Post Syndicated from Maitreya Ranganath original https://aws.amazon.com/blogs/security/use-aws-secrets-manager-to-simplify-the-management-of-private-certificates/
AWS Certificate Manager (ACM) lets you easily provision, manage, and deploy public and private Secure Sockets Layer/Transport Layer Security (SSL/TLS) certificates for use with Amazon Web Services (AWS) services and your internal connected resources. For private certificates, AWS Certificate Manager Private Certificate Authority (ACM PCA) can be used to create private CA hierarchies, including root and subordinate CAs, without the investment and maintenance costs of operating an on-premises CA. With these CAs, you can issue custom end-entity certificates or use the ACM defaults.
When you manage the lifecycle of certificates, it’s important to follow best practices. You can think of a certificate as an identity of a service you’re connecting to. You have to ensure that these identities are secure and up to date, ideally with the least amount of manual intervention. AWS Secrets Manager provides a mechanism for managing certificates, and other secrets, at scale. Specifically, you can configure secrets to automatically rotate on a scheduled basis by using pre-built or custom AWS Lambda functions, encrypt them by using AWS Key Management Service (AWS KMS) keys, and automatically retrieve or distribute them for use in applications and services across an AWS environment. This reduces the overhead of manually managing the deployment, creation, and secure storage of these certificates.
In this post, you’ll learn how to use Secrets Manager to manage and distribute certificates created by ACM PCA across AWS Regions and accounts.
We present two use cases in this blog post to demonstrate the difference between issuing private certificates with ACM and with ACM PCA. For the first use case, you will create a certificate by using the ACM defaults for private certificates. You will then deploy the ACM default certificate to an Amazon Elastic Compute Cloud (Amazon EC2) instance that is launched in the same account as the secret and private CA. In the second scenario, you will create a custom certificate by using ACM PCA templates and parameters. This custom certificate will be deployed to an EC2 instance in a different account to demonstrate cross-account sharing of secrets.
Solution overview
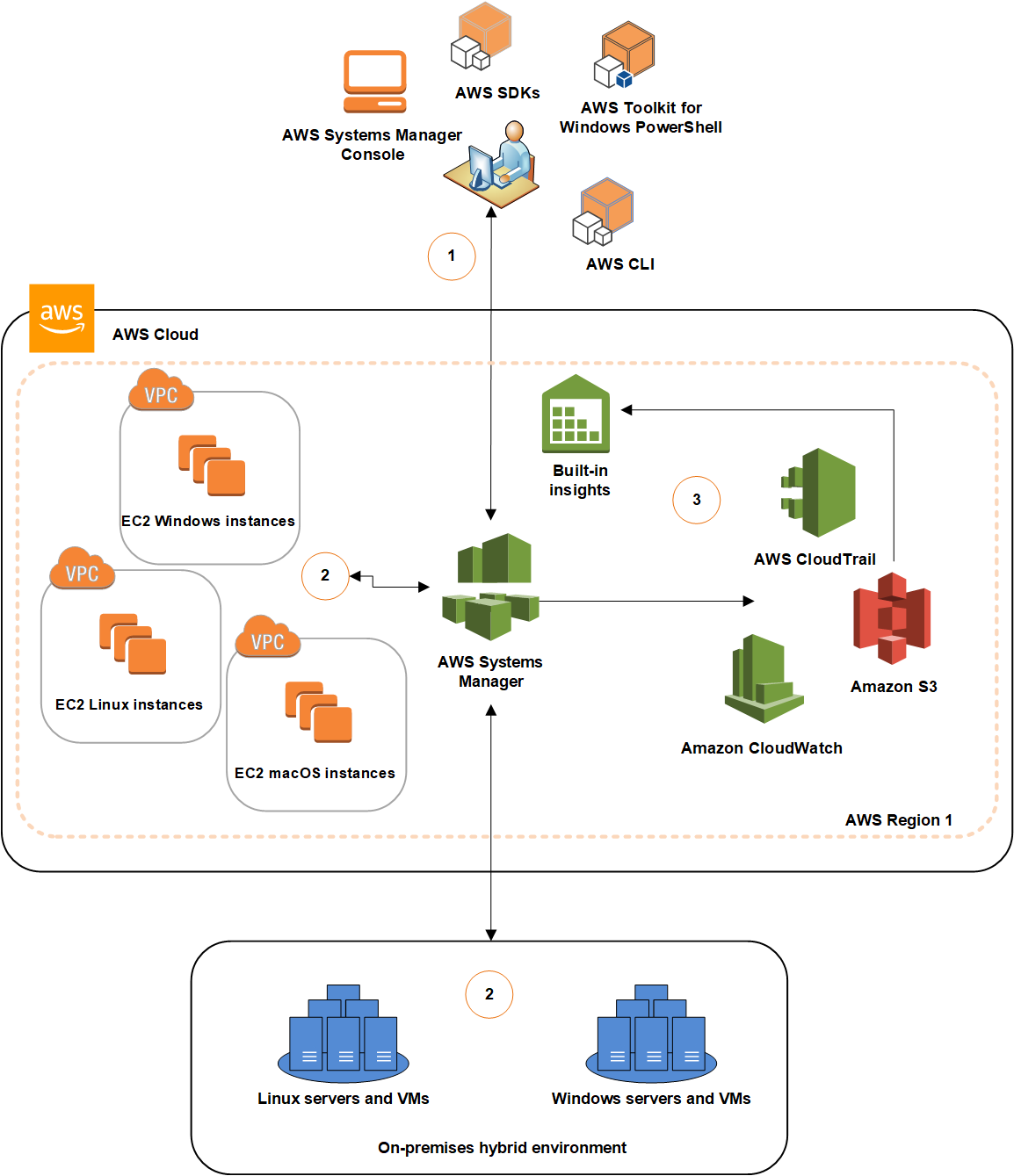
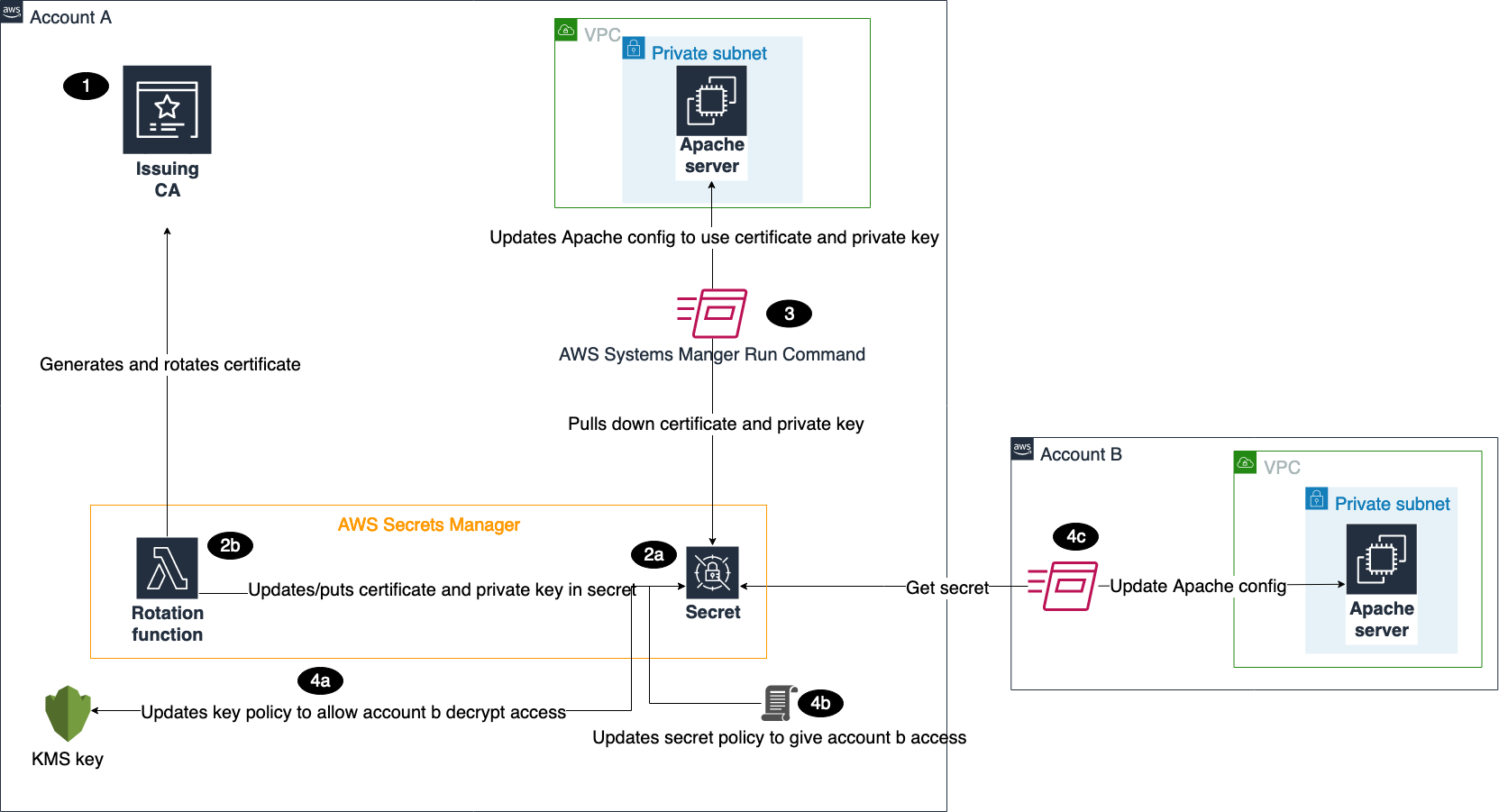
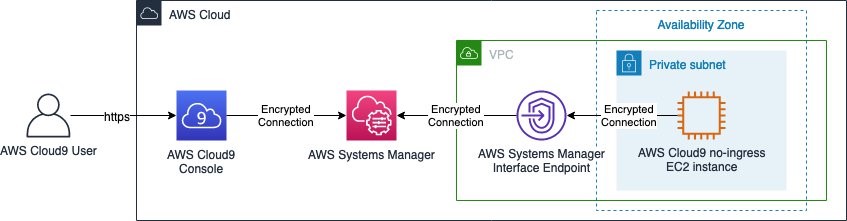
Figure 1 shows the architecture of our solution.

Figure 1: Solution architecture
This architecture includes resources that you will create during the blog walkthrough and by using AWS CloudFormation templates. This architecture outlines how these services can be used in a multi-account environment. As shown in the diagram:
- You create a certificate authority (CA) in ACM PCA to generate end-entity certificates.
- In the account where the issuing CA was created, you create secrets in Secrets Manager.
- There are several required parameters that you must provide when creating secrets, based on whether you want to create an ACM or ACM PCA issued certificate. These parameters will be passed to our Lambda function to make sure that the certificate is generated and stored properly.
- The Lambda rotation function created by the CloudFormation template is attached when configuring secrets rotation. Initially, the function generates two Privacy-Enhanced Mail (PEM) encoded files containing the certificate and private key, based on the provided parameters, and stores those in the secret. Subsequent calls to the function are made when the secret needs to be rotated, and then the function stores the resulting Certificate PEM and Private Key PEM in the desired secret. The function is written using Python, the AWS SDK for Python (Boto3), and OpenSSL. The flow of the function follows the requirements for rotating secrets in Secrets Manager.
- The first CloudFormation template creates a Systems Manager Run Command document that can be invoked to install the certificate and private key from the secret on an Apache Server running on EC2 in Account A.
- The second CloudFormation template deploys the same Run Command document and EC2 environment in Account B.
- To make sure that the account has the ability to pull down the certificate and private key from Secrets Manager, you need to update the key policy in Account A to give Account B access to decrypt the secret.
- You also need to add a resource-based policy to the secret that gives Account B access to retrieve the secret from Account A.
- Once the proper access is set up in Account A, you can use the Run Command document to install the certificate and private key on the Apache Server.
In a multi-account scenario, it’s common to have a central or shared AWS account that owns the ACM PCA resource, while workloads that are deployed in other AWS accounts use certificates issued by the ACM PCA. This can be achieved in two ways:
- Secrets in Secrets Manager can be shared with other AWS accounts by using resource-based policies. Once shared, the secrets can be deployed to resources, such as EC2 instances.
- You can share the central ACM PCA with other AWS accounts by using AWS Resource Access Manager or ACM PCA resource-based policies. These two options allow the receiving AWS account or accounts to issue private certificates by using the shared ACM PCA. These issued certificates can then use Secrets Manager to manage the secret in the child account and leverage features like rotation.
We will focus on first case for sharing secrets.
Solution cost
The cost for running this solution comes from the following services:
- AWS Certificate Manager Private Certificate Authority (ACM PCA)
Referring to the pricing page for ACM PCA, this solution incurs a prorated monthly charge of $400 for each CA that is created. A CA can be deleted the same day it’s created, leading to a charge of around $13/day (400 * 12 / 365.25). In addition, there is a cost for issuing certificates using ACM PCA. For the first 1000 certificates, this cost is $0.75. For this demonstration, you only need two certificates, resulting in a total charge of $1.50 for issuing certificates using ACM PCA. In all, the use of ACM PCA in this solution results in a charge of $14.50.
- Amazon EC2
The CloudFormation templates create t2.micro instances that cost $0.0116/hour, if they’re not eligible for Free Tier.
- Secrets Manager
There is a 30-day free trial for Secrets Manager, which is initiated when the first secret is created. After the free trial has completed, it costs $0.40 per secret stored per month. You will use two secrets for this solution and can schedule these for deletion after seven days, resulting in a prorated charge of $0.20.
- Lambda
Lambda has a free usage tier that allows for 1 million free requests per month and 400,000 GB-seconds of compute time per month. This fits within the usage for this blog, making the cost $0.
- AWS KMS
A single key created by one of the CloudFormation templates costs $1/month. The first 20,000 requests to AWS KMS are free, which fits within the usage of the test environment. In a production scenario, AWS KMS would charge $0.03 per 10,000 requests involving this key.
There are no charges for Systems Manager Run Command.
See the “Clean up resources” section of this blog post to get information on how to delete the resources that you create for this environment.
Deploy the solution
Now we’ll walk through the steps to deploy the solution. The CloudFormation templates and Lambda function code can be found in the AWS GitHub repository.
Create a CA to issue certificates
First, you’ll create an ACM PCA to issue private certificates. A common practice we see with customers is using a subordinate CA in AWS that is used to issue end-entity certificates for applications and workloads in the cloud. This subordinate can either point to a root CA in ACM PCA that is maintained by a central team, or to an existing on-premises public key infrastructure (PKI). There are some considerations when creating a CA hierarchy in ACM.
For demonstration purposes, you need to create a CA that can issue end-entity certificates. If you have an existing PKI that you want to use, you can create a subordinate CA that is signed by an external CA that can issue certificates. Otherwise, you can create a root CA and begin building a PKI on AWS. During creation of the CA, make sure that ACM has permissions to automatically renew certificates, because this feature will be used in later steps.
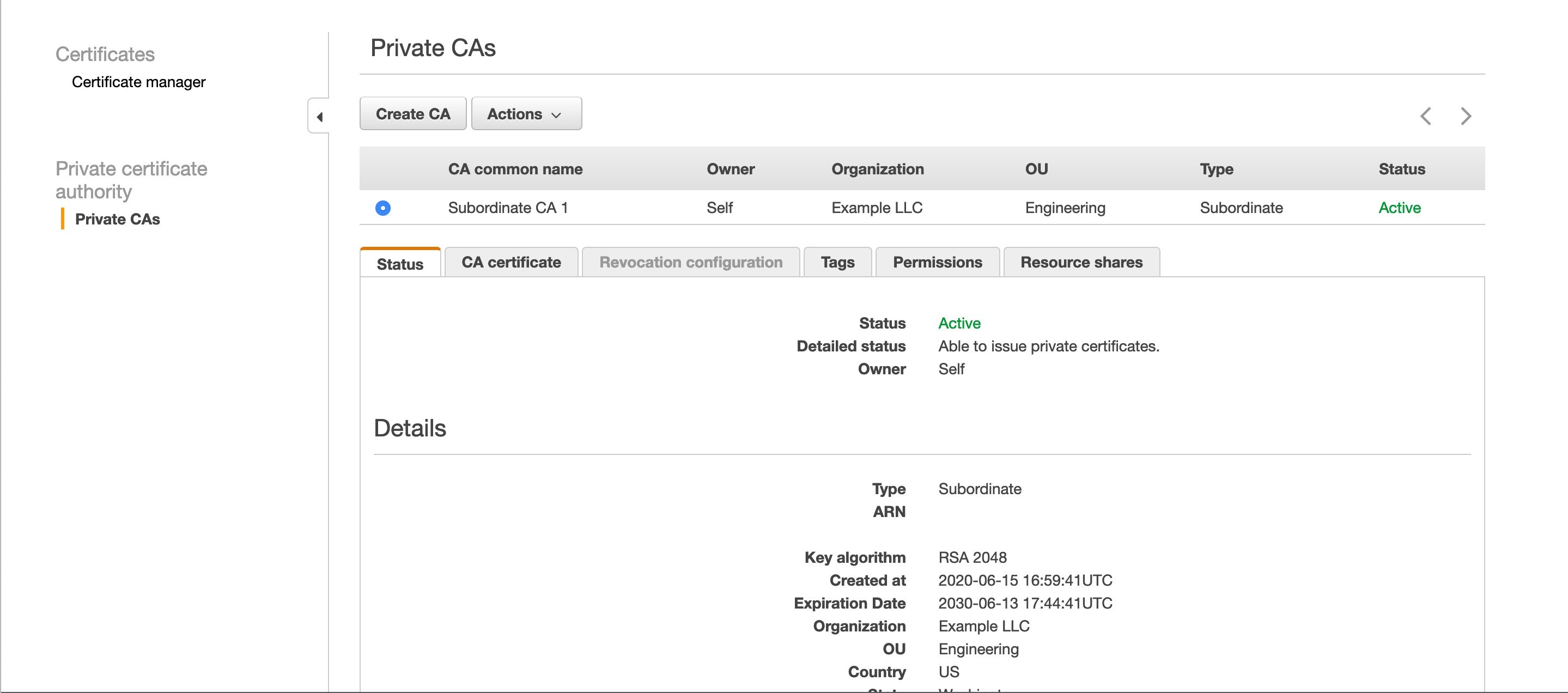
You should have one or more private CAs in the ACM console, as shown in Figure 2.

Figure 2: A private CA in the ACM PCA console
You will use two CloudFormation templates for this architecture. The first is launched in the same account where your private CA lives, and the second is launched in a different account. The first template generates the following: a Lambda function used for Secrets Manager rotation, an AWS KMS key to encrypt secrets, and a Systems Manager Run Command document to install the certificate on an Apache Server running on EC2 in Amazon Virtual Private Cloud (Amazon VPC). The second template launches the same Systems Manager Run Command document and EC2 environment.
To deploy the resources for the first template, select the following Launch Stack button. Make sure you’re in the N. Virginia (us-east-1) Region.

The template takes a few minutes to launch.
Use case #1: Create and deploy an ACM certificate
For the first use case, you’ll create a certificate by using the ACM defaults for private certificates, and then deploy it.
Create a Secrets Manager secret
To begin, create your first secret in Secrets Manager. You will create these secrets in the console to see how the service can be set up and used, but all these actions can be done through the AWS Command Line Interface (AWS CLI) or AWS SDKs.
To create a secret
- Navigate to the Secrets Manager console.
- Choose Store a new secret.
- For the secret type, select Other type of secrets.
- The Lambda rotation function has a set of required parameters in the secret type depending on what kind of certificate needs to be generated.For this first secret, you’re going to create an ACM_ISSUED certificate. Provide the following parameters.
| Key |
Value |
| CERTIFICATE_TYPE |
ACM_ISSUED |
| CA_ARN |
The Amazon Resource Name (ARN) of your certificate-issuing CA in ACM PCA |
| COMMON_NAME |
The end-entity name for your certificate (for example, server1.example) |
| ENVIRONMENT |
TEST (You need this later on to test the renewal of certificates. If using this outside of the blog walkthrough, set it to something like DEV or PROD.) |
- For Encryption key, select CAKey, and then choose Next.
- Give the secret a name and optionally add tags or a description. Choose Next.
- Select Enable automatic rotation and choose the Lambda function that starts with <CloudFormation Stack Name>-SecretsRotateFunction. Because you’re creating an ACM-issued certificate, the rotation will be handled 60 days before the certificate expires. The validity is set to 365 days, so any value higher than 305 would work. Choose Next.
- Review the configuration, and then choose Store.
- This will take you back to a list of your secrets, and you will see your new secret, as shown in Figure 3. Select the new secret.

Figure 3: The new secret in the Secrets Manager console
- Choose Retrieve secret value to confirm that CERTIFICATE_PEM, PRIVATE_KEY_PEM, CERTIFICATE_CHAIN_PEM, and CERTIFICATE_ARN are set in the secret value.
You now have an ACM-issued certificate that can be deployed to an end entity.
Deploy to an end entity
For testing purposes, you will now deploy the certificate that you just created to an Apache Server.
To deploy the certificate to the Apache Server
- In a new tab, navigate to the Systems Manager console.
- Choose Documents at the bottom left, and then choose the Owned by me tab.
- Choose RunUpdateTLS.
- Choose Run command at the top right.
- Copy and paste the secret ARN from Secrets Manager and make sure there are no leading or trailing spaces.
- Select Choose instances manually, and then choose ApacheServer.
- Select CloudWatch output to track progress.
- Choose Run.
The certificate and private key are now installed on the server, and it has been restarted.
To verify that the certificate was installed
- Navigate to the EC2 console.
- In the dashboard, choose Running Instances.
- Select ApacheServer, and choose Connect.
- Select Session Manager, and choose Connect.
- When you’re logged in to the instance, enter the following command.
openssl s_client -connect localhost:443 | openssl x509 -text -noout
This will display the certificate that the server is using, along with other metadata like the certificate chain and validity period. For the validity period, note the Not Before and Not After dates and times, as shown in figure 4.

Figure 4: Server certificate
Now, test the rotation of the certificate manually. In a production scenario, this process would be automated by using maintenance windows. Maintenance windows allow for the least amount of disruption to the applications that are using certificates, because you can determine when the server will update its certificate.
To test the rotation of the certificate
- Navigate back to your secret in Secrets Manager.
- Choose Rotate secret immediately. Because you set the ENVIRONMENT key to TEST in the secret, this rotation will renew the certificate. When the key isn’t set to TEST, the rotation function pulls down the renewed certificate based on its rotation schedule, because ACM is managing the renewal for you. In a couple of minutes, you’ll receive an email from ACM stating that your certificate was rotated.
- Pull the renewed certificate down to the server, following the same steps that you used to deploy the certificate to the Apache Server.
- Follow the steps that you used to verify that the certificate was installed to make sure that the validity date and time has changed.
Use case #2: Create and deploy an ACM PCA certificate by using custom templates
Next, use the second CloudFormation template to create a certificate, issued by ACM PCA, which will be deployed to an Apache Server in a different account. Sign in to your other account and select the following Launch Stack button to launch the CloudFormation template.
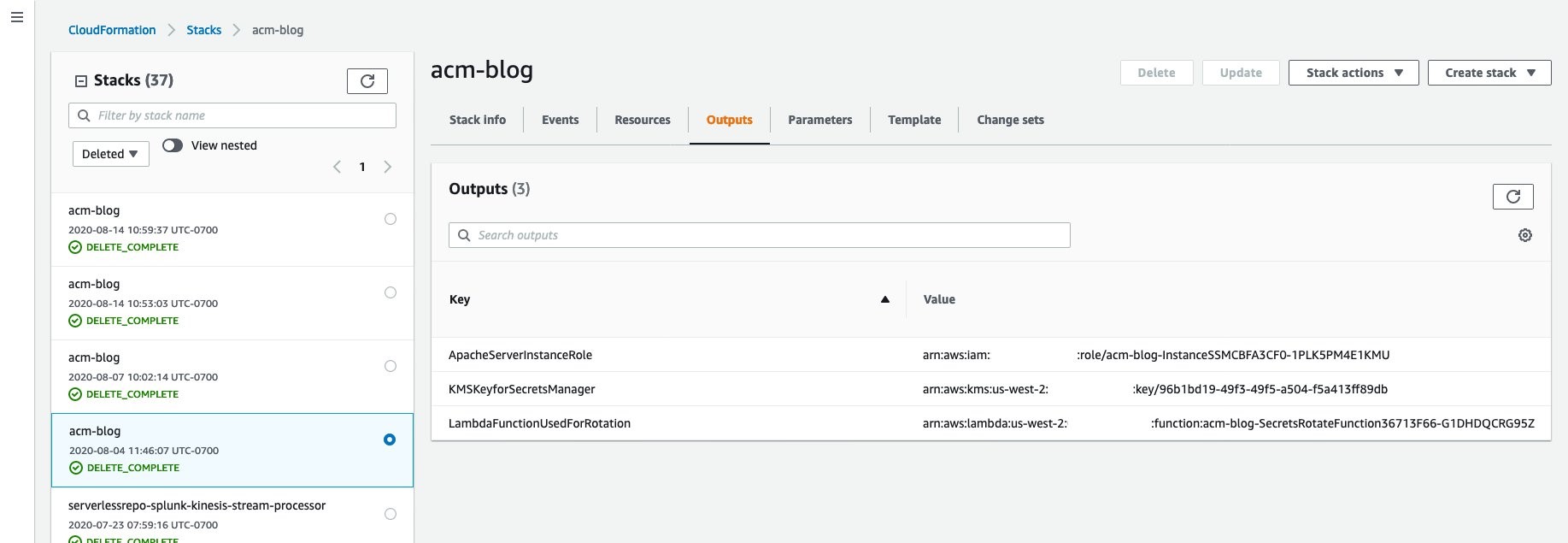
This creates the same Run Command document you used previously, as well as the EC2 and Amazon VPC environment running an Apache Server. This template takes in a parameter for the KMS key ARN; this can be found in the first template’s output section, shown in figure 5.

Figure 5: CloudFormation outputs
While that’s completing, sign in to your original account so that you can create the new secret.
To create the new secret
- Follow the same steps you used to create a secret, but change the secret values passed in to the following.
| Key |
Value |
| CA_ARN |
The ARN of your certificate-issuing CA in ACM PCA |
| COMMON_NAME |
You can use any name you want, such as server2.example |
| TEMPLATE_ARN |
For testing purposes, use arn:aws:acm-pca:::template/EndEntityCertificate/V1
This template ARN determines what type of certificate is being created and your desired path length. For more information, see Understanding Certificate Templates.
|
| KEY_ALGORITHM |
TYPE_RSA
(You can also use TYPE_DSA) |
| KEY_SIZE |
2048
(You can also use 1024 or 4096) |
| SIGNING_HASH |
sha256
(You can also use sha384 or sha512) |
| SIGNING_ALGORITHM |
RSA
(You can also use ECDSA if the key type for your issuing CA is set to ECDSA P256 or ECDSA P384) |
| CERTIFICATE_TYPE |
ACM_PCA_ISSUED |
- Add the following resource policy during the name and description step. This gives your other account access to pull this secret down to install the certificate on its Apache Server.
{
"Version" : "2012-10-17",
"Statement" : [ {
"Effect" : "Allow",
"Principal" : {
"AWS" : "<ARN in output of second CloudFormation Template>"
},
"Action" : "secretsmanager:GetSecretValue",
"Resource" : "*"
} ]
}
- Finish creating the secret.
After the secret has been created, the last thing you need to do is add permissions to the KMS key policy so that your other account can decrypt the secret when installing the certificate on your server.
To add AWS KMS permissions
- Navigate to the AWS KMS console, and choose CAKey.
- Next to the key policy name, choose Edit.
- For the Statement ID (SID) Allow use of the key, add the ARN of the EC2 instance role in the other account. This can be found in the CloudFormation templates as an output called ApacheServerInstanceRole, as shown in Figure 5. The Statement should look something like this:
{
"Sid": "Allow use of the key",
"Effect": "Allow",
"Principal": {
"AWS": [
"arn:aws:iam::<AccountID with CA>:role/<Apache Server Instance Role>",
"arn:aws:iam:<Second AccountID>:role/<Apache Server Instance Role>"
]
},
"Action": [
"kms:Encrypt",
"kms:Decrypt",
"kms:ReEncrypt*",
"kms:GenerateDataKey*",
"kms:DescribeKey"
],
"Resource": "*"
}
Your second account now has permissions to pull down the secret and certificate to the Apache Server. Follow the same steps described in the earlier section, “Deploy to an end entity.” Test rotating the secret the same way, and make sure the validity period has changed. You may notice that you didn’t get an email notifying you of renewal. This is because the certificate isn’t issued by ACM.
In this demonstration, you may have noticed you didn’t create resources that pull down the secret in different Regions, just in different accounts. If you want to deploy certificates in different Regions from the one where you create the secret, the process is exactly the same as what we described here. You don’t need to do anything else to accomplish provisioning and deploying in different Regions.
Clean up resources
Finally, delete the resources you created in the earlier steps, in order to avoid additional charges described in the section, “Solution cost.”
To delete all the resources created:
- Navigate to the CloudFormation console in both accounts, and select the stack that you created.
- Choose Actions, and then choose Delete Stack. This will take a few minutes to complete.
- Navigate to the Secrets Manager console in the CA account, and select the secrets you created.
- Choose Actions, and then choose Delete secret. This won’t automatically delete the secret, because you need to set a waiting period that allows for the secret to be restored, if needed. The minimum time is 7 days.
- Navigate to the Certificate Manager console in the CA account.
- Select the certificates that were created as part of this blog walkthrough, choose Actions, and then choose Delete.
- Choose Private CAs.
- Select the subordinate CA you created at the beginning of this process, choose Actions, and then choose Disable.
- After the CA is disabled, choose Actions, and then Delete. Similar to the secrets, this doesn’t automatically delete the CA but marks it for deletion, and the CA can be recovered during the specified period. The minimum waiting period is also 7 days.
Conclusion
In this blog post, we demonstrated how you could use Secrets Manager to rotate, store, and distribute private certificates issued by ACM and ACM PCA to end entities. Secrets Manager uses AWS KMS to secure these secrets during storage and delivery. You can introduce additional automation for deploying the certificates by using Systems Manager Maintenance Windows. This allows you to define a schedule for when to deploy potentially disruptive changes to EC2 instances.
If you have feedback about this post, submit comments in the Comments section below. If you have questions about this post, start a new thread on the AWS Secrets Manager forum or contact AWS Support.
Want more AWS Security how-to content, news, and feature announcements? Follow us on Twitter.