Post Syndicated from Taylor Blau original https://github.blog/2021-04-29-scaling-monorepo-maintenance/
At GitHub, we serve some of the largest Git repositories on the planet. We also serve some of the fastest-growing repositories. Each day, the largest repositories we host become even larger.
About a year ago, we noticed that the job we use to repack Git repositories began hitting our self-imposed timeouts on larger repositories. Even when expanding these timeouts, failing maintenance on these repositories has generally been the cause of degraded performance that is hard to mitigate.

Today, these problems do not exist. GitHub can repack even the largest repositories we host in a fraction of the time it used to take. In this post, we’ll talk about what problems we were encountering, the solutions we built, how we deployed them safely, and describe some possible future directions.
All of our work here is being contributed to the open source Git project, and will be available in an upcoming release.
The problem
Why is GitHub’s maintenance job so expensive in the first place? It’s because we chose to have maintenance repack the entire contents of each repository into a single packfile. Doing so is expensive, but having just one packfile carries some benefits, too. With only one packfile, looking up objects doesn’t require opening and searching through multiple packs to find it. It also means that all objects can be compressed as a delta relative to all other objects (Git’s packfile format supports cross-pack deltas, but currently Git will never store them on disk). But, the most important reason is that reachability bitmaps, a performance-critical data structure, are only compatible with a single pack.
A new feature in Git, multi-pack indexes solves the former problem by making all object lookups go through a single index, but didn’t yet solve the latter. So, we set out to fill in the gaps by bringing bitmap support to multi-pack indexes in order to remove the single-pack limitation on reachability bitmaps.
But in order to build multi-pack bitmaps, we had to solve a number of other interesting problems along the way. First, we had to decide how to arrange the objects in a multi-pack index to achieve good bitmap compression. We also had to figure out how to quickly invert that ordering to translate between bit positions back to the objects they refer to. Some of these steps also yielded notable performance improvements on single-pack repositories, too. Finally, we had to figure out a new repacking strategy that scaled with the size of recent pushes, rather than with the size of the entire repository.
But before we get into all of that, let’s start from the very beginning.
Objects, packs, and fetching
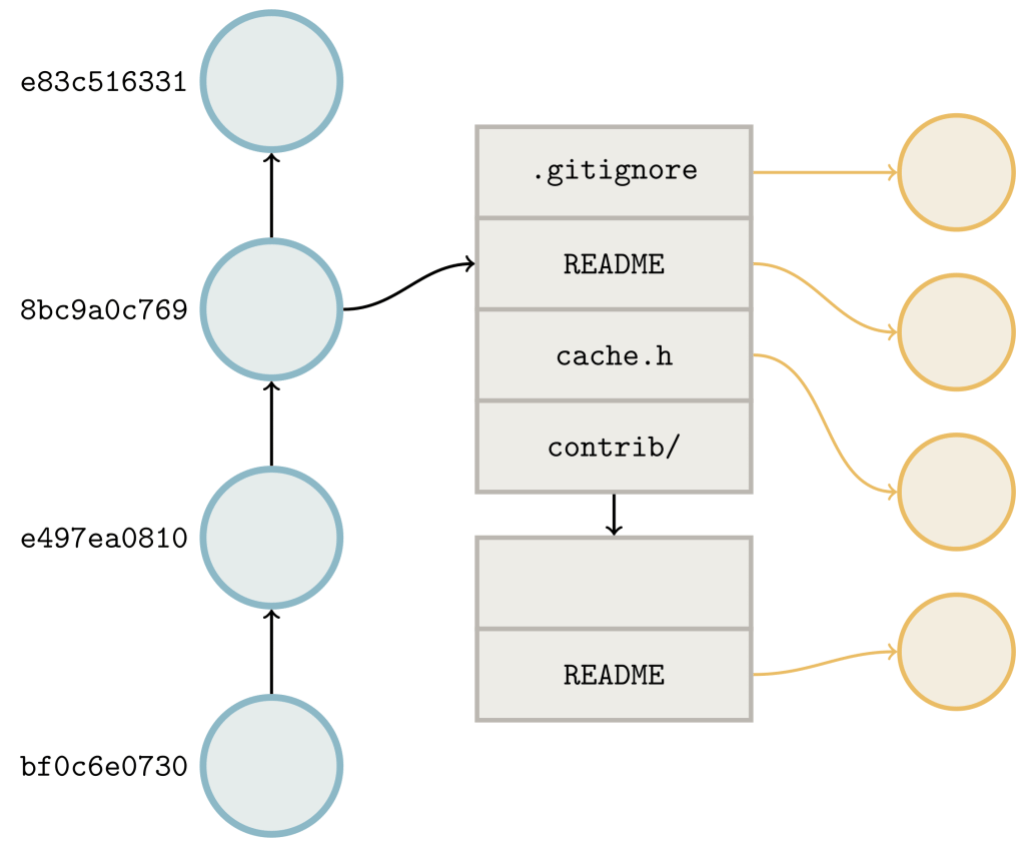
You might be aware that Git stores the contents of your repositories as a set of objects. Each object represents an individual piece of your repository: a single file, tree, commit, or tag. These objects may be stored individually as “loose” objects, or together in a packfile.
If you’ve ever heard that a Git repository is “nothing more than a directed acyclic graph,” then you know that these objects can refer to one another. A tree refers to a set of blobs (which correspond to files) and other trees (which correspond to sub-directories). A commit refers to a single tree (the repository root), and zero or more other commits which are its parents.

These links help Git figure out which objects it needs to transfer to fulfill a fetch or clone request. When you fetch a repository from GitHub, Git performs a negotiation to figure out which objects to send. The server advertises the objects at the tip of its references (basically the tips of branches and tags). The client does the same, along with the set of references that it wants from the server. Then, the server walks the links between the requested objects and the objects that the client already has in order to figure out what to send.

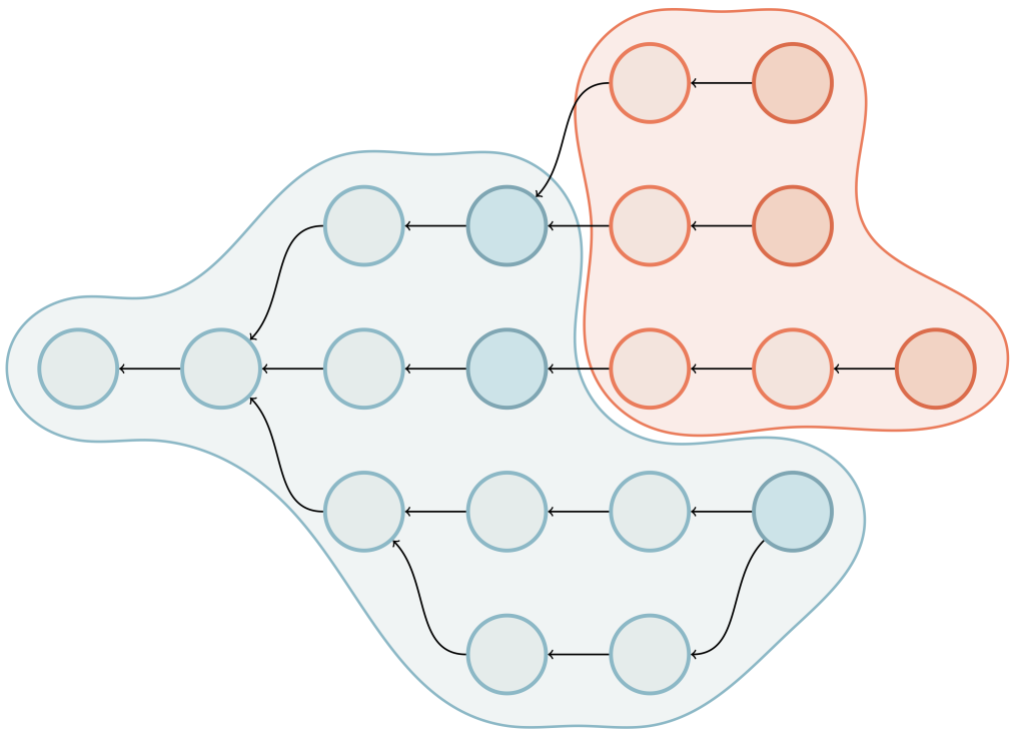
Above is an object graph. The client advertises its ref tips (indicated by the darker blue commits). The server’s advertised references are colored dark red. The blue shaded area represents the result of walking along the edges to obtain the reachability closure of the objects the client already has. The red shaded area represents the same closure from the server’s perspective, excluding objects that the client already has. Objects in this region are the ones which need to be sent to the client.
During a fetch, Git needs to send not just the commits in between what the client has and wants, but also all of the objects that are reachable from those commits. Because Git doesn’t store the list of every reachable object, this may be expensive, especially in the case of a clone. When cloning, the client doesn’t have any objects, so it asks the server for all of the objects reachable from any reference.
In an earlier blog post, we talked about how we use reachability bitmaps to accelerate this negotiation. In case you haven’t read that post, below is a quick primer.
Reachability bitmaps
How does Git handle this special case where the client has nothing and wants everything? Ultimately, the server needs to determine the reachability closure of all of the reference tips. In other words, it needs a list of all of the objects at the reference tips, and all of the ancestors of those objects in order to assemble a complete copy of the repository at the other end.
Unfortunately for us, the larger the repository is, the longer it takes Git to compute the list of objects to send. This isn’t feasible even for medium-sized repositories. Git could handle our case specially by just sending every object it has, but that might result in many unwanted objects being sent, too. (For example, GitHub stores the outcome of “test merges” in special refs which aren’t ordinarily sent during fetches, but whose objects are stored in the same object directory nonetheless.)
Instead, Git stores a set of reachability bitmaps corresponding to some of the commits in a packfile. The idea is rather simple: arrange the objects in a pack in some order (the particular order used is something we’ll discuss shortly in detail). Then, the ith bit in the bitmap corresponding to commit C is 1 if C can reach the ith object, and 0 otherwise.
Having a one-to-one correspondence between objects and bit positions has a couple of appealing properties: taking the union of reachable objects between commits is as simple as ORing their bitmaps together, and taking the difference is as simple as combining AND and NOT. So, when a bitmap exists, Git can dramatically speed up the object negotiation phase:
- First,
OR all of the bitmaps corresponding to the reference tips that the client wants. Call this new bitmap W.
- Then, do the same with the bitmaps corresponding to the reference tips that the client advertised as already having. Call this bitmap
H.
- Finally, compute
W AND NOT H to produce the set of objects the client needs (in other words, everything it wants but does not already have). Then, send those objects.
Because all of the reachability information is encoded directly into the bitmaps, Git saves time by avoiding the need to open up and parse objects, allowing it to produce the same result in a fraction of the time.
This idea has been used since at least the 1970s to speed up queries in relational databases. In Git, reachability bitmaps can provide dramatic speed-ups when walking objects that reside in the same pack: walking all of the objects in the Linux kernel repository took more than 33 seconds without bitmaps, but only 1.57 seconds to perform the same traversal with bitmaps.
The object order
How does Git turn a set of objects into a sequence of bit positions? One way you might imagine to do this is assign bit positions in lexicographic order. The first bit corresponds to 000023961a, the second to 0000d6543f, the third to 000182eacf, and so on in lexical order.
Why not do this? Recall that an object’s ID is determined by a SHA-1 of its contents, which means that reachability of any object in this order is only reachable to nearby objects by chance. And reachability of nearby objects matters: Git compresses the bitmaps using EWAH compression, which relies on having long runs of identical bits. If the object order makes reachability look essentially random from bit to bit, Git won’t be able to efficiently compress the bitmaps.
Pack order—that is, the physical arrangement of objects in a packfile—produces a sequence of bit positions that tends to place reachable objects next to each other. And this produces exactly the kind of long runs of identical bits that make EWAH compression perform well.
The problem
But, all of this creates a problem for us: if the order of bit positions is dictated by a pack, then bitmaps are coupled in implementation and in concept to the existence of a single packfile. So, any objects that accumulate outside of the bitmapped pack won’t benefit from the same speed-ups.
To address this, we periodically repack the repository’s entire contents into a single pack, and then generate a new reachability bitmap. This makes reachability queries in more recent parts of the repository’s history faster.
But generating that new pack takes time; in fact, it’s quadratic. Bigger repositories take longer to repack, but also grow at a faster rate, which means they run maintenance more often. This compounding effect sometimes makes it such that some repositories are constantly undergoing maintenance: by the time one maintenance job has finished, another is already sitting in the queue, waiting to be run.
Since the bottleneck for maintenance is the compression of an entire repository’s contents into a single packfile, what would it take to be able to repack the contents into multiple packfiles instead?
Multi-pack indexes
To order a set of objects spanning multiple packs, we looked to a recent Git feature: multi-pack indexes.
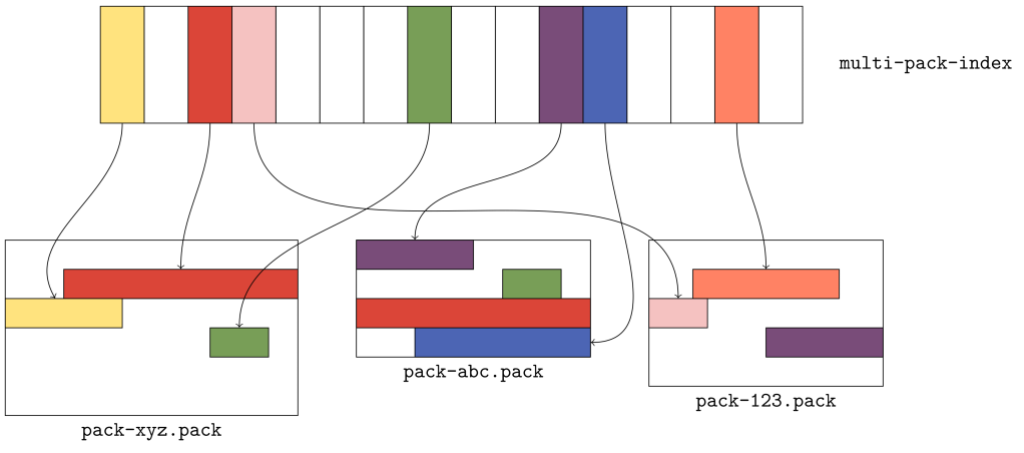
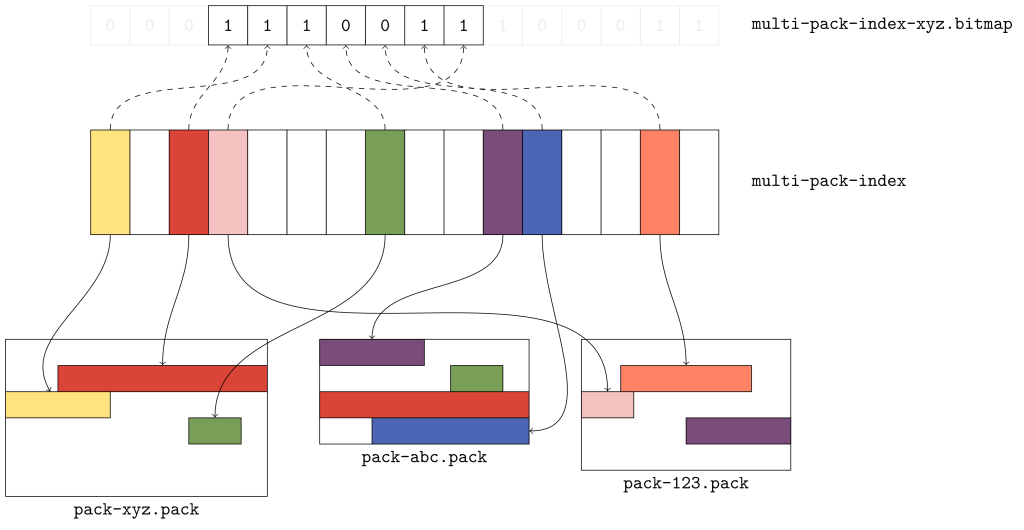
When Git wants to locate an object by name in a single pack, it uses that pack’s index (.idx) file, which provides a binary-searchable list of object locations. Multi-pack indexes work similarly to .idx files, but the location they indicate is a pair containing both the pack containing the object, as well as where in that pack the object can be found.

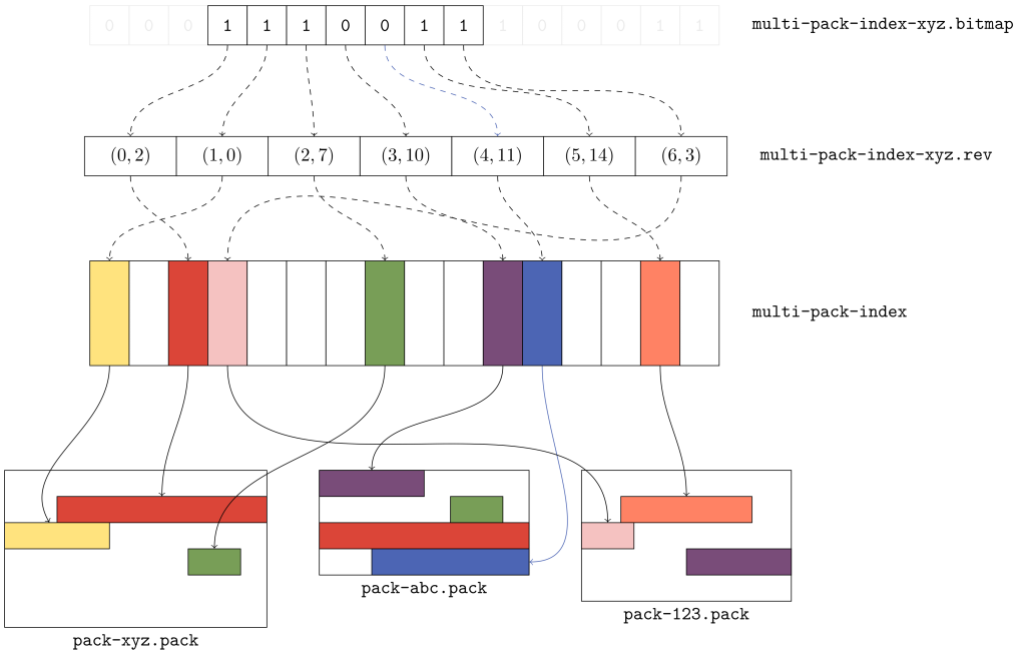
The figure above gives a flavor for what kind of data is organized in a multi-pack index. Here, there are three packs, each with a handful of objects. The multi-pack index stores the location of each unique object among the set of packs. When multiple copies of an object exist (like the green or red objects in packs xyz and abc), ties are broken in favor of the copy in the pack with the earliest modification time.
The order of objects in the multi-pack index differs from the order in each individual pack. Since a pack is free to store objects in any order it wants, the multi-pack index stores objects in lexicographic order so that an object can be found quickly by name using a binary search.
Ordering objects
Given a multi-pack index, how should we order the objects in the packs it contains? We discussed earlier that ordering objects lexicographically results in poor compression. We also noted that objects in packs are ordered topologically, which for our purposes we can consider to imply that individual objects tend to appear near other objects which they reach in this order.
So, any ordering of the objects in a multi-pack index should capture as much of those two properties as possible. With that in mind, we decided on the following order:
- Objects are first grouped according to which packfile they appear in, and packs are ordered according to the multi-pack index.
- Objects within the same pack should be ordered according to their locations within that pack.
This effectively concatenates the pack-order of multiple packs together, according to some other ordering defined on the packs themselves.
To see what this looks like, let’s overlay a portion of a bitmap that covers the objects in our earlier example:

The first three bits correspond to the red, yellow, and green objects, respectively. Each one of those objects comes from the xyz pack, which means that the xyz pack has the oldest modification among the three. Scanning the bitmap from left to right, these objects appear in pack order; that is, the byte offset of the red object is less than the byte offsets of the yellow and green objects that follow it.
The purple and blue objects come next, since they are in the pack that follows. But note that the copies of the red and green objects in the abc pack don’t correspond to any bits highlighted. Why? Because the multi-pack index selected the copy of those objects in the earlier pack.
Finally, the orange and pink objects appear, also in pack order. And, as we expect, the copy of the purple object that appears in pack 123 isn’t included in the bitmap, because the copy in pack abc was.
This ordering gives us great locality, but we still need to address how to map bit positions back to the objects they represent. For example, let’s look at the fifth bit position, which we know refers to the blue object: how could Git discover this same fact?
You could reasonably imagine that knowing how many total objects are in each pack would be good enough to figure out which objects each bit corresponds to. But that isn’t enough information; we don’t know how many unique objects selected by the multi-pack index appear in each pack, and we also don’t know which non-unique objects are missing. So it’s not good enough to count past the three bits corresponding to objects in pack xyz and then count two more bits up to the fifth bit, because that would point at the copy of the green object in pack abc.
Reverse indexes
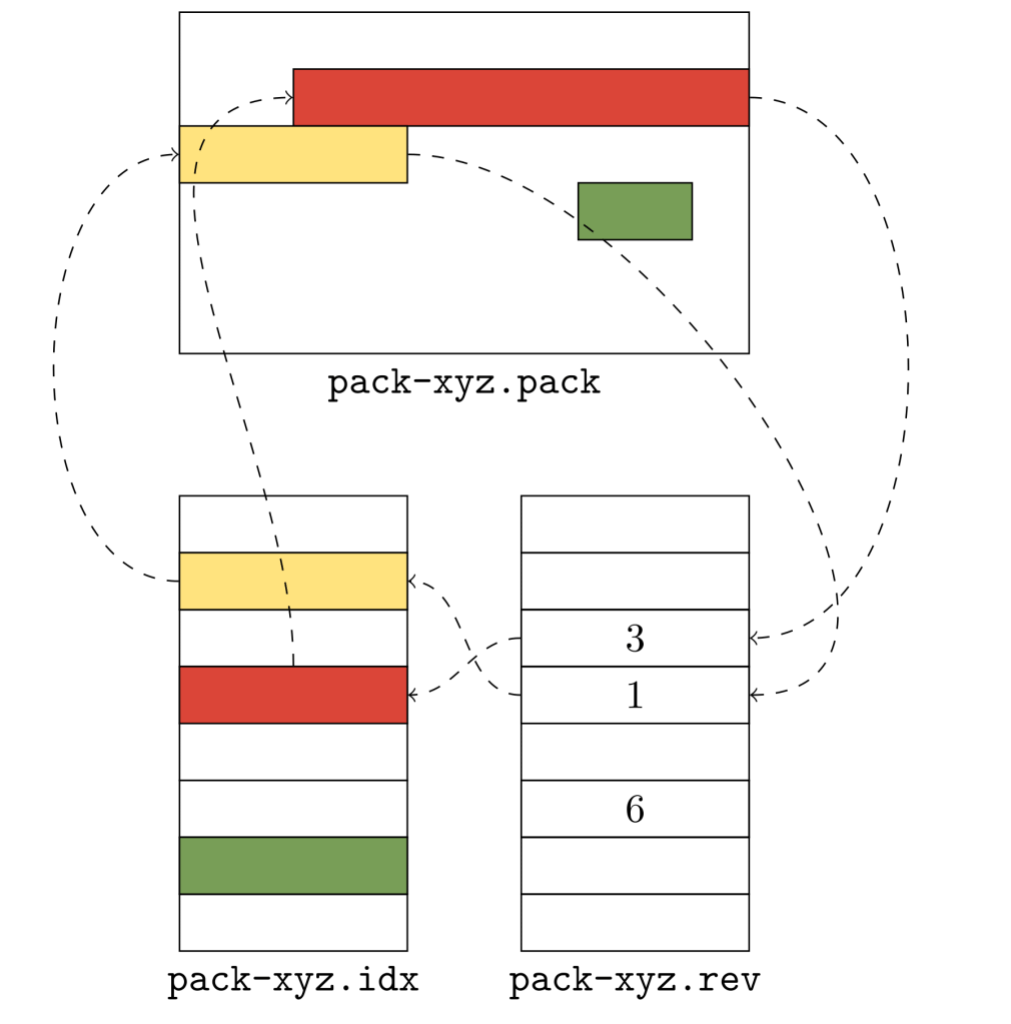
To solve this problem, we introduced reverse indexes. In the same way that the pack index provides a mapping from object name to object location, the reverse index maps an object’s location back to its name.
The idea is simple: in addition to the pack’s contents (stored in a .pack file) and index (stored in an .idx file), we’ll write an array of numbers (which comprise the reverse index, and are stored in a new .rev file). These numbers provide a mapping between an object’s position in pack order and its position in lexicographic order.
To better understand this, let’s take a look at an example on a single pack.

The .idx file (shown in the lower left) lists objects in lexicographic order: the yellow object comes before the red one, and the red one comes before the green one. But their pack order is different: there, the red object comes before the yellow one instead of the other way around. The reverse index helps us unwind the two: it tells us that the red object is in the position 3 in lexicographic order, and the yellow object is in position 1.
The reverse index allows us to map quickly from offsets into the packfile to object positions they correspond to. That allows us to quickly determine the size of a packed object. For example, say that you want to figure out how large the red object is. Because Git doesn’t store that information directly, you have one of two options: either scan linearly through the packed data (inflating its contents until you locate the stream end), or locate the adjacent object (in this case, the yellow one) by name, and measure the difference of their offsets.
Without the reverse index, there is no way to figure out where the adjacent object starts. But with a reverse index, locating the red object is as simple as reading the adjacent entry in the reverse index to discover the offset. Here, that value is 1, which points at an entry in the .idx file, which in turn points at the location in the pack.
Before the on-disk reverse index, Git computed this table on the fly and stored the results in an array in memory. This had a couple of major downsides. To build a reverse index on the fly, Git has to allocate a pair of pack offset and index position. This requires memory and runtime, which both scale relative to the size of the pack. Even though this processes using radix sort, sorting the reverse index entries can be noticeably slow when done once per process.
Some initial testing of these reverse indexes showed that they could enable rather dramatic speed-ups when serving fetches on real-world repositories. To verify our early results, we gradually rolled out reverse indexes on a handful of repositories.
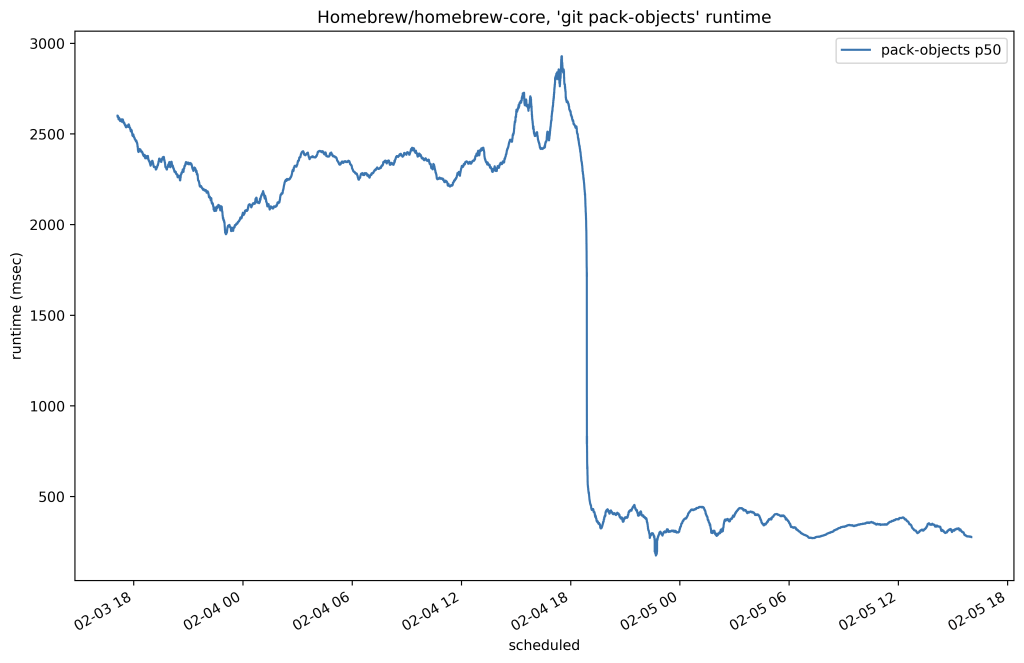
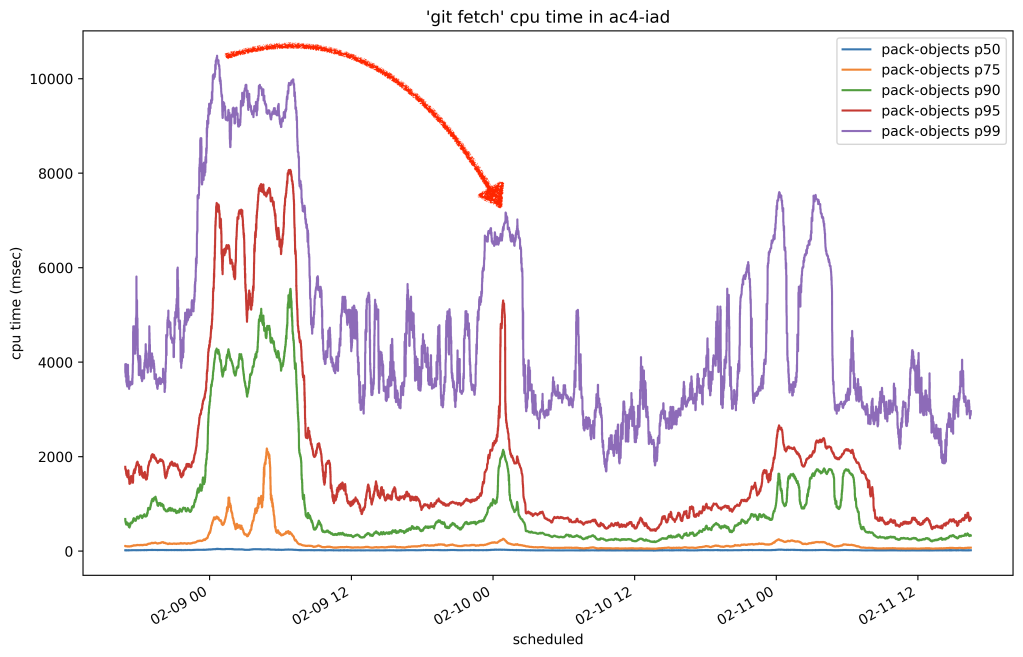
Below is the 50th percentile of CPU time for fetches to Homebrew/homebrew-core on our testing host before and after the change:

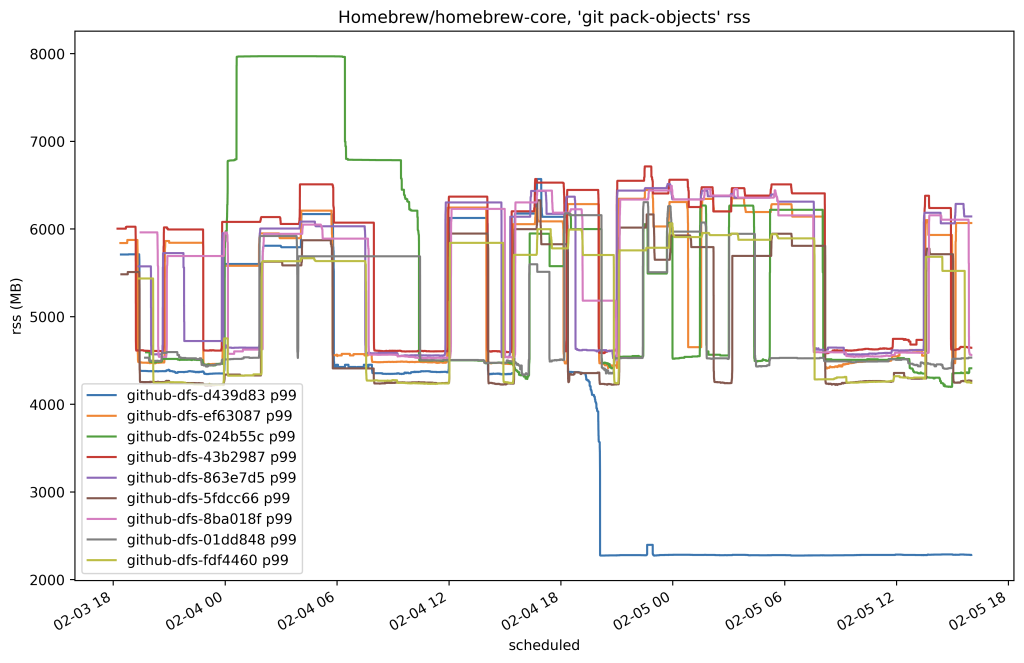
In this case, we reduced the amount of time it took to serve any fetch of that repository by around 80%. Here’s another plot from the same time which shows the resident set size of the program used to serve fetches by replicas of that same repository:
Encouraged by our first results in production, we proceeded to cautiously roll out on-disk reverse indexes to all other replicas. Once we completed the roll-out, we let a couple of days pass in order for replicas to have enough time to generate reverse indexes. Then, we sampled the overall CPU time it took to serve fetches across all repositories and observed the drop we were hoping for:

In the graph above, you can see three 24-hour cycles. The first day was before we rolled out .rev files, and the second two peaks are after. The per-day peaks dropped from around 10.8 seconds to 7 seconds, for a collective savings of around 35% on all repositories.
Multi-pack bitmaps
Now that we have a format for .rev files, we can reuse it as the missing piece we need to build multi-pack bitmaps. Instead of writing positions relative to a pack .idx file, a multi-pack reverse index writes positions which are relative to a multi-pack-index file.
This provides exactly the information we need to rediscover the mapping between bit positions and the objects they refer to in the multi-pack index. To see why, let’s take a look at another example:

To figure out that the fifth bit corresponds to the blue object in the above diagram, we read the fifth entry in the multi-pack reverse index and get back that the fifth bit maps to the eleventh object in the multi-pack index. And, sure enough, the 11th object points back to the blue object that we were looking for in pack abc.
Putting it all together, this gives us a bitmap which can refer to objects in multiple packs. Based on its filename, each bitmap knows whether or not it belongs to a pack (and if so, which one) or to a multi-pack index. And based on that information, it can translate its object lookups to be relative to a packfile, or to the multi-pack index via its reverse index.
Since we chose the ordering carefully, these multi-pack bitmaps compress exactly as well as their single-pack counterparts. And they decouple bitmaps from individual packs. So, a repository can still have at most one bitmap, but that bitmap can now correspond to multiple packs.
Geometric repacking
Now that we can include multiple packs in a single bitmap, what’s the best way to repack a repository during maintenance?
With single-pack bitmaps, the only option was to pack everything together into one enormous pack. But now that this restriction no longer exists, we have to figure out the best way to repack the objects. When deciding on a new repacking strategy, we wanted something that struck a balance between two properties:
- On average, there is a relatively small number of packs in the repository.
- On average, we create a pack that collects objects that were pushed since the last maintenance run.
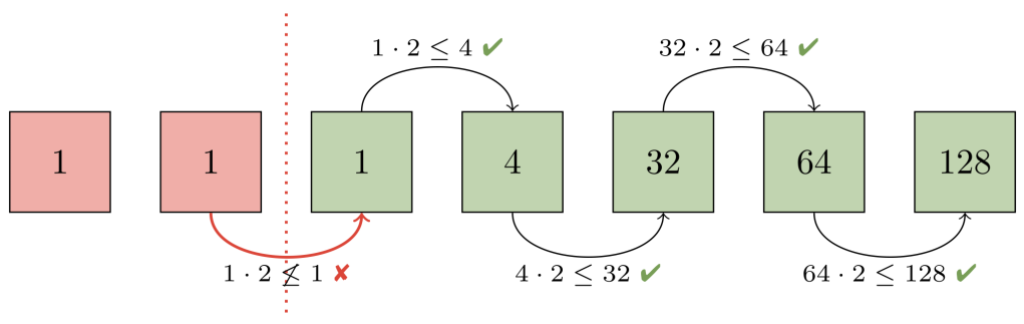
We decided on an invariant to ensure that the packs in a repository form a geometric progression by object size. In particular, if you sort the packs by number of objects, with the first pack having the most and the final pack having the least, then each pack will contain at least twice as many objects as the next one.
We taught git repack a new --geometric= mode, which creates exactly this geometric progression. Soon (at the time of writing, these patches are still being submitted and reviewed), you’ll be able to try this yourself on your own repository by running:
$ packsizes() {
find .git/objects/pack -type f -name '*.pack' |
while read pack; do
printf "%7d %s\n" \
"$(git show-index < ${pack%.pack}.idx | wc -l)" "$pack"
done | sort -rn
}
$ packsizes # before
$ git repack --write-midx --write-bitmap-index -d --geometric=2
$ packsizes # after
How does this command work? We select a set of packs and combine their objects into one new pack that replaces the set. But picking this set optimally is NP-hard, so we have to approximate it.
To see how we perform that approximation, let's walk through an example. The first step is to figure out how many packs already form a geometric progression. To do this, imagine ordering packs by how many objects they contain. Then, consider each adjacent pair of packs from largest to smallest. At each step, ask: "is the larger pack at least twice the size of the smaller one?". If so, then every pack from that pair onwards already forms a geometric progression.

In this example, the second and third packs (each containing one object) violate our progression. At that point, we know that the second pack, and any packs below it must be repacked together in order to restore the progression.
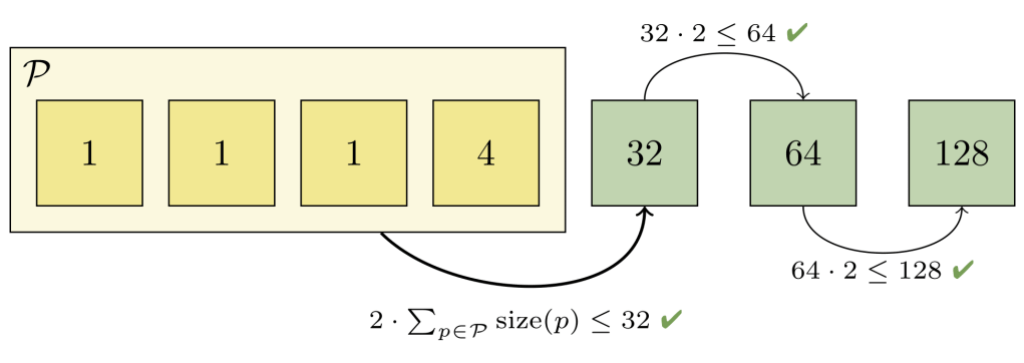
But we can't just repack the first two packs together, since the combined pack would still be too big (it would contain two objects, and the third pack only contains one). So we grow the set of packs to combine until the invariant is restored:

Here, we had to combine the first four packs together in order to restore a geometric progression. Those packs together contain 7 objects, which is less than half of the next-largest pack (which contains 32 objects). And we can't combine any more packs, since doing so would violate the remainder of the progression.
At this point, we can write a new pack containing just the objects in the set of packs we combined in the previous step. After discarding the now-redundant packs, the remaining packs again form a geometric progression:

This means that the number of packs grow logarithmically over time, so a repository will never have too many packs at any one point in time. It also has the appealing property that older objects tend to get pushed into the larger packs, meaning they get repacked less frequently as time passes. An important corollary of this is that each repack tends to focus on the most recently pushed objects. In other words, this strategy tends to make repacking take time proportional to the number of new objects, not the number of overall objects.
In order to keep the repository performing well over many geometric repacks, we intersperse an all-into-one repack once for every eight geometric repacks.
Importantly, this means that even though the classically-slow repacks are still slow, we aren't forced to run them every time we want to repack a repository.
Deploying to production
Now that we have a way to write a bitmap that covers the objects in multiple packs, a way to quickly map between bit positions and the objects they refer to in a multi-pack index, and a repacking strategy which only requires modifying recent additions to the repository, we are ready to put everything together.
Before rolling out a change as large as this one, we performed extensive local testing to ensure that writing bitmaps worked correctly, and that our new repacking strategy wasn't silently corrupting repositories. But our local testing can only go so far: there are endless corner cases when serving fetches and clones, so the real test occurs only after putting real traffic in front of these new paths. Our goal was to design a deployment strategy that simultaneously exercised enough of those cases, while also ensuring that any potential corruption could never occur on a majority of repository replicas.
Our first test cases were internal repositories. We broke our original tests into two phases. In the first phase, we wrote "multi-pack bitmaps" which contained only a single pack. This allowed us to exercise the most basic case of multi-pack bitmaps (having only one pack) without running our new repack code. Once we had built confidence in that approach, we expanded our test to alternate between geometric and full repacks.
After a couple of weeks without any issues, we were confident enough in our change to start testing it on other repositories external to GitHub. We selected first an individual host, and then a whole rack of hosts on which every repack would alternate between geometric and full. At this stage, results were encouraging: the average time to repack had dropped significantly, as had the overall amount of time spent repacking.
By this stage, our roll-out proceeded for several weeks in only one of three data centers. Because we never place a majority of repository replicas in any single datacenter, this configuration made it impossible for our changes to corrupt a majority set of replicas in an unrecoverable fashion, while still putting our changes in the request path for a large amount of traffic.
Finally, after adopting this configuration for a week, we proceeded to enroll percentages of replicas hosted in other datacenters to also use multi-pack bitmaps until all repositories were using multi-pack reachability bitmaps.

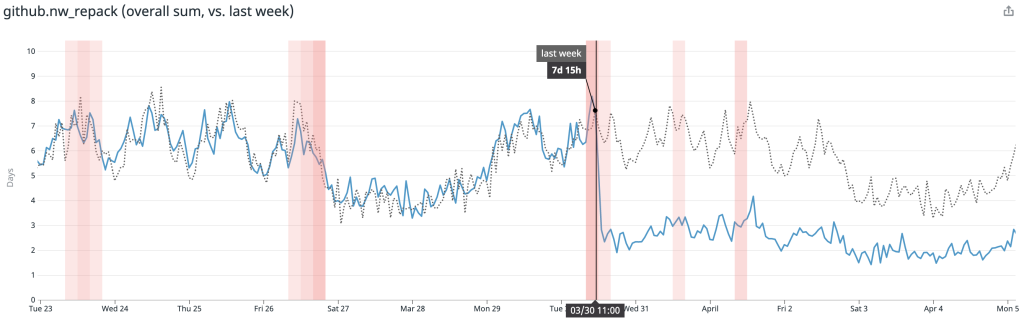
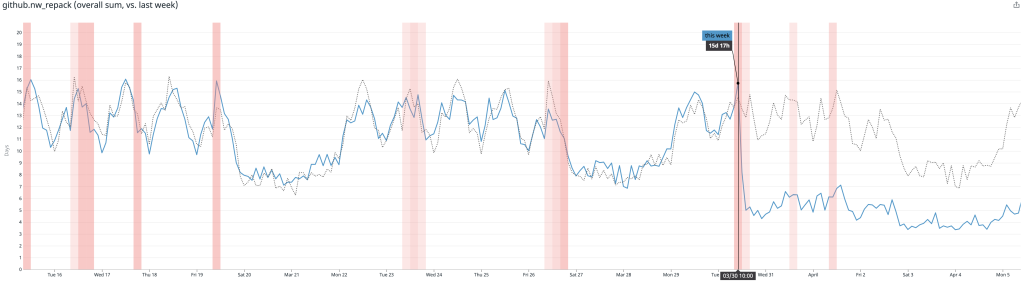
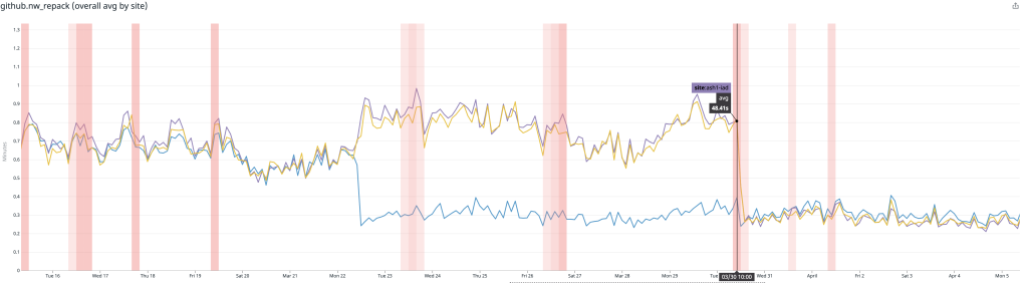
After rolling out our new repacking strategy with multi-pack bitmaps, we saved on average 5.67 CPU days every hour compared to the old strategy.
Likewise, the average time spent repacking any single repository also dropped considerably. Below, the plot is broken out per-site, and you can see when we began testing in a single site, as well as when we expanded our deployment to all sites.

There, the average dropped from around 1 minute to repack a repository to just 15 seconds.
Future directions
There are two major open areas we're considering for the future that will make it possible for further performance improvements:
One open area is the bitmap computation itself. Git's bitmap generation code can reuse existing bitmaps by permuting their bits into a new order, but this operation can still take time proportional to the size of the repository. One way to solve this would be to write bitmaps incrementally, only walking the new objects introduced since the last time a bitmap was written. This problem is tricky because it requires not only that the bitmap file be able to be written incrementally, but also that the object ordering we select is stable: that is, that introducing new bitmaps won't render the existing ones meaningless.
Another open area is the pack structure. Creating packs that form a geometric sequence is a promising step forward that allows us to trade off between full and partial repacks. But some repositories are so large that repacking the whole repository isn't feasible, much less desirable. Designing a strategy which freezes the packs containing the oldest objects in a repository's history will allow us to grow to support even larger repositories in the future.
Thank you
This project would not have been possible without help from the upstream Git community, as well as many engineering teams within GitHub. Each of these changes required extensive review, both to the Git project, as well as to internal GitHub services. Special thanks to Jeff King, Derrick Stolee, Jonathan Tan, Junio Hamano, and others for making this possible.