Post Syndicated from Grab Tech original https://engineering.grab.com/automated-experiment-analysis
Introduction
Trustworthy experiments are key to making sound decisions, so analysts and data scientists put a lot of effort into analysing them and making business impacts. An extension of Grab’s Experimentation (GrabX) platform, Automated Experiment Analysis is one of Grab’s data products that helps automate statistical analyses of experiments. It also provides automatic experimental data pipelines and customised tests for different types of experiments.
Designed to help Grab in its journey of innovation and data-driven decision making, the data product helps to:
- Standardise and automate the basic experiment analysis process on Grab experiments.
- Ensure post-experiment results are reproducible under a company-wide standard, and easily reviewed by each other.
- Democratise the institutional knowledge of experimentation across functions.
Background
Today, the GrabX platform provides the ability to define, configure, and execute online controlled experiments (OCEs), often called A/B tests, to gather trustworthy data and make data-driven decisions about how to improve our products.
Before the automated analysis, each experiment was analysed manually on an ad-hoc basis. This manual and federated model brings in several challenges at the company level:
- Inefficiency: Repetitive nature of data pipeline building and basic post-experiment analyses incur large costs and deplete the analysts’ bandwidth from running deeper analyses.
- Lack of quality control: Risk of unstandardised, inaccurate or late results as the platform cannot exercise data-governance/control or extend offerings to Grab’s other entities.
- Lack of scalability and availability: GrabX users have varied backgrounds and skills, making their approaches to experiments different and not easily transferable/shared. E.g. Some teams may use more advanced techniques to speed up their experiments without using too much resources but these techniques are not transferable without considerable training.
Solution
Architecture details
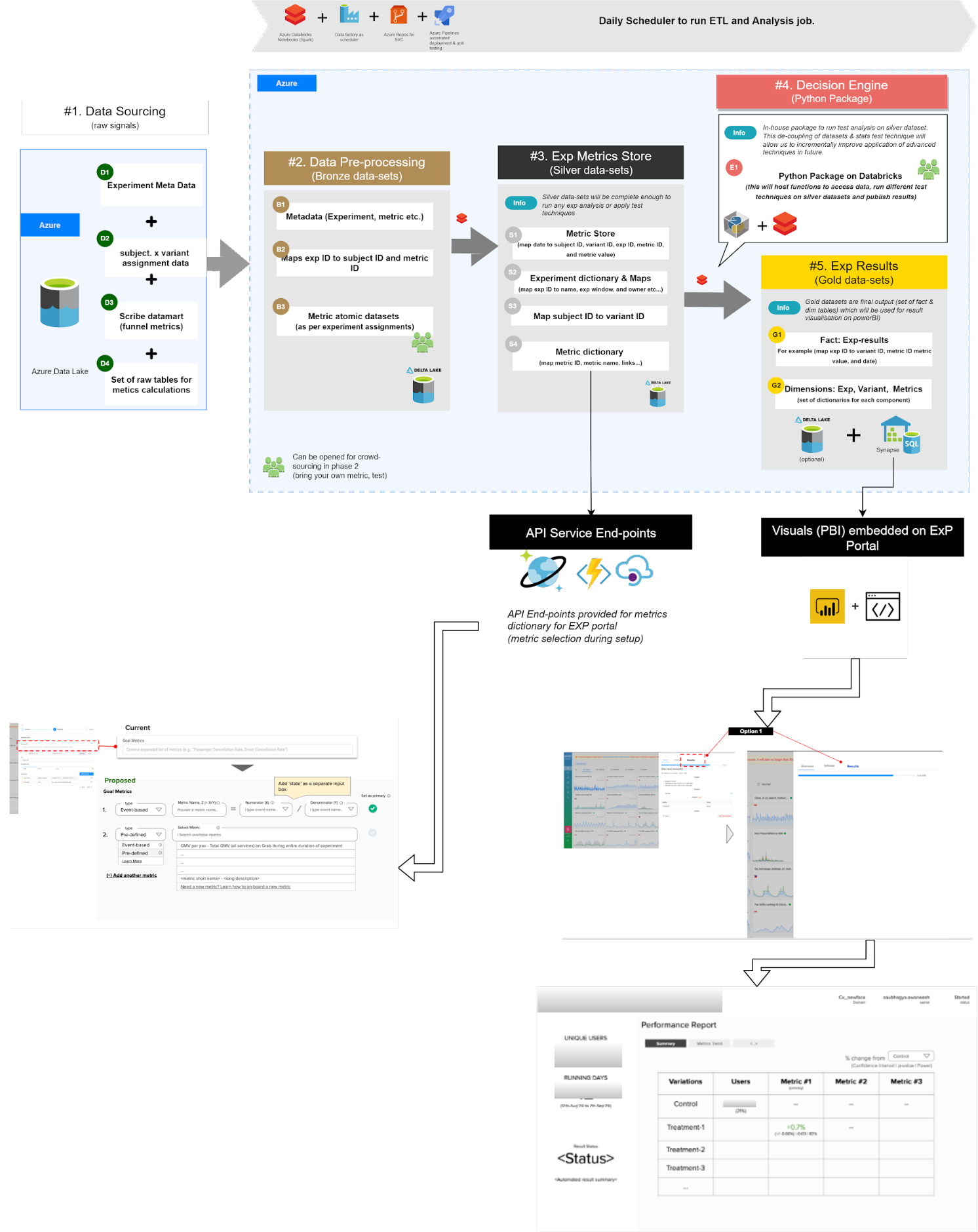
When users set up experiments on GrabX, they can configure the success metrics they are interested in. These metrics configurations are then stored in the metadata as “bronze”, “silver”, and “gold” datasets depending on the corresponding step in the automated data pipeline process.
Metrics configuration and “bronze” datasets
In this project, we have developed a metrics glossary that stores information about what the metrics are and how they are computed. The metrics glossary is stored in CosmoDB and serves as an API Endpoint for GrabX so users can pick from the list of available metrics. If a metric is not available, users can input their custom metrics definition.
This metrics selection, as an analysis configuration, is then stored as a “bronze” dataset in Azure Data Lake as metadata, together with the experiment configurations. Once the experiment starts, the data pipeline gathers all experiment subjects and their assigned experiment groups from our clickstream tracking system.
In this case, the experiment subject refers to the facets of the experiment. For example, if the experiment subject is a user, then the user will go through the same experience throughout the entire experimentation period.
Metrics computation and “silver” datasets
In this step, the metrics engine gathers all metrics data based on the metrics configuration and computes the metrics for each experiment subject. This computed data is then stored as a “silver” dataset and is the foundation dataset for all statistical analyses.
“Silver” datasets are then passed through the “Decision Engine” to get the final “gold” datasets, which contain the experiment results.
Results visualisation and ”gold” datasets
In “gold” datasets, we have the result of the experiment, along with some custom messages we want to show our users. These are saved in sets of fact and dim tables (typically used in star schemas).
For users to visualise the result on GrabX, we leverage the embedded Power BI visualisation. We build the visualisation using a “gold” dataset and embed it to each experiment page with a fixed filter. By doing so, users can experience the end-to-end flow directly from GrabX.
Implementation
The implementation consists of four key engineering components:
- Analysis configuration setup
- A data pipeline
- Automatic analysis
- Results visualisation
Analysis configuration is part of the experiment setup process where users select success metrics they are interested in. This is an essential configuration for post-experiment analysis, in addition to the usual experiment configurations (e.g. sampling strategies).
It ensures that the reported experiment results will align with the hypothesis setup, which helps avoid one of the common pitfalls in OCEs 1.
There are three types of metrics available:
- Pre-defined metrics: These metrics are already defined in the Scribe datamart, e.g. Gross Merchandise Value (GMV) per pax.
- Event-based metrics: Users can specify an ad-hoc metric in the form of a funnel with event names for funnel start and end.
- Build your own metrics: Users have the flexibility to define a metric in the form of a SQL query.
A data pipeline here mainly consists of data sourcing and data processing. We use Azure Data Factory to schedule ETL pipelines so we can calculate the metrics and statistical analysis. ETL jobs are written in spark and run using Databricks.
Data pipelines are streamlined to the following:
- Load experiments and metrics metadata, defined at the experiment creation stage.
- Load experiment and clickstream events.
- Load experiment assignments. An experiment assignment maps a randomisation unit ID to the corresponding experiment or variant IDs.
- Merge the data mentioned above for each experiment variant, and obtain sufficient data to do a deeper results analysis.
Automatic analysis uses an internal python package “Decision Engine”, which decouples the dataset and statistical tests, so that we can incrementally improve applications of advanced techniques. It provides a comprehensive set of test results at the variant level, which include statistics, p-values, confidence intervals, and the test choices that correspond to the experiment configurations. It’s a crowdsourced project which allows all to contribute what they believe should be included in fundamental post-experiment analysis.
Results visualisation leverages PowerBI, which is embedded in the GrabX UI, so users can run the experiments and review the results on a single platform.
Impact
At the individual user level, Automated Experiment Analysis is designed to enable analysts and data scientists to associate metrics with experiments, and present the experiment results in a standardised and comprehensive manner. It speeds up the decision-making process and frees up the bandwidths of analysts and data scientists to conduct deeper analyses.
At the user community level, it improves the efficiency of running experimental analysis by capturing all experiments, their results, and the launch decision within a single platform.
Learnings/Conclusion
Automated Experiment Analysis is the first building block to boost the trustworthiness of OCEs in Grab. Not all types of experiments are fully onboard, and they might not need to be. Through this journey, we believe these key learnings would be useful for experimenters and platform teams:
- To standardise and simplify several experimental analysis steps, there needs to be automation data pipelines, analytics tools, and a metrics store in the infrastructure.
- The “Decision Engine” analytics tool should be decoupled from the other engineering components, so that it can be incrementally improved in future.
- To democratise knowledge and ensure service coverage, many components need to have a crowdsourcing feature, e.g. the metrics store has a BYOM function, and “Decision Engine” is an open-sourced internal python package.
- Tracking implementation is important. To standardise data pipelines and achieve scalability, we need to standardise the way we implement tracking.
What’s next?
A centralised metric store – We built a metric calculation dictionary, which currently contains around 30-40 basic business metrics, but its functionality is limited to GrabX Experimentation use case.
If the metric store is expected to serve more general uses, it needs to be further enriched by allowing some “smarts”, e.g. fabric-agnostic metrics computations 2, other types of data slicing, and some considerations with real-time metrics or signals.
An end-to-end experiment guide rail – Currently, we provide automatic data analysis after an experiment is done, but no guardrail features at multiple experiment stages, e.g. sampling strategy choices, sample size recommendation from the planning stage, and data quality check during/after the experiment windows. Without the end-to-end guardrails, running experiments will be very prone to pitfalls. We therefore plan to add some degree of automation to ensure experiments adhere to the standards used by the post-experimental analysis.
A more comprehensive analysis toolbox – The current state of the project mainly focuses on infrastructure development, so it starts with basic frequentist’s A/B testing approaches. In future versions, it can be extended to include sequential testing, CUPED 3, attribution analysis, Causal Forest, heterogeneous treatment effects, etc.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!
References
-
Dmitriev, P., Gupta, S., Kim, D. W., & Vaz, G. (2017, August). A dirty dozen: twelve common metric interpretation pitfalls in online controlled experiments. In Proceedings of the 23rd ACM SIGKDD international conference on knowledge discovery and data mining (pp. 1427-1436). ↩
-
Metric computation for multiple backends, Craig Boucher, Ulf Knoblich, Dan Miller, Sasha Patotski, Amin Saied, Microsoft Experimentation Platform ↩
-
Deng, A., Xu, Y., Kohavi, R., & Walker, T. (2013, February). Improving the sensitivity of online controlled experiments by utilising pre-experiment data. In Proceedings of the sixth ACM international conference on Web search and data mining (pp. 123-132). ↩