Post Syndicated from Ashley Whittaker original https://www.raspberrypi.org/blog/raspberry-pi-turns-retro-radio-into-interactive-storyteller/
8 Bits and a Byte created this voice-controllable, interactive, storytelling device, hidden inside a 1960s radio for extra aesthetic wonderfulness.

A Raspberry Pi 3B works with an AIY HAT, a microphone, and the device’s original speaker to run chatbot and speech-to-text artificial intelligence.

This creature is a Bajazzo TS made by Telefunken some time during the 1960s in West Germany, and this detail inspired the espionage-themed story that 8 Bits and a Byte retrofitted it to tell. Users are intelligence agents whose task is to find the evil Dr Donogood.


The device works like one of those ‘choose your own adventure’ books, asking you a series of questions and offering you several options. The story unfolds according to the options you choose, and leads you to a choice of endings.

What’s the story?
8 Bits and a Byte designed a decision tree to provide a tight story frame, so users can’t go off on question-asking tangents.
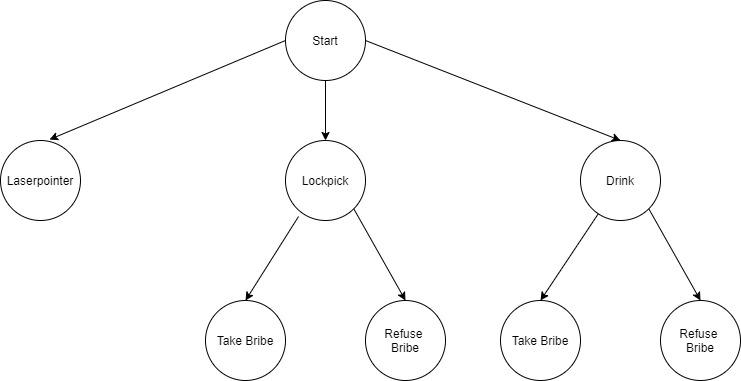
When you see the ‘choose your own adventure’ frame set out like this, you can see how easy it is to create something that feels interactive, but really only needs to understand the difference between a few phrases: ‘laser pointer’; ‘lockpick’; ‘drink’; take bribe’, and ‘refuse bribe’.
How does it interact with the user?
Google Dialogflow is a free natural language understanding platform that makes it easy to design a conversational user interface, which is long-speak for ‘chatbot’.
There are a few steps between the user talking to the radio, and the radio figuring out how to respond. The speech-to-text and chatbot software need to work in tandem. For this project, the data flow runs like so:
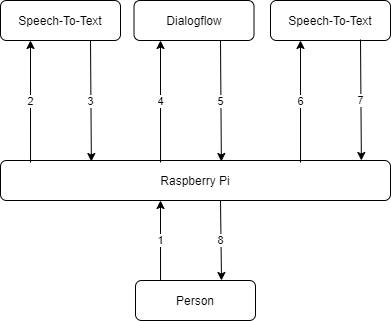
1: The microphone detects that someone is speaking and records the audio.
2-3: Google AI (the Speech-To-Text box) processes the audio and extracts the words the user spoke as text.
4-5: The chatbot (Google Dialogflow) receives this text and matches it with the correct response, which is sent back to the Raspberry Pi.
6-7: Some more artificial intelligence uses this text to generate artificial speech.
8: This audio is played to the user via the speaker.
The post Raspberry Pi turns retro radio into interactive storyteller appeared first on Raspberry Pi.