Counting the tail calls across BPF programs is not something we can do at load-time. The jump table (BPF program array) contents can change after the program has been verified. Our only option is to keep track of tail calls at run-time. That is why the JIT’ed code for the bpf_tail_call() helper checks and updates the tail_call_cnt counter.
The updated count is then passed from one BPF program to another, and from one BPF function to another, as we will see, through the rax register (r0 in BPF).
Luckily for us, the x86-64 calling convention dictates that the rax register does not partake in passing function arguments, but rather holds the function return value. The JIT can repurpose it to pass an additional – hidden – argument.
The function body is, however, free to make use of the r0/rax register in any way it pleases. This explains why we want to save the tail_call_cnt passed via rax onto stack right after we jump to another program. bpf_tail_call() can later load the value from a known location on the stack.
This way, the code emitted for each bpf_tail_call() invocation, and the BPF function prologue work in tandem, keeping track of tail call count across BPF program boundaries.
But what if our BPF program is split up into several BPF functions, each with its own stack frame? What if these functions perform BPF tail calls? How is the tail call count tracked then?
Mixing BPF function calls with BPF tail calls
BPF has its own terminology when it comes to functions and calling them, which is influenced by the internal implementation. Function calls are referred to as BPF to BPF calls. Also, the main/entry function in your BPF code is called “the program”, while all other functions are known as “subprograms”.
Each call to subprogram allocates a stack frame for local state, which persists until the function returns. Naturally, BPF subprogram calls can be nested creating a call chain. Just like nested function calls in user-space.
BPF subprograms are also allowed to make BPF tail calls. This, effectively, is a mechanism for extending the call chain to another BPF program and its subprograms.
If we cannot track how long the call chain can be, and how much stack space each function uses, we put ourselves at risk of overflowing the stack. We cannot let this happen, so BPF enforces limitations on when and how many BPF tail calls can be done:
static int check_max_stack_depth(struct bpf_verifier_env *env)
{
…
/* protect against potential stack overflow that might happen when
* bpf2bpf calls get combined with tailcalls. Limit the caller's stack
* depth for such case down to 256 so that the worst case scenario
* would result in 8k stack size (32 which is tailcall limit * 256 =
* 8k).
*
* To get the idea what might happen, see an example:
* func1 -> sub rsp, 128
* subfunc1 -> sub rsp, 256
* tailcall1 -> add rsp, 256
* func2 -> sub rsp, 192 (total stack size = 128 + 192 = 320)
* subfunc2 -> sub rsp, 64
* subfunc22 -> sub rsp, 128
* tailcall2 -> add rsp, 128
* func3 -> sub rsp, 32 (total stack size 128 + 192 + 64 + 32 = 416)
*
* tailcall will unwind the current stack frame but it will not get rid
* of caller's stack as shown on the example above.
*/
if (idx && subprog[idx].has_tail_call && depth >= 256) {
verbose(env,
"tail_calls are not allowed when call stack of previous frames is %d bytes. Too large\n",
depth);
return -EACCES;
}
…
}
While the stack depth can be calculated by the BPF verifier at load-time, we still need to keep count of tail call jumps at run-time. Even when subprograms are involved.
This means that we have to pass the tail call count from one BPF subprogram to another, just like we did when making a BPF tail call, so we yet again turn to value passing through the rax register.

🛈 To keep things simple, BPF code in our examples does not allocate anything on stack. I encourage you to check how the JIT’ed code changes when you add some local variables. Just make sure the compiler does not optimize them out.
To make it work, we need to:
① load the tail call count saved on stack into rax before call’ing the subprogram,
② adjust the subprogram prologue, so that it does not reset the rax like the main program does,
③ save the passed tail call count on subprogram’s stack for the bpf_tail_call() helper to consume it.
A bpf_tail_call() within our suprogram will then:
④ load the tail call count from stack,
⑤ unwind the BPF stack, but keep the current subprogram’s stack frame in tact, and
⑥ jump to the target BPF program.
Now we have seen how all the pieces of the puzzle fit together to make BPF tail work on x86-64 safely. The only open question is does it work the same way on other platforms like arm64? Time to shift gears and dive into a completely different BPF JIT implementation.

Tail calls on arm64
If you try loading a BPF program that uses both BPF function calls (aka BPF to BPF calls) and BPF tail calls on an arm64 machine running the latest 5.15 LTS kernel, or even the latest 5.19 stable kernel, the BPF verifier will kindly ask you to reconsider your choice:
# uname -rm
5.19.12 aarch64
# bpftool prog loadall tail_call_ex2.o /sys/fs/bpf
libbpf: prog 'entry_prog': BPF program load failed: Invalid argument
libbpf: prog 'entry_prog': -- BEGIN PROG LOAD LOG --
0: R1=ctx(off=0,imm=0) R10=fp0
; __attribute__((musttail)) return sub_func(skb);
0: (85) call pc+1
caller:
R10=fp0
callee:
frame1: R1=ctx(off=0,imm=0) R10=fp0
; bpf_tail_call(skb, &jmp_table, 0);
2: (18) r2 = 0xffffff80c38c7200 ; frame1: R2_w=map_ptr(off=0,ks=4,vs=4,imm=0)
4: (b7) r3 = 0 ; frame1: R3_w=P0
5: (85) call bpf_tail_call#12
tail_calls are not allowed in non-JITed programs with bpf-to-bpf calls
processed 4 insns (limit 1000000) max_states_per_insn 0 total_states 0 peak_states 0 mark_read 0
-- END PROG LOAD LOG --
…
#
That is a pity! We have been looking forward to reaping the benefits of code sharing with BPF to BPF calls in our lengthy machine generated BPF programs. So we asked – how hard could it be to make it work?
After all, BPF JIT for arm64 already can handle BPF tail calls and BPF to BPF calls, when used in isolation.
It is “just” a matter of understanding the existing JIT implementation, which lives in arch/arm64/net/bpf_jit_comp.c, and identifying the missing pieces.
To understand how BPF JIT for arm64 works, we will use the same method as before – look at its code together with sample input (BPF instructions) and output (arm64 instructions).
We don’t have to read the whole source code. It is enough to zero in on a few particular code paths:
bpf_int_jit_compile() 🔗
build_prologue() 🔗
build_body() 🔗
for (i = 0; i < prog->len; i++) {
build_insn() 🔗
switch (code) {
case BPF_JMP | BPF_CALL:
/* emit function call */ 🔗
case BPF_JMP | BPF_TAIL_CALL:
emit_bpf_tail_call() 🔗
}
}
build_epilogue() 🔗
One thing that the arm64 architecture, and RISC architectures in general, are known for is that it has a plethora of general purpose registers (x0-x30). This is a good thing. We have more registers to allocate to JIT internal state, like the tail call count. A cheat sheet of what roles the hardware registers play in the BPF JIT will be helpful:
| BPF | arm64 |
|---|---|
| r0 | x7 |
| r1 | x0 |
| r2 | x1 |
| r3 | x2 |
| r4 | x3 |
| r5 | x4 |
| r6 | x19 |
| r7 | x20 |
| r8 | x21 |
| r9 | x22 |
| r10 | x25 |
| internal | x9-x12, x26 (tail_call_cnt), x27 |
Now let’s try to understand the state of things by looking at the JIT’s input and output for two particular scenarios: (1) a BPF tail call, and (2) a BPF to BPF call.
It is hard to read assembly code selectively. We will have to go through all instructions one by one, and understand what each one is doing.
⚠ Brace yourself. Time to decipher a bit of ARM64 assembly. If this will be your first time reading ARM64 assembly, you might want to at least skim through this Guide to ARM64 / AArch64 Assembly on Linux before diving in.
Scenario #1: A single BPF tail call – tail_call_ex1.bpf.c
Input: BPF assembly (bpftool prog dump xlated)
0: (18) r2 = map[id:4] // jmp_table map
2: (b7) r3 = 0
3: (85) call bpf_tail_call#12
4: (b7) r0 = 61453 // 0xf00d
5: (95) exit
Output: ARM64 assembly (bpftool prog dump jited)
0: paciasp // Sign LR (ROP protection) ①
4: stp x29, x30, [sp, #-16]! // Save FP and LR registers ②
8: mov x29, sp // Set up Frame Pointer
c: stp x19, x20, [sp, #-16]! // Save callee-saved registers ③
10: stp x21, x22, [sp, #-16]! // ⋮
14: stp x25, x26, [sp, #-16]! // ⋮
18: stp x27, x28, [sp, #-16]! // ⋮
1c: mov x25, sp // Set up BPF stack base register (r10)
20: mov x26, #0x0 // Initialize tail_call_cnt ④
24: sub x27, x25, #0x0 // Calculate FP bottom ⑤
28: sub sp, sp, #0x200 // Set up BPF program stack ⑥
2c: mov x1, #0xffffff80ffffffff // r2 = map[id:4] ⑦
30: movk x1, #0xc38c, lsl #16 // ⋮
34: movk x1, #0x7200 // ⋮
38: mov x2, #0x0 // r3 = 0
3c: mov w10, #0x24 // = offsetof(struct bpf_array, map.max_entries) ⑧
40: ldr w10, [x1, x10] // Load array->map.max_entries
44: add w2, w2, #0x0 // = index (0)
48: cmp w2, w10 // if (index >= array->map.max_entries)
4c: b.cs 0x0000000000000088 // goto out;
50: mov w10, #0x21 // = MAX_TAIL_CALL_CNT (33)
54: cmp x26, x10 // if (tail_call_cnt >= MAX_TAIL_CALL_CNT)
58: b.cs 0x0000000000000088 // goto out;
5c: add x26, x26, #0x1 // tail_call_cnt++;
60: mov w10, #0x110 // = offsetof(struct bpf_array, ptrs)
64: add x10, x1, x10 // = &array->ptrs
68: lsl x11, x2, #3 // = index * sizeof(array->ptrs[0])
6c: ldr x11, [x10, x11] // prog = array->ptrs[index];
70: cbz x11, 0x0000000000000088 // if (prog == NULL) goto out;
74: mov w10, #0x30 // = offsetof(struct bpf_prog, bpf_func)
78: ldr x10, [x11, x10] // Load prog->bpf_func
7c: add x10, x10, #0x24 // += PROLOGUE_OFFSET * AARCH64_INSN_SIZE (4)
80: add sp, sp, #0x200 // Unwind BPF stack
84: br x10 // goto *(prog->bpf_func + prologue_offset)
88: mov x7, #0xf00d // r0 = 0xf00d
8c: add sp, sp, #0x200 // Unwind BPF stack ⑨
90: ldp x27, x28, [sp], #16 // Restore used callee-saved registers
94: ldp x25, x26, [sp], #16 // ⋮
98: ldp x21, x22, [sp], #16 // ⋮
9c: ldp x19, x20, [sp], #16 // ⋮
a0: ldp x29, x30, [sp], #16 // ⋮
a4: add x0, x7, #0x0 // Set return value
a8: autiasp // Authenticate LR
ac: ret // Return to caller
① BPF program prologue starts with Pointer Authentication Code (PAC), which protects against Return Oriented Programming attacks. PAC instructions are emitted by JIT only if CONFIG_ARM64_PTR_AUTH_KERNEL is enabled.
② Arm 64 Architecture Procedure Call Standard mandates that the Frame Pointer (register X29) and the Link Register (register X30), aka the return address, of the caller should be recorded onto the stack.
③ Registers X19 to X28, and X29 (FP) plus X30 (LR), are callee saved. ARM64 BPF JIT does not use registers X23 and X24 currently, so they are not saved.
④ We track the tail call depth in X26. No need to save it onto stack since we use a register dedicated just for this purpose.
⑤ FP bottom is an optimization that allows store/loads to BPF stack with a single instruction and an immediate offset value.
⑥ Reserve space for the BPF program stack. The stack layout is now as shown in a diagram in build_prologue() source code.
⑦ The BPF function body starts here.
⑧ bpf_tail_call() instructions start here.
⑨ The epilogue starts here.
Whew! That was a handful 😅.
Notice that the BPF tail call implementation on arm64 is not as optimized as on x86-64. There is no code patching to make direct jumps when the target program index is known at the JIT-compilation time. Instead, the target address is always loaded from the BPF program array.
Ready for the second scenario? I promise it will be shorter. Function prologue and epilogue instructions will look familiar, so we are going to keep annotations down to a minimum.
Scenario #2: A BPF to BPF call – sub_call_ex1.bpf.c
Input: BPF assembly (bpftool prog dump xlated)
int entry_prog(struct __sk_buff * skb):
0: (85) call pc+1#bpf_prog_a84919ecd878b8f3_sub_func
1: (95) exit
int sub_func(struct __sk_buff * skb):
2: (b7) r0 = 61453 // 0xf00d
3: (95) exit
Output: ARM64 assembly
int entry_prog(struct __sk_buff * skb):
bpf_prog_163e74e7188910f2_entry_prog:
0: paciasp // Begin prologue
4: stp x29, x30, [sp, #-16]! // ⋮
8: mov x29, sp // ⋮
c: stp x19, x20, [sp, #-16]! // ⋮
10: stp x21, x22, [sp, #-16]! // ⋮
14: stp x25, x26, [sp, #-16]! // ⋮
18: stp x27, x28, [sp, #-16]! // ⋮
1c: mov x25, sp // ⋮
20: mov x26, #0x0 // ⋮
24: sub x27, x25, #0x0 // ⋮
28: sub sp, sp, #0x0 // End prologue
2c: mov x10, #0xffffffffffff5420 // Build sub_func()+0x0 address
30: movk x10, #0x8ff, lsl #16 // ⋮
34: movk x10, #0xffc0, lsl #32 // ⋮
38: blr x10 ------------------. // Call sub_func()+0x0
3c: add x7, x0, #0x0 <----------. // r0 = sub_func()
40: mov sp, sp | | // Begin epilogue
44: ldp x27, x28, [sp], #16 | | // ⋮
48: ldp x25, x26, [sp], #16 | | // ⋮
4c: ldp x21, x22, [sp], #16 | | // ⋮
50: ldp x19, x20, [sp], #16 | | // ⋮
54: ldp x29, x30, [sp], #16 | | // ⋮
58: add x0, x7, #0x0 | | // ⋮
5c: autiasp | | // ⋮
60: ret | | // End epilogue
| |
int sub_func(struct __sk_buff * skb): | |
bpf_prog_a84919ecd878b8f3_sub_func: | |
0: paciasp <---------------------' | // Begin prologue
4: stp x29, x30, [sp, #-16]! | // ⋮
8: mov x29, sp | // ⋮
c: stp x19, x20, [sp, #-16]! | // ⋮
10: stp x21, x22, [sp, #-16]! | // ⋮
14: stp x25, x26, [sp, #-16]! | // ⋮
18: stp x27, x28, [sp, #-16]! | // ⋮
1c: mov x25, sp | // ⋮
20: mov x26, #0x0 | // ⋮
24: sub x27, x25, #0x0 | // ⋮
28: sub sp, sp, #0x0 | // End prologue
2c: mov x7, #0xf00d | // r0 = 0xf00d
30: mov sp, sp | // Begin epilogue
34: ldp x27, x28, [sp], #16 | // ⋮
38: ldp x25, x26, [sp], #16 | // ⋮
3c: ldp x21, x22, [sp], #16 | // ⋮
40: ldp x19, x20, [sp], #16 | // ⋮
44: ldp x29, x30, [sp], #16 | // ⋮
48: add x0, x7, #0x0 | // ⋮
4c: autiasp | // ⋮
50: ret ----------------------------' // End epilogue
We have now seen what a BPF tail call and a BPF function/subprogram call compiles down to. Can you already spot what would go wrong if mixing the two was allowed?
That’s right! Every time we enter a BPF subprogram, we reset the X26 register, which holds the tail call count, to zero (mov x26, #0x0). This is bad. It would let users create program chains longer than the MAX_TAIL_CALL_CNT limit.
How about we just skip this step when emitting the prologue for BPF subprograms?
@@ -246,6 +246,7 @@ static bool is_lsi_offset(int offset, int scale)
static int build_prologue(struct jit_ctx *ctx, bool ebpf_from_cbpf)
{
const struct bpf_prog *prog = ctx->prog;
+ const bool is_main_prog = prog->aux->func_idx == 0;
const u8 r6 = bpf2a64[BPF_REG_6];
const u8 r7 = bpf2a64[BPF_REG_7];
const u8 r8 = bpf2a64[BPF_REG_8];
@@ -299,7 +300,7 @@ static int build_prologue(struct jit_ctx *ctx, bool ebpf_from_cbpf)
/* Set up BPF prog stack base register */
emit(A64_MOV(1, fp, A64_SP), ctx);
- if (!ebpf_from_cbpf) {
+ if (!ebpf_from_cbpf && is_main_prog) {
/* Initialize tail_call_cnt */
emit(A64_MOVZ(1, tcc, 0, 0), ctx);
Believe it or not. This is everything that was missing to get BPF tail calls working with function calls on arm64. The feature will be enabled in the upcoming Linux 6.0 release.
Outro
From recursion to tweaking the BPF JIT. How did we get here? Not important. It’s all about the journey.
Along the way we have unveiled a few secrets behind BPF tails calls, and hopefully quenched your thirst for low-level programming. At least for today.
All that is left is to sit back and watch the fruits of our work. With GDB hooked up to a VM, we can observe how a BPF program calls into a BPF function, and from there tail calls to another BPF program:
https://demo-gdb-step-thru-bpf.pages.dev/
Until next time 🖖.