Post Syndicated from Yuchen Wu original https://blog.cloudflare.com/pingora-open-source

Today, we are proud to open source Pingora, the Rust framework we have been using to build services that power a significant portion of the traffic on Cloudflare. Pingora is released under the Apache License version 2.0.
As mentioned in our previous blog post, Pingora is a Rust async multithreaded framework that assists us in constructing HTTP proxy services. Since our last blog post, Pingora has handled nearly a quadrillion Internet requests across our global network.
We are open sourcing Pingora to help build a better and more secure Internet beyond our own infrastructure. We want to provide tools, ideas, and inspiration to our customers, users, and others to build their own Internet infrastructure using a memory safe framework. Having such a framework is especially crucial given the increasing awareness of the importance of memory safety across the industry and the US government. Under this common goal, we are collaborating with the Internet Security Research Group (ISRG) Prossimo project to help advance the adoption of Pingora in the Internet’s most critical infrastructure.
In our previous blog post, we discussed why and how we built Pingora. In this one, we will talk about why and how you might use Pingora.
Pingora provides building blocks for not only proxies but also clients and servers. Along with these components, we also provide a few utility libraries that implement common logic such as event counting, error handling, and caching.
What’s in the box
Pingora provides libraries and APIs to build services on top of HTTP/1 and HTTP/2, TLS, or just TCP/UDP. As a proxy, it supports HTTP/1 and HTTP/2 end-to-end, gRPC, and websocket proxying. (HTTP/3 support is on the roadmap.) It also comes with customizable load balancing and failover strategies. For compliance and security, it supports both the commonly used OpenSSL and BoringSSL libraries, which come with FIPS compliance and post-quantum crypto.
Besides providing these features, Pingora provides filters and callbacks to allow its users to fully customize how the service should process, transform and forward the requests. These APIs will be especially familiar to OpenResty and NGINX users, as many map intuitively onto OpenResty’s “*_by_lua” callbacks.
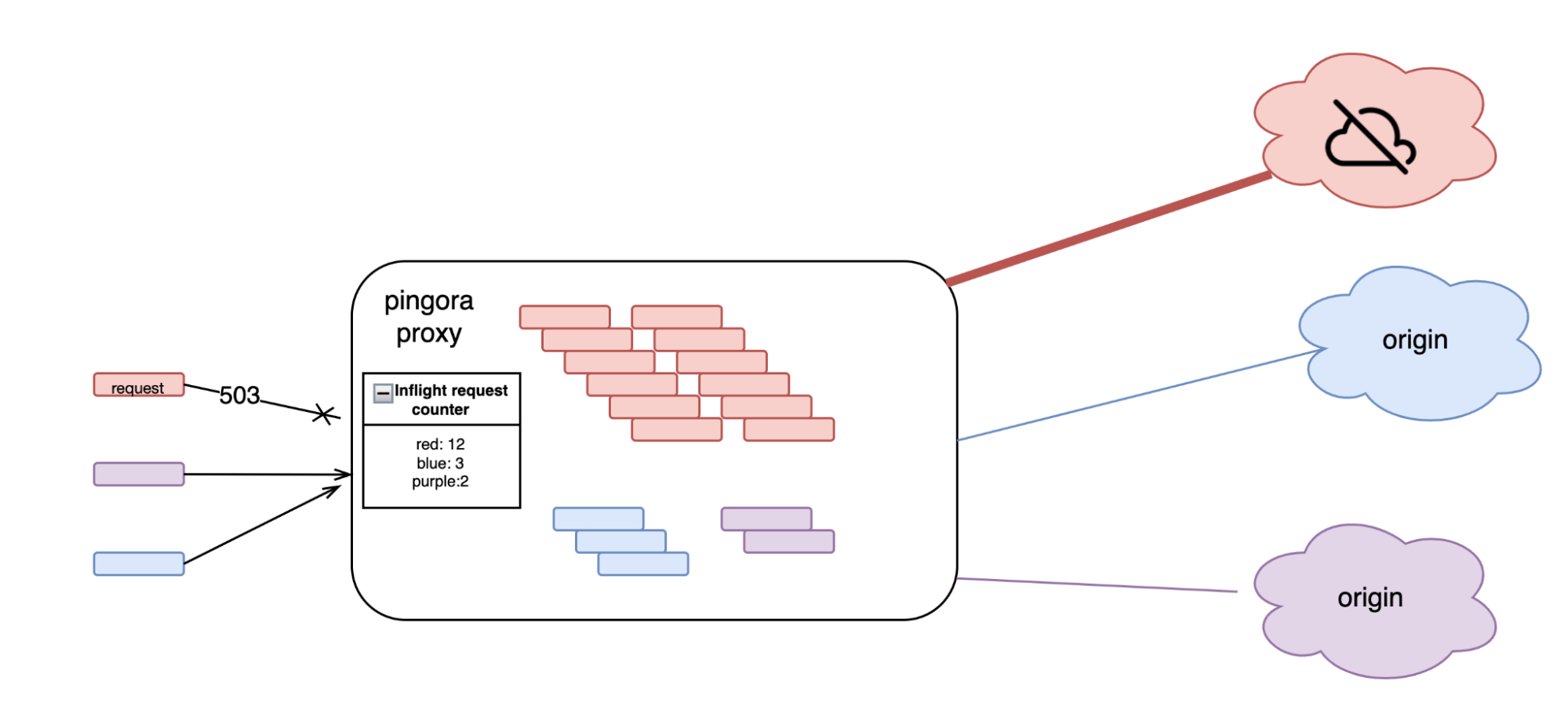
Operationally, Pingora provides zero downtime graceful restarts to upgrade itself without dropping a single incoming request. Syslog, Prometheus, Sentry, OpenTelemetry and other must-have observability tools are also easily integrated with Pingora as well.
Who can benefit from Pingora
You should consider Pingora if:
Security is your top priority: Pingora is a more memory safe alternative for services that are written in C/C++. While some might argue about memory safety among programming languages, from our practical experience, we find ourselves way less likely to make coding mistakes that lead to memory safety issues. Besides, as we spend less time struggling with these issues, we are more productive implementing new features.
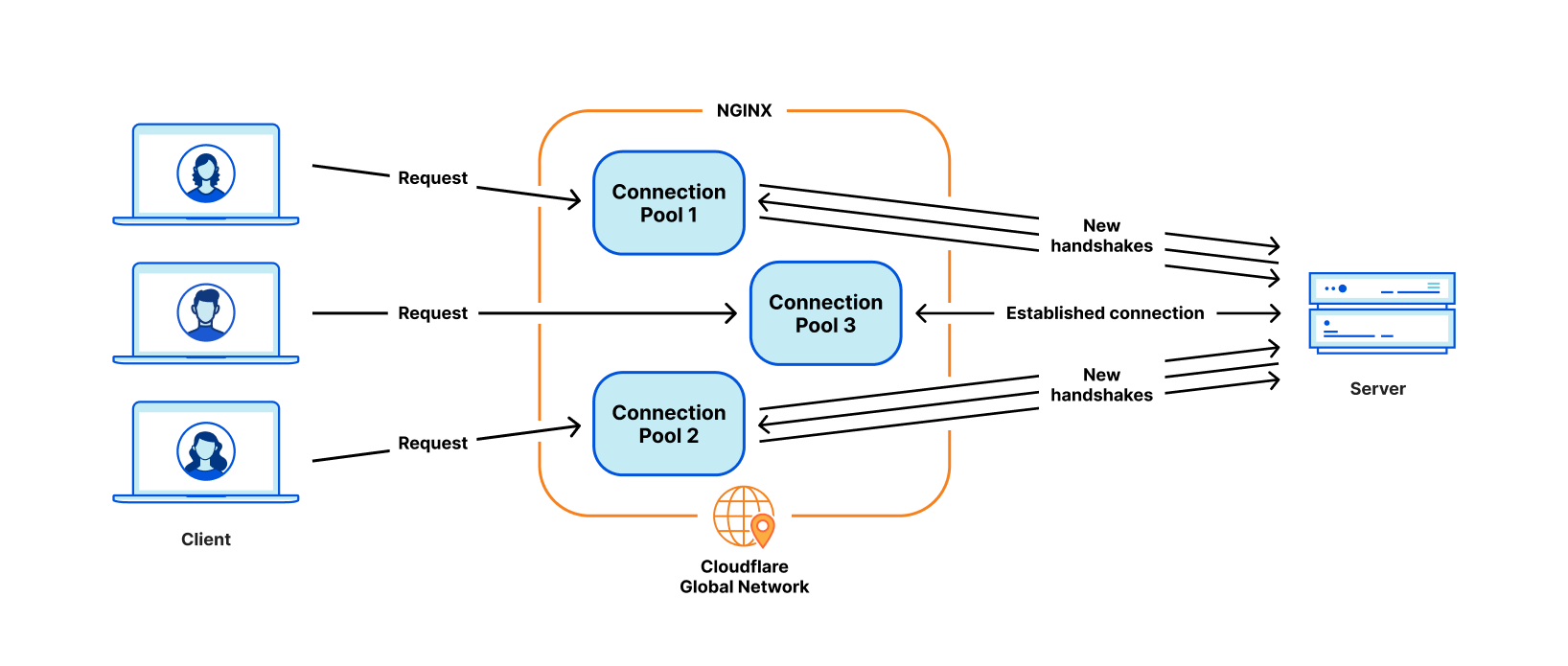
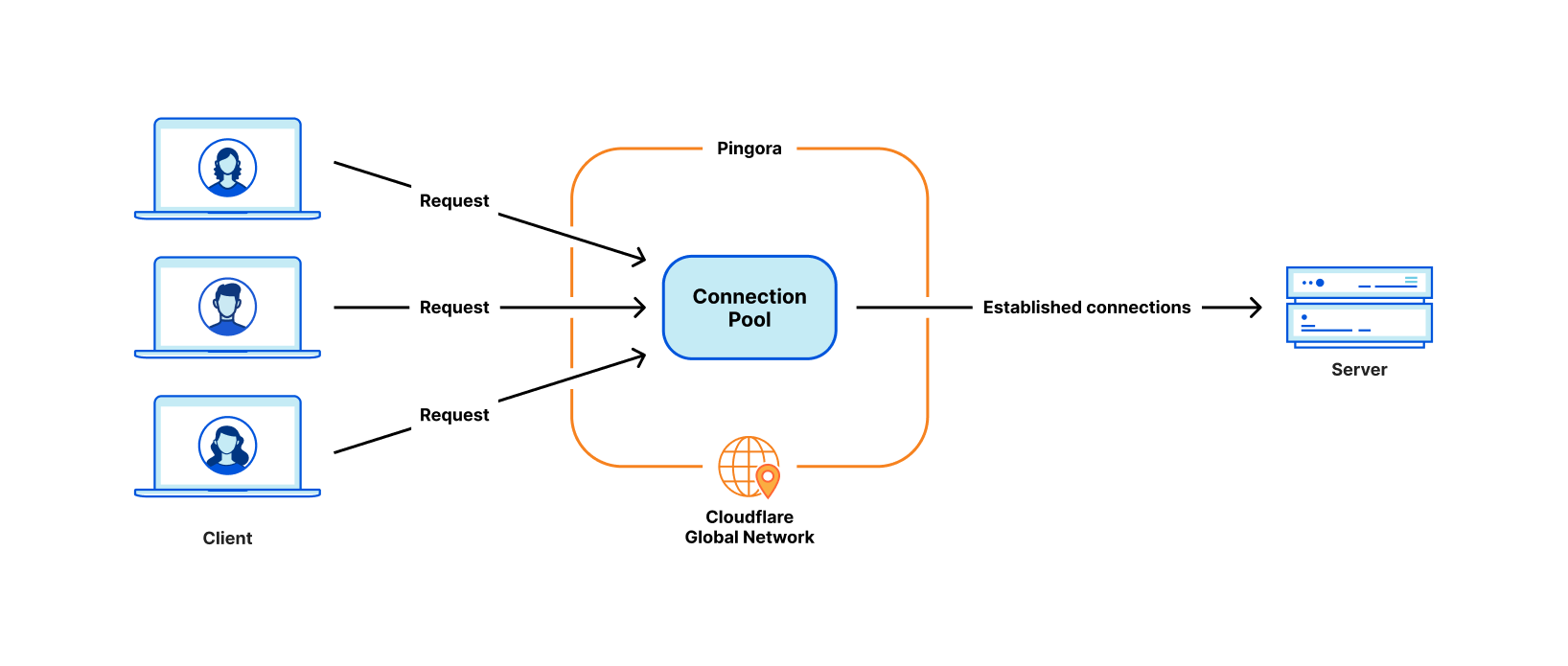
Your service is performance-sensitive: Pingora is fast and efficient. As explained in our previous blog post, we saved a lot of CPU and memory resources thanks to Pingora’s multi-threaded architecture. The saving in time and resources could be compelling for workloads that are sensitive to the cost and/or the speed of the system.
Your service requires extensive customization: The APIs that the Pingora proxy framework provides are highly programmable. For users who wish to build a customized and advanced gateway or load balancer, Pingora provides powerful yet simple ways to implement it. We provide examples in the next section.
Let’s build a load balancer
Let’s explore Pingora’s programmable API by building a simple load balancer. The load balancer will select between https://1.1.1.1/ and https://1.0.0.1/ to be the upstream in a round-robin fashion.
First let’s create a blank HTTP proxy.
pub struct LB();
#[async_trait]
impl ProxyHttp for LB {
async fn upstream_peer(...) -> Result<Box<HttpPeer>> {
todo!()
}
}
Any object that implements the ProxyHttp trait (similar to the concept of an interface in C++ or Java) is an HTTP proxy. The only required method there is upstream_peer(), which is called for every request. This function should return an HttpPeer which contains the origin IP to connect to and how to connect to it.
Next let’s implement the round-robin selection. The Pingora framework already provides the LoadBalancer with common selection algorithms such as round robin and hashing, so let’s just use it. If the use case requires more sophisticated or customized server selection logic, users can simply implement it themselves in this function.
pub struct LB(Arc<LoadBalancer<RoundRobin>>);
#[async_trait]
impl ProxyHttp for LB {
async fn upstream_peer(...) -> Result<Box<HttpPeer>> {
let upstream = self.0
.select(b"", 256) // hash doesn't matter for round robin
.unwrap();
// Set SNI to one.one.one.one
let peer = Box::new(HttpPeer::new(upstream, true, "one.one.one.one".to_string()));
Ok(peer)
}
}
Since we are connecting to an HTTPS server, the SNI also needs to be set. Certificates, timeouts, and other connection options can also be set here in the HttpPeer object if needed.
Finally, let’s put the service in action. In this example we hardcode the origin server IPs. In real life workloads, the origin server IPs can also be discovered dynamically when the upstream_peer() is called or in the background. After the service is created, we just tell the LB service to listen to 127.0.0.1:6188. In the end we created a Pingora server, and the server will be the process which runs the load balancing service.
fn main() {
let mut upstreams = LoadBalancer::try_from_iter(["1.1.1.1:443", "1.0.0.1:443"]).unwrap();
let mut lb = pingora_proxy::http_proxy_service(&my_server.configuration, LB(upstreams));
lb.add_tcp("127.0.0.1:6188");
let mut my_server = Server::new(None).unwrap();
my_server.add_service(lb);
my_server.run_forever();
}
Let’s try it out:
curl 127.0.0.1:6188 -svo /dev/null
> GET / HTTP/1.1
> Host: 127.0.0.1:6188
> User-Agent: curl/7.88.1
> Accept: */*
>
< HTTP/1.1 403 Forbidden
We can see that the proxy is working, but the origin server rejects us with a 403. This is because our service simply proxies the Host header, 127.0.0.1:6188, set by curl, which upsets the origin server. How do we make the proxy correct that? This can simply be done by adding another filter called upstream_request_filter. This filter runs on every request after the origin server is connected and before any HTTP request is sent. We can add, remove or change http request headers in this filter.
async fn upstream_request_filter(…, upstream_request: &mut RequestHeader, …) -> Result<()> {
upstream_request.insert_header("Host", "one.one.one.one")
}
Let’s try again:
curl 127.0.0.1:6188 -svo /dev/null
< HTTP/1.1 200 OKThis time it works! The complete example can be found here.
Below is a very simple diagram of how this request flows through the callback and filter we used in this example. The Pingora proxy framework currently provides more filters and callbacks at different stages of a request to allow users to modify, reject, route and/or log the request (and response).
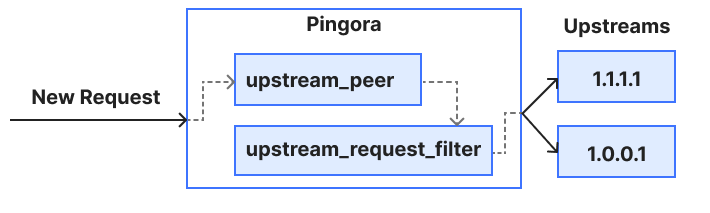
Behind the scenes, the Pingora proxy framework takes care of connection pooling, TLS handshakes, reading, writing, parsing requests and any other common proxy tasks so that users can focus on logic that matters to them.
Open source, present and future
Pingora is a library and toolset, not an executable binary. In other words, Pingora is the engine that powers a car, not the car itself. Although Pingora is production-ready for industry use, we understand a lot of folks want a batteries-included, ready-to-go web service with low or no-code config options. Building that application on top of Pingora will be the focus of our collaboration with the ISRG to expand Pingora’s reach. Stay tuned for future announcements on that project.
Other caveats to keep in mind:
- Today, API stability is not guaranteed. Although we will try to minimize how often we make breaking changes, we still reserve the right to add, remove, or change components such as request and response filters as the library evolves, especially during this pre-1.0 period.
- Support for non-Unix based operating systems is not currently on the roadmap. We have no immediate plans to support these systems, though this could change in the future.
How to contribute
Feel free to raise bug reports, documentation issues, or feature requests in our GitHub issue tracker. Before opening a pull request, we strongly suggest you take a look at our contribution guide.
Conclusion
In this blog we announced the open source of our Pingora framework. We showed that Internet entities and infrastructure can benefit from Pingora’s security, performance and customizability. We also demonstrated how easy it is to use Pingora and how customizable it is.
Whether you’re building production web services or experimenting with network technologies we hope you find value in Pingora. It’s been a long journey, but sharing this project with the open source community has been a goal from the start. We’d like to thank the Rust community as Pingora is built with many great open-sourced Rust crates. Moving to a memory safe Internet may feel like an impossible journey, but it’s one we hope you join us on.