Post Syndicated from Matheus Guimaraes original https://aws.amazon.com/blogs/aws/introducing-aws-transform-custom-crush-tech-debt-with-ai-powered-code-modernization/
Technical debt is one of the most persistent challenges facing enterprise development teams today. Studies show that organizations spend 20% of their IT budget on technical debt instead of advancing new capabilities. Whether it’s upgrading legacy frameworks, migrating to newer runtime versions, or refactoring outdated code patterns, these essential but repetitive tasks consume valuable developer time that could be spent on innovation.
Today, we’re excited to announce AWS Transform custom, a new agent that fundamentally changes how organizations approach modernization at scale. This intelligent agent combines pre-built transformations for Java, Node.js, and Python upgrades with the ability to define custom transformations. By learning specific transformation patterns and automating them across entire codebases, customers using AWS Transform custom have achieved up to 80% reduction in execution time in many cases, freeing developers to focus on innovation.
You can define transformations using your documentation, natural language descriptions, and code samples. The service then applies these specific patterns consistently across hundreds or thousands of repositories, improving its effectiveness through both explicit feedback and implicit signals like developers’ manual fixes within your transformation projects.
AWS Transform custom offers both CLI and web interfaces to suit different modernization needs. You can use the CLI to define transformations through natural language interactions and execute them on local codebases, either interactively or autonomously. You can also integrate it into code modernization pipelines or workflows, making it ideal for machine-driven automation. Meanwhile, the web interface provides comprehensive campaign management capabilities, helping teams track and coordinate transformation progress across multiple repositories at scale.
Language and framework modernization
AWS Transform supports runtime upgrades without the need to provide additional information, understanding not only the syntax changes required but also the subtle behavioral differences and optimization opportunities that come with newer versions. The same intelligent approach applies to Node.js, Python and Java runtime upgrades, and even extends to infrastructure-level transitions, such as migrating workloads from x86 processors to AWS Graviton.
It also navigates framework modernization with sophistication. When organizations need to update their Spring Boot applications to take advantage of newer features and security patches, AWS Transform custom doesn’t merely update version numbers but understands the cascading effects of dependency changes, configuration updates, and API modifications.
For teams facing more dramatic shifts, such as migrating from Angular to React, AWS Transform custom can learn the patterns of component translation, state management conversion, and routing logic transformation that make such migrations successful.
Infrastructure and enterprise-scale transformations
The challenge of keeping up with evolving APIs and SDKs becomes particularly acute in cloud-based environments where services are continuously improving. AWS Transform custom supports AWS SDK updates across a broad spectrum of programming languages that enterprises use including Java, Python, and JavaScript. The service understands not only the mechanical aspects of API changes, but also recognizes best practices and optimization opportunities available in newer SDK versions.
Infrastructure as Code transformations represent another critical capability, especially as organizations evaluate different tooling strategies. Whether you’re converting AWS Cloud Development Kit (AWS CDK) templates to Terraform for standardization purposes, or updating AWS CloudFormation configurations to access new service features, AWS Transform custom understands the declarative nature of these tools and can maintain the intent and structure of your infrastructure definitions.
Beyond these common scenarios, AWS Transform custom excels at addressing the unique, organization-specific code patterns that accumulate over years of development. Every enterprise has its own architectural conventions, utility libraries, and coding standards that need to evolve over time. It can learn these custom patterns and help refactor them systematically so that institutional knowledge and best practices are applied consistently across the entire application portfolio.
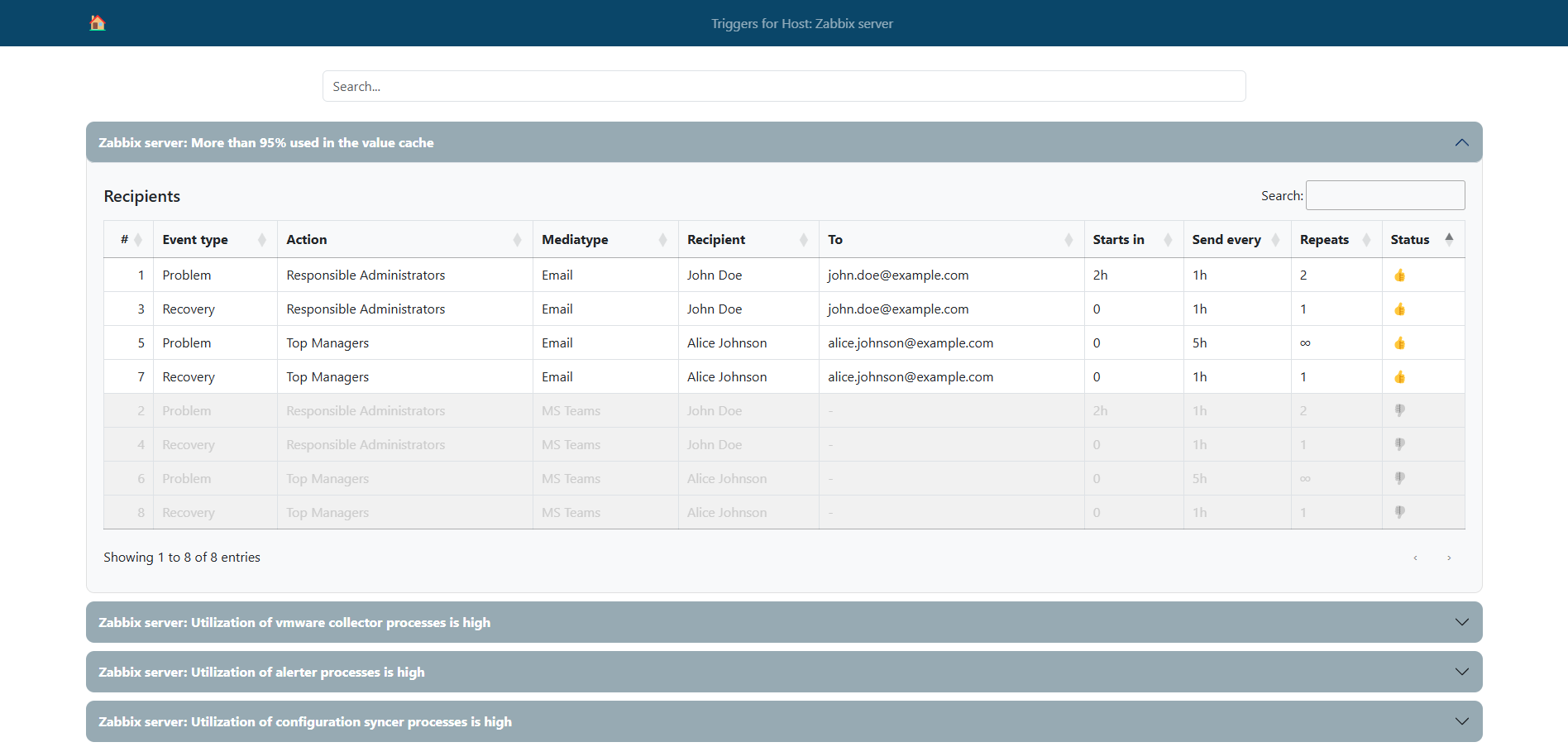
AWS Transform custom is designed with enterprise development workflows in mind, enabling center of excellence teams and system integrators to define and execute organization-wide transformations while application developers focus on reviewing and integrating the transformed code. DevOps engineers can then configure integrations with existing continuous integration and continuous delivery (CI/CD) pipelines and source control systems. It also includes pre-built transformations for Java, Node.js and Python runtime updates which can be particularly useful for AWS Lambda functions, along with transformations for AWS SDK modernization to help teams get started immediately.
Getting started
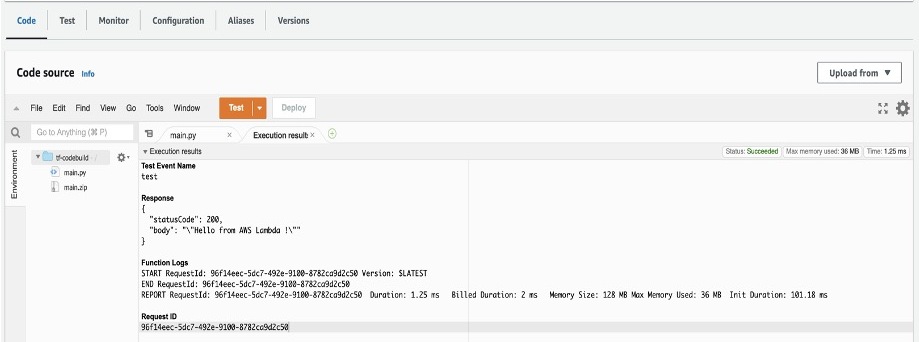
AWS Transform makes complex code transformations manageable through both pre-built and custom transformation capabilities. Let’s start by exploring how to use an existing transformation to address a common modernization challenge: upgrading AWS Lambda functions due to end-of-life (EOL) runtime support.
For this example, I’ll demonstrate migrating a Python 3.8 Lambda function to Python 3.13, as Python 3.8 reached EOL and is no longer receiving security updates. I’ll use the CLI for this demo, but I encourage you to also explore the web interface’s powerful campaign management capabilities.
First, I use the command atx custom def list to explore the available transformation definitions. You can also access this functionality through a conversational interface by typing only atx instead of issuing the command directly, if you prefer.
![]()
This command displays all available transformations, including both AWS-managed defaults and any existing custom transformations created by users in my organization. AWS-managed transformations are identified by the AWS/ prefix, indicating they’re maintained and updated by AWS. In the results, I can see several options such as AWS/java-version-upgrade for Java runtime modernization, AWS/python-boto2-to-boto3-migration for updating Python AWS SDK usage, AWS/nodejs-version-upgrade for Node.js runtime updates.
For my Python 3.8 to 3.13 migration, I’ll use the AWS/python-version-upgrade transformation.
![]()
You run a migration by using the atx custom def exec command. Please consult the documentation for more details about the command and all its options. Here, I run it against my project repository specifying the transformation name. I also add pytest to run unit tests for validation. More importantly, I use the additionalPlanContext section in the --configuration input to specify which Python version I want to upgrade to. For reference, here’s the command I have for my demo (I’ve used multiple lines and indented it here for clarity):
atx custom def exec
-p /mnt/c/Users/vasudeve/Documents/Work/Projects/ATX/lambda/todoapilambda
-n AWS/python-version-upgrade
-C "pytest"
--configuration
"additionalPlanContext= The target Python version to upgrade to is Python 3.13"
-x -tAWS Transform then starts the migration process. It analyzes my Lambda function code, identifies Python 3.8-specific patterns, and automatically applies the necessary changes for Python 3.13 compatibility. This includes updating syntax for deprecated features, modifying import statements, and adjusting any version-specific behaviors.
After execution, it provides a comprehensive summary including a report on dependencies updated in requirements.txt with Python 3.13-compatible package versions, instances of deprecated syntax replaced with current equivalents, updated runtime configuration notes for AWS Lambda deployment, suggested test cases to validate the migration, and more. It also provides a body of evidence that serve as proof of success.

The migrated code lives in a local branch so you can review and merge when satisfied. Alternatively, you can keep providing feedback and reiterating until yo’re happy that the migration is fully complete and meets your expectations.
This automated process changes what would typically require hours of manual work into a streamlined, consistent upgrade that maintains code quality while maintaining compatibility with the newer Python runtime.
Creating a new custom transformation
While AWS-managed transformations handle common scenarios effectively, you can also create custom transformations tailored to your organization’s specific needs. Let’s explore how to create a custom transformation to see how AWS Transform learns from your specific requirements.
I type atx to initialize the atx cli and start the process.
The first thing it asks me is if I want to use one of the existing transformations or create a new one. I choose to create a new one. Notice that from here on the whole conversation takes place using natural language, not commands. I typed new one but I could have typed I want to create a new one and it would’ve understood it exactly the same.
![]()
It then prompts me to provide more information about the kind of transformation I’d like to perform. For this demo, I’m going to migrate an Angular application, so I type angular 16 to 19 application migration which prompts the CLI to search for all transformations available for this type of migration. In my case, my team has already created and made available a few Angular migrations, so it shows me those. However, it warns me that none of them is an exact match to my specific request for migrating from Angular 16 to 19. It then asks if I’d like to select from one of the existing transformations listed or create a custom one.
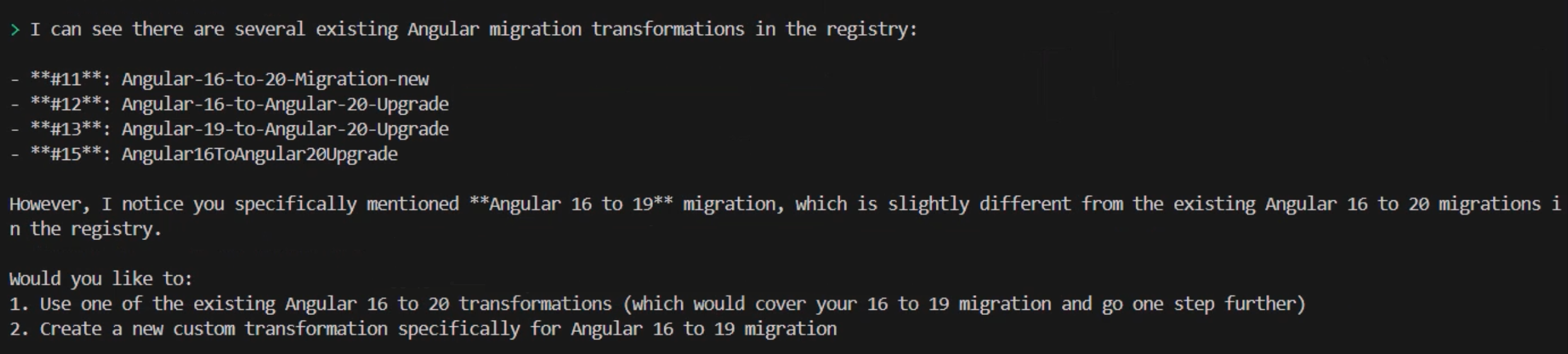
I choose to create a custom one by continuing to use natural language and typing create a new one as a command. Again, this could be any variation of that statement provided that you indicate your intentions clearly. It follows by asking me a few questions including whether I have any useful documentation, example code or migration guides that I can provide to help customize the transformation plan.

For this demo, I’m only going to rely on AWS Transform to provide me with good defaults. I type I don't have these details. Follow best practices. and the CLI responds by telling me that it will create a comprehensive transformation definition for migrating Angular 16 to Angular 19. Of course, I relied on the pre-trained data to generate results based on best practices. As usual, the recommendation is to provide as much information and relevant data as possible at this stage of the process for better results. However, you don’t need to have all the data upfront. You can keep on providing data at any time› as you iterate through the process of creating the custom transformation definition.
The transformation definition is generated as a markup file containing a summary and a comprehensive sequence of implementation steps grouped logically into phases such as premigration preparation, processing and partitioning, static dependency analysis, searching and applying specific transformation rules, and step-by-step migration and iterative validation.
![]()
It’s interesting to see that AWS Transform opted for the best practice of doing incremental framework updates creating steps for migrating the application first to 17 then 18 then 19 instead of trying to go directly from 16 to 19 to minimize issues.
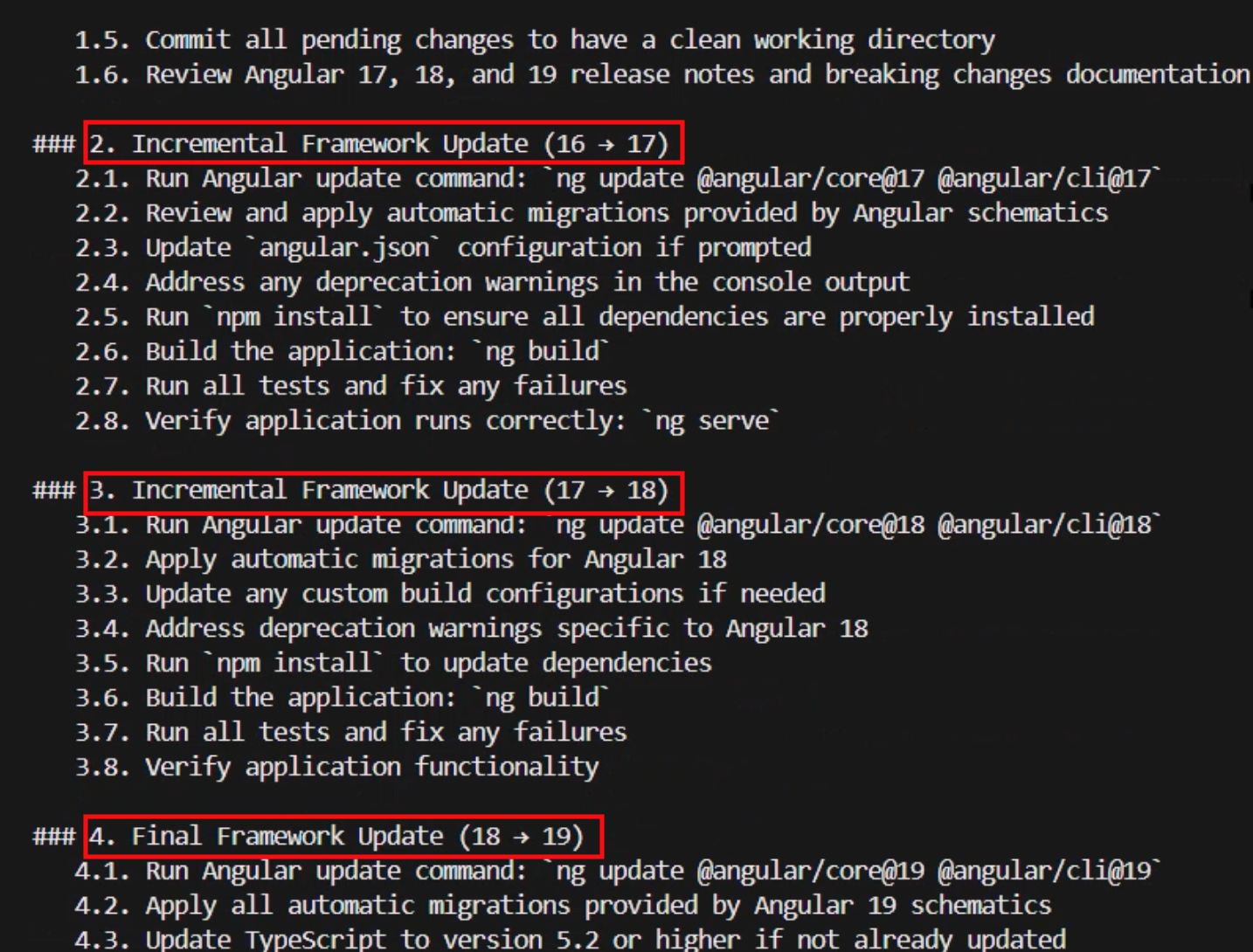
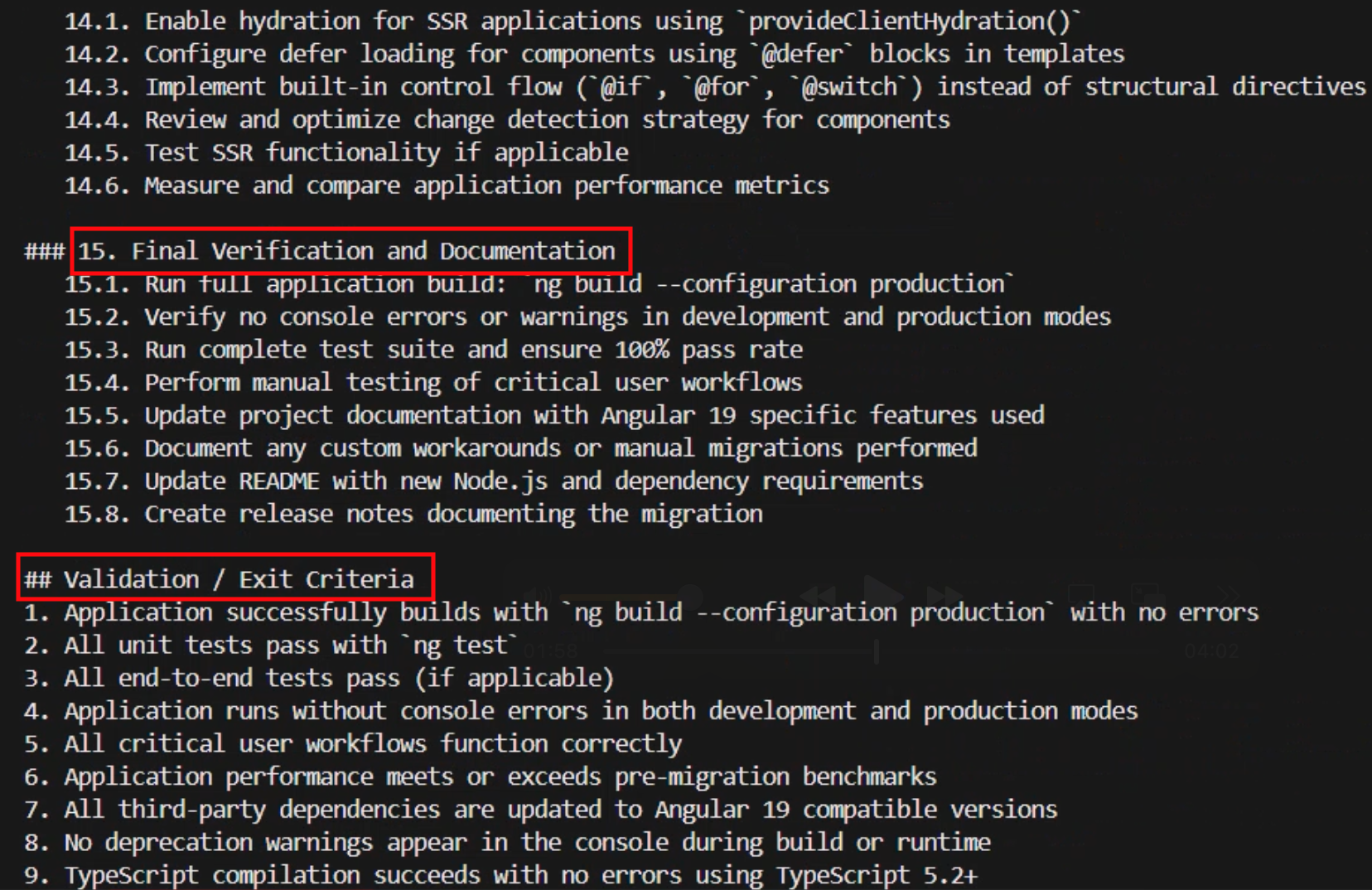
Note that the plan includes various stages of testing and verification to confirm that the various phases can be concluded with confidence. At the very end, it also includes a final validation stage listing exit criteria that performs a comprehensive set of tests against all aspects of the application that will be used to accept the migration as successfully complete.
After the transformation definition is created, AWS Transform asks me about what I would like to do next. I can choose to review or modify the transformation definition and I can reiterate through this process as much as I need until I arrive at one that I’m satisfied with. I can also choose to already apply this transformation definition to an Angular codebase. However, first I want to make this transformation available to my team members as well as myself so we can all use it again in the future. So, I choose option 4 to publish this transformation to the registry.
![]()
This custom transformation needs a name and a description of its objective which is displayed when users browse the registry. AWS Transforms automatically extracts those from context for me and asks me if I would like to modify them before going ahead. I like the sensible default of “Angular-16-to-19-Migration”, and the objective is clearly stated, so I choose to accept the suggestions and publish it by answering with yes, looks good.
![]()
Now that the transformation definition is created and published, I can use it and run it multiple times against any code repository. Let’s apply the transformation to a code repository with a project written in Angular 16. I now choose option 1 from the follow-up prompt and the CLI asks me for the path in my file system to the application that I want to migrate and, optionally, the build command that it should use.
![]()
After I provide that information, AWS Transform proceeds to analyze the code base and formulate a thorough step-by-step transformation plan based on the definition created earlier. After it’s done, it creates a JSON file containing the detailed migration plan specifically designed for applying our transformation definition to this code base. Similar to the process of creating the transformation definition, you can review and iterate through this plan as much as you need, providing it with feedback and adjusting it to any specific requirements you might have.
When I’m ready to accept the plan, I can use natural language to tell AWS Transform that we can start the migration process. I type looks good, proceed and watch the progress in my shell as it starts executing the plan and making the changes to my code base one step at a time.
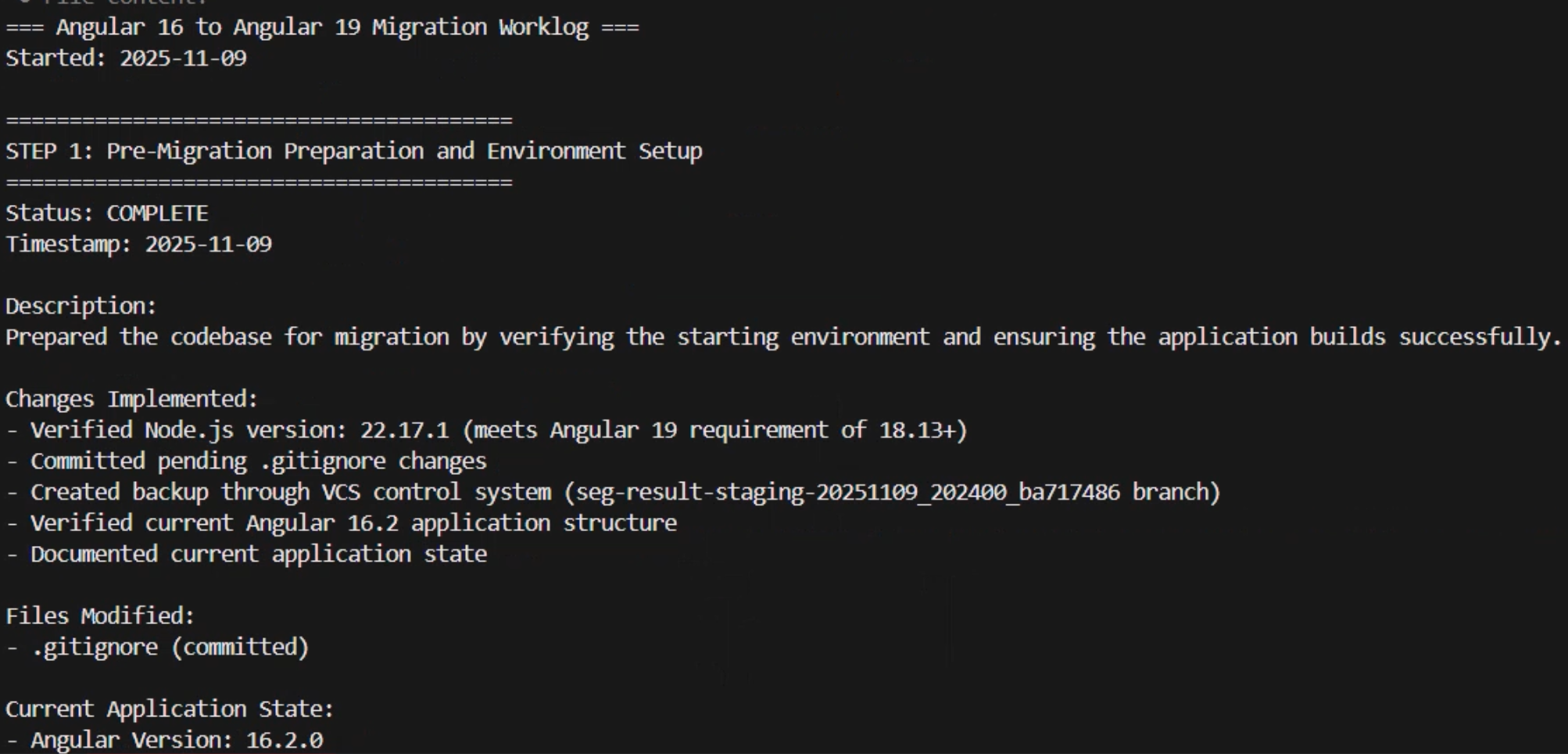
The time it takes will vary depending on the complexity of the application. In my case, it took a few minutes to complete. After it has finished, it provides me with a transformation summary and the status of each one of the exit criteria that were included in the final verification phase of the plan alongside all the evidence to support the reported status. For example, the Application Build – Production criteria was listed as passed and some of the evidence provided included the incremental Git commits, the time that it took to complete the production build, the bundle size, the build output message, and the details about all the output files created.
![]()
Conclusion
AWS Transform represents a fundamental shift in how organizations approach code modernization and technical debt. The service helps to transform what was at one time a fragmented, team-by-team effort into a unified, intelligent capability that eliminates knowledge silos, keeping your best practices and institutional knowledge available as scalable assets across the entire organization. This helps to accelerate modernization initiatives while freeing developers to spend more time on innovation and driving business value instead of focusing on repetitive maintenance and modernization tasks.
Things to know
AWS Transform custom is now generally available. Visit the get started guide to start your first transformation campaign or check out the documentation to learn more about setting up custom transformation definitions.




























 Shaheer Mansoor is a Senior Machine Learning Engineer at AWS, where he specializes in developing cutting-edge machine learning platforms. His expertise lies in creating scalable infrastructure to support advanced AI solutions. His focus areas are MLOps, feature stores, data lakes, model hosting, and generative AI.
Shaheer Mansoor is a Senior Machine Learning Engineer at AWS, where he specializes in developing cutting-edge machine learning platforms. His expertise lies in creating scalable infrastructure to support advanced AI solutions. His focus areas are MLOps, feature stores, data lakes, model hosting, and generative AI. Anoop Kumar K M is a Data Architect at AWS with focus in the data and analytics area. He helps customers in building scalable data platforms and in their enterprise data strategy. His areas of interest are data platforms, data analytics, security, file systems and operating systems. Anoop loves to travel and enjoys reading books in the crime fiction and financial domains.
Anoop Kumar K M is a Data Architect at AWS with focus in the data and analytics area. He helps customers in building scalable data platforms and in their enterprise data strategy. His areas of interest are data platforms, data analytics, security, file systems and operating systems. Anoop loves to travel and enjoys reading books in the crime fiction and financial domains. Sreenivas Nettem is a Lead Database Consultant at AWS Professional Services. He has experience working with Microsoft technologies with a specialization in SQL Server. He works closely with customers to help migrate and modernize their databases to AWS.
Sreenivas Nettem is a Lead Database Consultant at AWS Professional Services. He has experience working with Microsoft technologies with a specialization in SQL Server. He works closely with customers to help migrate and modernize their databases to AWS.