Post Syndicated from Filip Saina original https://aws.amazon.com/blogs/devops/deep-learning-image-vector-embeddings-at-scale-using-aws-batch-and-cdk/
Applying various transformations to images at scale is an easily parallelized and scaled task. As a Computer Vision research team at Amazon, we occasionally find that the amount of image data we are dealing with can’t be effectively computed on a single machine, but also isn’t large enough to justify running a large and potentially costly AWS Elastic Map Reduce (EMR) job. This is when we can utilize AWS Batch as our main computing environment, as well as Cloud Development Kit (CDK) to provision the necessary infrastructure in order to solve our task.
In Computer Vision, we often need to represent images in a more concise and uniform way. Working with standard image files would be challenging, as they can vary in resolution or are otherwise too large in terms of dimensionality to be provided directly to our models. For that reason, the common practice for deep learning approaches is to translate high-dimensional information representations, such as images, into vectors that encode most (if not all) information present in them — in other words, to create vector embeddings.
This post will demonstrate how we utilize the AWS Batch platform to solve a common task in many Computer Vision projects — calculating vector embeddings from a set of images so as to allow for scaling.
Architecture Overview

Figure 1: High-level architectural diagram explaining the major solution components.
As seen in Figure 1, AWS Batch will pull the docker image containing our code onto provisioned hosts and start the docker containers. Our sample code, referenced in this post, will then read the resources from S3, conduct the vectorization, and write the results as entries in the DynamoDB Table.
In order to run our image vectorization task, we will utilize the following AWS cloud components:
- Amazon ECR — Elastic Container Registry is a Docker image repository from which our batch instances will pull the job images;
- S3 — Amazon Simple Storage Service will act as our image source from which our batch jobs will read the image;
- Amazon DynamoDB — NoSQL database in which we will write the resulting vectors and other metadata;
- AWS Lambda — Serverless compute environment which will conduct some pre-processing and, ultimately, trigger the batch job execution; and
- AWS Batch — Scalable computing environment powering our models as embarrassingly parallel tasks running as AWS Batch jobs.
To translate an image to a vector, we can utilize a pre-trained model architecture, such as AlexNet, ResNet, VGG, or more recent ones, like ResNeXt and Vision Transformers. These model architectures are available in most of the popular deep learning frameworks, and they can be further modified and extended depending on our project requirements. For this post, we will utilize a pre-trained ResNet18 model from MxNet. We will output an intermediate layer of the model, which will result in a 512 dimensional representation, or, in other words, a 512 dimensional vector embedding.
Deployment using Cloud Development Kit (CDK)
In recent years, the idea of provisioning cloud infrastructure components using popular programming languages was popularized under the term of infrastructure as code (IaC). Instead of writing a file in the YAML/JSON/XML format, which would define every cloud component we want to provision, we might want to define those components trough a popular programming language.
As part of this post, we will demonstrate how easy it is to provision infrastructure on AWS cloud by using Cloud Development Kit (CDK). The CDK code included in the exercise is written in Python and defines all of the relevant exercise components.
Hands-on exercise
1. Deploying the infrastructure with AWS CDK
For this exercise, we have provided a sample batch job project that is available on Github (link). By using that code, you should have every component required to do this exercise, so make sure that you have the source on your machine. The root of your sample project local copy should contain the following files:
- Make sure you have installed and correctly configured the AWS CLI and AWS CDK in your environment. Refer to the CDK documentation for more information, as well as the CDK getting started guide.
- Set the
CDK_DEPLOY_ACCOUNTandCDK_DEPLOY_REGIONenvironmental variables, as described in the projectREADME.md. - Go to the sample project root and install the CDK python dependencies by running
pip install -r requirements.txt. - Install and configure Docker in your environment.
- If you have multiple AWS CLI profiles, utilize the
--profileoption to specify which profile to use for deployment. Otherwise, simply runcdk deployand deploy the infrastructure to your AWS account set in step 1.
NOTE: Before deploying, make sure that you are familiar with the restrictions and limitations of the AWS services we are using in this post. For example, if you choose to set an S3 bucket name in the CDK Bucket construct, you must avoid naming conflicts that might cause deployment errors.
The CDK tool will now trigger our docker image build, provision the necessary AWS infrastructure (i.e., S3 Bucket, DynamoDB table, roles and permissions), and, upon completion, upload the docker image to a newly created repository on Amazon Elastic Container Registry (ECR).
2. Upload data to S3
Figure 2: S3 console window with uploaded images to the `images` directory.
After CDK has successfully finished deploying, head to the S3 console screen and upload images you want to process to a path in the S3 bucket. For this exercise, we’ve added every image to the `images` directory, as seen in Figure 2.
For larger datasets, utilize the AWS CLI tool to sync your local directory with the S3 bucket. In that case, consider enabling the ‘Transfer acceleration’ option of your S3 bucket for faster data transfers. However, this will incur an additional fee.
3. Trigger batch job execution
Once CDK has completed provisioning our infrastructure and we’ve uploaded the image data we want to process, open the newly created AWS Lambda in the AWS console screen in order to trigger the batch job execution.
To do this, create a test event with the following JSON body:
The JSON body that we provide as input to the AWS Lambda function defines a list of paths to directories in the S3 buckets containing images. Having the ability to dynamically provide paths to directories with images in S3, lets us combine multiple data sources into a single AWS Batch job execution. Furthermore, if we decide in the future to put an API Gateway in front of the Lambda, you could pass every parameter of the batch job with a simple HTTP method call.
In this example, we specified just one path to the `images` directory in the S3 bucket, which we populated with images in the previous step.
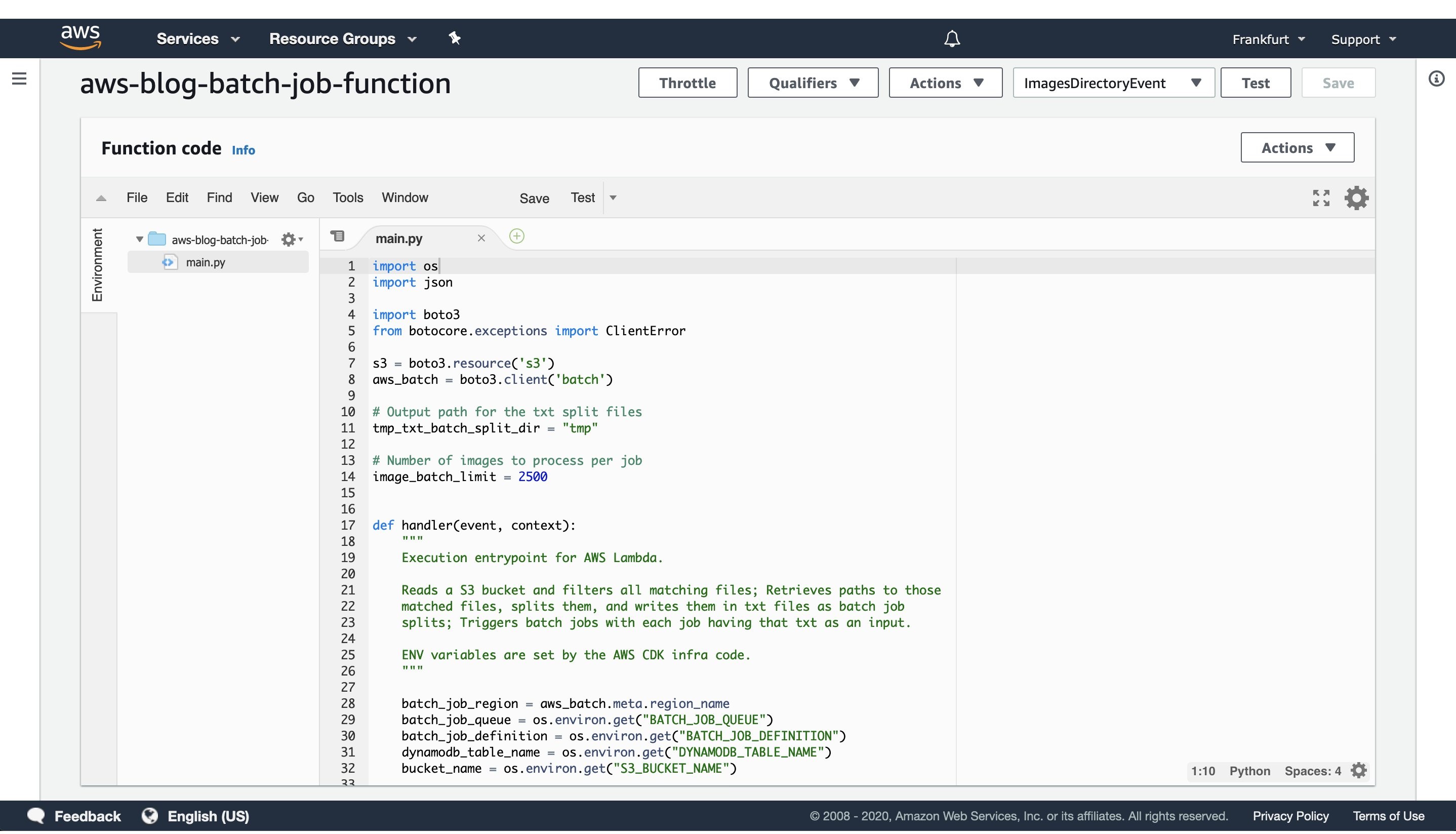
Figure 3: AWS Lambda console screen of the function that triggers batch job execution. Modify the batch size by modifying the `image_batch_limit` variable. The value of this variable will depend on your particular use-case, computation type, image sizes, as well as processing time requirements.
The python code will list every path under the images S3 path, batch them into batches of desired size, and finally save the paths to batches as txt files under tmp S3 path. Each path to a txt files in S3 will be passed as an input to a batch jobs.
Select the newly created event, and then trigger the Lambda function execution. The AWS Lambda function will submit the AWS Batch jobs to the provisioned AWS Batch compute environment.
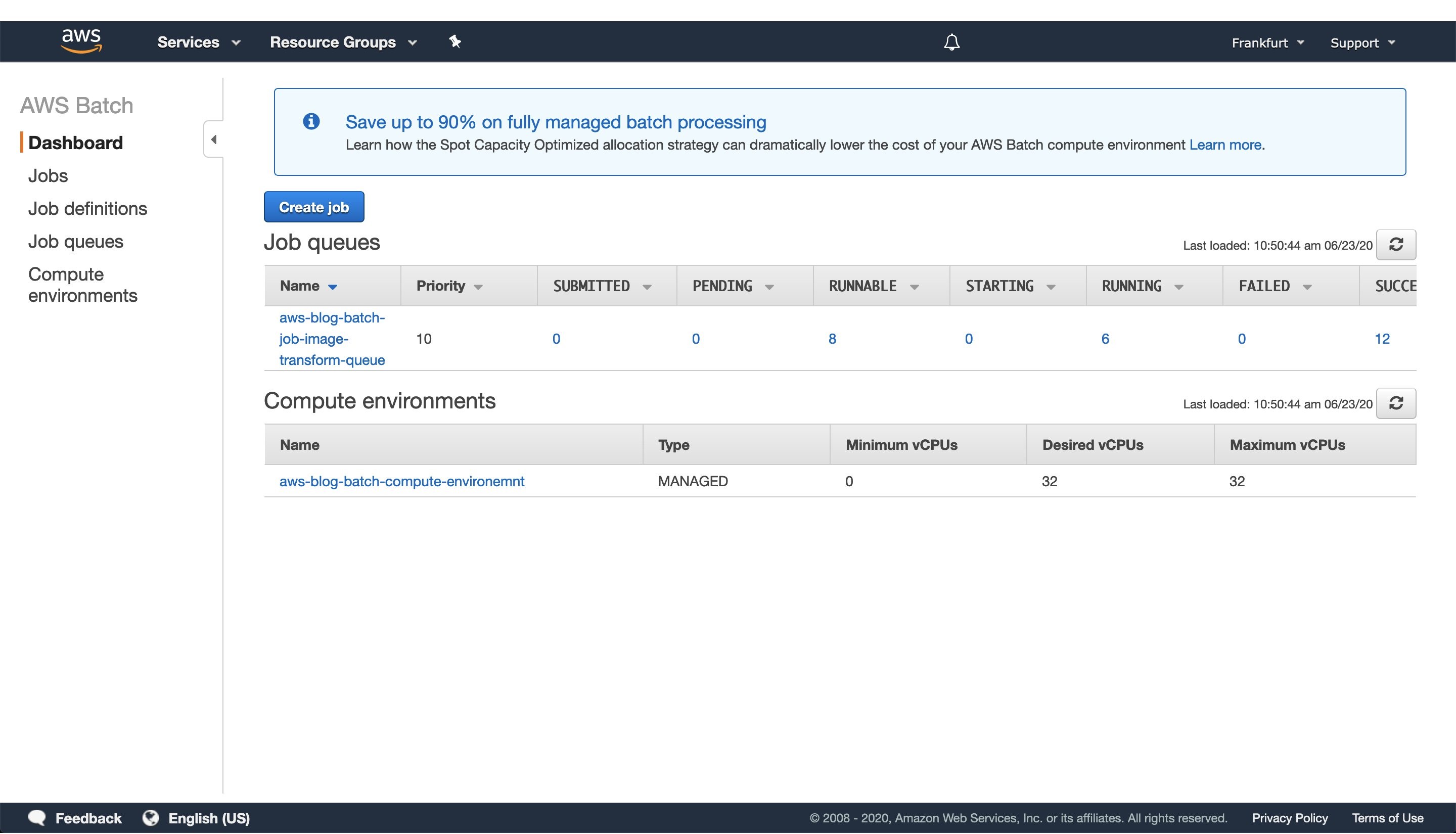
Figure 4: Screenshot of a running AWS Batch job that creates feature vectors from images and stores them to DynamoDB.
Once the AWS Lambda execution finishes its execution, we can monitor the AWS Batch jobs being processed on the AWS console screen, as seen in Figure 4. Wait until every job has finished successfully.
4. View results in DynamoDB
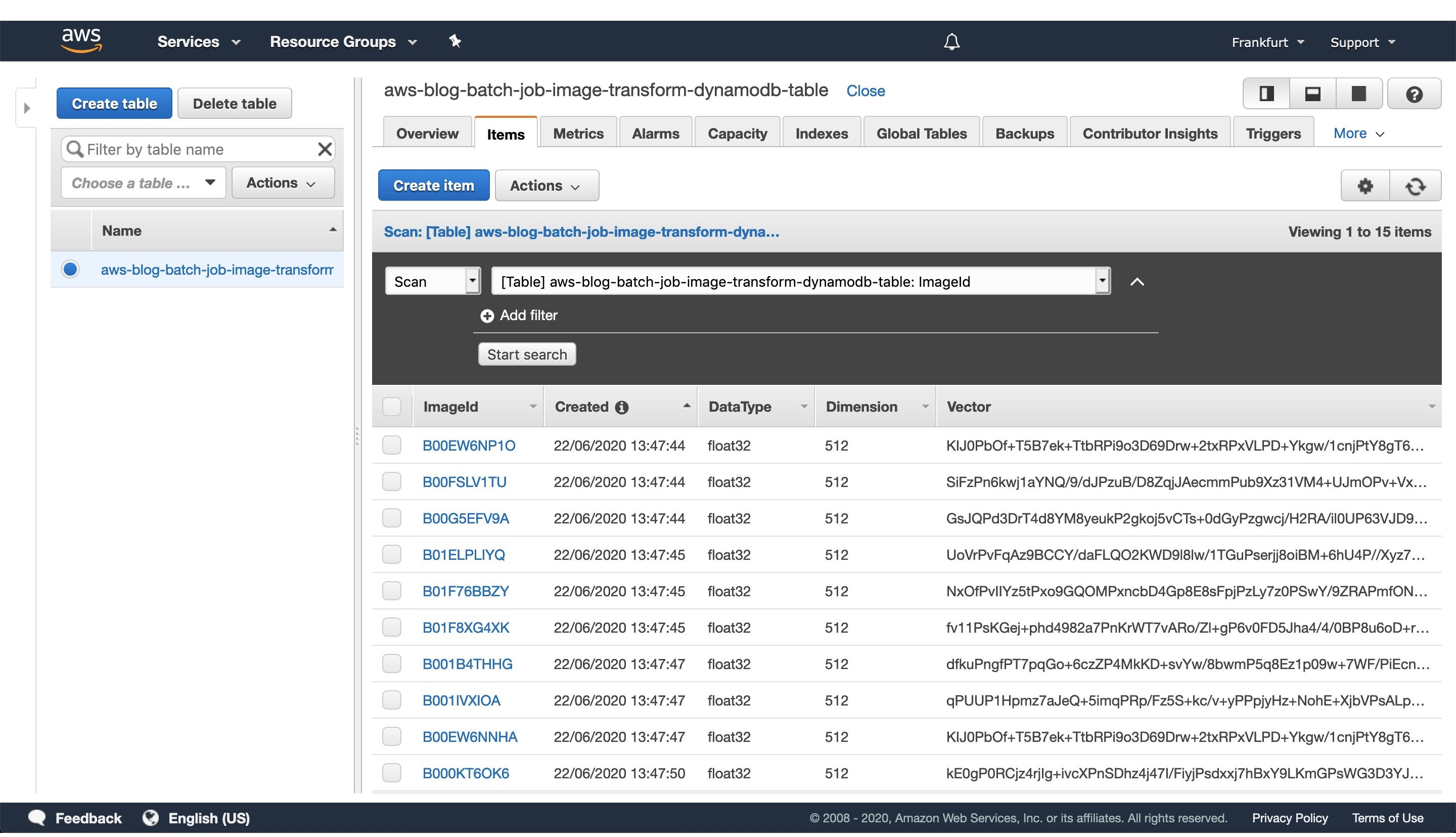
Figure 5: Image vectorization results stored for each image as a entry in the DynamoDB table.
Once every batch job is successfully finished, go to the DynamoDB AWS cloud console and see the feature vectors stored as strings obtained from the numpy tostring method, as well as other data we stored in the table.
When you are ready to access the vectors in one of your projects, utilize the code snippet provided here:
This code snippet will utilize the boto3 client to access the results stored in the DynamoDB table. Make sure to update the code variables, as well as to modify this implementation to one that fits your use-case.
5. Tear down the infrastructure using CDK
To finish off the exercise, we will tear down the infrastructure that we have provisioned. Since we are using CDK, this is very simple — go to the project root directory and run:
After a confirmation prompt, the infrastructure tear-down should be underway. If you want to follow the process in more detail, then go to the CloudFormation console view and monitor the process from there.
NOTE: The S3 Bucket, ECR image, and DynamoDB table resource will not be deleted, since the current CDK code defaults to RETAIN behavior in order to prevent the deletion of data we stored there. Once you are sure that you don’t need them, remove those remaining resources manually or modify the CDK code for desired behavior.
Conclusion
In this post we solved an embarrassingly parallel job of creating vector embeddings from images using AWS batch. We provisioned the infrastructure using Python CDK, uploaded sample images, submitted AWS batch job for execution, read the results from the DynamoDB table, and, finally, destroyed the AWS cloud resources we’ve provisioned at the beginning.
AWS Batch serves as a good compute environment for various jobs. For this one in particular, we can scale the processing to more compute resources with minimal or no modifications to our deep learning models and supporting code. On the other hand, it lets us potentially reduce costs by utilizing smaller compute resources and longer execution times.
The code serves as a good point for beginning to experiment more with AWS batch in a Deep Leaning/Machine Learning setup. You could extend it to utilize EC2 instances with GPUs instead of CPUs, utilize Spot instances instead of on-demand ones, utilize AWS Step Functions to automate process orchestration, utilize Amazon SQS as a mechanism to distribute the workload, as well as move the lambda job submission to another compute resource, or pretty much tailor your project for anything else you might need AWS Batch to do.
And that brings us to the conclusion of this post. Thanks for reading, and feel free to leave a comment below if you have any questions. Also, if you enjoyed reading this post, make sure to share it with your friends and colleagues!