Post Syndicated from Luca Mezzalira original https://aws.amazon.com/blogs/architecture/lets-architect-architecture-tools/
Tools, such as diagramming software, low-code applications, and frameworks, make it possible to experiment quickly. They are essential in today’s fast-paced and technology-driven world. From improving efficiency and accuracy, to enhancing collaboration and creativity, a well-defined set of tools can make a significant impact on the quality and success of a project in the area of software architecture.
As an architect, you can take advantage of a wide range of resources to help you build solutions that meet the needs of your organization. For example, with tools in the likes of the Amazon Web Services (AWS) Solutions Library and Serverless Land, you can boost your knowledge and productivity while working on event-driven architectures, microservices, and stateless computing.
In this Let’s Architect! edition, we explore how to incorporate these patterns into your architecture, and which tools to leverage to build solutions that are scalable, secure, and cost-effective.
How AWS Application Composer helps your team build great apps
In this re:Invent 2022 session, Chase Douglas, Principal Engineer at AWS, speaks about AWS Application Composer, a newly launched service.
This service has the potential to change the way architects design solutions—without writing a single line of code! The service is user-friendly, intuitive, and requires no prior coding experience. It allows users to scaffold a serverless architecture, defining a CloudFormation template visually with drag-and-drop. A detailed AWS Compute Blog post takes readers through the process of using AWS Application Composer.
Take me to this re:Invent 2022 video!

How an architecture can be designed with AWS Application Composer
AWS design + build tools
When migrating to the cloud, we suggest referencing these four tried-and-true AWS resources that can be used to design and build projects.
- AWS Workshops are created by AWS teams to provide opportunities for hands-on learning to develop practical skills. Workshops are available in multiple categories and for skill levels 100-400.
- AWS Architecture Center contains a collection of best practices and architectural patterns for designing and deploying cloud-based solutions using AWS services. Furthermore, it includes detailed architecture diagrams, whitepapers, case studies, and other resources that provide a wealth of information on how to design and implement cloud solutions.
- Serverless Land (an Amazon property) brings together various patterns, workflows, code snippets, and blog posts pertaining to AWS serverless architectures.
- AWS Solutions Library provides customers with templates, tools, and automated workflows to easily deploy, operate, and manage common use cases on the AWS Cloud.

Inside event-driven architectures designed by David Boyne on Serverless Land
The Well-Architected way
In this session, the AWS Well-Architected provides guidance on how to implement the architectural models reported in the AWS Well-Architected Framework within your organization at scale.
Discover a customer story and understand how to use the features of the AWS Well-Architected Tool and APIs to receive recommendations based on your workload and measure your architectural metrics. In the Framework whitepaper, you can explore the six pillars of Well-Architected (operational excellence, security, reliability, performance efficiency, cost optimization, and sustainability) and best practices to achieve them.
Understanding the key design pillars can help architects make informed design decisions, leading to more robust and efficient solutions. This knowledge also enables architects to identify potential problems early on in the design process and find appropriate patterns to address those issues.
Take me to the Well-Architected video!
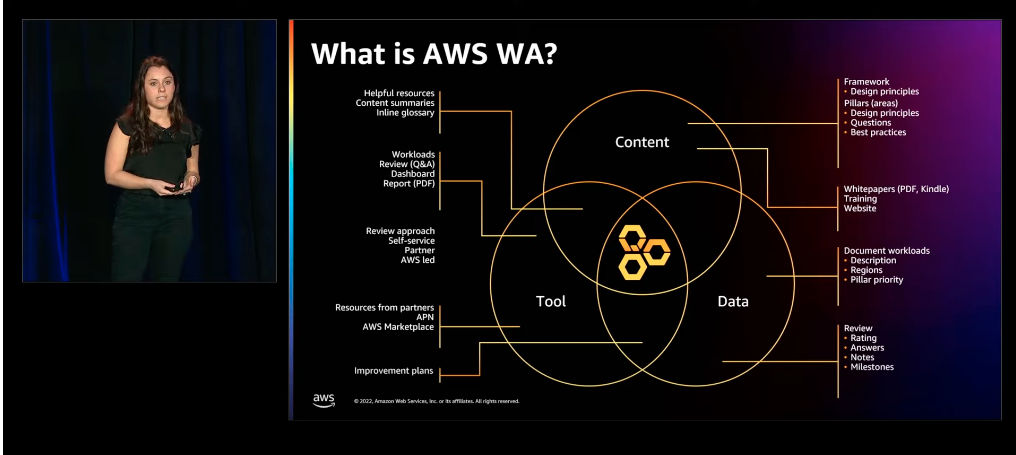
Discover how the AWS Well-Architected Framework can help you design scalable, maintainable, and reusable solutions
See you next time!
Thanks for exploring architecture tools and resources with us!
Join us next time when we’ll talk about data mesh architecture!
To find all the posts from this series, check out the Let’s Architect! page of the AWS Architecture Blog.