Post Syndicated from Richard Boulton original https://blog.cloudflare.com/20-percent-internet-upgrade/
Cloudflare is relentless about building and running the world’s fastest network. We have been tracking and reporting on our network performance since 2021: you can see the latest update here.
Building the fastest network requires work in many areas. We invest a lot of time in our hardware, to have efficient and fast machines. We invest in peering arrangements, to make sure we can talk to every part of the Internet with minimal delay. On top of this, we also have to invest in the software we run our network on, especially as each new product can otherwise add more processing delay.
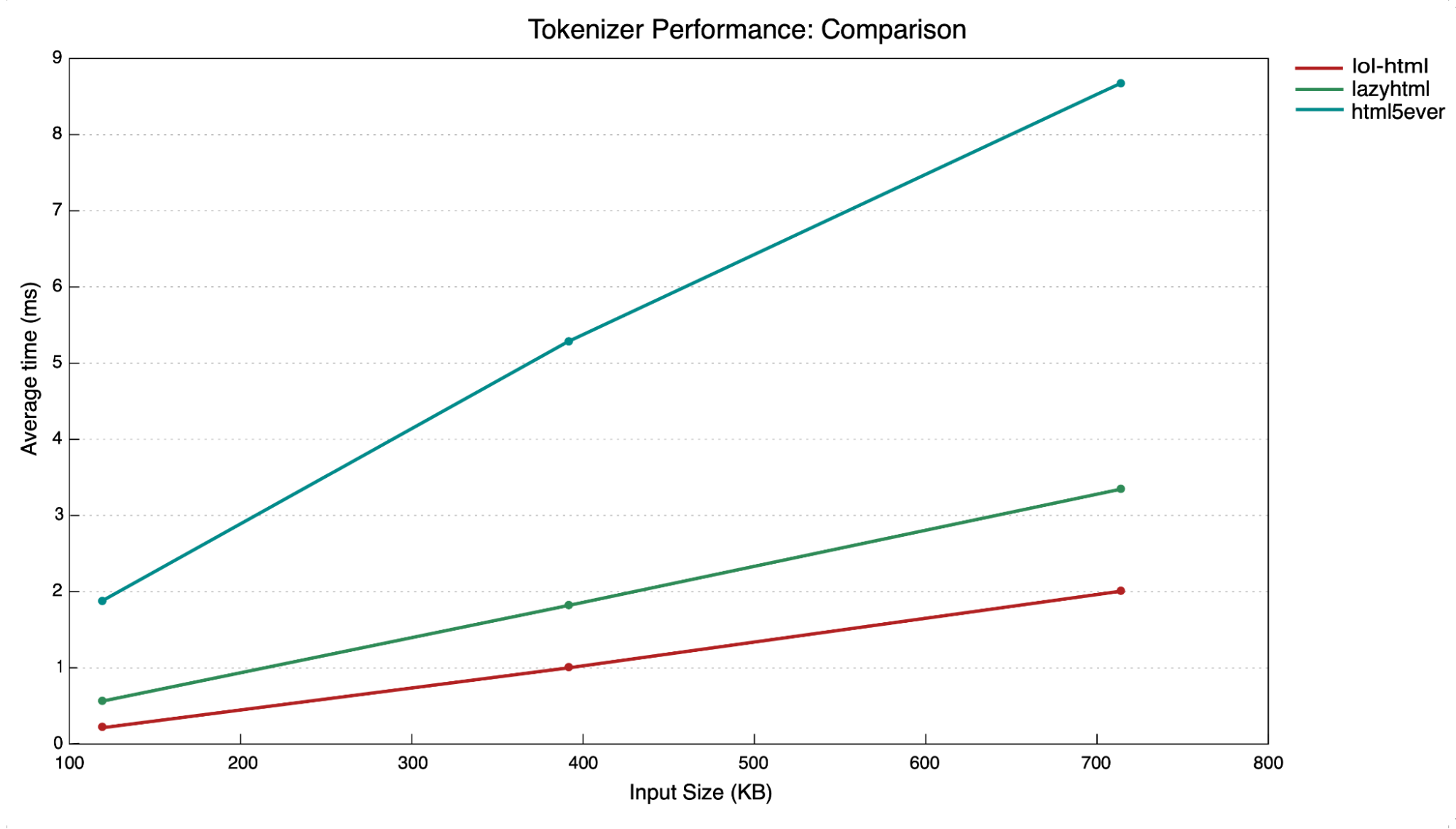
No matter how fast messages arrive, we introduce a bottleneck if that software takes too long to think about how to process and respond to requests. Today we are excited to share a significant upgrade to our software that cuts the median time we take to respond by 10ms and delivers a 25% performance boost, as measured by third-party CDN performance tests.
We’ve spent the last year rebuilding major components of our system, and we’ve just slashed the latency of traffic passing through our network for millions of our customers. At the same time, we’ve made our system more secure, and we’ve reduced the time it takes for us to build and release new products.
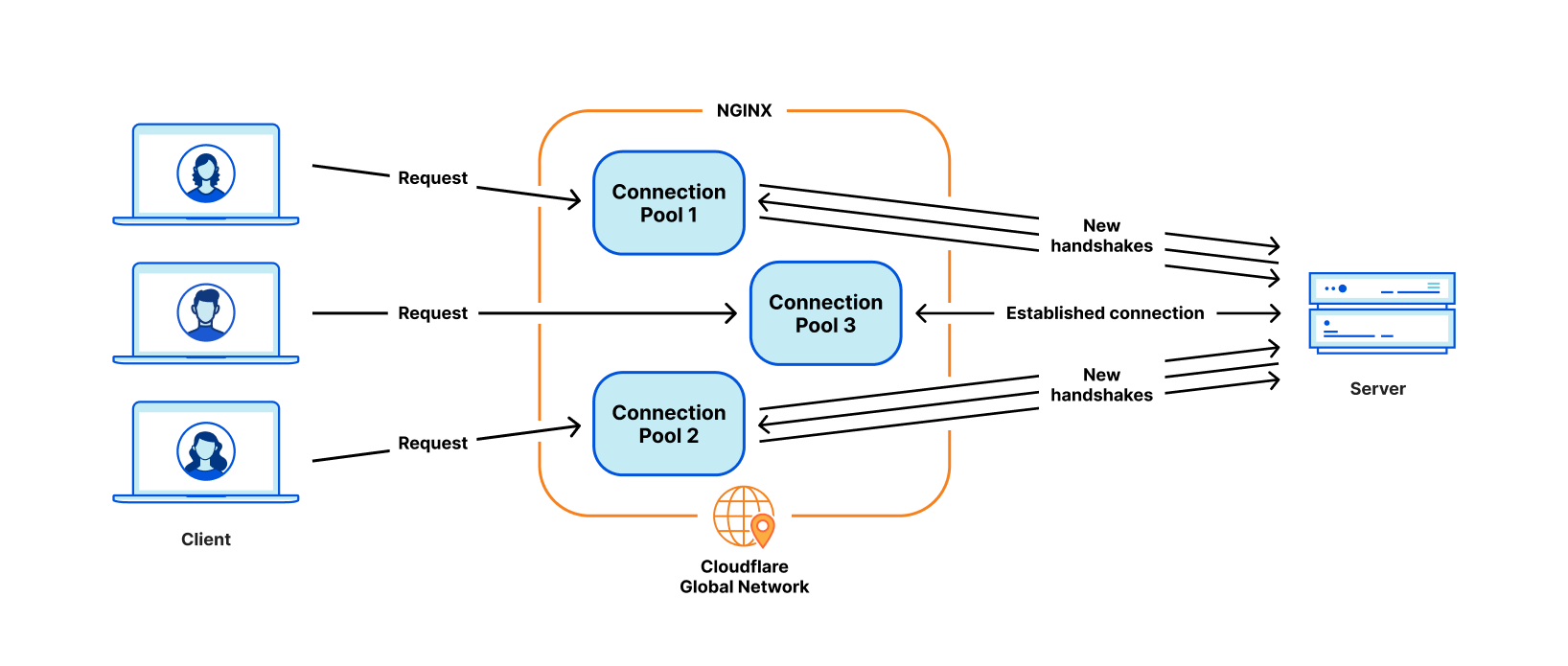
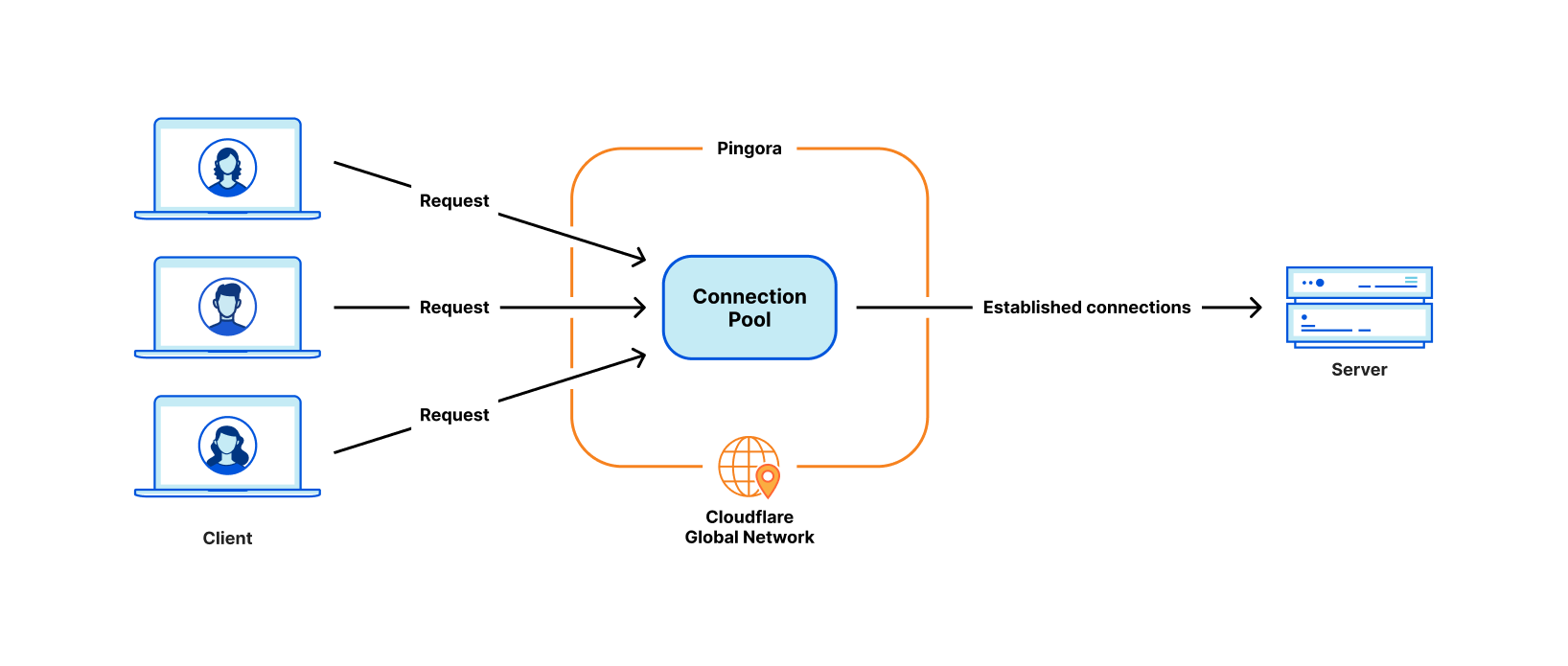
Every request that hits Cloudflare starts a journey through our network. It might come from a browser loading a webpage, a mobile app calling an API, or automated traffic from another service. These requests first terminate at our HTTP and TLS layer, then pass into a system we call FL, and finally through Pingora, which performs cache lookups or fetches data from the origin if needed.

FL is the brain of Cloudflare. Once a request reaches FL, we then run the various security and performance features in our network. It applies each customer’s unique configuration and settings, from enforcing WAF rules and DDoS protection to routing traffic to the Developer Platform and R2.
Built more than 15 years ago, FL has been at the core of Cloudflare’s network. It enables us to deliver a broad range of features, but over time that flexibility became a challenge. As we added more products, FL grew harder to maintain, slower to process requests, and more difficult to extend. Each new feature required careful checks across existing logic, and every addition introduced a little more latency, making it increasingly difficult to sustain the performance we wanted.
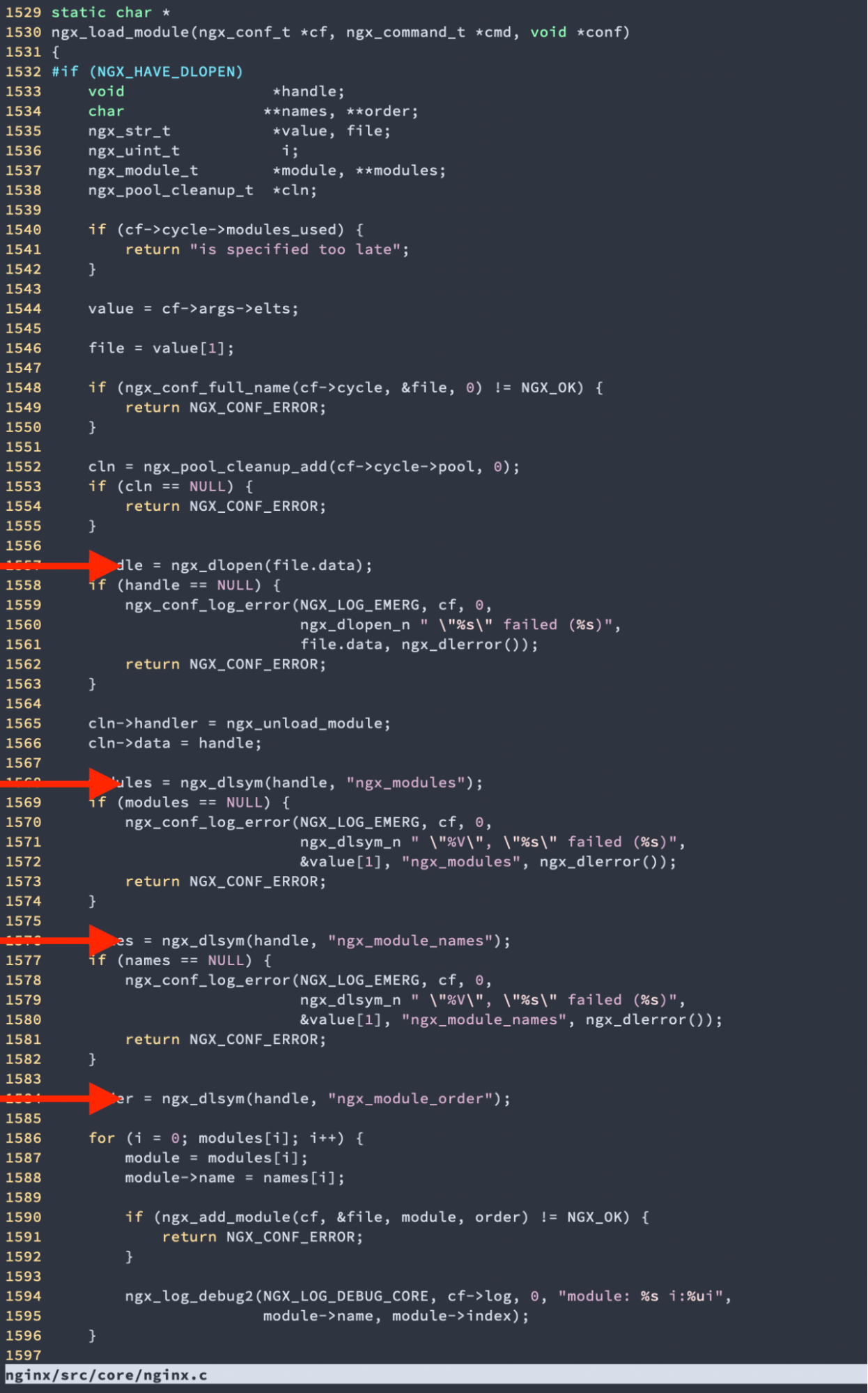
You can see how FL is key to our system — we’ve often called it the “brain” of Cloudflare. It’s also one of the oldest parts of our system: the first commit to the codebase was made by one of our founders, Lee Holloway, well before our initial launch. We’re celebrating our 15th Birthday this week – this system started 9 months before that!
commit 39c72e5edc1f05ae4c04929eda4e4d125f86c5ce
Author: Lee Holloway <q@t60.(none)>
Date: Wed Jan 6 09:57:55 2010 -0800
nginx-fl initial configurationAs the commit implies, the first version of FL was implemented based on the NGINX webserver, with product logic implemented in PHP. After 3 years, the system became too complex to manage effectively, and too slow to respond, and an almost complete rewrite of the running system was performed. This led to another significant commit, this time made by Dane Knecht, who is now our CTO.
commit bedf6e7080391683e46ab698aacdfa9b3126a75f
Author: Dane Knecht
Date: Thu Sep 19 19:31:15 2013 -0700
remove PHP.From this point on, FL was implemented using NGINX, the OpenResty framework, and LuaJIT. While this was great for a long time, over the last few years it started to show its age. We had to spend increasing amounts of time fixing or working around obscure bugs in LuaJIT. The highly dynamic and unstructured nature of our Lua code, which was a blessing when first trying to implement logic quickly, became a source of errors and delay when trying to integrate large amounts of complex product logic. Each time a new product was introduced, we had to go through all the other existing products to check if they might be affected by the new logic.
It was clear that we needed a rethink. So, in July 2024, we cut an initial commit for a brand new, and radically different, implementation. To save time agreeing on a new name for this, we just called it “FL2”, and started, of course, referring to the original FL as “FL1”.
commit a72698fc7404a353a09a3b20ab92797ab4744ea8
Author: Maciej Lechowski
Date: Wed Jul 10 15:19:28 2024 +0100
Create fl2 projectWe weren’t starting from scratch. We’ve previously blogged about how we replaced another one of our legacy systems with Pingora, which is built in the Rust programming language, using the Tokio runtime. We’ve also blogged about Oxy, our internal framework for building proxies in Rust. We write a lot of Rust, and we’ve gotten pretty good at it.
We built FL2 in Rust, on Oxy, and built a strict module framework to structure all the logic in FL2.
When we set out to build FL2, we knew we weren’t just replacing an old system; we were rebuilding the foundations of Cloudflare. That meant we needed more than just a proxy; we needed a framework that could evolve with us, handle the immense scale of our network, and let teams move quickly without sacrificing safety or performance.
Oxy gives us a powerful combination of performance, safety, and flexibility. Built in Rust, it eliminates entire classes of bugs that plagued our Nginx/LuaJIT-based FL1, like memory safety issues and data races, while delivering C-level performance. At Cloudflare’s scale, those guarantees aren’t nice-to-haves, they’re essential. Every microsecond saved per request translates into tangible improvements in user experience, and every crash or edge case avoided keeps the Internet running smoothly. Rust’s strict compile-time guarantees also pair perfectly with FL2’s modular architecture, where we enforce clear contracts between product modules and their inputs and outputs.
But the choice wasn’t just about language. Oxy is the culmination of years of experience building high-performance proxies. It already powers several major Cloudflare services, from our Zero Trust Gateway to Apple’s iCloud Private Relay, so we knew it could handle the diverse traffic patterns and protocol combinations that FL2 would see. Its extensibility model lets us intercept, analyze, and manipulate traffic from layer 3 up to layer 7, and even decapsulate and reprocess traffic at different layers. That flexibility is key to FL2’s design because it means we can treat everything from HTTP to raw IP traffic consistently and evolve the platform to support new protocols and features without rewriting fundamental pieces.
Oxy also comes with a rich set of built-in capabilities that previously required large amounts of bespoke code. Things like monitoring, soft reloads, dynamic configuration loading and swapping are all part of the framework. That lets product teams focus on the unique business logic of their module rather than reinventing the plumbing every time. This solid foundation means we can make changes with confidence, ship them quickly, and trust they’ll behave as expected once deployed.
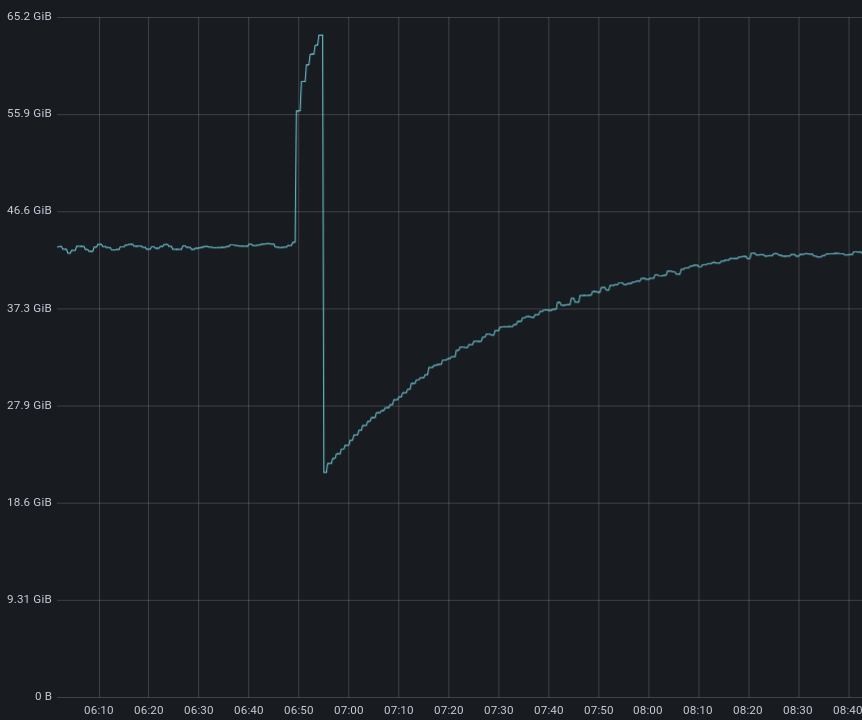
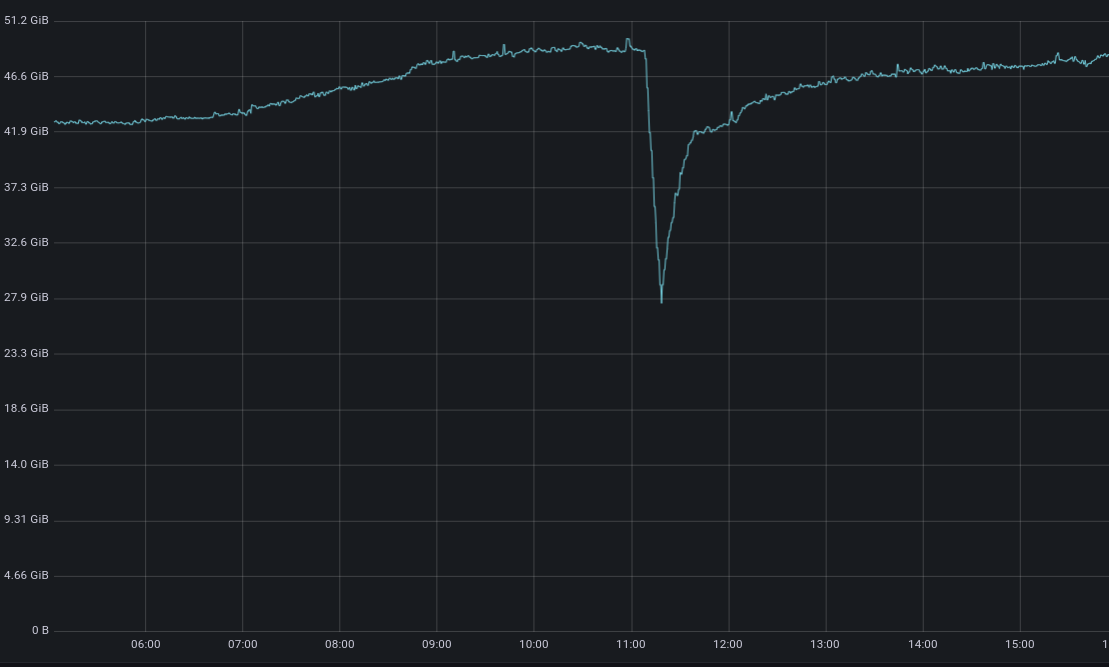
One of the most impactful improvements Oxy brings is handling of restarts. Any software under continuous development and improvement will eventually need to be updated. In desktop software, this is easy: you close the program, install the update, and reopen it. On the web, things are much harder. Our software is in constant use and cannot simply stop. A dropped HTTP request can cause a page to fail to load, and a broken connection can kick you out of a video call. Reliability is not optional.
In FL1, upgrades meant restarts of the proxy process. Restarting a proxy meant terminating the process entirely, which immediately broke any active connections. That was particularly painful for long-lived connections such as WebSockets, streaming sessions, and real-time APIs. Even planned upgrades could cause user-visible interruptions, and unplanned restarts during incidents could be even worse.
Oxy changes that. It includes a built-in mechanism for graceful restarts that lets us roll out new versions without dropping connections whenever possible. When a new instance of an Oxy-based service starts up, the old one stops accepting new connections but continues to serve existing ones, allowing those sessions to continue uninterrupted until they end naturally.
This means that if you have an ongoing WebSocket session when we deploy a new version, that session can continue uninterrupted until it ends naturally, rather than being torn down by the restart. Across Cloudflare’s fleet, deployments are orchestrated over several hours, so the aggregate rollout is smooth and nearly invisible to end users.
We take this a step further by using systemd socket activation. Instead of letting each proxy manage its own sockets, we let systemd create and own them. This decouples the lifetime of sockets from the lifetime of the Oxy application itself. If an Oxy process restarts or crashes, the sockets remain open and ready to accept new connections, which will be served as soon as the new process is running. That eliminates the “connection refused” errors that could happen during restarts in FL1 and improves overall availability during upgrades.
We also built our own coordination mechanisms in Rust to replace Go libraries like tableflip with shellflip. This uses a restart coordination socket that validates configuration, spawns new instances, and ensures the new version is healthy before the old one shuts down. This improves feedback loops and lets our automation tools detect and react to failures immediately, rather than relying on blind signal-based restarts.
To avoid the problems we had in FL1, we wanted a design where all interactions between product logic were explicit and easy to understand.
So, on top of the foundations provided by Oxy, we built a platform which separates all the logic built for our products into well-defined modules. After some experimentation and research, we designed a module system which enforces some strict rules:
-
No IO (input or output) can be performed by the module.
-
The module provides a list of phases.
-
Phases are evaluated in a strictly defined order, which is the same for every request.
-
Each phase defines a set of inputs which the platform provides to it, and a set of outputs which it may emit.
Here’s an example of what a module phase definition looks like:
Phase {
name: phases::SERVE_ERROR_PAGE,
request_types_enabled: PHASE_ENABLED_FOR_REQUEST_TYPE,
inputs: vec![
InputKind::IPInfo,
InputKind::ModuleValue(
MODULE_VALUE_CUSTOM_ERRORS_FETCH_WORKER_RESPONSE.as_str(),
),
InputKind::ModuleValue(MODULE_VALUE_ORIGINAL_SERVE_RESPONSE.as_str()),
InputKind::ModuleValue(MODULE_VALUE_RULESETS_CUSTOM_ERRORS_OUTPUT.as_str()),
InputKind::ModuleValue(MODULE_VALUE_RULESETS_UPSTREAM_ERROR_DETAILS.as_str()),
InputKind::RayId,
InputKind::StatusCode,
InputKind::Visitor,
],
outputs: vec![OutputValue::ServeResponse],
filters: vec![],
func: phase_serve_error_page::callback,
}This phase is for our custom error page product. It takes a few things as input — information about the IP of the visitor, some header and other HTTP information, and some “module values.” Module values allow one module to pass information to another, and they’re key to making the strict properties of the module system workable. For example, this module needs some information that is produced by the output of our rulesets-based custom errors product (the “MODULE_VALUE_RULESETS_CUSTOM_ERRORS_OUTPUT” input). These input and output definitions are enforced at compile time.
While these rules are strict, we’ve found that we can implement all our product logic within this framework. The benefit of doing so is that we can immediately tell which other products might affect each other.
Building a framework is one thing. Building all the product logic and getting it right, so that customers don’t notice anything other than a performance improvement, is another.
The FL code base supports 15 years of Cloudflare products, and it’s changing all the time. We couldn’t stop development. So, one of our first tasks was to find ways to make the migration easier and safer.
It’s a big enough distraction from shipping products to customers to rebuild product logic in Rust. Asking all our teams to maintain two versions of their product logic, and reimplement every change a second time until we finished our migration was too much.
So, we implemented a layer in our old NGINX and OpenResty based FL which allowed the new modules to be run. Instead of maintaining a parallel implementation, teams could implement their logic in Rust, and replace their old Lua logic with that, without waiting for the full replacement of the old system.
For example, here’s part of the implementation for the custom error page module phase defined earlier (we’ve cut out some of the more boring details, so this doesn’t quite compile as-written):
pub(crate) fn callback(_services: &mut Services, input: &Input<'_>) -> Output {
// Rulesets produced a response to serve - this can either come from a special
// Cloudflare worker for serving custom errors, or be directly embedded in the rule.
if let Some(rulesets_params) = input
.get_module_value(MODULE_VALUE_RULESETS_CUSTOM_ERRORS_OUTPUT)
.cloned()
{
// Select either the result from the special worker, or the parameters embedded
// in the rule.
let body = input
.get_module_value(MODULE_VALUE_CUSTOM_ERRORS_FETCH_WORKER_RESPONSE)
.and_then(|response| {
handle_custom_errors_fetch_response("rulesets", response.to_owned())
})
.or(rulesets_params.body);
// If we were able to load a body, serve it, otherwise let the next bit of logic
// handle the response
if let Some(body) = body {
let final_body = replace_custom_error_tokens(input, &body);
// Increment a metric recording number of custom error pages served
custom_pages::pages_served("rulesets").inc();
// Return a phase output with one final action, causing an HTTP response to be served.
return Output::from(TerminalAction::ServeResponse(ResponseAction::OriginError {
rulesets_params.status,
source: "rulesets http_custom_errors",
headers: rulesets_params.headers,
body: Some(Bytes::from(final_body)),
}));
}
}
}The internal logic in each module is quite cleanly separated from the handling of data, with very clear and explicit error handling encouraged by the design of the Rust language.
Many of our most actively developed modules were handled this way, allowing the teams to maintain their change velocity during our migration.

It’s essential to have a seriously powerful test framework to cover such a migration. We built a system, internally named Flamingo, which allows us to run thousands of full end-to-end test requests concurrently against our production and pre-production systems. The same tests run against FL1 and FL2, giving us confidence that we’re not changing behaviours.
Whenever we deploy a change, that change is rolled out gradually across many stages, with increasing amounts of traffic. Each stage is automatically evaluated, and only passes when the full set of tests have been successfully run against it – as well as overall performance and resource usage metrics being within acceptable bounds. This system is fully automated, and pauses or rolls back changes if the tests fail.
The benefit is that we’re able to build and ship new product features in FL2 within 48 hours – where it would have taken weeks in FL1. In fact, at least one of the announcements this week involved such a change!
Over 100 engineers have worked on FL2, and we have over 130 modules. And we’re not quite done yet. We’re still putting the final touches on the system, to make sure it replicates all the behaviours of FL1.
So how do we send traffic to FL2 without it being able to handle everything? If FL2 receives a request, or a piece of configuration for a request, that it doesn’t know how to handle, it gives up and does what we’ve called a fallback – it passes the whole thing over to FL1. It does this at the network level – it just passes the bytes on to FL1.
As well as making it possible for us to send traffic to FL2 without it being fully complete, this has another massive benefit. When we have implemented a piece of new functionality in FL2, but want to double check that it is working the same as in FL1, we can evaluate the functionality in FL2, and then trigger a fallback. We are able to compare the behaviour of the two systems, allowing us to get a high confidence that our implementation was correct.
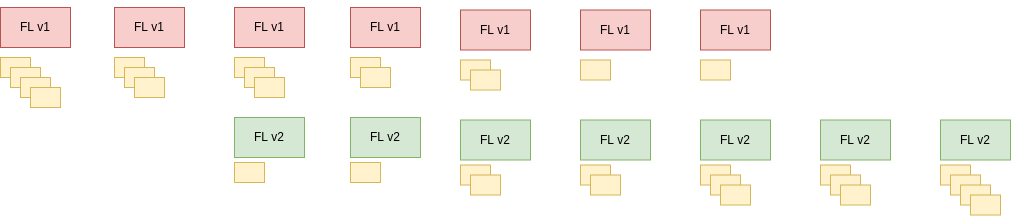
We started running customer traffic through FL2 early in 2025, and have been progressively increasing the amount of traffic served throughout the year. Essentially, we’ve been watching two graphs: one with the proportion of traffic routed to FL2 going up, and another with the proportion of traffic failing to be served by FL2 and falling back to FL1 going down.
We started this process by passing traffic for our free customers through the system. We were able to prove that the system worked correctly, and drive the fallback rates down for our major modules. Our Cloudflare Community MVPs acted as an early warning system, smoke testing and flagging when they suspected the new platform might be the cause of a new reported problem. Crucially their support allowed our team to investigate quickly, apply targeted fixes, or confirm the move to FL2 was not to blame.
We then advanced to our paying customers, gradually increasing the amount of customers using the system. We also worked closely with some of our largest customers, who wanted the performance benefits of FL2, and onboarded them early in exchange for lots of feedback on the system.
Right now, most of our customers are using FL2. We still have a few features to complete, and are not quite ready to onboard everyone, but our target is to turn off FL1 within a few more months.
As we described at the start of this post, FL2 is substantially faster than FL1. The biggest reason for this is simply that FL2 performs less work. You might have noticed in the module definition example a line
filters: vec![],Every module is able to provide a set of filters, which control whether they run or not. This means that we don’t run logic for every product for every request — we can very easily select just the required set of modules. The incremental cost for each new product we develop has gone away.
Another huge reason for better performance is that FL2 is a single codebase, implemented in a performance focussed language. In comparison, FL1 was based on NGINX (which is written in C), combined with LuaJIT (Lua, and C interface layers), and also contained plenty of Rust modules. In FL1, we spent a lot of time and memory converting data from the representation needed by one language, to the representation needed by another.
As a result, our internal measures show that FL2 uses less than half the CPU of FL1, and much less than half the memory. That’s a huge bonus — we can spend the CPU on delivering more and more features for our customers!
Using our own tools and independent benchmarks like CDNPerf, we measured the impact of FL2 as we rolled it out across the network. The results are clear: websites are responding 10 ms faster at the median, a 25% performance boost.

FL2 is also more secure by design than FL1. No software system is perfect, but the Rust language brings us huge benefits over LuaJIT. Rust has strong compile-time memory checks and a type system that avoids large classes of errors. Combine that with our rigid module system, and we can make most changes with high confidence.
Of course, no system is secure if used badly. It’s easy to write code in Rust, which causes memory corruption. To reduce risk, we maintain strong compile time linting and checking, together with strict coding standards, testing and review processes.
We have long followed a policy that any unexplained crash of our systems needs to be investigated as a high priority. We won’t be relaxing that policy, though the main cause of novel crashes in FL2 so far has been due to hardware failure. The massively reduced rates of such crashes will give us time to do a good job of such investigations.
We’re spending the rest of 2025 completing the migration from FL1 to FL2, and will turn off FL1 in early 2026. We’re already seeing the benefits in terms of customer performance and speed of development, and we’re looking forward to giving these to all our customers.
We have one last service to completely migrate. The “HTTP & TLS Termination” box from the diagram way back at the top is also an NGINX service, and we’re midway through a rewrite in Rust. We’re making good progress on this migration, and expect to complete it early next year.
After that, when everything is modular, in Rust and tested and scaled, we can really start to optimize! We’ll reorganize and simplify how the modules connect to each other, expand support for non-HTTP traffic like RPC and streams, and much more.
If you’re interested in being part of this journey, check out our careers page for open roles – we’re always looking for new talent to help us to help build a better Internet.