Post Syndicated from Joaquin Manuel Rinaudo original https://aws.amazon.com/blogs/security/how-to-use-interface-vpc-endpoints-to-meet-your-security-objectives/
Amazon Virtual Private Cloud (Amazon VPC) endpoints—powered by AWS PrivateLink—enable customers to establish private connectivity to supported AWS services, enterprise services, and third-party services by using private IP addresses. There are three types of VPC endpoints: interface endpoints, Gateway Load Balancer endpoints, and gateway endpoints. An interface VPC endpoint, in particular, allows customers to design applications that connect to AWS services privately, including the more than 130 AWS services that are available over AWS PrivateLink. For a complete list of services that integrate with PrivateLink, see the documentation for VPC endpoints.
The decision regarding when to use interface VPC endpoints to further secure your AWS infrastructure depends on your need for additional security controls or your preferred architecture patterns. In this blog post, we present four security objectives that VPC endpoints help you achieve. It’s important to note that other non-security benefits, such as reduced latency and cost management, are not covered in this post. For more information on those benefits, see these topics:
- Improve the latency of sensitive applications with Amazon SageMaker real-time inference endpoints
- Reduce network costs by centralizing access to AWS services through AWS Transit Gateway
Background
By default, network packets that originate in the AWS network with a destination on the AWS network (for example, public endpoints for AWS services) stay in the AWS network, except traffic to and from AWS China Regions. In addition, all data flowing across the AWS global network that interconnects AWS data centers and Regions is automatically encrypted at the physical layer before it leaves AWS secured facilities.
AWS PrivateLink VPC endpoints enable customers to further enhance the security posture of their applications by establishing private connectivity to supported AWS services, enterprise services, and third-party services by using a private IP address. You can find patterns for how to use the different types of endpoints in the Securely Access Services Over AWS PrivateLink whitepaper.
An interface VPC endpoint is a collection of one or more elastic network interfaces with private IP addresses. These endpoints can serve as an entry point for traffic destined to a supported AWS service in the same AWS Region as the VPC, without requiring an internet gateway, NAT device, VPN connection, AWS Direct Connect connection, or a public IP. Customers can then use interface VPC endpoints to help meet multiple security objectives, such as the following:
- Implement networks that are isolated from the internet
- Implement a data perimeter by using VPC endpoint policies
- Enable private connectivity to AWS service API endpoints for on-premises environments
- Align with specific compliance requirements
In the rest of this post, we’ll discuss each of these objectives in detail and how interface VPC endpoints can help you implement them.
Security objective 1: Implementing networks that are isolated from the internet
If you operate sensitive workloads, you might require that they run in private subnets that are isolated from the internet. In this scenario, the subnets in the network don’t have routes to an internet gateway and won’t be able to either send packets to the internet or receive packets from it.
In this case, you can use interface VPC endpoints to connect your VPC to AWS services in the same Region as if they were in your VPC, without configuring an internet gateway, NAT instance, or route tables. For information on how to configure a cross-Region VPC interface endpoint by using VPC peering, see this guidance.
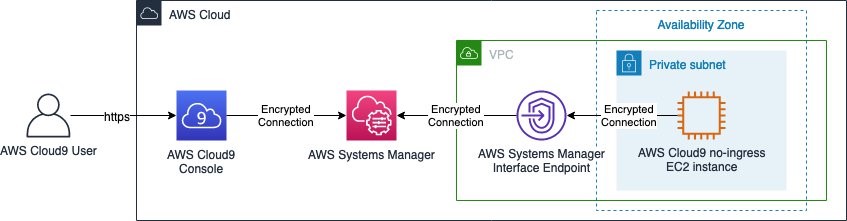
Figure 1 shows an example architecture with an Amazon Elastic Compute Cloud (Amazon EC2) instance running in an isolated network and using interface VPC endpoints to send messages to Amazon Simple Queue Service (Amazon SQS).

Figure 1: Isolated subnet for EC2 server sending messages to Amazon SQS
Security objective 2: Implement a data perimeter using VPC endpoint policies
A data perimeter is a set of guardrails to help ensure that only your trusted identities are accessing trusted resources from expected networks. Learn more about data perimeters on AWS.
You can use VPC endpoint policies to implement a data perimeter by allowing access to only trusted entities and resources from your network, helping to prevent unintended access. This enables you to take advantage of the power of AWS Identity and Access Management (IAM) policy and flexibility to control access to your resources at a granular level.
In the VPC diagram in Figure 2, EC2 instance traffic flows out through a firewall endpoint, NAT gateway, and internet gateway to reach the S3 public API endpoint, remaining within the AWS network. However, this setup does not allow the implementation of a logical data perimeter to control the specific resources that the EC2 instance can access.

Figure 2: Before implementing a data perimeter
In contrast, in the diagram in Figure 3, you can see how VPC interface endpoints enable the use of VPC endpoint policies to enforce a data perimeter, such as only allowing certain S3 buckets to be accessed by the EC2 instance.

Figure 3: After implementing a data perimeter
For example, you can attach a policy, similar to the one below, to an Amazon S3 interface or gateway VPC endpoint to restrict access from the VPC to only S3 buckets that are owned by the same AWS Organizations organization. Make sure to replace <MY-ORG-ID> with your own information.
As a further example, the following policy shows how you can limit access to only trusted identities. You can attach this policy to an S3 interface VPC endpoint to permit access only to principals from your organization, to help mitigate the risk of unintended disclosure through non-corporate credentials. Make sure to replace <MY-ORG-ID> with your own information.
Finally, you can create resource policies for your resources to restrict access to only VPC interface endpoints. For example, you can use the following policy from our Amazon S3 User Guide for S3 buckets. Make sure to replace <MY-VPCE-ID> and <MY-BUCKET> with your own information.
For more information on the use of these condition keys and how to implement a data perimeter, see this blog post.
Security objective 3: Enable private connectivity to AWS service API endpoints for on-premises environments
You might be required to run private connectivity to AWS only from your on-premises environments, such as when your on-premises firewalls are configured to limit the connectivity to the internet, including AWS public endpoints.
In this case, you can use interface VPC endpoints with Direct Connect private virtual interfaces (VIFs) or Site-to-Site VPN to extend private connectivity to your on-premises networks. With this setup, you can also enforce data perimeter rules like those shown earlier in this post.
For example, customers can use interface VPC endpoints from Amazon CloudWatch agents running on on-premises servers to CloudWatch through a private connection, as demonstrated in this blog post.
In the diagram in Figure 4, we show how you can extend this approach to include other services, such as Amazon S3, in a single VPC setup. To implement this pattern, you need to set up conditional forwarding on your on-premises DNS resolver to forward queries for amazonaws.com to an Amazon Route 53 Resolver’s inbound endpoint IPs.
The flow in this scenario is as follows:
- The DNS query for your S3 endpoint from your on-premises host is routed to the locally configured on-premises DNS server.
- The on-premises DNS server performs conditional forwarding to an Amazon Route 53 inbound resolver endpoint IP address.
- The inbound resolver returns the IP address of the interface VPC endpoint, which allows the on-premises host to establish private connectivity through AWS VPN or AWS Direct Connect.

Figure 4: On-premises private connectivity to Amazon S3 and Amazon CloudWatch
You can extend this architecture to support a cross-Region and multi-VPC setup by using AWS Transit Gateway and Amazon Route 53 private hosted zones, as described in the Building a Scalable and Secure Multi-VPC AWS Network Infrastructure whitepaper. Keep in mind that a distributed VPC endpoint approach (one that uses one endpoint per VPC) will allow you to implement least-privilege policies in VPC endpoints. A centralized approach, while more cost-effective, can increase the complexity of maintaining least privilege in a single policy and increase the scope of impact of a security event.
Security objective 4: Align with specific compliance requirements
In certain cases, customers operating in industries such as financial services or healthcare need to maintain compliance with regulations or standards such as HIPAA, the EU-US Data Privacy Framework, and PCI DSS. Although all communication between instances and services hosted in AWS use the AWS private network, using an interface VPC endpoint can help prove to auditors that you’re applying a defense-in-depth approach. This approach includes designing your workloads to run in networks that are isolated from the internet or implementing additional conditions such as the example VPC endpoint policies shown earlier in this post.
You can use AWS Audit Manager to get started mapping your compliance requirements to industry and geographic frameworks, such as NIST SP 800-53 Rev. 5, FedRAMP, and PCI DSS, and to automate evidence collection for controls such as the use of VPC endpoints. If you also have custom compliance requirements, you can create your own custom controls by using the Configure Amazon Virtual Private Cloud (VPC) service endpoints core control in the AWS Audit Manager control library console.
If you want to know how the use of VPC endpoints can help you align with compliance requirements for your specific workload and require assistance beyond what is provided in the public documentation on the AWS Compliance Programs webpage, you can consult with AWS Security Assurance Services (AWS SAS). AWS SAS has expert consultants and advisors who can help you design your systems to achieve, maintain, and automate compliance in the cloud.
Conclusion
In this blog post, we presented four security objectives to consider when deciding whether to use AWS interface VPC endpoints. You can use this information when you design your architecture or create a threat model to help implement secure architectures for your AWS hosted workloads. If you want to learn more about AWS PrivateLink and interface endpoints, see the AWS PrivateLink documentation. If you’re interested in learning more about implementing data perimeter concepts by using VPC endpoints, we suggest this workshop.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, contact AWS Support.