Post Syndicated from Grab Tech original https://engineering.grab.com/zero-trust-with-kafka
Introduction
Grab’s real-time data platform team, also known as Coban, has been operating large-scale Kafka clusters for all Grab verticals, with a strong focus on ensuring a best-in-class-performance and 99.99% availability.
Security has always been one of Grab’s top priorities and as fraudsters continue to evolve, there is an increased need to continue strengthening the security of our data streaming platform. One of the ways of doing this is to move from a pure network-based access control to state-of-the-art security and zero trust by default, such as:
- Authentication: The identity of any remote systems – clients and servers – is established and ascertained first, prior to any further communications.
- Authorisation: Access to Kafka is granted based on the principle of least privilege; no access is given by default. Kafka clients are associated with the whitelisted Kafka topics and permissions – consume or produce – they strictly need. Also, granted access is auditable.
- Confidentiality: All in-transit traffic is encrypted.
Solution
We decided to use mutual Transport Layer Security (mTLS) for authentication and encryption. mTLS enables clients to authenticate servers, and servers to reciprocally authenticate clients.
Kafka supports other authentication mechanisms, like OAuth, or Salted Challenge Response Authentication Mechanism (SCRAM), but we chose mTLS because it is able to verify the peer’s identity offline. This verification ability means that systems do not need an active connection to an authentication server to ascertain the identity of a peer. This enables operating in disparate network environments, where all parties do not necessarily have access to such a central authority.
We opted for Hashicorp Vault and its PKI engine to dynamically generate clients and servers’ certificates. This enables us to enforce the usage of short-lived certificates for clients, which is a way to mitigate the potential impact of a client certificate being compromised or maliciously shared. We said zero trust, right?
For authorisation, we chose Policy-Based Access Control (PBAC), a more scalable solution than Role-Based Access Control (RBAC), and the Open Policy Agent (OPA) as our policy engine, for its wide community support.
To integrate mTLS and the OPA with Kafka, we leveraged Strimzi, the Kafka on Kubernetes operator. In a previous article, we have alluded to Strimzi and hinted at how it would help with scalability and cloud agnosticism. Built-in security is undoubtedly an additional driver of our adoption of Strimzi.
Server authentication
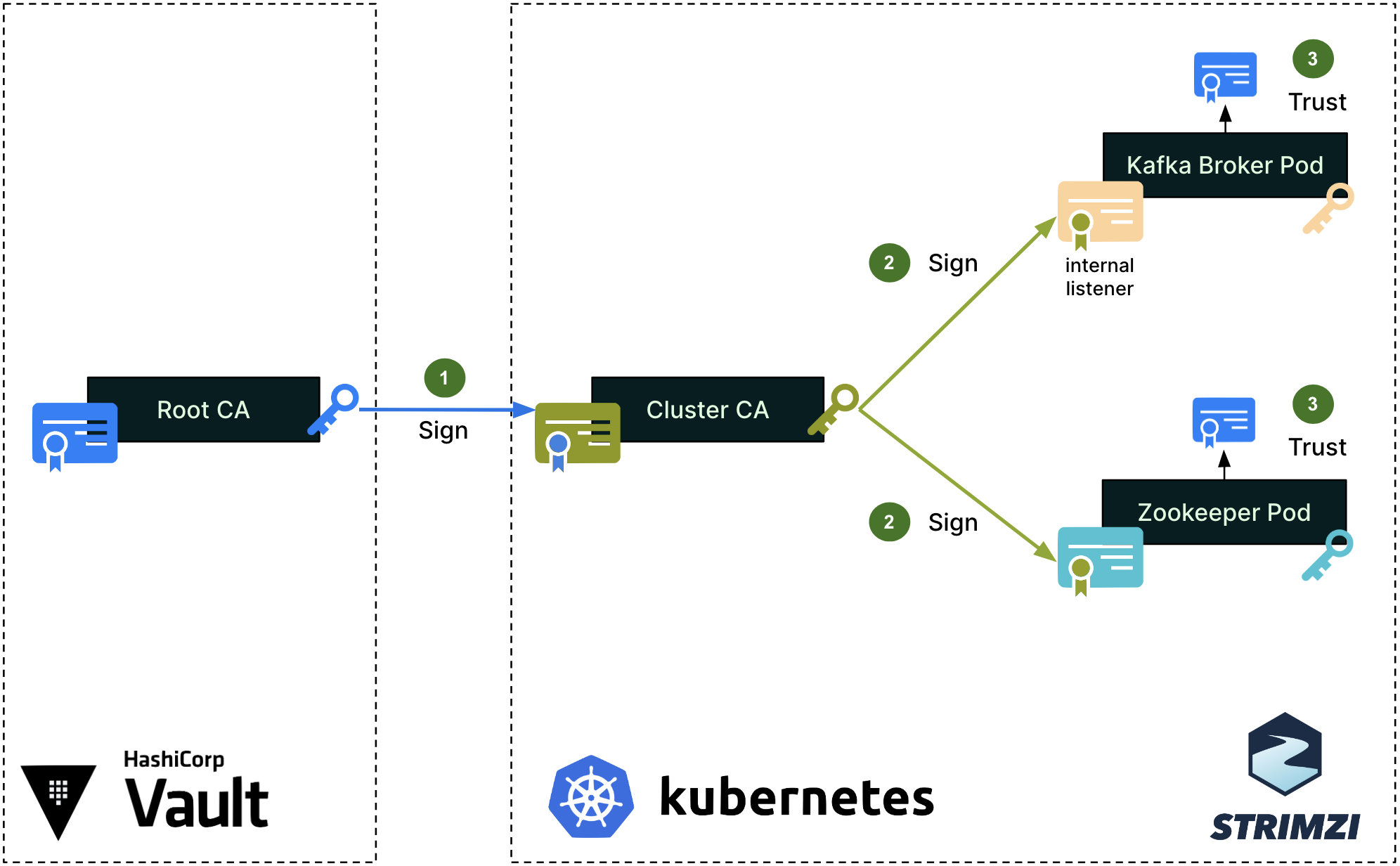
We first set up a single Root Certificate Authority (CA) for each environment (staging, production, etc.). This Root CA, in blue on the diagram, is securely managed by the Hashicorp Vault cluster. Note that the color of the certificates, keys, signing arrows and signatures on the diagrams are consistent throughout this article.
To secure the cluster’s internal communications, like the communications between the Kafka broker and Zookeeper pods, Strimzi sets up a Cluster CA, which is signed by the Root CA (step 1). The Cluster CA is then used to sign the individual Kafka broker and zookeeper certificates (step 2). Lastly, the Root CA’s public certificate is imported into the truststores of both the Kafka broker and Zookeeper (step 3), so that all pods can mutually verify their certificates when authenticating one with the other.
Strimzi’s embedded Cluster CA dynamically generates valid individual certificates when spinning up new Kafka and Zookeeper pods. The signing operation (step 2) is handled automatically by Strimzi.
For client access to Kafka brokers, Strimzi creates a different set of intermediate CA and server certificates, as shown in the next diagram.
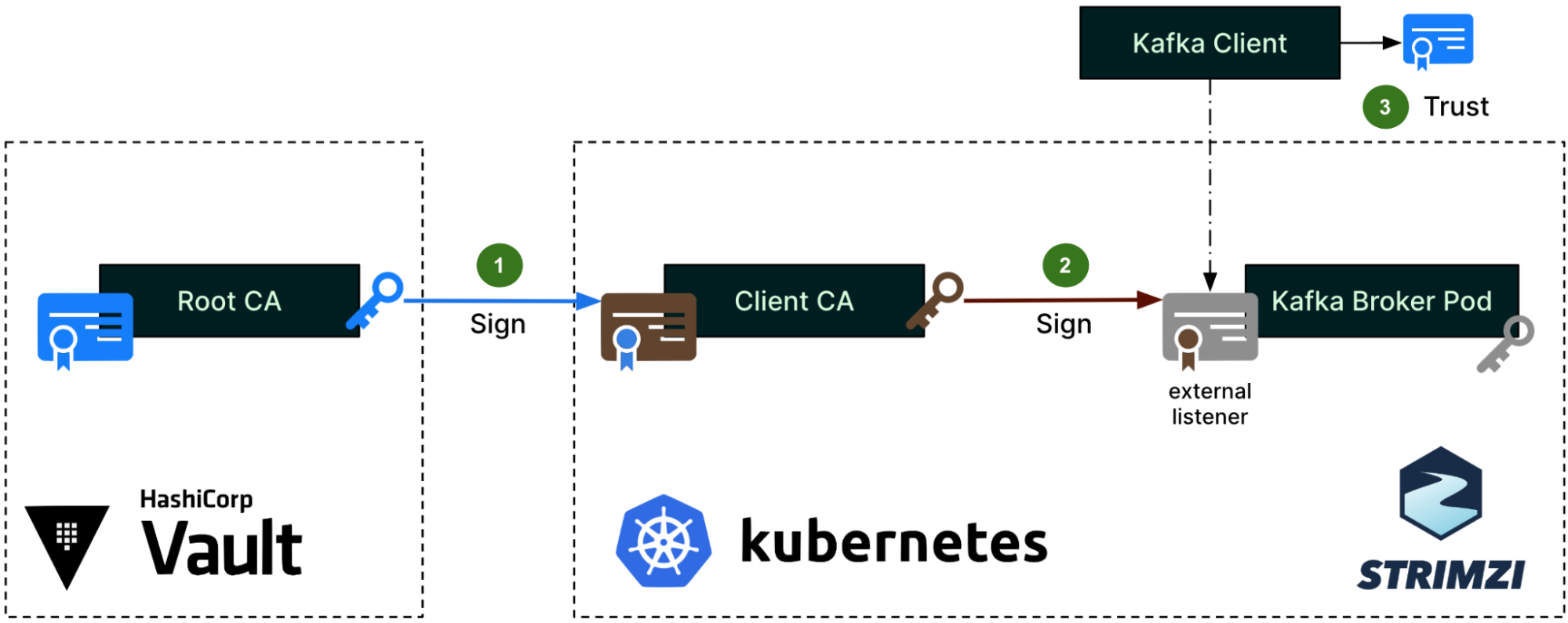
The same Root CA from Figure 1 now signs a different intermediate CA, which the Strimzi community calls the Client CA (step 1). This naming is misleading since it does not actually sign any client certificates, but only the server certificates (step 2) that are set up on the external listener of the Kafka brokers. These server certificates are for the Kafka clients to authenticate the servers. This time, the Root CA’s public certificate will be imported into the Kafka Client truststore (step 3).
Client authentication
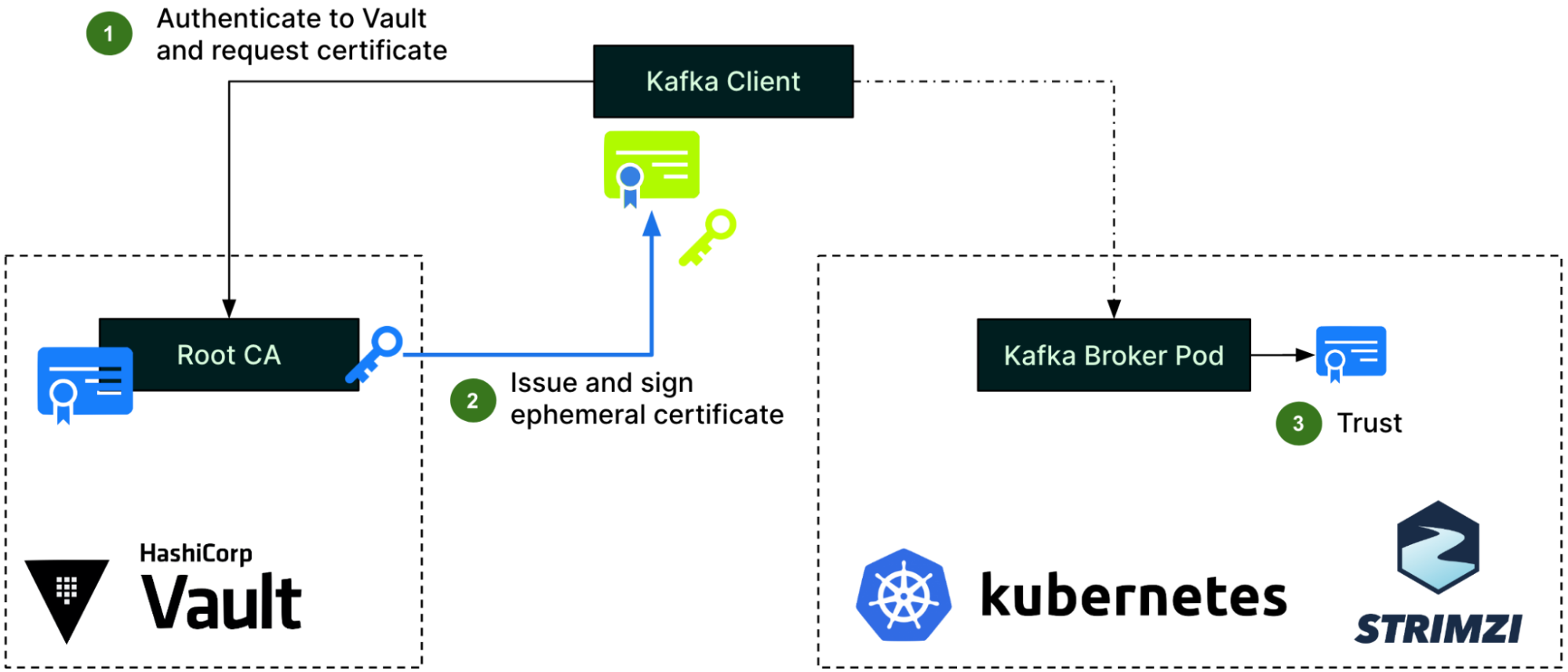
For client authentication, the Kafka client first needs to authenticate to Hashicorp Vault and request an ephemeral certificate from the Vault PKI engine (step 1). Vault then issues a certificate and signs it using its Root CA (step 2). With this certificate, the client can now authenticate to Kafka brokers, who will use the Root CA’s public certificate already in their truststore, as previously described (step 3).
CA tree
Putting together the three different authentication processes we have just covered, the CA tree now looks like this. Note that this is a simplified view for a single environment, a single cluster, and two clients only.
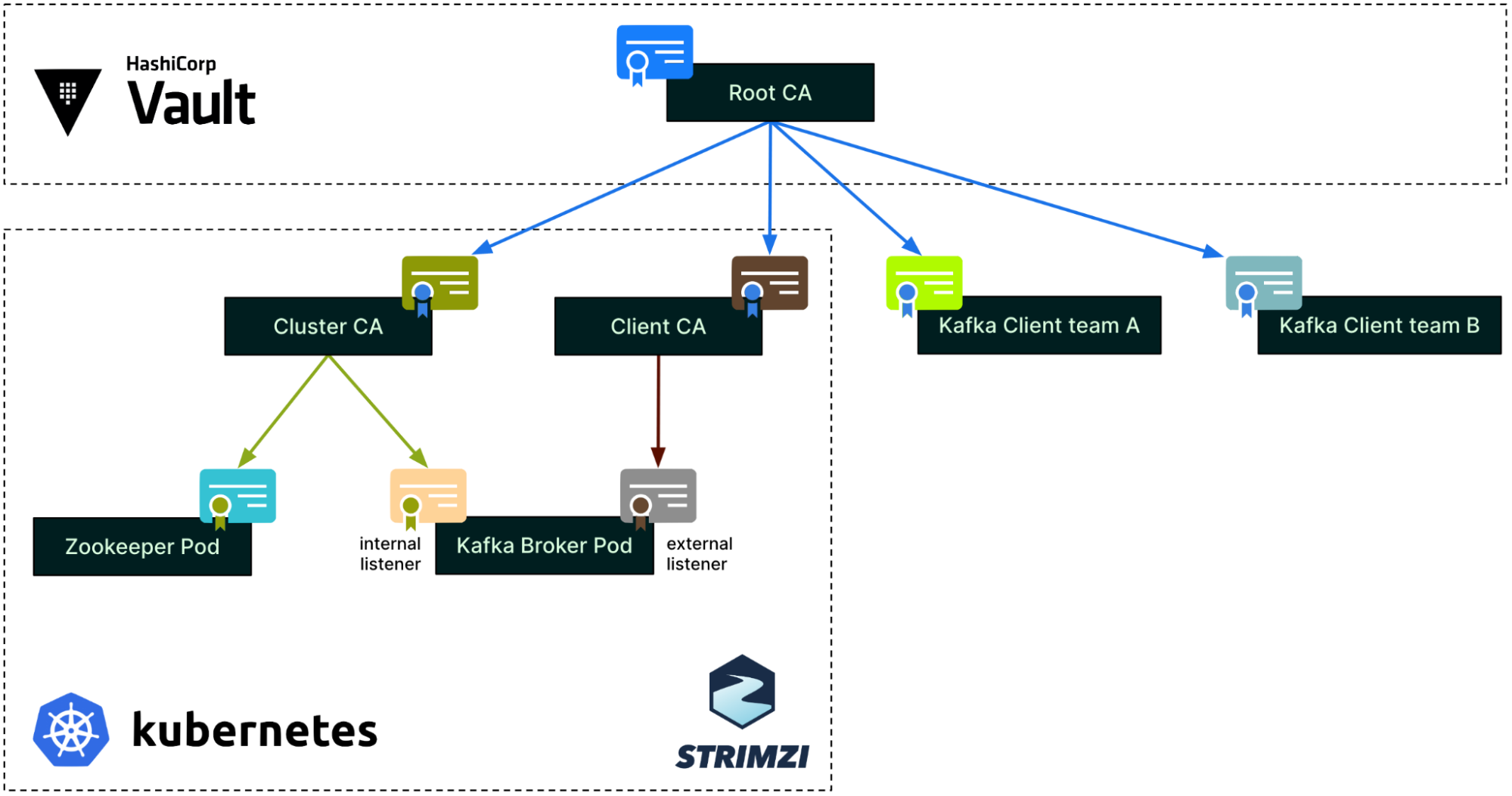
As mentioned earlier, each environment (staging, production, etc.) has its own Root CA. Within an environment, each Strimzi cluster has its own pair of intermediate CAs: the Cluster CA and the Client CA. At the leaf level, the Zookeeper and Kafka broker pods each have their own individual certificates.
On the right side of the diagram, each Kafka client can get an ephemeral certificate from Hashicorp Vault whenever they need to connect to Kafka. Each team or application has a dedicated Vault PKI role in Hashicorp Vault, restricting what can be requested for its certificate (e.g., Subject, TTL, etc.).
Strimzi deployment
We heavily use Terraform to manage and provision our Kafka and Kafka-related components. This enables us to quickly and reliably spin up new clusters and perform cluster scaling operations.
Under the hood, Strimzi Kafka deployment is a Kubernetes deployment. To increase the performance and the reliability of the Kafka cluster, we create dedicated Kubernetes nodes for each Strimzi Kafka broker and each Zookeeper pod, using Kubernetes taints and tolerations. This ensures that all resources of a single node are dedicated solely to either a single Kafka broker or a single Zookeeper pod.
We also decided to go with a single Kafka cluster by Kubernetes cluster to make the management easier.
Client setup
Coban provides backend microservice teams from all Grab verticals with a popular Kafka SDK in Golang, to standardise how teams utilise Coban Kafka clusters. Adding mTLS support mostly boils down to upgrading our SDK.
Our enhanced SDK provides a default mTLS configuration that works out of the box for most teams, while still allowing customisation, e.g., for teams that have their own Hashicorp Vault Infrastructure for compliance reasons. Similarly, clients can choose among various Vault auth methods such as AWS or Kubernetes to authenticate to Hashicorp Vault, or even implement their own logic for getting a valid client certificate.
To mitigate the potential risk of a user maliciously sharing their application’s certificate with other applications or users, we limit the maximum Time-To-Live (TTL) for any given certificate. This also removes the overhead of maintaining a Certificate Revocation List (CRL). Additionally, our SDK stores the certificate and its associated private key in memory only, never on disk, hence reducing the attack surface.
In our case, Hashicorp Vault is a dependency. To prevent it from reducing the overall availability of our data streaming platform, we have added two features to our SDK – a configurable retry mechanism and automatic renewal of clients’ short-lived certificates when two thirds of their TTL is reached. The upgraded SDK also produces new metrics around this certificate renewal process, enabling better monitoring and alerting.
Authorisation
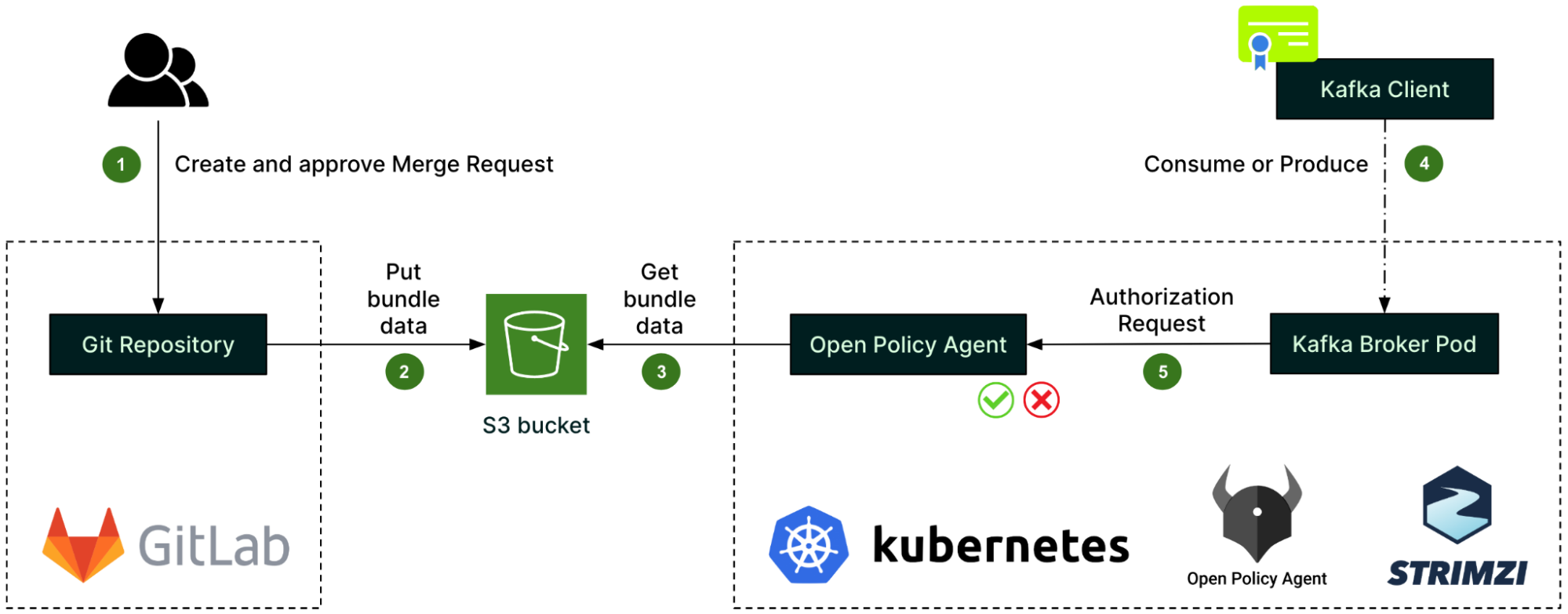
For authorisation, we set up the Open Policy Agent (OPA) as a standalone deployment in the Kubernetes cluster, and configured Strimzi to integrate the Kafka brokers with that OPA.
OPA policies – written in the Rego language – describe the authorisation logic. They are created in a GitLab repository along with the authorisation rules, called data sources (step 1). Whenever there is a change, a GitLab CI pipeline automatically creates a bundle of the policies and data sources, and pushes it to an S3 bucket (step 2). From there, it is fetched by the OPA (step 3).
When a client – identified by its TLS certificate’s Subject – attempts to consume or produce a Kafka record (step 4), the Kafka broker pod first issues an authorisation request to the OPA (step 5) before processing the client’s request. The outcome of the authorisation request is then cached by the Kafka broker pod to improve performance.
As the core component of the authorisation process, the OPA is deployed with the same high availability as the Kafka cluster itself, i.e. spread across the same number of Availability Zones. Also, we decided to go with one dedicated OPA by Kafka cluster instead of having a unique global OPA shared between multiple clusters. This is to reduce the blast radius of any OPA incidents.
For monitoring and alerting around authorisation, we submitted an Open Source contribution in the opa-kafka-plugin project in order to enable the OPA authoriser to expose some metrics. Our contribution to the open source code allows us to monitor various aspects of the OPA, such as the number of authorised and unauthorised requests, as well as the cache hit-and-miss rates. Also, we set up alerts for suspicious activity such as unauthorised requests.
Finally, as a platform team, we need to make authorisation a scalable, self-service process. Thus, we rely on the Git repository’s permissions to let Kafka topics’ owners approve the data source changes pertaining to their topics.
Teams who need their applications to access a Kafka topic would write and submit a JSON data source as simple as this:
{
"example_topic": {
"read": [
"clientA.grab",
"clientB.grab"
],
"write": [
"clientB.grab"
]
}
}
GitLab CI unit tests and business logic checks are set up in the Git repository to ensure that the submitted changes are valid. After that, the change would be submitted to the topic’s owner for review and approval.
What’s next?
The performance impact of this security design is significant compared to unauthenticated, unauthorised, plaintext Kafka. We observed a drop in throughput, mostly due to the low performance of encryption and decryption in Java, and are currently benchmarking different encryption ciphers to mitigate this.
Also, on authorisation, our current PBAC design is pretty static, with a list of applications granted access for each topic. In the future, we plan to move to Attribute-Based Access Control (ABAC), creating dynamic policies based on teams and topics’ metadata. For example, teams could be granted read and write access to all of their own topics by default. Leveraging a versatile component such as the OPA as our authorisation controller enables this evolution.
Join us
Grab is the leading superapp platform in Southeast Asia, providing everyday services that matter to consumers. More than just a ride-hailing and food delivery app, Grab offers a wide range of on-demand services in the region, including mobility, food, package and grocery delivery services, mobile payments, and financial services across 428 cities in eight countries.
Powered by technology and driven by heart, our mission is to drive Southeast Asia forward by creating economic empowerment for everyone. If this mission speaks to you, join our team today!