Post Syndicated from Jakub Sitnicki original https://blog.cloudflare.com/the-quantum-state-of-a-tcp-port/
Have you noticed how simple questions sometimes lead to complex answers? Today we will tackle one such question. Category: our favorite – Linux networking.
When can two TCP sockets share a local address?
If I navigate to https://blog.cloudflare.com/, my browser will connect to a remote TCP address, might be 104.16.132.229:443 in this case, from the local IP address assigned to my Linux machine, and a randomly chosen local TCP port, say 192.0.2.42:54321. What happens if I then decide to head to a different site? Is it possible to establish another TCP connection from the same local IP address and port?
To find the answer let’s do a bit of learning by discovering. We have prepared eight quiz questions. Each will let you discover one aspect of the rules that govern local address sharing between TCP sockets under Linux. Fair warning, it might get a bit mind-boggling.
Questions are split into two groups by test scenario:
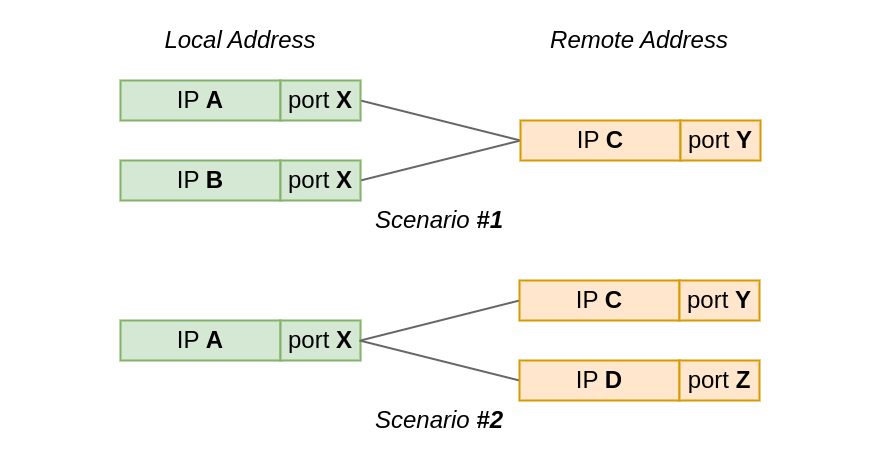
In the first test scenario, two sockets connect from the same local port to the same remote IP and port. However, the local IP is different for each socket.
While, in the second scenario, the local IP and port is the same for all sockets, but the remote address, or actually just the IP address, differs.
In our quiz questions, we will either:
- let the OS automatically select the the local IP and/or port for the socket, or
- we will explicitly assign the local address with
bind()beforeconnect()’ing the socket; a method also known as bind-before-connect.
Because we will be examining corner cases in the bind() logic, we need a way to exhaust available local addresses, that is (IP, port) pairs. We could just create lots of sockets, but it will be easier to tweak the system configuration and pretend that there is just one ephemeral local port, which the OS can assign to sockets:
sysctl -w net.ipv4.ip_local_port_range='60000 60000'
Each quiz question is a short Python snippet. Your task is to predict the outcome of running the code. Does it succeed? Does it fail? If so, what fails? Asking ChatGPT is not allowed 😉
There is always a common setup procedure to keep in mind. We will omit it from the quiz snippets to keep them short:
from os import system
from socket import *
# Missing constants
IP_BIND_ADDRESS_NO_PORT = 24
# Our network namespace has just *one* ephemeral port
system("sysctl -w net.ipv4.ip_local_port_range='60000 60000'")
# Open a listening socket at *:1234. We will connect to it.
ln = socket(AF_INET, SOCK_STREAM)
ln.bind(("", 1234))
ln.listen(SOMAXCONN)
With the formalities out of the way, let us begin. Ready. Set. Go!
Scenario #1: When the local IP is unique, but the local port is the same
In Scenario #1 we connect two sockets to the same remote address – 127.9.9.9:1234. The sockets will use different local IP addresses, but is it enough to share the local port?
| local IP | local port | remote IP | remote port |
|---|---|---|---|
| unique | same | same | same |
| 127.0.0.1 127.1.1.1 127.2.2.2 |
60_000 | 127.9.9.9 | 1234 |
Quiz #1
On the local side, we bind two sockets to distinct, explicitly specified IP addresses. We will allow the OS to select the local port. Remember: our local ephemeral port range contains just one port (60,000).
s1 = socket(AF_INET, SOCK_STREAM)
s1.bind(('127.1.1.1', 0))
s1.connect(('127.9.9.9', 1234))
s1.getsockname(), s1.getpeername()
s2 = socket(AF_INET, SOCK_STREAM)
s2.bind(('127.2.2.2', 0))
s2.connect(('127.9.9.9', 1234))
s2.getsockname(), s2.getpeername()
GOTO Answer #1
Quiz #2
Here, the setup is almost identical as before. However, we ask the OS to select the local IP address and port for the first socket. Do you think the result will differ from the previous question?
s1 = socket(AF_INET, SOCK_STREAM)
s1.connect(('127.9.9.9', 1234))
s1.getsockname(), s1.getpeername()
s2 = socket(AF_INET, SOCK_STREAM)
s2.bind(('127.2.2.2', 0))
s2.connect(('127.9.9.9', 1234))
s2.getsockname(), s2.getpeername()
GOTO Answer #2
Quiz #3
This quiz question is just like the one above. We just changed the ordering. First, we connect a socket from an explicitly specified local address. Then we ask the system to select a local address for us. Obviously, such an ordering change should not make any difference, right?
s1 = socket(AF_INET, SOCK_STREAM)
s1.bind(('127.1.1.1', 0))
s1.connect(('127.9.9.9', 1234))
s1.getsockname(), s1.getpeername()
s2 = socket(AF_INET, SOCK_STREAM)
s2.connect(('127.9.9.9', 1234))
s2.getsockname(), s2.getpeername()
GOTO Answer #3
Scenario #2: When the local IP and port are the same, but the remote IP differs
In Scenario #2 we reverse our setup. Instead of multiple local IP’s and one remote address, we now have one local address 127.0.0.1:60000 and two distinct remote addresses. The question remains the same – can two sockets share the local port? Reminder: ephemeral port range is still of size one.
| local IP | local port | remote IP | remote port |
|---|---|---|---|
| same | same | unique | same |
| 127.0.0.1 | 60_000 | 127.8.8.8 127.9.9.9 |
1234 |
Quiz #4
Let’s start from the basics. We connect() to two distinct remote addresses. This is a warm up 🙂
s1 = socket(AF_INET, SOCK_STREAM)
s1.connect(('127.8.8.8', 1234))
s1.getsockname(), s1.getpeername()
s2 = socket(AF_INET, SOCK_STREAM)
s2.connect(('127.9.9.9', 1234))
s2.getsockname(), s2.getpeername()
GOTO Answer #4
Quiz #5
What if we bind() to a local IP explicitly but let the OS select the port – does anything change?
s1 = socket(AF_INET, SOCK_STREAM)
s1.bind(('127.0.0.1', 0))
s1.connect(('127.8.8.8', 1234))
s1.getsockname(), s1.getpeername()
s2 = socket(AF_INET, SOCK_STREAM)
s2.bind(('127.0.0.1', 0))
s2.connect(('127.9.9.9', 1234))
s2.getsockname(), s2.getpeername()
GOTO Answer #5
Quiz #6
This time we explicitly specify the local address and port. Sometimes there is a need to specify the local port.
s1 = socket(AF_INET, SOCK_STREAM)
s1.bind(('127.0.0.1', 60_000))
s1.connect(('127.8.8.8', 1234))
s1.getsockname(), s1.getpeername()
s2 = socket(AF_INET, SOCK_STREAM)
s2.bind(('127.0.0.1', 60_000))
s2.connect(('127.9.9.9', 1234))
s2.getsockname(), s2.getpeername()
GOTO Answer #6
Quiz #7
Just when you thought it couldn’t get any weirder, we add SO_REUSEADDR into the mix.
First, we ask the OS to allocate a local address for us. Then we explicitly bind to the same local address, which we know the OS must have assigned to the first socket. We enable local address reuse for both sockets. Is this allowed?
s1 = socket(AF_INET, SOCK_STREAM)
s1.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
s1.connect(('127.8.8.8', 1234))
s1.getsockname(), s1.getpeername()
s2 = socket(AF_INET, SOCK_STREAM)
s2.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
s2.bind(('127.0.0.1', 60_000))
s2.connect(('127.9.9.9', 1234))
s2.getsockname(), s2.getpeername()
GOTO Answer #7
Quiz #8
Finally, a cherry on top. This is Quiz #7 but in reverse. Common sense dictates that the outcome should be the same, but is it?
s1 = socket(AF_INET, SOCK_STREAM)
s1.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
s1.bind(('127.0.0.1', 60_000))
s1.connect(('127.9.9.9', 1234))
s1.getsockname(), s1.getpeername()
s2 = socket(AF_INET, SOCK_STREAM)
s2.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
s2.connect(('127.8.8.8', 1234))
s2.getsockname(), s2.getpeername()
GOTO Answer #8
The secret tri-state life of a local TCP port
Is it all clear now? Well, probably no. It feels like reverse engineering a black box. So what is happening behind the scenes? Let’s take a look.
Linux tracks all TCP ports in use in a hash table named bhash. Not to be confused with with ehash table, which tracks sockets with both local and remote address already assigned.
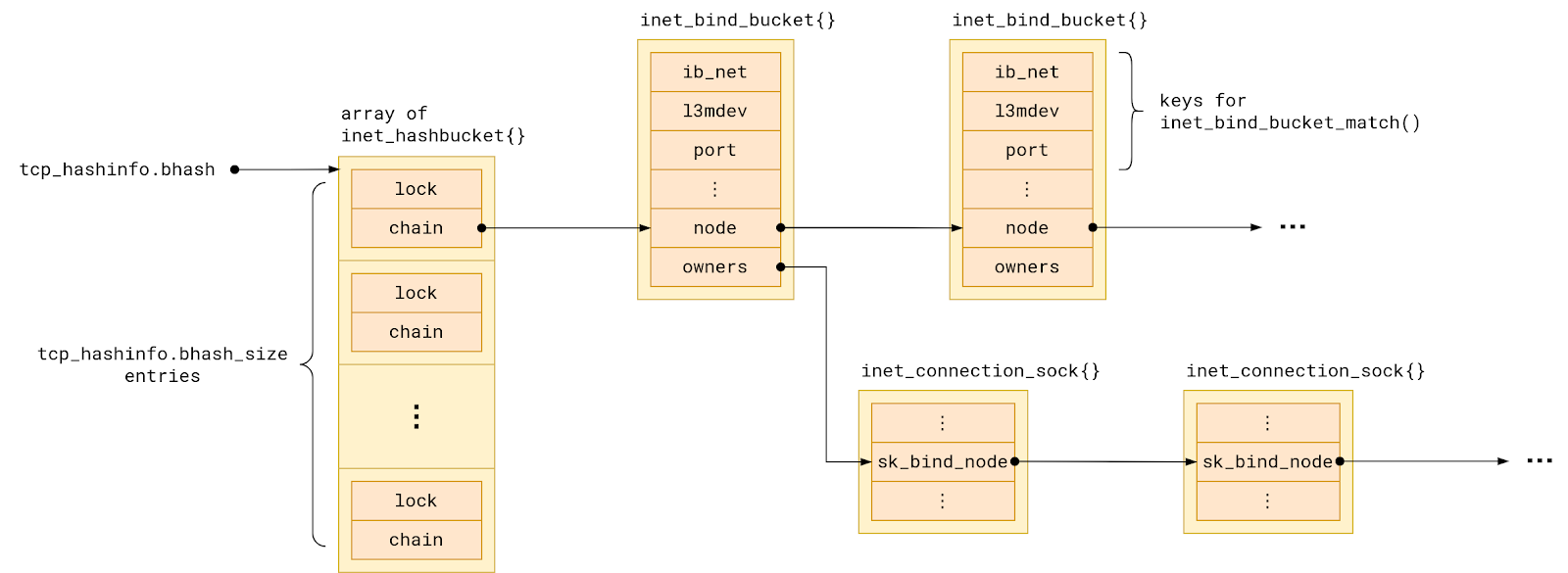
Each hash table entry points to a chain of so-called bind buckets, which group together sockets which share a local port. To be precise, sockets are grouped into buckets by:
- the network namespace they belong to, and
- the VRF device they are bound to, and
- the local port number they are bound to.
But in the simplest possible setup – single network namespace, no VRFs – we can say that sockets in a bind bucket are grouped by their local port number.
The set of sockets in each bind bucket, that is sharing a local port, is backed by a linked list named owners.
When we ask the kernel to assign a local address to a socket, its task is to check for a conflict with any existing socket. That is because a local port number can be shared only under some conditions:
/* There are a few simple rules, which allow for local port reuse by
* an application. In essence:
*
* 1) Sockets bound to different interfaces may share a local port.
* Failing that, goto test 2.
* 2) If all sockets have sk->sk_reuse set, and none of them are in
* TCP_LISTEN state, the port may be shared.
* Failing that, goto test 3.
* 3) If all sockets are bound to a specific inet_sk(sk)->rcv_saddr local
* address, and none of them are the same, the port may be
* shared.
* Failing this, the port cannot be shared.
*
* The interesting point, is test #2. This is what an FTP server does
* all day. To optimize this case we use a specific flag bit defined
* below. As we add sockets to a bind bucket list, we perform a
* check of: (newsk->sk_reuse && (newsk->sk_state != TCP_LISTEN))
* As long as all sockets added to a bind bucket pass this test,
* the flag bit will be set.
* ...
*/
The comment above hints that the kernel tries to optimize for the happy case of no conflict. To this end the bind bucket holds additional state which aggregates the properties of the sockets it holds:
struct inet_bind_bucket {
/* ... */
signed char fastreuse;
signed char fastreuseport;
kuid_t fastuid;
#if IS_ENABLED(CONFIG_IPV6)
struct in6_addr fast_v6_rcv_saddr;
#endif
__be32 fast_rcv_saddr;
unsigned short fast_sk_family;
bool fast_ipv6_only;
/* ... */
};
Let’s focus our attention just on the first aggregate property – fastreuse. It has existed since, now prehistoric, Linux 2.1.90pre1. Initially in the form of a bit flag, as the comment says, only to evolve to a byte-sized field over time.
The other six fields came on much later with the introduction of SO_REUSEPORT in Linux 3.9. Because they play a role only when there are sockets with the SO_REUSEPORT flag set. We are going to ignore them today.
Whenever the Linux kernel needs to bind a socket to a local port, it first has to look for the bind bucket for that port. What makes life a bit more complicated is the fact that the search for a TCP bind bucket exists in two places in the kernel. The bind bucket lookup can happen early – at bind() time – or late – at connect() – time. Which one gets called depends on how the connected socket has been set up:
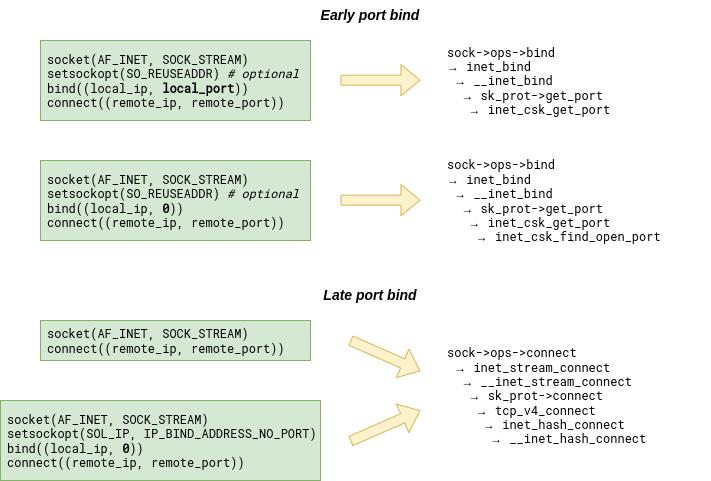
However, whether we land in inet_csk_get_port or __inet_hash_connect, we always end up walking the bucket chain in the bhash looking for the bucket with a matching port number. The bucket might already exist or we might have to create it first. But once it exists, its fastreuse field is in one of three possible states: -1, 0, or +1. As if Linux developers were inspired by quantum mechanics.
That state reflects two aspects of the bind bucket:
- What sockets are in the bucket?
- When can the local port be shared?
So let us try to decipher the three possible fastreuse states then, and what they mean in each case.
First, what does the fastreuse property say about the owners of the bucket, that is the sockets using that local port?
| fastreuse is | owners list contains |
|---|---|
| -1 | sockets connect()’ed from an ephemeral port |
| 0 | sockets bound without SO_REUSEADDR |
| +1 | sockets bound with SO_REUSEADDR |
While this is not the whole truth, it is close enough for now. We will soon get to the bottom of it.
When it comes port sharing, the situation is far less straightforward:
| Can I … when … | fastreuse = -1 | fastreuse = 0 | fastreuse = +1 |
|---|---|---|---|
| bind() to the same port (ephemeral or specified) | yes IFF local IP is unique ① | ← idem | ← idem |
| bind() to the specific port with SO_REUSEADDR | yes IFF local IP is unique OR conflicting socket uses SO_REUSEADDR ① | ← idem | yes ② |
| connect() from the same ephemeral port to the same remote (IP, port) | yes IFF local IP unique ③ | no ③ | no ③ |
| connect() from the same ephemeral port to a unique remote (IP, port) | yes ③ | no ③ | no ③ |
① Determined by inet_csk_bind_conflict() called from inet_csk_get_port() (specific port bind) or inet_csk_get_port() → inet_csk_find_open_port() (ephemeral port bind).
② Because inet_csk_get_port() skips conflict check for fastreuse == 1 buckets.
③ Because inet_hash_connect() → __inet_hash_connect() skips buckets with fastreuse != -1.
While it all looks rather complicated at first sight, we can distill the table above into a few statements that hold true, and are a bit easier to digest:
bind(), or early local address allocation, always succeeds if there is no local IP address conflict with any existing socket,connect(), or late local address allocation, always fails when TCP bind bucket for a local port is in any state other thanfastreuse = -1,connect()only succeeds if there is no local and remote address conflict,SO_REUSEADDRsocket option allows local address sharing, if all conflicting sockets also use it (and none of them is in the listening state).
This is crazy. I don’t believe you.
Fortunately, you don’t have to. With drgn, the programmable debugger, we can examine the bind bucket state on a live kernel:
#!/usr/bin/env drgn
"""
dump_bhash.py - List all TCP bind buckets in the current netns.
Script is not aware of VRF.
"""
import os
from drgn.helpers.linux.list import hlist_for_each, hlist_for_each_entry
from drgn.helpers.linux.net import get_net_ns_by_fd
from drgn.helpers.linux.pid import find_task
def dump_bind_bucket(head, net):
for tb in hlist_for_each_entry("struct inet_bind_bucket", head, "node"):
# Skip buckets not from this netns
if tb.ib_net.net != net:
continue
port = tb.port.value_()
fastreuse = tb.fastreuse.value_()
owners_len = len(list(hlist_for_each(tb.owners)))
print(
"{:8d} {:{sign}9d} {:7d}".format(
port,
fastreuse,
owners_len,
sign="+" if fastreuse != 0 else " ",
)
)
def get_netns():
pid = os.getpid()
task = find_task(prog, pid)
with open(f"/proc/{pid}/ns/net") as f:
return get_net_ns_by_fd(task, f.fileno())
def main():
print("{:8} {:9} {:7}".format("TCP-PORT", "FASTREUSE", "#OWNERS"))
tcp_hashinfo = prog.object("tcp_hashinfo")
net = get_netns()
# Iterate over all bhash slots
for i in range(0, tcp_hashinfo.bhash_size):
head = tcp_hashinfo.bhash[i].chain
# Iterate over bind buckets in the slot
dump_bind_bucket(head, net)
main()
Let’s take this script for a spin and try to confirm what Table 1 claims to be true. Keep in mind that to produce the ipython --classic session snippets below I’ve used the same setup as for the quiz questions.
Two connected sockets sharing ephemeral port 60,000:
>>> s1 = socket(AF_INET, SOCK_STREAM)
>>> s1.connect(('127.1.1.1', 1234))
>>> s2 = socket(AF_INET, SOCK_STREAM)
>>> s2.connect(('127.2.2.2', 1234))
>>> !./dump_bhash.py
TCP-PORT FASTREUSE #OWNERS
1234 0 3
60000 -1 2
>>>
Two bound sockets reusing port 60,000:
>>> s1 = socket(AF_INET, SOCK_STREAM)
>>> s1.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
>>> s1.bind(('127.1.1.1', 60_000))
>>> s2 = socket(AF_INET, SOCK_STREAM)
>>> s2.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
>>> s2.bind(('127.1.1.1', 60_000))
>>> !./dump_bhash.py
TCP-PORT FASTREUSE #OWNERS
1234 0 1
60000 +1 2
>>>
A mix of bound sockets with and without REUSEADDR sharing port 60,000:
>>> s1 = socket(AF_INET, SOCK_STREAM)
>>> s1.setsockopt(SOL_SOCKET, SO_REUSEADDR, 1)
>>> s1.bind(('127.1.1.1', 60_000))
>>> !./dump_bhash.py
TCP-PORT FASTREUSE #OWNERS
1234 0 1
60000 +1 1
>>> s2 = socket(AF_INET, SOCK_STREAM)
>>> s2.bind(('127.2.2.2', 60_000))
>>> !./dump_bhash.py
TCP-PORT FASTREUSE #OWNERS
1234 0 1
60000 0 2
>>>
With such tooling, proving that Table 2 holds true is just a matter of writing a bunch of exploratory tests.
But what has happened in that last snippet? The bind bucket has clearly transitioned from one fastreuse state to another. This is what Table 1 fails to capture. And it means that we still don’t have the full picture.
We have yet to find out when the bucket’s fastreuse state can change. This calls for a state machine.
Das State Machine
As we have just seen, a bind bucket does not need to stay in the initial fastreuse state throughout its lifetime. Adding sockets to the bucket can trigger a state change. As it turns out, it can only transition into fastreuse = 0, if we happen to bind() a socket that:
- doesn’t conflict existing owners, and
- doesn’t have the
SO_REUSEADDRoption enabled.

And while we could have figured it all out by carefully reading the code in inet_csk_get_port → inet_csk_update_fastreuse, it certainly doesn’t hurt to confirm our understanding with a few more tests.
Now that we have the full picture, this begs the question…
Why are you telling me all this?
Firstly, so that the next time bind() syscall rejects your request with EADDRINUSE, or connect() refuses to cooperate by throwing the EADDRNOTAVAIL error, you will know what is happening, or at least have the tools to find out.
Secondly, because we have previously advertised a technique for opening connections from a specific range of ports which involves bind()’ing sockets with the SO_REUSEADDR option. What we did not realize back then, is that there exists a corner case when the same port can’t be shared with the regular, connect()‘ed sockets. While that is not a deal-breaker, it is good to understand the consequences.
To make things better, we have worked with the Linux community to extend the kernel API with a new socket option that lets the user specify the local port range. The new option will be available in the upcoming Linux 6.3. With it we no longer have to resort to bind()-tricks. This makes it possible to yet again share a local port with regular connect()‘ed sockets.
Closing thoughts
Today we posed a relatively straightforward question – when can two TCP sockets share a local address? – and worked our way towards an answer. An answer that is too complex to compress it into a single sentence. What is more, it’s not even the full answer. After all, we have decided to ignore the existence of the SO_REUSEPORT feature, and did not consider conflicts with TCP listening sockets.
If there is a simple takeaway, though, it is that bind()’ing a socket can have tricky consequences. When using bind() to select an egress IP address, it is best to combine it with IP_BIND_ADDRESS_NO_PORT socket option, and leave the port assignment to the kernel. Otherwise we might unintentionally block local TCP ports from being reused.
It is too bad that the same advice does not apply to UDP, where IP_BIND_ADDRESS_NO_PORT does not really work today. But that is another story.
Until next time 🖖.
If you enjoy scratching your head while reading the Linux kernel source code, we are hiring.















{kind=link}
{kind=link}