Post Syndicated from Jan Maarten original https://github.blog/engineering/user-experience/design-system-annotations-part-2-advanced-methods-of-annotating-components/
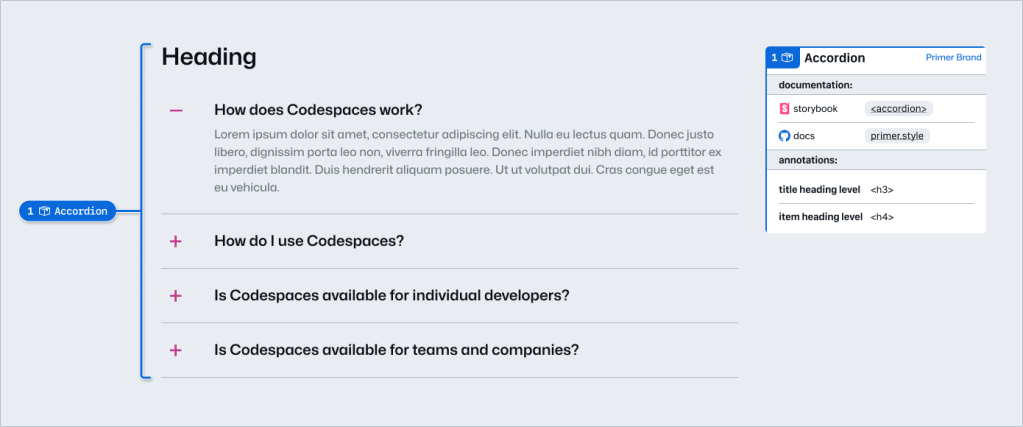
In part one of our design system annotation series, we discussed the ways in which accessibility can get left out of design system components from one instance to another. Our solution? Using a set of “Preset annotations” for each component with Primer. This allows designers to include specific pre-set details that aren’t already built into the component and visually communicated in the design itself.
That being said, Preset annotations are unique to each design system — and while ours may be a helpful reference for how to build them — they’re not something other organizations can utilize if you’re not also using the Primer design system.
Luckily, you can build your own. Here’s how.
How to make Preset annotations for your design system
Start by assessing components to understand which ones would need Preset annotations—not all of them will. Prioritize components that would benefit most from having a Preset annotation, and build that key information into each one. Next, determine what properties should be included. Only include key information that isn’t conveyed visually, isn’t in the component properties, and isn’t already baked into a coded component.

Prioritizing components
When a design system has 60+ components, knowing where to start can be a challenge. Which components need these annotations the most? Which ones would have the highest impact for both design teams and our users?
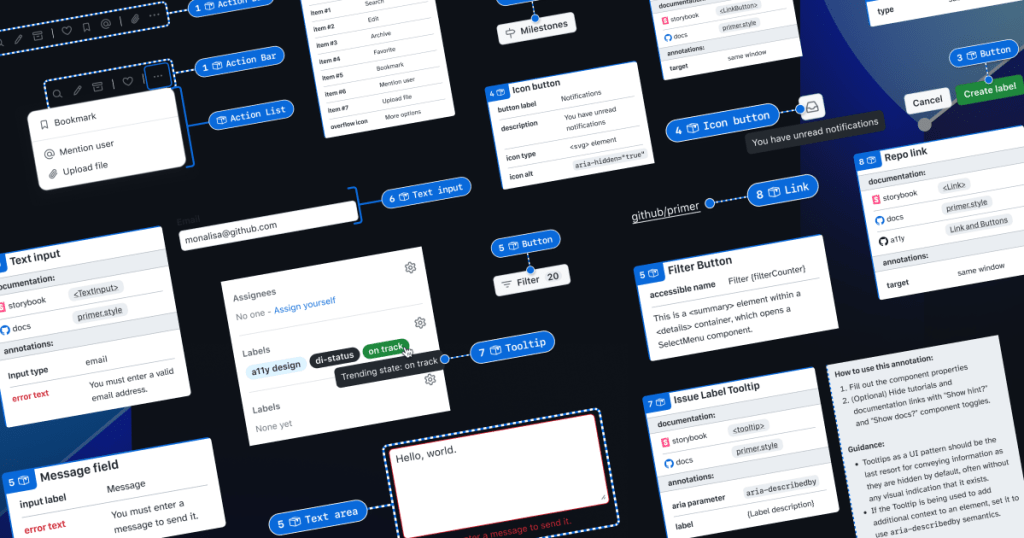
When we set out to create a new set of Preset annotations based on our proof of concept, we decided to use ten Primer components that would benefit the most. To help pick them, we used an internal tool called Primer Query that tracks all component implementations across the GitHub codebase as well as any audit issues connected to them. Here is a video breakdown of how it works, if you’re curious.
We then prioritized new Preset annotations based on the following criteria:
- Components that align to organization priorities (i.e. high value products and/or those that receive a lot of traffic).
- Components that appear frequently in accessibility audit issues.
- Components with React implementations (as our preferred development framework).
- Most frequently implemented components.
Mapping out the properties
For each component, we cross-referenced multiple sources to figure out what component properties and attributes would need to be added in each Preset annotation. The things we were looking for may only exist in one or two of those places, and thus are less likely to be accounted for all the way through the design and development lifecycle. The sources include:
Component documentation on Primer.style
Design system docs should contain usage guidance for designers and developers, and accessibility requirements should be a part of this guidance as well. Some of the guidance and requirements get built into the component’s Figma asset, while some only end up in the coded component.
Look for any accessibility requirements that are not built into either Figma or code. If it’s built in, putting the same info in the Preset annotation may be redundant or irrelevant.
Coded demos in Storybook
Our component sandbox helped us see how each component is built in React or Rails, as well as what the HTML output is. We looked for any code structure or accessibility attributes that are not included in the component documentation or the Figma asset itself—especially when they may vary from one implementation to another.
Component properties in the Figma asset library
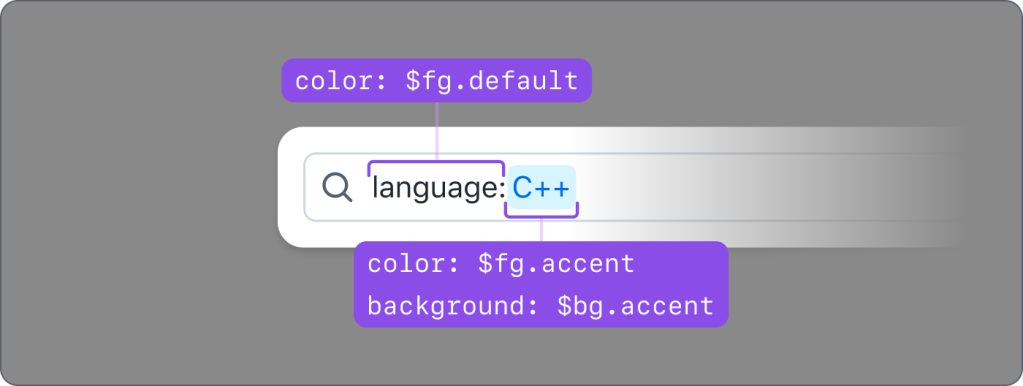
Library assets provide a lot of flexibility through text layers, image fills, variants, and elaborate sets of component properties. We paid close attention to these options to understand what designers can and can’t change. Worthwhile additions to a Preset Annotation are accessibility attributes, requirements, and usage guidance in other sources that aren’t built into the Figma component.
Other potential sources
- Experiences from team members: The designers, developers, and accessibility specialists you work with may have insight into things that the docs and design tools may have missed. If your team and design system have been around for a while, their insights may be more valuable than those you’ll find in the docs, component demos, or asset libraries. Take some time to ask which components have had challenging bugs and which get intentionally broken when implemented.
- Findings from recent audits: Design system components themselves may have unresolved audit issues and remediation recommendations. If that’s the case, those issues are likely present in Storybook demos and may be unaccounted for in the component documentation. Design system audit issues may have details that both help create a Preset annotation and offer insights about what should not be carried over from existing resources.
What we learned from creating Preset annotations
Preset annotations may not be for every team or organization. However, they are especially well suited for younger design systems and those that aren’t well adopted.
Mature design systems like Primer have frequent updates. This means that without close monitoring, the design system components themselves may fall out of sync with how a Preset annotation is built. This can end up causing confusion and rework after development starts, so it may be wise to make sure there’s some capacity to maintain these annotations after they’ve been created.
For newer teams at GitHub, new members of existing teams, and team members who were less familiar with the design system, the built-in guidance and links to documentation and component demos proved very useful. Those who are more experienced are also able to fine-tune the Presets and how they’re used.
If you don’t already have extensive experience with the design system components (or peers to help build them), it can take a lot of time to assess and map out the properties needed to build a Preset. It can also be challenging to name a component property succinctly enough that it doesn’t get truncated in Figma’s properties panel. If the context is not self-evident, some training or additional documentation may help.
It’s not always clear that you need a Preset annotation
There may be enough overlap between the Preset annotation for a component and types of annotations that aren’t specific to the design system.
For example, the GitHub Annotation Toolkit has components to annotate basic <textarea> form elements in addition to a Preset annotation for our <TextArea> Primer component:
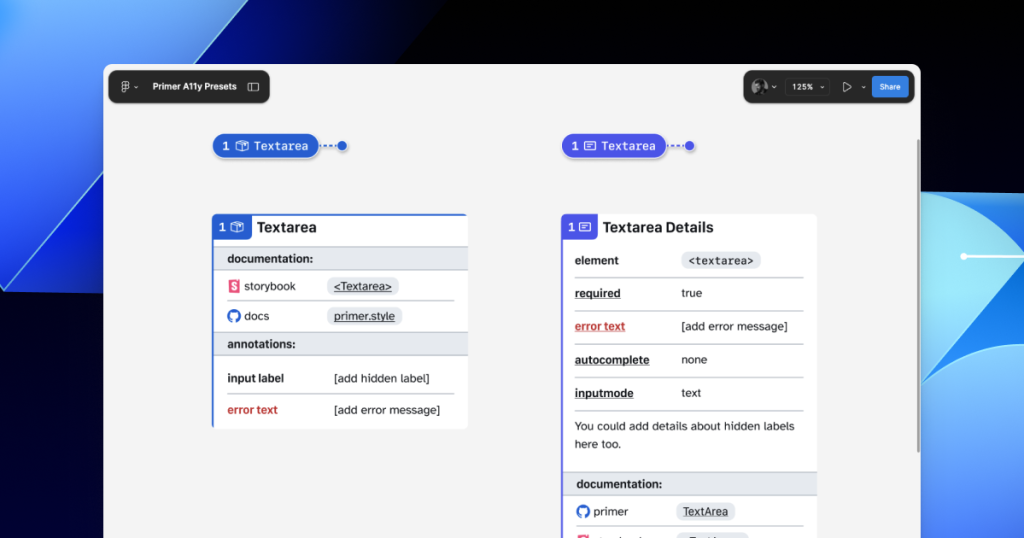
In many instances, this flexibility may be confusing because you could use either annotation. For example, the Primer <TextArea> Preset has built-in links to specific Primer docs, and while the non-Preset version doesn’t, you could always add the links manually. While there’s some overlap between the two, using either one is better than none.
One way around this confusion is to add Primer-specific properties to the default set of annotations. This would allow you to do things like toggle a boolean property on a normal Button annotation and have it show links and properties specific to your design system’s button component.
Our Preset creation process may unlock automation
There are currently a number of existing Figma plugins that advertise the ability to scan a design file to help with annotations. That being said, the results are often mixed and contain an unmanageable amount of noise and false positives. One of the reasons these issues happen is that these public plugins are design system agnostic.
Current automated annotation tools aren’t able to understand that any design system components are being used without bespoke programming or thorough training of AI models. For plugins like this to be able to label design elements accurately, they first need to understand how to identify the components on the canvas, the variants used, and the set properties.
With that in mind, perhaps the most exciting insight is that the process of mapping out component properties for a Preset annotation—the things that don’t get conveyed in the visual design or in the code—is also something that would need to be done in any attempt to automate more usable annotations.
In other words, if a team uses a design system and wants to automate adding annotations, the tool they use would need to understand their components. In order for it to understand their components well enough to automate accurately, these hidden component properties would need to be mapped out. The task of creating a set of Preset annotations may be a vital stepping stone to something even more streamlined.
A promising new method: Figma’s Code Connect
While building our new set of Preset annotations, we experimented with other ways to enhance Primer with annotations. Though not all of those experiments worked out, one of them did: adding accessibility attributes through Code Connect.
Primer was one of the early adopters of Figma’s new Code Connect feature in Dev Mode. Says Lukas Oppermann, our staff systems designer, “With Code Connect, we can actually move the design and the code a little bit further apart again. We can concentrate on creating the best UX for the designers working in Figma with design libraries and, on the code side, we can have the best developer experience.”
To that end, Code Connect allows us to bypass much of our Preset annotations, as well as the downsides of some of our other experiments. It does this by adding key accessibility details directly into the code that developers can export from Figma.
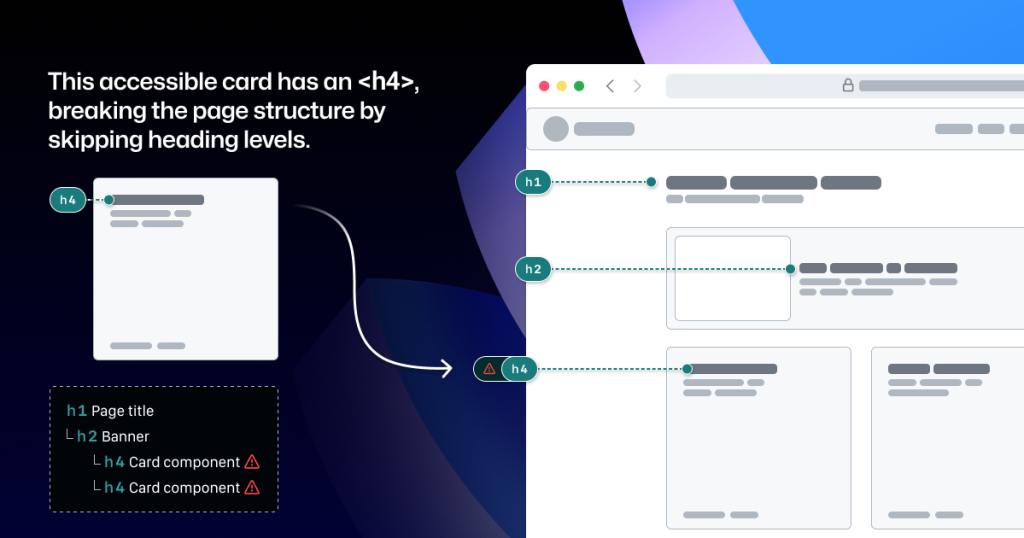
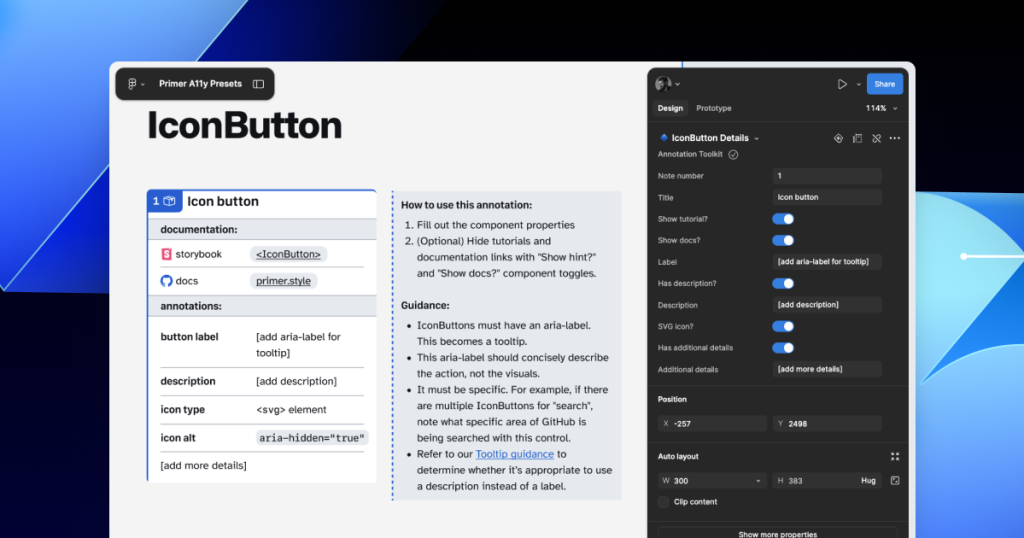
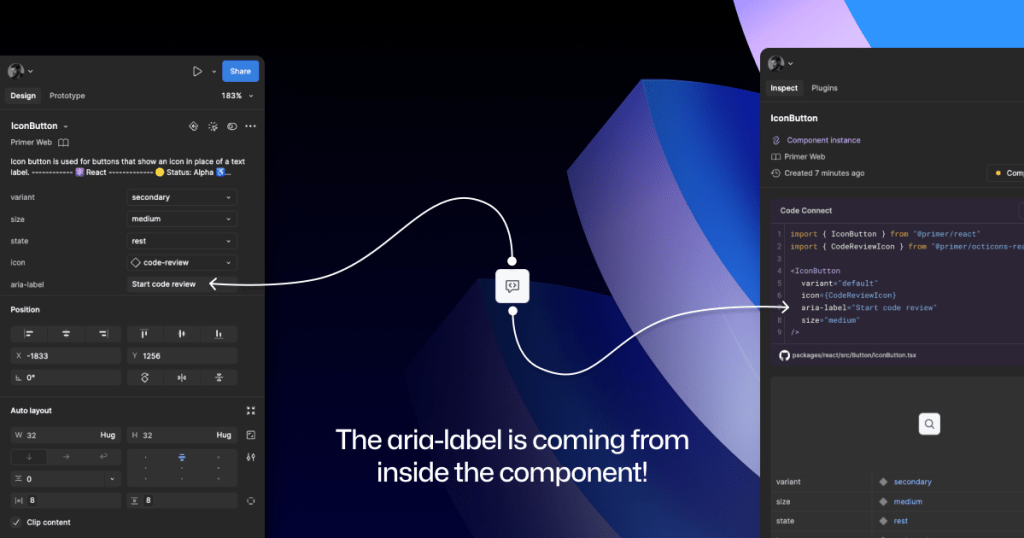
GitHub’s Octicons are used in many of our Primer components. They are decorative by default, but they sometimes need alt text or aria-label attributes depending on how they’re used. In the IconButton component, that button uses an Octicon and needs an accessible name to describe its function.
When using a basic annotation kit, this may mean adding stamps for a Button and Decorative Image as well as a note in the margins that specifies what the aria-label should be. When using Preset annotations, there are fewer things to add to the canvas and the annotation process takes less time.
With Code Connect set up, Lukas added a hidden layer in the IconButton Figma component. It has a text property for aria-label which lets designers add the value directly from the component properties panel. No annotations needed. The hidden layer doesn’t disrupt any of the visuals, and the aria-label property gets exported directly with the rest of the component’s code.
It takes time to set up Code Connect with each of your design system components. Here are a few tips to help:
- Consistency is key. Make sure that the properties you create and how you place hidden layers is consistent across components. This helps set clear expectations so your teams can understand how these hidden layers and properties function.
- Use a branch of your design system library to experiment. Hiding attributes like aria-label is quite simple compared to other complex information that Preset annotations are capable of handling.
- Use visual regression testing (VRT). Adding complexity directly to a component comes with increased risk of things breaking in the future, especially for those with many variants. Figma’s merge conflict UI is helpful, but may not catch everything.
We’ve made the GitHub Annotation Toolkit open source, so you can see first-hand how we’ve implemented our Primer A11y Preset annotations and visual regression tests. Check it out and start annotating today!

Further reading
Accessibility annotation kits are a great resource, provided they’re used responsibly. Eric Bailey, one of the contributors to our forthcoming GitHub Annotation Toolkit, has written extensively about how annotations can highlight and amplify deeply structural issues when you’re building digital products.
The post Design system annotations, part 2: Advanced methods of annotating components appeared first on The GitHub Blog.