Kuhu Shukla (bottom center) and team at the 2017 DataWorks Summit
By Kuhu Shukla
This post first appeared here on the Apache Software Foundation blog as part of ASF’s “Success at Apache” monthly blog series.
As I sit at my desk on a rather frosty morning with my coffee, looking up new JIRAs from the previous day in the Apache Tez project, I feel rather pleased. The latest community release vote is complete, the bug fixes that we so badly needed are in and the new release that we tested out internally on our many thousand strong cluster is looking good. Today I am looking at a new stack trace from a different Apache project process and it is hard to miss how much of the exceptional code I get to look at every day comes from people all around the globe. A contributor leaves a JIRA comment before he goes on to pick up his kid from soccer practice while someone else wakes up to find that her effort on a bug fix for the past two months has finally come to fruition through a binding +1.
Yahoo – which joined AOL, HuffPost, Tumblr, Engadget, and many more brands to form the Verizon subsidiary Oath last year – has been at the frontier of open source adoption and contribution since before I was in high school. So while I have no historical trajectories to share, I do have a story on how I found myself in an epic journey of migrating all of Yahoo jobs from Apache MapReduce to Apache Tez, a then-new DAG based execution engine.
Oath grid infrastructure is through and through driven by Apache technologies be it storage through HDFS, resource management through YARN, job execution frameworks with Tez and user interface engines such as Hive, Hue, Pig, Sqoop, Spark, Storm. Our grid solution is specifically tailored to Oath’s business-critical data pipeline needs using the polymorphic technologies hosted, developed and maintained by the Apache community.
On the third day of my job at Yahoo in 2015, I received a YouTube link on An Introduction to Apache Tez. I watched it carefully trying to keep up with all the questions I had and recognized a few names from my academic readings of Yarn ACM papers. I continued to ramp up on YARN and HDFS, the foundational Apache technologies Oath heavily contributes to even today. For the first few weeks I spent time picking out my favorite (necessary) mailing lists to subscribe to and getting started on setting up on a pseudo-distributed Hadoop cluster. I continued to find my footing with newbie contributions and being ever more careful with whitespaces in my patches. One thing was clear – Tez was the next big thing for us. By the time I could truly call myself a contributor in the Hadoop community nearly 80-90% of the Yahoo jobs were now running with Tez. But just like hiking up the Grand Canyon, the last 20% is where all the pain was. Being a part of the solution to this challenge was a happy prospect and thankfully contributing to Tez became a goal in my next quarter.
The next sprint planning meeting ended with me getting my first major Tez assignment – progress reporting. The progress reporting in Tez was non-existent – “Just needs an API fix,” I thought. Like almost all bugs in this ecosystem, it was not easy. How do you define progress? How is it different for different kinds of outputs in a graph? The questions were many.
I, however, did not have to go far to get answers. The Tez community actively came to a newbie’s rescue, finding answers and posing important questions. I started attending the bi-weekly Tez community sync up calls and asking existing contributors and committers for course correction. Suddenly the team was much bigger, the goals much more chiseled. This was new to anyone like me who came from the networking industry, where the most open part of the code are the RFCs and the implementation details are often hidden. These meetings served as a clean room for our coding ideas and experiments. Ideas were shared, to the extent of which data structure we should pick and what a future user of Tez would take from it. In between the usual status updates and extensive knowledge transfers were made.
Oath uses Apache Pig and Apache Hive extensively and most of the urgent requirements and requests came from Pig and Hive developers and users. Each issue led to a community JIRA and as we started running Tez at Oath scale, new feature ideas and bugs around performance and resource utilization materialized. Every year most of the Hadoop team at Oath travels to the Hadoop Summit where we meet our cohorts from the Apache community and we stand for hours discussing the state of the art and what is next for the project. One such discussion set the course for the next year and a half for me.
We needed an innovative way to shuffle data. Frameworks like MapReduce and Tez have a shuffle phase in their processing lifecycle wherein the data from upstream producers is made available to downstream consumers. Even though Apache Tez was designed with a feature set corresponding to optimization requirements in Pig and Hive, the Shuffle Handler Service was retrofitted from MapReduce at the time of the project’s inception. With several thousands of jobs on our clusters leveraging these features in Tez, the Shuffle Handler Service became a clear performance bottleneck. So as we stood talking about our experience with Tez with our friends from the community, we decided to implement a new Shuffle Handler for Tez. All the conversation points were tracked now through an umbrella JIRA TEZ-3334 and the to-do list was long. I picked a few JIRAs and as I started reading through I realized, this is all new code I get to contribute to and review. There might be a better way to put this, but to be honest it was just a lot of fun! All the whiteboards were full, the team took walks post lunch and discussed how to go about defining the API. Countless hours were spent debugging hangs while fetching data and looking at stack traces and Wireshark captures from our test runs. Six months in and we had the feature on our sandbox clusters. There were moments ranging from sheer frustration to absolute exhilaration with high fives as we continued to address review comments and fixing big and small issues with this evolving feature.
As much as owning your code is valued everywhere in the software community, I would never go on to say “I did this!” In fact, “we did!” It is this strong sense of shared ownership and fluid team structure that makes the open source experience at Apache truly rewarding. This is just one example. A lot of the work that was done in Tez was leveraged by the Hive and Pig community and cross Apache product community interaction made the work ever more interesting and challenging. Triaging and fixing issues with the Tez rollout led us to hit a 100% migration score last year and we also rolled the Tez Shuffle Handler Service out to our research clusters. As of last year we have run around 100 million Tez DAGs with a total of 50 billion tasks over almost 38,000 nodes.
In 2018 as I move on to explore Hadoop 3.0 as our future release, I hope that if someone outside the Apache community is reading this, it will inspire and intrigue them to contribute to a project of their choice. As an astronomy aficionado, going from a newbie Apache contributor to a newbie Apache committer was very much like looking through my telescope - it has endless possibilities and challenges you to be your best.
About the Author:
Kuhu Shukla is a software engineer at Oath and did her Masters in Computer Science at North Carolina State University. She works on the Big Data Platforms team on Apache Tez, YARN and HDFS with a lot of talented Apache PMCs and Committers in Champaign, Illinois. A recent Apache Tez Committer herself she continues to contribute to YARN and HDFS and spoke at the 2017 Dataworks Hadoop Summit on “Tez Shuffle Handler: Shuffling At Scale With Apache Hadoop”. Prior to that she worked on Juniper Networks’ router and switch configuration APIs. She likes to participate in open source conferences and women in tech events. In her spare time she loves singing Indian classical and jazz, laughing, whale watching, hiking and peering through her Dobsonian telescope.
By Murali Krishna Bachhu, Anurag Damle, and Utkarsh Shrivastava
As engineers on the Yahoo Mail team at Oath, we pride ourselves on the things that matter most to developers: faster development cycles, more reliability, and better performance. Users don’t necessarily see these elements, but they certainly feel the difference they make when significant improvements are made. Recently, we were able to upgrade all three of these areas at scale by adopting webpack® as Yahoo Mail’s underlying module bundler, and you can do the same for your web application.
What is webpack?
webpack is an open source module bundler for modern JavaScript applications. When webpack processes your application, it recursively builds a dependency graph that includes every module your application needs. Then it packages all of those modules into a small number of bundles, often only one, to be loaded by the browser.
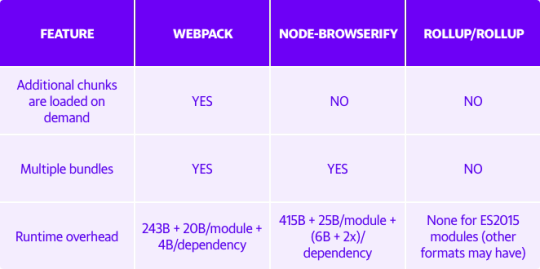
webpack became our choice module bundler not only because it supports on-demand loading, multiple bundle generation, and has a relatively low runtime overhead, but also because it is better suited for web platforms and NodeJS apps and has great community support.
Comparison of webpack to other open source bundlers
How did we integrate webpack?
Like any developer does when integrating a new module bundler, we started integrating webpack into Yahoo Mail by looking at its basic config file. We explored available default webpack plugins as well as third-party webpack plugins and then picked the plugins most suitable for our application. If we didn’t find a plugin that suited a specific need, we wrote the webpack plugin ourselves (e.g., We wrote a plugin to execute Atomic CSS scripts in the latest Yahoo Mail experience in order to decrease our overall CSS payload**).
During the development process for Yahoo Mail, we needed a way to make sure webpack would continuously run in the background. To make this happen, we decided to use the task runner Grunt. Not only does Grunt keep the connection to webpack alive, but it also gives us the ability to pass different parameters to the webpack config file based on the given environment. Some examples of these parameters are source map options, enabling HMR, and uglification.
Before deployment to production, we wanted to optimize the javascript bundles for size to make the Yahoo Mail experience faster. webpack provides good default support for this with the UglifyJS plugin. Although the default options are conservative, they give us the ability to configure the options. Once we modified the options to our specifications, we saved approximately 10KB.
Code snippet showing the configuration options for the UglifyJS plugin
Faster development cycles for developers
While developing a new feature, engineers ideally want to see their code changes reflected on their web app instantaneously. This allows them to maintain their train of thought and eventually results in more productivity. Before we implemented webpack, it took us around 30 seconds to 1 minute for changes to reflect on our Yahoo Mail development environment. webpack helped us reduce the wait time to 5 seconds.
More reliability
Consumers love a reliable product, where all the features work seamlessly every time. Before we began using webpack, we were generating javascript bundles on demand or during run-time, which meant the product was more prone to exceptions or failures while fetching the javascript bundles. With webpack, we now generate all the bundles during build time, which means that all the bundles are available whenever consumers access Yahoo Mail. This results in significantly fewer exceptions and failures and a better experience overall.
Better Performance
We were able to attain a significant reduction of payload after adopting webpack.
Reduction of about 75 KB gzipped Javascript payload
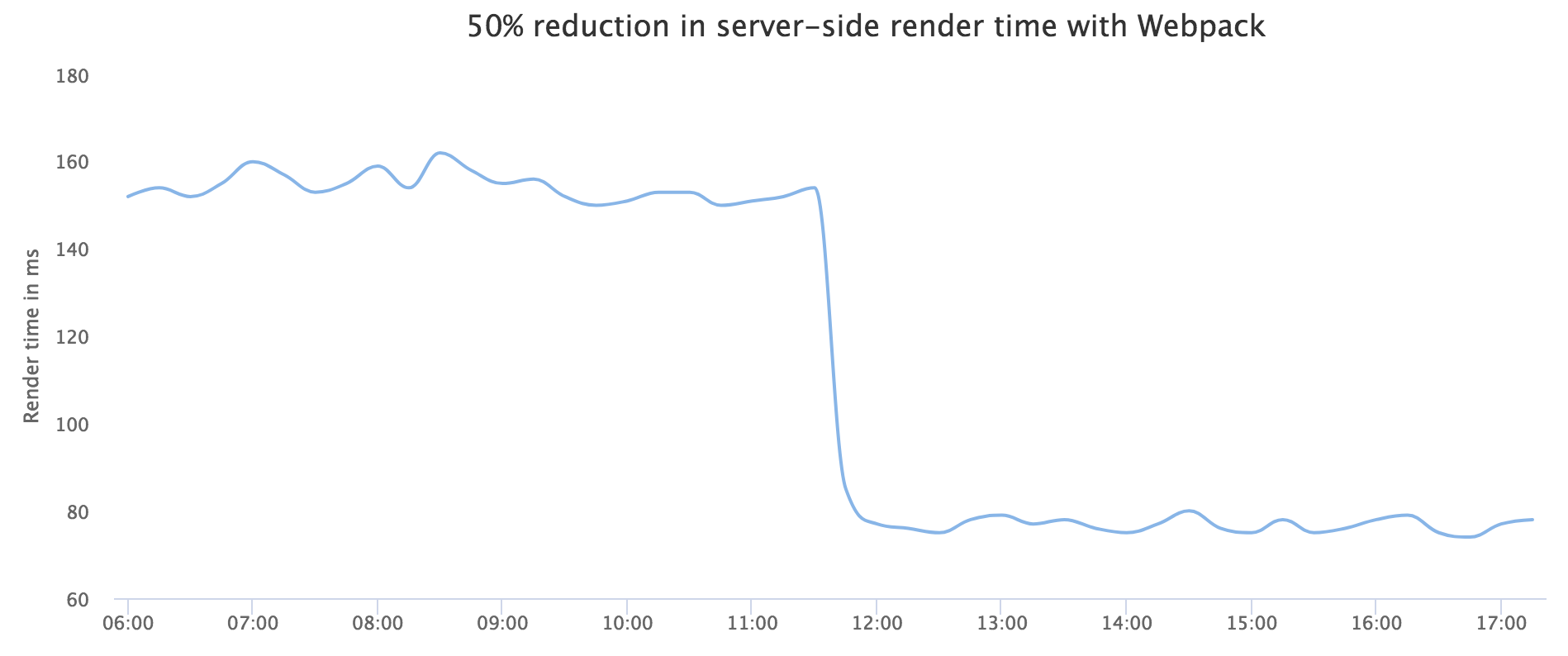
50% reduction on server-side render time
10% improvement in Yahoo Mail’s launch performance metrics, as measured by render time above the fold (e.g., Time to load contents of an email).
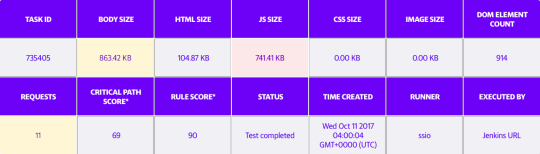
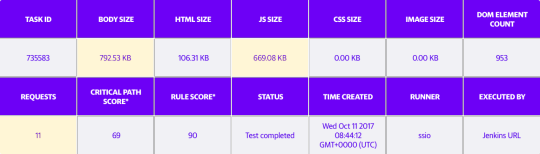
Below are some charts that demonstrate the payload size of Yahoo Mail before and after implementing webpack.
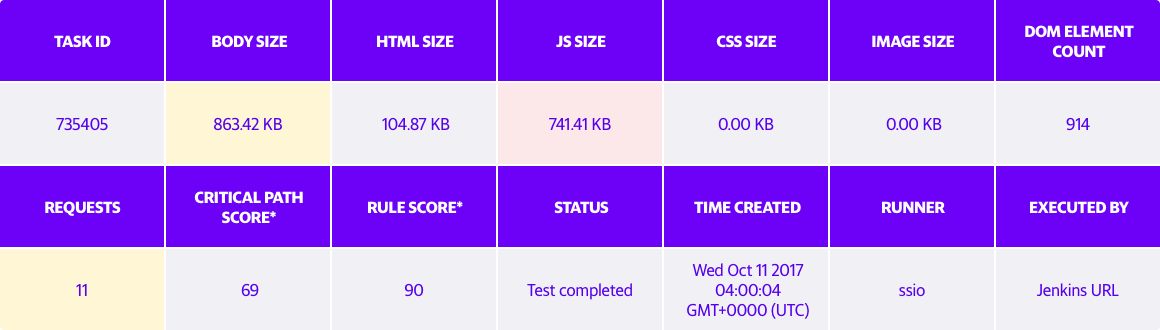
Payload before using webpack (JavaScript Size = 741.41KB)
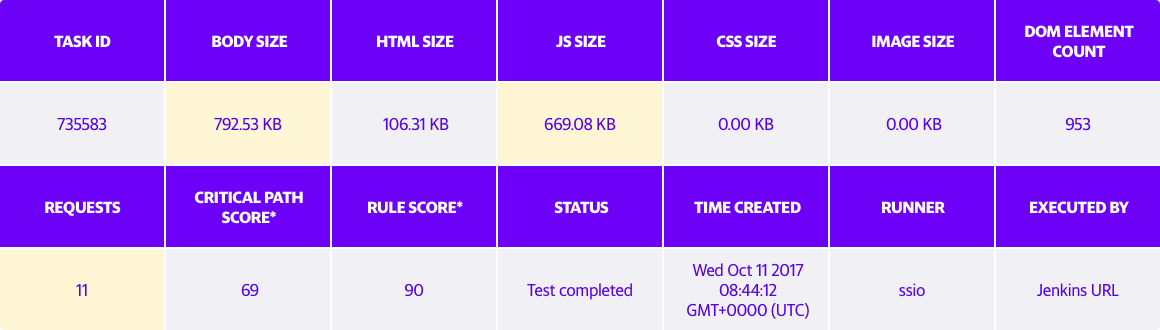
Payload after switching to webpack (JavaScript size = 669.08KB)
Conclusion
Shifting to webpack has resulted in significant improvements. We saw a common build process go from 30 seconds to 5 seconds, large JavaScript bundle size reductions, and a halving in server-side rendering time. In addition to these benefits, our engineers have found the community support for webpack to have been impressive as well. webpack has made the development of Yahoo Mail more efficient and enhanced the product for users. We believe you can use it to achieve similar results for your web application as well.
**Optimized CSS generation with Atomizer
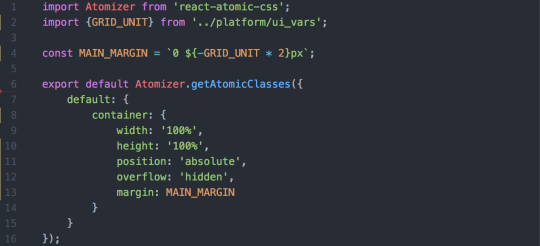
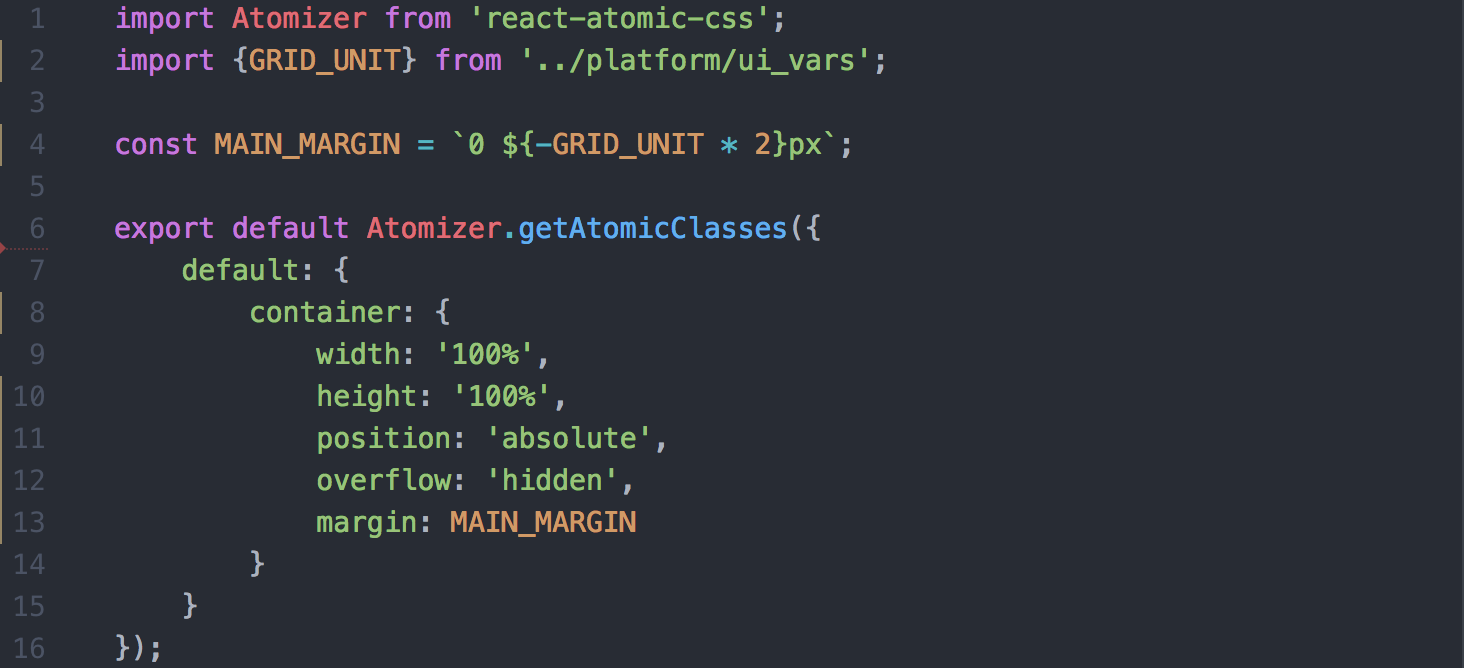
Before we implemented webpack into the development of Yahoo Mail, we looked into how we could decrease our CSS payload. To achieve this, we developed an in-house solution for writing modular and scoped CSS in React. Our solution is similar to the Atomizer library, and our CSS is written in JavaScript like the example below:
Sample snippet of CSS written with Atomizer
Every React component creates its own styles.js file with required style definitions. React-Atomic-CSS converts these files into unique class definitions. Our total CSS payload after implementing our solution equaled all the unique style definitions in our code, or only 83KB (21KB gzipped).
During our migration to webpack, we created a custom plugin and loader to parse these files and extract the unique style definitions from all of our CSS files. Since this process is tied to bundling, only CSS files that are part of the dependency chain are included in the final CSS.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}