Post Syndicated from milemons original https://github.blog/2023-07-06-accessibility-considerations-behind-code-search-and-code-view/
GitHub prides itself on being the home for all developers, including developers with disabilities. Accessibility is a core priority for all new projects at GitHub, so it was top of mind when we started our project to rework code search and the code view at GitHub. With the old code view, some developers preferred to look at raw code rather than code view due to accessibility barriers, and that’s what we set out to fix. This blog post will shed light on our process and three major tasks that required thoughtful design and implementation—code search and query builder, the file tree, and navigating code by keyboard.
Process
We worked with a team of experts at GitHub dedicated to accessibility, since while we are confident in our development skills, accessibility has many nuances and requires a large depth of knowledge to get right. This team helped us immensely in three main ways:
- External auditing
In this project, we performed accessibility auditing on all of our features. This meant that another team of auditors reviewed our webpage with all the changes implemented to find accessibility errors. They used tools including screen readers, color contrast tools, and more, to identify areas that users with disabilities may find hard to use. Once those issues were identified, the accessibility team would take a look at those issues and suggest a proper solution to the problem. Then, it was up to us to implement the solution and collaborate with the team where we needed additional assistance. - Design reviews
The user interface for code search and code view were both entirely redesigned to support our new goals—to allow users to search, navigate, and understand code in a way they weren’t able to before. As a part of the design process, a team of accessibility designers reviewed the Figma mockups to determine proper HTML markup and tab order. Then, they included detailed explanations of what interactions should look like in order to meet our accessibility goals. - Office hours
The accessibility team at GitHub hosts weekly meetings where engineers can sign up and discuss how to solve problems with their features with the team and a consultant. The consultant is incredibly helpful and knowledgeable about how to properly address issues because he has lived experience with screen readers and accessibility.During these meetings, we were able to discuss complicated issues, such as the following: proper filtering for code search, making an accessible file tree, and navigating code on a keyboard, along with other issues like tab order, and focus management across the whole feature.
Implementation details
Code search
This has been written about frequently on our blog—from one post on the details of QueryBuilder, our implementation of an accessible finder component to details about what navigating code search accessibly looks like. Those two posts are great reads and I strongly recommend checking them out, but they’re not the only thing that we’ve worked on. Thanks to @lindseywild, @smockle, @kendallgassner, @owenniblock, and @khiga8 for their guidance and help resolving issues with code search. This is still a work in progress, especially in areas like the filtering behavior on the search pages.
Two areas that also required careful consideration were managing focus after changing the sort order of search results and how to announce the result of the search for screen reader users.
Changing sort—changing focus?
When we first implemented this sort dropdown for non-code search types, if you navigated to it with your keyboard and then selected a different sort option, the whole page would reload and your focus moved back to the header. Our preferred, accessible behavior is that, when a dropdown menu is closed, focus returns to the button that opened the menu. However, our problem was that the “Sort” dropdown didn’t merely perform client-side operations like most dropdowns where you select an option. In this case, once a user selects an option, we do a full page navigation to perform the new search with the sort order added. This meant that the focus was being placed back on the header by default after the page navigation, instead of returning to the sort dropdown. For sighted mouse users, this is a nonissue; for sighted keyboard users, it is unexpected and annoying; for blind users, this is confusing and makes the product hard to use. To fix this, we had to make sure we returned focus to the dropdown after reloading the page.
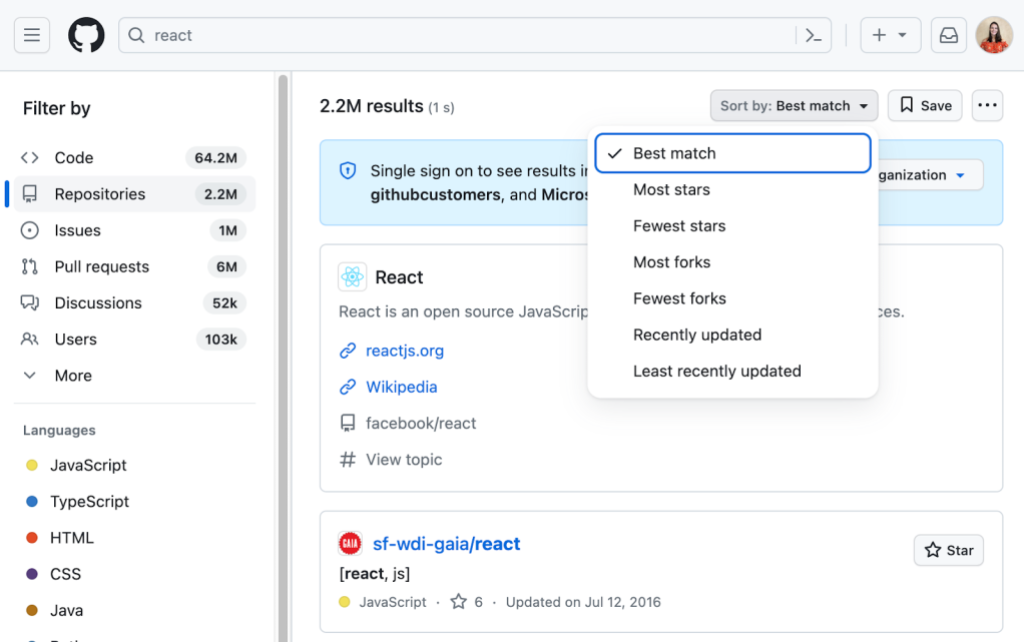
Announcing search results
When a sighted user types in the search bar and presses ‘Enter’ they quickly receive feedback that the search has completed and whether or not they found any results by looking at the page. For screen reader users, though, how to give the feedback that there were results, how many, or if there was an error requires more thought. One solution could be to place focus on the first result. That has a number of problems though.
- The user will not receive feedback about the number of search results and may think there’s only one.
- The user may miss important context like the Single sign on banner.
- The user will have to tab through more elements if they want to get back.
Another solution could be to use aria-live announcements to read out the number of results and success. This has its own problems.
- We already have an announcement on page navigation to read out the new title and these two announcements would compete or cause a race condition.
- There isn’t a way to programmatically force announcements to be read in order on page load.
- Some screen reader users have aria-live announcements turned off since they can be annoying.
After some discussion, we decided to focus and read out the header with the number of search results after a search and allow users to explore for errors, banners, or results on their own once they know how many results they received.
Tree navigation
We knew when redesigning the code viewing experience that we wanted to include the tree panel to allow users to quickly switch between folders or files, because understanding code often requires looking in multiple places. We started the project by making our own tree to the aria spec, but it was too verbose. To fix this, our accessibility and design teams created the TreeView, which is open source. This was implemented to support various generic list elements and use proper HTML structure to make navigating through the tree a breeze, including typeahead (the ability to type a bit and have focus move to the first matching element), proper announcements for asynchronous loading of deeply nested items, and proper IDs for all elements that are guaranteed to be unique (that is, not constructed from their contents which may be the same). The valid markup for a tree view is very specific and developing it requires careful reviews for common issues, like invalid child item types under a role="group" element or using nested list elements without considering screen reader support, which is unlike most TreeView implementations on the internet. For more information about the design details for the tree view, check out the markdown documentation. Thanks to @colebemis, @mperrotti, and @ericwbailey for the work on this.
Reading and navigating code by keyboard
Before the new code view, reading code on GitHub wasn’t a great experience for screen reader users. The old experience presented code as a table—a hidden detail for sighted users but a major hurdle for screen readers, since code isn’t a table, and the semantics didn’t make sense in that context. For example, in code, whitespace has meaning. Whether stylistic or functional, that whitespace gets lost for screen reader users when the code is presented as a table. In addition, table semantics force users into line-by-line navigation, instead of character-by-character or word-by-word navigation. For many users, these hurdles meant that they mostly used GitHub just enough to be able to access the raw code or use a code editor for reading code. Since we want to support all our users, we knew we needed to totally rethink the way we structured code in the DOM.
This problem became even more complicated when we introduced symbols and the symbols panel. Mouse users are able to click on a “symbol” in the code—a special code element, like a function name—to see extra details about it, including references and definitions, in the symbol panel. They can then explore the code more deeply, navigating between lines of code where that symbol is found to investigate and understand the code better. This ability to dive deep has been game changing for many developers. However, for keyboard users, it doesn’t work. At best, a keyboard user can use the “Open symbols panel” button in the code header and then filter all symbol definitions for one they are interested in, but this doesn’t allow users to access symbol references when no definitions are found in a file. In addition, this flow really isn’t the same—if we want to support all developers, then we need to offer keyboard users a way to navigate through the code and select symbols they are interested in.
In addition, for many performance reasons mentioned in the post “Crafting a better, faster code view,” we introduced virtualization to the code viewer which created its own accessibility problems—not having all elements in the DOM can interfere with screen readers and overriding the cmd / ctrl + f shortcut is generally bad practice for screen readers as well. In addition, virtualization posed a problem for selecting text outside of the virtualization window.
This is when we came up with the solution of using a cursor from a <textarea> or a <div> that has the property contentEditable. This solution is modeled after Monaco, the text editor that powers VS Code. <textarea> elements, when not marked as readOnly, and contentEditiable<div> elements have a built in cursor that allows screen reader users to navigate code in their preferred manner using their built in screen reader settings. While a contentEditiable <div> would support syntax highlighting and the deep interactions we needed, screen readers don’t support them well1 which defeats the purpose of the cursor. As a result, we decided to go with the <textarea> However, <textarea> elements do not support syntax highlighting or deeper interactions like selecting symbols, which meant we needed to use both the <textarea> as a hidden element and syntax highlighted elements aligned perfectly above. Since we hide the text element, we need to add a visual “fake” cursor to show and keep it in sync with the “real” <textarea> cursor.
While the <textarea> and cursor help with our goals of allowing screen reader users and keyboard users to navigate code and symbols easily, they also ended up helping us with some of the problems we had run into with virtualization. One example of this was the cmd + f problem that we talk about more in depth in the blog post here. Another problem this solved was the drag and select behavior (or select all) for long files. Since the <textarea> is just one DOM node, we are able to load the whole file contents and select the contents directly from the <textarea> instead of the virtualized syntax highlighted version.
Unfortunately, while the <textarea> solved many problems we had, it also introduced a few other tricky ones. Since we have two layers of text, one hidden unless selected and one visual, we need to make sure that the scroll states are aligned. To do this, we have written observers to watch when one scrolls and mimic the scroll on the other. In addition, we often need to override the default <textarea> behaviors for some events—such as the middle click on mouse which was taking users all the way to the bottom of the code. Along with that issue, different browsers handle <textarea>s differently and making sure our solution behaves properly on all browsers has proven to be time intensive to say the least. In addition, we found that some browsers, like Firefox, allow users to customize their font size using Text zoom, which would apply to the formatted text but not the <textarea>. This led to “ghost text” issues with selection. We were able to resolve that by measuring the height of the text that is rendered and passing that to the <textarea>, though there are still some issues with certain plugins that modify text. We are still working to resolve these specific issues as well. In addition, the <textarea> currently does not work with our Wrap lines view option, which we are working to fix. Thanks especially to @joycezhu, @andrialexandrou, @adamshwert, and @jbrown1618 who put in a ton of work here.
Always iterating
We have taken huge strides to improve accessibility for all developers, but we recognize that we aren’t all the way there. It can be challenging to accommodate all developers, but we are committed to improving and iterating on what we have until we get it right. We want our tools to support everyone to access and explore code. We still have work—a lot of work—to do across GitHub, but we are excited for this journey.
To learn more about accessibility at GitHub, go to accessibility.github.com.
-
For more information about
contentEditableand screen readers, see this article written by @joycezhu from our Accessibility Engineering team. ↩