AWS re:Invent 2025 is just around the corner, and if you’re a developer looking to level up your skills, the Developer Tool (DVT) track has an incredible lineup waiting for you. From CI/CD pipelines and full-stack development to Infrastructure as Code and AI-powered coding agents, this year’s sessions will help you build faster, smarter, and more efficiently. Here’s your essential guide to navigating the week.
Must-Attend Sessions
AWS re:Invent is a learning focused conference and the best place for developer to learn is in one of the roughly 75 sessions on the Developer Tools track. With breakout sessions, lightening talks, chalk talks, code talks, workshops, builder sessions, and meetups, you are sure to find a something that appeals the developer in you. Check you the event catalog, or start with these stand out sessions.
DVT202: Continuous integration and continuous delivery (CI/CD) on AWS – Learn about creating complete CI/CD pipelines using infrastructure as code on AWS, with hands-on insights into planning work, collaborating on code, and deploying applications. Mandalay Bay – Monday 10:00 AM
DVT203: AWS infrastructure as code: A year in review – Discover the latest features and improvements for AWS CloudFormation and AWS CDK, and learn how these tools can bring rigor, clarity, and reliability to your application development. MGM Grand – Monday 10:30 AM
DVT204: What’s new in full-stack AWS app development – Find out how AWS is evolving to help web developers deliver differentiating experiences at 10x speed with solutions that empower you to get started easily, ship quickly, and iterate rapidly. Mandalay Bay – Monday 12:00 PM
DVT209: Kiro: Your agentic IDE for spec-driven development – Explore how Kiro is revolutionizing development with spec-driven workflows, agent hooks, multimodal agent chat, and MCP support to help you go from idea to production faster. MGM Grand – Wednesday 11:30 AM
DVT405: From Code completion to autonomous agents: The evolution of software development – Journey through the evolution of AI-powered coding agents from inline code completion to sophisticated autonomous tools, grounded in empirical evidence and real-world applications. MGM Grand – Wednesday 3:00 PM
DVT207: Developer experience economics: moving past productivity metrics – Learn Amazon’s approach to understanding the impact of developer experience and tooling, and discover how to bring strategic thinking to your team’s developer experience improvements. Mandalay Bay – Tuesday 5:30 PM
House of Kiro
Start your journey at the House of Kiro in the Venetian. Walk through Kiro’s haunted house filled with developer nightmares and horrors, and explore how Kiro brings structure to coding chaos through spec-driven development, vibe coding, and agent hooks. If you survive the haunted house, you will be rewarded with Kiro swag.
AWS Village
Visit the AWS Village in the Expo at the Venetian Level 2 Hall B to speak with me and other experts at either the Kiro kiosk or the Developer Tools kiosk, covering CodePipeline, CodeBuild, CloudFormation, CDK, and all the essential developer tools.
The Venetian, Monday, Dec 1: 4:00 PM – 7:00 PM
Tuesday, Dec 2: 10:00 AM – 6:00 PM
Wednesday, Dec 3: 10:00 AM – 6:00 PM
Thursday, Dec 4: 10:00 AM – 4:00 PM
Builders Loft
Located at the south end of the strip in Mandalay Bay, the Builders Loft offers a collaborative workspace with dedicated co-working spaces and meetup zones. Enjoy coffee, snacks, SWAG, and daily tech challenges for a chance to win AWS credits. Kiro experts will be at the builders loft Monday-Thursday:
8:00 AM – 12:00 PM: Co-working space for one-on-one consultations
12:00 PM – 1:00 PM: Daily meetup in the meetup space
4:50 PM – 5:00 PM: Q&A in the whiteboard section
Hands-On Challenges
Kiro’s Labyrinth
Stop by the Kiro kiosk in the Venetian Expo to participate in Kiro’s Labyrinth, a coding challenge where you’ll help Kiro escape from a spooky Halloween maze and win prizes. The Kiro code champions will be crowned in DVT221 at Mandalay Bay on Thursday at 11:30 AM.
Kiroween Hackathon
Build something wicked for Kiroween, the annual hackathon that started on Halloween and ends on Friday, December 5th—the last day of re:Invent. Need help? Visit us at in the Builder Loft in Mandalay Bay: Monday-Friday, 8:30 AM – 12:00 PM or the Developer Pavilion in Venetian whenever the Expo is open.
Conclusion
Make the most of your re:Invent experience by attending these sessions, connecting with experts at the AWS Village and Builders Loft, and participating in hands-on challenges. Whether you’re interested in CI/CD, infrastructure as code, AI-powered development, or just want to network with fellow builders, the Developer Tools track has something for everyone. See you in Vegas!
Well, it’s been another historic year! We’ve watched in awe as the use of real-world generative AI has changed the tech landscape, and while we at the Architecture Blog happily participated, we also made every effort to stay true to our channel’s original scope, and your readership this last year has proven that decision was the right one.
AI/ML carries itself in the top posts this year, but we’re also happy to see that foundational topics like resiliency and cost optimization are still of great interest to our audience.
(By the way, if you were hoping for more AI/ML content, head on over to our sister channel, the AWS Machine Learning Blog!).
Without further ado, here are our top posts from 2024!
In keeping with Let’s Architect! series, we have our first of three favorites for the year. This set of resources helps you apply Well-Architected standards in practice.
As I said, Let’s Architect! has a winning series, and they’ve got a finger on the pulse of the tech world. This post about machine learning showcases some of the most exciting things happening at AWS.
Figure 3. Let’s Architect
If you’re more interested in generative AI, you can also take a look at another post from 2024: Let’s Architect! GenAI
Preparedness is another common theme in this year’s favorites. Michael, John, and Saurabh are well-versed in multi-Region architecture, and they’re here to share some strategies to contain failure impact.
Figure 4. When the application experiences an impairment using S3 resources in the primary Region, it fails over to use an S3 bucket in the secondary Region.
Let’s talk cost optimization. This post about a three-tier architecture that relies on the AWS Free Tier is a must-read for anyone looking for tips to help them avoid unnecessary costs (and that’s everyone).
Figure 5. Example of a three-tier architecture on AWS
As usual, Haleh & team are pros at making sure the Well-Architected Framework is current and relevant. Take a look at the enhanced and expanded guidance in all six pillars.
One more winning post from Luca, Federica, Vittorio, and Zamira! This collection of developer resources includes new ideas in AWS Lambda, Amazon Q Developer, and Amazon DynamoDB.
Frugality AND Well-Architected? What a winning combo! This post, inspired by the 2023 re:Invent keynote, outlines the seven laws of Frugal Architecture.
And finally, our number one post of the year! Amit and Luiz showcase a customer solution with real-world applications that builds on the guidelines of other posts in this list! Well done!
Figure 10. The Pilot Light scenario for a 3-tier application that has application servers and a database deployed in two Regions
Thank you!
As always, thanks to our contributors for their dedication and desire to share, and to you, our readers! We would be nothing with you. Literally.
For other top post lists, see our Top 10 and Top 5 posts from previous years.
As part of the re:Invent 2023 keynote, Dr. Werner Vogels introduced the Frugal Architect mindset. This mindset emphasizes the importance of continuous learning, curiosity, and regular revision of architectural choices with a focus on cost and sustainability. Cost and sustainability should be treated as critical non-functional requirements, alongside factors like security, compliance, and performance. The Frugal Architect approach involves measuring and optimizing cost at every stage of the development process, which allows for innovation in parallel with promoting responsible resource usage. In the rapidly-evolving technology landscape, builders should adopt the Frugal Architect mindset to balance innovation with cost efficiency and environmental sustainability.
This blog discusses how the six pillars of the AWS Well-Architected Framework (operational excellence, security, reliability, performance efficiency, cost optimization, and sustainability) align with the seven Frugal Architect laws. It demonstrates how adhering to the principles and best practices outlined in these pillars can help architects and builders effectively implement the Frugal Architect laws in their projects. The Well-Architected Framework provides a comprehensive set of guidelines that embed the concepts of frugality, efficiency, and cost effectiveness, which are the core tenets of the Frugal Architect laws. By following the Framework’s pillars, architects can build secure, reliable, efficient, and cost-optimized systems and promote sustainability.
Non-functional requirements are criteria that evaluate a system’s operation instead of its specific features or functionality. This includes aspects like accessibility, availability, scalability, security, portability, maintainability, and compliance. However, one crucial non-functional requirement that is often overlooked is cost. Consider implications early on and throughout the design, development, and operation of your systems. Organizations can strike a balance between desired features, time-to-market, and operational efficiency through early prioritization of cost considerations. The Frugal Architect argues that you should treat cost as a fundamental non-functional requirement that should be given upfront consideration when planning and initiating system development projects.
The Cost Optimization Pillar of the AWS Well-Architected Framework provides guidance on how to optimize costs when using AWS Cloud services. It emphasizes treating cost as a key requirement, not an afterthought. The main principles focus on the importance of a robust financial management processes, adoption of a cloud consumption model that allows for flexible scaling and pay-per-use billing, continual measurement of outputs against costs to optimize efficiency, use of managed services to minimize operational overhead, and implementation of transparent cost attribution to tie cloud spending to revenue sources and workloads. Organizations that follow these practices can effectively manage and optimize their costs and benefit from the scalability and agility of cloud computing.
These cost optimization principles can help organizations maximize the financial benefits of using the AWS Cloud and avoid wasteful spending. Cost optimization is an ongoing process that includes rightsizing, higher output for the same cost, and use of the most cost-effective AWS services. The pillar promotes a disciplined approach to evaluate trade-offs between cost and other optimization areas like performance or reliability. Overall, you can use this pillar to make informed decisions to provision and operate AWS services cost-effectively.
The durability and longevity of a system are closely tied to how well its costs align with the underlying business model. During the creation of a system, consider revenue sources and profit drivers. The key is to identify the primary dimension or aspect that generates revenue, and then verify that the system architecture supports and optimizes for that revenue-generating dimension. Essentially, revenue and profitability considerations should be the primary forces behind cost decisions in system design.
The AWS Well-Architected Cost Optimization Pillar provides practices and guidance for organizations to accurately monitor their AWS costs and usage. This visibility helps users understand the profitability of different business units and products, which facilitates informed decisions on resource allocation across the organization. Organizations can implement these practices to gain insights into their AWS spending patterns, which aids in development of effective cost optimization strategies. Overall, accurate expenditure analysis and attribution are crucial for organizations to optimize cloud costs, measure ROI, and make data-driven resource allocation decisions.
It’s important to accurately identify and attribute cloud costs to specific workloads. The cloud allows for transparent cost attribution, which helps organizations link costs to individual revenue streams and workload owners. This granular cost attribution data empowers workload owners to measure return on investment (ROI) for their workloads. With detailed cost information, workload owners can optimize resource utilization and reduce costs by rightsizing resources, eliminating waste, and making informed decisions. Organizations must use accurate cost attribution to understand where their cloud spending is going and verify that resources are being used efficiently across different workloads and revenue streams.
Architectural decisions involve trade-offs, particularly between cost, resilience, and performance. Systems will inevitably fail, so investment in resilience is important but may impact performance. It’s important to find the right balance between technical requirements and business needs and align with risk tolerance and budget constraints. Frugality is about maximizing value, not just minimizing spend. Frugality means that you determine what you’re can pay for based on your priorities and make informed trade-off decisions. Ultimately, architectural choices require careful consideration of the tensions between different non-functional requirements.
The AWS Well-Architected Framework helps you make architectural trade-offs through its design principles and practices across its six pillars with your business requirements in mind. As you architect workloads, you make trade-offs between pillars based on your business context. You might optimize to improve the sustainability impact and reduce cost at the expense of reliability in development environments, or for mission-critical solutions. You might optimize reliability with increased costs and sustainability impact. In ecommerce solutions, performance can affect revenue and customer propensity to buy. Security generally is not a viable trade-off against the other pillars.
Rather than optimizing for any single pillar, the Framework guides a holistic evaluation across all pillars to determine the right architectural approach. Organizations can use AWS best practices while they find the optimal balance that aligns with their unique requirements. The key is making intentional trade-off decisions instead of following any uniform approach.
Without proper observation and measurement, the true operational costs of a system remain hidden, and wasteful practices can persist unnoticed. Just as exposing a utility meter prompts more mindful usage, visibility increases into costs can drive more sustainable behaviors. While implementing comprehensive monitoring requires upfront investment, the long-term benefits of conserving resources and optimizing efficiency make it a worthwhile endeavor. Ultimately, you should maintain cost awareness to foster a culture of responsible, sustainable practices.
The Operational Excellence Pillar of the AWS Well-Architected Framework emphasizes the importance of observability to gain actionable insights into workloads. This involves creation of key performance indicators (KPIs) and use of observability data telemetry to comprehensively understand workload behavior, performance, reliability, cost, and health. Organizations can implement observability best practices to make informed decisions and take prompt action when business outcomes are at risk due to issues with workload operation. Observability data provides visibility into the current state and helps identify areas for improvement. This means that organizations can be proactive in performance optimization, reliability enhancement, and cost reduction based on the actionable insights derived from observability telemetry data. Overall, observability is crucial for maintenance of operational excellence through the use of data-driven decision-making and continuous improvement of workloads.
Overall, monitoring guidance is a core component across multiple pillars of the Well-Architected Framework, as it helps organizations effectively manage and optimize their cloud workloads. For more detail on the monitoring principles of the AWS Well-Architected Framework, see Cost-Aware Architectures Implement Cost Controls (Law 5).
The key aspects of frugal architecture combine granular controls with robust monitoring to identify areas for optimization. This helps you optimize costs and maintain a good user experience. With a robust monitoring system, you can take action where improvements are needed.
The AWS Well-Architected Framework aligns with the concept of frugality, which focuses on maximizing value rather than just minimizing spending. The Framework helps businesses achieve maximum value by making architectural choices that meet their specific requirements.
The Cost Optimization Pillar emphasizes the continual monitoring of usage and costs to identify opportunities for efficiency improvements and cost savings. This includes expenditure analysis, adoption of consumption-based models, and implementation of cloud financial management practices.
The Security Pillar, Reliability Pillar, and Performance Efficiency Pillar reinforce the importance of monitoring systems, workloads, and costs in real-time to maintain security, automatically recover from failures, and optimize performance relative to cost.
The Sustainability Pillar focuses on measurement of a workload’s current and forecasted environmental impact. It recommends continual evaluation of new hardware and software offerings that can reduce the environmental footprint.
Overall, monitoring guidance spans multiple Well-Architected pillars to maximize value through optimization of cost, performance, security, reliability, and sustainability.
Cost efficiency is a continuous process, not a one-time goal. Regularly monitor your systems to identify inefficient patterns and areas for optimization. Revisit and refine systems periodically to find additional opportunities for improvement and further reduce costs over time.
The Cost Optimization Pillar covers principles like analysis and attribution of expenditure, measurement of overall efficiency, adoption of a consumption model, and implementation of cloud financial management practices.
Additionally, the Operational Excellence Pillar provides principles that apply not just to cost optimization but all pillars. These include observability for actionable insights, safe automation where possible, frequent small reversible changes, frequent refinement of operations procedures, anticipation of failure, and documentation and distribution of learning from operational events and metrics.
Organizations can follow these AWS Well-Architected Framework principles and their practices to continuously improve their cloud architectures and operations and optimize costs effectively.
We should continue to reevaluate past approaches, even those that were previously successful. Just because something worked before does not mean that it is still the best method. Grace Hopper, a computer scientist, mathematician, and United States Navy rear admiral, cautioned against blind adherence to tradition, saying that “we’ve always done it this way” is a dangerous mindset. We must be willing to question the old ways and explore new and potentially better methods.
The AWS Well-Architected Framework advocates for an evolutionary architecture approach to system design. Traditional architectures are often designed as static, with only a few major version updates during the system’s lifetime. However, as businesses and requirements change over time, initial architectural decisions can limit the ability to adapt and evolve the system. Cloud computing enables capabilities like automated testing and lower-risk design changes, which allows systems to evolve continually rather than being constrained by the original design. An evolutionary architecture positions businesses to take advantage of new innovations and changes as part of standard practice. Rather than being locked into original architectural choices, an evolutionary approach fosters ongoing adaptation and modernization as requirements shift. This contrasts with traditional fixed architectures that make it difficult to evolve over time and provides greater flexibility to evolve systems iteratively.
The Operational Excellence Pillar includes implementation of observability to understand system behavior, safe automation of processes, frequent but reversible changes, regular refinement of operations procedures, proactive anticipation potential failures proactively, and distribution of learnings from operational events and metrics to drive continuous improvement.
Overall, the Well-Architected Framework provides guidance on evolutionary architecture and operations processes to effectively manage increasing software complexity over time.
Conclusion
Frugality is about maximizing value, rather than just minimizing costs. Following AWS Well-Architected Framework best practices regarding security, reliability, and operational excellence can help realize frugal yet robust architectures. True frugality involves optimizing costs by aligning spending with areas that deliver the highest business value and impact. The Well-Architected Framework provides guidance for making architectural decisions that increase efficiency, lower risks, and maximize return on cloud investments. This involves determining priorities, understanding sources of value, and making informed trade-off decisions based on those priorities. It’s important to avoid indiscriminate cost-cutting and instead focus on resources on what matters most to drive value for the organization. By following Well-Architected best practices, companies can practice frugality in a strategic way that balances optimization with business goals.
SQL databases in Amazon Web Services (AWS), using services like Amazon Relational Database Service (Amazon RDS) and Amazon Aurora, offer software architects scalability, automated management, robust security, and cost-efficiency. This combination simplifies database management, improves performance, enhances security, and allows architects to create efficient and scalable software systems.
In this post, we introduce caching strategies and continue with real case studies that use services like Amazon ElastiCache or Amazon MemoryDB in real workloads where customers share the reasoning behind their approaches. It’s very important to understand the context for leveraging a specific solution or pattern, and these resources answer many commonly asked questions.
For software architects and developers, striking the right balance between operational complexity and cost efficiency is a perpetual challenge. Often, provisioning a separate database for each workload is the gold standard, offering unmatched isolation and granular operational controls. However, it’s not always the most cost-effective or operationally manageable approach. Through a real-world success story, we explore how Aurora played a pivotal role in helping VMware Aria Cost, powered by CloudHealth, consolidate a staggering 166 self-managed MySQL databases onto 62 Aurora clusters.
Amazon RDS Blue/Green Deployments revolutionizes the way you handle database updates, ensuring safety and simplicity, often achieving rapid updates in just a minute, with zero data loss. Meanwhile, Amazon RDS Optimized Writes turbocharges write transaction throughput by as much as double, without any additional extra cost. Amazon RDS Optimized Reads steps in to deliver a significant boost to database performance, processing queries up to 50% faster.
Discover how to leverage these capabilities of Amazon RDS in this one-hour video from re:Invent 2022.
In the world of mission-critical workloads, the importance of a robust disaster recovery (DR) strategy cannot be overstated. It’s the lifeline that ensures databases stay operational, even in the face of unexpected events. Discover the intricacies of crafting a dependable, cross-Region DR strategy tailored to Amazon RDS for SQL Server.
In this AWS Developers session, we uncover the best practices for efficiently managing and monitoring these cross-Region read replicas. From proactive monitoring to fine-tuning, you’ll gain the insights needed to keep your DR strategy finely tuned.
Aurora represents a paradigm shift in relational databases, boasting an architecture that decouples computational processes from data storage. It introduces advanced features, such as Global Database and low-latency read replicas, redefining the landscape of database management.
This modern database service excels in performance, scalability, and high availability on a large scale, offering compatibility with both MySQL and PostgreSQL open-source editions. Additionally, it provides an array of developer tools tailored for serverless and machine learning-driven applications.
This re:Invent 2022 session is an in-depth exploration of some of Aurora’s most compelling features, including Aurora Serverless v2 and Global Database. We also share the most recent innovations aimed at enhancing performance, scalability, and security while streamlining operational processes.
In-memory databases play a critical role in modern computing, particularly in reducing the strain on existing resources, scaling workloads efficiently, and minimizing the cost of infrastructure. The advanced performance capabilities of in-memory databases make them vital for demanding applications characterized by voluminous data, real-time analytics, and rapid response requirements.
In this edition of Let’s Architect!, we are introducing caching strategies and, further, examining case studies that use Amazon Web Services (AWS), like Amazon ElastiCache or Amazon MemoryDB for Redis, in real workloads where customers share the reasoning behind their approaches. It is very important understanding the context for leveraging a specific solution or pattern, and many common questions can be answered with these resources.
Many services built at Amazon rely on caching systems in the background to speed up performance, deal with low latency requirements, and avoid overloading on source databases and other microservices. Operating caches and adding caches into our systems may present complex challenges in terms of monitoring, data consistency, and load on the other components of the system. Indeed, a cache can give big benefits, but it’s also a new component to run and keep healthy. Furthermore, engineers may need to use empirical methods to choose the cache size, expiration policy, and eviction policy: we always have to perform tests and use the metrics to tune the setup.
With this Amazon Builder’s Library resource, you can learn strategies for using caching in your architecture and best practices directly from Amazon’s engineers.
Discover how Yahoo effectively leverages the power of Amazon ElastiCache and data tiering to process an astounding 1.3 million advertising data events per second, all while generating savings of up to 50% on their overall bill.
Data tiering is an ingenious method to scale up to hundreds of terabytes of capacity by intelligently managing data. It achieves this by automatically shifting the least-recently accessed data between RAM and high-performance SSDs.
In this video, you will gain insights into how data tiering operates and how you can unlock ultra-fast speeds and seamless scalability for your workloads in a cost-efficient manner. Furthermore, you can also learn how it’s implemented under the hood.
MemoryDB is a robust, durable database marked by microsecond reads, low single-digit millisecond writes, scalability, and fortified enterprise security. It guarantees an impressive 99.99% availability, coupled with instantaneous recovery without any data loss.
In this session, we explore multiple use cases across sectors, such as Financial Services, Retail, and Media & Entertainment, like payment processing, message brokering, and durable session store applications. Moreover, through a practical demonstration, you can learn how to utilize MemoryDB to establish a microservices message broker for a Media & Entertainment application.
MemoryDB offers the kind of ultra-fast performance that only an in-memory database can deliver, curtailing latency to microseconds and processing 160+ million requests per second —without data loss. In this re:Invent 2022 session, you will understand why Samsung SmartThings selected MemoryDB as the engine to power the next generation of their IoT device connectivity platform, one that processes millions of events every day.
You can also discover the intricate design of MemoryDB and how it ensures data durability without compromising the performance of in-memory operations, thanks to the utilization of a multi-AZ transactional log. This session is an enlightening deep-dive into durable, in-memory data operations.
In this edition of AWS Online Tech Talks, explore Amazon ElastiCache, a managed service that facilitates the seamless setup, operation, and scaling of widely used, open-source–compatible, in-memory datastores in the cloud environment. This service positions you to develop data-intensive applications or enhance the performance of your existing databases through high-throughput, low-latency, in-memory datastores. Learn how it is leveraged for caching, session stores, gaming, geospatial services, real-time analytics, and queuing functionalities.
This course can help cultivate a deeper understanding of Amazon ElastiCache, and how it can be used to accelerate your data processing while maintaining robustness and reliability.
Every software component built by engineers and architects is designed with a purpose: to offer particular functionalities and, ultimately, contribute to the generation of business value. We should consider fundamental factors, such as the scalability of the software and the ease of evolution during times of business changes. However, performance and cost are important factors as well since they can impact the business profitability.
This edition of Let’s Architect! follows a similar series post from 2022, which discusses optimizing the cost of an architecture. Today, we focus on architectural patterns, services, and best practices to design cost-optimized cloud workloads. We also want to identify solutions, such as the use of Graviton processors, for increased performance at lower price. Cost optimization is a continuous process that requires the identification of the right tools for each job, as well as the adoption of efficient designs for your system.
Govern cloud usage and avoid cost surprises without slowing down innovation within your organization. In this re:Invent 2022 session, you can learn how to set up guardrails and operationalize cost control within your organizations using services, such as AWS Budgets and AWS Cost Anomaly Detection, and explore the latest enhancements in the AWS cost control space. Additionally, Mercado Libre shares how they automate their cloud cost control through central management and automated algorithms.
Work backwards from team needs to define/deploy cloud governance in AWS environments
Compute optimization
When it comes to optimizing compute workloads, there are many tools available, such as AWS Compute Optimizer, Amazon EC2 Spot Instances, Amazon EC2 Reserved Instances, and Graviton instances. Modernizing your applications can also lead to cost savings, but you need to know how to use the right tools and techniques in an effective and efficient way.
For AWS Lambda functions, you can use the AWS Lambda Cost Optimization video to learn how to optimize your costs. The video covers topics, such as understanding and graphing performance versus cost, code optimization techniques, and avoiding idle wait time. If you are using Amazon Elastic Container Service (Amazon ECS) and AWS Fargate, you can watch a Twitch video on cost optimization using Amazon ECS and AWS Fargate to learn how to adjust your costs. The video covers topics like using spot instances, choosing the right instance type, and using Fargate Spot.
The choice of the hardware is a fundamental driver for performance, cost, as well as resource consumption of the systems we build. Graviton is a family of processors designed by AWS to support cloud-based workloads and give improvements in terms of performance and cost. This re:Invent 2022 presentation introduces Graviton and addresses the problems it can solve, how the underlying CPU architecture is designed, and how to get started with it. Furthermore, you can learn the journey to move different types of workloads to this architecture, such as containers, Java applications, and C applications.
The Cost Optimization section of the AWS Well Architected Workshop helps you learn how to optimize your AWS costs by using features, such as AWS Compute Optimizer, Spot Instances, and Reserved Instances. The workshop includes hands-on labs that walk you through the process of optimizing costs for different types of workloads and services, such as Amazon Elastic Compute Cloud, Amazon ECS, and Lambda.
In a multi-tenant architecture multiple instances of an application run on a shared infrastructure. With this type of approach, each tenant is isolated from others, typically through logical separation, while utilizing a shared infrastructure. This allows multiple tenants to use the same application and maintain their data security, privacy, and customization requirements.
Understanding architectural patterns for multi-tenancy has become crucial for architects and developers aiming to deliver scalable, secure, and cost-effective solutions. Isolating tenant data is a fundamental responsibility for Software as a Service (SaaS) providers. In this edition of Let’s Architect!, we talk about comprehensive exploration of multi-tenant architectures, covering various aspects, such as SaaS microservices, SaaS serverless, SaaS EKS, and an insightful whitepaper.
In this session, Michael Beardsley, Principal Solutions Architect at AWS, takes a deep dive into the realm of multi-tenant microservices, exploring various patterns and strategies that enable the seamless implementation of multi-tenant microservices, all while ensuring that additional complexity is not imposed upon the SaaS builders. He shares practical patterns to simplify the development process by addressing crucial aspect, such as authorization, data access, tenant isolation, metrics, billing, logging, and a plethora of other considerations; this is irrespective of the chosen compute platform (like Amazon Elastic Container Service, Amazon Elastic Kubernetes Service [Amazon EKS], or AWS Lambda) or database solution.
There is another session available that highlights specific techniques and architecture strategies that can directly impact the success of a SaaS business. If you’re interested in learning more about optimizing multi-tenant SaaS architecture, this session is a great opportunity.
In this AWS Partner Network (APN) Blog post, you will explore a reference solution that presents a comprehensive perspective on a functional multi-tenant serverless SaaS environment. This solution effectively showcases various essential components required to construct a multi-tenant SaaS solution using serverless services, including onboarding processes, tenant isolation mechanisms, data partitioning techniques, a tenant deployment pipeline, and robust observability measures.
By delving into these aspects, you can gain valuable insights into the architecture and design considerations involved in creating a successful multi-tenant SaaS solution.
In this re:Invent 2021 presentation, Tod Golding, Principal Partner Solutions Architect, chats about a SaaS reference solution that addresses fundamental multi-tenant considerations, examining its approach to core SaaS topics, including tenant isolation, identity, onboarding, tenant administration, and data partitioning. The goal is to explore an Amazon EKS SaaS architecture through the lens of working code and highlight the key architectural strategies that were used in this reference environment.
There is also valuable information available on Github regarding EKS multi-tenancy. Exploring the Github repositories related to EKS multi-tenancy can provide further insights, resources, and practical examples for implementing multi-tenant architectures on EKS. This presentation is an engaging way to dive deeper into this topic and gain a more comprehensive understanding of best practices and real-world implementations.
Storage represents a challenging aspect of building and delivering multi-tenant software solutions. There are different strategies that can be used to partition tenant data, each with a unique set of trade-offs for implementing separation between tenants. This whitepaper covers different storage models for multi-tenancy; in particular, you can learn about the:
Silo model (data from the tenant is fully isolated)
Pool model (all the tenants use the same database and table)
Bridge model (single database but a different table for each tenant)
For each of these models, the whitepaper describes in detail how they can be implemented, as well as the different trade-offs in terms of isolation and agility. You can also discover how these tenancy models can be implemented specifically on databases, such as Amazon DynamoDB and Amazon Relational Database Service, thus covering both NoSQL and SQL scenarios.
In 2022, we published Let’s Architect! Architecting microservices with containers. We covered integrations patterns and some approaches for implementing microservices using containers. In this Let’s Architect! post, we want to drill down into microservices only, by focusing on the main challenges that software architects and engineers face while working on large distributed systems structured as a set of independent services.
There are many considerations to cover in detail within a broad topic like microservices. We should reflect on the organizational structure, automation pipelines, multi-account strategy, testing, communication, and many other areas. With this post we dive deep into the topic by analyzing the options for discoverability and connectivity available through Amazon VPC Lattice; then, we focus on architectural patterns for communication, mainly on asynchronous communication, as it fits very well into the paradigm. Finally, we explore how to work with serverless microservices and analyze a case study from Amazon, coming directly from the Amazon Builder’s Library.
Modern applications are often built using a microservice distributed approach, which involves dividing the application into smaller, specialized services. Each of these services implement their own subset of functionalities or business logic. To facilitate communication between these services, it is essential to have a method to authorize, route, and monitor network traffic. It is also important, in case of issues, to have the ability of identifying the root cause of an issue, whether it originates at the application, service, or network level.
Amazon VPC Lattice can offer a consistent way to connect, secure, and monitor communication between instances, containers, and serverless functions. With Amazon VPC Lattice, you can define policies for traffic management, network access, advanced routing, implement discoverability, and, at the same time, monitor how the traffic is flowing inside complex applications in near real time.
Loosely coupled integration can help you design independent systems that can be developed and operated individually, plus increase the availability and reliability of the overall system landscape—particularly by using asynchronous communication. While there are many approaches for integration and conversation scenarios, it’s not always clear which approach is best for a given situation.
Join this re:Invent 2022 session to learn about foundational patterns for integration and conversation scenarios with an emphasis on loose coupling and asynchronous communication. Explore real-world use cases architected with cloud-native and serverless services, and receive guidance on choosing integration technology.
Loosely coupled integration can help you design independent systems that can be developed and operated individually and can also increase the availability and reliability of the overall system
Software engineers love patterns—proven approaches to well-known problems that make software development easier and set our projects up for success. In complex, distributed systems, such as microservices, patterns like CQRS and Event Sourcing help decouple and scale systems.
The first part of the video is all about introducing architectural patterns and their applications, while the second part contains a set of demos and examples from the AWS console. In this session, we examine at some typical patterns for building robust and performant serverless microservices, and how data access patterns can drive polyglot persistence.
With event sourcing data is stored as a series of events, instead of direct updates to data stores; microservices replay events from an event store to compute the appropriate state of their own data stores
If we don’t pay attention to the relative scale of a service and its clients, distributed systems with microservices can be at risk of overload. A common architecture pattern adopted by many AWS services consists of splitting the system in a control plane and a data plane.
This article drills down into this scenario to understand what could happen if the data plane fleet exceeds the scale of the control plane fleet by a factor of 100 or more. This can happen in a microservices-based architecture when service X recovers from an outage and starts sending a large amount of request to service Y. Without careful fine-tuning, this shift in behavior can overwhelm the smaller callee. With this resource, we want to share some mental models and design strategies that are beneficial for distributed systems and teams working on microservices architectures.
To stay updated on the data plane’s operational state, the control plane can poll an Amazon S3 bucket into which data plane servers periodically write that information
See you next time!
Thanks for stopping by! Join us in two weeks when we’ll discuss multi-tenancy and patterns for SaaS on AWS.
During his re:Invent 2022 keynote, Werner Vogels, AWS Vice President and Chief Technology Officer, emphasized the asynchronous nature of our world and the challenges associated with incorporating asynchronicity into our architectures. AWS serverless services can help users concentrate on the asynchronous aspects of their workloads, easing the execution of event-driven architectures and enabling the adoption of effective integration patterns for communication both within and beyond a bounded context.
In this edition of Let’s Architect!, we offer an in-depth exploration of the architecture of serverless AWS services, such as AWS Lambda. We also present a new workshop centered on design patterns employing serverless AWS services, which ultimately delivers valuable insights on implementing event-driven architectures within systems.
This video is the perfect companion for those seeking to learn and master a Lambda architecture, empowering you to effectively leverage its capabilities in your workloads.
With the knowledge gained from this video, you will be well-equipped to design your functions’ code in a highly optimized manner, ensuring efficient performance and resource utilization. Furthermore, a comprehensive understanding of Lambda functions can help identify and apply the most suitable approach to cloud workloads, resulting in an agile and robust cloud infrastructure that meets a project’s unique requirements.
This example of an event-driven serverless architecture showcases the power of leveraging AWS services and AI technologies to develop innovative solutions. Built upon a foundation of serverless services, including Amazon EventBridge, Amazon DynamoDB, Lambda, Amazon Simple Storage Service, and managed artificial intelligence (AI ) services like Amazon Polly, this architecture demonstrates the seamless capacity to create daily stories with a scheduled launch. By utilizing EventBridge scheduler, an Lambda function is initiated every night to generate new content. The integration of AI services, like ChatGPT and DALL-E, further elevates the solution, as their compatibility with the serverless model enables efficient and dynamic content creation. This case serves as a testament to the potential of combining event-driven serverless architectures, with cutting-edge AI technologies for inventive and impactful applications.
The AWS Serverless Patterns workshop offers a comprehensive learning experience to enhance your understanding of architectural patterns applicable to serverless projects. Throughout the workshop, participants will delve into various patterns, such as synchronous and asynchronous implementations, tailored to meet the demands of modern serverless applications. This hands-on approach ensures a production-ready understanding, encompassing crucial topics like testing serverless workloads, establishing automation pipelines, and more. Take this workshop to elevate your serverless architecture knowledge!
Serverlesspresso is an event-driven, serverless workload that uses EventBridge and AWS Step Functions to coordinate events across microservices and support thousands of orders per day. This comprehensive session delves into design considerations, development processes, and valuable lessons learned from creating a production-ready solution. Discover practical patterns and extensibility options that contribute to a robust, scalable, and cost-effective application. Gain insights into combining EventBridge and Step Functions to address complex architectural challenges in larger applications.
Most of AWS customers building cloud-native applications or modernizing applications choose containers to run their microservices applications to accelerate innovation and time to market while lowering their total cost of ownership (TCO). Using containers in AWS comes with other benefits, such as increased portability, scalability, and flexibility.
The combination of containers technologies and AWS services also provides features such as load balancing, auto scaling, and service discovery, making it easier to deploy and manage applications at scale.
In this edition of Let’s Architect! we share useful resources to help you to get started with containers on AWS.
This whitepaper describes the Container Build Lens for the AWS Well-Architected Framework. It helps customers review and improve their cloud-based architectures and better understand the business impact of their design decisions. The document describes general design principles for containers, as well as specific best practices and implementation guidance using the Six Pillars of the Well-Architected Framework.
The EKS Workshop is a useful resource to familiarize yourself with Amazon Elastic Kubernetes Service (Amazon EKS) by practicing on real use-cases. It is built to help users learn about Amazon EKS features and integrations with popular open-source projects. The workshop is abstracted into high-level learning modules, including Networking, Security, DevOps Automation, and more. These are further broken down into standalone labs focusing on a particular feature, tool, or use case.
Once you’re done experimenting with EKS Workshop, start building your environments with Amazon EKS Blueprints, a collection of Infrastructure as Code (IaC) modules that helps you configure and deploy consistent, batteries-included Amazon EKS clusters across accounts and regions following AWS best practices. Amazon EKS Blueprints are available in both Terraform and CDK.
Learn how to architect an highly available and resilient application using AWS App Runner. With App Runner, you can start with just the source code of your application or a container image. The complexity of running containerized applications is abstracted away, including the cloud resources needed for running your web application or API. App Runner manages load balancers, TLS certificates, auto scaling, logs, metrics, teachability and more, so you can focus on implementing your business logic in a highly scalable and elastic environment.
As part of designing any modern system on AWS, it is necessary to think about the security implications and what can affect your security posture. This session introduces the fundamentals of the Kubernetes architecture and common attack vectors. It also includes security controls provided by Amazon EKS and suggestions on how to address them. With these strategies, you can learn how to reduce risk for your Kubernetes-based workloads.
Many customers migrate their systems to Amazon Web Services (AWS) to increase their competitive edge and drive business value. To maximize the benefits of a cloud migration, companies tend to move their applications in conjunction with modernization initiatives. These joined efforts help your applications gain more agility, scalability, and resilience. Modernizing the portfolio of workloads with AWS means that you can re-platform, refactor, or replace these workloads by using containers, serverless technologies, purpose-built data stores, and software automation. These functionalities allow you to benefit from the best of the AWS agility and total cost optimization (TCO) benefits.
In this edition of Let’s Architect! we share hands-on activities, customer stories, and tips and tricks to migrate and modernize your applications with AWS.
Would you think that small companies always migrate faster than large enterprises? Actually, cloud migration speed doesn’t necessarily depend on the size of the business! Company size is not a clear indicator of migration and modernization success, but a shift of culture and mindset is essential for successful company evolution.
When it comes to migration, the cost of doing nothing is not just financial: Businesses can also expect a slower pace of innovation and a higher security burden. This video analyzes the financial benefits of migration and shares mental models for approaching an AWS cloud migration, and Marriott team members explain how they planned their migration and the lessons learned along the way.
Organizations aim to deliver the best technological solutions based on customer needs. At any stage in their cloud adoption journey, businesses often end up managing and building monolithic applications. Let’s explore a migration path for a monolithic .NET Framework application to a modern microservices-based stack on AWS, and discuss AWS tools to break the monolith into microservices and containerize applications.
Cost optimization is another key factor for modernizing your workloads and solutions include moving to Linux-based systems or using open-source database engines. This Migrate and Modernize enterprise workloads with AWS video walks you through the process of migrating and modernizing enterprise workloads with AWS.
Organizations of all sizes want to benefit from the agility, cost savings, and developer experience that serverless architectures can provide on AWS. For large enterprises, the return on investment (ROI) can be massive, but overcoming architecture inertia while ensuring security best practices and governance stay in place is a hurdle that many struggle with. In this lightning talk, learn how your organization can implement a serverless-first strategy to overcome these obstacles. Delta Air Lines shares the story of making serverless-first a reality as part of their AWS journey.
This workshop shows you how to migrate and modernize a fictional application to the AWS Cloud by:
Performing a database migration
Migrating and modernizing your web server using different migration strategies (for example, breaking down the monolith into containers)
Teaching you how to improve Operation excellence, Security, Performance efficiency, and Cost optimization of the deployed architecture by following these pillars of the AWS Well-Architected Framework.
Tools, such as diagramming software, low-code applications, and frameworks, make it possible to experiment quickly. They are essential in today’s fast-paced and technology-driven world. From improving efficiency and accuracy, to enhancing collaboration and creativity, a well-defined set of tools can make a significant impact on the quality and success of a project in the area of software architecture.
As an architect, you can take advantage of a wide range of resources to help you build solutions that meet the needs of your organization. For example, with tools in the likes of the Amazon Web Services (AWS) Solutions Library and Serverless Land, you can boost your knowledge and productivity while working on event-driven architectures, microservices, and stateless computing.
In this Let’s Architect! edition, we explore how to incorporate these patterns into your architecture, and which tools to leverage to build solutions that are scalable, secure, and cost-effective.
In this re:Invent 2022 session, Chase Douglas, Principal Engineer at AWS, speaks about AWS Application Composer, a newly launched service.
This service has the potential to change the way architects design solutions—without writing a single line of code! The service is user-friendly, intuitive, and requires no prior coding experience. It allows users to scaffold a serverless architecture, defining a CloudFormation template visually with drag-and-drop. A detailed AWS Compute Blog post takes readers through the process of using AWS Application Composer.
How an architecture can be designed with AWS Application Composer
AWS design + build tools
When migrating to the cloud, we suggest referencing these four tried-and-true AWS resources that can be used to design and build projects.
AWS Workshops are created by AWS teams to provide opportunities for hands-on learning to develop practical skills. Workshops are available in multiple categories and for skill levels 100-400.
AWS Architecture Center contains a collection of best practices and architectural patterns for designing and deploying cloud-based solutions using AWS services. Furthermore, it includes detailed architecture diagrams, whitepapers, case studies, and other resources that provide a wealth of information on how to design and implement cloud solutions.
Serverless Land (an Amazon property) brings together various patterns, workflows, code snippets, and blog posts pertaining to AWS serverless architectures.
AWS Solutions Library provides customers with templates, tools, and automated workflows to easily deploy, operate, and manage common use cases on the AWS Cloud.
Inside event-driven architectures designed by David Boyne on Serverless Land
In this session, the AWS Well-Architected provides guidance on how to implement the architectural models reported in the AWS Well-Architected Framework within your organization at scale.
Discover a customer story and understand how to use the features of the AWS Well-Architected Tool and APIs to receive recommendations based on your workload and measure your architectural metrics. In the Framework whitepaper, you can explore the six pillars of Well-Architected (operational excellence, security, reliability, performance efficiency, cost optimization, and sustainability) and best practices to achieve them.
Understanding the key design pillars can help architects make informed design decisions, leading to more robust and efficient solutions. This knowledge also enables architects to identify potential problems early on in the design process and find appropriate patterns to address those issues.
Sustainability is an important topic in the tech industry, as well as society as a whole, and defined as the ability to continue to perform a process or function over an extended period of time without depletion of natural resources or the environment.
One of the key elements to designing a sustainable workload is software architecture. Think about how event-driven architecture can help reduce the load across multiple microservices, leveraging solutions like batching and queues. In these cases, the main traffic is absorbed at the entry-point of a cloud workload and ease inside your system. On top of architecture, think about data patterns, hardware optimizations, multi-environment strategies, and many more aspects of a software development lifecycle that can contribute to your sustainable posture in the Cloud.
The key takeaway: designing with sustainability in mind can help you build an application that is not only durable but also flexible enough to maintain the agility your business requires.
In this edition of Let’s Architect!, we share hands-on activities, case studies, and tips and tricks for making your Cloud applications more sustainable.
This session provides updates on these programs and highlights the most effective techniques for optimizing your AWS architectures. Find out how Amazon Prime Video used these tools to establish baselines and drive significant efficiencies across their AWS usage.
The modern data architecture is the foundation for a sustainable and scalable platform that enables business intelligence. This AWS Architecture Blog series provides tips on how to develop a modern data architecture with sustainability in mind.
Comprised of two posts, it helps you revisit and enhance your current data architecture without compromising sustainability.
This workshop introduces participants to the AWS Well-Architected Framework, a set of best practices for designing and operating high-performing, highly scalable, and cost-efficient applications on AWS. The workshop also discusses how sustainability is critical to software architecture and how to use the AWS Well-Architected Framework to improve your application’s sustainability performance.
In this video, you can learn about the benefits of Rust and AWS Graviton to reduce energy consumption and increase performance. Rust combines the resource efficiency of programming languages, like C, with memory safety of languages, like Java. The video also explains the benefits deriving from AWS Graviton processors designed to deliver performance- and cost-optimized cloud workloads. This resource is very helpful to understand how sustainability can become a driver for cost optimization.
During the design of distributed systems, we have to identify a communication strategy to exchange information between different services while keeping the evolutionary nature of the architecture in mind. Event-driven architectures are based on events (facts that happened in a system), which are asynchronously exchanged to implement communication across different services while having a high degree of decoupling. This paradigm also allows us to run code in response to events, with benefits like cost optimization and sustainability for the entire infrastructure.
In this edition of Let’s Architect!, we share architectural resources to introduce event-driven architectures, how to build them on AWS, and how to approach the design phase.
re:Invent 2022 may be finished, but the keynote given by Amazon’s Chief Technology Officer, Dr. Werner Vogels, will not be forgotten. Vogels not only covered the announcements of new services but also event-driven architecture foundations in conjunction with customers’ stories on how this architecture helped to improve their systems.
In this blog post, we enumerate clearly and concisely the benefits of event-driven architectures, such as scalability, fault tolerance, and developer velocity. This is a great post to start your journey into the event-driven architecture style, as it explains the difference from request-response architecture.
When we build distributed systems or migrate from a monolithic to a microservices architecture, we need to identify a communication strategy to integrate the different services. Teams who are building microservices often find that integration with other applications and external services can make their workloads tightly coupled.
In this re:Invent 2022 video, you learn how to use event-driven architectures to decouple and decentralize application components through asynchronous communication. The video introduces the differences between synchronous and asynchronous communications before drilling down into some key concepts for designing and building event-driven architectures on AWS.
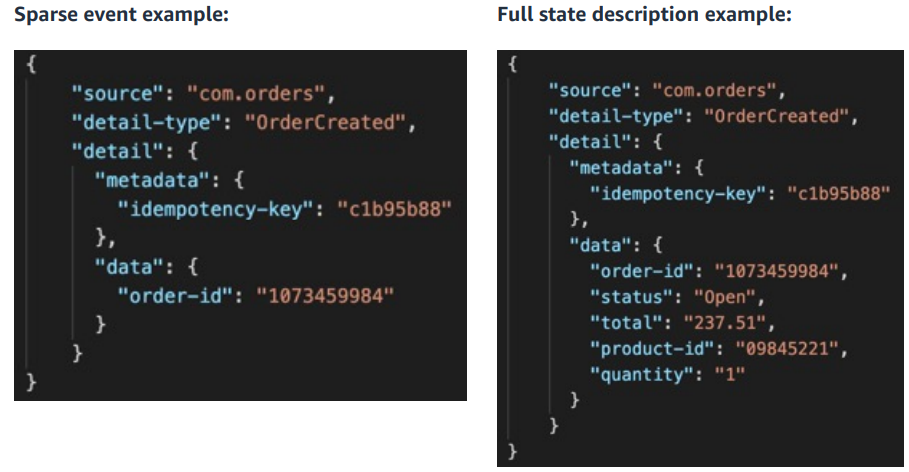
When starting on the journey to event-driven architectures, a common challenge is how to design events: “how much data should an event contain?” is a typical first question we encounter.
In this pragmatic post, you can explore the different types of events, watch a video that explains even further how to use event-driven architectures, and also go through the new event-driven architecture section of serverlessland.com.
AWS re:Invent returned to Las Vegas, Nevada, November 28 to December 2, 2022. After a virtual event in 2020 and a hybrid 2021 edition, spirits were high as over 51,000 in-person attendees returned to network and learn about the latest AWS innovations.
Now in its 11th year, the conference featured 5 keynotes, 22 leadership sessions, and more than 2,200 breakout sessions and hands-on labs at 6 venues over 5 days.
With well over 100 service and feature announcements—and innumerable best practices shared by AWS executives, customers, and partners—distilling highlights is a challenge. From a security perspective, three key themes emerged.
Turn data into actionable insights
Security teams are always looking for ways to increase visibility into their security posture and uncover patterns to make more informed decisions. However, as AWS Vice President of Data and Machine Learning, Swami Sivasubramanian, pointed out during his keynote, data often exists in silos; it isn’t always easy to analyze or visualize, which can make it hard to identify correlations that spark new ideas.
“Data is the genesis for modern invention.” – Swami Sivasubramanian, AWS VP of Data and Machine Learning
At AWS re:Invent, we launched new features and services that make it simpler for security teams to store and act on data. One such service is Amazon Security Lake, which brings together security data from cloud, on-premises, and custom sources in a purpose-built data lake stored in your account. The service, which is now in preview, automates the sourcing, aggregation, normalization, enrichment, and management of security-related data across an entire organization for more efficient storage and query performance. It empowers you to use the security analytics solutions of your choice, while retaining control and ownership of your security data.
Amazon Security Lake has adopted the Open Cybersecurity Schema Framework (OCSF), which AWS cofounded with a number of organizations in the cybersecurity industry. The OCSF helps standardize and combine security data from a wide range of security products and services, so that it can be shared and ingested by analytics tools. More than 37 AWS security partners have announced integrations with Amazon Security Lake, enhancing its ability to transform security data into a powerful engine that helps drive business decisions and reduce risk. With Amazon Security Lake, analysts and engineers can gain actionable insights from a broad range of security data and improve threat detection, investigation, and incident response processes.
Strengthen security programs
According to Gartner, by 2026, at least 50% of C-Level executives will have performance requirements related to cybersecurity risk built into their employment contracts. Security is top of mind for organizations across the globe, and as AWS CISO CJ Moses emphasized during his leadership session, we are continuously building new capabilities to help our customers meet security, risk, and compliance goals.
In addition to Amazon Security Lake, several new AWS services announced during the conference are designed to make it simpler for builders and security teams to improve their security posture in multiple areas.
Identity and networking
Authorization is a key component of applications. Amazon Verified Permissions is a scalable, fine-grained permissions management and authorization service for custom applications that simplifies policy-based access for developers and centralizes access governance. The new service gives developers a simple-to-use policy and schema management system to define and manage authorization models. The policy-based authorization system that Amazon Verified Permissions offers can shorten development cycles by months, provide a consistent user experience across applications, and facilitate integrated auditing to support stringent compliance and regulatory requirements.
Additional services that make it simpler to define authorization and service communication include Amazon VPC Lattice, an application-layer service that consistently connects, monitors, and secures communications between your services, and AWS Verified Access, which provides secure access to corporate applications without a virtual private network (VPN).
Threat detection and monitoring
Monitoring for malicious activity and anomalous behavior just got simpler. Amazon GuardDuty RDS Protection expands the threat detection capabilities of GuardDuty by using tailored machine learning (ML) models to detect suspicious logins to Amazon Aurora databases. You can enable the feature with a single click in the GuardDuty console, with no agents to manually deploy, no data sources to enable, and no permissions to configure. When RDS Protection detects a potentially suspicious or anomalous login attempt that indicates a threat to your database instance, GuardDuty generates a new finding with details about the potentially compromised database instance. You can view GuardDuty findings in AWS Security Hub, Amazon Detective (if enabled), and Amazon EventBridge, allowing for integration with existing security event management or workflow systems.
To bolster vulnerability management processes, Amazon Inspector now supports AWS Lambda functions, adding automated vulnerability assessments for serverless compute workloads. With this expanded capability, Amazon Inspector automatically discovers eligible Lambda functions and identifies software vulnerabilities in application package dependencies used in the Lambda function code. Actionable security findings are aggregated in the Amazon Inspector console, and pushed to Security Hub and EventBridge to automate workflows.
Data protection and privacy
The first step to protecting data is to find it. Amazon Macie now automatically discovers sensitive data, providing continual, cost-effective, organization-wide visibility into where sensitive data resides across your Amazon Simple Storage Service (Amazon S3) estate. With this new capability, Macie automatically and intelligently samples and analyzes objects across your S3 buckets, inspecting them for sensitive data such as personally identifiable information (PII), financial data, and AWS credentials. Macie then builds and maintains an interactive data map of your sensitive data in S3 across your accounts and Regions, and provides a sensitivity score for each bucket. This helps you identify and remediate data security risks without manual configuration and reduce monitoring and remediation costs.
Encryption is a critical tool for protecting data and building customer trust. The launch of the end-to-end encrypted enterprise communication service AWS Wickr offers advanced security and administrative controls that can help you protect sensitive messages and files from unauthorized access, while working to meet data retention requirements.
Management and governance
Maintaining compliance with regulatory, security, and operational best practices as you provision cloud resources is key. AWS Config rules, which evaluate the configuration of your resources, have now been extended to support proactive mode, so that they can be incorporated into infrastructure-as-code continuous integration and continuous delivery (CI/CD) pipelines to help identify noncompliant resources prior to provisioning. This can significantly reduce time spent on remediation.
Managing the controls needed to meet your security objectives and comply with frameworks and standards can be challenging. To make it simpler, we launched comprehensive controls management with AWS Control Tower. You can use it to apply managed preventative, detective, and proactive controls to accounts and organizational units (OUs) by service, control objective, or compliance framework. You can also use AWS Control Tower to turn on Security Hub detective controls across accounts in an OU. This new set of features reduces the time that it takes to define and manage the controls required to meet specific objectives, such as supporting the principle of least privilege, restricting network access, and enforcing data encryption.
Do more with less
As we work through macroeconomic conditions, security leaders are facing increased budgetary pressures. In his opening keynote, AWS CEO Adam Selipsky emphasized the effects of the pandemic, inflation, supply chain disruption, energy prices, and geopolitical events that continue to impact organizations.
Now more than ever, it is important to maintain your security posture despite resource constraints. Citing specific customer examples, Selipsky underscored how the AWS Cloud can help organizations move faster and more securely. By moving to the cloud, agricultural machinery manufacturer Agco reduced costs by 78% while increasing data retrieval speed, and multinational HVAC provider Carrier Global experienced a 40% reduction in the cost of running mission-critical ERP systems.
“If you’re looking to tighten your belt, the cloud is the place to do it.” – Adam Selipsky, AWS CEO
Security teams can do more with less by maximizing the value of existing controls, and bolstering security monitoring and analytics capabilities. Services and features announced during AWS re:Invent—including Amazon Security Lake, sensitive data discovery with Amazon Macie, support for Lambda functions in Amazon Inspector, Amazon GuardDuty RDS Protection, and more—can help you get more out of the cloud and address evolving challenges, no matter the economic climate.
Security is our top priority
AWS re:Invent featured many more highlights on a variety of topics, such as Amazon EventBridge Pipes and the pre-announcement of GuardDuty EKS Runtime protection, as well as Amazon CTO Dr. Werner Vogels’ keynote, and the security partnerships showcased on the Expo floor. It was a whirlwind week, but one thing is clear: AWS is working harder than ever to make our services better and to collaborate on solutions that ease the path to proactive security, so that you can focus on what matters most—your business.
In the weeks leading up to AWS re:invent 2022, I’ll share conversations I’ve had with some of the humans who work in AWS Security who will be presenting at the conference, and get a sneak peek at their work and sessions. In this profile, I interviewed Sarah Currey, Delivery Practice Manager in World Wide Professional Services (ProServe).
How long have you been at AWS and what do you do in your current role?
I’ve been at AWS since 2019, and I’m a Security Practice Manager who leads a Security Transformation practice dedicated to helping customers build on AWS. I’m responsible for leading enterprise customers through a variety of transformative projects that involve adopting AWS services to help achieve and accelerate secure business outcomes.
In this capacity, I lead a team of awesome security builders, work directly with the security leadership of our customers, and—one of my favorite aspects of the job—collaborate with internal security teams to create enterprise security solutions.
How did you get started in security?
I come from a non-traditional background, but I’ve always had an affinity for security and technology. I started off learning HTML back in 2006 for my Myspace page (blast from the past, I know) and in college, I learned about offensive security by dabbling in penetration testing. I took an Information Systems class my senior year, but otherwise I wasn’t exposed to security as a career option. I’m from Nashville, TN, so the majority of people I knew were in the music or healthcare industries, and I took the healthcare industry path.
I started my career working at a government affairs firm in Washington, D.C. and then moved on to a healthcare practice at a law firm. I researched federal regulations and collaborated closely with staffers on Capitol Hill to educate them about controls to protect personal health information (PHI), and helped them to determine strategies to adhere to security, risk, and compliance frameworks such as HIPAA and (NIST) SP 800-53. Government regulations can lag behind technology, which creates interesting problems to solve. But in 2015, I was assigned to a project that was planned to last 20 years, and I decided I wanted to move into an industry that operated as a faster pace—and there was no better place than tech.
From there, I moved to a startup where I worked as a Project Manager responsible for securely migrating customers’ data to the software as a service (SaaS) environment they used and accelerating internal adoption of the environment. I often worked with software engineers and asked, “why is this breaking?” so they started teaching me about different aspects of the service. I interacted regularly with a female software engineer who inspired me to start teaching myself to code. After two years of self-directed learning, I took the leap and quit my job to do a software engineering bootcamp. After the course, I worked as a software engineer where I transformed my security assurance skills into the ability to automate security. The cloud kept coming up in conversations around migrations, so I was curious and achieved software engineering and AWS certifications, eventually moving to AWS. Here, I work closely with highly regulated customers, such as those in healthcare, to advise them on using AWS to operate securely in the cloud, and work on implementing security controls to help them meet frameworks like NIST and HIPAA, so I’ve come full circle.
How do you explain your job to non-technical friends and family?
The general public isn’t sure how to define the cloud, and that’s no different with my friends and family. I get questions all the time like “what exactly is the cloud?” Since I love storytelling, I use real-world examples to relate it to their profession or hobbies. I might talk about the predictive analytics used by the NFL or, for my friends in healthcare, I talk about securing PHI.
However, my favorite general example is describing the AWS Shared Responsibility Model as a house. Imagine a house—AWS is responsible for security of the house. We’re responsible for the physical security of the house, and we build a fence, we make sure there is a strong foundation and secure infrastructure. The customer is the tenant—they can pay as they go, leave when they need to—and they’re responsible for running the house and managing the items, or data, in the house. So it’s my job to help the customer implement new ideas or technologies in the house to help them live more efficiently and securely. I advise them on how to best lock the doors, where to store their keys, how to keep track of who is coming in and out of the house with access to certain rooms, and how to protect their items in the house from other risks.
And for my friends that love Harry Potter, I just say that I work in the Defense Against the Dark Arts.
What are you currently working on that you’re excited about?
There are a lot of things in different spaces that I’m excited about.
One is that I’m part of a ransomware working group to provide an offering that customers can use to prepare for a ransomware event. Many customers want to know what AWS services and features they can use to help them protect their environments from ransomware, and we take real solutions that we’ve used with customers and scale them out. Something that’s really cool about Professional Services is that we’re on the frontlines with customers, and we get to see the different challenges and how we can relate those back to AWS service teams and implement them in our products. These efforts are exciting because they give customers tangible ways to secure their environments and workloads. I’m also excited because we’re focusing not just on the technology but also on the people and processes, which sometimes get forgotten in the technology space.
I’m a huge fan of cross-functional collaboration, and I love working with all the different security teams that we have within AWS and in our customer security teams. I work closely with the Amazon Managed Services (AMS) security team, and we have some very interesting initiatives with them to help our customers operate more securely in the cloud, but more to come on that.
Another exciting project that’s close to my heart is the Inclusion, Diversity, and Equity (ID&E) workstream for the U.S. It’s really important to me to not only have diversity but also inclusion, and I’m leading a team that is helping to amplify diverse voices. I created an Amplification Flywheel to help our employees understand how they can better amplify diverse voices in different settings, such as meetings or brainstorming sessions. The flywheel helps illustrate a process in which 1) an idea is voiced by an underrepresented individual, 2) an ally then amplifies the idea by repeating it and giving credit to the author, 3) others acknowledge the contribution, 4) this creates a more equitable workplace, and 5) the flywheel continues where individuals feel more comfortable sharing ideas in the future.
Within this workstream, I’m also thrilled about helping underrepresented people who already have experience speaking but who may be having a hard time getting started with speaking engagements at conferences. I do mentorship sessions with them so they can get their foot in the door and amplify their own voice and ideas at conferences.
You’re presenting at re:Invent this year. Can you give us a sneak peek of your session?
I’m partnering with Johnny Ray, who is an AMS Senior Security Engineer, to present a session called SEC203: Revitalize your security with the AWS Security Reference Architecture. We’ll be discussing how the AWS SRA can be used as a holistic guide for deploying the full complement of AWS security services in a multi-account environment. The AWS SRA is a living document that we continuously update to help customers revitalize their security best practices as they grow, scale, and innovate.
What do you hope attendees take away from your session?
Technology is constantly evolving, and the security space is no exception. As organizations adopt AWS services and features, it’s important to understand how AWS security services work together to improve your security posture. Attendees will be able to take away tangible ways to:
Define the target state of your security architecture
Review the capabilities that you’ve already designed and revitalize them with the latest services and features
Bootstrap the implementation of your security architecture
Start a discussion about organizational governance and responsibilities for security
Johnny and I will also provide attendees with a roadmap at the end of the session that gives customers a plan for the first week after the session, one to three months after the session, and six months after the session, so they have different action items to implement within their organization.
You’ve written about the importance of ID&E in the workplace. In your opinion, what’s the most effective way leaders can foster an inclusive work environment?
I’m super passionate about ID&E, because it’s really important and it makes businesses more effective and a better place to work as a whole. My favorite Amazon Leadership Principle is Earn Trust. It doesn’t matter if you Deliver Results or Insist on the Highest Standards if no one is willing to listen to you because you don’t have trust built up. When it comes to building an inclusive work environment, a lot of earning trust comes from the ability to have empathy, vulnerability, and humility—being able to admit when you made a mistake—with your teammates as well as with your customers. I think we have a unique opportunity at AWS to work closely with customers and learn about what they’re doing and their best practices with ID&E, and share our best practices.
We all make mistakes, we’re all learning, and that’s okay, but having the ability to admit when you’ve made a mistake, apologize, and learn from it makes a much better place to work. When it comes to intent versus impact, I love to give the example—going back to storytelling—of walking down the street and accidentally bumping into someone, causing them to drop their coffee. You didn’t intend to hurt them or spill their coffee; your intent was to keep walking down the street. However, the impact that you had was maybe they’re burnt now, maybe their coffee is all down their clothes, and you had a negative impact on them. Now, you want to apologize and maybe look up more while you’re walking and be more observant of your surroundings. I think this is a good example because sometimes when it comes to ID&E, it can become a culture of blame and that’s not what we want to do—we want to call people in instead of calling them out. I think that’s a great way to build an inclusive team.
You can have a diverse workforce, but if you don’t have inclusion and you’re not listening to people who are underrepresented, that’s not going to help. You need to make sure you’re practicing transformative leadership and truly wanting to change how people behave and think when it comes to ID&E. You want to make sure people are more kind to each other, rather than only checking the box on arbitrary diversity goals. It’s important to be authentic and curious about how you learn from others and their experiences, and to respect them and implement that into different ideas and processes. This is important to make a more equitable workplace.
I love learning from different ID&E leaders like Camille Leak, Aiko Bethea, and Brené Brown. They are inspirational to me because they all approach ID&E with vulnerability and tackle the uncomfortable.
What’s the thing you’re most proud of in your career?
I have two different things—one from a technology standpoint and one from a personal impact perspective.
On the technology side, one of the coolest projects I’ve been on is Change Healthcare, which is an independent healthcare technology company that connects payers, providers, and patients across the United States. They have an important job of protecting a lot of PHI and personally identifiable information (PII) for American citizens. Change Healthcare needed to quickly migrate its ClaimsXten claims processing application to the cloud to meet the needs of a large customer, and it sought to move an internal demo and training application environment to the cloud to enable self-service and agility for developers. During this process, they reached out to AWS, and I took the lead role in advising Change Healthcare on security and how they were implementing their different security controls and technical documentation. I led information security meetings on AWS services, because the processes were new to a lot of the employees who were previously working in data centers. Through working with them, I was able to cut down their migration hours by 58% by using security automation and reduce the cost of resources, as well. I oversaw security for 94 migration cutovers where no security events occurred. It was amazing to see that process and build a great relationship with the company. I still meet with Change Healthcare employees for lunch even though I’m no longer on their projects. For this work, I was awarded the “Above and Beyond the Call of Duty” award, which only three Amazonians get a year, so that was an honor.
From a personal impact perspective, it was terrifying to quit my job and completely change careers, and I dealt with a lot of imposter syndrome—which I still have every day, but I work through it. Something impactful that resulted from this move was that it inspired a lot of people in my network from non-technical backgrounds, especially underrepresented individuals, to dive into coding and pursue a career in tech. Since completing my bootcamp, I’ve had more than 100 people reach out to me to ask about my experience, and about 30 of them quit their job to do a bootcamp and are now software engineers in various fields. So, it’s really amazing to see the life-changing impact of mentoring others.
You do a lot of volunteer work. Can you tell us about the work you do and why you’re so passionate about it?
Absolutely! The importance of giving back to the community cannot be understated.
Over the last 13 years, I have fundraised, volunteered, and advocated in building over 40 different homes throughout the country with Habitat for Humanity. One of my most impactful volunteer experiences was in 2013. I volunteered with a nonprofit called Bike & Build, where we cycled across the United States to raise awareness and money for affordable housing efforts. From Charleston, South Carolina to Santa Cruz, California, the team raised over $158,000, volunteered 3,584 hours, and biked 4,256 miles over the course of three months. This was such an incredible experience to meet hundreds of people across the country and help empower them to learn about affordable housing and improve their lives. It also tested me so much emotionally, mentally, and physically that I learned a lot about myself in the process. Additionally, I was selected by Gap, Inc. to participate in an international Habitat build in Antigua, Guatemala in October of 2014.
I’m currently on the Associate Board of Gilda’s Club, which provides free cancer support to anyone in need. Corporate social responsibility is a passion of mine, and so I helped organize AWS Birthday Boxes and Back to School Bags volunteer events with Gilda’s Club of Middle Tennessee. We purchased and assembled birthday and back-to-school boxes for children whose caregiver was experiencing cancer, so their caregiver would have one less thing to worry about and make sure the child feels special during this tough time. During other AWS team offsites, I’ve organized volunteering through Nashville Second Harvest food bank and created 60 shower and winter kits for individuals experiencing homelessness through ShowerUp.
I also mentor young adult women and non-binary individuals with BuiltByGirls to help them navigate potential career paths in STEM, and I recently joined the Cyversity organization, so I’m excited to give back to the security community.
If you had to pick an industry outside of security, what would you want to do?
History is one of my favorite topics, and I’ve always gotten to know people by having an inquisitive mind. I love listening and asking curious questions to learn more about people’s experiences and ideas. Since I’m drawn to the art of storytelling, I would pick a career as a podcast host where I bring on different guests to ask compelling questions and feature different, rarely heard stories throughout history.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In the weeks leading up to AWS re:Invent 2022, I’m interviewing some of the humans who work in AWS Security, help keep our customers safe and secure, and also happen to be speaking at re:Invent. This interview is with Param Sharma, principal software engineer for AWS Private Certificate Authority (AWS Private CA). AWS Private CA enables you to create private certificate authority (CA) hierarchies, including root and subordinate CAs, without the investment and maintenance costs of operating an on-premises CA.
How long have you been at AWS and what do you do in your current role?
I’ve been here for more than eight years—I joined AWS in July 2014, working in AWS Security. These days, I work on public key infrastructure (PKI) and cryptography, focusing on products like AWS Certificate Manager (ACM) and AWS Private CA.
How did you get started in the world of security, specifically cryptography?
I had a very short stint with crypto during my university days—I presented a paper on steganography and cryptography back in 2002 or 2003. Security has been an integral part of developing and deploying large-scale web applications, which I’ve done throughout my career. But security took center stage in 2014 when I heard from an AWS recruiter about a new service being built that would make certificates easier. I had no clue what that service was, since it was confidential and hadn’t been launched yet, but it brought cryptography back into my life. I started working on this brand-new service, AWS Certificate Manager. I designed the operational security aspect of it and worked to make sure it could be used by millions of our customers and could be available and secure at the same time. I was the second person hired on the ACM team, and since then the team has grown significantly.
What was the most surprising or interesting thing you’ve worked on in your time at AWS?
It might not be surprising, but certainly interesting to me: I was the first engineer to be hired on the AWS Private CA team and I started studying the problem of how certificate authorities would work in the cloud. I had to think about how the customer experience would look, the service architecture design, the operational side of things like availability and security of customer data. Doing a 360-degree review of the service and writing the design document for a service that was eventually deployed in a multitude of AWS Regions was one of the most interesting things I have worked on at AWS. It continues to be an interesting challenge as we add new features—which tend to be like smaller AWS services in their own right even though they are features of AWS Private CA.
How do you explain to customers how to use AWS Private CA?
I start by explaining what a private certificate is. A private certificate provides a flexible way to identify almost anything in an organization without disclosing the name publicly. With AWS Private CA, AWS takes care of the undifferentiated heavy lifting involved in operating a private CA. We provide security configuration, management, and monitoring of highly available private CAs. The service also helps organizations avoid spending money on servers, hardware security modules (HSMs), operations, personnel, infrastructure, software training, and maintenance. Maintaining PKI administrators, for example, can cost hundreds or thousands of dollars per year. AWS Private CA simplifies the process of creating and managing these private CAs and certificates that are used to identify resources and provide a basis for trusted identity in communications.
In your opinion, what is the coolest feature of AWS Private CA?
That’s going to be really hard to pick! To me, the coolest feature is root CA, which gives customers the ability to create and manage root CAs in the cloud. Root CAs are used to create subordinate CAs for issuing identity certificates. And these private CAs can be used to identify resources in a private network within an organization. You can use these private certs on application services, devices, or even for identifying users for identity certificates.
AWS Private CA has evolved since its launch in 2018. What are some of the new ways you see customers using the service?
When AWS Private CA was launched in 2018, the primary feature was to create and manage subordinate CAs, which were signed offline outside of AWS Private CA. The secondary feature was to issue certificates for identifying endpoints for TLS/SSL communication. Over the last four or five years, I’ve seen use cases become more diversified, and the service has evolved as the customers’ needs have evolved. The biggest paradigm shift that I’ve seen is that customers are customizing certificates and using them to identify IoT devices or customer-managed Kubernetes clusters. The certificates can even be used on-premises for your Amazon Elastic Compute Cloud (Amazon EC2) instances or your on-premises servers, where you can use these services to encrypt the traffic in transit or at rest in certain cases. The other more recent use case I’ve started to see is customers using AWS Private CA with AWS Identity and Access Management Roles Anywhere, which launched in July 2022. Customers are using this combination to issue certificates for identity, which is tied to the credentials themselves.
I understand you’ll be speaking at re:Invent 2022. Can you tell us about your session there? What do you hope customers take away from your session?
I am doing two sessions at re:Invent this year. The first one, Understanding the evolution of cloud-based PKI use cases, is a chalk talk about how cloud-based PKI use cases have evolved over the last 5–10 years. This talk is mainly for PKI administrators, information security engineers, developers, managers, directors, and IoT security professionals who want to learn more about how X.509 digital certificates are used in the cloud. We will dive deep into how these certs are being used for normal TLS communication, device certificates, containers, or even certificates used for identity like in IAM Roles Anywhere. The second session is a breakout session called AWS data protection: Using locks, keys, signatures, and certificates. It puts a spotlight on what AWS offers in terms of cryptographic tools and PKI platforms that help our customers navigate their data protection and digital signing needs. This session will provide a ground-floor understanding of how to get this protection by default or when needed, and how can you build your own logs, keys, and signatures for you own cloud application.
What’s the thing you’re most proud of in your career?
I’m proud to work with some of the smartest people who, at the same time, are very humble and genuinely believe in making this world a better place for everyone.
Outside of your work in tech, what is something you’re interested in that might surprise people?
I have a five-year-old and a three-year-old, so whenever I get some time to myself between those two, I love to read and take long strolls. I’m a passionate advocate that every voice is unique and has value to share. I’m a diversity and inclusion ambassador at Amazon and as part of this program, I mentor underrepresented groups and help build a community with integrity and a willingness to listen to others, which provides a space for us to be ourselves without fear of judgement. I try to do volunteer work whenever possible, being involved in community service programs organized through my children’s school activities, or even participating in local community kitchens by cooking and serving food that is distributed through a local non-profit organization.
If you had to pick an industry outside of security, what would you want to do?
I would’ve been a teacher or worked with a non-profit organization mentoring and volunteering. I think volunteering gives me a sense of peace.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.
Want more AWS Security news? Follow us on Twitter.
In the week leading up to AWS re:Invent 2021, we’ll share conversations we’ve had with people at AWS who will be presenting, and get a sneak peek at their work.
How long have you been at AWS, and what do you do in your current role?
I’ve been at AWS for 5½ years. I get to focus on the future of security and compliance. It gives me a lot of space to experiment and try new things, which is how I like to operate.
How did you get started in AWS Security?
I joined AWS through a startup acquisition, and I actually didn’t think I was going to go with the acquisition. I thought AWS would be way too big and move way too slow. I love being in environments where I get to move fast and be entrepreneurial. I started on the product side. I was able to learn what it takes to build and ship products at the scale of AWS – which is on another level and mind-blowing.
Then, like others at AWS, I was able to reinvent myself, find different passions, and experiment with new things. One of those areas for me was compliance. I started to get perspective on how that space was being defined by regulatory activity for the cloud, and it started opening my mind in different ways.
I started thinking, how do you make compliance easier for customers? How do you work with regulated entities to understand how to audit, and to understand the function of how the cloud operates? From there, my career has been about changing how to think about product, about how to make security easier. Layering in this compliance aspect, too, means I get to play in all these different worlds, work with internal and external customers, and work to simplify security, while also understanding where and how compliance fits in, without slowing down innovation.
How do you explain your job to non-tech friends?
I explain my work as removing the fear around security. You go see images of people in hoodies, with darkened faces, and binary code running behind them, and my job is to break that perception and walk in the light – yes, that’s my nod to Olivia Pope in Scandal. I love the idea of that gladiator mentality. You’re going in and solving the big problems, but you’re also creating more visibility and transparency around how security operates. And you’re doing this without making anyone afraid that they’re being watched or monitored, and without holding back innovation. My job is to provide that transparency and clarity, and give people prescriptive guidance on how to operate securely on AWS.
What are you currently working on that you’re excited about?
So much! That’s what I really love about my job – I get to play in a lot of spaces, and the context switching is something that really fuels me. One of the top projects I’m working on is something we just released in response to an ask from the White House, which I feel really privileged to work on. We released a new Cybersecurity Awareness training which is now available to everyone in the world. You can access this training right now, and you can share it with your grandparents or implement it in your corporation or small business. We were able to take a training product we built for all Amazon employees–and then externalize it. The size and the scope is something I’m really excited about. Making security easier for everybody is a big mission for us.
Another big area is up-skilling. You hear a lot about security jobs being the future, so we’re building everything from apprenticeships to new learning paths for anyone interested in security. We’re thinking about how we can build quick learning modules for people to listen to on the go. That’s something I get really excited about in this job – creating opportunities for people to understand that security jobs and opportunities are vast. If you’re curious and want to learn new things, AWS is endless.
You’re presenting at re:Invent this year – can you give readers a sneak peek at what you’re covering?
I am partnering with Eric Brandwine, AWS VP/Distinguished Engineer for a session called Introverts and extroverts collide: Build an inclusive workforce (SEC204). Eric and I are night and day in terms of how we work. In our talk we’ll touch on some of the challenges we had when we first started working together, but how we found value in our different approaches.
We’ll be discussing how he solves problems with technology and how I solve problems regarding people, and thinking about how that empathetic layer resonates between the two perspectives. Not every problem needs technology, and not every problem needs a people-focused solution. But, humans are behind any of those aspects of impact.
We’ll give prescriptive guidance to customers on how they should think about their security culture as it relates to people and as it relates to technology. We’ll talk about how those two worlds can blend together in a way that empowers an entire organization to prioritize security, and that they shouldn’t be afraid of it. We want to help bridge the gaps between the technologists and the empathetic individuals who think about how the technology lands in use cases across a business.
From your perspective, what’s the most important thing leaders can do to create an inclusive work environment?
Listening. Sitting back, getting the feedback, being vulnerable, asking the questions. So much of what we need to do now is practice that listening skill, really understand the motivations of our teams, and then try to create these safe working environments where people feel comfortable sharing their perspectives. It’s not that you’re going to act on everything everyone’s talking about, but at least you get diverse perspectives and points of view to help create an inclusive work environment that makes everyone want to show up, support each other, and do the best work possible.
I have two. One is Learn and Be Curious because that is how I like to operate. I think, “what if…” or “why can’t we…”. Then Think Big pairs with “why can’t we…” The culture within AWS really supports that. On a daily basis, we can flip the script on how we think about our jobs and how we position the business.
If you’re entrepreneurial and like to create, this place is like a magic playground. Some people look at my job and they’re so confused with all the different things I get to do – but it goes back to that context switching. I believe that Learn and Be Curious and Think Big fit in that realm for me–I feel like I can be anything, I can do anything. I also had parents who told me as a kid that I could do anything and be anything, so I think that’s just who I am. Those two leadership principles help me to produce and do my best work.
What’s the thing you’re most proud of in your career?
That’s hard. It’s a couple of things. I’ve had a lot of incredible opportunities. One of which was being involved in a startup. We raised the money quickly, we worked with incredible customers, we solved really challenging business issues. The fact that I was able to bring that here to AWS, in a way that now hundreds of thousands of people get to see the kind of work we’re able to produce, is pretty cool.
But honestly, working with some of our new hires who are just getting into the workforce–especially with our diverse candidates–I’m at a place in my career where I want to create opportunities for others. I’m working to create safe spaces for people to operate and do their best work and really break down barriers for people who might not otherwise get those opportunities. That’s what I’m most excited about for the future, and also the most proud about–giving people opportunities to work in careers they never thought were available to them. I love that, and I get to do it daily.
If you had to pick any other job, what would you want to do?
Sports agent. I think I’d be so good at it. I would love to go work with young athletes, especially with the new NCAA ruling that college athletes can get paid for the use of their likeness. I would love to help them develop really interesting business plans.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
In the week leading up to AWS re:Invent 2021, we’ll share conversations we’ve had with people at AWS who will be presenting, and get a sneak peek at their work.
How long have you been at Amazon Web Services (AWS), and what do you do in your current role?
I’ve been at AWS nearly 4 years, and in IT security over 15 years. I’m a solutions architect with a specialty in security. I work with commercial customers in North America, helping them solve security problems and build out secure foundations for their AWS workloads.
How did you get started in security?
I took part in a Boeing internship for three summers starting my junior year of high school. This internship gave me the opportunity to work with mechanical engineers at Boeing. The specific team I worked with were engineers responsible for building digital tools and robots for the 767-400 line at the Everett plant in Washington state. The purpose of these custom tools and robots was to help build the planes more efficiently and accurately. I had a lot of fun and learned a lot from my time working with them. I asked the group for career advice during lunch one day, and they all pointed me towards computer science (CS) instead of mechanical engineering. Because of their strong support for CS, I took the first course, Intro to Computer Science, and was excited that something that I previously thought was intimidating was actually approachable and a subject I really enjoyed.
During my sophomore year there was a new elective class offered called Digital Security, which piqued my interest and influenced my senior project. I built (coded) an intrusion detection program that identified nefarious network traffic. I also worked on campus during college in the sound services department and participated in the Dance Ensemble Program, where I met the IT manager for a local hospital in Washington state, Good Samaritan Hospital in Puyallup. He was helping mix music at the studio I worked in. After showing him my senior project, he told me about a job opening for a network security specialist at the hospital. No one else had applied for the role. I then interviewed with the team, which was made up of only three engineers including the manager. They were responsible for the all-backend systems including the hospital information system, patient telemetry and clinic systems, the hospital network, etc. The group of people I worked with at the hospital is still very special to me, we are all still friends.
How do you explain your job to non-tech friends?
I’m in tech, and I help companies protect their websites and their customers’ data.
What are you currently working on that you’re excited about?
I’m very excited about re:Invent. It’s the 10th anniversary, we’re back in person, and I’ve got quite a few sessions I’m delivering.
Speaking of AWS re:Invent 2021 – can you give readers a sneak peek at what you’re covering?
The first is a session I’m delivering is called Use AWS to improve your security posture against ransomware (SEC308) with Merritt Baer, Principal in the Office of the CISO. We’re discussing what AWS services and features you can use to help you protect your systems from ransomware.
The second is a chalk talk, Automating and evidencing key compliance security controls (STP211-R1 and STP211-R2), I’m delivering with Kristin Haught, Principal Security TPM, and we’re discussing strategies for automating, monitoring, and evidencing common controls required for multiple compliance standards.
The third session is a builder session called Grant least privilege temporary access securely at scale (WPS304). We’ll use AWS Secrets Manager, AWS Identity and Access Management (IAM), and the isolated compute functionality provided by AWS Nitro Enclaves to allow system administrators to request and retrieve narrowly scoped and limited-time access.
The fourth session is another builder session called Detecting security threats with Amazon GuardDuty (SEC213-R1 and SEC213-R2). It includes several simulated scenarios, representing just a small sample of the threats that GuardDuty can detect. We will review how to view and analyze GuardDuty findings, how to send alerts based on the findings, and, finally, how to remediate findings.
From your perspective, what’s the most important thing to know about ransomware?
Whenever we see a security event continue to make news, it’s a call to action and an opportunity for customers to analyze their security programs including operations and controls. There’s no silver bullet when it comes to protection from ransomware, but it’s time to level up your security operations and controls. This means minimize human access, translate security policies into code, build mechanism and measure them, streamline the use of environment and infrastructure, and use advanced data/database service features.
For example, we still see customers with large amounts of long-lived credentials; it’s time to take inventory and minimize or eliminate them. While there is a small subset of use cases where they may be required, such as on-premises to AWS access, I recommend the following:
Inventory your long-lived credentials.
Ensure the access is least privilege, absolutely no wildcard actions and/or resources.
If the access is interactive, apply multi-factor authentication (MFA).
Ask if you can architect a better option that doesn’t rely on static access keys.
Learn and Be Curious! I am the most happy in my job and personal life when I’m learning new things. I also believe that this principle is a way of life for us technology folks. Learning new technology and finding better ways of implementing technology is our job. My favorite quote/laptop sticker is:
“I hate programming”
“I hate programming”
“I hate programming”
“IT WORKS! ”
“I love programming.”
It just makes me laugh because it’s so true. Of course we are only that frustrated when something is very new. It’s like solving a puzzle. When a project comes together, it’s absolutely worth it – the puzzle pieces now fit.
What’s the best career advice you’ve ever gotten?
Work with a mentor. This can be casual by finding projects where you can collaborate with folks who have more experience than you. Or it can be more formal by asking someone to be your mentor and setting up a regular cadence of meetings with them. I’ve done both, a simple example is by collaborating with Merritt and Kristen on upcoming re:Invent presentations, I’ve already learned a lot from both of them just through the preparation process and developing the content. Having a mentor by your side can be especially helpful when setting new goals. Sometimes we need someone to push us out of our comfort zone and believe that we can achieve bigger things than we would have thought and then can help devise a plan to help you achieve those goals. All it takes is someone else believing in us.
If you had to pick any other job, what would you want to do?
I’ve always been interested in naturopathic medicine and getting to the root cause of an issue. It’s somewhat similar to my job in that I’m solving puzzles and complex problems, but in technology, instead of the body.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
In the week leading up AWS re:Invent 2021, we’ll share conversations we’ve had with people at AWS who will be presenting, and get a sneak peek at their work.
How long have you been at Amazon Web Services (AWS), and what do you do in your current role?
I’m a Principal in the Office of the Chief Information Security Officer (OCISO), and I’ve been at AWS about four years. In the past, I’ve worked in all three branches of the U.S. Government, doing security on behalf of the American people.
My current role involves both internal- and external- facing security.
I love having C-level conversations around hard but simple questions about how to prioritize the team’s resources and attention. A lot of my conversations revolve around organizational change, and how to motivate the move to the cloud from a security perspective. Within that, there’s a technical “how”—we might talk about the move to an intelligent multi-account governance structure using AWS Organizations, or the use of appropriate security controls, including remediations like AWS Config Rules and Amazon EventBridge. We might also talk about the ability to do forensics, which in the cloud looks like logging and monitoring with AWS CloudTrail, Amazon CloudWatch, Amazon GuardDuty, and others aggregated in AWS Security Hub.
I also handle strategic initiatives for our security shop, from operational considerations like how we share threat intelligence internally, to the ways we can better streamline our policy and contract vehicles, to the ways that we can incorporate customer feedback into our products and services. The work I do for AWS’ security gives me the empathy and credibility to talk with our customers—after all, we’re a security organization, running on AWS.
What drew you to security?
(Sidebar: it’s a little bit of who I am— I mean, doesn’t everyone rely on polaroid photos? just kidding— kind of :))
I always wanted to matter.
I was in school post-9/11, and security was an imperative. Meanwhile, I was in Mark Zuckerberg’s undergrad class at Harvard. A lot of the technologies that feel so intimate and foundational—cloud, AI/ML, IoT, and the use of mobile apps, for example—were just gaining traction back then. I loved both emerging tech and security, and I was convinced that they needed to speak to and with one another. I wanted our approach to include considerations around how our systems impact vulnerable people and communities. I became an expert in child pornography law, which continues to be an important area of security definition.
I am someone who wonders what we’re all doing here, and I got into security because I wanted to help change the world. In the words of Poet Laureate Joy Harjo, “There is no world like the one surfacing.”
How do you explain your job to non-tech friends?
I often frame my work relative to what they do, or where we are when we’re chatting. Today, nearly everyone interacts with cloud infrastructure in our everyday lives. If I’m talking to a person who works in finance, I might point to AWS’ role providing IT infrastructure to the global financial system; if we’re walking through a pharmacy I might describe how research and development cycles have accelerated because of high-performance computing (HPC) on AWS.
What are you currently working on that you’re excited about?
Right now, I’m helping customer executives who’ve had a tumultuous (different, not necessarily all bad) couple of years. I help them adjust to a new reality in their employee behavior and access needs, like the move to fully remote work. I listen to their challenges in the ability to democratize security knowledge through their organizations, including embedding security in dev teams. And I help them restructure their consumption of AWS, which has been changing in light of the events of the last two years.
On a strategic level, I have a lot going on … here’s a good sampling: I’ve been championing new work based on customers asking our experts to be more proactive by “snapshotting” metadata about their resources and evaluating that metadata against our well-architected security framework. I work closely with our Trust and Safety team on new projects that both increase automation for high volume issues but also provide more “high touch” and prioritized responses to trusted reporters. I’m also building the business case for security service teams to make their capabilities even more broadly available by extended free tiers and timelines. I’m providing expertise to our private equity folks on a framework for evaluating the maturity of security capabilities of target acquisitions. Finally, I’ve helped lead our efforts to add tighter security controls when AWS teams provide prototyping and co-development work. I live in Miami, Florida, USA, and I also work on building out the local tech ecosystem here!
I’m also working on some of the ways we can address ransomware. During our interview process, Amazon requests that folks do an hour-long presentation on a topic of your choice. I did mine on ransomware in the cloud, and when I came on board I pointed to that area of need for security solutions. Now we have a ransomware working group I help lead, with efforts underway to help out customers doing both education and architectural guidance, as well as curated solutions with industries and partners, including healthcare.
You’re presenting at AWS re:Invent this year—can you give readers a sneak peek at what you’re covering?
One talk is on cloud-native approaches to ransomware defense, encouraging folks to think innovatively as they mature their IT infrastructure. And a second talk highlights partner solutions that can help meet customers where they are, and improve their anti-ransomware posture using vendors—from MSSPs and systems integrators, to endpoint security, DNS filtering, and custom backup solutions.
What are you hoping the audience will take away from the sessions?
These days, security doesn’t just take the form of security services (like GuardDuty and AWS WAF), but will also manifest in the ways you design a cloud-aware architecture. For example, our managed database service Aurora can be cloned; that clone might act as a canary when you see data drift (a canary is security concept for testing your expectations). You can use this to get back to a known good state.
Security is a bottom line proposition. What I mean by that is:
It’s a business criticality to avoid a bad day
Embracing mature security will enable your entity’s development innovation
The security of your products is a meaningful part of what you deliver on to your customers.
From your perspective, what’s the most important thing to know about ransomware?
Ransomware is a big headline-maker right now, but it’s not new. Most ransomware attacks are not based on zero days; they’re knowable but opportunistic. So, without victim-blaming, I mean to equip us with the confidence to confront the security issue. There’s no need to be ransomed.
I try not to get wrapped around particular issues, and instead emphasize building the foundation right. So sure, we can call it ransomware defense, but we can also point to these security maturity measures as best practices in general.
I think it’s fair to say that you’re passionate about women in tech and in security specifically. You recently presented at the Day of Shecurity conference and the Women in Business Summit, and did an Instagram takeover for Women in CyberSecurity (WiCyS). Why do you feel passionately about this?
I see security as an inherently creative field. As security professionals, we’re capable of freeing the business to get stuff done, and to get it done securely. That sounds simple, and it’s hard!
Any time you’re working in a creative field, you rely on human ingenuity and pragmatism to ensure you’re doing it imaginatively instead of simply accepting old realities. When we want to be creative, we need more of the stuff life is made of: human experience. We know that people who move through the world with different identities and experiences think differently. They approach problems differently. They code differently.
So, I think having women in security is important, both for the women who choose to work in security, and for the security field as a whole.
What advice would you give a woman just starting out in the security industry?
No one is born with a brain full of security knowledge. Technology is human-made and imperfect, and we all had to learn it at some point. Start somewhere. No one is going to tap you on the shoulder and invite you to your life 🙂
Operationally, I recommend:
Curate your “elevator pitch” about who you are and what you’re looking for, and be explicit when asking for folks for a career conversation or a referral (you can find me on Twitter @MerrittBaer, feel free to send a note).
Don’t accept a first job offer—ask for more.
Beware of false choices. For example, sometimes there’s a job that’s not in the description—consider writing your own value proposition and pitching it to the organization. This is a field that’s developing all the time, and you may be seeing a need they hadn’t yet solidified.
I think Bias for Action takes precedence for me— there’s a business decision here to move fast. We know that comes with some costs and risks, but we’ve made that calculated decision to pursue high velocity.
I have a law degree, and I see the Leadership Principles sort of like the Bill of Rights: they are frequently in tension and sometimes even at odds with one another (for example, Bias for Action and Are Right, A Lot might demand different modes). That is what makes them timeless—yet even more contingent on our interpretation—as we derive value from them. As a security person, I want us to pursue the good, and also to transcend the particular fears of the day.
If you had to pick any other industry, what would you want to do?
Probably public health. I think if I wasn’t doing security, I would want to do something else landscape-level.
Even before I had a daughter, but certainly now that I have a one-year-old, I would calculate the ROI of my life’s existence and my investment in my working life.
That being said, there are days I just need to come home to some unconditional love from my rescue pug, Peanut Butter.
If you have feedback about this post, submit comments in the Comments section below.
Want more AWS Security news? Follow us on Twitter.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.