Post Syndicated from Julian Wood original https://aws.amazon.com/blogs/compute/introducing-aws-lambda-native-support-for-avro-and-protobuf-formatted-apache-kafka-events/
AWS Lambda now provides native support for Apache Avro and Protocol Buffers (Protobuf) formatted events with Apache Kafka event source mapping (ESM) when using Provisioned Mode. The support allows you to validate your schema with popular schema registries. This allows you to use and filter the more efficient binary event formats and share data using schema in a centralized and consistent way. This blog post shows how you can use Lambda to process Avro and Protobuf formatted events from Kafka topics using schema registry integration.
This new capability works with both Amazon Managed Streaming for Apache Kafka (Amazon MSK), Confluent Cloud and self-managed Kafka clusters. To get started, update your existing Kafka ESM to Provisioned Mode and add schema registry configuration, or create a new ESM in Provisioned Mode with schema registry integration enabled.
Avro and Protobuf
Many organizations use Avro and Protobuf formats with Apache Kafka because these binary serialization formats offer advantages over JSON. They provide 50-80% smaller message sizes, faster serialization and deserialization performance, robust schema evolution capabilities, and strong typing across multiple programming languages.Working with these formats in Lambda functions previously necessitated custom code. Developers needed to implement schema registry clients, handle authentication and caching, write format-specific deserialization logic, and manage schema evolution scenarios.
What’s new
Lambda’s Kafka Event Source Mapping (ESM) now provides built-in integration with AWS Glue Schema Registry, Confluent Cloud Schema Registry, and self-managed Confluent Schema Registry. When you configure schema registry settings for your Kafka ESM, the service automatically validates incoming JSON Schema, Avro, and Protobuf records against their registered schema. This moves complex schema registry integration logic from your application layer to the managed Lambda service.
You can build your function with Kafka’s open-source ConsumerRecords interface using Powertools for AWS Lambda to get your Avro or Protobuf generated business objects directly. Optionally you can specify to get your records in the JSON format, where your function receives clean, validated JSON data regardless of the original serialization format, removing the need for custom deserialization code in your Lambda functions. This also allows you to create Kafka consumers across multiple programming languages.
Powertools for AWS Lambda is a developer toolkit that provides specific support for Java, .NET, Python, and TypeScript, maintaining consistency with existing Kafka development patterns. You can directly access business objects without custom deserialization code.
You can also setup filtering rules to discard irrelevant, JSON, Avro or Protobuf formatted events before function invocations, which can improve processing performance and reduce costs.
How schema validation works
When you configure schema registry integration for your Kafka ESM, you specify the registry endpoint, authentication details, and which event fields (key, value, or both) to validate. The ESM polls your Kafka topics for records as usual but now performs additional processing before invoking your Lambda function.For each incoming event, the ESM extracts the schema ID embedded in the serialized data. It fetches the corresponding schema from your configured registry. This process happens transparently, with schema definitions cached for up to 24 hours to optimize performance. The ESM identifies the format of your events using schema metadata and validates the event structure. It keeps either the original binary data or deserializes it to JSON format based on your customer configuration and sends it to your function for processing.

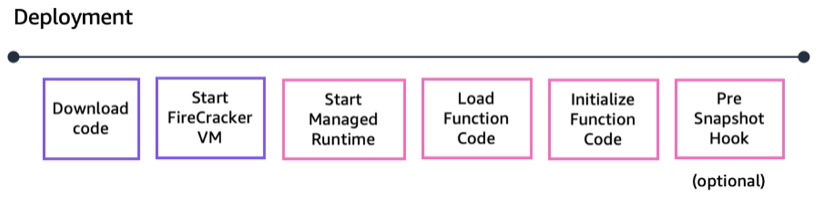
Figure 1: Kafka processing flow diagram.
The ESM handles schema evolution automatically. When producers begin using new schema versions, the service detects the updated schema IDs and fetches the latest definitions from your registry. This makes sure that your functions always receive properly deserialized data without requiring code changes.
Event record format
As a part of the ESM schema registry configuration, you need to specify Event Record Format, which Lambda uses to deliver validated records to your function. The schema registry configuration supports SOURCE and JSON.
SOURCE preserves the original binary format of the data as a base64-encoded string with producer-appended schema-id removed. This allows direct conversion to Avro or Protobuf objects so that you can use Kafka’s ConsumerRecords interface for a Kafka-like experience. Use this format when working with strongly typed languages or when you need to maintain the full capabilities of Avro or Protobuf schemas. Then, you can use any Avro or Protobuf deserializer to convert raw bytes to your business object. Powertools provides native support for this deserialization.
With JSON, the ESM deserializes the data ready for direct use in languages with native JSON support. Use this when you don’t need to preserve the original binary format or work with generated classes. You can also use Powertools to convert the base64 to your business object. See the documentation for payload formats and deserialization behavior.
If you configure filtering rules, then they operate on the JSON-formatted events after deserialization. This upstream filtering prevents unnecessary Lambda invocations for events that don’t match your processing criteria, directly reducing your compute costs.
Configuration and setup
To use this feature, you must enable Provisioned Mode for your Kafka ESM, which provides the dedicated compute resources needed for schema registry integration.
You can configure the integration through the AWS Management Console, AWS Command Line Interface (AWS CLI), AWS Language SDKs, or infrastructure as code (IaC) tools such as the AWS Serverless Application Model (AWS SAM) or AWS Cloud Development Kit (AWS CDK).
Your schema registry configuration includes the registry endpoint URL, authentication method (AWS Identity and Access Management (IAM) for AWS Glue Schema Registry, or Basic Auth, SASL/SCRAM, or mTLS for Confluent registries), and validation settings. You specify which event attributes to validate and optionally define filtering rules using standard Lambda event filtering syntax.
For error handling, configure Lambda failure destinations where events that fail schema validation or deserialization are sent. This makes sure that problematic events don’t disappear silently but are routed to other services such as Amazon Simple Queue Service (Amazon SQS), Amazon Simple Notification Service (Amazon SNS), and Amazon S3 for debugging and analysis.
Seeing the new features in action
There are a number of Serverless Patterns that you can use to process Kafka streams using Lambda. This example uses the Java pattern.
Deploy a sample Amazon MSK cluster
To set up an Amazon MSK cluster, follow the instructions in the GitHub repo and create a new AWS CloudFormation stack using the MSKAndKafkaClientEC2.yaml template file. The stack creates the Amazon MSK cluster, along with a client Amazon EC2 instance, to manage the Kafka cluster. There are costs involved when running this infrastructure.
- Connect to the EC2 instance using EC2 Instance Connect.
- Check that the Kafka topic is created by checking the contents of the
kafka_topic_creator_output.txtfile. - The file should contain the text: “Created topic MskIamJavaLambdaTopic.”
Deploy the Glue schema registry and consumer Lambda function
The EC2 instance contains the software needed to deploy the schema registry and Lambda function.
- Change directory to the pattern directory.
cd serverless-patterns/msk-lambda-iam-java-sam - Build the application using AWS SAM.
sam build - To deploy your application for the first time, run the following in the EC2 instance shell:
- You can accept all the defaults by hitting Enter. You can browse to the AWS Glue schema registry console and view the ContactSchema definition:
The consumer Lambda function ESM is configured for Provisioned Mode.
- View the ESM configuration from the Lambda console for the Lambda function name prefixed with msk-lambda-schema-avro-ja-LambdaMSKConsumer.
- Choose the MSK Lambda trigger which opens the Triggers pane under Configuration.

Figure 2: View Lambda ESM schema configuration - The configuration specifies using the Event record format
SOURCEso your function can use Kafka’s native open-sourceConsumerRecordsinterface. Powertools then deserializes the payload. - The schema validation attribute is
VALUE. - The ESM filter configuration only processes the records that match zip codes of 2000.
- In your function code, specify the open-source Kafka
ConsumersRecordsinterface by including Powertools for Lambda as a dependency.ConsumerRecordsprovides metadata about Kafka records and allows you to get direct access to your Avro/Protobuf generated business objects without requiring any additional deserialization code.

To send messages to Kafka, there is a LambdaMSKProducerJava function.
- Invoke the function from the Lambda console or CLI within the EC2 instance.
- You can view the Producer logs to see the 10 records produced.The consumer Lambda function processes the records.
- View the consumer Lambda function logs using the Amazon CloudWatch logs console or CLI within the EC2 instance.
The Lambda function processes and logs only the records that match the filter FILTER. The Avro binary data is deserialized using Powertools for AWS Lambda. You should see the function logs showing each record processed with the decoded keys and values.

Figure 3: Lambda consumer logs showing Avro processing
Cleaning up
You can clean up the example Lambda function by running the sam delete command.
If you created the Amazon MSK cluster and EC2 client instance, then navigate to the CloudFormation console, choose the stack, and choose Delete.
Performance and cost considerations
Schema validation and deserialization can add processing time before your function invocation. However, this overhead is typically minimal when compared to the benefits. ESM caching minimizes schema registry API calls. Using filtering allows you to reduce costs, depending on how effectively your filtering rules eliminate irrelevant events. This feature simplifies the operational overhead of managing schema registry integration code so teams can focus on business logic rather than infrastructure concerns.
Error handling and monitoring
If schema registries become temporarily unavailable, then cached schemas allow event processing to continue until the registry is available again. Authentication failures generate error messages with automatic retry logic. Schema evolution happens seamlessly as Lambda automatically detects and fetches new versions.
If events fail validation or deserialization, they are routed to your configured failure destinations. For Amazon SQS and Amazon SNS destinations, the service sends metadata about the failure. For Amazon S3 destinations, both metadata and the original serialized payload are included for detailed analysis.
You can use standard Lambda monitoring, with more CloudWatch metrics providing visibility into schema validation success rates, registry API usage, and filtering effectiveness.
Conclusion
AWS Lambda now supports Avro and Protobuf formats for Kafka event processing in Provisioned Mode for Kafka ESM. This enables schema validation, event filtering, and integration with both Amazon MSK, Confluent, and self-managed Kafka clusters. Whether you’re building new Kafka applications or migrating existing consumers to Lambda, this native schema registry integration streamlines processing pipelines.
For more information about the Lambda Kafka integration capabilities, go to the learning guide, Lambda ESM documentation. To learn about Lambda pricing, such as Provisioned Mode costs, visit the Lambda pricing page.
For more serverless learning resources, visit Serverless Land.

 Fig 2: part of pom.xml changes after dependency upgrades
Fig 2: part of pom.xml changes after dependency upgrades



















































 Jonathan Vogel
Jonathan Vogel Venugopalan Vasudevan
Venugopalan Vasudevan