Post Syndicated from Prabhu Pandian original https://aws.amazon.com/blogs/big-data/why-tombola-chose-graviton-powered-rg-instances-for-amazon-redshift/
Part of Flutter Entertainment, the world’s largest online sports betting and iGaming operator, tombola is the world’s biggest online bingo community and has been using Amazon Redshift to run its data analytics workloads. Founded in Sunderland, UK, the company traces its roots to the 1950s, when it began printing bingo tickets during the golden age of the game. tombola launched online in 2006 and has since expanded to Italy, Spain, Denmark, and Sweden. The company builds all of its games in-house, holds the most prestigious Safer Gambling award, and recently partnered with Flutter sibling brand Sisal to bring its bingo application to Italian players.
In this post, you learn how tombola followed a strict engineering principle: no changes to production without evidence. That meant a head-to-head comparison of RA3 versus RG on their actual workload. You also see benchmark results on Amazon S3 Tables and the migration from RA3 to RG instances.
Current data architecture
Amazon Redshift sits at the center of tombola’s data architecture. The production cluster runs on RA3 nodes and serves multiple schemas with hundreds of tables, supporting every analytical workload the business runs, from sub-second application lookups to multi-minute extract, transform, load (ETL) transforms. What makes tombola’s Amazon Redshift workload distinctive is the breadth of what flows through it. Amazon Managed Workflows for Apache Airflow (Amazon MWAA) DAGs orchestrate pipelines across over 14 business domains, including segmentation, fraud detection, marketing, finance, and SafePlay responsible-gaming. Configuration-driven ingestion pipelines land data from SQL Server, Amazon DynamoDB, Amazon OpenSearch Service, Postgres, and external APIs into Bronze and Silver layers on Amazon Simple Storage Service (Amazon S3), before loading it into Amazon Redshift. From there, over 250 dbt models running on Amazon Elastic Container Service (Amazon ECS) transform the data into analytical gold layers. Outputs feed multiple downstream consumers: Amazon SageMaker for fraud scoring and churn prediction, Amazon DynamoDB for low-latency APIs, and region-specific pipelines spanning the UK, Italy, Spain, Denmark, and Sweden. As the application grew, with more domains, more DAGs, and more concurrent users, the team began evaluating ways to reduce steady-state query latency and lower compute cost without rearchitecting the system. When AWS made Graviton-powered RG nodes available for Amazon Redshift, the timing was right.
Benchmark performance results
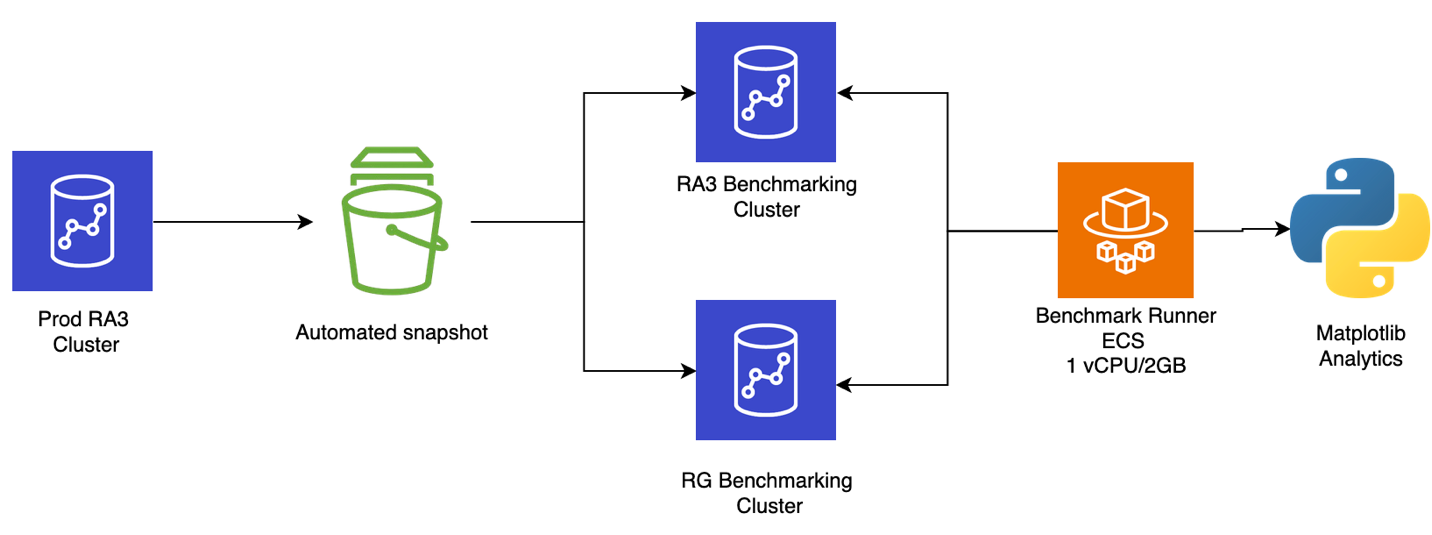
The benchmark infrastructure was fully defined as infrastructure as code (IaC), making sure every test run was reproducible. The team deployed two test benchmark clusters (one RA3 and one RG) in a like-for-like configuration. They mirrored the settings (Amazon Virtual Private Cloud (Amazon VPC), security groups, AWS Key Management Service (AWS KMS), AWS Identity and Access Management (IAM) roles, and parameter groups) from the production environment to remove configuration drift. The benchmark runner was containerized as an Amazon ECS task (python:3.11-slim-bookworm ARM64 base), providing repeatable, isolated execution for each test round. Benchmark workloads were selected by analyzing production cluster logs and metrics, then classified into three tiers:
- Heavy: ETL queries with multi-table CTE chains, full-table scans, and aggregation windows.
- Medium: Business intelligence (BI) queries driving reporting and analytics dashboards.
- Light: Application queries with sub-second response times.
Architecture
Scenarios tested
To validate the performance of Graviton-powered RG instances against the existing RA3 nodes, tombola designed four benchmark scenarios that progressively increase in complexity and realism. Together, these scenarios provide a comprehensive view of performance from isolated query execution through to sustained, real-world analytical workloads.
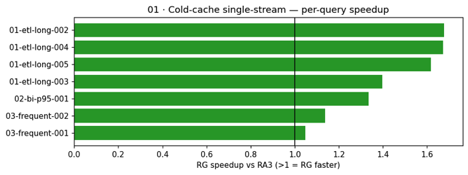
Scenario 01: Cold-cache, single-stream execution. This scenario isolates raw compute performance by running queries against a cold cache in a single stream, avoiding caching and concurrency as variables.
Per-query speedups ranged from 1.05× (light lookup queries) to 1.68× (heavy ETL transforms). Zero errors on both clusters (28 attempts each).
| Weight Class | RA3 p50 (ms) | RG p50 (ms) | Speedup |
| Heavy (ETL) | 210,372 | 133,855 | 1.57× |
| Medium (BI) | 2,193 | 1,642 | 1.34× |
| Light (App) | 3.20 | 2.76 | 1.16× |
The following chart shows per-query speedup ratios for the cold-cache scenario. Heavy ETL queries (left) show the largest gains, with speedups of 1.57–1.68×, and lighter queries still benefit at 1.05–1.16×. The pattern is consistent: RG’s advantage scales with query complexity.
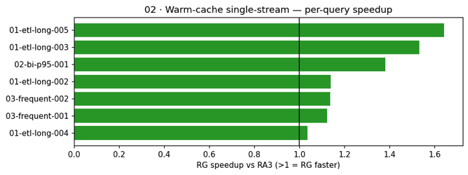
Scenario 02: Warm-cache, single-stream execution. This scenario repeats Scenario 01 with the result cache enabled to confirm that RG maintains its latency advantage even when cached results are in play.
Per-query speedups ranged from 1.04× to 1.64×. Zero errors on both clusters (35 attempts each).
| Weight Class | RA3 p50 (ms) | RG p50 (ms) | Speedup |
| Heavy (ETL) | 93,636 | 61,691 | 1.52× |
| Medium (BI) | 2,189 | 1,584 | 1.38× |
| Light (App) | 3.08 | 2.58 | 1.19× |
With result caching enabled, the speedup pattern holds for non-cached queries. Cache hits on both clusters land in 118–185 ms, confirming the caching subsystem operates identically regardless of node type. The RG advantage appears exclusively on execution paths that bypass the cache.
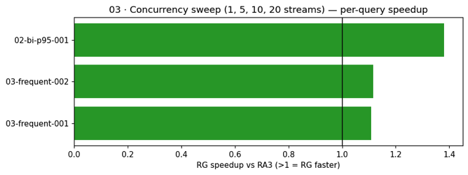
Scenario 03: Concurrency sweep. This scenario introduces parallel load by sweeping through 1, 5, 10, and 20 concurrent streams, testing how each node type handles contention and queuing under pressure.
Both clusters used the same Concurrency Scaling configuration (max_concurrency_scaling_clusters=1, WLM-only). RG completed 482 more queries in the same wall-clock window.
| Metric | RA3 | RG | Improvement |
| Total queries completed | 1,438 | 1,920 | +33% throughput |
| Light p50 (ms) | 3.44 | 3.04 | 1.13× |
| Medium p50 (ms) | 20,784 | 15,055 | 1.38× |
| Errors | 0 | 0 | — |
Under increasing parallel load (1, 5, 10, and 20 concurrent streams), RG maintained lower latencies and completed 33 percent more queries in the same wall-clock window. Both clusters used the same Concurrency Scaling configuration, so the throughput difference is attributable to per-node compute efficiency.
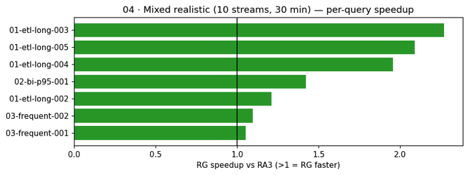
Scenario 04: Mixed realistic workload. This scenario combines the previous elements into a mixed realistic workload, running 10 streams simultaneously for 30 minutes with a weighted distribution of heavy, medium, and light queries to simulate actual production conditions.
This scenario best simulates production. The headline finding: heavy ETL queries saw speedups of up to 2.27× under concurrent load, and RG completed 46 percent more total queries in the same 30-minute window. Zero errors on both clusters.
| Metric | RA3 | RG | Improvement |
| Total queries completed | 405 | 593 | +46% throughput |
| Heavy p50 (ms) | 1,186,572 | 642,294 | 1.85× |
| Medium p50 (ms) | 2,319 | 1,631 | 1.42× |
| Light p50 (ms) | 3.12 | 2.90 | 1.08× |
| Errors | 0 | 0 | — |
The mixed-realistic scenario best simulates production. Under 10 concurrent streams over 30 minutes, heavy ETL queries showed speedups of up to 2.27×. RG’s per-vCPU throughput advantage compounds under contention, exactly the condition where production clusters spend most of their time.
Extended benchmark: Amazon S3 Tables (Iceberg) performance
tombola’s future data architecture will integrate with agents and revolves around Apache Iceberg, backed by Amazon S3 Tables. Amazon S3 Tables offer Amazon S3 storage that is specifically tuned for analytics, with built-in capabilities that keep making queries faster and helping lower storage costs for table data. They’re purpose-built to hold tabular datasets, such as daily purchase logs, streaming sensor readings, or ad impression events. In this model, data is organized into rows and columns, similar to how information is structured in a traditional database table. With that direction in mind, tombola also benchmarked Graviton’s performance querying Iceberg tables directly. The dataset includes player profiles, game session history, and geolocation data: a mix of wide tables and high-cardinality columns that stress both compute and I/O.
To evaluate performance across different scenarios, tombola generated queries at varying levels of complexity. Medium queries involve standard analytical functions like ranking and aggregation, and Medium-High queries introduce multi-step transformations with joins and cumulative calculations. At the High tier, queries combine distinct counting, conditional pivoting, and time-window aggregations. Very High queries are the most demanding: self-joins across the full dataset, multi-signal scoring logic, and advanced statistical functions. This tiered approach captures how each node type performs as computational demands increase.
As with the previous benchmarks, the team kept the test as comparable as possible: a true like-for-like evaluation between RG (powered by Graviton) and RA3 nodes of equivalent size.
Testing was split into two phases:
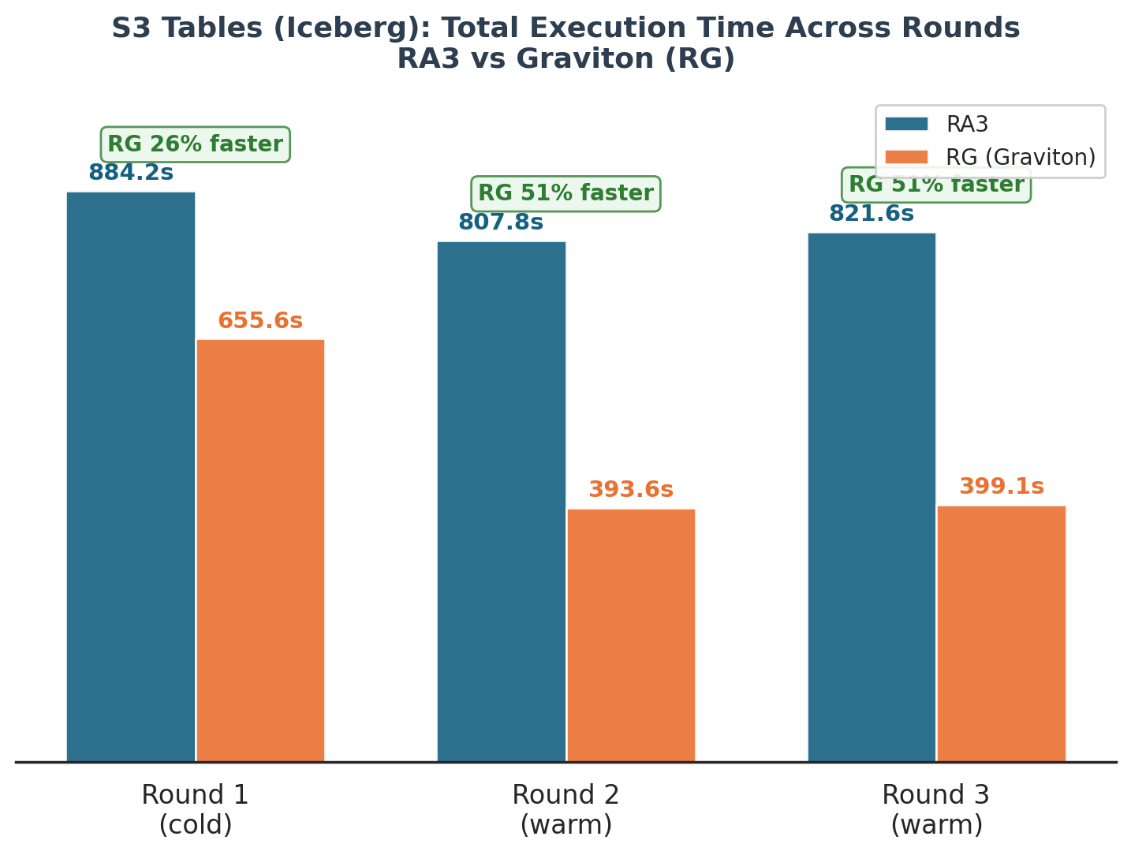
Phase 1: Concurrency. All queries were submitted simultaneously to measure how well each node type handles concurrent workloads. The goal was to understand throughput differences: how much more work RG nodes can push through under pressure compared to similarly sized RA3 nodes.
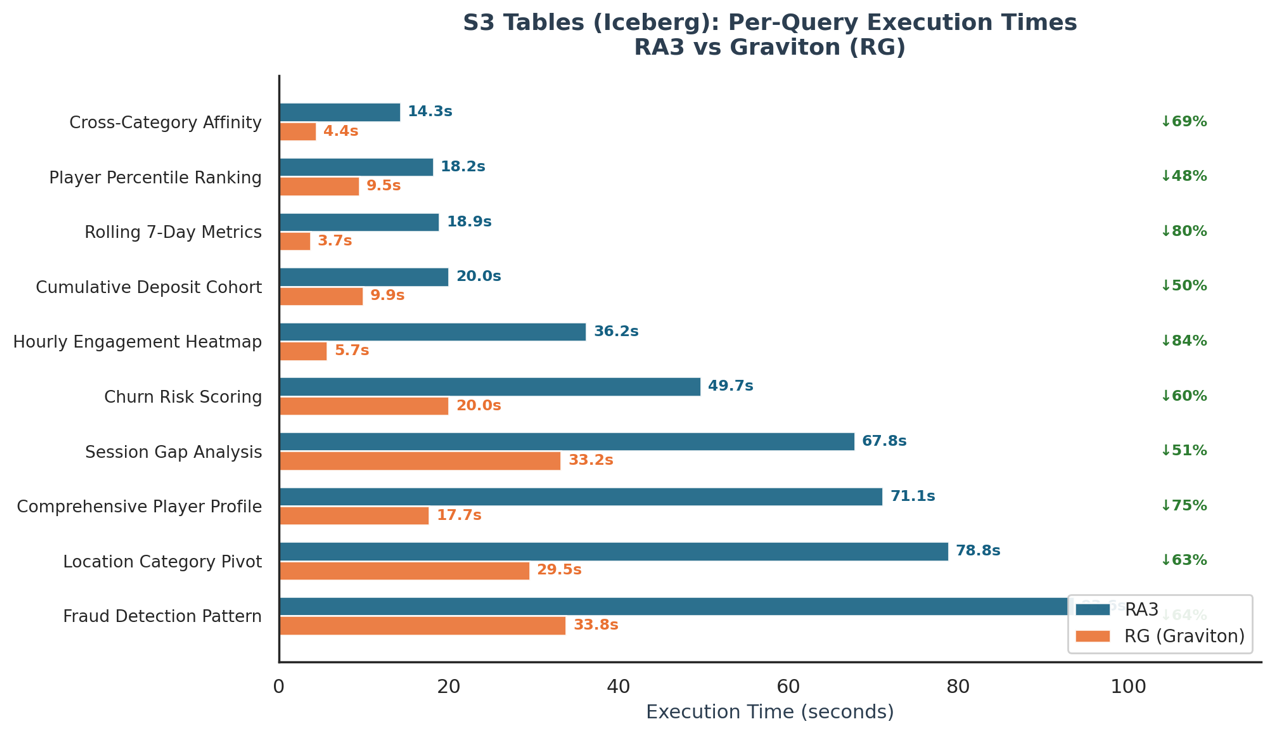
All queries were run simultaneously across multiple rounds:
Phase 2: Sequential execution. Each query was run in isolation with full compute resources available. This removed concurrency as a variable and gave a clean read on raw query performance. The results were clear: RG outperformed RA3 across multiple query types, showing consistent gains when given dedicated compute.
In sequential execution, Graviton (RG) delivered consistent performance gains across all query complexity levels: Medium-complexity queries ran 45–73 percent faster (average 58 percent), Medium-High queries improved by 42 percent, High-complexity queries achieved 57–66 percent faster execution (average 62 percent), and Very High-complexity queries saw gains of 60–67 percent (average 63 percent). The results demonstrate that RG’s advantage scales with workload complexity, delivering the largest improvements on the most demanding analytical queries.
tombola’s modernization approach
tombola is modernizing its Amazon Redshift cluster using the Elastic Resize path to change from RA3 to RG node types. The operation snapshots the existing cluster, provisions a new RG cluster from that snapshot, and transfers data in the background. During this transfer period, the source cluster remains available in read-only mode. When the resize nears completion, Amazon Redshift automatically updates the endpoint to point to the new RG cluster and drops connections to the source. The team chose this approach because it aligns with their engineering principle of evidence-based changes: no production cutover without proof. The benchmark results, with zero errors across all scenarios against production-representative workloads, provided the confidence needed to proceed. After the resize is complete, the external tables, schemas, and query syntax remain unchanged. With RG’s integrated data lake query engine, tombola also removes its dependency on Amazon Redshift Spectrum. Data lake queries now run directly on cluster nodes within the Amazon VPC boundary, using existing IAM roles, with zero per-TB scanning charges.
Conclusion
The benchmark results make a compelling case for migrating tombola’s Amazon Redshift infrastructure from RA3 (Intel Xeon) to RG (Graviton4) instances. Across every scenario tested, RG delivered significant and consistent performance gains:
- Cold-cache performance: 1.57× faster on heavy ETL queries, with per-query speedups up to 1.68×.
- Warm-cache performance: 1.52× faster on heavy workloads, maintaining advantage even with result caching enabled.
- Concurrency: 33 percent higher throughput under parallel load, with RG sustaining lower latencies as streams increased from 1 to 20.
- Mixed realistic workload: 1.85× faster on heavy ETL queries and 46 percent more total queries completed, the scenario closest to production traffic patterns.
- Amazon S3 Tables (Iceberg): Up to 51 percent faster under concurrent load and 57 percent faster in sequential execution, critical for tombola’s future lakehouse architecture.
Beyond raw performance, RG delivers architectural benefits that align with tombola’s strategic direction. The integrated data lake query engine removes Amazon Redshift Spectrum overhead and per-TB scan charges. The 4:3 node mapping (4 ra3.4xlarge nodes to 3 rg.4xlarge nodes) reduces infrastructure costs by 25 percent.
Based on these results, tombola are modernizing their production Amazon Redshift cluster to Graviton4-based RG instances. The work has already started and similar results as above are noticed. The existing RA3 features, including concurrency scaling, data sharing, and system views, are fully supported on RG. This positions tombola to handle growing data volumes and user concurrency with better performance, greater cost efficiency, and a predictable pricing model as the application scales.
The results and benefits described in this post are specific to tombola’s workload and environment. Although Amazon Redshift RG instances powered by AWS Graviton4 processors can deliver significant performance improvements, actual results will vary based on factors including workload characteristics, data volumes, cluster configuration, and query complexity. We encourage you to evaluate RG instances with your own workloads to determine the benefits for your environment. To learn more, visit the Amazon Redshift marketing page and the Amazon Redshift documentation, or get started in the Amazon Redshift console.