Post Syndicated from Dmitry Vorobev original https://blog.cloudflare.com/the-effect-of-switching-to-tcmalloc-on-rocksdb-memory-use/
In previous posts we wrote about our configuration distribution system Quicksilver and the story of migrating its storage engine to RocksDB. This solution proved to be fast, resilient and stable. During the migration process, we noticed that Quicksilver memory consumption was unexpectedly high. After our investigation we found out that the root cause was a default memory allocator that we used. Switching memory allocator improved service memory consumption by almost three times.
Unexpected memory growth
After migrating to RocksDB, the memory used by the application increased significantly. Also, the way memory was growing over time looked suspicious. It was around 15GB immediately after start and then was steadily growing for multiple days, until stabilizing at around 30GB. Below, you can see a memory consumption increase after migrating one of our test instances to RocksDB.
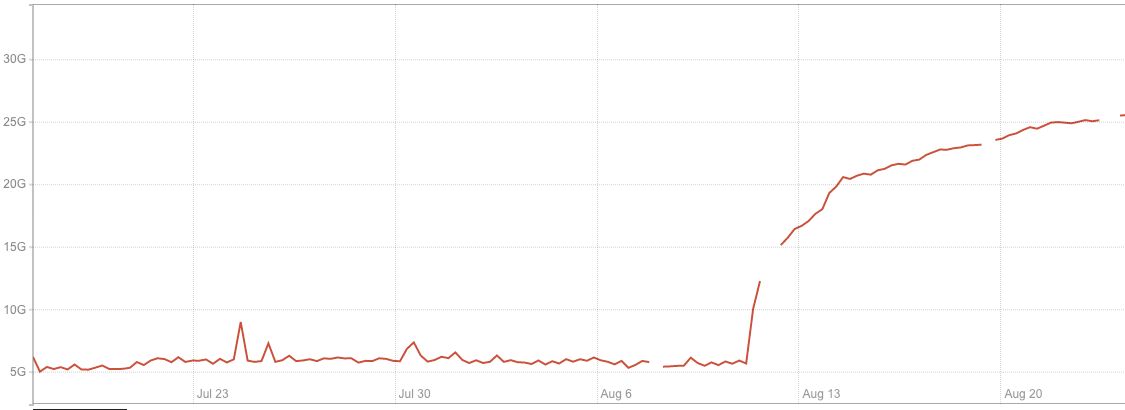
We started our investigation with heap profiling with the assumption that we had a memory leak somewhere and found that heap size was almost three times less than the RSS value reported by the operating system. So, if our application does not actually use all this memory, it means that memory is ‘lost’ somewhere between the system and our application, which points to possible problems with the memory allocator.
We have multiple services running with the tcmalloc allocator, so in order to test our hypothesis, we ran a test with TCMalloc on a couple of instances. The test showed significant improvement in memory usage. So why did this happen? We’ll dig into memory allocator internals to understand the issue.
glibc malloc
Let’s begin with a high level view of glibc’s malloc design. malloc uses a concept called an arena. An arena is a contiguous block of memory obtained from the system. An important part of glibc malloc design is that it expects developers to free memory in a reverse order of allocation, otherwise a lot of memory will be ‘locked’, and never returned to the system. Let’s see what it means on practise:
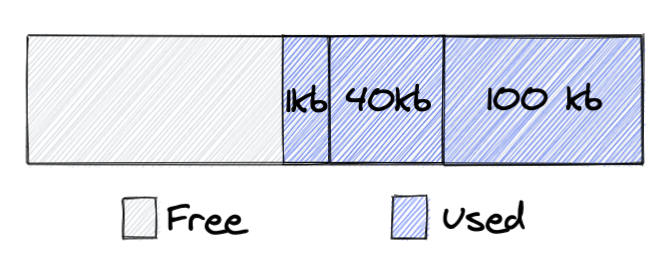
In the picture, you can see an arena, from which we allocated three chunks of memory: 100kb, 40kb, 1kb. Next, the application frees the chunks with sizes of 40kb and 100kb:
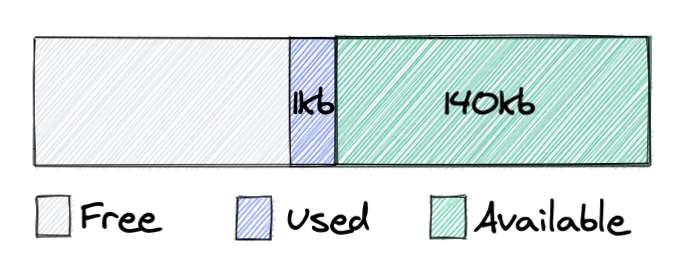
Before we go further, let me explain the terminology I use here and what each type of memory means:
- Free – this is virtual memory of a process, not backed by physical memory, and corresponds to the VIRT parameter of the top/ps command.
- Used – memory used by the application, backed by physical memory, contributes to the RES parameter of the top/ps command.
- Available – memory held by the allocator, backed by physical memory. The allocator can either return this memory to the OS, and it would become ‘Free’ or later reuse it to satisfy application requests. From a system perspective, this memory is still held by the application. Available + Used = RES.
So we see that memory which was used by the application changed state to Available, and it’s not returned to the operating system. This is because malloc can only return memory from the top of the heap, and in the case above we have a chunk of memory that blocks 140kb from being released back to the system. As soon as we release this 1kb object, all memory can be returned to the system.
Let’s go further with our simple example, if our application allocates/frees memory without keeping malloc’s design in mind, after a while we will see roughly following picture:
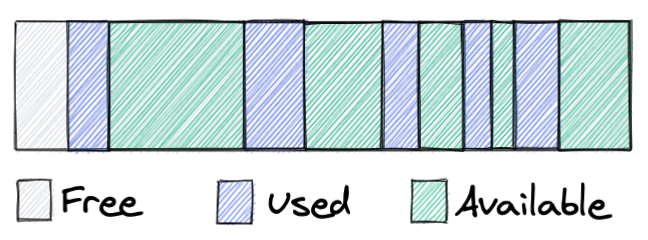
Here we see one of the main problems that all allocators try to solve: memory fragmentation. We have some chunks used by the application, but a lot of the memory is not used at the moment. And since it’s not returned to the system, other services can’t use this memory either. Malloc implements several mechanisms to decrease memory fragmentation, but it’s a problem that all allocators have, and how bad this problem is depends on a lot of factors: allocator design, workload, settings, etc.
OK, so the problem is clear, memory fragmentation, but why did it lead to such high memory usage? To understand that, let’s take a step back and consider how malloc works for highly concurrent multithreaded applications.
To allocate a chunk of memory from an arena, a thread should acquire an exclusive lock for that arena. When an application has multiple threads this would create lock contention and poor performance for multithreaded services. To handle this situation malloc creates several arenas, using the following logic:
- A thread tries to get a chunk of memory from an arena it used last time, in order to do that it acquires an exclusive lock for the arena
- If the lock is held by another thread, it tries the next arena
- If all arenas were locked it creates a new arena and uses memory from it
- There is a limit on the number of arenas – eight arenas per core
Normally, our service has around 25 threads, and we have seen 60-80 arenas allocated by malloc using the logic above.
And this is a place where the fragmentation problem magnifies and leads to huge memory waste. All arenas are independent of each other and memory can never move from one arena to another. Why is that bad? Let’s take a look at the following example:
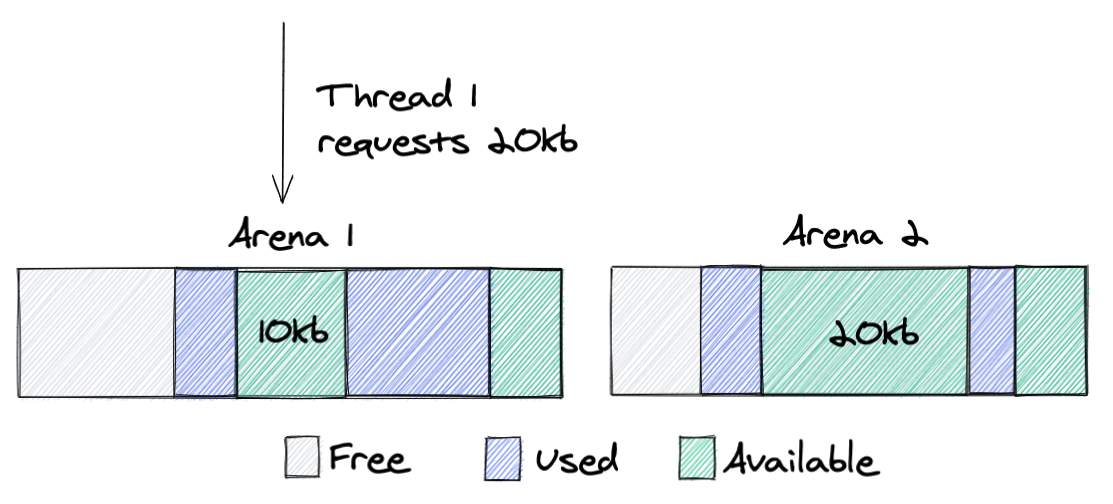
Here, we can see that Thread 1 requests 20kb of memory from Arena 1; as I’ve written before, malloc tries to allocate memory from the same arena it’s used before. Since Arena 1 still has enough free memory, Thread 1 will get a block from it, which at the end will increase memory that the process takes from the system. Ideally, in this scenario, we would prefer to get this block of memory from Arena 2, since it has a chunk of that size available. However, due to the design this won’t happen.
The main point here: having multiple independent arenas improves the performance of multithreaded applications, by reducing lock contention, but the trade-off is that it increases memory fragmentation, since each memory request chooses the best fit fragment from an individual arena and not the best fit fragment overall.
Remember, I wrote that memory locked between used chunks can never be returned to the system? Actually, there is a way to do that, ‘malloc_trim’ is a function provided by glibc malloc, and it does exactly that. It goes through all the unused chunks and returns them to the system. The problem is that you need to explicitly call this function from your application. You might say: “Oh, wait, I remember that this function is sometimes called when you call the free function, I saw it in the man page.” No, that never happens, it’s a bug in the man page that has existed for more than 15 years, which is now finally fixed!
Let’s now discuss what options we have to improve the memory consumption of glibc malloc. Here are a couple of useful strategies to try out:
- The first thing you would find on the Internet is to reduce MALLOC_ARENA_MAX to a lower value, usually 2. This setting limits the number of arenas malloc would create per core. The fewer arenas we have the better the memory reuse, hence lower fragmentation, but at the same time it would increase lock contention.
- Calling malloc_trim from time to time. This function goes through all arenas one at a time, it locks the arena and releases all locked chunks back to the system. This at the end increases lock contention and will execute a lot of syscalls to return memory and later would lead to more page faults and again worse performance.
- M_MMAP_THRESHOLD. All allocations higher than this parameter would use the mmap syscall, and would not take memory from the arena directly. That means that memory allocated with this approach would never be locked between used chunks of memory and can always be returned to the system. It solves the fragmentation problem for large chunks, so only small chunks would be locked. The trade-off here is that each such allocation would execute an expensive syscall. And there is a system limit that caps the maximum number of chunks allocated with mmap.
Short summary: multiple arenas cause higher memory fragmentation that can lead to 2-3x higher memory consumption.
TCMalloc
While glibc malloc was designed for single-threaded applications and later optimized for multithreaded services, TCMalloc was built for multithreading at the beginning. Let’s take a look at how it tries to solve the problems we just talked about. The TCMalloc design is more complex, so if you want to understand the details I recommend reading the official design page. Here is a high level view of its design:
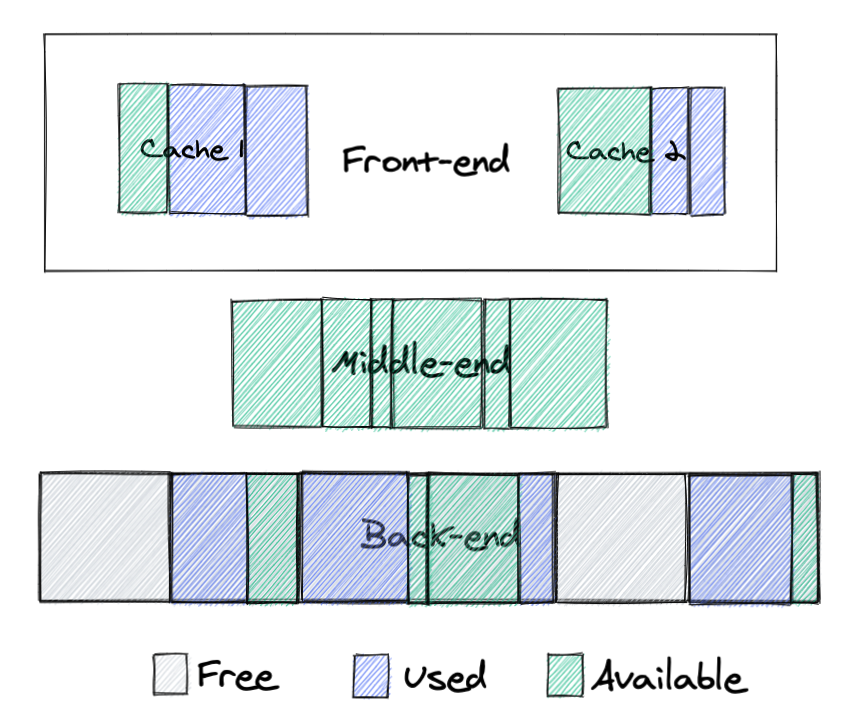
Here we can see 3 main parts of TCMalloc design:
- Back-end: allocates big chunks of memory from the system, returns these chunks back to the operating system when they are not needed and also serves big allocation requests.
- Front-end: serves allocation requests, there is one cache per core.
- Middle-end: this is a core part of the TCMalloc design, which helps to significantly reduce fragmentation for multithreaded applications. It populates caches and returns unused memory to the back-end, but most importantly it can move memory from one cache to another, dramatically improving memory reuse.
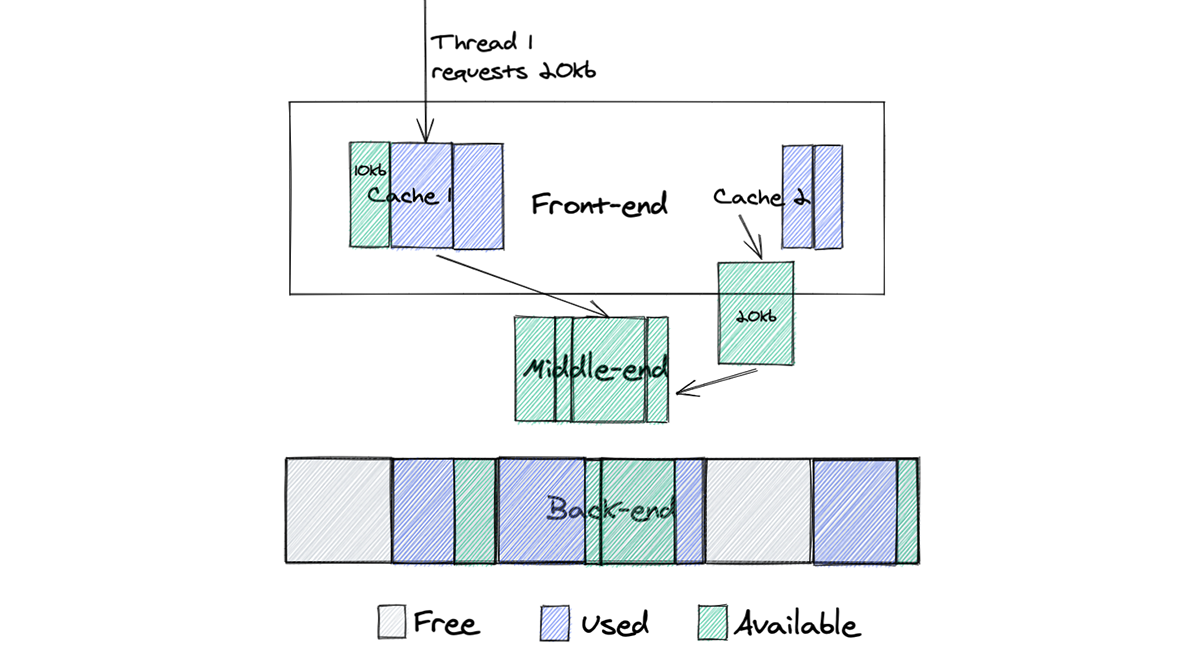
Let’s look how it works on the example that we showed for malloc:
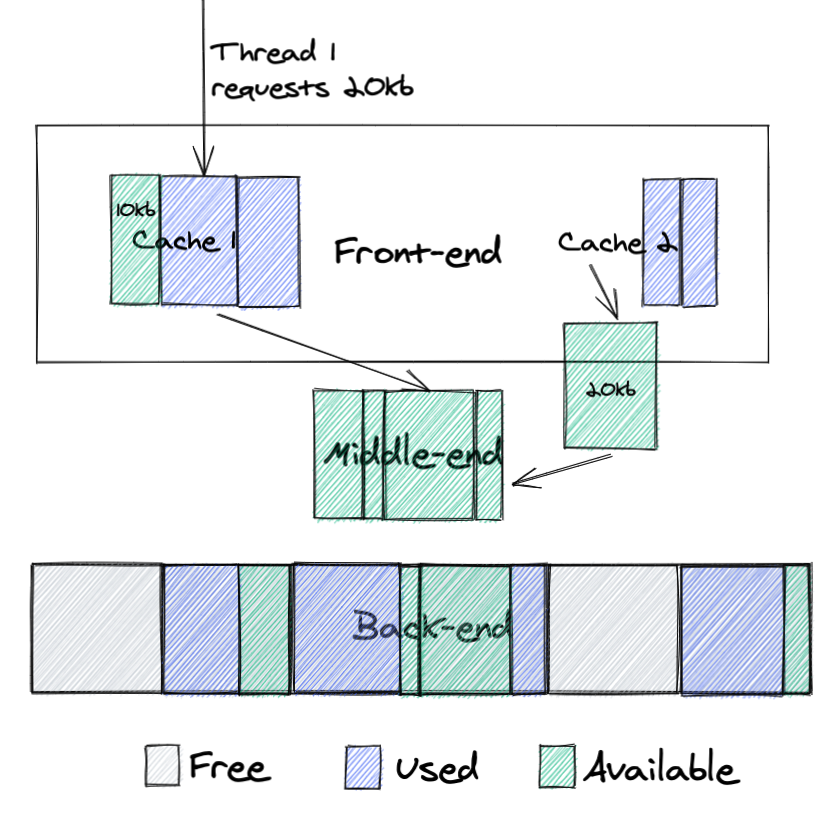
Here we see the following:
- Cache 2 has a chunk of memory that it doesn’t need, so it returns it to the middle-end
- Thread 1 requests 20kb of memory from cache 1
- Cache 1 doesn’t have a chunk of memory of that size, so it requests this memory from middle-end, where it can reuse memory from cache 2
This design dramatically improves memory reuse. If memory was freed by one thread it can be moved to the middle-end and later reused by other threads.
Conclusion
The main goal of this post is to make people aware of the importance of the choice of memory allocator. After deploying TCMalloc, we decreased memory usage by 2.5 times.
Usage of an allocator which is not optimal for a workload can cause a huge waste of memory. If you have a long-running application with a lot of threads and care about memory usage then glibc malloc is probably not your choice. Allocators that are designed for multithreaded services, like TCMalloc, jemalloc and others can provide much better memory utilization. So be conscious of this factor and go and check how much memory your application wastes.