By Akshay Sarma, Principal Engineer, Verizon Media & Brian Xiao, Software Engineer, Verizon Media
This is the first of an ongoing series of blog posts sharing releases and announcements for Bullet, an open-sourced lightweight, scalable, pluggable, multi-tenant query system.
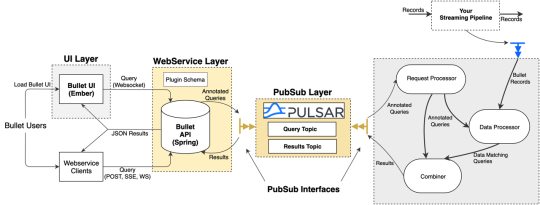
Bullet allows you to query any data flowing through a streaming system without having to store it first through its UI or API. The queries are injected into the running system and have minimal overhead. Running hundreds of queries generally fit into the overhead of just reading the streaming data. Bullet requires running an instance of its backend on your data. This backend runs on common stream processing frameworks (Storm and Spark Streaming currently supported).
The data on which Bullet sits determines what it is used for. For example, our team runs an instance of Bullet on user engagement data (~1M events/sec) to let developers find their own events to validate their code that produces this data. We also use this instance to interactively explore data, throw up quick dashboards to monitor live releases, count unique users, debug issues, and more.
Since open sourcing Bullet in 2017, we’ve been hard at work adding many new features! We’ll highlight some of these here and continue sharing update posts for future releases.
Windowing
Bullet used to operate in a request-response fashion – you would submit a query and wait for the query to meet its termination conditions (usually duration) before receiving results. For short-lived queries, say, a few seconds, this was fine. But as we started fielding more interactive and iterative queries, waiting even a minute for results became too cumbersome.
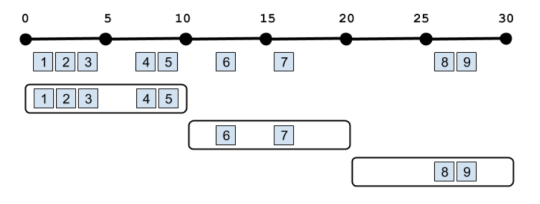
Enter windowing! Bullet now supports time and record-based windowing. With time windowing, you can break up your query into chunks of time over its duration and retrieve results for each chunk. For example, you can calculate the average of a field, and stream back results every second:
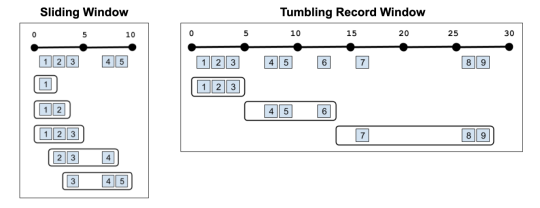
In the above example, the aggregation is operating on all the data since the beginning of the query, but you can also do aggregations on just the windows themselves. This is often called a Tumbling window:
With record windowing, you can get the intermediate aggregation for each record that matches your query (a Sliding window). Or you can do a Tumbling window on records rather than time. For example, you could get results back every three records:
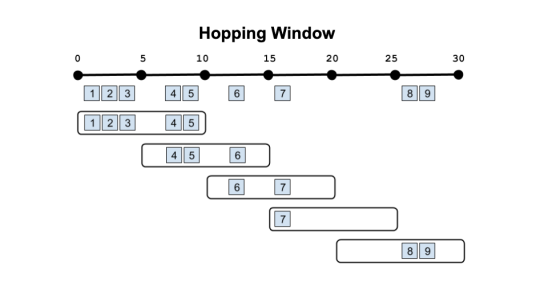
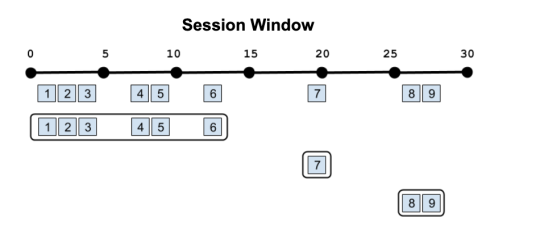
Overlapping windows in other ways (Hopping windows) or windows that reset based on different criteria (Session windows, Cascading windows) are currently being worked on. Stay tuned!
Apache Pulsar support as a native PubSub
Bullet uses a PubSub (publish-subscribe) message queue to send queries and results between the Web Service and Backend. As with everything else in Bullet, the PubSub is pluggable. You can use your favorite pubsub by implementing a few interfaces if you don’t want to use the ones we provide. Until now, we’ve maintained and supported a REST-based PubSub and an Apache Kafka PubSub. Now we are excited to announce supporting Apache Pulsar as well! Bullet Pulsar will be useful to those users who want to use Pulsar as their underlying messaging service.
If you aren’t familiar with Pulsar, setting up a local standalone is very simple, and by default, any Pulsar topics written to will automatically be created. Setting up an instance of Bullet with Pulsar instead of REST or Kafka is just as easy. You can refer to our documentation for more details.
Plug your data into Bullet without code
While Bullet worked on any data source located in any persistence layer, you still had to implement an interface to connect your data source to the Backend and convert it into a record container format that Bullet understands. For instance, your data might be located in Kafka and be in the Avro format. If you were using Bullet on Storm, you would perhaps write a Storm Spout to read from Kafka, deserialize, and convert the Avro data into the Bullet record format. This was the only interface in Bullet that required our customers to write their own code. Not anymore! Bullet DSL is a text/configuration-based format for users to plug in their data to the Bullet Backend without having to write a single line of code.
Bullet DSL abstracts away the two major components for plugging data into the Bullet Backend. A Connector piece to read from arbitrary data-sources and a Converter piece to convert that read data into the Bullet record container. We currently support and maintain a few of these – Kafka and Pulsar for Connectors and Avro, Maps and arbitrary Java POJOs for Converters. The Converters understand typed data and can even do a bit of minor ETL (Extract, Transform and Load) if you need to change your data around before feeding it into Bullet. As always, the DSL components are pluggable and you can write your own (and contribute it back!) if you need one that we don’t support.
We appreciate your feedback and contributions! Explore Bullet on GitHub, use and help contribute to the project, and chat with us on Google Groups. To get started, try our Quickstarts on Spark or Storm to set up an instance of Bullet on some fake data and play around with it.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.