Post Syndicated from Ashley Whittaker original https://www.raspberrypi.org/blog/what-the-blink-is-my-ip-address/
Picture the scene: you have a Raspberry Pi configured to run on your network, you power it up headless (without a monitor), and now you need to know which IP address it was assigned.
Matthias came up with this solution, which makes your Raspberry Pi blink its IP address, because he used a Raspberry Pi Zero W headless for most of his projects and got bored with having to look it up with his DHCP server or hunt for it by pinging different IP addresses.
How does it work?
A script runs when you start your Raspberry Pi and indicates which IP address is assigned to it by blinking it out on the device’s LED. The script comprises about 100 lines of Python, and you can get it on GitHub.
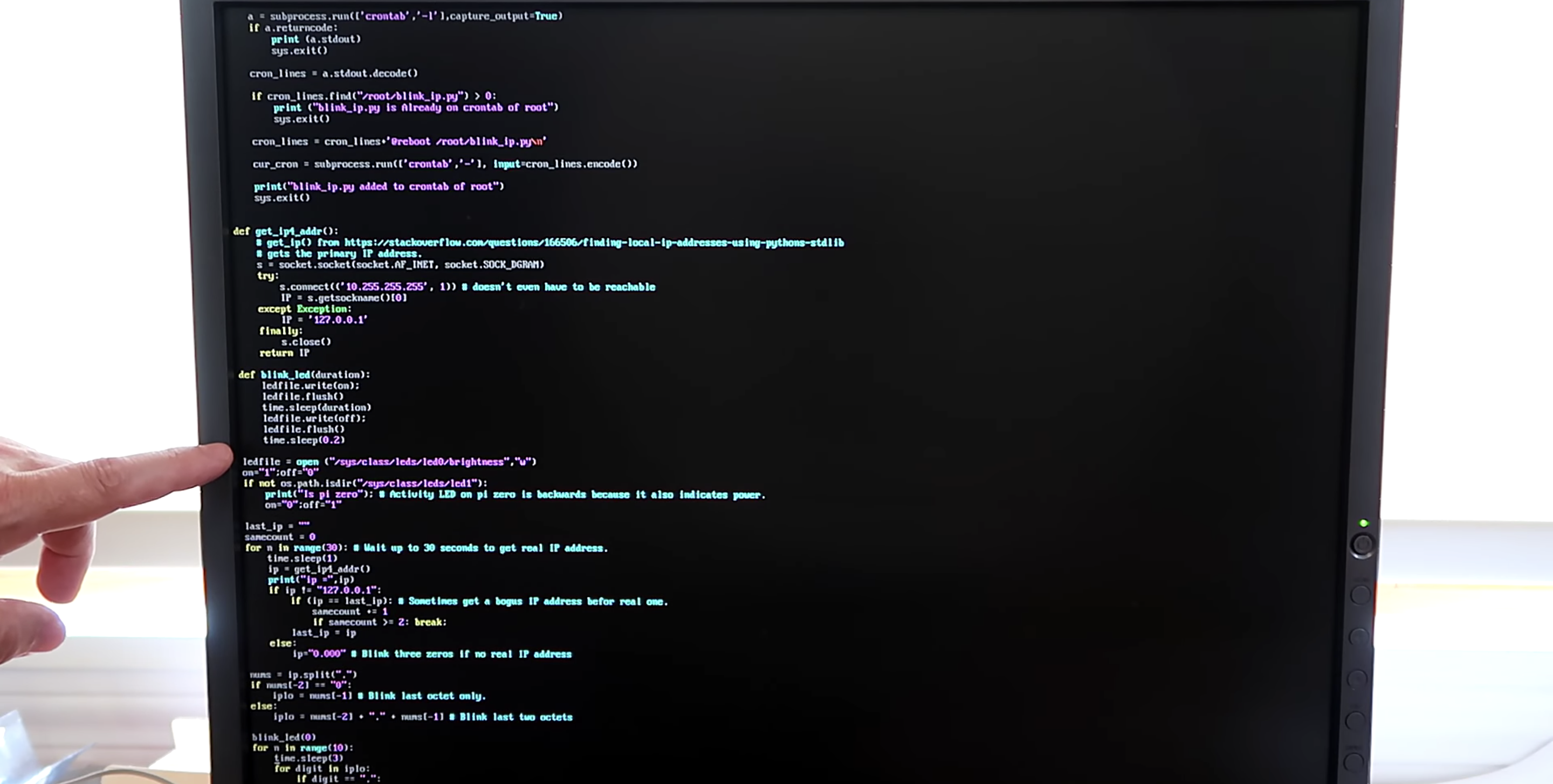
The power/status LED on the edge of the Raspberry Pi blinks numbers in a Roman numeral-like scheme. You can tell which number it’s blinking based on the length of the blink and the gaps between each blink, rather than, for example, having to count nine blinks for a number nine.
Blinking in Roman numerals
Short, fast blinks represent the numbers one to four, depending on how many short, fast blinks you see. A gap between short, fast blinks means the LED is about to blink the next digit of the IP address, and a longer blink represents the number five. So reading the combination of short and long blinks will give you your device’s IP address.
You can see this in action at this exact point in the video. You’ll see the LED blink fast once, then leave a gap, blink fast once again, then leave a gap, then blink fast twice. That means the device’s IP address ends in 112.
What are octets?
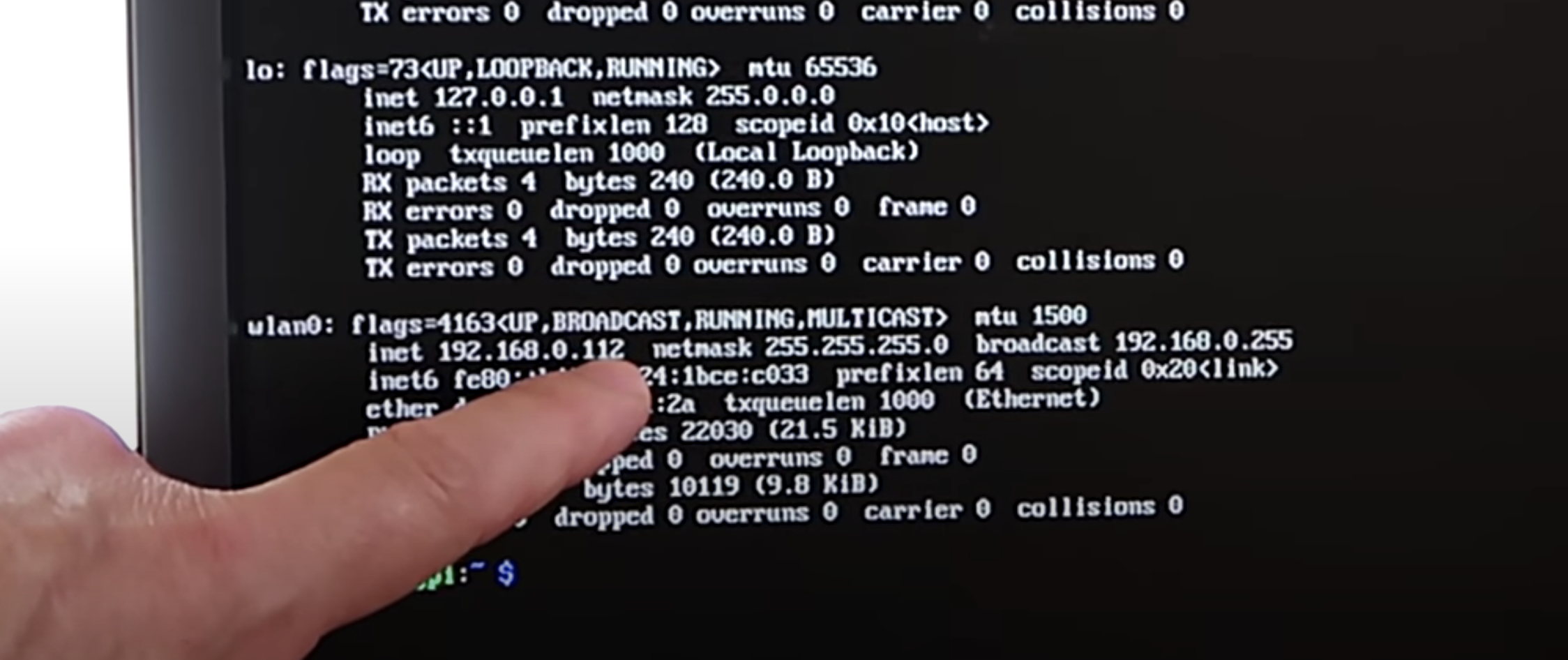
Luckily, you usually only need to know the last three numbers of the IP address (the last octet), as the previous octets will almost always be the same for all other computers on the LAN.

The script blinks out the last octet ten times, to give you plenty of chances to read it. Then it returns the LED to its default functionality.
Which LED on which Raspberry Pi?
On a Raspberry Pi Zero W, the script uses the green status/power LED, and on other Raspberry Pis it uses the green LED next to the red power LED.

Once you get the hang of the Morse code-like blinking style, this is a really nice quick solution to find your device’s IP address and get on with your project.
The post What the blink is my IP address? appeared first on Raspberry Pi.