Today, AWS announced Amazon Managed Workflows for Apache Airflow (MWAA) Serverless. This is a new deployment option for MWAA that eliminates the operational overhead of managing Apache Airflow environments while optimizing costs through serverless scaling. This new offering addresses key challenges that data engineers and DevOps teams face when orchestrating workflows: operational scalability, cost optimization, and access management.
With MWAA Serverless you can focus on your workflow logic rather than monitoring for provisioned capacity. You can now submit your Airflow workflows for execution on a schedule or on demand, paying only for the actual compute time used during each task’s execution. The service automatically handles all infrastructure scaling so that your workflows run efficiently regardless of load.
Beyond simplified operations, MWAA Serverless introduces an updated security model for granular control through AWS Identity and Access Management (IAM). Each workflow can now have its own IAM permissions, running on a VPC of your choosing so you can implement precise security controls without creating separate Airflow environments. This approach significantly reduces security management overhead while strengthening your security posture.
In this post, we demonstrate how to use MWAA Serverless to build and deploy scalable workflow automation solutions. We walk through practical examples of creating and deploying workflows, setting up observability through Amazon CloudWatch, and converting existing Apache Airflow DAGs (Directed Acyclic Graphs) to the serverless format. We also explore best practices for managing serverless workflows and show you how to implement monitoring and logging.
How does MWAA Serverless work?
MWAA Serverless processes your workflow definitions and executes them efficiently in service-managed Airflow environments, automatically scaling resources based on workflow demands. MWAA Serverless uses the Amazon Elastic Container Service (Amazon ECS) executor to run each individual task on its own ECS Fargate container, on either your VPC or a service-managed VPC. Those containers then communicate back to their assigned Airflow cluster using the Airflow 3 Task API.
Figure 1: Amazon MWAA Architecture
MWAA Serverless uses declarative YAML configuration files based on the popular open source DAG Factory format to enhance security through task isolation. You have two options for creating these workflow definitions:
Write your workflows directly in YAML using AWS managed operators from the Amazon Provider Package
This declarative approach provides two key benefits. First, since MWAA Serverless reads workflow definitions from YAML it can determine task scheduling without running any workflow code. Second, this allows MWAA Serverless to grant execution permissions only when tasks run, rather than requiring broad permissions at the workflow level. The result is a more secure environment where task permissions are precisely scoped and time limited.
Service considerations for MWAA Serverless
MWAA Serverless has the following limitations that you should consider when deciding between serverless and provisioned MWAA deployments:
Operator support
MWAA Serverless only supports operators from the Amazon Provider Package.
To execute custom code or scripts, you’ll need to use AWS services, such as:
Note: Throughout this post, we use example values that you’ll need to replace with your own:
Replace amzn-s3-demo-bucket with your S3 bucket name
Replace 111122223333 with your AWS account number
Replace us-east-2 with your AWS Region. MWAA Serverless is available in multiple AWS Regions. Check the List of AWS Services Available by Region for current availability.
Creating your first serverless workflow
Let’s start by defining a simple workflow that gets a list of S3 objects and writes that list to a file in the same bucket. Create a new file called simple_s3_test.yaml with the following content:
For this workflow to run, you must create an Execution role that has permissions to list and write to the above bucket. The role also needs to be assumable from MWAA Serverless. The following CLI commands create this role and its associated policy:
AWS has published a conversion tool that uses the open-source Airflow DAG processor to serialize Python DAGs into YAML DAG factory format. To install, you run the following:
Note that, because the YAML conversion is done after the DAG parsing, the loop that creates the tasks is run first and the resulting static list of tasks is written to the YAML document with their dependencies.
Migrating an MWAA environment’s DAGs to MWAA Serverless
You can take advantage of a provisioned MWAA environment to develop and test your workflows and then move them to serverless to run efficiently at scale. Further, if your MWAA environment is using compatible MWAA Serverless operators, then you can convert all of the environment’s DAGs at once. The first step is to allow MWAA Serverless to assume the MWAA Execution role via a trust relationship. This is a one-time operation for each MWAA Execution role, and can be performed manually in the IAM console or using an AWS CLI command as follows:
MWAA Serverless workflow execution status is returned via the GetWorkflowRun function. The results from that will return details for that particular run. If there are errors in the workflow definition, they are returned under RunDetail in the ErrorMessage field as in the following example:
MWAA Serverless task logs are stored in the CloudWatch log group /aws/mwaa-serverless/<workflow id>/ (where /<workflow id> is the same string as the unique workflow id in the ARN of the workflow). For specific task log streams, you will need to list the tasks for the workflow run and then get each task’s information. You can combine these operations into a single CLI command.
After completing these steps, verify in the AWS Management Console that all resources have been properly removed. Remember that CloudWatch Logs are retained by default and may need to be deleted separately if you want to remove all traces of your workflow executions.
If you encounter any errors during cleanup, verify you have the necessary permissions and that resources exist before attempting to delete them. Some resources may have dependencies that require them to be deleted in a specific order.
Conclusion
In this post, we explored Amazon MWAA Serverless, a new deployment option that simplifies Apache Airflow workflow management. We demonstrated how to create workflows using YAML definitions, convert existing Python DAGs to the serverless format, and monitor your workflows.
MWAA Serverless offers several key advantages:
No provisioning overhead
Pay-per-use pricing model
Automatic scaling based on workflow demands
Enhanced security through granular IAM permissions
Simplified workflow definitions using YAML
To learn more MWAA Serverless, review the documentation.
Apache Airflow 3.x on Amazon MWAA introduces architectural improvements such as API-based task execution that provides enhanced security and isolation. Other major updates include a redesigned UI for better user experience, scheduler-based backfills for improved performance, and support for Python 3.12. Unlike in-place minor Airflow version upgrades in Amazon MWAA, upgrading to Airflow 3 from Airflow 2 requires careful planning and execution through a migration approach due to fundamental breaking changes.
This migration presents an opportunity to embrace next-generation workflow orchestration capabilities while providing business continuity. However, it’s more than a simple upgrade. Organizations migrating to Airflow 3.x on Amazon MWAA must understand key breaking changes, including the removal of direct metadata database access from workers, deprecation of SubDAGs, changes to default scheduling behavior, and library dependency updates. This post provides best practices and a streamlined approach to successfully navigate this critical migration, providing minimal disruption to your mission-critical data pipelines while maximizing the enhanced capabilities of Airflow 3.
Understanding the migration process
The journey from Airflow 2.x to 3.x on Amazon MWAA introduces several fundamental changes that organizations must understand before beginning their migration. These changes affect core workflow operations and require careful planning to achieve a smooth transition.
You should be aware of the following breaking changes:
Removal of direct database access – A critical change in Airflow 3 is the removal of direct metadata database access from worker nodes. Tasks and custom operators must now communicate through the REST API instead of direct database connections. This architectural change affects code that previously accessed the metadata database directly through SQLAlchemy connections, requiring refactoring of existing DAGs and custom operators.
SubDAG deprecation – Airflow 3 removes the SubDAG construct in favor of TaskGroups, Assets, and Data Aware Scheduling. Organizations must refactor existing SubDAGs to one of the previously mentioned constructs.
Scheduling behavior changes – Two notable changes to default scheduling options require an impact analysis:
The default values for catchup_by_default and create_cron_data_intervals changed to False. This change affects DAGs that don’t explicitly set these options.
Airflow 3 removes several context variables, such as execution_date, tomorrow_ds, yesterday_ds, prev_ds, and next_ds. You must replace these variables with currently supported context variables.
Library and dependency changes – A significant number of libraries change in Airflow 3.x, requiring DAG code refactoring. Many previously included provider packages might need explicit addition to the requirements.txt file.
Authentication system – Although Airflow 3.0.1 and later versions default to SimpleAuthManager instead of Flask-AppBuilder, Amazon MWAA will continue using Flask-AppBuilder for Airflow 3.x. This means customers on Amazon MWAA will not see any authentication changes.
The migration requires creating a new environment rather than performing an in-place upgrade. Although this approach demands more planning and resources, it provides the advantage of maintaining your existing environment as a fallback option during the transition, facilitating business continuity throughout the migration process.
Pre-migration planning and assessment
Successful migration depends on thorough planning and assessment of your current environment. This phase establishes the foundation for a smooth transition by identifying dependencies, configurations, and potential compatibility issues. Evaluate your environment and code against the previously mentioned breaking changes to have a successful migration.
Environment assessment
Begin by conducting a complete inventory of your current Amazon MWAA environment. Document all DAGs, custom operators, plugins, and dependencies, including their specific versions and configurations. Make sure your current environment is on version 2.10.x, because this provides the best compatibility path for upgrading to Amazon MWAA with Airflow 3.x.
Identify the structure of the Amazon Simple Storage Service (Amazon S3) bucket containing your DAG code, requirements file, startup script, and plugins. You will replicate this structure in a new bucket for the new environment. Creating separate buckets for each environment avoids conflicts and allows continued development without affecting current pipelines.
Configuration documentation
Document all custom Amazon MWAA environment variables, Airflow connections, and environment configurations. Review AWS Identity and Access Management (IAM) resources, because your new environment’s execution role will need identical policies. IAM users or roles accessing the Airflow UI require the CreateWebLoginToken permission for the new environment.
Pipeline dependencies
Understanding pipeline dependencies is critical for a successful phased migration. Identify interdependencies through Datasets (now Assets), SubDAGs, TriggerDagRun operators, or external API interactions. Develop your migration plan around these dependencies so related DAGs can migrate at the same time.
Consider DAG scheduling frequency when planning migration waves. DAGs with longer intervals between runs provide larger migration windows and lower risk of duplicate execution compared with frequently running DAGs.
Testing strategy
Create your testing strategy by defining a systematic approach to identifying compatibility issues. Use the ruff linter with the AIR30 ruleset to automatically identify code requiring updates:
Then, review and update your environment’s requirements.txt file to make sure package versions comply with the updated constraints file. Additionally, commonly used Operators previously included in the airflow-core package now reside in a separate package and need to be added to your requirements file.
Test your DAGs using the Amazon MWAA Docker images for Airflow 3.x. These images make it possible to create and test your requirements file, and confirm the Scheduler successfully parses your DAGs.
Migration strategy and best practices
A methodical migration approach minimizes risk while providing clear validation checkpoints. The recommended strategy employs a phased blue/green deployment model that provides reliable migrations and immediate rollback capabilities.
Phased migration approach
The following migration phases can assist you in defining your migration plan:
Phase 1: Discovery, assessment, and planning – In this phase, complete your environment inventory, dependency mapping, and breaking change analysis. With the gathered information, develop the detailed migration plan. This plan will include steps for updating code, updating your requirements file, creating a test environment, testing, creating the blue/green environment (discussed later in this post), and the migration steps. Planning must also include the training, monitoring strategy, rollback conditions, and the rollback plan.
Phase 2: Pilot migration – The pilot migration phase serves to validate your detailed migration plan in a controlled environment with a small range of impact. Focus the pilot on two or three non-critical DAGs with diverse characteristics, such as different schedules and dependencies. Migrate the selected DAGs using the migration plan defined in the previous phase. Use this phase to validate your plan and monitoring tools, and adjust both based on actual results. During the pilot, establish baseline migration metrics to help predict the performance of the full migration.
Phase 3: Wave-based production migration – After a successful pilot, you are ready to begin the full wave-based migration for the remaining DAGs. Group remaining DAGs into logical waves based on business criticality (least critical first), technical complexity, interdependencies (migrate dependent DAGs together), and scheduling frequency (less frequent DAGs provide larger migration windows). After you define the waves, work with stakeholders to develop the wave schedule. Include sufficient validation periods between waves to confirm the wave is successful before starting the next wave. This time also reduces the range of impact in the event of a migration issue, and provides sufficient time to perform a rollback.
Phase 4: Post-migration review and decommissioning – After all waves are complete, conduct a post-migration review to identify lessons learned, optimization opportunities, and any other unresolved items. This is also a good time to provide an approval on system stability. The final step is decommissioning the original Airflow 2.x environment. After stability is determined, based on business requirements and input, decommission the original (blue) environment.
Blue/green deployment strategy
Implement a blue/green deployment strategy for safe, reversible migration. With this strategy, you will have two Amazon MWAA environments operating during the migration and manage which DAGs operate in which environment.
The blue environment (current Airflow 2.x) maintains production workloads during transition. You can implement a freeze window for DAG changes before migration to avoid last-minute code conflicts. This environment serves as the immediate rollback environment if an issue is identified in the new (green) environment.
The green environment (new Airflow 3.x) receives migrated DAGs in controlled waves. It mirrors the networking, IAM roles, and security configurations from the blue environment. Configure this environment with the same options as the blue environment, and create identical monitoring mechanisms so both environments can be monitored simultaneously. To avoid duplicate DAG runs, make sure a DAG only runs in a single environment. This involves pausing the DAG in the blue environment before activating the DAG in the green environment.Maintain the blue environment in warm standby mode during the entire migration. Document specific rollback steps for each migration wave, and test your rollback procedure for at least one non-critical DAG. Additionally, define clear criteria for triggering the rollback (such as specific failure rates or SLA violations).
Step-by-step migration process
This section provides detailed steps for conducting the migration.
Pre-migration assessment and preparation
Before initiating the migration process, conduct a thorough assessment of your current environment and develop the migration plan:
Make sure your current Amazon MWAA environment is on version 2.10.x
Create a detailed inventory of your DAGs, custom operators, and plugins including their dependencies and versions
Review your current requirements.txt file to understand package requirements
Document all environment variables, connections, and configuration settings
Determine your migration success criteria, rollback conditions, and rollback plan
Identify a small number of DAGs suitable for the pilot migration
Develop a plan to train, or familiarize, Amazon MWAA users on Airflow 3
Compatibility checks
Identifying compatibility issues is critical to a successful migration. This step helps developers focus on specific code that is incompatible with Airflow 3.
Use the ruff linter with the AIR30 ruleset to automatically identify code requiring updates:
Based on your findings during compatibility testing, update the affected DAG code for Airflow 3.x. The ruff DAG check utility can automatically fix common changes. Use the following command to run the utility in update mode:
ruff check dag/ --select AIR301 --fix –preview
Common changes include:
Replace direct metadata database access with API calls:
# Before (Airflow 2.x) - Direct DB access
from airflow.settings import Session
from airflow.models.taskInstance import TaskInstance
session=Session()
result=session.query(TaskInstance)
For Apache Airflow v3.x, utilize in the Amazon MWAA SDK.
Update core construct imports with the new Airflow SDK namespace:
# Before (Airflow 2.x)
from airflow.decorators import dag, task
# After (Airflow 3.x)
from airflow.sdk import dag, task
Replace deprecated context variables with their modern equivalents:
# Before (Airflow 2.x)
def my_task(execution_date, **context):
# Using execution_date
# After (Airflow 3.x)
def my_task(logical_date, **context):
# Using logical_date
Next, evaluate the usage of the two scheduling-related default changes. catchup_by_default is now False, meaning missing DAG runs will no longer automatically backfill. If backfill is required, update the DAG definition with catchup=True. If your DAGs require backfill, you must consider the impact of this migration and backfilling. Because you’re migrating a DAG to a clean environment with no history, enabling backfilling will create DAG runs for all runs beginning with the specified start_date. Consider updating the start_date to avoid unnecessary runs.
create_cron_data_intervals is also now False. With this change, cron expressions are evaluated as a CronTriggerTimetable construct.
Finally, evaluate the usage of deprecated context variables for manually and Asset-triggered DAGs, then update your code with suitable replacements.
Updating requirements and testing
In addition to possible package version changes, several core Airflow operators previously included in the airflow-core package moved to the apache-airflow-providers-standard package. These changes must be incorporated into your requirements.txt file. Specifying, or pinning, package versions in your requirements file is a best practice and recommended for this migration.To update your requirements file, complete the following steps:
Download and configure the Amazon MWAA Docker images. For more details, refer to the GitHub repo.
Copy the current environment’s requirements.txt file to a new file.
If needed, add the apache-airflow-providers-standard package to the new requirements file.
Download the appropriate Airflow constraints file for your target Airflow version to your working director. A constraints file is available for each Airflow version and Python version combination. The URL takes the following form: https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt
Create your versioned requirements file using your un-versioned file and the constraints file. For guidance on creating a requirements file, see Creating a requirements.txt file. Make sure there are no dependency conflicts before moving forward.
Verify your requirements file using the Docker image. Run the following command inside the running container:
./run.sh test-requirements
Address any installation errors by updating package versions.
As a best practice, we recommend packaging your packages into a ZIP file for deployment in Amazon MWAA. This makes sure the same exact packages are installed on all Airflow nodes. Refer to Installing Python dependencies using PyPi.org Requirements File Format for detailed information about packaging dependencies.
Creating a new Amazon MWAA 3.x environment
Because Amazon MWAA requires a migration approach for major version upgrades, you must create a new environment for your blue/green deployment. This post uses the AWS Command Line Interface (AWS CLI) as an example, you can also use infrastructure as code (IaC).
Create a new S3 bucket using the same structure as the current S3 bucket.
Upload the updated requirements file and any plugin packages to the new S3 bucket.
Generate a template for your new environment configuration:
Copy configurations from your existing environment.
Update the environment name.
Set the AirflowVersion parameter to the target 3.x version.
Update the S3 bucket properties with the new S3 bucket name.
Review and update other configuration parameters as needed.
Configure the new environment with the same networking settings, security groups, and IAM roles as your existing environment. Refer to the Amazon MWAA User Guide for these configurations.
Your new environment requires the same variables, connections, roles, and pool configurations. Use this section as a guide for migrating this information. If you’re using AWS Secrets Manager as your secrets backend, you don’t need to migrate any connections. Depending your environment’s size, you can migrate this metadata using the Airflow UI or the Apache Airflow REST API.
Update any custom pool information in the new environment using the Airflow UI.
For environments using the metadatabase as a secrets backend, migrate all connections to the new environment.
Migrate all variables to the new environment.
Migrate any custom Airflow roles to the new environment.
Migration execution and validation
Plan and execute the transition from your old environment to the new one:
Schedule the migration during a period of low workflow activity to minimize disruption.
Implement a freeze window for DAG changes before and during the migration.
Execute the migration in phases:
Pause DAGs in the old environment. For a small number of DAGs, you can use the Airflow UI. For larger groups, consider using the REST API.
Verify all running tasks have completed in the Airflow UI.
Redirect DAG triggers and external integrations to the new environment.
Copy the updated DAGs to the new environment’s S3 bucket.
Enable DAGs in the new environment. For a small number of DAGs, you can use the Airflow UI. For larger groups, consider using the REST API.
Monitor the new environment closely during the initial operation period:
Watch for failed tasks or scheduling issues.
Check for missing variables or connections.
Verify external system integrations are functioning correctly.
Monitor Amazon CloudWatch metrics to confirm the environment is performing as expected.
Post-migration validation
After the migration, thoroughly validate the new environment:
Verify that all DAGs are being scheduled correctly according to their defined schedules
Check that task history and logs are accessible and complete
Test critical workflows end-to-end to confirm they execute successfully
Validate connections to external systems are functioning properly
Monitor CloudWatch metrics for performance validation
Cleanup and documentation
When the migration is complete and the new environment is stable, complete the following steps:
Document the changes made during the migration process.
Update runbooks and operational procedures to reflect the new environment.
After a sufficient stability period, defined by stakeholders, decommission the old environment:
aws mwaa delete-environment --name old-mwaa2-env
Archive backup data according to your organization’s retention policies.
Conclusion
The journey from Airflow 2.x to 3.x on Amazon MWAA is an opportunity to embrace next-generation workflow orchestration capabilities while maintaining the reliability of your workflow operations. By following these best practices and maintaining a methodical approach, you can successfully navigate this transition while minimizing risks and disruptions to your business operations.
A successful migration requires thorough preparation, systematic testing, and maintaining clear documentation throughout the process. Although the migration approach requires more initial effort, it provides the safety and control needed for such a significant upgrade.
Today, Amazon Web Services (AWS) announced the general availability of Apache Airflow 3 on Amazon Managed Workflows for Apache Airflow (Amazon MWAA). This release transforms how organizations use Apache Airflow to orchestrate data pipelines and business processes in the cloud, bringing enhanced security, improved performance, and modern workflow orchestration capabilities to Amazon MWAA customers.
Amazon MWAA introduces Airflow 3 features that modernize workflow management for AWS customers. Following the April 2025 release of Airflow 3 by the Apache community, AWS has incorporated these capabilities into Amazon MWAA. Airflow now features a completely redesigned, intuitive UI that simplifies workflow orchestration for users across experience levels. With the Task Execution Interface (Task API), tasks can run both within Airflow and as standalone Python scripts, improving code portability and testing. Scheduler-managed Backfill moves operations from the CLI to the scheduler, providing centralized control and visibility through the Airflow UI. CLI security improvements replace direct database access with API calls, maintaining consistent security across interfaces. Airflow now supports event-driven workflows, enabling triggers from AWS services and external sources. Amazon MWAA also adds support for Python 3.12, bringing the latest language capabilities to workflow development.
This post explores the features of Airflow 3 on Amazon MWAA and outlines enhancements that improve your workflow orchestration capabilities. The service maintains the Amazon MWAA pay-as-you-go pricing model with no upfront commitments. You can begin immediately by visiting the Amazon MWAA console, launching new Apache Airflow environments through the AWS Management Console, AWS Command Line Interface (AWS CLI), AWS CloudFormation, or AWS SDK within minutes.
Architectural advancements in Airflow 3 on Amazon MWAA
Airflow 3 on Amazon MWAA introduces significant architectural improvements that enhance security, performance, and flexibility. These advancements create a more robust foundation for workflow orchestration while maintaining backward compatibility with existing workflows.
Enhanced security
Amazon MWAA with Airflow 3 changes the security model by making component isolation a standard practice rather than optional. In Airflow 2, the DAG processor (the component that parses and processes DAG files) runs within the scheduler process by default, but can optionally be separated into its own process for better scalability and security isolation. Airflow 3 makes this separation standard, maintaining consistent security practices across deployments.
API server and Task API
Building on this security foundation, a new API server component is introduced in Amazon MWAA with Airflow 3, which serves as an intermediary between task instances and the Airflow metadata database. This change improves your workflows’ security posture by minimizing direct access to the Airflow metadata database from tasks. Tasks now operate with least privilege database access, reducing the risk of one task affecting others and improving overall system stability through fewer direct database connections.
The standardized communication through well-defined API endpoints creates a foundation for more secure, scalable, and flexible workflow orchestration. The Task Execution Interface (Task API) helps tasks run both within Airflow and as standalone Python scripts, improving code portability and testing capabilities.
From data-aware to event-driven scheduling
Airflow’s evolution toward event-driven scheduling began with the introduction of data-aware scheduling in Airflow 2.4, so DAGs could be triggered based on data availability rather than time schedules alone. Amazon MWAA with Airflow 3 builds on this foundation through a transition that includes the renaming of datasets to assets and introduces advanced capabilities, including asset partitions, external event integration, and asset-centric workflow design.
The transition from datasets to assets represents more than a simple rename. A data asset is a collection of logically related data that can represent diverse data products, including database tables, persisted ML models, embedded dashboards, or directories containing files.
Amazon MWAA with Airflow 3 introduces a new asset-centric syntax that represents an important shift in how workflows can be designed. The @asset decorator helps developers put data assets at the center of their workflow design, creating more intuitive asset-driven pipelines.
The following code is an example of asset-aware DAG scheduling:
from airflow.sdk import DAG, Asset
from airflow.providers.standard.operators.python import PythonOperator
# Define the asset
customer_data_asset = Asset(name="customer_data", uri="s3://my-bucket/customer-data.csv")
def process_customer_data():
"""Process customer data..."""
# Implementation here
# Create the DAG and task
with DAG(dag_id="process_customer_data", schedule="@daily"):
PythonOperator(
task_id="process_data",
outlets=[customer_data_asset],
python_callable=process_customer_data
)
The following code shows an asset-centric approach with the @asset decorator:
from airflow.sdk import asset
@asset(uri="s3://my-bucket/customer-data.csv", schedule="@daily")
def customer_data():
"""Process customer data..."""
# Implementation here
The @asset decorator automatically creates an asset with the function name, a DAG with the same identifier, and a task that produces the asset. This reduces code complexity and facilitates automatic DAG creation, where each asset becomes a self-contained workflow unit.
External event-driven scheduling with Asset Watchers
A significant advancement in Amazon MWAA with Airflow 3 is the introduction of Asset Watchers, which help Airflow react to events happening outside of the Airflow system itself. Whereas previous versions supported internal cross-DAG dependencies, Asset Watchers extend this capability to external data systems and message queues through the AssetWatcher class.
Amazon MWAA with Airflow 3 includes support for Amazon Simple Queue Service (Amazon SQS) through Asset Watchers. This allows your workflows to be triggered by external messages and facilitates more event-driven scheduling. Airflow now supports event-driven workflows, enabling triggers from AWS services and external sources. Asset Watchers monitor external systems asynchronously and trigger workflow execution when specific events occur, enabling workflows to respond to business events, data updates, or system notifications without the overhead of traditional sensor-based polling mechanisms.
Modern React-based UI
Amazon MWAA with Airflow 3 features a completely redesigned, intuitive UI built with React and FastAPI that simplifies workflow orchestration for users across experience levels. The new interface provides more intuitive navigation and workflow visualization, with an enhanced grid view that offers better visibility into task status and history. Users will appreciate the addition of dark mode support, which reduces eye strain during extended use, and the overall faster performance that’s especially noticeable when working with large DAGs.
The new UI maintains familiar workflows while providing a more modern and efficient experience for DAG management and monitoring, making daily operations more productive for both developers and operators. The legacy UI has been completely removed, offering a cleaner, more consistent experience across the system. The foundation for the new UI is built on REST APIs and a set of internal APIs for UI operations, both of which are now based on FastAPI, creating a more cohesive and secure architecture for both programmatic access and UI operations.
Scheduler optimizations
Amazon MWAA with Airflow 3’s enhanced scheduler delivers performance improvements for task execution and workflow management. The redesigned scheduling engine processes tasks more efficiently, reducing the time between task submissions and executions. This optimization benefits data pipeline operations that require rapid task processing and timely workflow completion.
The scheduler now manages computing resources more effectively, enabling stable performance even as workloads scale. When running multiple DAGs simultaneously, the improved resource allocation system helps prevent bottlenecks and maintains consistent execution speeds. This advancement is particularly useful for organizations running complex workflows with varying resource requirements. The new scheduler also handles concurrent operations with increased precision, so teams can run multiple DAG instances simultaneously while maintaining system stability and predictable performance.
Enhanced scheduler backfill operations
Scheduler-managed backfill (the process of running DAGs for historical dates) moves operations from the CLI to the scheduler, providing centralized control and visibility through the Airflow UI. Amazon MWAA with Airflow 3 delivers important upgrades to the scheduler’s backfill capabilities, helping data teams process historical data more efficiently. The backfill process has been optimized for better performance, reducing the database load during these operations and making sure backfills can be completed more quickly, minimizing the impact on near real-time workflow execution.
Amazon MWAA with Airflow 3 also improves the management of backfill operations, with the scheduler providing better isolation between backfill jobs and supporting more efficient processing of historical datasets. Operators now have better monitoring tools to track the progress and status of their backfill jobs, resulting in more effective management of these critical data processing tasks.
Developer-focused improvements
Airflow 3 on Amazon MWAA delivers several enhancements designed to improve the developer experience, from simplified task definition to better workflow management capabilities.
Task SDK
The Task SDK provides a more intuitive way to define tasks and DAGs:
# Example using the Task SDK
from airflow.sdk import dag, task
from datetime import datetime
@dag(
start_date=datetime(2023, 1, 1),
schedule="@daily",
catchup=False
)
def modern_etl_workflow():
@task
def extract():
# Extract data from source
return {"data": [1, 2, 3, 4, 5]}
@task
def transform(input_data):
# Transform the data
return [x * 10 for x in input_data]
@task
def load(transformed_data):
# Load data to destination
print(f"Loading data: {transformed_data}")
# Define the workflow
extracted_data = extract()
transformed_data = transform(extracted_data["data"])
load(transformed_data)
# Instantiate the DAG
etl_dag = modern_etl_workflow()
This approach offers more intuitive data flow between tasks, better integrated development environment (IDE) support with improved type hinting, and more straightforward unit testing of task logic. The result is cleaner, more maintainable code that better represents the actual data flow of your pipelines. Teams adopting this pattern often find their DAGs become more readable and simpler to maintain over time, especially as workflows grow in complexity.
DAG versioning
Amazon MWAA with Airflow 3 includes basic DAG versioning capabilities that come by default with Airflow 3. Each time a DAG is modified and deployed, Airflow serializes and stores the DAG definition to preserve history. This automatic version tracking minimizes the need for manual record-keeping and ensures every modification is documented.
Through the Airflow UI, teams can access and review the history of their DAGs. This visual representation shows version numbers (v1, v2, v3, etc.) and helps teams understand how their workflows have evolved over time.
The DAG versioning supported in Amazon MWAA provides the capability to see different DAG versions that were run in the Airflow UI, offering improved workflow visibility and enhanced collaboration for data engineering teams managing complex, evolving data pipelines.
Python 3.12 support
Amazon MWAA adds support for Python 3.12, bringing the latest language capabilities to workflow development. This upgrade provides access to the latest Python language improvements, performance enhancements, and library updates, keeping your data pipelines modern and efficient.
Features not currently supported in Amazon MWAA
Although we are launching most of the Airflow 3 features on Amazon MWAA in this release, some features are not supported at this time:
DAG versioning (AIP-63) – Advanced versioning features beyond basic version tracking
Replace Flask AppBuilder (AIP-79) – Full replacement capabilities
Edge Executor and task isolations (AIP-69) – Remote execution capabilities
Multi-language support (AIP-72) – Support for languages other than Python
We plan to support these features in subsequent versions of Airflow on Amazon MWAA.
Conclusion
Airflow 3 on Amazon MWAA delivers enhanced workflow automation capabilities. The architectural improvements, enhanced security model, and developer-friendly features provide a solid foundation for building more reliable and maintainable data pipelines.The introduction of Asset Watchers changes how workflows can respond to external events, enabling truly event-driven scheduling. This capability, combined with the new asset-centric workflow design, makes Airflow 3 a more powerful and flexible orchestration service.
The scheduler optimizations deliver performance improvements for task execution and workflow management, and the enhanced backfill capabilities make historical data processing more efficient. The DAG versioning system improves workflow stability and collaboration, and Python 3.12 support keeps your data pipelines modern and efficient.
Organizations can now take advantage of these new features and improvements in Airflow 3 on Amazon MWAA to enhance their workflow orchestration capabilities. To get started, visit the Amazon MWAA product page.
About the authors
Anurag Srivastava works as a Senior Big Data Cloud Engineer at Amazon Web Services (AWS), specializing in Amazon MWAA. He’s passionate about helping customers build scalable data pipelines and workflow automation solutions on AWS.
Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect, Amazon MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on LinkedIn to keep up to date with the latest Amazon MWAA and AWS Glue features and news!
Ankit Sahu brings over 18 years of expertise in building innovative digital products and services. His diverse experience spans product strategy, go-to-market execution, and digital transformation initiatives. Currently, Ankit serves as Senior Product Manager at Amazon Web Services (AWS), where he leads the Amazon MWAA service.
Mohammad Sabeel works as a Senior Cloud Support Engineer at Amazon Web Services (AWS), specializing in AWS Analytics services including AWS Glue, Amazon MWAA, and Amazon Athena. With over 14 years of IT experience, he’s passionate about helping customers build scalable data processing pipelines and optimize their analytics solutions on AWS.
Satya Chikkala is a Solutions Architect at Amazon Web Services. Based in Melbourne, Australia, he works closely with enterprise customers to accelerate their cloud journey. Beyond work, he is very passionate about nature and photography.
Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backward from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data system transformations across industry verticals. His core area of expertise include technology strategy, data analytics, and data science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla.
Orchestrating machine learning pipelines is complex, especially when data processing, training, and deployment span multiple services and tools. In this post, we walk through a hands-on, end-to-end example of developing, testing, and running a machine learning (ML) pipeline using workflow capabilities in Amazon SageMaker, accessed through the Amazon SageMaker Unified Studio experience. These workflows are powered by Amazon Managed Workflows for Apache Airflow (Amazon MWAA).
While SageMaker Unified Studio includes a visual builder for low-code workflow creation, this guide focuses on the code-first experience: authoring and managing workflows as Python-based Apache Airflow DAGs (Directed Acyclic Graphs). A DAG is a set of tasks with defined dependencies, where each task runs only after its upstream dependencies are complete, promoting correct execution order and making your ML pipeline more reproducible and resilient.We’ll walk through an example pipeline that ingests weather and taxi data, transforms and joins datasets, and uses ML to predict taxi fares—all orchestrated using SageMaker Unified Studio workflows.
This solution demonstrates how SageMaker Unified Studio workflows can be used to orchestrate a complete data-to-ML pipeline in a centralized environment. The pipeline runs through the following sequential tasks, as shown in the preceding diagram.
Task 1: Ingest and transform weather data: This task uses a Jupyter notebook in SageMaker Unified Studio to ingest and preprocess synthetic weather data. The synthetic weather dataset includes hourly observations with attributes such as time, temperature, precipitation, and cloud cover. For this task, the focus is on time, temperature, rain, precipitation, and wind speed.
Task 2: Ingest, transform and join taxi data: A second Jupyter notebook in SageMaker Unified Studio ingests the raw New York City taxi ride dataset. This dataset includes attributes such as pickup time, drop-off time, trip distance, passenger count, and fare amount. The relevant fields for this task include pickup and drop-off time, trip distance, number of passengers, and total fare amount. The notebook transforms the taxi dataset in preparation for joining it with the weather data. After transformation, the taxi and weather datasets are joined to create a unified dataset, which is then written to Amazon S3 for downstream use.
Task 3: Train and predict using ML: A third Jupyter notebook in SageMaker Unified Studio applies regression techniques to the joined dataset to create a model to determine how attributes of the weather and taxi data such as rain and trip distance impact taxi fares and create a fare prediction model. The trained model is then used to generate fare predictions for new trip data.
This unified approach enables orchestration of extract, transform, and load (ETL) and ML steps with full visibility into the data lifecycle and reproducibility through governed workflows in SageMaker Unified Studio.
Sign in to your SageMaker Unified Studio domain: Use the domain you created in Step 1 sign in. For more information, see Access Amazon SageMaker Unified Studio.
Create a SageMaker Unified Studio project: Create a new project in your domain by following the project creation guide. For Project profile, select All capabilities.
Set up workflows
You can use workflows in SageMaker Unified Studio to set up and run a series of tasks using Apache Airflow to design data processing procedures and orchestrate your querybooks, notebooks, and jobs. You can create workflows in Python code, test and share them with your team, and access the Airflow UI directly from SageMaker Unified Studio. It provides features to view workflow details, including run results, task completions, and parameters. You can run workflows with default or custom parameters and monitor their progress. Now that you have your SageMaker Unified Studio project set up, you can build your workflows.
In your SageMaker Unified Studio project, navigate to the Compute section and select Workflow environment.
Choose Create environment to set up a new workflow environment.
Review the options and choose Create environment. By default, SageMaker Unified Studio creates an mw1.micro class environment, which is suitable for testing and small-scale workflows. To update the environment class before project creation, navigate to Domain and select Project Profiles and then All Capabilities and go to OnDemand Workflows blueprint deployment settings. By using these settings, you can override default parameters and tailor the environment to your specific project requirements.
Develop workflows
You can use workflows to orchestrate notebooks, querybooks, and more in your project repositories. With workflows, you can define a collection of tasks organized as a DAG that can run on a user-defined schedule.To get started:
Go to Build and select JupyterLab; choose Upload files and import the three notebooks you downloaded in the previous step.
Configure your SageMaker Unified Studio space: Spaces are used to manage the storage and resource needs of the relevant application. For this demo, configure the space with an ml.m5.8xlarge instance
Choose Configure Space in the right-hand corner and stop the space.
Update instance type to ml.m5.8xlarge and start the space. Any active processes will be paused during the restart, and any unsaved changes will be lost. Updating the workspace might take a take few minutes.
Go to Build and select Orchestration and then Workflows.
Select the down arrow (▼) next to Create new workflow. From the dropdown menu that appears, select Create in code editor.
In the editor, create a new Python file named multinotebook_dag.py under src/workflows/dags. Copy the following DAG code, which implements a sequential ML pipeline that orchestrates multiple notebooks in SageMaker Unified Studio. Replace <REPLACE-OWNER> with your username. Update NOTEBOOK_PATHS to match your actual notebook locations.
from airflow.decorators import dag
from airflow.utils.dates import days_ago
from workflows.airflow.providers.amazon.aws.operators.sagemaker_workflows import NotebookOperator
WORKFLOW_SCHEDULE = '@daily'
NOTEBOOK_PATHS = [
'<REPLACE FULL PATH FOR Weather_Data_Ingestion.ipynb>',
'<REPLACE FULL PATH FOR Taxi_Weather_Data_Collection.ipynb>',
'<REPLACE FULL PATH FOR Prediction.ipynb>'
]
default_args = {
'owner': '<REPLACE-OWNER>',
}
@dag(
dag_id='workflow-multinotebooks',
default_args=default_args,
schedule_interval=WORKFLOW_SCHEDULE,
start_date=days_ago(2),
is_paused_upon_creation=False,
tags=['MLPipeline'],
catchup=False
)
def multi_notebook():
previous_task = None
for idx, notebook_path in enumerate(NOTEBOOK_PATHS, 1):
current_task = NotebookOperator(
task_id=f"Notebook{idx}task",
input_config={'input_path': notebook_path, 'input_params': {}},
output_config={'output_formats': ['NOTEBOOK']},
wait_for_completion=True,
poll_interval=5
)
# Ensure tasks run sequentially
if previous_task:
previous_task >> current_task
previous_task = current_task # Update previous task
multi_notebook()
The code uses the NotebookOperator to execute three notebooks in order: data ingestion for weather data, data ingestion for taxi data, and the trained model created by combining the weather and taxi data. Each notebook runs as a separate task, with dependencies to help ensure that they execute in sequence. You can customize with your own notebooks. You can modify the NOTEBOOK_PATHS list to orchestrate any number of notebooks in their workflow while maintaining sequential execution order.
The workflow schedule can be customized by updating WORKFLOW_SCHEDULE (for example: '@hourly', '@weekly', or cron expressions like ‘13 2 1 * *’) to match your specific business needs.
To validate your DAG, Go to Build > Orchestration > Workflows. You should now see the workflow running in Local Space based on the Schedule.
Once the execution completes, workflow would change to success start as shown below.
For each execution, you can zoom in to get a detailed workflow run details and task logs
Access the airflow UI from actions for more information on the dag and execution.
Results
The model’s output is written to the Amazon Simple Storage Service (Amazon S3) output folder as shown the following figure. These results should be evaluated for correctness of fit, prediction accuracy, and the consistency of relationships between variables. If any results appear unexpected or unclear, it is important to review the data, engineering steps, and model assumptions to verify that they align with the intended use case.
Clean up
To avoid incurring additional charges associated with resources created as part of this post, make sure you delete the items created in the AWS account for this post.
The SageMaker domain
The S3 bucket associated with the SageMaker domain
Conclusion
In this post, we demonstrated how you can use Amazon SageMaker to build powerful, integrated ML workflows that span the full data and AI/ML lifecycle. You learned how to create an Amazon SageMaker Unified Studio project, use a multi-compute notebook to process data, and use the built-in SQL editor to explore and visualize results. Finally, we showed you how to orchestrate the entire workflow within the SageMaker Unified Studio interface.
SageMaker offers a comprehensive set of capabilities for data practitioners to perform end-to-end tasks, including data preparation, model training, and generative AI application development. When accessed through SageMaker Unified Studio, these capabilities come together in a single, centralized workspace that helps eliminate the friction of siloed tools, services, and artifacts.
As organizations build increasingly complex, data-driven applications, teams can use SageMaker, together with SageMaker Unified Studio, to collaborate more effectively and operationalize their AI/ML assets with confidence. You can discover your data, build models, and orchestrate workflows in a single, governed environment.
Effective collaboration and scalability are essential for building efficient data pipelines. However, data modeling teams often face challenges with complex extract, transform, and load (ETL) tools, requiring programming expertise and a deep understanding of infrastructure. This complexity can lead to operational inefficiencies and challenges in maintaining data quality at scale.
dbt addresses these challenges by providing a simpler approach where data teams can build robust data models using SQL, a language they’re already familiar with. When integrated with modern development practices, dbt projects can use version control for collaboration, incorporate testing for data quality, and utilize reusable components through macros. dbt also automatically manages dependencies, making sure data transformations execute in the correct sequence.
In this post, we explore a streamlined, configuration-driven approach to orchestrate dbt Core jobs using Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and Cosmos, an open source package. These jobs run transformations on Amazon Redshift, a fully managed data warehouse that enables fast, scalable analytics using standard SQL. With this setup, teams can collaborate effectively while maintaining data quality, operational efficiency, and observability. Key steps covered include:
Creating a sample dbt project
Enabling auditing within the dbt project to capture runtime metrics for each model
Creating a GitHub Actions workflow to automate deployments
These enhancements enable model-level auditing, automated deployments, and real-time failure alerts. By the end of this post, you will have a practical and scalable framework for running dbt Core jobs with Cosmos on Amazon MWAA, so your team can ship reliable data workflows faster.
Solution overview
The following diagram illustrates the solution architecture.
The workflow contains the following steps:
Analytics engineers manage their dbt project in their version control tool. In this post, we use GitHub as an example.
We configure an Apache Airflow Directed Acyclic Graph (DAG) to use the Cosmos library to create an Airflow task group that contains all the dbt models as part of the dbt project.
We use a GitHub Actions workflow to sync the dbt project files and the DAG to an Amazon Simple Storage Service (Amazon S3) bucket.
During the DAG run, dbt converts the models, tests, and macros to Amazon Redshift SQL statements, which run directly on the Redshift cluster.
If a task in the DAG fails, the DAG invokes an AWS Lambda function to send out a notification using Amazon SNS.
Prerequisites
You must have the following prerequisites:
A Redshift provisioned cluster or a Redshift serverless workgroup. For creation instructions, refer to the Amazon Redshift Management Guide.
Network connectivity from Amazon MWAA to Amazon Redshift. Deploy Amazon MWAA and your Redshift cluster in the same virtual private cloud (VPC). Add an Amazon MWAA security group as a source for the Redshift security group inbound rule.
A dbt project is structured to facilitate modular, scalable, and maintainable data transformations. The following code is a sample dbt project structure that this post will follow:
dbt_project.yml – Serves as the main configuration for your project. Objects in this project will inherit settings defined here unless overridden at the model level. For example:
# Name your project! Project names should contain only lowercase characters
# and underscores.
name: 'my_sample_dbt_project'
version: '1.0.0'
# These configurations specify where dbt should look for different types of files.
# The `model-paths` config, for example, states that models in this project can be
# found in the "models/" directory.
model-paths: ["models"]
macro-paths: ["macros"]
# Configuring models
# Full documentation: https://docs.getdbt.com/docs/configuring-models
# In this example config, we tell dbt to build models in the example/
# directory as views. These settings can be overridden in the individual model
# files using the `{{ config(...) }}` macro.
models:
my_sample_dbt_project:
# Config indicated by + and applies to files under models/example/
example:
+materialized: view
on-run-end:
# add run results to audit table
- "{{ log_audit_table(results) }}"
sources.yml – Defines the external data sources that your dbt models will reference. For example:
schema.yml – Outlines the schema of your models and data quality tests. In the following example, we have defined two columns, full_name for the model model1 and sales_id for model2. We have declared them as the primary key and defined data quality tests to check if the two columns are unique and not null.
Enabling auditing within your dbt project is crucial for facilitating transparency, traceability, and operational oversight across your data pipeline. You can capture run metrics at the model level for each execution in an audit table. By capturing detailed run metrics such as load identifier, runtime, and number of rows affected, teams can systematically monitor the health and performance of each load, quickly identify issues, and trace changes back to specific runs.
The audit table consists of the following attributes:
load_id – An identifier for each model run executed as part of the load
database_name – The name of the database within which data is being loaded
schema_name – The name of the schema within which data is being loaded
name – The name of the object within which data is being loaded
resource_type – The type of object to which data is being loaded
execution_time – The time duration taken for each dbt model to complete execution as part of each load
rows_affected – The number of rows affected in the dbt model as part of the load
Complete the following steps to enable auditing within your dbt project:
Navigate to the models directory (src/my_sample_dbt_project/models) and create the audit_table.sql model file:
{%- set run_date = "CURRENT_DATE" -%}
{{
config(
materialized='incremental',
incremental_strategy='append',
tags=["audit"]
)
}}
with empty_table as (
select
'test_load_id'::varchar(200) as load_id,
'test_invocation_id'::varchar(200) as invocation_id,
'test_database_name'::varchar(200) as database_name,
'test_schema_name'::varchar(200) as schema_name,
'test_model_name'::varchar(200) as name,
'test_resource_type'::varchar(200) as resource_type,
'test_status'::varchar(200) as status,
cast('12122012' as float) as execution_time,
cast('100' as int) as rows_affected,
{{run_date}} as model_execution_date
)
select * from empty_table
-- This is a filter so we will never actually insert these values
where 1 = 0
Navigate to the macros directory (src/my_sample_dbt_project/macros) and create the parse_dbt_results.sql macro file:
{% macro parse_dbt_results(results) %}
-- Create a list of parsed results
{%- set parsed_results = [] %}
-- Flatten results and add to list
{% for run_result in results %}
-- Convert the run result object to a simple dictionary
{% set run_result_dict = run_result.to_dict() %}
-- Get the underlying dbt graph node that was executed
{% set node = run_result_dict.get('node') %}
{% set rows_affected = run_result_dict.get(
'adapter_response', {}).get('rows_affected', 0) %}
{%- if not rows_affected -%}
{% set rows_affected = 0 %}
{%- endif -%}
{% set parsed_result_dict = {
'load_id': invocation_id ~ '.' ~ node.get('unique_id'),
'invocation_id': invocation_id,
'database_name': node.get('database'),
'schema_name': node.get('schema'),
'name': node.get('name'),
'resource_type': node.get('resource_type'),
'status': run_result_dict.get('status'),
'execution_time': run_result_dict.get('execution_time'),
'rows_affected': rows_affected
}%}
{% do parsed_results.append(parsed_result_dict) %}
{% endfor %}
{{ return(parsed_results) }}
{% endmacro %}
Navigate to the macros directory (src/my_sample_dbt_project/macros) and create the log_audit_table.sql macro file:
{% macro log_audit_table(results) %}
-- depends_on: {{ ref('audit_table') }}
{%- if execute -%}
{{ print("Running log_audit_table Macro") }}
{%- set run_date = "CURRENT_DATE" -%}
{%- set parsed_results = parse_dbt_results(results) -%}
{%- if parsed_results | length > 0 -%}
{% set allowed_columns = ['load_id', 'invocation_id', 'database_name',
'schema_name', 'name', 'resource_type', 'status', 'execution_time',
'rows_affected', 'model_execution_date'] -%}
{% set insert_dbt_results_query -%}
insert into {{ ref('audit_table') }}
(
load_id,
invocation_id,
database_name,
schema_name,
name,
resource_type,
status,
execution_time,
rows_affected,
model_execution_date
) values
{%- for parsed_result_dict in parsed_results -%}
(
{%- for column, value in parsed_result_dict.items() %}
{% if column not in allowed_columns %}
{{ exceptions.raise_compiler_error("Invalid
column") }}
{% endif %}
{% set sanitized_value = value | replace("'", "''") %}
'{{ sanitized_value }}'
{%- if not loop.last %}, {% endif %}
{%- endfor -%}
)
{%- if not loop.last %}, {% endif %}
{%- endfor -%}
{%- endset -%}
{%- do run_query(insert_dbt_results_query) -%}
{%- endif -%}
{%- endif -%}
{{ return ('') }}
{% endmacro %}
Append the following lines to the dbt_project.yml file:
on-run-end:
- "{{ log_audit_table(results) }}"
Create a GitHub Actions workflow
This step is optional. If you prefer, you can skip it and instead upload your files directly to your S3 bucket.
The following GitHub Actions workflow automates the deployment of dbt project files and DAG file to Amazon S3. Replace the placeholders {s3_bucket_name}, {account_id}, {role_name}, and {region} with your S3 bucket name, account ID, IAM role name, and AWS Region in the workflow file.
To enhance security, it’s recommended to use OpenID Connect (OIDC) for authentication with IAM roles in GitHub Actions instead of relying on long-lived access keys.
name: Sync dbt Project with S3
on:
workflow_dispatch:
push:
branches: [ main ]
paths:
- "src/**"
permissions:
id-token: write # This is required for requesting the JWT
contents: read # This is required for actions/checkout
pull-requests: write
jobs:
sync-dev:
runs-on: ubuntu-latest
environment: dev
defaults:
run:
shell: bash
steps:
- uses: actions/checkout@v4
- name: Assume AWS IAM Role
uses: aws-actions/[email protected]
with:
aws-region: {region}
role-to-assume: arn:aws:iam::{account_id}:role/{role_name}
role-session-name: my_sample_dbt_project_${{ github.run_id }}
role-duration-seconds: 3600 # 1 hour
- run: aws sts get-caller-identity
- name: Sync dbt Model files
id: dbt_project_files
working-directory: src/my_sample_dbt_project
run: aws s3 sync . s3://{s3_bucket_name}/dags/dbt/my_sample_dbt_project
--delete
continue-on-error: false
- name: Sync DAG files
id: dag_file
working-directory: src/dags
run: aws s3 sync . s3://{s3_bucket_name}/dags
GitHub has the following security requirements:
Branch protection rules – Before proceeding with the GitHub Actions workflow, make sure branch protection rules are in place. These rules enforce required status checks before merging code into protected branches (such as main).
Code review guidelines – Implement code review processes to make sure changes undergo review. This can include requiring at least one approving review before code is merged into the protected branch.
Incorporate security scanning tools – This can help detect vulnerabilities in your repository.
Make sure you are also adhering to dbt-specific security best practices:
Pay attention to dbt macros with variables and validate their inputs.
When adding new packages to your dbt project, evaluate their security, compatibility, and maintenance status to make sure they don’t introduce vulnerabilities or conflicts into your project.
Review dynamically generated SQL to safeguard against issues like SQL injection.
Update the Amazon MWAA instance
Complete the following steps to update the Amazon MWAA instance:
Install the Cosmos library on Amazon MWAA by adding astronomer-cosmos in the requirements.txt file. Make sure to check for version compatibility for Amazon MWAA and the Cosmos library.
Add the following entries in your startup.sh script:
In the following code, DBT_VENV_PATH specifies the location where the Python virtual environment for dbt will be created. DBT_PROJECT_PATH points to the location of your dbt project inside Amazon MWAA.
The following code creates a Python virtual environment at the path ${DBT_VENV_PATH} and installs the dbt-redshift adapter to run dbt transformations on Amazon Redshift:
Create a dbt user in Amazon Redshift and store credentials
To create dbt models in Amazon Redshift, you must set up a native Redshift user with the necessary permissions to access source tables and create new tables. It is essential to create separate database users with minimal permissions to follow the principle of least privilege. The dbt user should not be granted admin privileges, instead, it should only have access to the specific schemas required for its tasks.
We create one Redshift connection in Amazon MWAA for each Redshift database, making sure that each data pipeline (DAG) can only access one database. This approach provides distinct access controls for each pipeline, helping prevent unauthorized access to data. Complete the following steps:
Log in to the Amazon MWAA UI.
On the Admin menu, choose Connections.
Choose Add a new record.
For Connection Id, enter a name for this connection.
For Connection Type, choose Amazon Redshift.
For Host, enter the endpoint of the Redshift cluster without the port and database name (for example, redshift-cluster-1.xxxxxx.us-east-1.redshift.amazonaws.com).
For Database, enter the database of the Redshift cluster.
For Port, enter the port of the Redshift cluster.
Set up an SNS notification
Setting up SNS notifications is optional, but they can be a useful enhancement to receive alerts on failures. Complete the following steps:
Modify the function code in your Lambda function, and replace {topic_arn} with your SNS topic Amazon Resource Name (ARN):
import json
sns_client = boto3.client('sns')
def lambda_handler(event, context):
try:
# Extract DAG name from event
failed_dag = event['dag_name']
# Send notification
sns_client.publish(
TopicArn={topic_arn},
Subject="Data modelling dags - WARNING",
Message=json.dumps({'default': json.dumps(f"Data modelling DAG -
{failed_dag} has failed, please inform the data modelling team")}),
MessageStructure='json'
)
except KeyError as e:
# Handle missing 'dag_name' in the event
logger.error(f"KeyError: invalid payload - dag_name not present")
Configure a DAG
The following sample DAG orchestrates a dbt workflow for processing and auditing data models in Amazon Redshift. It retrieves credentials from Secrets Manager, runs dbt tasks in a virtual environment, and sends an SNS notification if a failure occurs. The workflow consists of the following steps:
It starts with the audit_dbt_task task group, which creates the audit model.
The transform_data task group executes the other dbt models, excluding the audit-tagged one. Inside the transform_data group, there are two dbt models, model1 and model2, and each is followed by a corresponding test task that runs data quality tests defined in the schema.yml file.
To properly detect and handle failures, the DAG includes a dbt_check Python task that runs a custom function, check_dbt_failures. This is important because when using DbtTaskGroup, individual model-level failures inside the group don’t automatically propagate to the task group level. As a result, downstream tasks (such as the Lambda operator sns_notification_for_failure) configured with trigger_rule='one_failed' will not be triggered unless a failure is explicitly raised.
The check_dbt_failures function addresses this by inspecting the results of each dbt model and test, and raising an AirflowException if a failure is found. When an AirflowException is raised, the sns_notification_for_failure task is triggered.
If a failure occurs, the sns_notification_for_failure task invokes a Lambda function to send an SNS notification. If no failures are detected, this task is skipped.
The following diagram illustrates this workflow.
Configure DAG variables
To customize this DAG for your environment, configure the following variables:
project_name – Make sure the project_name matches the S3 prefix of your dbt project
secret_name – Provide the name of the secret that stores dbt user credentials
target_database and target_schema – Update these variables to reflect where you want to land your dbt models in Amazon Redshift
redshift_connection_id – Set this to match the connection configured in Amazon MWAA for this Redshift database
sns_lambda_function_name – Provide the Lambda function name to send SNS notifications
dag_name – Provide the DAG name that will be passed to the SNS notification Lambda function
import os
import json
import boto3
from airflow import DAG
from cosmos import (
DbtTaskGroup, ProfileConfig, ProjectConfig,
ExecutionConfig, RenderConfig
)
from cosmos.constants import ExecutionMode, LoadMode
from cosmos.profiles import RedshiftUserPasswordProfileMapping
from pendulum import datetime
from airflow.operators.python_operator import PythonOperator
from airflow.providers.amazon.aws.operators.lambda_function import (
LambdaInvokeFunctionOperator
)
from airflow.exceptions import AirflowException
# project name - should match the s3 prefix of your dbt project
project_name = "my_sample_dbt_project"
# name of the secret that stores dbt user credentials
secret_name = "dbt_user_credentials_secret"
# target database to land dbt models
target_database = "sample_database"
# target schema to land dbt models
target_schema = "sample_schema"
# Redshift connection name from MWAA
redshift_connection_id = "my_sample_dbt_project_connection"
# sns lambda function name
sns_lambda_function_name = "sns_notification"
# dag name - this will be passed to SNS for notification
payload = json.dumps({
"dag_name": "my_sample_dbt_project_dag"
})
Incorporate DAG components
After setting the variables, you can now incorporate the following components to complete the DAG.
Secrets Manager
The DAG retrieves dbt user credentials from Secrets Manager:
Audit dbt task group (audit_dbt_task) – Runs the dbt model tagged with audit
dbt task group (transform_data) – Runs the dbt models tagged with operations, excluding the audit model
In dbt, tags are labels that you can assign to models, tests, seeds, and other dbt resources to organize and selectively run subsets of your dbt project. In your render_config, you have exclude=["tag:audit"]. This means dbt will exclude models that have the tag audit, because the audit model runs separately.
Failure check (dbt_check) – Checks for dbt model failures, raises an AirflowException if upstream dbt tasks fail
SNS notification on failure (sns_notification_for_failure) – Invokes a Lambda function to send an SNS notification upon a dbt task failure (for example, a dbt model in the task group)
The sample dbt orchestrates a dbt workflow in Amazon Redshift, starting with an audit task and followed by a task group that processes data models. It includes a failure handling mechanism that checks for failures and raises an exception to trigger an SNS notification using Lambda if a failure occurs. If no failures are detected, the SNS notification task is skipped.
Clean up
If you no longer need the resources you created, delete them to avoid additional charges. This includes the following:
Amazon MWAA environment
S3 bucket
IAM role
Redshift cluster or serverless workgroup
Secrets Manager secret
SNS topic
Lambda function
Conclusion
By integrating dbt with Amazon Redshift and orchestrating workflows using Amazon MWAA and the Cosmos library, you can simplify data transformation workflows while maintaining robust engineering practices. The sample dbt project structure, combined with automated deployments through GitHub Actions and proactive monitoring using Amazon SNS, provides a foundation for building reliable data pipelines. The addition of audit logging facilitates transparency across your transformations, so teams can maintain high data quality standards.
You can use this solution as a starting point for your own dbt implementation on Amazon MWAA. The approach we outlined emphasizes SQL-based transformations while incorporating essential operational capabilities like deployment automation and failure alerting. Get started by adapting the configuration to your environment, and build upon these practices as your data needs evolve.
Cindy Li is an Associate Cloud Architect at AWS Professional Services, specialising in Data Analytics. Cindy works with customers to design and implement scalable data analytics solutions on AWS. When Cindy is not diving into tech, you can find her out on walks with her playful toy poodle Mocha.
Akhil B is a Data Analytics Consultant at AWS Professional Services, specializing in cloud-based data solutions. He partners with customers to design and implement scalable data analytics platforms, helping organizations transform their traditional data infrastructure into modern, cloud-based solutions on AWS. His expertise helps organizations optimize their data ecosystems and maximize business value through modern analytics capabilities.
Joao Palma is a Senior Data Architect at Amazon Web Services, where he partners with enterprise customers to design and implement comprehensive data platform solutions. He specializes in helping organizations transform their data into strategic business assets and enabling data-driven decision making.
Harshana Nanayakkara is a Delivery Consultant at AWS Professional Services, where he helps customers tackle complex business challenges using AWS Cloud technology. He specializes in data and analytics, data governance, and AI/ML implementations.
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) has become a cornerstone for organizations embracing data-driven decision-making. As a scalable solution for managing complex data pipelines, Amazon MWAA enables seamless orchestration across AWS services and on-premises systems. Although AWS manages the underlying infrastructure, you must carefully plan and execute your Amazon MWAA environment updates according to the shared responsibility model. Upgrading to the latest Amazon MWAA version can provide significant advantages, including enhanced security through critical security patches and potential improvements in performance with faster DAG parsing and reduced database load. You can use advanced features while maintaining ecosystem compatibility and receiving prioritized AWS support. The key to successful upgrades lies in choosing the right solution and following a methodical implementation approach.
In this post, we explore best practices for upgrading your Amazon MWAA environment and provide a step-by-step guide to seamlessly transition to the latest version.
Solution overview
Amazon MWAA provides two primary upgrade solutions:
In-place upgrade – This method works best when you can accommodate planned downtime. You deploy the new version directly on your existing infrastructure. In-place version upgrades on Amazon MWAA are supported for environments running Apache Airflow version 2.x and later. However, if you’re running version 1.10.z or older versions, you must create a new environment and migrate your resources, because these versions don’t support in-place upgrades.
Cutover upgrade – This method helps minimize disruption to production environments. You create a new Amazon MWAA environment with the target version and then transition from your old environment to the new one.
Each solution offers a different approach to help you upgrade while working to maintain data integrity and system reliability.
In-place upgrade
In-place upgrades work well for environments where you can schedule a maintenance window for the upgrade process. During this window, Amazon MWAA preserves your workflow history. This method works best when you can accommodate planned downtime. It helps maintain historical data, provides a straightforward upgrade process, and includes rollback capabilities if issues occur during provisioning. You also use fewer resources because you don’t need to create a new environment.
You can perform in-place upgrades through the AWS Management Console with a single operation. This process helps reduce operational overhead by managing many upgrade steps for you.
During the upgrade process, your environment can’t schedule or run new tasks. Amazon MWAA helps manage the upgrade process and implements safety measures—if issues occur during the provisioning phase, the service attempts to revert to the previous stable version.
Before you begin an in-place upgrade, we recommend testing your DAGs for compatibility with the target version, because DAG compatibility issues can affect the upgrade process. You can use the Amazon MWAA local runner to test DAG compatibility before you start the upgrade. You can start the upgrade using either the console and specifying the new version or the AWS Command Line Interface (AWS CLI). The following is an example Amazon MWAA upgrade command using the AWS CLI:
A cutover upgrade provides an alternative solution when you need to minimize downtime, though it requires more manual steps and operational planning. With this approach, you create a new Amazon MWAA environment, migrate your metadata, and manage the transition between environments. Although this method offers more control over the upgrade process, it requires additional planning and execution effort compared to an in-place upgrade.
This method can work well for environments with complex workflows, particularly when you plan to make significant changes alongside the version upgrade. The approach offers several benefits: you can minimize production downtime, perform comprehensive testing before switching environments, and maintain the ability to return to your original environment if needed. You can also review and update your configurations during the transition.
Consider the following aspects of the cutover approach. When you run two environments simultaneously, you pay for both environments. The pricing for each Amazon MWAA environment depends on:
Duration of environment uptime (billed hourly with per-second resolution)
Environment size configuration
Automatic scaling capacity for workers
Scheduler capacity
AWS calculates the cost of additional automatic scaled workers separately. You can estimate costs for your specific configuration using the AWS Pricing Calculator.
To help prevent data duplication or corruption during parallel operation, we recommend implementing idempotent DAGs. The Airflow scheduler automatically populates some metadata tables (dag, dag_tag, and dag_code) in your new environment. However, you need to plan the migration of the following additional metadata components:
DAG history
Variables
Slot pool configurations
SLA miss records
XCom data
Job records
Log tables
You can choose this approach when your requirements prioritize minimal downtime and you can manage the additional operational complexity.
The cutover upgrade process involves three main steps: creating a new environment, restoring it with the existing data, and performing the upgrade. The following diagram illustrates the full workflow.
In the following sections, we walk through the key steps to perform a cutover upgrade.
Prerequisites
Before you begin the upgrade process, complete the following steps:
Plan your transition timing carefully. When your original environment continues to process workflows during this upgrade, the metadata between environments can change.
Clean up
After you verify the stability of your upgraded environment through monitoring, you can begin the cleanup process:
Remove your original Amazon MWAA environment using the AWS CLI command:
aws mwaa delete-environment --name <old-env-name>
Clean up your associated resources by removing unused backup data from S3 buckets, deleting temporary AWS Identity and Access Management (IAM) roles and policies created for the upgrade, and updating your DNS or routing configurations.
Before removing any resources, make sure you follow your organization’s backup retention policies, maintain necessary backup data for your compliance requirements, and document configuration changes made during the upgrade.
This approach helps you perform a controlled upgrade with opportunities for testing and the ability to return to your original environment if needed.
Monitoring and validation
You can track your upgrade progress using Amazon CloudWatch metrics, with a focus on DAG processing metrics and scheduler heartbeat. Your environment transitions through several states during the upgrade process, including UPDATING and CREATING. When your environment shows the AVAILABLE state, you can begin validation testing. We recommend checking system accessibility, testing critical workflow operations, and verifying external connections. For detailed monitoring guidance, see Monitoring and metrics for Amazon Managed Workflows for Apache Airflow.
Key considerations
Consider using infrastructure as code (IaC) practices to help maintain consistent environment management and support repeatable deployments. Schedule metadata backups using mwaa-dr during periods of low activity to help protect your data. When designing your workflows, implement idempotent pipelines to help manage potential interruptions, and maintain documentation of your configurations and dependencies.
Conclusion
A successful Amazon MWAA upgrade starts with selecting an approach that aligns with your operational requirements. Whether you choose an in-place or cutover upgrade, thorough preparation and testing help support a controlled transition. Using available tools, monitoring capabilities, and recommended practices can help you upgrade to the latest Amazon MWAA features while working to maintain your workflow operations.
Apache, Apache Airflow, and Airflow are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
About the Authors
Anurag Srivastava works as a Senior Big Data Cloud Engineer at Amazon Web Services (AWS), specializing in Amazon MWAA. He’s passionate about helping customers build scalable data pipelines and workflow automation solutions on AWS.
Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla.
Venu Thangalapally is a Senior Solutions Architect at AWS, based in Chicago, with deep expertise in cloud architecture, data and analytics, containers, and application modernization. He partners with Financial Services industry customers to translate business goals into secure, scalable, and compliant cloud solutions that deliver measurable value. Venu is passionate about leveraging technology to drive innovation and operational excellence. Outside of work, he enjoys spending time with his family, reading, and taking long walks.
Chandan Rupakheti is a Senior Solutions Architect at AWS. His main focus at AWS lies in the intersection of analytics, serverless, and AdTech services. He is a passionate technical leader, researcher, and mentor with a knack for building innovative solutions in the cloud. Outside of his professional life, he loves spending time with his family and friends, and listening to and playing music.
This is a guest post coauthored with LaunchDarkly.
The LaunchDarkly feature management platform equips software teams to proactively reduce the risk of shipping bad software and AI applications while accelerating their release velocity. In this post, we explore how LaunchDarkly scaled the internal analytics platform up to 14,000 tasks per day, with minimal increase in costs, after migrating from another vendor-managed Apache Airflow solution to AWS, using Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and Amazon Elastic Container Service (Amazon ECS). We walk you through the issues we ran into during the migration, the technical solution we implemented, the trade-offs we made, and lessons we learned along the way.
The challenge
LaunchDarkly has a mission to enable high-velocity teams to release, monitor, and optimize software in production. The centralized data team is responsible for tracking how LaunchDarkly is progressing toward that mission. Additionally, this team is responsible for the majority of the company’s internal data needs, which include ingesting, warehousing, and reporting on the company’s data. Some of the large datasets we manage include product usage, customer engagement, revenue, and marketing data.
As the company grew, our data volume increased, and the complexity and use cases of our workloads expanded exponentially. While using other vendor-managed Airflow-based solutions, our data analytics team faced new challenges on time to integrate and onboard new AWS services, data locality, and a non-centralized orchestration and monitoring solution across different engineering teams within the organization.
Solution overview
LaunchDarkly has a long history of using AWS services to solve business use cases, such as scaling our ingestion from 1 TB to 100 TB per day with Amazon Kinesis Data Streams. Similarly, migrating to Amazon MWAA helped us scale and optimize our internal extract, transform, and load (ETL) pipelines. We used existing monitoring and infrastructure as code (IaC) implementations and eventually extended Amazon MWAA to other teams, establishing it as a centralized batch processing solution orchestrating multiple AWS services.
The solution for our transformation jobs include the following components:
A central Amazon MWAA environment responsible for orchestration
An ECS cluster and AWS Fargate task definition for running tasks
With the flexibility and ease of integration within AWS ecosystem, iteratively make enhancements around containerization, logging, and continuous deployment.
Steps 1 and 2 were executed quickly—we used the Terraform AWS provider and the existing LaunchDarkly Terraform infrastructure to build a reusable Amazon MWAA module initially at Airflow version 1.12. We had an Amazon MWAA instance and the supporting pieces (CloudWatch and artifacts S3 bucket) running on AWS within a week.
When we started cutting over DAGs to Amazon MWAA in Step 3, we ran into some issues. At the time of migration, our Airflow code base was centered around a custom operator implementation that created a Python virtual environment for our workload requirements on the Airflow worker disk assigned to the task. By trial and error in our migration attempt, we learned that this custom operator was essentially dependent on the behavior and isolation of Airflow’s Kubernetes executors used in the original cloud provider platform. When we began to run our DAGs concurrently on Amazon MWAA (which uses Celery Executor workers that behave differently), we ran into a few transient issues where the behavior of that custom operator could affect other running DAGs.
At this time, we took a step back and evaluated solutions for promoting isolation between our running tasks, eventually landing on Fargate for ECS tasks that could be started from Amazon MWAA. We had initially planned to move our tasks to their own isolated system rather than having them run directly in Airflow’s Python runtime environment. Due to the circumstances, we decided to advance this requirement, transforming our rehosting project into a refactoring migration.
We chose Amazon ECS on Fargate for its ease of use, existing Airflow integrations (ECSRunTaskOperator), low cost, and lower management overhead compared to a Kubernetes-based solution such as Amazon Elastic Kubernetes Service (Amazon EKS). Although a solution using Amazon EKS would improve the task provisioning time even further, the Amazon ECS solution met the latency requirements of the data analytics team’s batch pipelines. This was acceptable because these queries run for several minutes on a periodic basis, so a couple more minutes for spinning up each ECS task didn’t significantly impact overall performance.
Our first Amazon ECS implementation involved a single container that downloads our project from an artifacts repository on Amazon S3, and runs the command passed to the ECS task. We trigger those tasks using the ECSRunTaskOperator in a DAG in Amazon MWAA, and created a wrapper around the built-in Amazon ECS operator, so analysts and engineers on the data analytics team could create new DAGs just by specifying the commands they were already familiar with.
The following diagram illustrates the DAG and task deployment flows.
When our initial Amazon ECS implementation was complete, we were able to cut all of our existing DAGs over to Amazon MWAA without the prior concurrency issues, because each task ran in its own isolated Amazon ECS task on Fargate.
Within a few months, we proceeded to Step 4 to upgrade our Amazon MWAA instance to Airflow 2. This was a major version upgrade (from 1.12 to 2.5.1), which we implemented by following the Amazon MWAA Migration Guide and subsequently tearing down our legacy resources.
The cost increase of adding Amazon ECS to our pipelines was minimal. This was because our pipelines run on batch schedules, and therefore aren’t active at all times, and Amazon ECS on Fargate only charges for vCPU and memory resources requested to complete the tasks.
As a part of Step 5 for continuous assessment and improvements, we enhanced our Amazon ECS implementation to push logs and metrics to Datadog and CloudWatch. We could monitor for errors and model performance, and catch data test failures alongside existing LaunchDarkly monitoring.
Scaling the solution beyond internal analytics
During the initial implementation for the data analytics team, we created an Amazon MWAA Terraform module, which enabled us to quickly spin up more Amazon MWAA environments and share our work with other engineering teams. This allowed the use of Airflow and Amazon MWAA to power batch pipelines within the LaunchDarkly product itself in a couple of months shortly after the data analytics team completed the initial migration.
Through our journey of orchestrating data pipelines at scale with Amazon MWAA and Amazon ECS, we’ve gained valuable insights and lessons that have shaped the success of our implementation. One of the key lessons learned was the importance of isolation. During the initial migration to Amazon MWAA, we encountered issues with our custom Airflow operator that relied on the specific behavior of the Kubernetes executors used in the original cloud provider platform. This highlighted the need for isolated task execution to maintain the reliability and scalability of our pipelines.
As we scaled our implementation, we also recognized the importance of monitoring and observability. We enhanced our monitoring and observability by integrating with tools like Datadog and CloudWatch, so we could better monitor errors and model performance and catch data test failures, improving the overall reliability and transparency of our data pipelines.
With the previous Airflow implementation, we were running approximately 100 Airflow tasks per day across one team and two services (Amazon ECS and Snowflake). As of the time of writing this post, we’ve scaled our implementation to three teams, four services, and execution of over 14,000 Airflow tasks per day. Amazon MWAA has become a critical component of our batch processing pipelines, increasing the speed of onboarding new teams, services, and pipelines to our data platform from weeks to days.
Looking ahead, we plan to continue iterating on this solution to expand our use of Amazon MWAA to additional AWS services such as AWS Lambda and Amazon Simple Queue Service (Amazon SQS), and further automate our data workflows to support even greater scalability as our company grows.
Conclusion
Effective data orchestration is essential for organizations to gather and unify data from diverse sources into a centralized, usable format for analysis. By automating this process across teams and services, businesses can transform fragmented data into valuable insights to drive better decision-making. LaunchDarkly has achieved this by using managed services like Amazon MWAA and adopting best practices such as task isolation and observability, enabling the company to accelerate innovation, mitigate risks, and shorten the time-to-value of its product offerings.
If your organization is planning to modernize its data pipelines orchestration, start assessing your current workflow management setup, exploring the capabilities of Amazon MWAA, and considering how containerization could benefit your workflows. With the right tools and approach, you can transform your data operations, drive innovation, and stay ahead of growing data processing demands.
About the Authors
Asena Uyar is a Software Engineer at LaunchDarkly, focusing on building impactful experimentation products that empower teams to make better decisions. With a background in mathematics, industrial engineering, and data science, Asena has been working in the tech industry for over a decade. Her experience spans various sectors, including SaaS and logistics, and she has spent a significant portion of her career as a Data Platform Engineer, designing and managing large-scale data systems. Asena is passionate about using technology to simplify and optimize workflows, making a real difference in the way teams operate.
Dean Verhey is a Data Platform Engineer at LaunchDarkly based in Seattle. He’s worked all across data at LaunchDarkly, ranging from internal batch reporting stacks to streaming pipelines powering product features like experimentation and flag usage charts. Prior to LaunchDarkly, he worked in data engineering for a variety of companies, including procurement SaaS, travel startups, and fire/EMS records management. When he’s not working, you can often find him in the mountains skiing.
Daniel Lopes is a Solutions Architect for ISVs at AWS. His focus is on enabling ISVs to design and build their products in alignment with their business goals with all advantages AWS services can provide them. His areas of interest are event-driven architectures, serverless computing, and generative AI. Outside work, Daniel mentors his kids in video games and pop culture.
Apache Spark workloads running on Amazon EMR on EKS form the foundation of many modern data platforms. EMR on EKS offers benefits by providing managed Spark that integrates seamlessly with other AWS services and your organization’s existing Kubernetes-based deployment patterns.
Data platforms processing large-scale data volumes often require multiple EMR on EKS clusters. In the post Use Batch Processing Gateway to automate job management in multi-cluster Amazon EMR on EKS environments, we introduced Batch Processing Gateway (BPG) as a solution for managing Spark workloads across these clusters. Although BPG provides foundational functionality to distribute workloads and support routing for Spark jobs in multi-cluster environments, enterprise data platforms require additional features for a comprehensive data processing pipeline.
This post shows how to enhance the multi-cluster solution by integrating Amazon Managed Workflows for Apache Airflow (Amazon MWAA) with BPG. By using Amazon MWAA, we add job scheduling and orchestration capabilities, enabling you to build a comprehensive end-to-end Spark-based data processing pipeline.
Overview of solution
Consider HealthTech Analytics, a healthcare analytics company managing two distinct data processing workloads. Their Clinical Insights Data Science team processes sensitive patient outcome data requiring HIPAA compliance and dedicated resources, and their Digital Analytics team handles website interaction data with more flexible requirements. As their operation grows, they face increasing challenges in managing these diverse workloads efficiently.
The company needs to maintain strict separation between protected health information (PHI) and non-PHI data processing, while also addressing different cost center requirements. The Clinical Insights Data Science team runs critical end-of-day batch processes that need guaranteed resources, whereas the Digital Analytics team can use cost-optimized spot instances for their variable workloads. Additionally, data scientists from both teams require environments for experimentation and prototyping as needed.
This scenario presents an ideal use case for implementing a data pipeline using Amazon MWAA, BPG, and multiple EMR on EKS clusters. The solution needs to route different Spark workloads to appropriate clusters based on security requirements and cost profiles, while maintaining the necessary isolation and compliance controls. To effectively manage such an environment, we need a solution that maintains clean separation between application and infrastructure management concerns and stitching together multiple components into a robust pipeline.
Our solution consists of integrating Amazon MWAA with BPG through an Airflow custom operator for BPG called BPGOperator. This operator encapsulates the infrastructure management logic needed to interact with BPG. BPGOperator provides a clean interface for job submission through Amazon MWAA. When executed, the operator communicates with BPG, which then routes the Spark workloads to available EMR on EKS clusters based on predefined routing rules.
The following architecture diagram illustrates the components and their interactions.
The solution works through the following steps:
Amazon MWAA executes scheduled DAGs using BPGOperator. Data engineers create DAGs using this operator, requiring only the Spark application configuration file and basic scheduling parameters.
BPGOperator authenticates and submits jobs to the BPG submit endpoint POST:/apiv2/spark. It handles all HTTP communication details, manages authentication tokens, and provides secure transmission of job configurations.
BPG routes submitted jobs to EMR on EKS clusters based on predefined routing rules. These routing rules are managed centrally through BPG configuration, allowing rules-based distribution of workloads across multiple clusters.
BPGOperator monitors job status, captures logs, and handles execution retries. It polls the BPG job status endpoint GET:/apiv2/spark/{subID}/status and streams logs to Airflow by polling the GET:/apiv2/log endpoint every second. The BPG log endpoint retrieves the most current log information directly from the Spark Driver Pod.
The DAG execution progresses to subsequent tasks based on job completion status and defined dependencies. BPGOperator communicates the job status through Airflow’s built-in task communication system, enabling complex workflow orchestration.
Refer to the BPG REST API interface documentation for additional details.
This architecture provides several key benefits:
Separation of responsibilities – Data Engineering and Platform Engineering teams in enterprise organizations typically maintain distinct responsibilities. The modular design in this solution enables platform engineers to configure BPGOperator and manage EMR on EKS clusters, while data engineers maintain DAGs.
Centralized code management – BPGOperator encapsulates all core functionalities required for Amazon MWAA DAGs to submit Spark jobs through BPG into a single, reusable Python module. This centralization minimizes code duplication across DAGs and improves maintainability by providing a standardized interface for job submissions.
Airflow custom operator for BPG
An Airflow Operator is a template for a predefined Task that you can define declaratively inside your DAGs. Airflow provides multiple built-in operators such as BashOperator, which executes bash commands, PythonOperator, which executes Python functions, and EmrContainerOperator, which submits new jobs to an EMR on EKS cluster. However, no built-in operators exist to implement all the steps required for the Amazon MWAA integration with BPG.
Airflow allows you to create new operators to suit your specific requirements. This operator type is known as a custom operator. A custom operator encapsulates the custom infrastructure-related logic in a single, maintainable component. Custom operators are created by extending the airflow.models.baseoperator.BaseOperator class. We have developed and open sourced an Airflow custom operator for BPG called BPGOperator, which implements the necessary steps to provide a seamless integration of Amazon MWAA with BPG.
The following class diagram provides a detailed view of the BPGOperator implementation.
When a DAG includes a BPGOperator task, the Amazon MWAA instance triggers the operator to send a job request to BPG. The operator typically performs the following steps:
Initialize job – BPGOperator prepares the job payload, including input parameters, configurations, connection details, and other metadata required by BPG.
Submit job – BPGOperator handles HTTP POST requests to submit jobs to BPG endpoints with the provided configurations.
Monitor job execution – BPGOperator checks the job status, polling BPG until the job completes successfully or fails. The monitoring process includes handling various job states, managing timeout scenarios, and responding to errors that occur during job execution.
Handle job completion – Upon completion, BPGOperator captures the job results, logs relevant details, and can trigger downstream tasks based on the execution outcome.
The following sequence diagram illustrates the interaction flow between the Airflow DAG, BPGOperator, and BPG.
Deploying the solution
In the remainder of this post, you will implement the end-to-end pipeline to run Spark jobs on multiple EMR on EKS clusters. You will begin by deploying the common components that serve as the foundation for building the pipelines. Next, you will deploy and configure BPG on an EKS cluster, followed by deploying and configuring BPGOperator on Amazon MWAA. Finally, you will execute Spark jobs on multiple EMR on EKS clusters from Amazon MWAA.
To streamline the setup process, we’ve automated the deployment of all infrastructure components required for this post, so you can focus on the essential aspects of job submission to build an end-to-end pipeline. We provide detailed information to help you understand each step, simplifying the setup while preserving the learning experience.
To showcase the solution, you will create three clusters and an Amazon MWAA environment:
Two EMR on EKS clusters: analytics-cluster and datascience-cluster
An EKS cluster: gateway-cluster
An Amazon MWAA environment: airflow-environment
analytics-cluster and datascience-cluster serve as data processing clusters that run Spark workloads, gateway-cluster hosts BPG, and airflow-environment hosts Airflow for job orchestration and scheduling.
This step handles the setup of networking infrastructure, including virtual private cloud (VPC) and subnets, along with the configuration of AWS Identity and Access Management (IAM) roles, Amazon Simple Storage Service (Amazon S3) storage, Amazon Elastic Container Registry (Amazon ECR) repository for BPG images, Amazon Aurora PostgreSQL-Compatible Edition database, Amazon MWAA environment, and both EKS and EMR on EKS clusters with a preconfigured Spark operator. With this infrastructure automatically provisioned, you can concentrate on the subsequent steps without getting caught up in basic setup tasks.
Clone the repository to your local machine and set the two environment variables. Replace <AWS_REGION> with the AWS Region where you want to deploy these resources.
git clone https://github.com/aws-samples/sample-mwaa-bpg-emr-on-eks-spark-pipeline.git
cd sample-mwaa-bpg-emr-on-eks-spark-pipeline
export REPO_DIR=$(pwd)
export AWS_REGION=<AWS_REGION>
Execute the following script to create the common infrastructure:
cd ${REPO_DIR}/infra
./setup.sh
To verify successful infrastructure deployment, navigate to the AWS CloudFormation console, open your stack, and check the Events, Resources, and Outputs tabs for completion status, details, and list of resources created.
You have completed the setup of the common components that serve as the foundation for rest of the implementation.
Set up Batch Processing Gateway
This section builds the Docker image for BPG, deploys the helm chart on the gateway-cluster EKS cluster, and exposes the BPG endpoint using Kubernetes service of type LoadBalancer. Complete the following steps:
Deploy BPG on the gateway-cluster EKS cluster:
cd ${REPO_DIR}/infra/bpg
./configure_bpg.sh
Verify the deployment by listing the pods and viewing the pod logs:
kubectl get pods --namespace bpg
kubectl logs <BPG-PODNAME> --namespace bpg
Review the logs and confirm there are no errors or exceptions.
Exec into the BPG pod and verify the health check:
The healthcheck API should return a successful response of {"status":"OK"}, confirming successful deployment of BPG on the gateway-cluster EKS cluster.
We have successfully configured BPG on gateway-cluster and set up EMR on EKS for both datascience-cluster and analytics-cluster. This is where we left off in the previous blog post. In the next steps, we will configure Amazon MWAA with BPGOperator, and then write and submit DAGs to demonstrate an end-to-end Spark-based data pipeline.
Configure the Airflow operator for BPG on Amazon MWAA
This section configures the BPGOperator plugin on the Amazon MWAA environment airflow-environment. Complete the following steps:
Configure BPGOperator on Amazon MWAA:
cd ${REPO_DIR}/bpg_operator
./configure_bpg_operator.sh
On the Amazon MWAA console, navigate to the airflow-environment environment.
Choose Open Airflow UI, and in the Airflow UI, choose the Admin dropdown menu and choose Plugins. You will see the BPGOperator plugin listed in the Airflow UI.
Configure Airflow connections for BPG integration
This section guides you through setting up the Airflow connections that enable secure communication between your Amazon MWAA environment and BPG. BPGOperator uses the configured connection to authenticate and interact with BPG endpoints.
Execute the following script to configure the Airflow connection bpg_connection.
cd $REPO_DIR/airflow
./configure_connections.sh
In the Airflow UI, choose the Admin dropdown menu and choose Connections. You will see the bpg_connection listed in the Airflow UI.
Configure the Airflow DAG to execute Spark jobs
This step configures an Airflow DAG to run a sample application. In this case, we will submit a DAG containing multiple sample Spark jobs using Amazon MWAA to EMR on EKS clusters using BPG. Please wait for few minutes for the DAG to appear in the Airflow UI.
cd $REPO_DIR/jobs
./configure_job.sh
Trigger the Amazon MWAA DAG
In this step, we trigger the Airflow DAG and observe the job execution behavior, including reviewing the Spark logs in the Airflow UI:
In the Airflow UI, review the MWAASparkPipelineDemoJob DAG and choose the play icon trigger the DAG.
Wait for DAG to complete successfully. Upon successful completion of the DAG, you should see Success:1 under the Runs column.
In the Airflow UI, locate and choose the MWAASparkPipelineDemoJob DAG.
On the Graph tab, choose any task (in this example, we select the calculate_pi task) and then choose the Logs
View the Spark logs in the Airflow UI.
Migrate existing Airflow DAGs to use BPG
In enterprise data platforms, a typical data pipeline consists of Amazon MWAA submitting Spark jobs to multiple EMR on EKS clusters using the SparkKubernetesOperator and an Airflow Connection of type Kubernetes. An Airflow Connection is a set of parameters and credentials used to establish communication between Amazon MWAA and external systems or services. A DAG refers to the connection name and connects to the external system.
The following diagram shows the typical architecture.
In this setup, Airflow DAGs typically uses SparkKubernetesOperator and SparkKubernetesSensor to submit Spark jobs to a remote EMR on EKS cluster using kubernetes_conn_id=<connection_name>.
The following code snippet shows the relevant details:
# Submit Spark-Pi job using Kubernetes connection
submit_spark_pi = SparkKubernetesOperator(
task_id='submit_spark_pi',
namespace='default',
application_file=spark_pi_yaml,
kubernetes_conn_id='emr_on_eks_connection_[1|2]', # Connection ID defined in Airflow
dag=dag
)
To migrate the infrastructure to a BPG-based infrastructure without impacting the continuity of the environment, we can deploy a parallel infrastructure using BPG, create a new Airflow Connection for BPG, and incrementally migrate the DAGs to use the new connection. By doing so, we won’t disrupt the existing infrastructure until the BPG-based infrastructure is completely operational, including the migration of all existing DAGs.
The following diagram showcases the interim state where both the Kubernetes connection and BPG connection are operational. Blue arrows indicate the existing workflow paths, and red arrows represent the new BPG-based migration paths.
The modified code snippet for the DAG is as follows:
# Submit Spark-Pi job using BPG connection
submit_spark_pi = BPGOperator(
task_id='submit_spark_pi',
application_file=spark_pi_yaml,
application_file_type='yaml'
connection_id='bpg_connection', # Connection ID defined in Airflow
dag=dag
)
Finally, when all the DAGs have been modified to use BPGOperator instead of SparkKubernetesOperator, you can decommission any remnants of the old workflow. The final state of the infrastructure will look like the following diagram.
Using this approach, we can seamlessly introduce BPG into an environment that currently uses only Amazon MWAA and EMR on EKS clusters.
Clean up
To avoid incurring future charges from the resources created in this tutorial, clean up your environment after you’ve completed the steps. You can do this by running the cleanup.sh script, which will safely remove all the resources provisioned during the setup:
cd ${REPO_DIR}/setup
./cleanup.sh
Conclusion
In the post Use Batch Processing Gateway to automate job management in multi-cluster Amazon EMR on EKS environments, we introduced Batch Processing Gateway as a solution for routing Spark workloads across multiple EMR on EKS clusters. In this post, we demonstrated how to enhance this foundation by integrating BPG with Amazon MWAA. Through our custom BPGOperator, we’ve shown how to build robust end-to-end Spark-based data processing pipelines while maintaining clear separation of responsibilities and centralized code management. Finally, we demonstrated how to seamlessly incorporate the solution into your existing Amazon MWAA and EMR on EKS data platform without impacting operational continuity.
We encourage you to experiment with this architecture in your own environment, adapting it to fit your unique workloads and operational requirements. By implementing this solution, you can build efficient and scalable data processing pipelines that use the full potential of EMR on EKS and Amazon MWAA. Explore further by deploying the solution in your AWS account while adhering to your organizational security best practices and share your experiences with the AWS Big Data community.
About the Authors
Suvojit Dasgupta is a Principal Data Architect at AWS. He leads a team of skilled engineers in designing and building scalable data solutions for AWS customers. He specializes in developing and implementing innovative data architectures to address complex business challenges.
Avinash Desireddy is a Cloud Infrastructure Architect at AWS, passionate about building secure applications and data platforms. He has extensive experience in Kubernetes, DevOps, and enterprise architecture, helping customers containerize applications, streamline deployments, and optimize cloud-native environments.
This post is co-written with Monica Cujerean and Ionut Hedesiu from Flutter UKI.
In this post, we share how Flutter UKI transitioned from a monolithic Amazon Elastic Compute Cloud (Amazon EC2)-based Airflow setup to a scalable and optimized Amazon Managed Workflows for Apache Airflow (Amazon MWAA) architecture using features like Kubernetes Pod Operator, continuous integration and delivery (CI/CD) integration, and performance optimization techniques.
About Flutter UKI
As a division of Flutter Entertainment, Flutter UKI stands at the forefront of the sports betting and gaming industry. Flutter UKI offers a diverse portfolio of entertainment options, encompassing sports wagering, casino games, bingo, and poker experiences. Flutter UKI’s digital presence is robust, operating through an array of renowned online brands. These include the iconic Paddy Power, Sky Betting and Gaming, and Tombola. While Flutter UKI has established a strong online foothold, it maintains a significant physical presence with a network of 576 Paddy Power betting shops strategically located across the United Kingdom and Ireland.
The Data team at Flutter UKI is integral to the company’s mission of using data to drive business success and innovation. Specializing in data, their teams are dedicated to ensuring the seamless integration, management, and accessibility of data across multiple facets of the organization. By developing robust data pipelines and maintaining high data quality standards, Flutter UKI empowers stakeholders with reliable insights, optimizes operational efficiencies, and enhances the user experience. Its commitment to data excellence underpins its efforts to remain at the forefront of the online gaming and entertainment industry, delivering value and strategic advantage to the business.
The journey from self managing Airflow on Amazon EC2 to operating Airflow workloads at scale using Amazon MWAA
Flutter UKI’s data orchestration story began in 2017 with a modest Apache Airflow deployment on EC2 instances. As the company’s digital footprint expanded, so did their data pipeline requirements, leading to an increasingly complex monolithic cluster that demanded constant attention and resource scaling. The operational overhead of managing these EC2 instances became a significant challenge for their engineering teams. In 2022, Flutter UKI reached a crossroads. They needed to choose between re-architecting their service on Amazon Elastic Kubernetes Service (Amazon EKS) or embracing Amazon Managed Workflows for Apache Airflow (MWAA).
Flutter UKI was looking to transform their data orchestration service from a resource-intensive, self-managed system to a more efficient, managed service that would allow them to focus on their core business objectives rather than infrastructure management. Through extensive proof-of-concept (POC) testing and close collaboration with AWS Enterprise Support, Flutter UKI gained confidence in the ability of Amazon MWAA to handle their sophisticated workloads at scale. Their choice of MWAA over a self-managed solution on Amazon EKS reflected Flutter UKI’s strategic focus on using managed services to reduce operational complexity and accelerate innovation.
The migration to Amazon MWAA followed a methodical approach. There was extensive testing of multiple POCs. During the POCs, the engineering team found MWAA to have a good ease of use, which helped them reduce the learning curve resulting in faster. Learning from each POC, they iterated on the final architecture by making data-driven decisions. Starting with a small subset of directed acyclic graphs (DAG), the Flutter UKI team expanded their deployment over time, gradually moving hundreds and eventually thousands of workflows to the managed service. This careful, phased transition allowed them to validate the performance and reliability of MWAA while minimizing operational risk.
High-level architecture design
During the service re-architecture, the data team strategically managed over 3,500 dynamically generated DAGs by implementing a sophisticated distribution approach across multiple Amazon MWAA environments to create a workload isolated environment. Another reason for having multiple environments was to make sure that no one MWAA environment doesn’t get overloaded by multiple DAGs. By placing DAG files across diverse Amazon Simple Storage Service (Amazon S3) locations and configuring unique DAG_FOLDER paths for each environment, the data team created an intelligent load balancing mechanism that allocates workflows based on complex criteria including environment type, task volume, and environment-specific DAG affinity. A round-robin distribution strategy was designed to minimize single environment load, ensuring scalable infrastructure with zero performance degradation. This approach allowed the team to optimize workflow orchestration, maintaining high performance while efficiently managing an extensive collection of dynamically generated DAGs across multiple MWAA environments. To provide more compute to individual tasks and to keep the MWAA efficient, Flutter UKI delegated the DAG execution to an external compute environment using Amazon Elastic Kubernetes Service (Amazon EKS). The resulting high-level architecture is shown in the following figure.
Kubernetes Pod Operator (KPO) for tasks: Flutter UKI transitioned from using custom operators and many native Airflow operators to exclusively utilizing the Kubernetes Pod Operator (KPO). This decision simplified their architecture by eliminating unnecessary complexity, reducing maintenance overhead, and mitigating potential bugs. Additionally, this approach enabled them to allocate compute resources on a per-task basis, optimizing overall service performance. It also enabled the use of different container images for different tasks, thereby avoiding library dependency conflicts.
Kubernetes Pod Operator wrapper (KPOw): Instead of using KPO directly, they developed a wrapper (KPOw) around it. This wrapper abstracts the underlying complexity and minimizes the impact of signature changes in Airflow, Amazon MWAA, Amazon EKS, or operator versions. By centralizing these changes, they only need to update the wrapper rather than thousands of individual DAGs. The wrapper also simplifies DAGs by hiding repetitive parameters, such as node affinity, pod resources, and EKS cluster configurations. Furthermore, it enforces company-specific naming conventions and allows for parameter validation at task execution time rather than during DagBag refresh. They also introduced profiles and image files, where profile files contain necessary KPO parameters, and the corresponding image files link to the repository for the task’s container image. This setup ensures consistency across tasks using the same profile and facilitates simultaneous updates across tasks.
Monthly image updates in Kubernetes: Enforcing a policy of monthly image updates made sure that their code remained current, preventing security vulnerabilities and avoiding extensive code changes due to deprecated libraries.
Continuous Airflow updates: Flutter UKI maintains a cutting-edge infrastructure by implementing new Airflow versions shortly after release, while following a carefully orchestrated deployment strategy. Their approach uses standard Amazon MWAA configurations and employs a systematic testing protocol. New versions are first deployed to development and test environments for thorough validation before reaching production systems. This methodical progression significantly reduces the risk of disruptions to business-critical workflows.
To achieve operational excellence, Flutter UKI has implemented a comprehensive monitoring framework centered on Amazon CloudWatch metrics. Their monitoring solution includes strategically configured alarms that provide early warning signals for potential issues. This proactive monitoring approach enables their teams to quickly identify and investigate anomalies in production workload executions, ensuring high availability and performance of their data pipelines. The combination of careful version management and robust monitoring exemplifies Flutter UKI’s commitment to operational excellence in their cloud infrastructure.
CI/CD integration: By managing their code in GitLab, with mandatory code reviews and using Argo Events and Argo Workflows for image updates in AWS ECR, they streamlined their development processes.
Performance Optimization: A significant portion of the DAGs are dynamically generated based on database metadata. This generation process runs outside Amazon MWAA, with its own CI/CD pipeline, and the resulting DAG files are stored in the S3 DAG. Placing code outside of tasks was avoided, including parameter evaluation. Parameters and secrets are stored in AWS Secrets Manager and retrieved at task runtime. Engineers aim to minimize or eliminate inter-service dependencies within MWAA.
DAGs are scheduled to distribute execution times as evenly as possible. Task code and common modules are hosted on Amazon S3 and retrieved at runtime. For larger codebases, Amazon Elastic File System (Amazon EFS) volumes are mounted to task pods are used.
Results
Today, Flutter UKI’s infrastructure comprises four Amazon MWAA clusters, each executing tasks on dedicated Amazon EKS node groups. They manage approximately 5,500 DAGs encompassing over 30,000 tasks, handling more than 60,000 DAG runs daily with a concurrency exceeding 450 tasks running simultaneously across clusters. They anticipate a 10% monthly increase in this workload in the short to medium term. During major events like Cheltenham and Grand National, where data load increases by 30%, their MWAA service has demonstrated stability and scalability, achieving a 100% success rate for critical processes in 2025, a significant improvement over previous years.
Conclusion
Flutter UKI’s journey with AWS Managed Workflows for Apache Airflow (Amazon MWAA) has resulted in a stable, scalable, and resilient production environment. The careful re-architecting of Flutter UKI’s service, combined with strategic decisions around task execution and infrastructure management, has not only simplified their operations, but also enhanced performance and reliability. Security and compliance benefits were also noticed, because MWAA provides managed security updates, built-in encryption, and integration with AWS security services. Perhaps most importantly, the shift to MWAA has allowed Flutter UKI’s engineering teams to redirect their efforts from infrastructure maintenance to business-critical tasks, focusing on DAG development and improving data pipeline efficiency, ultimately accelerating innovation in their core business operations.
If you’re looking to reduce operational overhead and migrate to a fully managed Airflow solution on AWS, consider using Amazon MWAA. Get in touch with your Technical Account Manager or your Solutions Architect to discuss a solution specific to your use-case. You can also reach out to AWS Support by creating a case if you’re facing an issues setting up the service.
Monica Cujerean is a Principal Data Engineer at Flutter UKI, focusing on service related initiatives that cover performance optimization, cost effectiveness, and new feature adoption on most AWS service in our stack: Amazon MWAA, Amazon Redshift, Amazon Aurora, and Amazon SageMaker.
Ionut Hedesiu is a Senior Data Architect at Flutter UKI, responsible for designing strategic solutions to cover complex and varied business needs. His main expertise is on Amazon MWAA, Kubernetes, Amazon Sagemaker, and ETL solutions.
Nidhi Agrawal is a Technical Account Manager at AWS and works with large enterprise customers to provide the technical guidance, best practices, and strategic support to customers, helping them optimize their environments in the AWS Cloud.
John Kellett is a Senior Customer Solutions Manager with 25 years of experience across private and public sectors. John helps drive end-to-end customer engagement through program management excellence. By understanding and representing customers’ strategic visions, John aligns to develop the people, organizational readiness, and technology competencies to meet the desired outcomes.
Sidhanth Muralidhar is a Principal Technical Account Manager at AWS. He works with large enterprise customers who run their workloads on AWS. He is passionate about working with customers and helping them architect workloads for cost, reliability, performance, and operational excellence at scale in their cloud journey. He has a keen interest in data analytics as well.
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) provides a secure and managed environment to run Apache Airflow on AWS. Airflow is often used in highly regulated industries, such as finance and healthcare. These customers might want to further restrict access and traffic to enhance security posture than what the Amazon MWAA default configurations provide. This post covers some recommended practices.
The principle of least privilege is a fundamental tenet that should be followed diligently. When it comes to configuring AWS services, it’s essential to grant only the minimum required permissions to resources, avoiding overly broad or permissive policies.
In this post, we explore how to apply the principle of least privilege to your Amazon MWAA environment by tightening network security using security groups, network access control lists (ACLs), and virtual private cloud (VPC) endpoints. We also discuss the Amazon MWAA execution and deployment roles and their respective permissions.
Understanding the Amazon MWAA environment
When an Amazon MWAA environment is created, resources are created in an AWS managed service VPC and your customer managed VPC. In the customer VPC provided at environment creation, the necessary resources to run the Airflow environment are deployed, including schedulers and workers running on Amazon Elastic Container Service (Amazon ECS) clusters. These clusters are deployed in your VPC and they assume Elastic Network Interfaces (ENIs) with private IP addresses in the customer account. These ENIs span private subnets across two Availability Zones to connect to the Airflow database and web server, which reside in the service-owned account (if in private access mode). The following diagram illustrates this architecture.
VPC security groups act as virtual firewalls that can control network traffic at the ENI level, or instance level. Security groups are stateful, meaning that inbound traffic is automatically permitted outbound and vice versa. The default security group configuration in a VPC starts with is no inbound rules and an outbound rule allowing all traffic. By definition, a security group with no inbound rules denies all ingress traffic that wasn’t allowed out through the 0.0.0.0/0 outbound rule.
Amazon MWAA offers two web server access modes inside the customer VPC: public and private. Public web server mode must have a way for traffic to access the web servers in the customer-owned VPC through the public internet. This requires routing to the public internet using public subnets and a NAT gateway. A NAT gateway can be used to provide internet access for resources in private subnets. With private access mode, the security group for the Amazon MWAA environment doesn’t need to allow traffic to and from the NAT gateway, only granting access to the Airflow UI to users with appropriate permissions from within the VPC. An Application Load Balancer is only provisioned in public mode to route traffic to the public web servers. The customer must provision the rest of the networking components.
If your Amazon MWAA environment needs to communicate with resources outside your VPC (such as external data sources or APIs), you might need to configure appropriate security group rules and routing to allow the necessary traffic. In such cases, you would typically use a NAT gateway or VPN connection to facilitate the communication between your Amazon MWAA environment and the external resources and VPC endpoints for AWS resources.
For tighter security restrictions, an environment with private routing without internet access is possible, and finer-grained security group rules can be applied and VPC endpoint policies can be used. Because this post is focusing on least privilege, we will focus on the minimum security requirements needed for an Amazon MWAA environment.
Security groups: Minimizing permissions
Your Amazon MWAA environment will have a security group associated with your VPC’s environment resources. This security group is also used by the ENIs created by the interface VPC endpoint that is used to communicate with the database and web server. By default, security groups deny all inbound traffic and security group rules need to be explicitly stated, denoting the ports and source that the instance will allow network traffic from. At a minimum, the Amazon MWAA environment must allow for traffic to and from the Amazon Aurora PostgreSQL-Compatible Edition metadata database that is owned and managed by Amazon MWAA. The metadata database is a crucial component of Airflow that acts as a centralized source of truth for task execution, configuration, and monitoring. Both the scheduler and workers require access to this database to perform their respective roles in orchestrating and running tasks. This database listens on TCP port 5432. Additionally, the web server traffic can be restricted to HTTPS through TCP port 443. At a minimum, the Amazon MWAA security group must have the two inbound rules, detailed in the following table.
Type
Protocol
Port Range
Source Type
Source
Custom TCP
TCP
5432
Custom
sg-xxxxx / my-mwaa-vpc-security-group
HTTPS
TCP
443
Custom
sg-xxxxx / my-mwaa-vpc-security-group
Many customers have other AWS resources residing in VPCs, to which the Amazon MWAA workers need access. These resources can be granted network access in a private routing configuration using security groups as well. If the resource sits in the same security group, add an additional inbound rule with the port needed. For example, if an Amazon Redshift cluster sits in the same security group, add the following rule.
Type
Protocol
Port Range
Source Type
Source
Custom TCP
TCP
5439
Custom
sg-xxxxx / my-mwaa-vpc-security-group
If the Redshift cluster is in a different security group, change the source to the Redshift security group.
Type
Protocol
Port Range
Source Type
Source
Custom TCP
TCP
5439
Custom
sg-xxxxx / redshift-security-group
If the resources are in another VPC, then VPC peering must be enabled before referencing that other VPC’s security group. For resources that don’t reside in a subnet, a VPC endpoint will also provide private routing to and from the Amazon MWAA environment and those resources. For example, a VPC endpoint for Amazon Simple Storage Service (Amazon S3) can provide enhanced security, improved performance, and lower costs.
Network ACLs: Minimizing permissions
Network ACLs can manage (by allow or deny rules) inbound and outbound traffic at the subnet level. An ACL is stateless, which means that inbound and outbound rules must be specified separately and explicitly. It is used to specify the types of network traffic that are allowed in or out from the instances in a VPC network.
Every Amazon VPC has a default ACL that allows all inbound and outbound traffic, with a rule as follows.
Rule number
Type
Protocol
Port Range
Source
Allow/Deny
100
All IPv4 traffic
All
All
0.0.0.0/0
Allow
*
All IPv4 traffic
All
All
0.0.0.0/0
Deny
You can edit the default ACL rules or create a custom ACL and attach it to your subnets. A subnet can only have one ACL attached to it at any time, but one ACL can be attached to multiple subnets. To implement least privilege in your Amazon MWAA environment, restrict the inbound ACL to allow traffic from the metadata database and web server and restrict the outbound to allow traffic to only the clients in the private subnet. Note the following examples use example private IPs for the subnets used.
Inbound NACL
Rule number
Type
Protocol
Port Range
Source
Allow/Deny
Comments
100
Custom TCP
TCP
5432
10.192.21.0/16
Allow
Allow inbound database traffic from private subnet
110
HTTPS
TCP
443
10.192.21.0/16
Allow
Allow inbound HTTPS traffic from private subnet
*
All traffic
All
All
0.0.0.0/0
Deny
Denies all inbound IPv4 traffic not already handled by a preceding rule (not modifiable)
Outbound NACL
Rule number
Type
Protocol
Port Range
Source
Allow/Deny
Comments
100
Custom TCP
TCP
1024-65535
10.192.21.0/24
Allow
Allows outbound return IPv4 traffic to clients in private subnet
*
All traffic
All
All
0.0.0.0/0
Deny
Denies all outbound IPv4 traffic not already handled by a preceding rule (not modifiable)
VPC endpoints: Minimizing permissions
When you create an Amazon MWAA environment, it is deployed within a VPC. This allows you to control the network access and security of your Airflow deployment. However, some customer workloads executing in the Amazon MWAA environment might need to orchestrate tasks using other AWS services, such as Amazon S3 to access files, AWS Glue to start ETL (extract, transform, and load) jobs, or Amazon Redshift for running data warehouse queries, which reside outside of your VPC. To establish a secure and private connection between your Amazon MWAA environment and these external AWS services, you can use VPC endpoints. The purpose of VPC endpoints in Amazon MWAA is to provide a secure and private connection between your Amazon MWAA environment and other AWS services within your VPC. VPC endpoints are virtual devices that are provisioned within your VPC and act as an entry point for the specified AWS service, allowing your Amazon MWAA environment to communicate with the service using a private IP address, without needing to go through the public internet. The following diagram illustrates this architecture.
VPC endpoints allow you to keep your Amazon MWAA environment’s network traffic within the AWS network, reducing the exposure to the public internet and enhancing the overall security of your Airflow deployment. Although private VPC endpoints are automatically created for the database and web server, to create a least privileged environment without internet access, additional VPC endpoints will be needed for the additional Amazon MWAA required resources. Amazon S3, Amazon Simple Queue Service (Amazon SQS), Amazon CloudWatch, and optionally AWS Key Management Service (AWS KMS) will need VPC endpoints created. For more details, see Creating the required VPC service endpoints in an Amazon VPC with private routing. Outside of the necessary services, many customers run Amazon MWAA workflows that orchestrate additional AWS services, such as Amazon Redshift, Amazon EMR, and AWS Glue. Let’s look at an example VPC endpoint that we want to use to connect to Amazon Redshift, which is commonly called in the Airflow DAGS using the Redshift Operator for workflows that interact with Amazon Redshift as a data warehouse. For more information on creating Amazon VPC interface endpoints, see Access an AWS service using an interface VPC endpoint.
On the Amazon VPC console, create a new VPC endpoint for the amazonaws.region.redshift service, where region is the AWS Region where your Amazon MWAA environment and Redshift cluster are located. Make sure that private DNS is enabled.
Create a VPC endpoint policy. This can be used to limit access to the Redshift cluster only to the Amazon MWAA environment, preventing unauthorized access from other resources. The following is an example policy:
The Version field specifies the policy language version.
The Statement section contains a single statement that allows the specified actions on the Redshift cluster.
The Effect field is set to Allow, which means the policy grants the specified permissions.
The Principal field specifies the AWS Identity and Access Management (IAM) role associated with your Amazon MWAA execution role, which is authorized to access the Redshift cluster.
The Action field lists the specific Redshift actions that the Amazon MWAA execution role is allowed to perform, such as describing the cluster, getting cluster credentials, and restoring from a snapshot.
The Resource field specifies the Amazon Resource Name (ARN) of the Redshift cluster that the policy applies to.
Associate the VPC endpoint with the correct route table. This route table should be used by the subnets where your Amazon MWAA environment is deployed. If using a VPC interface endpoint, associate the endpoint with the two private subnets and security group used by Amazon MWAA.
Make sure that the security groups associated with the Amazon MWAA environment and the Redshift cluster allow the necessary inbound and outbound traffic between them. This typically includes allowing access on the Redshift port (typically 5439) from the Amazon MWAA environment’s security group.
On the Amazon MWAA console, under Admin, Connections, update the Redshift connection details to use the VPC endpoint address instead of the public Redshift endpoint. This makes sure that the connection between Amazon MWAA and Amazon Redshift is secure and stays within the VPC.
By configuring VPC endpoints for the AWS services your Amazon MWAA environment needs to access, you can provide secure, private, and efficient communication between your Airflow deployment and AWS resources.
Restricting traffic within AWS with a customer managed endpoints for Amazon MWAA resources
As mentioned earlier, Amazon MWAA integrates with various AWS services, such as CloudWatch for logging, Amazon S3 for DAGs and requirements, Amazon SQS as a messaging middleware, and optionally AWS KMS for encryption. You can create VPC endpoints for these services to make sure traffic stays within the AWS network. Access to these endpoints can be restricted by allowing only the Amazon MWAA security group as the ingress source. For details on how to create these endpoints and policies, see Introducing shared VPC support on Amazon MWAA. If the Amazon MWAA environment was updated after April 2, 2024, it will be on AWS Fargate v1.4 and will not use Amazon Elastic Container Registry (Amazon ECR) and therefore you will not need to create a VPC endpoint for it.
Managing permissions to deploy an Amazon MWAA environment
To create and deploy an Amazon MWAA environment, you need to have the appropriate permissions granted to your IAM user or role. The required permissions can be granted through an IAM policy attached to your user or role. When you create an Amazon MWAA environment, you can specify an execution role that will be assumed by the Airflow workers to perform tasks. The execution role should have the necessary permissions to access the required AWS services and resources based on your workflow requirements. It’s important to follow the principle of least privilege when granting permissions to IAM roles and users. You should only grant the minimum permissions required for your Amazon MWAA environment and Airflow workflows to function correctly.
Amazon MWAA trust policy
Amazon MWAA needs to be able to assume the execution role in order to perform actions on your behalf. To do this, create a trust policy, allowing the Amazon MWAA service the ability to AssumeRole. To avoid the confused deputy problem, we add a condition to the trust policy, and replace the AWS account number and Region as needed. The following is an example policy:
Although the service-linked role creates the VPC endpoints, the deployer role requires permissions to create VPC endpoints and perform a dry run. You can limit these permissions by allowing the ec2:CreateVpcEndpoint action and specifying resource ARNs for VPC endpoints, VPCs, subnets, and security groups. Additionally, you can use the aws:CalledVia condition key to restrict access to the airflow.amazonaws.com service.
Amazon MWAA execution role: Required permissions
When creating an Amazon MWAA environment, you need to specify an execution role that grants the necessary permissions for Airflow to interact with other AWS services. Instead of using a wildcard policy, you can create a custom policy with the minimum required permissions.
The following is an example of an execution role policy that allows Amazon MWAA to interact with various services using an AWS managed key:
This policy grants Amazon MWAA the necessary permissions to interact with CloudWatch Logs, Amazon S3, Amazon SQS, and AWS KMS when using the AWS managed key offering, while explicitly specifying the resources it can access. You can further refine this policy based on your specific requirements.
The following is an example of an execution policy that allows Amazon MWAA to interact with various services using a KMS customer managed key:
For the use case of using the customer managed key, attach the following JSON policy to the key to provide access to the Airflow logs in CloudWatch Logs:
You can attach multiple policies to the execution role as needed to allow your workers to access additional AWS resources. For example, let’s explore how to enable Amazon EMR access. You can create a JSON policy that contains the narrowest permissions you can configure, as in the following example:
In this post, we discussed best practices for least privilege configuration in Amazon MWAA. By following these approaches, you can adhere to the principle of least privilege and maintain a secure posture within your Amazon MWAA environment, without compromising functionality or relying on overly permissive policies. Security is always top priority; to learn more about security in Amazon MWAA, see Security in Amazon Managed Workflows for Apache Airflow and Security best practices on Amazon MWAA.
About the Authors
Elizabeth Davis is a Sr Solutions Architect at Amazon Web Services (AWS). She currently works with educational technology companies and has a passion for serverless and data orchestration technologies. She has been an Amazon MWAA as a subject matter expert (SME) for the last 3+ years.
Mark Richman is a Principal Solutions Architect at Amazon Web Services with 30 years of experience building complex web and enterprise software. He contributes to Apache Airflow, bringing his expertise in cloud computing and serverless technologies to the open-source platform. Mark is also an accomplished writer and speaker who has authored commercial publications and AWS courses while regularly presenting at industry events.
As organizations scale their Amazon Web Services (AWS) infrastructure, they frequently encounter challenges in orchestrating data and analytics workloads across multiple AWS accounts and AWS Regions. While multi-account strategy is essential for organizational separation and governance, it creates complexity in maintaining secure data pipelines and managing fine-grained permissions particularly when different teams manage resources in separate accounts.
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a managed orchestration service for Apache Airflow that you can use to set up and operate data pipelines in the Amazon Cloud at scale. Apache Airflow is an open source tool used to programmatically author, schedule, and monitor sequences of processes and tasks, referred to as workflows. With Amazon MWAA, you can use Apache Airflow to create workflows without having to manage the underlying infrastructure for scalability, availability, and security.
In this blog post, we demonstrate how to use Amazon MWAA for centralized orchestration, while distributing data processing and machine learning tasks across different AWS accounts and Regions for optimal performance and compliance.
Solution overview
Let’s consider an example of a global enterprise with distributed teams spread across different AWS regions. Each team generates and processes valuable data that is often required by other teams for comprehensive insights and streamlined operations. In this post, we consider a scenario where the data processing team sits in one region and the machine learning (ML) team sits in another region and there is a central team that manages the tasks between the two teams.
To address this complex challenge of orchestrating dependent teams across geographic regions, we’ve designed a data pipeline that spans multiple AWS accounts across different AWS Regions and is centrally orchestrated using Amazon MWAA. This design enables seamless data flow between teams, making sure that each team has access to the necessary data from other AWS accounts and Regions while maintaining compliance and operational efficiency.
Here’s a high-level overview of the architecture:
Centralized orchestration hub (Account A, us-east-1)
Amazon MWAA serves as the central orchestrator, coordinating operations across all regional data pipelines.
Amazon SageMaker performs ML tasks on the replicated data in the S3 bucket (ML)
This architecture maintains the concept of separate regional operations within Account B, with data processing in AWS Region 1 and ML in AWS Region 2. The central Amazon MWAA instance in Account A orchestrates these operations across AWS Regions, enabling different teams to work with the data they need. It enables scalability, automation, and streamlined data processing and ML workflows across multiple AWS environments.
Account A: Central managed account for the Amazon MWAA environment.
Account B: Data processing and ML operations
Primary Region: US East (N. Virginia) [us-east-1]: Data processing workloads
Secondary Region: US West (Oregon) [us-west-2]: ML workloads
Step 1: Set up Account B (data processing and ML tasks)
in us-east-1 and provide Account A as input. This template creates the following three stacks:
Stack in us-east-1: Creates the required roles for stackset execution.
Second stack in us-east-1: Creates an S3 bucket, S3 folders, and AWS Glue job.
Stack in us-west-2: Creates a S3 bucket, S3 folders, Amazon SageMaker Config file, cross-account-role, and AWS Lambda function.
Collect stack outputs: After successful deployment, gather the following output values from the created stacks. These outputs will be used in subsequent steps of the setup process.
From the us-east-1 stack:
The value of SourceBucketName
From the us-west-2 stack:
The value of DestinationBucketName
The value of CrossAccountRoleArn
Step 2: Set up Account A (central orchestration)
in us-east-1. Provide value of CrossAccountRoleArn from Account B setup as input. This template does the following:
Deploys an Amazon MWAA environment
Sets up an Amazon MWAA Execution role with a cross-account trust policy.
Step 3: Setting up S3 CRR and bucket policies in Account B
in us-east-1 for cross-Region replication of the S3 data-processing bucket in us-east-1 and the ML pipeline bucket in us-west-1. Provide values of SourceBucketName, DestinationBucketName, and AccountAId as input parameters.
This stack should be deployed after completing the Amazon MWAA setup. This sequence is necessary because you need to grant the Amazon MWAA execution role appropriate permissions to access both the source and destination buckets.
The stack in Step 2 created an AWS Identity and Access Management (IAM) role in Account B with a trust relationship that allows the Amazon MWAA execution role from Account A (the central orchestration account) to assume it. Additionally, this role is granted the necessary permissions to access AWS resources in both Regions of Account B.
This setup enables the Amazon MWAA environment in Account A to securely perform actions and access resources across different Regions in Account B, maintaining the principle of least privilege while allowing for flexible, cross-account orchestration.
Airflow connection in Account A
To establish cross-account connections in Amazon MWAA:
Create a connection for us-east-1. Open the Airflow UI and navigate to Admin and then to Connections. Choose the plus (+) icon to add a new connection and enter the following details:
Connection ID: Enter aws_crossaccount_role_conn_east1
Connection type: Select Amazon Web Services.
Extras: Add the cross-account-role and Region name using the following code. Replace <CrossAccountRoleArn> with the cross-account role Amazon Resource Name (ARN) created while setting Account B in Step 1, in Region 2 (us-west-2):
By setting up these Airflow connections, Amazon MWAA can securely access resources in both us-east-1 and us-west-2, helping to ensure seamless workflow execution.
Implement cross-account workflows in Account A
Now that your environment is set up with the necessary IAM roles and Airflow connections, you can create data processing and ML workflows that span across accounts and Regions.
DAG 1: Cross-account data processing
The directed acyclic graph (DAG) depicted in the preceding figure demonstrates a cross-account data processing workflow using Amazon MWAA and AWS services.
Replace <INSERT-DATA-PROCESSING-BUCKET-NAME-US-EAST-1> with the value of SourceBucketName from Account B.
Here’s a description of its key operators:
S3KeySensor: This sensor monitors a specified S3 bucket for the presence of a raw data file (raw/ml_train_data.csv). It uses a cross-account AWS connection (aws_crossaccount_role_conn_east1) to access the S3 bucket in a different AWS account. The sensor checks every 60 seconds and times out after 1 hour if the file is not detected.
GlueJobOperator: This operator triggers an AWS Glue job (mwaa_glue_raw_to_transform) for data preprocessing. It passes the bucket name as a script argument to the AWS Glue job. Like the S3KeySensor, it uses the cross-account AWS connection to execute the AWS Glue job in the target account.
DAG 2: Cross-account and cross-Region ML
The DAG in the preceding figure demonstrates a cross-account machine learning workflow using Amazon MWAA and AWS services. It shows Airflow’s flexibility in enabling users to write custom operators for specific use cases, particularly for cross-account operations.
Replace <INSERT-MACHINE-LEARNING-BUCKET-NAME-US-WEST-2> with the value of DestinationBucketName from Account B.
Here’s a description of the custom operators and key components:
CrossAccountSageMakerHook: This custom hook extends the SageMakerHook to enable cross-account access. It uses AWS Security Token Service (AWS STS) to assume a role in the target account, enabling seamless interaction with SageMaker across account boundaries.
CrossAccountSageMakerTrainingOperator: Building on the CrossAccountSageMakerHook, this operator enables SageMaker training jobs to be executed in a different AWS account. It overrides the default SageMakerTrainingOperator to use the cross-account hook.
S3KeySensor: Used to monitor the presence of training data in a specified S3 bucket. These sensors verify that the required data is available before proceeding with the machine learning workflow. It uses a cross-account AWS connection (aws_crossaccount_role_conn_west2) to access the S3 bucket in a different AWS account.
SageMakerTrainingOperator: Uses the custom CrossAccountSageMakerTrainingOperator to initiate a SageMaker training job in the target account. The configuration for this job is dynamically loaded from an S3 bucket.
LambdaInvokeFunctionOperator: Invokes a Lambda function named dagcleanup after the SageMaker training job completes. This can be used for post-processing or cleanup tasks.
Step 5: Schedule and verify the Airflow DAGs
To schedule the DAGs, copy the Python scripts cross_account_data_processing_dag.py and cross_account_machine_learning_dag.py to the S3 location associated with Amazon MWAA in central Account A. Go to the Airflow environment created in Account A, us-east-1, and locate the S3 bucket link and upload them to the dags folder.
Download data file to the source bucket created in Account B, us-east-1, under raw folder.
Navigate to the Airflow UI.
Locate your DAG in the DAGs tab. The DAG automatically syncs from Amazon S3 to the Airflow UI. Choose the toggle button to enable the DAGs.
Trigger the DAG runs.
Best practices for cross-account integration
When implementing cross-account, cross-Region workflows with Amazon MWAA, consider the following best practices to help ensure security, efficiency, and maintainability.
Networking: Choose the appropriate networking solution (AWS Transit Gateway, VPC Peering, AWS PrivateLink) based on your specific requirements, considering factors such as the number of VPCs, security needs, and scalability requirements. Implement appropriate security groups and network ACLs to control traffic flow between connected networks.
IAM role management: Follow the principle of least privilege when creating IAM roles for cross-account access.
Error handling and retries: Implement robust error handling in your DAGs to manage cross-account access issues. Use Airflow’s retry mechanisms to handle transient failures in cross-account operations.
To avoid future charges, remove any resources you created for this solution.
Empty the S3 buckets: Manually delete all objects within each bucket, verify they are empty, then delete the buckets themselves.
Delete the CloudFormation stacks: Identify and delete the stacks associated with the architecture.
Verify resource cleanup: Make sure that Amazon MWAA, AWS Glue, SageMaker, Lambda, and other services are terminated.
Remove remaining resources: Delete any manually created IAM roles, policies, or security groups.
Conclusion
By using Airflow connections, custom operators, and features such as Amazon S3 cross-Region replication, you can create a sophisticated workflow that seamlessly operates across multiple AWS accounts and Regions. This approach allows for complex, distributed data processing and machine learning pipelines that can take advantage of resources spread across your entire AWS infrastructure. The combination of cross-account access, cross-Region replication, and custom operators provides a powerful toolkit for building scalable and flexible data workflows. As always, careful planning and adherence to security best practices are crucial when implementing these advanced multi-account, multi-Region architectures.
Ready to tackle your own cross-account orchestration challenges? Test this approach and share your experience in the comments section.
About the authors
Suba Palanisamy is a Senior Technical Account Manager helping customers achieve operational excellence using AWS. Suba is passionate about all things data and analytics. She enjoys traveling with her family and playing board games
Anubhav Gupta is a Solutions Architect at AWS supporting enterprise greenfield customers, focusing on the financial services industry. He has worked with hundreds of customers worldwide building their cloud foundational environments and platforms, architecting new workloads, and creating governance strategy for their cloud environments. In his free time, he enjoys traveling and spending time outdoors
Anusha Pininti is a Solutions Architect guiding enterprise greenfield customers through every stage of their cloud transformation, specializing in data analytics. She supports customers across various industries, helping them achieve their business objectives through cloud-based solutions. In her free time, Anusha loves to travel, spend time with family, and experiment with new dishes
Sriharsh Adari is a Senior Solutions Architect at AWS, where he helps customers work backward from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise includes technology strategy, data analytics, and data science. In his spare time, he enjoys playing sports, watching TV shows, and playing Tabla
Geetha Penmatsa is a Solutions Architect supporting enterprise greenfield customers through their cloud journey. She helps customers across various industries transform their business with the AWS Cloud. She has a background in data analytics and is specializing in Amazon Connect Cloud contact center to help transform customer experience at scale. Outside work, Geetha loves to travel, ski, hike, and spend time with friends and family
This recognition, we feel, reflects our ongoing commitment to innovation and excellence in data integration, demonstrating our continued progress in providing comprehensive data management solutions.
The Gartner Magic Quadrant evaluates 20 data integration tool vendors based on two axes—Ability to Execute and Completeness of Vision. This evaluation, we feel, critically examines vendors’ capabilities to address key service needs, including data engineering, operational data integration, modern data architecture delivery, and enabling less-technical data integration across various deployment models.
Discover, prepare, and integrate all your data at any scale
AWS Glue is a fully managed, serverless data integration service that simplifies data preparation and transformation across diverse data sources. With its comprehensive suite of tools, AWS Glue allows users to build and manage data pipelines efficiently, without requiring extensive infrastructure management expertise.
We have embarked on a journey to unify the broad range of AWS data processing, analytics, and AI capabilities, starting with the announcement of Amazon SageMaker Unified Studio at re:Invent 2024. This includes the data integration capabilities mentioned above, with support for both structured and unstructured data. With an integrated experience for data workers, SageMaker Unified Studio provides an environment where users can collaborate and build faster. It supports model development, generative AI, data processing, and SQL analytics, all accelerated by Amazon Q Developer—our most capable generative AI assistant for software development. The Unified Studio provides unified access to all data sources, whether stored in data lakes, data warehouses, or third-party and federated sources, with robust governance and enterprise-grade security built-in.
Review the Gartner Magic Quadrant
Access a complimentary copy of the full report to see why Gartner positioned AWS as a Leader, and dive deep into the strengths and cautions of AWS. We believe our recognition as a Leader in the Gartner Magic Quadrant is a testament to delivering innovations for our customers.
Gartner does not endorse any vendor, product or service depicted in its research publications and does not advise technology users to select only those vendors with the highest ratings or other designation. Gartner research publications consist of the opinions of Gartner’s research organization and should not be construed as statements of fact. Gartner disclaims all warranties, expressed or implied, with respect to this research, including any warranties of merchantability or fitness for a particular purpose.
GARTNER is a registered trademark and service mark of Gartner and Magic Quadrant is a registered trademark of Gartner, Inc. and/or its affiliates in the U.S. and internationally and are used herein with permission. All rights reserved. This graphic was published by Gartner, Inc. as part of a larger research document and should be evaluated in the context of the entire document. The Gartner document is available upon request from here.
About the authors
William Vambenepe is Director of Product Management at AWS, where he leads the Product Management, Solutions Engineering, and UX Design team for data processing services (Amazon EMR, AWS Glue, Athena, Amazon MWAA), SageMaker Unified Studio, and SageMaker Catalog. Prior to AWS, William worked at Google (6 years building and growing the Data and Analytics product portfolio for Google Cloud, and 5 years as Product Management Director for Google Search). He had previously held software engineering leadership roles at Oracle and HP. William holds an Engineering degree from Ecole Centrale Paris, a graduate Diploma in Computer Science from Cambridge University, and a Masters in Engineering Management from Stanford University.
Santosh Chandrachood has been with AWS for over 8 years and helped build, launch, and scale a variety of AWS services. Currently, Santosh is Director and service leader for Data Processing, managing Amazon EMR, Athena, AWS Glue, and Managed Workflows for Apache Airflow (Amazon MWAA). Santosh also led AWS Data Integration as the General Manager. Before joining AWS, Santosh lead engineering teams in networking, storage, and data infrastructure areas.
Businesses of all sizes are challenged with the complexities and constraints posed by traditional extract, transform and load (ETL) tools. These intricate solutions, while powerful, often come with a significant financial burden, particularly for small and medium enterprise customers. Beyond the substantial costs of procurement and licensing, customers must also contend with the expenses associated with installation, maintenance, and upgrades—a perpetual cycle of investment that can strain even the most robust budgets. At Wipro, scalability of data pipelines in addition to automation remains a persistent concern for their customers and they’ve learned through customer engagements that it’s not achievable without considerable effort. As data volumes continue to swell, these tools can struggle to keep pace with the ever-increasing demand, leading to processing delays and disruptions in data delivery—a critical bottleneck in an era when timely insights are paramount.
This blog post discusses how a programmatic data processing framework developed by Wipro can help data engineers overcome obstacles and streamline their organization’s ETL processes. The framework leverages Amazon EMR improved runtime for Apache Spark and integrates with AWS Managed services. This framework is robust and capable of connecting with multiple data sources and targets. By using capabilities from AWS managed services, the framework eliminates the undifferentiated heavy lifting typically associated with infrastructure management in traditional ETL tools, enabling customers to allocate resources more strategically. Furthermore, we will show you how the framework’s inherent scalability ensures that businesses can effortlessly adapt to increasing data volumes, fostering agility and responsiveness in an evolving digital landscape.
Solution overview
The proposed solution helps build a fully automated data processing pipeline that streamlines the entire workflow. It triggers processes when code is pushed to Git, orchestrates and schedules processing of jobs, validates data with the help of defined rules, transforms data prescribed within code, and loads the transformed datasets into a specified target. The primary component of this solution is the robust framework, developed using Amazon EMR runtime for Apache Spark. The framework can be used for any ETL process where input might be fetched from various data sources, transformed, and loaded into specified targets. To enable gaining valuable insights and provide overall job monitoring and automation, the framework is integrated with AWS managed services:
Amazon EC2 to host and run a Jenkins build server.
Solution walkthrough
The solution architecture is shown in the preceding figure and includes:
Continuous integration and delivery (CI/CD) for data processing
Data engineers can define the underlying data processing job within a JSON template. A pre-defined template is available on GitHub for you to review syntax. At a high level, this step includes the following objectives:
Writing the Spark job configuration to be executed on Amazon EMR.
Split the data processing into three phases:
Parallelize fetching data from source, validate source data, and prepare the dataset for further processing.
Provide flexibility to write business transformation rules defined in JSON, including data validation checks such as duplicate record, null value check, and their removal. It can also include any SQL based transformation written in Apache Spark SQL.
Take the transformed data set and load it to the target and perform reconciliation as needed.
It’s important to highlight that each step of the three phases is recorded for auditing, and error reporting, and troubleshooting and security purposes.
After the data engineer has prepared the configuration file following the prescribed template in step 1 and committed it to the Git repository, it triggers the Jenkins pipeline. Jenkins is an open source continuous integration tool running on an EC2 instance that takes the configuration file, processes it, and builds (compiles the Spark application code) end artifacts—a JAR file and a configuration file (.conf) that’s copied to an S3 bucket and will be used later by Amazon EMR.
CI/CD for data pipeline
The CI/CD for the data pipeline is shown in the following figure.
After the data processing job is written, the data engineers can use a similar code-driven development approach to define the data processing pipeline to schedule, orchestrate, and execute the data processing job. Apache Airflow is a popular open source platform used for developing, scheduling, and monitoring batch-oriented workflows. In this solution, we use Amazon MWAA to execute the data pipeline through a Direct Acyclic Graph (DAG). To make it easier for engineers to build the required DAG in this solution, you can define the data pipeline in simple YAML. A sample of the YAML file is available on GitHub for review.
When a user commits the YAML file containing the DAG details to the project Git repository, another Jenkins pipeline is triggered.
The Jenkins pipeline now reads the YAML configuration file and based on the task and dependencies given, it generates the DAG script file, which is copied to the configured S3 bucket.
Airflow DAG execution
After both the data processing job and data pipeline are configured, Amazon MWAA retrieves the most recent scripts from the S3 bucket to display the latest DAG definition in the Airflow user interface. These DAGs contain at least three tasks and except for creating and terminating an EMR cluster, every task represents an ETL process. Sample DAG code is available in GitHub. The following figure shows the DAG grid view within Amazon MWAA.
As defined in the schedule specified in the job, Airflow executes the create Amazon EMR task that launches the Amazon EMR cluster on the EC2 instance. After the cluster is created, the ETL processes are submitted to Amazon EMR as steps.
Amazon EMR executes these steps concurrently (Amazon EMR provides step concurrency levels that define how many steps to process concurrently). After the tasks are finished, the Amazon EMR cluster is terminated to save costs.
ETL processing
Each step submitted by Airflow to Amazon EMR with a Spark submit command also includes the S3 bucket path of the configuration file passed as an argument.
Based on the configuration file, the input data is fetched and technical validations are applied. If data mapping has been enabled within the data processing job, then the structured data is prepared based on the given schema. This output is passed to next phase where data transformations and business validations can be applied.
A set of reconciliation rules are applied to the transformed data to ensure the data quality dimensions. After this step, data is loaded to specified target.
The following figure shows the ETL data processing job as executed by Amazon EMR.
Logging, monitoring and notification
Amazon MWAA provides the logs generated by each task of the DAG within the Airflow UI. Using these logs, you can monitor Apache Airflow task details, delays, and workflow errors.
Amazon MWAA also frequently pings the Amazon EMR cluster to fetch the latest status of the step being executed and updates the task status accordingly.
If a step has failed, for example, if the database connection was not established because of high traffic, Amazon MWAA repeats the process.
Whenever a task has failed, an email notification is sent to the configured recipients with the failure cause and logs using Amazon SNS.
The key capabilities of this solution are:
Full automation: After the user commits the configuration files to Git, the remainder of the process is fully automated from when the CI/CD pipelines deploy the artifacts and DAG code. The DAG code is later executed in Airflow at the scheduled time. The entire ETL job is logged and monitored, and email notifications are sent in case of any failures.
Flexible integration: The application can seamlessly accommodate a new ETL process with minimal effort. To create a new process, prepare a configuration file that contains the source and target details and the necessary transformation logic. An example of how to specify your data transformation is shown in the following sample code.
"data_transformations": [{
"functionName": "cast column date_processed",
"sqlQuery": "Select *, from_unixtime(UNIX_TIMESTAMP(date_processed, 'yyyy-MM-dd HH:mm:ss'), 'dd/MM/yyyy') as dateprocessed from table_details",
"outputDFName": "table_details"
},
{
"functionName": "find the reference data from lookup",
"sqlQuery": "join_query_table_lookup.sql",
"outputDFName": "super_search_table_details"
}]
Fault tolerance: In addition to Apache Spark’s fault-tolerant capabilities, this solution offers the ability to recover data even after the Amazon EMR has been terminated. The application solution has three phases. In the event of a failure in the Apache Spark job, the output of the last successful phase is temporarily stored in Amazon S3. When the job is triggered again through Airflow DAG, the Apache Spark job will resume from the point at which it previously failed, thereby ensuring continuity and minimizing disruptions to the workflow. The following figure shows job reporting in the Amazon MWAA UI.
Scalability: As shown in the following figure, the Amazon EMR cluster is configured to use instance fleet options to scale up or down the number of nodes depending on the size of the data, which makes this application an ideal choice for businesses with growing data needs.
Customizable: This solution can be customized to meet the needs of specific use cases, allowing you to add your own transformations, validations, and reconciliations according to your unique data management requirements.
Enhanced data flexibility: By incorporating support for multiple file formats, the Apache Spark application and Airflow DAGs gain the ability to seamlessly integrate and process data from various sources. This advantage allows data engineers to work with a wide range of file formats, including JSON, XML, Text, CSV, Parquet, Avro, and so on.
Concurrent execution: Amazon MWAA submits the tasks to Amazon EMR for concurrent execution, using the scalability and performance of distributed computing to process large volumes of data efficiently.
Proactive error notification: Email notifications are sent to configured recipients whenever a task fails, providing timely awareness of failures and facilitating prompt troubleshooting.
Considerations
In our deployments, we have noticed that the average time of a DAG completion is 15–20 minutes containing 18 ETL processes concurrently and dealing with 900 thousand to 1.2 million records each. However, if you want to further optimize the DAG completion time, you can configure the core.dag_concurrency from the Amazon MWAA console as described in Example high performance use case.
Conclusion
The proposed code-driven data processing framework developed by Wipro using Amazon EMR Runtime for Apache Spark and Amazon MWAA demonstrates a solution to address the challenges associated with traditional ETL tools. By harnessing the capabilities from open source frameworks and seamlessly integrating with AWS services, you can build cost-effective, scalable, and automated approaches for your enterprise data processing pipelines.
Now that you have seen how to use Amazon EMR Runtime for Apache Spark with Amazon MWAA , we encourage you to use Amazon MWAA to create a workflow that will run your ETL jobs on Amazon EMR Runtime for Apache Spark.
The configuration file samples and example DAG code referred in this blog post can be found in GitHub.
Sample code, software libraries, command line tools, proofs of concept, templates, or other related technology are provided as AWS Content or third-party content under the AWS Customer Agreement, or the relevant written agreement between you and AWS (whichever applies). You should not use this AWS Content or third-party content in your production accounts, or on production or other critical data. Performance metrics, including the stated DAG completion time, may vary based on the specific deployment environment. You are responsible for testing, securing, and optimizing the AWS Content or third-party content, such as sample code, as appropriate for production grade use based on your specific quality control practices and standards. Deploying AWS Content or Third-Party Content may incur AWS charges for creating or using AWS chargeable resources, such as running Amazon EC2 instances or using Amazon S3 storage.
About the Authors
Deependra Shekhawat is a Senior Energy and Utilities Industry Specialist Solutions Architect based in Sydney, Australia. In his role, Deependra helps Energy companies across APJ region use cloud technologies to drive sustainability and operational efficiency. He specializes in creating robust data foundations and advanced workflows that enable organizations to harness the power of big data, analytics, and machine learning for solving critical industry challenges.
Senaka Ariyasinghe is a Senior Partner Solutions Architect working with Global Systems Integrators at AWS. In his role, Senaka guides AWS partners in the APJ region to design and scale well-architected solutions, focusing on generative AI, machine learning, cloud migrations, and application modernization initiatives.
Sandeep Kushwaha is a Senior Data Scientist at Wipro and has extensive experience in big data and machine learning. With a strong command of Apache Spark, Sandeep has designed and implemented cutting-edge cloud solutions that optimize data processing and drive efficiency. His expertise in using AWS services and best practices, combined with his deep knowledge of data management and automation, has enabled him to lead successful projects that meet complex technical challenges and deliver high-impact results.
In today’s rapidly evolving financial landscape, data is the bedrock of innovation, enhancing customer and employee experiences and securing a competitive edge. Recognizing this paradigm shift, ANZ Institutional Division has embarked on a transformative journey to redefine its approach to data management, utilization, and extracting significant business value from data insights.
Like many large financial institutions, ANZ Institutional Division operated with siloed data practices and centralized data management teams. As time went on, the limitations of this approach became apparent due to rising data complexity, larger volumes, and the growing demand for swift, business-driven insights. Consequently, the bank encountered several challenges and needed to take the following actions:
Create business insights from untapped data potential, estimated to be approximately $150 million in the Institutional Division alone
Improve operational efficiency by removing manual data handling, the use of spreadsheets, and duplicate data entries
Increase agility by making data expertise more readily available, thereby improving time to market and overall customer experience
Address data quality
Standardize tooling and remove the Shadow IT culture, driving scalability, reducing risk, and minimizing overall operational inefficiencies
These challenges are not unique to ANZ Institutional Division. Globally, financial institutions have been experiencing similar issues, prompting a widespread reassessment of traditional data management approaches.
One major trend, embraced by many financial institutions, has been the adoption of the data mesh architecture and the shift towards treating data as a product. This paradigm, pioneered by thought leaders like Zhamak Dehghani, introduces a decentralized approach to data management that aligns closely with modern organizational structures and agile methodologies.
Inspired by these global trends and driven by its own unique challenges, ANZ’s Institutional Division decided to pivot from viewing data as a byproduct of projects to treating it as a valuable product in its own right.
This shift promises several business benefits:
Empowered domain expertise – By decentralizing data ownership to domain-based teams, ANZ can use the deep business knowledge within each unit to create more relevant and valuable data products
Increased agility – Domain teams can now respond more quickly to business needs, creating and iterating on data products without relying on a centralized bottleneck
Improved data quality – With domain experts overseeing their own data, there’s a greater likelihood of catching and correcting quality issues at the source
Scalability – The federated approach allows for greater scalability, enabling ANZ to handle increasing data volumes and complexity more effectively
Innovation catalyst – By democratizing data access and empowering teams to create data products, ANZ is fostering a culture of innovation and data-driven decision-making across the organization
This transition is not just about technology; it represents a fundamental shift in how ANZ views and values its data assets. By treating data as a product, the bank is positioned to not only overcome current challenges, but to unlock new opportunities for growth, customer service, and competitive advantage.
This post explores how the shift to a data product mindset is being implemented, the challenges faced, and the early wins that are shaping the future of data management in the Institutional Division.
ANZ’s federated data strategy
In response to the challenges, ANZ Group formulated a data strategy that focuses on empowering employees to securely use data to improve the sustainability and financial well-being of their customers. At its core are the following pillars:
Introducing new ways of working that focus on generating customer value first
New technology platforms and tooling that allow the bank to collect, share, archive, and dispose data in a secure and controlled way
Achieving consistency in how data is produced and consumed across the entire bank through data products and better-connected systems
Supporting the bank’s risk and regulatory obligations by providing a secure and resilient data platform that provides fine-grained, controlled access to quality data products
ANZ has made the strategic decision to adopt an architectural and operational model aligned with the data mesh paradigm, which revolves around four key principles: domain ownership, data as a product, a self-serve data platform, and federated computational governance.
Domain ownership recognizes that the teams generating the data have the deepest understanding of it and are therefore best suited to manage, govern, and share it effectively. This principle makes sure data accountability remains close to the source, fostering higher data quality and relevance.
Treating data as a product instils a product-centric mindset, emphasizing that data must be secure, discoverable, understandable, interoperable, reusable, and managed throughout its lifecycle. This principle makes sure data consumers, both internal and external, derive consistent value from well-designed data products.
A self-serve data platform empowers domains to create, discover, and consume data products independently. It abstracts technical complexities and provides user-friendly tools, enabling a scalable, repeatable, and automated approach to producing high-quality data products.
Under the federated mesh architecture, each divisional mesh functions as a node within the broader enterprise data mesh, maintaining a degree of autonomy in managing its data products. To effectively coordinate these autonomous nodes and facilitate seamless integration, enterprise-wide standards, such as those related to data governance, interoperability, and security, are essential to maintain alignment and consistency across all nodes and domains and teams within.
With this approach, each node in ANZ maintains its divisional alignment and adherence to data risk and governance standards and policies to manage local data products and data assets. This enables global discoverability and collaboration without centralizing ownership or operations.
As a result, governance resides with the data products themselves, making sure standards and policies, such as access control, data quality, and compliance, are enforced where the data lives. In this regard, the enterprise data product catalog acts as a federated portal, facilitating cross-domain access and interoperability while maintaining alignment with governance principles. This model balances node or domain-level autonomy with enterprise-level oversight, creating a scalable and consistent framework across ANZ.
Within the ANZ enterprise data mesh strategy, aligning data mesh nodes with the ANZ Group’s divisional structure provides optimal alignment between data mesh principles and organizational structure, as shown in the following diagram.
Central to the success of this strategy is its support for each division’s autonomy and freedom to choose their own domain structure, which is closely aligned to their business needs. Divisions decide how many domains to have within their node; some may have one, others many. These nodes can implement analytical platforms like data lake houses, data warehouses, or data marts, all united by producing data products. Nodes and domains serve business needs and are not technology mandated.
Under the federated computational governance model, the ANZ Group strategy defines guardrails that treat a node as a logical data container suitable for the following:
Ingestion and metadata management
Creating source-aligned data products complying with ANZ’s Data Product Specification (DPS)
Integrating source-aligned data products from other nodes
Producing consumer-aligned data products for specific business purposes
Publishing conforming data products to ANZ’s Data Product Catalog (DPC)
Following on from this strategy is organizing its domain structure to provide autonomy to various functional teams while preserving the core values of data mesh. The following diagram depicts an example of the possible structure.
For instance, Domain A will have the flexibility to create data products that can be published to the divisional catalog, while also maintaining the autonomy to develop data products that are exclusively accessible to teams within the domain. These products will not be available to others until they are deemed ready for broader enterprise use.
This strategy supports each division’s autonomy to implement their own data catalogs and decide which data products to publish to the group-level catalog. This flexibility extends to divisional domains, which can choose which data products to publish to the divisional catalog or keep visible only to domain consumers.
Institutional Data & AI Platform architecture
The Institutional Division has implemented a self-service data platform to enable the domain teams to build and manage data products autonomously. The Institutional Data & AI platform adopts a federated approach to data while centralizing the metadata to facilitate simpler discovery and sharing of data products. The following diagram illustrates the building blocks of the Institutional Data & AI Platform.
The building blocks are as follows:
Foundational Data & AI Platform capabilities – A dedicated data platform team provides domain-agnostic tools, systems, and capabilities to enable autonomous data product development across domains. This self-serve infrastructure allows domain teams to manage the full data lifecycle without relying on a centralized data team. Key capabilities include data storage, data onboarding and transformation, and data utilities that facilitate data sharing with interoperability between domains. These capabilities abstract the technical complexities associated with data management infrastructure, allowing domain experts to focus on creating valuable data products rather than infrastructure management.
Domain-owned data assets – The domain-oriented data ownership approach distributes responsibility for data across the business units within the Institutional Division. Domain teams are responsible for developing, deploying, and managing their own analytical data products alongside operational data services. Data contracts authored by data product owners automate data product creation and provide a standard to access data products. By treating the data as a product, the outcome is a reusable asset that outlives a project and meets the needs of the enterprise consumer. Consumer feedback and demand drives creation and maintenance of the data product.
Division-level metadata management and data governance – A centrally hosted service provides domain teams with the capability to publish their data products along with relevant metadata, like business definitions and lineage. Some of the key features implemented are:
Metadata management that centralizes metadata and presents it within the context of data products, such as data quality scores and data product lineage.
A data portal for consumers to discover data products and access associated metadata.
Subscription workflows that simplify access management to the data products.
Computational governance that enforces divisional and enterprise data policies and standards, such as data classification and business data models for aligning terminology.
The following diagram is a high-level example of the technical architecture approach towards the Institutional Data & AI Platform. The solution uses a building block approach, on a cloud-centered platform comprised of AWS services, with partner solutions and open standards like OpenLineage and Apache Iceberg.
Let’s look at the key services that enable the federated platform to operate at scale:
Amazon Redshift allows domain teams to create and manage fit-for-purpose data marts
AWS Lambda and AWS Glue are used for data onboarding and processing, and data utilities created in Python and PySpark promote reusability and quality across the data processing pipelines
dbt simplifies data transformation rules and allows sub-domain data analysts to build modeling logic as SQL statements
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) enables efficient management of workflows and data pipeline orchestration using out-of-the-box integrations with AWS services
Metadata management and data governance:
To maintain data reliability and accuracy, a robust data quality framework using Soda core is used that automates data quality using checks defined in a data contract
Amazon DataZone enables data product cataloging, discovery, metadata management, and implementing computational governance
OpenLineage simplifies harvesting and collection of data and process-level lineage, which are then published to Amazon DataZone
Tableau offers capabilities for sub-domains with data visualization and business intelligence capabilities
Observability and security:
Observability needs of the platform are built into all the processes using monitoring, with logging functionality provided by Amazon CloudWatch and AWS CloudTrail
AWS Secrets Manager makes sure secrets are stored and made available for data pipelines to access services in a secure manner
The technical implementation actualizes the data product strategy at ANZ Institutional Division. Amazon DataZone plays an essential role in facilitating data product management for the domain teams. The service addresses several critical aspects of the Institutional Division’s data product strategy, including:
Data cataloging and metadata management – Amazon DataZone provides comprehensive data cataloging and metadata management capabilities
Data governance and compliance – Effective data governance is essential for scaling data products
Self-service capabilities – Amazon DataZone empowers domain teams with self-service capabilities, enabling them to create, manage, and deploy data products independently
Integration and interoperability – One of the challenges in scaling data products is providing seamless integration across various data sources and systems
Collaboration and sharing – Amazon DataZone provides a platform for sharing data and metadata across teams and domains
Institutional Division’s delivery model to achieve scale
The Institutional Division has successfully used the federated architecture, and key to this delivery model is the implementation of Foundational Data & AI Platform capabilities that serve all domains within the division. This model promotes self-service and accelerates the delivery of subsequent initiatives by using the capabilities built for previous use cases.
To evaluate the success of the delivery model, ANZ has implemented key metrics, such as cost transparency and domain adoption, to guide the data mesh governance team in refining the delivery approach. For instance, one enhancement involves integrating cross-functional squads to support data literacy.
The key to scaling the Institutional Division operating model are the following considerations:
Data as a product approach – Use techniques like event storming and domain-driven design to capture business events and their meanings.
Education and enablement – Conduct learning interventions to upskill teams on understanding and using the data as a product approach.
Iterative data platformdelivery – Work backward from business initiative to iteratively deliver self-service data platform infrastructure capabilities.
Managing demand efficiently – Implement a feedback mechanism to manage demand on data products. Track and manage data debt using standard data contract specifications. Most importantly, adopt governance and standards to make sure data products are built and maintained with a long-term perspective, minimizing technical debt.
“The Institutional Data & Analytics Platform (IDAP) has allowed the Institutional team to establish a base foundation to allow various teams to aggregate and consume the wealth of data across the division. This self-service platform enables business leaders to both create and consume reusable data products, unlocking value across this division. It’s also an excellent proof point for our broader data mesh architecture, allowing us to connect this divisional data to broader enterprise data stores—further positioning us to put the customer at the center of everything we do.”
– Tim Hogarth, CTO ANZ
“AWS believes that democratizing data, while not compromising on security and fine-grained access, is a key component of any future-proof, scalable data platform, so we are pleased to be enabling ANZ bank’s IDAP metadata management and data governance capabilities through Amazon DataZone. This allows the diverse business functions at ANZ the autonomy to self-serve on their data needs with built-in governance.”
– Shikha Verma, Head of Product, Amazon DataZone
Conclusion
ANZ’s journey to move towards a data product approach has improved the organization’s approach to manage data and reduce data silos, and has positioned it to become a data-driven, customer-centric organization. By combining federated platform practices and adopting AWS services and open standards, ANZ Institutional Division is achieving its objectives in decentralization with a scalable data platform that enables its domain teams to make informed decisions, drive innovation, and maintain a competitive edge.
Special thanks: This implementation success is a result of close collaboration between ANZ Institutional Division, AWS ProServe, and the AWS account team. We want to thank ANZ Institutional Executives and the Leadership Team for the strong sponsorship and direction.
About the Authors
Leo Ramsamy is a Platform Architect specializing in data and analytics for ANZ’s Institutional division. He focuses on modern data practices, including Data Mesh architecture, data governance, quality management, and observability. His work aligns data strategies with business goals, improving accessibility and enabling better decision-making across ANZ.
Srinivasan Kuppusamy is a Senior Cloud Architect – Data at AWS ProServe, where he helps customers solve their business problems using the power of AWS Cloud technology. His areas of interests are data and analytics, data governance, and AI/ML.
Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.
Amazon Managed Workflows for Apache Airflow (Amazon MWAA), is a managed Apache Airflow service used to extract business insights across an organization by combining, enriching, and transforming data through a series of tasks called a workflow. It enhances infrastructure security and availability while reducing operational overhead.
Today, we’re excited to announce mw1.micro, the latest addition to Amazon MWAA environment classes. This offering is designed to provide an even more cost-effective solution for running Airflow environments in the cloud. With mw1.micro, we’re bringing the power of Amazon MWAA to teams who require a lightweight environment without compromising on essential features. In this post, we’ll explore mw1.micro characteristics, key benefits, ideal use cases, and how you can set up an Amazon MWAA environment based on this new environment class.
Customers maintain multiple MWAA environments to separate development stages, optimize resources, manage versions, enhance security, ensure redundancy, customize settings, improve scalability, and facilitate experimentation. This approach offers greater flexibility and control over workflow management. These organizations often maintain multiple AWS accounts for development, testing, and production stages, leading to increased complexity and cost. The traditional approach of using full-sized Amazon MWAA environments for development and testing can also be expensive, especially for teams working on smaller projects or proof-of-concept initiatives. Additionally, customers adopting a federated deployment model find it challenging to provide isolated environments for different teams or departments, and at the same time optimize cost. The introduction of mw1.micro addresses these pain points by offering an option that enables a more efficient resource utilization and significant cost savings.
The micro environment class
The mw1.micro configuration provides a balanced set of resources suitable for small-scale data processing and orchestration tasks. The class allocates 1 vCPU and 3GB of RAM for a scheduler/worker hybrid container. Similarly, the web server is equipped with 1 vCPU and 3 GB RAM configuration. The Amazon Elastic Container Service (Amazon ECS) tasks launched in the environment use AWS Fargate platform version 1.4.0, increasing ephemeral task storage to 20 GB.
mw1.micro environments support up to three concurrent tasks, making it ideal for sequential or lightly parallelized workflows. Additionally, it can accommodate up to 25 DAGs, providing ample capacity for organizing and managing various data pipelines and processes. This micro environment is particularly well-suited for development, testing, or small production workloads where resource optimization and cost-efficiency are primary concerns.
For mw1.micro, we maintain the general architecture of Amazon MWAA, and combine the Airflow scheduler and worker into a single container. For this reason, mw1.micro uses only two AWS Fargate tasks, one scheduler/worker hybrid, and one web server. The following diagram illustrates the environment architecture.
Another important change is that the meta database will now use a t4g.mediumAmazon Aurora PostgreSQL-Compatible Edition instance powered by AWS Graviton2. With the Graviton2 family of processors, you get compute, storage, and networking improvements, and the reduction of your carbon footprint offered by the AWS family of processors.
Supported features
mw1.micro maintains Amazon MWAA and Airflow key functionalities that developers currently rely on:
You can set up a public or private web server, allowing you to control access to your Airflow UI as needed
You can add custom plugins and requirements, enabling you to extend Airflow’s capabilities and manage dependencies effortlessly
Startup scripts can be used to perform initialization tasks, making sure your environment is configured precisely to your specifications
The Airflow UI is fully functional, providing the same intuitive interface for managing and monitoring your workflows
It has the same networking features as other Amazon MWAA environment classes, such as custom URLs and shared virtual private cloud (VPC) support
Scheduler and worker logs remain separate in their respective Amazon CloudWatch log groups, providing ease of monitoring and troubleshooting
Considerations
The architectural decisions behind mw1.micro reflect a balance between functionality and cost-effectiveness. Here are the constraints the limited resources in mw1.micro brings:
The scheduler and worker are combined into a single Fargate task. Only a single scheduler/worker container is supported.
micro consists of a single Fargate task for the web server. The maximum number of web servers is 1.
The number of concurrent Airflow tasks in the worker (worker_autoscale) can be set to a maximum value of 3.
Pricing and availability
Amazon MWAA pricing dimensions remains unchanged, and you only pay for what you use:
When you start using the new environment class, it’s important to understand its behavior for maintaining optimal operation and identifying potential capacity issues. It’s essential to monitor key metrics such as metadata database memory usage, and CPU utilization of the worker/scheduler hybrid container. We recommend following the guidance described in Introducing container, database, and queue utilization metrics for Amazon MWAA to better understand the state of your environments, and get insights to right-size your resources.
The Amazon MWAA micro environment class is available today in all Regions where Amazon MWAA is currently available.
Conclusion
In this post, we announced the availability of the new micro environment class in Amazon MWAA. This offering addresses the needs of teams working on smaller projects, proof-of-concept initiatives, or those requiring isolated environments for different departments. By providing a lightweight yet feature-rich solution, mw1.micro enables organizations to achieve substantial cost savings without compromising on essential functionalities.
As you explore the possibilities of mw1.micro, remember to monitor its performance using the recommended metrics to maintain optimal operation. With its availability across all Regions where Amazon MWAA is offered, your teams can now use the power of Airflow in a more streamlined and economical manner, opening up new opportunities for efficient data pipeline management and orchestration in the cloud.
Apache, Apache Airflow, and Airflow are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries.
About the Authors
Hernan Garcia is a Senior Solutions Architect at AWS based in the Netherlands. He works in the financial services industry, supporting enterprises in their cloud adoption. He is passionate about serverless technologies, security, and compliance. He enjoys spending time with family and friends, and trying out new dishes from different cuisines.
Sriharsh Adari is a Senior Solutions Architect at AWS, where he helps customers work backward from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise includes technology strategy, data analytics, and data science. In his spare time, he enjoys playing sports, watching TV shows, and playing Tabla.
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a fully managed service that builds upon Apache Airflow, offering its benefits while eliminating the need for you to set up, operate, and maintain the underlying infrastructure, reducing operational overhead while increasing security and resilience.
Today, we are excited to announce an enhancement to the Amazon MWAA integration with the Airflow REST API. This improvement streamlines the ability to access and manage your Airflow environments and their integration with external systems, and allows you to interact with your workflows programmatically. The Airflow REST API facilitates a wide range of use cases, from centralizing and automating administrative tasks to building event-driven, data-aware data pipelines.
In this post, we discuss the enhancement and present several use cases that the enhancement unlocks for your Amazon MWAA environment.
Airflow REST API
The Airflow REST API is a programmatic interface that allows you to interact with Airflow’s core functionalities. It’s a set of HTTP endpoints to perform operations such as invoking Directed Acyclic Graphs (DAGs), checking task statuses, retrieving metadata about workflows, managing connections and variables, and even initiating dataset-related events, without directly accessing the Airflow web interface or command line tools.
Before today, Amazon MWAA provided the foundation for interacting with the Airflow REST API. Though functional, the process of obtaining and managing access tokens and session cookies added complexity to the workflow. Amazon MWAA now supports a simplified mechanism for interacting with the Airflow REST API using AWS credentials, significantly reducing complexity and improving overall usability.
Enhancement overview
The new InvokeRestApi capability allows you to run Airflow REST API requests with a valid SigV4 signature using your existing AWS credentials. This feature is now available to all Amazon MWAA environments (2.4.3+) in supported Amazon MWAA AWS Regions. By acting as an intermediary, this REST API processes requests on behalf of users, requiring only the environment name and API request payload as inputs.
Integrating with the Airflow REST API through the enhanced Amazon MWAA API provides several key benefits:
Simplified integration – The new InvokeRestApi capability in Amazon MWAA removes the complexity of managing access tokens and session cookies, making it straightforward to interact with the Airflow REST API.
Improved usability – By acting as an intermediary, the enhanced API delivers Airflow REST API execution results directly to the client, reducing complexity and improving overall usability.
Automated administration – The simplified REST API access enables automating various administrative and management tasks, such as managing Airflow variables, connections, slot pools, and more.
Event-driven architectures – The enhanced API facilitates seamless integration with external events, enabling the triggering of Airflow DAGs based on these events. This supports the growing emphasis on event-driven data pipelines.
Data-aware scheduling – Using the dataset-based scheduling feature in Airflow, the enhanced API enables the Amazon MWAA environment to manage the incoming workload and scale resources accordingly, improving the overall reliability and efficiency of event-driven pipelines.
In the following sections, we demonstrate how to use the enhanced API in various use cases.
How to use the enhanced Amazon MWAA API
The following code snippet shows the general request format for the enhanced REST API:
The Name of the Amazon MWAA environment, the Path of the Airflow REST API endpoint to be called, and the HTTP Method to use are the required parameters, whereas QueryParameters and Body are optional and can be used as needed in the API calls.
The following code snippet shows the general response format:
The RestApiStatusCode represents the HTTP status code returned by the Airflow REST API call, and the RestApiResponse contains the response payload from the Airflow REST API.
The following sample code snippet showcases how to update the description field of an Airflow variable using the enhanced integration. The call uses the AWS Python SDK to invoke the Airflow REST API for the task.
import boto3
# Create a boto3 client
mwaa_client = boto3.client("mwaa")
# Call the enhanced REST API using boto3 client
# Using QueryParameters, you can selectively specify the field to be updated
# Without QueryParameters, all fields will be updated
response = mwaa_client.invoke_rest_api(
Name="<your-environment-name>",
Method="PATCH",
Path=f"/variables/<your-variable-key>",
Body={
"key": "<key>",
"value": "<value>",
"description": "<description>"
},
QueryParameters={
"update_mask": ["description"]
}
)
# Access the outputs of the REST call
status_code = response["RestApiStatusCode"]
result = response['RestApiResponse']
To make the invoke_rest_api SDK call, the calling client should have an AWS Identity and Access Management (IAM) principal of airflow:InvokeRestAPI attached to call the requisite environment. The permission can be scoped to specific Airflow roles (Admin, Op, User, Viewer, or Public) to control access levels.
This simple yet powerful REST API supports various use cases for your Amazon MWAA environments. Let’s review some important ones in the subsequent sections.
Automate administration and management tasks
Prior to this launch, to automate configurations and setup of resources such as variables, connections, slot pools, and more, you had to develop a lengthy boilerplate code to make API requests to the Amazon MWAA web servers. You had to handle the cookie and session management in the process. You can simplify this automation with the new enhanced REST API support.
For this example, let’s assume you want to automate maintaining your Amazon MWAA environment variables. You need to perform API operations such as create, read, update, and delete on Airflow variables to achieve this task. The following is a simple Python client to do so (mwaa_variables_client.py):
import boto3
# Client for managing MWAA environment variables
class MWAAVariablesClient:
# Initialize the client with environment name and optional MWAA boto3 client
def __init__(self, env_name, mwaa_client=None):
self.env_name = env_name
self.client = mwaa_client or boto3.client("mwaa")
# List all variables in the MWAA environment
def list(self):
response = self.client.invoke_rest_api(
Name=self.env_name,
Method="GET",
Path="/variables"
)
output = response['RestApiResponse']['variables']
return output
# Get a specific variable by key
def get(self, key):
response = self.client.invoke_rest_api(
Name=self.env_name,
Method="GET",
Path=f"/variables/{key}"
)
return response['RestApiResponse']
# Create a new variable with key, value, and optional description
def create(self, key, value, description=None):
response = self.client.invoke_rest_api(
Name=self.env_name,
Method="POST",
Path="/variables",
Body={
"key": key,
"value": value,
"description": description
}
)
return response['RestApiResponse']
# Update an existing variable's value and description
def update(self, key, value, description, query_parameters=None):
response = self.client.invoke_rest_api(
Name=self.env_name,
Method="PATCH",
Path=f"/variables/{key}",
Body={
"key": key,
"value": value,
"description": description
},
QueryParameters=query_parameters
)
return response['RestApiResponse']
# Delete a variable by key
def delete(self, key):
response = self.client.invoke_rest_api(
Name=self.env_name,
Method="DELETE",
Path=f"/variables/{key}"
)
return response['RestApiStatusCode']
if __name__ == "__main__":
client = MWAAVariablesClient("<your-mwaa-environment-name>")
print("\nCreating a test variable ...")
response = client.create(
key="test",
value="Test value",
description="Test description"
)
print(response)
print("\nListing all variables ...")
variables = client.list()
print(variables)
print("\nGetting the test variable ...")
response = client.get("test")
print(response)
print("\nUpdating the value and description of test variable ...")
response = client.update(
key="test",
value="Updated Value",
description="Updated description"
)
print(response)
print("\nUpdating only description of test variable ...")
response = client.update(
key="test",
value="Updated Value",
description="Yet another updated description",
query_parameters={ "update_mask": ["description"] }
)
print(response)
print("\nDeleting the test variable ...")
response_code = client.delete("test")
print(f"Response code: {response_code}")
print("\nFinally, getting the deleted test variable ...")
try:
response = client.get("test")
print(response)
except Exception as e:
print(e.response["RestApiResponse"])
Assuming that you have configured your terminal with appropriate AWS credentials, you can run the preceding Python script to achieve the following results:
$python mwaa_variables_client.py
Creating a test variable ...
{'description': 'Test description', 'key': 'test', 'value': 'Test value'}
Listing all variables ...
[{'key': 'test', 'value': 'Test value'}]
Getting the test variable ...
{'key': 'test', 'value': 'Test value'}
Updating the value and description of test variable ...
{'description': 'Updated description', 'key': 'test', 'value': 'Updated Value'}
Updating only description of test variable ...
{'description': 'Yet another updated description', 'key': 'test', 'value': 'Updated Value'}
Deleting the test variable ...
Response code: 204
Finally, getting the deleted test variable ...
{'detail': 'Variable does not exist', 'status': 404, 'title': 'Variable not found', 'type': 'https://airflow.apache.org/docs/apache-airflow/2.8.1/stable-rest-api-ref.html#section/Errors/NotFound'}
Let’s further explore other useful use cases.
Build event-driven data pipelines
The Airflow community has been actively innovating to enhance the platform’s data awareness, enabling you to build more dynamic and responsive workflows. When we announced support for version 2.9.2 in Amazon MWAA, we introduced capabilities that allow pipelines to react to changes in datasets, both within Airflow environments and in external systems. The new simplified integration with the Airflow REST API makes the implementation of data-driven pipelines more straightforward.
Consider a use case where you need to run a pipeline that uses input from an external event. The following sample DAG runs a bash command supplied as a parameter (any_bash_command.py):
"""
This DAG allows you to execute a bash command supplied as a parameter to the DAG.
The command is passed as a parameter called `command` in the DAG configuration.
"""
from airflow import DAG
from airflow.operators.bash_operator import BashOperator
from airflow.models.param import Param
from datetime import datetime
with DAG(
dag_id="any_bash_command",
schedule=None,
start_date=datetime(2022, 1, 1),
catchup=False,
params={
"command": Param("env", type="string")
},
) as dag:
cli_command = BashOperator(
task_id="triggered_bash_command",
bash_command="{{ dag_run.conf['command'] }}"
)
With the help of the enhanced REST API, you can create a client that can invoke this DAG, supplying the bash command of your choice as follows (mwaa_dag_run_client.py):
import boto3
# Client for triggering DAG runs in Amazon MWAA
class MWAADagRunClient:
# Initialize the client with MWAA environment name and optional MWAA boto3 client
def __init__(self, env_name, mwaa_client=None):
self.env_name = env_name
self.client = mwaa_client or boto3.client("mwaa")
# Trigger a DAG run with specified parameters
def trigger_run(self,
dag_id,
dag_run_id=None,
logical_date=None,
data_interval_start=None,
data_interval_end=None,
note=None,
conf=None,
):
body = {}
if dag_run_id:
body["dag_run_id"] = dag_run_id
if logical_date:
body["logical_date"] = logical_date
if data_interval_start:
body["data_interval_start"] = data_interval_start
if data_interval_end:
body["data_interval_end"] = data_interval_end
if note:
body["note"] = note
body["conf"] = conf or {}
response = self.client.invoke_rest_api(
Name=self.env_name,
Method="POST",
Path=f"/dags/{dag_id}/dagRuns",
Body=body
)
return response['RestApiResponse']
if __name__ == "__main__":
client = MWAADagRunClient("<your-mwaa-environment-name>")
print("\nTriggering a dag run ...")
result = client.trigger_run(
dag_id="any_bash_command",
conf={
"command": "echo 'Hello from external trigger!'"
}
)
print(result)
The following snippet shows a sample run of the script:
$python mwaa_dag_run_client.py
Triggering a dag run ...
{'conf': {'command': "echo 'Hello from external trigger!'"}, 'dag_id': 'any_bash_command', 'dag_run_id': 'manual__2024-10-21T16:56:09.852908+00:00', 'data_interval_end': '2024-10-21T16:56:09.852908+00:00', 'data_interval_start': '2024-10-21T16:56:09.852908+00:00', 'execution_date': '2024-10-21T16:56:09.852908+00:00', 'external_trigger': True, 'logical_date': '2024-10-21T16:56:09.852908+00:00', 'run_type': 'manual', 'state': 'queued'}
On the Airflow UI, the trigger_bash_command task shows the following execution log:
[2024-10-21, 16:56:12 UTC] {local_task_job_runner.py:123} ▶ Pre task execution logs
[2024-10-21, 16:56:12 UTC] {subprocess.py:63} INFO - Tmp dir root location: /tmp
[2024-10-21, 16:56:12 UTC] {subprocess.py:75} INFO - Running command: ['/usr/bin/bash', '-c', "echo 'Hello from external trigger!'"]
[2024-10-21, 16:56:12 UTC] {subprocess.py:86} INFO - Output:
[2024-10-21, 16:56:12 UTC] {subprocess.py:93} INFO - Hello from external trigger!
[2024-10-21, 16:56:12 UTC] {subprocess.py:97} INFO - Command exited with return code 0
[2024-10-21, 16:56:12 UTC] {taskinstance.py:340} ▶ Post task execution logs
You can further expand this example to more useful event-driven architectures. Let’s expand the use case to run your data pipeline and perform extract, transform, and load (ETL) jobs when a new file lands in an Amazon Simple Storage Service (Amazon S3) bucket in your data lake. The following diagram illustrates one architectural approach.
In the context of invoking a DAG through an external input, the AWS Lambda function would have no knowledge of how busy the Amazon MWAA web server is, potentially leading to the function overwhelming the Amazon MWAA web server by processing a large number of files in a short timeframe.
One way to regulate the file processing throughput would be to introduce an Amazon Simple Queue Service (Amazon SQS) queue between the S3 bucket and the Lambda function, which can help with rate limiting the API requests to the web server. You can achieve this by configuring maximum concurrency for Lambda for the SQS event source. However, the Lambda function would still be unaware of the processing capacity available in the Amazon MWAA environment to run the DAGs.
In addition to the SQS queue, to help afford the Amazon MWAA environment manage the load natively, you can use the Airflow’s data-aware scheduling feature using datasets. This approach involves using the enhanced Amazon MWAA REST API to create dataset events, which are then used by the Airflow scheduler to schedule the DAG natively. This way, the Amazon MWAA environment can effectively batch the dataset events and scale resources based on the load. Let’s explore this approach in more detail.
Configure data-aware scheduling
Consider the following DAG that showcases a framework for an ETL pipeline (data_aware_pipeline.py). It uses a dataset for scheduling.
"""
DAG to run the given ETL pipeline based on the datalake dataset event.
"""
from airflow import DAG, Dataset
from airflow.decorators import task
from datetime import datetime
# Create a dataset
datalake = Dataset("datalake")
# Return a list of S3 file URIs from the supplied dataset events
def get_resources(dataset_uri, triggering_dataset_events=None):
events = triggering_dataset_events[dataset_uri] if triggering_dataset_events else []
s3_uris = list(map(lambda e: e.extra["uri"], events))
return s3_uris
with DAG(
dag_id="data_aware_pipeline",
schedule=[datalake],
start_date=datetime(2022, 1, 1),
catchup=False
):
@task
def extract(triggering_dataset_events=None):
resources = get_resources("datalake", triggering_dataset_events)
for resource in resources:
print(f"Running data extraction for {resource} ...")
@task
def transform(triggering_dataset_events=None):
resources = get_resources("datalake", triggering_dataset_events)
for resource in resources:
print(f"Running data transformation for {resource} ...")
@task()
def load(triggering_dataset_events=None):
resources = get_resources("datalake", triggering_dataset_events)
for resource in resources:
print(f"Loading finalized data for {resource} ...")
extract() >> transform() >> load()
In the preceding code snippet, a Dataset object called datalake is used to schedule the DAG. The get_resources function extracts the extra information that contains the locations of the newly added files in the S3 data lake. Upon receiving dataset events, the Amazon MWAA environment batches the dataset events based on the load and schedules the DAG to handle them appropriately. The modified architecture to support the data-aware scheduling is presented below.
The following is a simplified client that can create a dataset event through the enhanced REST API (mwaa_dataset_client.py):
import boto3
# Client for interacting with MWAA datasets
class MWAADatasetClient:
# Initialize the client with environment name and optional MWAA boto3 client
def __init__(self, env_name, mwaa_client=None):
self.env_name = env_name
self.client = mwaa_client or boto3.client("mwaa")
# Create a dataset event in the MWAA environment
def create_event(self, dataset_uri, extra=None):
body = {
"dataset_uri": dataset_uri
}
if extra:
body["extra"] = extra
response = self.client.invoke_rest_api(
Name=self.env_name,
Method="POST",
Path="/datasets/events",
Body=body
)
return response['RestApiResponse']
The following is a code snippet for the Lambda function in the preceding architecture to generate the dataset event, assuming the function is configured to handle one S3 PUT event at a time (dataset_event_lambda.py):
import os
import json
from mwaa_dataset_client import MWAADatasetClient
environment = os.environ["MWAA_ENV_NAME"]
client = MWAADatasetClient(environment)
def handler(event, context):
# Extract S3 file URI from SQS record
record = event["Records"][0]
bucket = record["s3"]["bucket"]["name"]
key = record["s3"]["object"]["key"]
s3_file_uri = f"s3://{bucket}/{key}"
# Create a dataset event
result = client.create_event(
dataset_uri="datalake",
extra={"uri": s3_file_uri}
)
return {
"statusCode": 200,
"body": json.dumps(result)
}
As new files get dropped into the S3 bucket, the Lambda function will generate a dataset event per file, passing in the Amazon S3 location of the newly added files. The Amazon MWAA environment will schedule the ETL pipeline upon receiving the dataset events. The following diagram illustrates a sample run of the ETL pipeline on the Airflow UI.
The following snippet shows the execution log of the extract task from the pipeline. The log shows how the Airflow scheduler batched three dataset events together to handle the load.
[2024-10-21, 16:47:15 UTC] {local_task_job_runner.py:123} ▶ Pre task execution logs
[2024-10-21, 16:47:15 UTC] {logging_mixin.py:190} INFO - Running data extraction for s3://example-bucket/path/to/file1.csv ...
[2024-10-21, 16:47:15 UTC] {logging_mixin.py:190} INFO - Running data extraction for s3://example-bucket/path/to/file2.csv ...
[2024-10-21, 16:47:15 UTC] {logging_mixin.py:190} INFO - Running data extraction for s3://example-bucket/path/to/file3.csv ...
[2024-10-21, 16:47:15 UTC] {python.py:240} INFO - Done. Returned value was: None
[2024-10-21, 16:47:16 UTC] {taskinstance.py:340} ▶ Post task execution logs
In this way, you can use the enhanced REST API to create data-aware, event-driven pipelines.
Considerations
When implementing solutions using the enhanced Amazon MWAA REST API, it’s important to consider the following:
IAM permissions – Make sure the IAM principal making the invoke_rest_api SDK call has the airflow:InvokeRestAPI permission on the Amazon MWAA resource. To control access levels, the permission can be scoped to specific Airflow roles (Admin, Op, User, Viewer, or Public).
Error handling – Implement robust error handling mechanisms to handle various HTTP status codes and error responses from the Airflow REST API.
Monitoring and logging – Set up appropriate monitoring and logging to track the performance and reliability of your API-based integrations and data pipelines.
Versioning and compatibility – Monitor the versioning of the Airflow REST API and the Amazon MWAA service to make sure your integrations remain compatible with any future changes.
Security and compliance – Adhere to your organization’s security and compliance requirements when integrating external systems with Amazon MWAA and handling sensitive data.
You can start using the simplified integration with the Airflow REST API in your Amazon MWAA environments with Airflow version 2.4.3 or greater, in all currently supported Regions.
Conclusion
The enhanced integration between Amazon MWAA and the Airflow REST API represents a significant improvement in the ease of interacting with Airflow’s core functionalities. This new capability opens up a wide range of use cases, from centralizing and automating administrative tasks, improving overall usability, to building event-driven, data-aware data pipelines.
As you explore this new feature, consider the various use cases and best practices outlined in this post. By using the new InvokeRestApi, you can streamline your data management processes, enhance operational efficiency, and drive greater value from your data-driven systems.
About the Authors
Chandan Rupakheti is a Senior Solutions Architect at AWS. His main focus at AWS lies in the intersection of analytics, serverless, and AdTech services. He is a passionate technical leader, researcher, and mentor with a knack for building innovative solutions in the cloud. Outside of his professional life, he loves spending time with his family and friends, and listening to and playing music.
Hernan Garcia is a Senior Solutions Architect at AWS based out of Amsterdam. He has worked in the financial services industry since 2018, specializing in application modernization and supporting customers in their adoption of the cloud with a focus on serverless technologies.
Customers who use Amazon Managed Workflows for Apache Airflow (Amazon MWAA) often need Python dependencies that are hosted in private code repositories. Many customers opt for public network access mode for its ease of use and ability to make outbound Internet requests, all while maintaining secure access. However, private code repositories may not be accessible via the Internet. It’s also a best practice to only install Python dependencies where they are needed. You can use Amazon MWAA startup scripts to selectively install Python dependencies required for running code on workers, while avoiding issues due to web server restrictions.
This post demonstrates a method to selectively install Python dependencies based on the Amazon MWAA component type (web server, scheduler, or worker) from a Git repository only accessible from your virtual private cloud (VPC).
Solution overview
This solution focuses on using a private Git repository to selectively install Python dependencies, although you can use the same pattern demonstrated in this post with private Python package indexes such as AWS CodeArtifact. For more information, refer to Amazon MWAA with AWS CodeArtifact for Python dependencies.
The Amazon MWAA architecture allows you to choose a web server access mode to control whether the web server is accessible from the internet or only from your VPC. You can also control whether your workers, scheduler, and web servers have access to the internet through your customer VPC configuration. In this post, we demonstrate an environment such as the one shown in the following diagram, where the environment is using public network access mode for the web servers, and the Apache Airflow workers and schedulers don’t have a route to the internet from your VPC.
There are up to four potential networking configurations for an Amazon MWAA environment:
Public routing and public web server access mode
Private routing and public web server access mode (pictured in the preceding diagram)
Public routing and private web server access mode
Private routing and private web server access mode
We focus on one networking configuration for this post, but the fundamental concepts are applicable for any networking configuration.
The solution we walk through relies on the fact that Amazon MWAA runs a startup script (startup.sh) during startup on every individual Apache Airflow component (worker, scheduler, and web server) before installing requirements (requirements.txt) and initializing the Apache Airflow process. This startup script is used to set an environment variable, which is then referenced in the requirements.txt file to selectively install libraries.
The following steps allow us to accomplish this:
Create and install the startup script (startup.sh) in the Amazon MWAA environment. This script sets the environment variable for selectively installing dependencies.
Create and install global Python dependencies (requirements.txt) in the Amazon MWAA environment. This file contains the global dependencies required by all Amazon MWAA components.
Create and install component-specific Python dependencies in the Amazon MWAA environment. This step involves creating separate requirements files for each component type (worker, scheduler, web server) to selectively install the necessary dependencies.
Prerequisites
For this walkthrough, you should have the following prerequisites:
Create and install the startup script in the Amazon MWAA environment
Create the startup.sh file using the following example code:
#!/bin/sh
echo "Printing Apache Airflow component"
echo $MWAA_AIRFLOW_COMPONENT
if [[ "${MWAA_AIRFLOW_COMPONENT}" != "webserver" ]]
then
sudo yum -y install libaio
fi
if [[ "${MWAA_AIRFLOW_COMPONENT}" == "webserver" ]]
then
echo "Setting extended python requirements for webservers"
export EXTENDED_REQUIREMENTS="webserver_reqs.txt"
fi
if [[ "${MWAA_AIRFLOW_COMPONENT}" == "worker" ]]
then
echo "Setting extended python requirements for workers"
export EXTENDED_REQUIREMENTS="worker_reqs.txt"
fi
if [[ "${MWAA_AIRFLOW_COMPONENT}" == "scheduler" ]]
then
echo "Setting extended python requirements for schedulers"
export EXTENDED_REQUIREMENTS="scheduler_reqs.txt"
fi
Upload startup.sh to the S3 bucket for your Amazon MWAA environment:
Browse the CloudWatch log streams for your workers and view the worker_console log. Notice the startup script is now running and setting the environment variable.
Create and install global Python dependencies in the Amazon MWAA environment
Your requirements file must include a –constraint statement to make sure the packages listed in your requirements are compatible with the version of Apache Airflow you are using. The statement beginning with -r references the environment variable you set in your startup.sh script based on the component type.
The following code is an example of the requirements.txt file:
Create and install component-specific Python dependencies in the Amazon MWAA environment
For this example, we want to install the Python package scrapy on workers and schedulers from our private Git repository. We also want to install pprintpp on the web server from the public Python packages indexes. To accomplish that, we need to create the following files (we provide example code):
Browse the CloudWatch log streams for your workers and view the requirements_install log. Notice the startup script is now running and setting the environment variable.
Conclusion
In this post, we demonstrated a method to selectively install Python dependencies based on the Amazon MWAA component type (web server, scheduler, or worker) from a Git repository only accessible from your VPC.
We hope this post provided you with a better understanding of how startup scripts and Python dependency management work in an Amazon MWAA environment. You can implement other variations and configurations using the concepts outlined in this post, depending on your specific network setup and requirements.
About the Author
Tim Wilhoit is a Sr. Solutions Architect for the Department of Defense at AWS. Tim has over 20 years of enterprise IT experience. His areas of interest are serverless computing and ML/AI. In his spare time, Tim enjoys spending time at the lake and rooting on the Oklahoma State Cowboys. Go Pokes!
In this blog post, we will highlight how ZS Associates used multiple AWS services to build a highly scalable, highly performant, clinical document search platform. This platform is an advanced information retrieval system engineered to assist healthcare professionals and researchers in navigating vast repositories of medical documents, medical literature, research articles, clinical guidelines, protocol documents, activity logs, and more. The goal of this search platform is to locate specific information efficiently and accurately to support clinical decision-making, research, and other healthcare-related activities by combining queries across all the different types of clinical documentation.
ZS is a management consulting and technology firm focused on transforming global healthcare. We use leading-edge analytics, data, and science to help clients make intelligent decisions. We serve clients in a wide range of industries, including pharmaceuticals, healthcare, technology, financial services, and consumer goods. We developed and host several applications for our customers on Amazon Web Services (AWS). ZS is also an AWS Advanced Consulting Partner as well as an Amazon Redshift Service Delivery Partner. As it relates to the use case in the post, ZS is a global leader in integrated evidence and strategy planning (IESP), a set of services that help pharmaceutical companies to deliver a complete and differentiated evidence package for new medicines.
ZS uses several AWS service offerings across the variety of their products, client solutions, and services. AWS services such as Amazon Neptune and Amazon OpenSearch Service form part of their data and analytics pipelines, and AWS Batch is used for long-running data and machine learning (ML) processing tasks.
Clinical data is highly connected in nature, so ZS used Neptune, a fully managed, high performance graph database service built for the cloud, as the database to capture the ontologies and taxonomies associated with the data that formed the supporting a knowledge graph. For our search requirements, We have used OpenSearch Service, an open source, distributed search and analytics suite.
About the clinical document search platform
Clinical documents comprise of a wide variety of digital records including:
Study protocols
Evidence gaps
Clinical activities
Publications
Within global biopharmaceutical companies, there are several key personas who are responsible to generate evidence for new medicines. This evidence supports decisions by payers, health technology assessments (HTAs), physicians, and patients when making treatment decisions. Evidence generation is rife with knowledge management challenges. Over the life of a pharmaceutical asset, hundreds of studies and analyses are completed, and it becomes challenging to maintain a good record of all the evidence to address incoming questions from external healthcare stakeholders such as payers, providers, physicians, and patients. Furthermore, almost none of the information associated with evidence generation activities (such as health economics and outcomes research (HEOR), real-world evidence (RWE), collaboration studies, and investigator sponsored research (ISR)) exists as structured data; instead, the richness of the evidence activities exists in protocol documents (study design) and study reports (outcomes). Therein lies the irony—teams who are in the business of knowledge generation struggle with knowledge management.
ZS unlocked new value from unstructured data for evidence generation leads by applying large language models (LLMs) and generative artificial intelligence (AI) to power advanced semantic search on evidence protocols. Now, evidence generation leads (medical affairs, HEOR, and RWE) can have a natural-language, conversational exchange and return a list of evidence activities with high relevance considering both structured data and the details of the studies from unstructured sources.
Overview of solution
The solution was designed in layers. The document processing layer supports document ingestion and orchestration. The semantic search platform (application) layer supports backend search and the user interface. Multiple different types of data sources, including media, documents, and external taxonomies, were identified as relevant for capture and processing within the semantic search platform.
Document processing solution framework layer
All components and sub-layers are orchestrated using Amazon Managed Workflows for Apache Airflow. The pipeline in Airflow is scaled automatically based on the workload using Batch. We can broadly divide layers here as shown in the following figure:
Document Processing Solution Framework Layers
Data crawling:
In the data crawling layer, documents are retrieved from a specified source SharePoint location and deposited into a designated Amazon Simple Storage Service (Amazon S3) bucket. These documents could be in variety of formats, such as PDF, Microsoft Word, and Excel, and are processed using format-specific adapters.
Data ingestion:
The data ingestion layer is the first step of the proposed framework. At this later, data from a variety of sources smoothly enters the system’s advanced processing setup. In the pipeline, the data ingestion process takes shape through a thoughtfully structured sequence of steps.
These steps include creating a unique run ID each time a pipeline is run, managing natural language processing (NLP) model versions in the versioning table, identifying document formats, and ensuring the health of NLP model services with a service health check.
The process then proceeds with the transfer of data from the input layer to the landing layer, creation of dynamic batches, and continuous tracking of document processing status throughout the run. In case of any issues, a failsafe mechanism halts the process, enabling a smooth transition to the NLP phase of the framework.
Database ingestion:
The reporting layer processes the JSON data from the feature extraction layer and converts it into CSV files. Each CSV file contains specific information extracted from dedicated sections of documents. Subsequently, the pipeline generates a triple file using the data from these CSV files, where each set of entities signifies relationships in a subject-predicate-object format. This triple file is intended for ingestion into Neptune and OpenSearch Service. In the full document embedding module, the document content is segmented into chunks, which are then transformed into embeddings using LLMs such as llama-2 and BGE. These embeddings, along with metadata such as the document ID and page number, are stored in OpenSearch Service. We use various chunking strategies to enhance text comprehension. Semantic chunking divides text into sentences, grouping them into sets, and merges similar ones based on embeddings.
Agentic chunking uses LLMs to determine context-driven chunk sizes, focusing on proposition-based division and simplifying complex sentences. Additionally, context and document aware chunking adapts chunking logic to the nature of the content for more effective processing.
NLP:
The NLP layer serves as a crucial component in extracting specific sections or entities from documents. The feature extraction stage proceeds with localization, where sections are identified within the document to narrow down the search space for further tasks like entity extraction. LLMs are used to summarize the text extracted from document sections, enhancing the efficiency of this process. Following localization, the feature extraction step involves extracting features from the identified sections using various procedures. These procedures, prioritized based on their relevance, use models like Llama-2-7b, mistral-7b, Flan-t5-xl, and Flan-T5-xxl to extract important features and entities from the document text.
The auto-mapping phase ensures consistency by mapping extracted features to standard terms present in the ontology. This is achieved through matching the embeddings of extracted features with those stored in the OpenSearch Service index. Finally, in the Document Layout Cohesion step, the output from the auto-mapping phase is adjusted to aggregate entities at the document level, providing a cohesive representation of the document’s content.
Semantic search platform application layer
This layer, shown in the following figure, uses Neptune as the graph database and OpenSearch Service as the vector engine.
Semantic search platform application layer
Amazon OpenSearch Service:
OpenSearch Service served the dual purpose of facilitating full-text search and embedding-based semantic search. The OpenSearch Service vector engine capability helped to drive Retrieval-Augmented Generation (RAG) workflows using LLMs. This helped to provide a summarized output for search after the retrieval of a relevant document for the input query. The method used for indexing embeddings was FAISS.
OpenSearch Service domain details:
Version of OpenSearch Service: 2.9
Number of nodes: 1
Instance type: r6g.2xlarge.search
Volume size: Gp3: 500gb
Number of Availability Zones: 1
Dedicated master node: Enabled
Number of Availability Zones: 3
No of master Nodes: 3
Instance type(Master Node) : r6g.large.search
To determine the nearest neighbor, we employ the Hierarchical Navigable Small World (HNSW) algorithm. We used the FAISS approximate k-NN library for indexing and searching and the Euclidean distance (L2 norm) for distance calculation between two vectors.
Amazon Neptune:
Neptune enables full-text search (FTS) through the integration with OpenSearch Service. A native streaming service for enabling FTS provided by AWS was established to replicate data from Neptune to OpenSearch Service. Based on the business use case for search, a graph model was defined. Considering the graph model, subject matter experts from the ZS domain team curated custom taxonomy capturing hierarchical flow of classes and sub-classes pertaining to clinical data. Open source taxonomies and ontologies were also identified, which would be part of the knowledge graph. Sections and entities were identified to be extracted from clinical documents. An unstructured document processing pipeline developed by ZS processed the documents in parallel and populated triples in RDF format from documents for Neptune ingestion.
The triples are created in such a way that semantically similar concepts are linked—hence creating a semantic layer for search. After the triples files are created, they’re stored in an S3 bucket. Using the Neptune Bulk Loader, we were able to load millions of triples to the graph.
Neptune ingests both structured and unstructured data, simplifying the process to retrieve content across different sources and formats. At this point, we were able to discover previously unknown relationships between the structured and unstructured data, which was then made available to the search platform. We used SPARQL query federation to return results from the enriched knowledge graph in the Neptune graph database and integrated with OpenSearch Service.
Neptune was able to automatically scale storage and compute resources to accommodate growing datasets and concurrent API calls. Presently, the application sustains approximately 3,000 daily active users. Concurrently, there is an observation of approximately 30–50 users initiating queries simultaneously within the application environment. The Neptune graph accommodates a substantial repository of approximately 4.87 million triples. The triples count is increasing because of our daily and weekly ingestion pipeline routines.
Neptune configuration:
Instance Class: db.r5d.4xlarge
Engine version: 1.2.0.1
LLMs:
Large language models (LLMs) like Llama-2, Mistral and Zephyr are used for extraction of sections and entities. Models like Flan-t5 were also used for extraction of other similar entities used in the procedures. These selected segments and entities are crucial for domain-specific searches and therefore receive higher priority in the learning-to-rank algorithm used for search.
Additionally, LLMs are used to generate a comprehensive summary of the top search results.
The LLMs are hosted on Amazon Elastic Kubernetes Service (Amazon EKS) with GPU-enabled node groups to ensure rapid inference processing. We’re using different models for different use cases. For example, to generate embeddings we deployed a BGE base model, while Mistral, Llama2, Zephyr, and others are used to extract specific medical entities, perform part extraction, and summarize search results. By using different LLMs for distinct tasks, we aim to enhance accuracy within narrow domains, thereby improving the overall relevance of the system.
Fine tuning :
Already fine-tuned models on pharma-specific documents were used. The models used were:
PharMolix/BioMedGPT-LM-7B (finetuned LLAMA-2 on medical)
emilyalsentzer/Bio_ClinicalBERT
stanford-crfm/BioMedLM
microsoft/biogpt
Re ranker, sorter, and filter stage:
Remove any stop words and special characters from the user input query to ensure a clean query. Upon pre-processing the query, create combinations of search terms by forming combinations of terms with varying n-grams. This step enriches the search scope and improves the chances of finding relevant results. For instance, if the input query is “machine learning algorithms,” generating n-grams could result in terms like “machine learning,” “learning algorithms,” and “machine learning algorithms”. Run the search terms simultaneously using the search API to access both Neptune graph and OpenSearch Service indexes. This hybrid approach broadens the search coverage, tapping into the strengths of both data sources. Specific weight is assigned to each result obtained from the data sources based on the domain’s specifications. This weight reflects the relevance and significance of the result within the context of the search query and the underlying domain. For example, a result from Neptune graph might be weighted higher if the query pertains to graph-related concepts, i.e. the search term is related directly to the subject or object of a triple, whereas a result from OpenSearch Service might be given more weightage if it aligns closely with text-based information. Documents that appear in both Neptune graph and OpenSearch Service receive the highest priority, because they likely offer comprehensive insights. Next in priority are documents exclusively sourced from the Neptune graph, followed by those solely from OpenSearch Service. This hierarchical arrangement ensures that the most relevant and comprehensive results are presented first. After factoring in these considerations, a final score is calculated for each result. Sorting the results based on their final scores ensures that the most relevant information is presented in the top n results.
Final UI
An evidence catalogue is aggregated from disparate systems. It provides a comprehensive repository of completed, ongoing and planned evidence generation activities. As evidence leads make forward-looking plans, the existing internal base of evidence is made readily available to inform decision-making.
The following video is a demonstration of an evidence catalog:
Customer impact
When completed, the solution provided the following customer benefits:
The search on multiple data source (structured and unstructured documents) enables visibility of complex hidden relationships and insights.
Clinical documents often contain a mix of structured and unstructured data. Neptune can store structured information in a graph format, while the vector database can handle unstructured data using embeddings. This integration provides a comprehensive approach to querying and analyzing diverse clinical information.
By building a knowledge graph using Neptune, you can enrich the clinical data with additional contextual information. This can include relationships between diseases, treatments, medications, and patient records, providing a more holistic view of healthcare data.
The search application helped in staying informed about the latest research, clinical developments, and competitive landscape.
This has enabled customers to make timely decisions, identify market trends, and help positioning of products based on a comprehensive understanding of the industry.
The application helped in monitoring adverse events, tracking safety signals, and ensuring that drug-related information is easily accessible and understandable, thereby supporting pharmacovigilance efforts.
The search application is currently running in production with 3000 active users.
Customer success criteria
The following success criteria were use to evaluate the solution:
Quick, high accuracy search results: The top three search results were 99% accurate with an overall latency of less than 3 seconds for users.
Identified, extracted portions of the protocol: The sections identified has a precision of 0.98 and recall of 0.87.
Accurate and relevant search results based on simple human language that answer the user’s question.
Clear UI and transparency on which portions of the aligned documents (protocol, clinical study reports, and publications) matched the text extraction.
Knowing what evidence is completed or in-process reduces redundancy in newly proposed evidence activities.
Challenges faced and learnings
We faced two main challenges in developing and deploying this solution.
Large data volume
The unstructured documents were required to be embedded completely and OpenSearch Service helped us achieve this with the right configuration. This involved deploying OpenSearch Service with master nodes and allocating sufficient storage capacity for embedding and storing unstructured document embeddings entirely. We stored up to 100 GB of embeddings in OpenSearch Service.
Inference time reduction
In the search application, it was vital that the search results were retrieved with lowest possible latency. With the hybrid graph and embedding search, this was challenging.
We addressed high latency issues by using an interconnected framework of graphs and embeddings. Each search method complemented the other, leading to optimal results. Our streamlined search approach ensures efficient queries of both the graph and the embeddings, eliminating any inefficiencies. The graph model was designed to minimize the number of hops required to navigate from one entity to another, and we improved its performance by avoiding the storage of bulky metadata. Any metadata too large for the graph was stored in OpenSearch, which served as our metadata store for graph and vector store for embeddings. Embeddings were generated using context-aware chunking of content to reduce the total embedding count and retrieval time, resulting in efficient querying with minimal inference time.
The Horizontal Pod Autoscaler (HPA) provided by Amazon EKS, intelligently adjusts pod resources based on user-demand or query loads, optimizing resource utilization and maintaining application performance during peak usage periods.
Conclusion
In this post, we described how to build an advanced information retrieval system designed to assist healthcare professionals and researchers in navigating through a diverse range of medical documents, including study protocols, evidence gaps, clinical activities, and publications. By using Amazon OpenSearch Service as a distributed search and vector database and Amazon Neptune as a knowledge graph, ZS was able to remove the undifferentiated heavy lifting associated with building and maintaining such a complex platform.
If you’re facing similar challenges in managing and searching through vast repositories of medical data, consider exploring the powerful capabilities of OpenSearch Service and Neptune. These services can help you unlock new insights and enhance your organization’s knowledge management capabilities.
About the authors
Abhishek Pan is a Sr. Specialist SA-Data working with AWS India Public sector customers. He engages with customers to define data-driven strategy, provide deep dive sessions on analytics use cases, and design scalable and performant analytical applications. He has 12 years of experience and is passionate about databases, analytics, and AI/ML. He is an avid traveler and tries to capture the world through his lens.
Gourang Harhare is a Senior Solutions Architect at AWS based in Pune, India. With a robust background in large-scale design and implementation of enterprise systems, application modernization, and cloud native architectures, he specializes in AI/ML, serverless, and container technologies. He enjoys solving complex problems and helping customer be successful on AWS. In his free time, he likes to play table tennis, enjoy trekking, or read books
Kevin Phillips is a Neptune Specialist Solutions Architect working in the UK. He has 20 years of development and solutions architectural experience, which he uses to help support and guide customers. He has been enthusiastic about evangelizing graph databases since joining the Amazon Neptune team, and is happy to talk graph with anyone who will listen.
Sandeep Varma is a principal in ZS’s Pune, India, office with over 25 years of technology consulting experience, which includes architecting and delivering innovative solutions for complex business problems leveraging AI and technology. Sandeep has been critical in driving various large-scale programs at ZS Associates. He was the founding member the Big Data Analytics Centre of Excellence in ZS and currently leads the Enterprise Service Center of Excellence. Sandeep is a thought leader and has served as chief architect of multiple large-scale enterprise big data platforms. He specializes in rapidly building high-performance teams focused on cutting-edge technologies and high-quality delivery.
Alex Turok has over 16 years of consulting experience focused on global and US biopharmaceutical companies. Alex’s expertise is in solving ambiguous, unstructured problems for commercial and medical leadership. For his clients, he seeks to drive lasting organizational change by defining the problem, identifying the strategic options, informing a decision, and outlining the transformation journey. He has worked extensively in portfolio and brand strategy, pipeline and launch strategy, integrated evidence strategy and planning, organizational design, and customer capabilities. Since joining ZS, Alex has worked across marketing, sales, medical, access, and patient services and has touched over twenty therapeutic categories, with depth in oncology, hematology, immunology and specialty therapeutics.
This post is co-written with Hemant Aggarwal and Naveen Kambhoji from Kaplan.
Kaplan, Inc. provides individuals, educational institutions, and businesses with a broad array of services, supporting our students and partners to meet their diverse and evolving needs throughout their educational and professional journeys. Our Kaplan culture empowers people to achieve their goals. Committed to fostering a learning culture, Kaplan is changing the face of education.
Kaplan data engineers empower data analytics using Amazon Redshift and Tableau. The infrastructure provides an analytics experience to hundreds of in-house analysts, data scientists, and student-facing frontend specialists. The data engineering team is on a mission to modernize its data integration platform to be agile, adaptive, and straightforward to use. To achieve this, they chose the AWS Cloud and its services. There are various types of pipelines that need to be migrated from the existing integration platform to the AWS Cloud, and the pipelines have different types of sources like Oracle, Microsoft SQL Server, MongoDB, Amazon DocumentDB (with MongoDB compatibility), APIs, software as a service (SaaS) applications, and Google Sheets. In terms of scale, at the time of writing over 250 objects are being pulled from three different Salesforce instances.
In this post, we discuss how the Kaplan data engineering team implemented data integration from the Salesforce application to Amazon Redshift. The solution uses Amazon Simple Storage Service as a data lake, Amazon Redshift as a data warehouse, Amazon Managed Workflows for Apache Airflow (Amazon MWAA) as an orchestrator, and Tableau as the presentation layer.
Solution overview
The high-level data flow starts with the source data stored in Amazon S3 and then integrated into Amazon Redshift using various AWS services. The following diagram illustrates this architecture.
Amazon MWAA is our main tool for data pipeline orchestration and is integrated with other tools for data migration. While searching for a tool to migrate data from a SaaS application like Salesforce to Amazon Redshift, we came across Amazon AppFlow. After some research, we found Amazon AppFlow to be well-suited for our requirement to pull data from Salesforce. Amazon AppFlow provides the ability to directly migrate data from Salesforce to Amazon Redshift. However, in our architecture, we chose to separate the data ingestion and storage processes for the following reasons:
We needed to store data in Amazon S3 (data lake) as an archive and a centralized location for our data infrastructure.
From a future perspective, there might be scenarios where we need to transform the data before storing it in Amazon Redshift. By storing the data in Amazon S3 as an intermediate step, we can integrate transformation logic as a separate module without impacting the overall data flow significantly.
Apache Airflow is the central point in our data infrastructure, and other pipelines are being built using various tools like AWS Glue. Amazon AppFlow is one part of our overall infrastructure, and we wanted to maintain a consistent approach across different data sources and targets.
To accommodate these requirements, we divided the pipeline into two parts:
Migrate data from Salesforce to Amazon S3 using Amazon AppFlow
Load data from Amazon S3 to Amazon Redshift using Amazon MWAA
This approach allows us to take advantage of the strengths of each service while maintaining flexibility and scalability in our data infrastructure. Amazon AppFlow can handle the first part of the pipeline without the need for any other tool, because Amazon AppFlow provides functionalities like creating a connection to source and target, scheduling the data flow, and creating filters, and we can choose the type of flow (incremental and full load). With this, we were able to migrate the data from Salesforce to an S3 bucket. Afterwards, we created a DAG in Amazon MWAA that runs an Amazon Redshift COPY command on the data stored in Amazon S3 and moves the data into Amazon Redshift.
We faced the following challenges with this approach:
To do incremental data, we have to manually change the filter dates in the Amazon AppFlow flows, which isn’t elegant. We wanted to automate that date filter change.
Both parts of the pipeline were not in sync because there was no way to know if the first part of the pipeline was complete so that the second part of the pipeline could start. We wanted to automate these steps as well.
Implementing the solution
To automate and resolve the aforementioned challenges, we used Amazon MWAA. We created a DAG that acts as the control center for Amazon AppFlow. We developed an Airflow operator that can perform various Amazon AppFlow functions using Amazon AppFlow APIs like creating, updating, deleting, and starting flows, and this operator is used in the DAG. Amazon AppFlow stores the connection data in an AWS Secrets Managermanaged secret with the prefix appflow. The cost of storing the secret is included with the charge for Amazon AppFlow. With this, we were able to run the complete data flow using a single DAG.
The complete data flow consists of the following steps:
Create the flow in the Amazon AppFlow using a DAG.
Update the flow with the new filter dates using the DAG.
After updating the flow, the DAG starts the flow.
The DAG waits for the flow complete by checking the flow’s status repeatedly.
A success status indicates that the data has been migrated from Salesforce to Amazon S3.
After the data flow is complete, the DAG calls the COPY command to copy data from Amazon S3 to Amazon Redshift.
This approach helped us resolve the aforementioned issues, and the data pipelines have become more robust, simple to understand, straightforward to use with no manual intervention, and less prone to error because we are controlling everything from a single point (Amazon MWAA). Amazon AppFlow, Amazon S3, and Amazon Redshift are all configured to use encryption to protect the data. We also performed logging and monitoring, and implemented auditing mechanisms to track the data flow and access using AWS CloudTrail and Amazon CloudWatch. The following figure shows a high-level diagram of the final approach we took.
Conclusion
In this post, we shared how Kaplan’s data engineering team successfully implemented a robust and automated data integration pipeline from Salesforce to Amazon Redshift, using AWS services like Amazon AppFlow, Amazon S3, Amazon Redshift, and Amazon MWAA. By creating a custom Airflow operator to control Amazon AppFlow functionalities, we orchestrated the entire data flow seamlessly within a single DAG. This approach has not only resolved the challenges of incremental data loading and synchronization between different pipeline stages, but has also made the data pipelines more resilient, straightforward to maintain, and less error-prone. We reduced the time for creating a pipeline for a new object from an existing instance and a new pipeline for a new source by 50%. This also helped remove the complexity of using a delta column to get the incremental data, which also helped reduce the cost per table by 80–90% compared to a full load of objects every time.
With this modern data integration platform in place, Kaplan is well-positioned to provide its analysts, data scientists, and student-facing teams with timely and reliable data, empowering them to drive informed decisions and foster a culture of learning and growth.
Try out Airflow with Amazon MWAA and other enhancements to improve your data orchestration pipelines.
Hemant Aggarwal is a senior Data Engineer at Kaplan India Pvt Ltd, helping in developing and managing ETL pipelines leveraging AWS and process/strategy development for the team.
Naveen Kambhoji is a Senior Manager at Kaplan Inc. He works with Data Engineers at Kaplan for building data lakes using AWS Services. He is the facilitator for the entire migration process. His passion is building scalable distributed systems for efficiently managing data on cloud.Outside work, he enjoys travelling with his family and exploring new places.
Jimy Matthews is an AWS Solutions Architect, with expertise in AI/ML tech. Jimy is based out of Boston and works with enterprise customers as they transform their business by adopting the cloud and helps them build efficient and sustainable solutions. He is passionate about his family, cars and Mixed martial arts.
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a managed service for Apache Airflow that allows you to orchestrate data pipelines and workflows at scale. With Amazon MWAA, you can design Directed Acyclic Graphs (DAGs) that describe your workflows without managing the operational burden of scaling the infrastructure. In this post, we provide guidance on how you can optimize performance and save cost by following best practices.
Amazon MWAA environments include four Airflow components hosted on groups of AWS compute resources: the scheduler that schedules the work, the workers that implement the work, the web server that provides the UI, and the metadata database that keeps track of state. For intermittent or varying workloads, optimizing costs while maintaining price and performance is crucial. This post outlines best practices to achieve cost optimization and efficient performance in Amazon MWAA environments, with detailed explanations and examples. It may not be necessary to apply all of these best practices for a given Amazon MWAA workload; you can selectively choose and implement relevant and applicable principles for your specific workloads.
Right-sizing your Amazon MWAA environment
Right-sizing your Amazon MWAA environment makes sure you have an environment that is able to concurrently scale across your different workloads to provide the best price-performance. The environment class you choose for your Amazon MWAA environment determines the size and the number of concurrent tasks supported by the worker nodes. In Amazon MWAA, you can choose from five different environment classes. In this section, we discuss the steps you can follow to right-size your Amazon MWAA environment.
Monitor resource utilization
The first step in right-sizing your Amazon MWAA environment is to monitor the resource utilization of your existing setup. You can monitor the underlying components of your environments using Amazon CloudWatch, which collects raw data and processes data into readable, near real-time metrics. With these environment metrics, you have greater visibility into key performance indicators to help you appropriately size your environments and debug issues with your workflows. Based on the concurrent tasks needed for your workload, you can adjust the environment size as well as the maximum and minimum workers needed. CloudWatch will provide CPU and memory utilization for all the underlying AWS services utilize by Amazon MWAA. Refer to Container, queue, and database metrics for Amazon MWAA for additional details on available metrics for Amazon MWAA. These metrics also include the number of base workers, additional workers, schedulers, and web servers.
Analyze your workload patterns
Next, take a deep dive into your workflow patterns. Examine DAG schedules, task concurrency, and task runtimes. Monitor CPU/memory usage during peak periods. Query CloudWatch metrics and Airflow logs. Identify long-running tasks, bottlenecks, and resource-intensive operations for optimal environment sizing. Understanding the resource demands of your workload will help you make informed decisions about the appropriate Amazon MWAA environment class to use.
Choose the right environment class
Match requirements to Amazon MWAA environment class specifications (mw1.small to mw1.2xlarge) that can handle your workload efficiently. You can vertically scale up or scale down an existing environment through an API, the AWS Command Line Interface (AWS CLI), or the AWS Management Console. Be aware that a change in the environment class requires a scheduled downtime.
Fine tune configuration parameters
Fine-tuning configuration parameters in Apache Airflow is crucial for optimizing workflow performance and cost reductions. It allows you to tune settings such as Auto scaling, parallelism, logging, and DAG code optimizations.
Auto scaling
Amazon MWAA supports worker auto scaling, which automatically adjusts the number of running worker and web server nodes based on your workload demands. You can specify the minimum and maximum number of Airflow workers that run in your environment. For worker node auto scaling, Amazon MWAA uses RunningTasks and QueuedTasks metrics, where (tasks running + tasks queued) / (tasks per worker) = (required workers). If the required number of workers is greater than the current number of running workers, Amazon MWAA will add additional worker instances using AWS Fargate, up to the maximum value specified by the maximum worker configuration.
Auto scaling in Amazon MWAA will gracefully downscale when there are more additional workers than required. For example, let’s assume a large Amazon MWAA environment with a minimum of 1 worker and a maximum of 10, where each large Amazon MWAA worker can support up to 20 tasks. Let’s say, each day at 8:00 AM, DAGs start up that use 190 concurrent tasks. Amazon MWAA will automatically scale to 10 workers, because the required workers = 190 requested tasks (some running, some queued) / 20 (tasks per worker) = 9.5 workers, rounded up to 10. At 10:00 AM, half of the tasks complete, leaving 85 running. Amazon MWAA will then downscale to 6 workers (95 tasks/20 tasks per worker = 5.25 workers, rounded up to 6). Any workers that are still running tasks remain protected during downscaling until they’re complete, and no tasks will be interrupted. As the queued and running tasks decrease, Amazon MWAA will remove workers without affecting running tasks, down to the minimum specified worker count.
Web server auto scaling in Amazon MWAA allows you to automatically scale the number of web servers based on CPU utilization and active connection count. Amazon MWAA makes sure your Airflow environment can seamlessly accommodate increased demand, whether from REST API requests, AWS CLI usage, or more concurrent Airflow UI users. You can specify the maximum and minimum web server count while configuring your Amazon MWAA environment.
Logging and metrics
In this section, we discuss the steps to select and set the appropriate log configurations and CloudWatch metrics.
Choose the right log levels
If enabled, Amazon MWAA will send Airflow logs to CloudWatch. You can view the logs to determine Airflow task delays or workflow errors without the need for additional third-party tools. You need to enable logging to view Airflow DAG processing, tasks, scheduler, web server, and worker logs. You can enable Airflow logs at the INFO, WARNING, ERROR, or CRITICAL level. When you choose a log level, Amazon MWAA sends logs for that level and higher levels of severity. Standard CloudWatch logs charges apply, so reducing log levels where possible can reduce overall costs. Use the most appropriate log level based on environment, such as INFO for dev and UAT, and ERROR for production.
You can choose which Airflow metrics are sent to CloudWatch by using the Amazon MWAA configuration option metrics.statsd_allow_list. Refer to the complete list of available metrics. Some metrics such as schedule_delay and duration_success are published per DAG, whereas others such as ti.finish are published per task per DAG.
Therefore, the cumulative number of DAGs and tasks directly influence your CloudWatch metric ingestion costs. To control CloudWatch costs, choose to publish selective metrics. For example, the following will only publish metrics that start with scheduler and executor:
An effective practice is to utilize regular expression (regex) pattern matching against the entire metric name instead of only matching the prefix at the beginning of the name.
Monitor CloudWatch dashboards and set up alarms
Create a custom dashboard in CloudWatch and add alarms for a particular metric to monitor the health status of your Amazon MWAA environment. Configuring alarms allows you to proactively monitor the health of the environment.
Optimize AWS Secrets Manager invocations
Airflow has a mechanism to store secrets such as variables and connection information. By default, these secrets are stored in the Airflow meta database. Airflow users can optionally configure a centrally managed location for secrets, such as AWS Secrets Manager. When specified, Airflow will first check this alternate secrets backend when a connection or variable is requested. If the alternate backend contains the needed value, it is returned; if not, Airflow will check the meta database for the value and return that instead. One of the factors affecting the cost to use Secrets Manager is the number of API calls made to it.
On the Amazon MWAA console, you can configure the backend Secrets Manager path for the connections and variables that will be used by Airflow. By default, Airflow searches for all connections and variables in the configured backend. To reduce the number of API calls Amazon MWAA makes to Secrets Manager on your behalf, configure it to use a lookup pattern. By specifying a pattern, you narrow the possible paths that Airflow will look at. This will help in lowering your costs when using Secrets Manager with Amazon MWAA.
To use a secrets cache, enable AIRFLOW_SECRETS_USE_CACHE with TTL to help to reduce the Secrets Manager API calls.
For example, if you want to only look up a specific subset of connections, variables, or config in Secrets Manager, set the relevant *_lookup_pattern parameter. This parameter takes a regex as a string as value. To lookup connections starting with m in Secrets Manager, your configuration file should look like the following code:
Schedulers and workers are two components that are involved in parsing the DAG. After the scheduler parses the DAG and places it in a queue, the worker picks up the DAG from the queue. At the point, all the worker knows is the DAG_id and the Python file, along with some other info. The worker has to parse the Python file in order to run the task.
DAG parsing is run twice, once by the scheduler and then by the worker. Because the workers are also parsing the DAG, the amount of time it takes for the code to parse dictates the number of workers needed, which adds cost of running those workers.
For example, for a total of 200 DAGs having 10 tasks each, taking 60 seconds per task to parse, we can calculate the following:
Total tasks across all DAGs = 2,000
Time per task = 60 seconds + 20 seconds (parse DAG)
Total time = 2000 * 80 = 160,000 seconds
Total time per worker = 72,000 seconds
Number of workers needs = Total time/Total time per worker = 160,000/72,000 = ~3
Now, let’s increase the time taken to parse the DAGs to 100 seconds:
Total tasks across all DAGs = 2,000
Time per task = 60 seconds + 100 seconds
Total time = 2,000 *160 = 320,000 seconds
Total time per worker = 72,000 seconds
Number of workers needs = Total time/Total time per worker = 320,000/72,000 = ~5
As you can see, when the DAG parsing time increased from 20 seconds to 100 seconds, the number of worker nodes needed increased from 3 to 5, thereby adding compute cost.
To reduce the time it takes for parsing the code, follow the best practices in the subsequent sections.
Remove top-level imports
Code imports will run every time the DAG is parsed. If you don’t need the libraries being imported to create the DAG objects, move the import to the task level instead of defining it at the top. After it’s defined in the task, the import will be called only when the task is run.
Avoid multiple calls to databases like the meta database or external system database. Variables are used within the DAG that are defined in the meta database or a backend system like Secrets Manager. Use templating (Jinja) wherein calls to populate the variables are only made at task runtime and not at task parsing time.
For example, see the following code:
import pendulum
from airflow import DAG
from airflow.decorators import task
import numpy as np # <-- DON'T DO THAT!
with DAG(
dag_id="example_python_operator",
schedule=None,
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
tags=["example"],
) as dag:
@task()
def print_array():
"""Print Numpy array."""
import numpy as np # <-- INSTEAD DO THIS!
a = np.arange(15).reshape(3, 5)
print(a)
return a
print_array()
The following code is another example:
# Bad example
from airflow.models import Variable
foo_var = Variable.get("foo") # DON'T DO THAT
bash_use_variable_bad_1 = BashOperator(
task_id="bash_use_variable_bad_1", bash_command="echo variable foo=${foo_env}", env={"foo_env": foo_var}
)
bash_use_variable_bad_2 = BashOperator(
task_id="bash_use_variable_bad_2",
bash_command=f"echo variable foo=${Variable.get('foo')}", # DON'T DO THAT
)
bash_use_variable_bad_3 = BashOperator(
task_id="bash_use_variable_bad_3",
bash_command="echo variable foo=${foo_env}",
env={"foo_env": Variable.get("foo")}, # DON'T DO THAT
)
# Good example
bash_use_variable_good = BashOperator(
task_id="bash_use_variable_good",
bash_command="echo variable foo=${foo_env}",
env={"foo_env": "{{ var.value.get('foo') }}"},
)
@task
def my_task():
var = Variable.get("foo") # this is fine, because func my_task called only run task, not scan DAGs.
print(var)
Writing DAGs
Complex DAGs with a large number of tasks and dependencies between them can impact performance of scheduling. One way to keep your Airflow instance performant and well utilized is to simplify and optimize your DAGs.
For example, a DAG that has simple linear structure A → B → C will experience less delays in task scheduling than a DAG that has a deeply nested tree structure with an exponentially growing number of dependent tasks.
Dynamic DAGs
In the following example, a DAG is defined with hardcoded table names from a database. A developer has to define N number of DAGs for N number of tables in a database.
# Bad example
dag_params = getData()
no_of_dags = int(dag_params["no_of_dags"]['N'])
# build a dag for each number in no_of_dags
for n in range(no_of_dags):
dag_id = 'dynperf_t1_{}'.format(str(n))
default_args = {'owner': 'airflow','start_date': datetime(2022, 2, 2, 12, n)}
To reduce verbose and error-prone work, use dynamic DAGs. The following definition of the DAG is created after querying a database catalog, and creates as many DAGs dynamically as there are tables in the database. This achieves the same objective with less code.
Running all DAGs simultaneously or within a short interval in your environment can result in a higher number of worker nodes required to process the tasks, thereby increasing compute costs. For business scenarios where the workload is not time-sensitive, consider spreading the schedule of DAG runs in a way that maximizes the utilization of available worker resources.
DAG folder parsing
Simpler DAGs are usually only in a single Python file; more complex DAGs might be spread across multiple files and have dependencies that should be shipped with them. You can either do this all inside of the DAG_FOLDER , with a standard filesystem layout, or you can package the DAG and all of its Python files up as a single .zip file. Airflow will look into all the directories and files in the DAG_FOLDER. Using the .airflowignore file specifies which directories or files Airflow should intentionally ignore. This will increase the efficiency of finding a DAG within a directory, improving parsing times.
Deferrable operators
You can run deferrable operators on Amazon MWAA. Deferrable operators have the ability to suspend themselves and free up the worker slot. No tasks in the worker means fewer required worker resources, which can lower the worker cost.
For example, let’s assume you’re using a large number of sensors that wait for something to occur and occupy worker node slots. By making the sensors deferrable and using worker auto scaling improvements to aggressively downscale workers, you will immediately see an impact where fewer worker nodes are needed, saving on worker node costs.
Dynamic Task Mapping
Dynamic Task Mapping allows a way for a workflow to create a number of tasks at runtime based on current data, rather than the DAG author having to know in advance how many tasks would be needed. This is similar to defining your tasks in a for loop, but instead of having the DAG file fetch the data and do that itself, the scheduler can do this based on the output of a previous task. Right before a mapped task is run, the scheduler will create N copies of the task, one for each input.
Stop and start the environment
You can stop and start your Amazon MWAA environment based on your workload requirements, which will result in cost savings. You can perform the action manually or automate stopping and starting Amazon MWAA environments. Refer to Automating stopping and starting Amazon MWAA environments to reduce cost to learn how to automate the stop and start of your Amazon MWAA environment retaining metadata.
Conclusion
In conclusion, implementing performance optimization best practices for Amazon MWAA can significantly reduce overall costs while maintaining optimal performance and reliability. Key strategies include right-sizing environment classes based on CloudWatch metrics, managing logging and monitoring costs, using lookup patterns with Secrets Manager, optimizing DAG code, and selectively stopping and starting environments based on workload demands. Continuously monitoring and adjusting these settings as workloads evolve can maximize your cost-efficiency.
About the Authors
Sriharsh Adari is a Senior Solutions Architect at AWS, where he helps customers work backward from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise includes technology strategy, data analytics, and data science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla.
Retina Satish is a Solutions Architect at AWS, bringing her expertise in data analytics and generative AI. She collaborates with customers to understand business challenges and architect innovative, data-driven solutions using cutting-edge technologies. She is dedicated to delivering secure, scalable, and cost-effective solutions that drive digital transformation.
Jeetendra Vaidya is a Senior Solutions Architect at AWS, bringing his expertise to the realms of AI/ML, serverless, and data analytics domains. He is passionate about assisting customers in architecting secure, scalable, reliable, and cost-effective solutions.
The collective thoughts of the interwebz
Manage Consent
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.
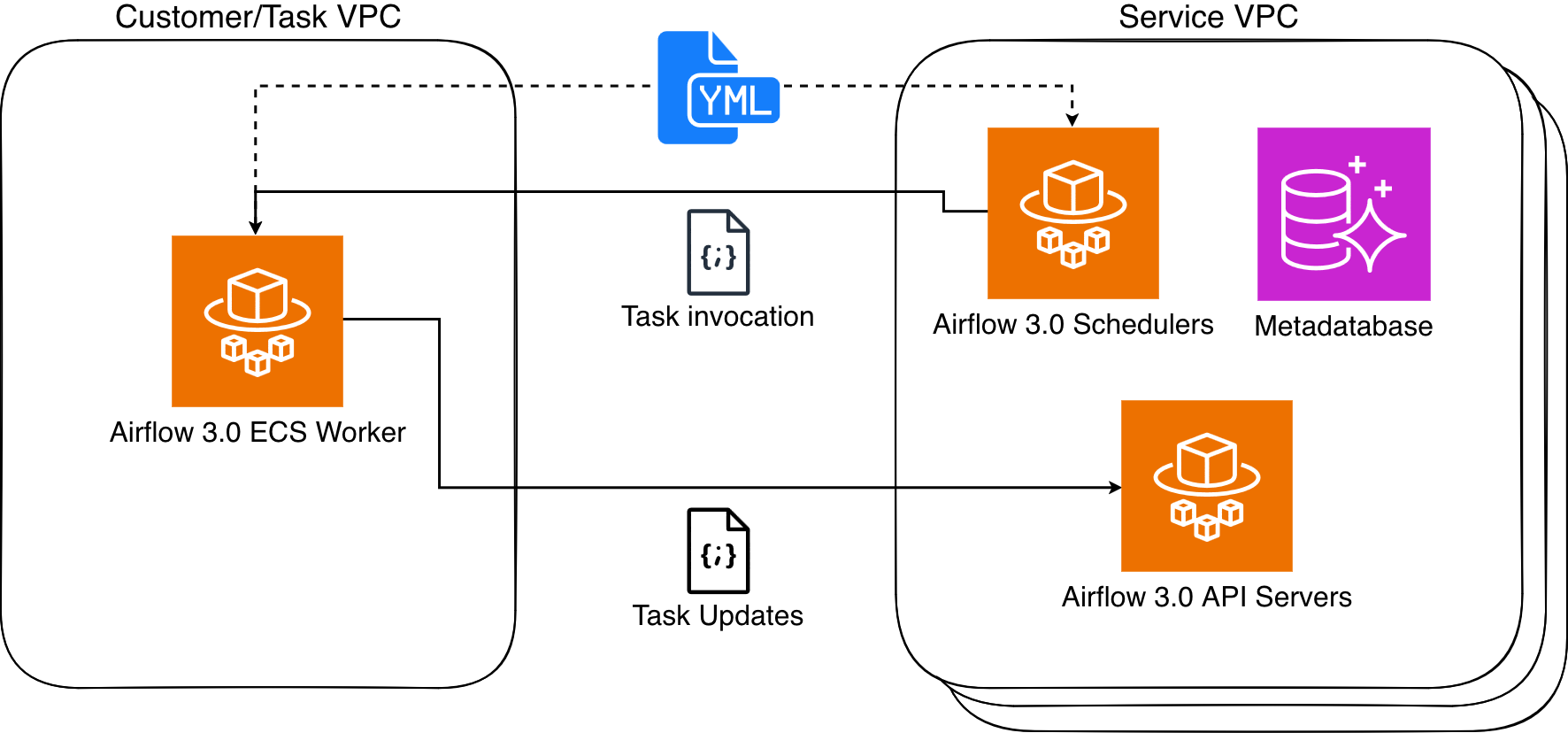
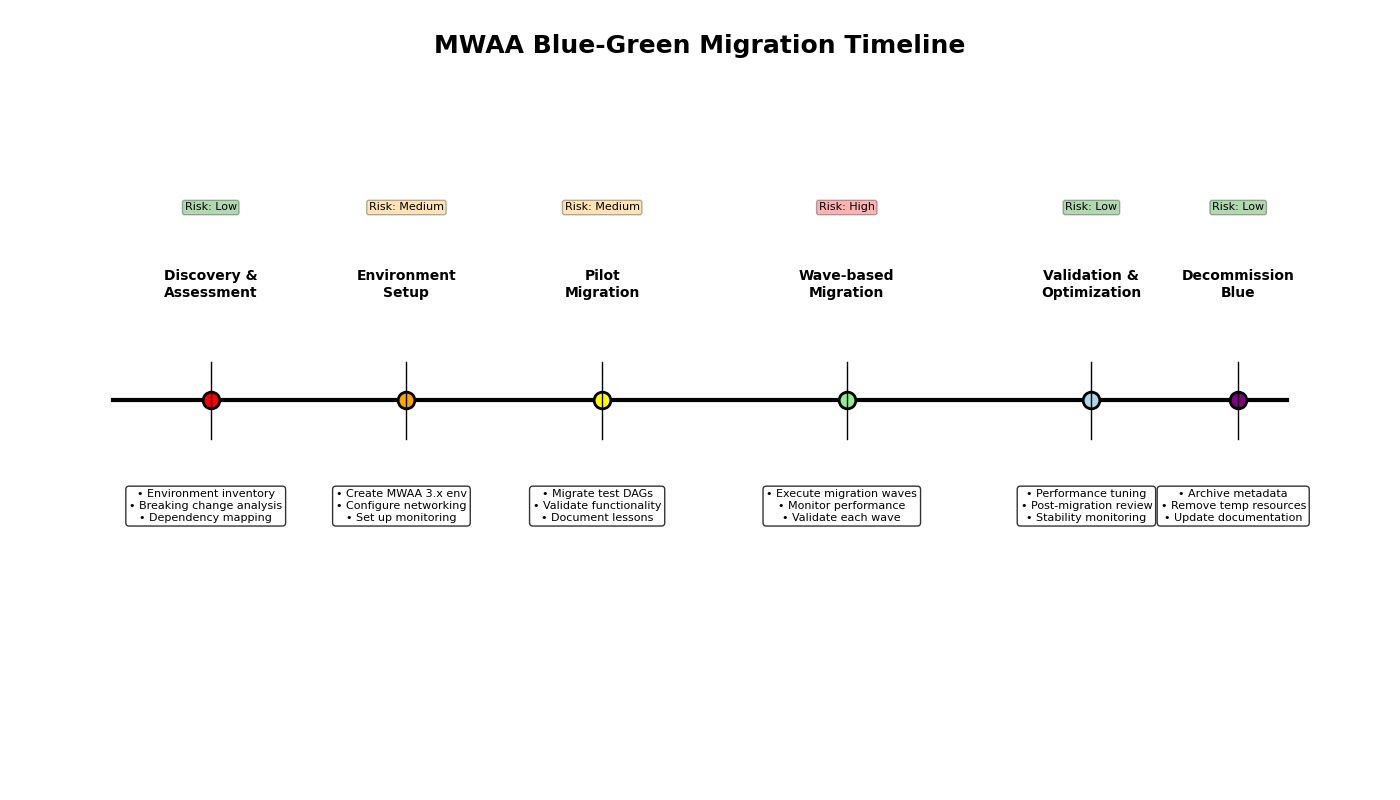
 Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect, Amazon MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on LinkedIn to keep up to date with the latest Amazon MWAA and AWS Glue features and news!
Kamen Sharlandjiev is a Sr. Big Data and ETL Solutions Architect, Amazon MWAA and AWS Glue ETL expert. He’s on a mission to make life easier for customers who are facing complex data integration and orchestration challenges. His secret weapon? Fully managed AWS services that can get the job done with minimal effort. Follow Kamen on LinkedIn to keep up to date with the latest Amazon MWAA and AWS Glue features and news! Ankit Sahu brings over 18 years of expertise in building innovative digital products and services. His diverse experience spans product strategy, go-to-market execution, and digital transformation initiatives. Currently, Ankit serves as Senior Product Manager at Amazon Web Services (AWS), where he leads the Amazon MWAA service.
Ankit Sahu brings over 18 years of expertise in building innovative digital products and services. His diverse experience spans product strategy, go-to-market execution, and digital transformation initiatives. Currently, Ankit serves as Senior Product Manager at Amazon Web Services (AWS), where he leads the Amazon MWAA service. Mohammad Sabeel works as a Senior Cloud Support Engineer at Amazon Web Services (AWS), specializing in AWS Analytics services including AWS Glue, Amazon MWAA, and Amazon Athena. With over 14 years of IT experience, he’s passionate about helping customers build scalable data processing pipelines and optimize their analytics solutions on AWS.
Mohammad Sabeel works as a Senior Cloud Support Engineer at Amazon Web Services (AWS), specializing in AWS Analytics services including AWS Glue, Amazon MWAA, and Amazon Athena. With over 14 years of IT experience, he’s passionate about helping customers build scalable data processing pipelines and optimize their analytics solutions on AWS. Satya Chikkala is a Solutions Architect at Amazon Web Services. Based in Melbourne, Australia, he works closely with enterprise customers to accelerate their cloud journey. Beyond work, he is very passionate about nature and photography.
Satya Chikkala is a Solutions Architect at Amazon Web Services. Based in Melbourne, Australia, he works closely with enterprise customers to accelerate their cloud journey. Beyond work, he is very passionate about nature and photography. Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backward from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data system transformations across industry verticals. His core area of expertise include technology strategy, data analytics, and data science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla.
Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backward from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data system transformations across industry verticals. His core area of expertise include technology strategy, data analytics, and data science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla.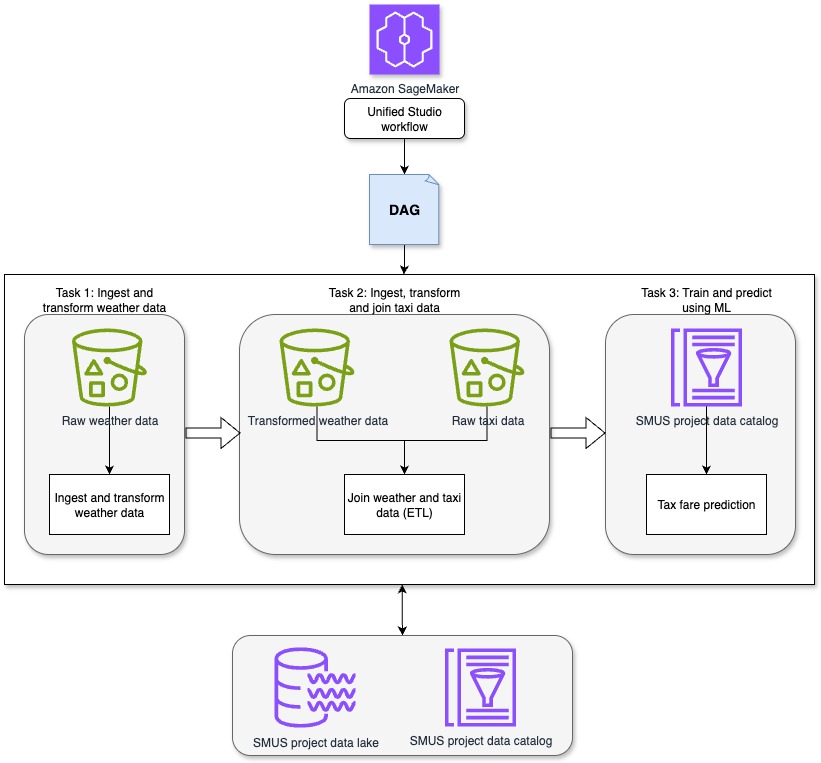
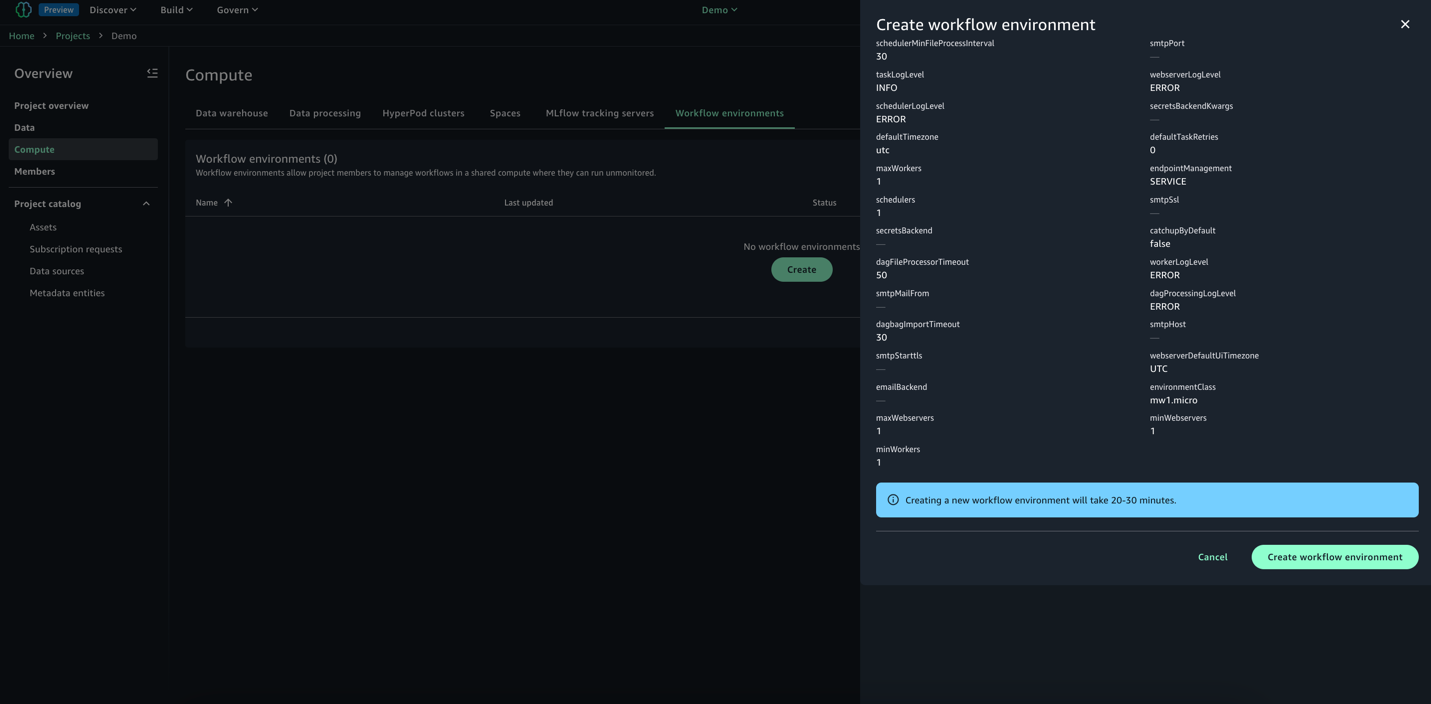
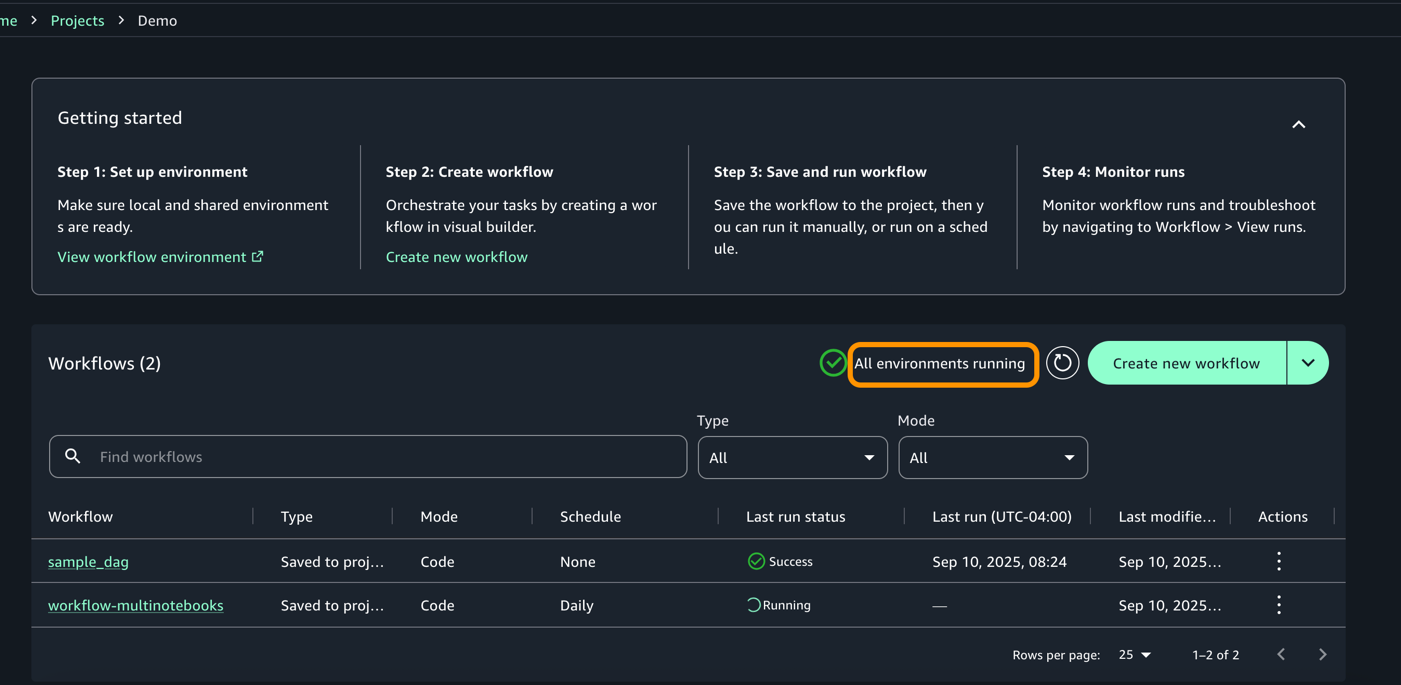
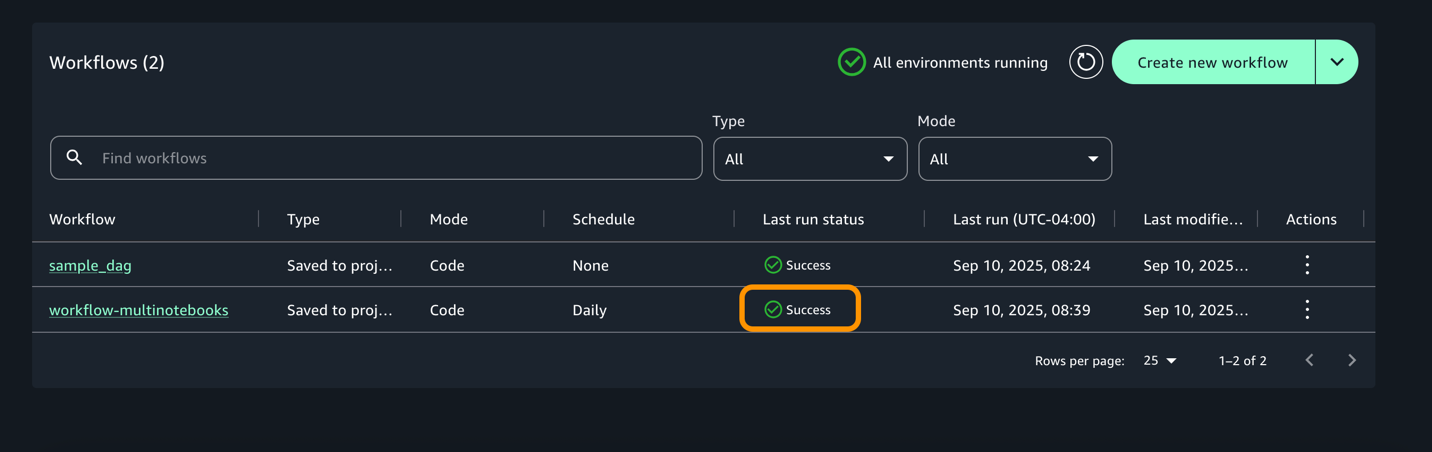
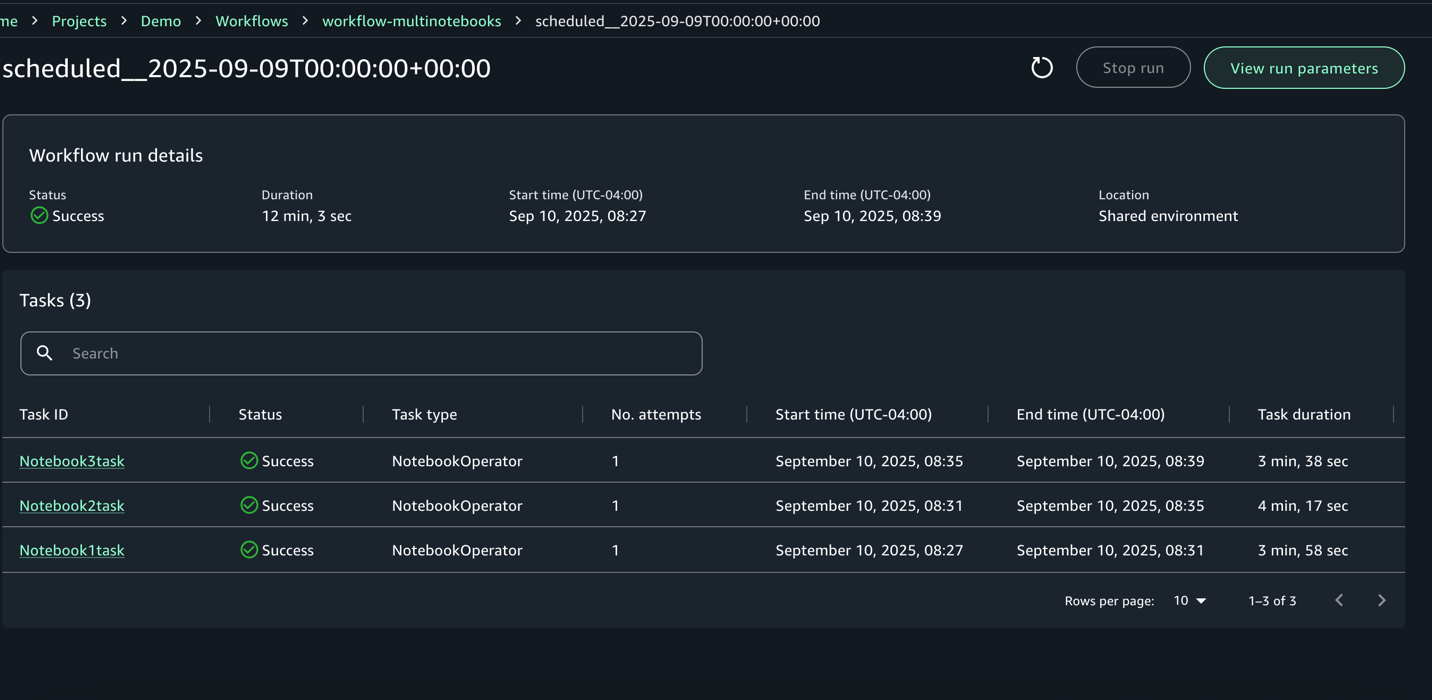
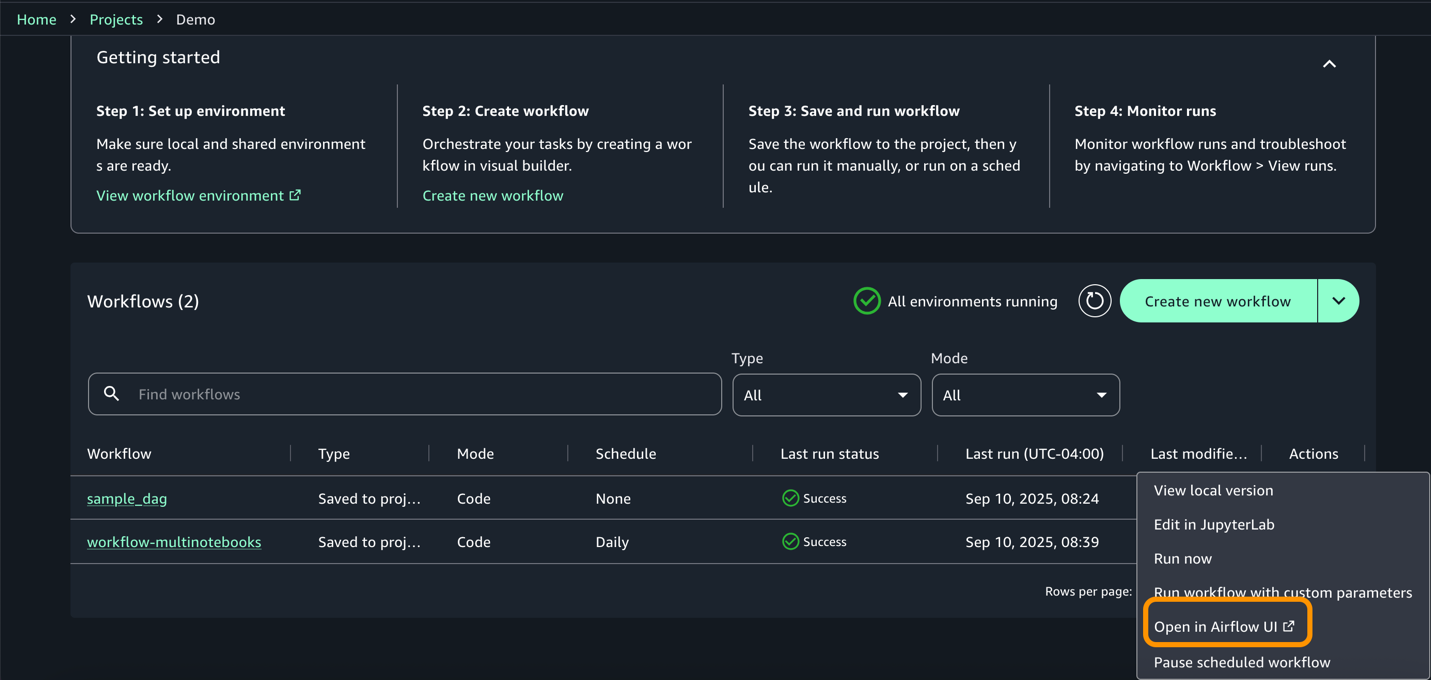
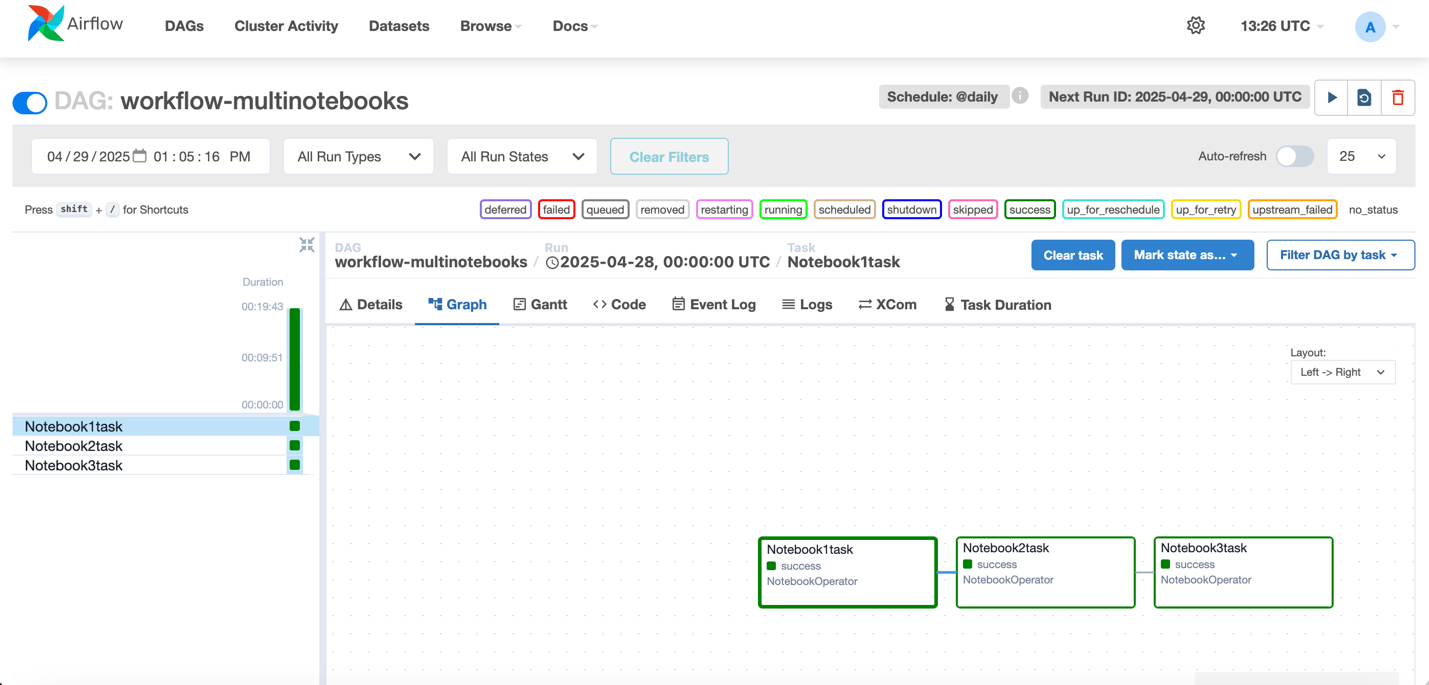
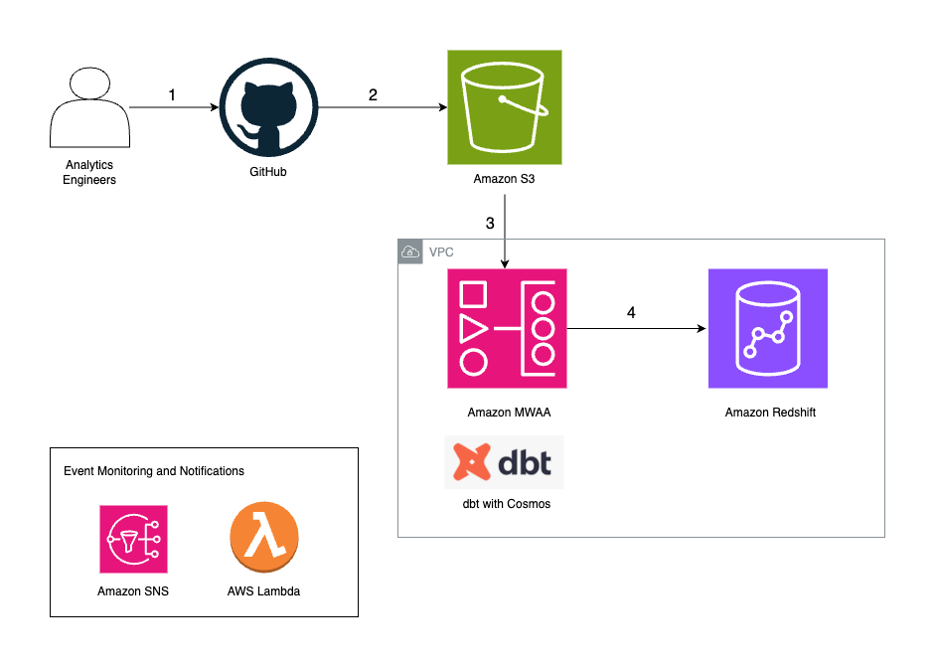
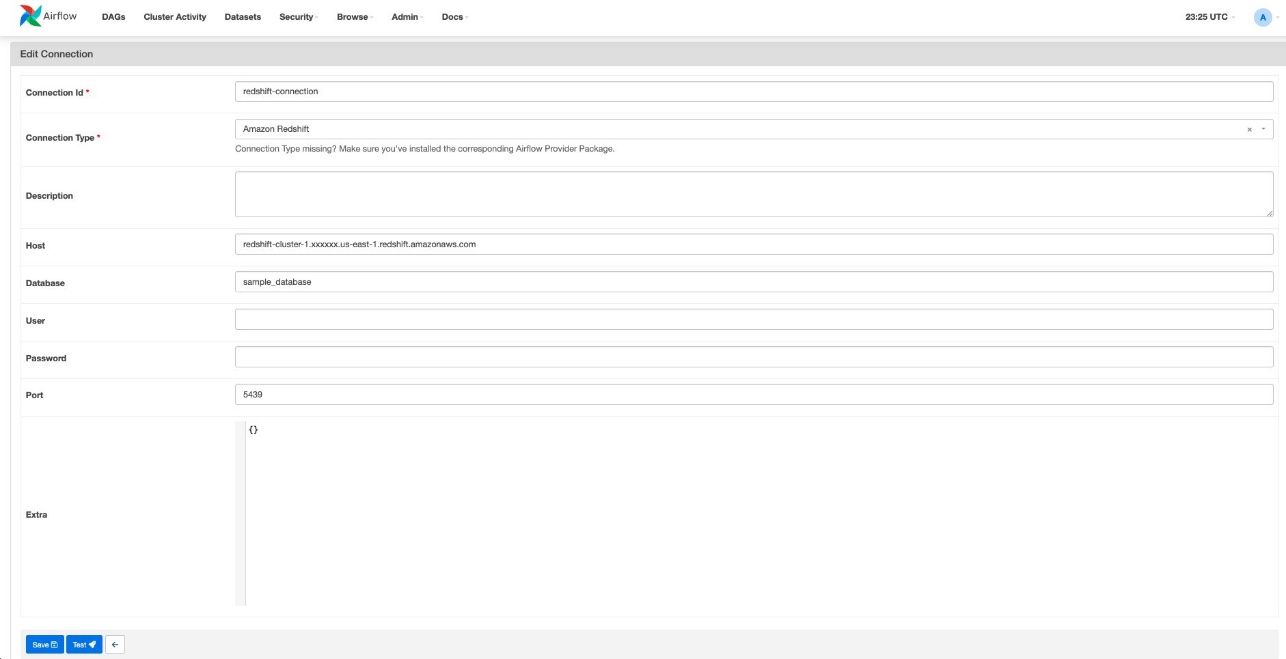
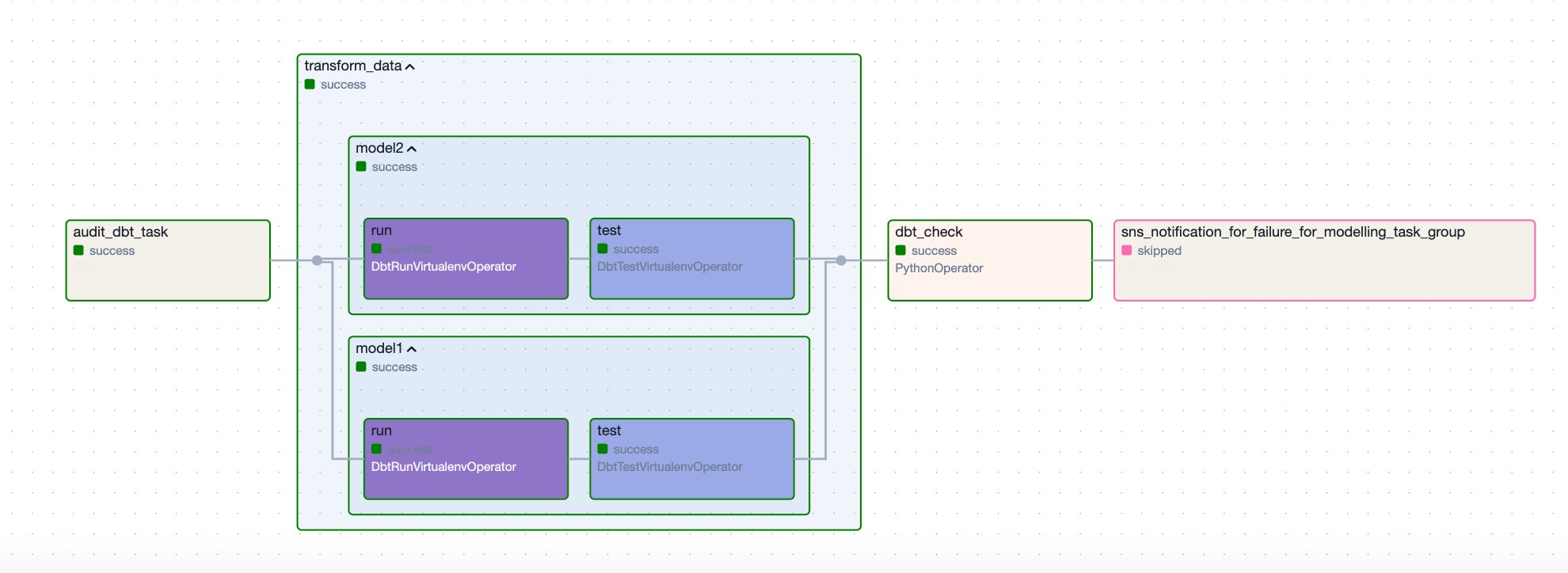






 Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla.
Sriharsh Adari is a Senior Solutions Architect at Amazon Web Services (AWS), where he helps customers work backwards from business outcomes to develop innovative solutions on AWS. Over the years, he has helped multiple customers on data platform transformations across industry verticals. His core area of expertise include Technology Strategy, Data Analytics, and Data Science. In his spare time, he enjoys playing sports, binge-watching TV shows, and playing Tabla. Venu Thangalapally is a Senior Solutions Architect at AWS, based in Chicago, with deep expertise in cloud architecture, data and analytics, containers, and application modernization. He partners with Financial Services industry customers to translate business goals into secure, scalable, and compliant cloud solutions that deliver measurable value. Venu is passionate about leveraging technology to drive innovation and operational excellence. Outside of work, he enjoys spending time with his family, reading, and taking long walks.
Venu Thangalapally is a Senior Solutions Architect at AWS, based in Chicago, with deep expertise in cloud architecture, data and analytics, containers, and application modernization. He partners with Financial Services industry customers to translate business goals into secure, scalable, and compliant cloud solutions that deliver measurable value. Venu is passionate about leveraging technology to drive innovation and operational excellence. Outside of work, he enjoys spending time with his family, reading, and taking long walks. Chandan Rupakheti is a Senior Solutions Architect at AWS. His main focus at AWS lies in the intersection of analytics, serverless, and AdTech services. He is a passionate technical leader, researcher, and mentor with a knack for building innovative solutions in the cloud. Outside of his professional life, he loves spending time with his family and friends, and listening to and playing music.
Chandan Rupakheti is a Senior Solutions Architect at AWS. His main focus at AWS lies in the intersection of analytics, serverless, and AdTech services. He is a passionate technical leader, researcher, and mentor with a knack for building innovative solutions in the cloud. Outside of his professional life, he loves spending time with his family and friends, and listening to and playing music.
 Asena Uyar is a Software Engineer at LaunchDarkly, focusing on building impactful experimentation products that empower teams to make better decisions. With a background in mathematics, industrial engineering, and data science, Asena has been working in the tech industry for over a decade. Her experience spans various sectors, including SaaS and logistics, and she has spent a significant portion of her career as a Data Platform Engineer, designing and managing large-scale data systems. Asena is passionate about using technology to simplify and optimize workflows, making a real difference in the way teams operate.
Asena Uyar is a Software Engineer at LaunchDarkly, focusing on building impactful experimentation products that empower teams to make better decisions. With a background in mathematics, industrial engineering, and data science, Asena has been working in the tech industry for over a decade. Her experience spans various sectors, including SaaS and logistics, and she has spent a significant portion of her career as a Data Platform Engineer, designing and managing large-scale data systems. Asena is passionate about using technology to simplify and optimize workflows, making a real difference in the way teams operate. Dean Verhey is a Data Platform Engineer at LaunchDarkly based in Seattle. He’s worked all across data at LaunchDarkly, ranging from internal batch reporting stacks to streaming pipelines powering product features like experimentation and flag usage charts. Prior to LaunchDarkly, he worked in data engineering for a variety of companies, including procurement SaaS, travel startups, and fire/EMS records management. When he’s not working, you can often find him in the mountains skiing.
Dean Verhey is a Data Platform Engineer at LaunchDarkly based in Seattle. He’s worked all across data at LaunchDarkly, ranging from internal batch reporting stacks to streaming pipelines powering product features like experimentation and flag usage charts. Prior to LaunchDarkly, he worked in data engineering for a variety of companies, including procurement SaaS, travel startups, and fire/EMS records management. When he’s not working, you can often find him in the mountains skiing. Daniel Lopes is a Solutions Architect for ISVs at AWS. His focus is on enabling ISVs to design and build their products in alignment with their business goals with all advantages AWS services can provide them. His areas of interest are event-driven architectures, serverless computing, and generative AI. Outside work, Daniel mentors his kids in video games and pop culture.
Daniel Lopes is a Solutions Architect for ISVs at AWS. His focus is on enabling ISVs to design and build their products in alignment with their business goals with all advantages AWS services can provide them. His areas of interest are event-driven architectures, serverless computing, and generative AI. Outside work, Daniel mentors his kids in video games and pop culture.













 Monica Cujerean is a Principal Data Engineer at Flutter UKI, focusing on service related initiatives that cover performance optimization, cost effectiveness, and new feature adoption on most AWS service in our stack: Amazon MWAA, Amazon Redshift, Amazon Aurora, and Amazon SageMaker.
Monica Cujerean is a Principal Data Engineer at Flutter UKI, focusing on service related initiatives that cover performance optimization, cost effectiveness, and new feature adoption on most AWS service in our stack: Amazon MWAA, Amazon Redshift, Amazon Aurora, and Amazon SageMaker. Ionut Hedesiu is a Senior Data Architect at Flutter UKI, responsible for designing strategic solutions to cover complex and varied business needs. His main expertise is on Amazon MWAA, Kubernetes, Amazon Sagemaker, and ETL solutions.
Ionut Hedesiu is a Senior Data Architect at Flutter UKI, responsible for designing strategic solutions to cover complex and varied business needs. His main expertise is on Amazon MWAA, Kubernetes, Amazon Sagemaker, and ETL solutions. Nidhi Agrawal is a Technical Account Manager at AWS and works with large enterprise customers to provide the technical guidance, best practices, and strategic support to customers, helping them optimize their environments in the AWS Cloud.
Nidhi Agrawal is a Technical Account Manager at AWS and works with large enterprise customers to provide the technical guidance, best practices, and strategic support to customers, helping them optimize their environments in the AWS Cloud. John Kellett is a Senior Customer Solutions Manager with 25 years of experience across private and public sectors. John helps drive end-to-end customer engagement through program management excellence. By understanding and representing customers’ strategic visions, John aligns to develop the people, organizational readiness, and technology competencies to meet the desired outcomes.
John Kellett is a Senior Customer Solutions Manager with 25 years of experience across private and public sectors. John helps drive end-to-end customer engagement through program management excellence. By understanding and representing customers’ strategic visions, John aligns to develop the people, organizational readiness, and technology competencies to meet the desired outcomes. Sidhanth Muralidhar is a Principal Technical Account Manager at AWS. He works with large enterprise customers who run their workloads on AWS. He is passionate about working with customers and helping them architect workloads for cost, reliability, performance, and operational excellence at scale in their cloud journey. He has a keen interest in data analytics as well.
Sidhanth Muralidhar is a Principal Technical Account Manager at AWS. He works with large enterprise customers who run their workloads on AWS. He is passionate about working with customers and helping them architect workloads for cost, reliability, performance, and operational excellence at scale in their cloud journey. He has a keen interest in data analytics as well.













 William Vambenepe is Director of Product Management at AWS, where he leads the Product Management, Solutions Engineering, and UX Design team for data processing services (Amazon EMR, AWS Glue, Athena, Amazon MWAA), SageMaker Unified Studio, and SageMaker Catalog. Prior to AWS, William worked at Google (6 years building and growing the Data and Analytics product portfolio for Google Cloud, and 5 years as Product Management Director for Google Search). He had previously held software engineering leadership roles at Oracle and HP. William holds an Engineering degree from Ecole Centrale Paris, a graduate Diploma in Computer Science from Cambridge University, and a Masters in Engineering Management from Stanford University.
William Vambenepe is Director of Product Management at AWS, where he leads the Product Management, Solutions Engineering, and UX Design team for data processing services (Amazon EMR, AWS Glue, Athena, Amazon MWAA), SageMaker Unified Studio, and SageMaker Catalog. Prior to AWS, William worked at Google (6 years building and growing the Data and Analytics product portfolio for Google Cloud, and 5 years as Product Management Director for Google Search). He had previously held software engineering leadership roles at Oracle and HP. William holds an Engineering degree from Ecole Centrale Paris, a graduate Diploma in Computer Science from Cambridge University, and a Masters in Engineering Management from Stanford University. Santosh Chandrachood has been with AWS for over 8 years and helped build, launch, and scale a variety of AWS services. Currently, Santosh is Director and service leader for Data Processing, managing Amazon EMR, Athena, AWS Glue, and Managed Workflows for Apache Airflow (Amazon MWAA). Santosh also led AWS Data Integration as the General Manager. Before joining AWS, Santosh lead engineering teams in networking, storage, and data infrastructure areas.
Santosh Chandrachood has been with AWS for over 8 years and helped build, launch, and scale a variety of AWS services. Currently, Santosh is Director and service leader for Data Processing, managing Amazon EMR, Athena, AWS Glue, and Managed Workflows for Apache Airflow (Amazon MWAA). Santosh also led AWS Data Integration as the General Manager. Before joining AWS, Santosh lead engineering teams in networking, storage, and data infrastructure areas.





 Deependra Shekhawat is a Senior Energy and Utilities Industry Specialist Solutions Architect based in Sydney, Australia. In his role, Deependra helps Energy companies across APJ region use cloud technologies to drive sustainability and operational efficiency. He specializes in creating robust data foundations and advanced workflows that enable organizations to harness the power of big data, analytics, and machine learning for solving critical industry challenges.
Deependra Shekhawat is a Senior Energy and Utilities Industry Specialist Solutions Architect based in Sydney, Australia. In his role, Deependra helps Energy companies across APJ region use cloud technologies to drive sustainability and operational efficiency. He specializes in creating robust data foundations and advanced workflows that enable organizations to harness the power of big data, analytics, and machine learning for solving critical industry challenges. Senaka Ariyasinghe is a Senior Partner Solutions Architect working with Global Systems Integrators at AWS. In his role, Senaka guides AWS partners in the APJ region to design and scale well-architected solutions, focusing on generative AI, machine learning, cloud migrations, and application modernization initiatives.
Senaka Ariyasinghe is a Senior Partner Solutions Architect working with Global Systems Integrators at AWS. In his role, Senaka guides AWS partners in the APJ region to design and scale well-architected solutions, focusing on generative AI, machine learning, cloud migrations, and application modernization initiatives. Sandeep Kushwaha is a Senior Data Scientist at Wipro and has extensive experience in big data and machine learning. With a strong command of Apache Spark, Sandeep has designed and implemented cutting-edge cloud solutions that optimize data processing and drive efficiency. His expertise in using AWS services and best practices, combined with his deep knowledge of data management and automation, has enabled him to lead successful projects that meet complex technical challenges and deliver high-impact results.
Sandeep Kushwaha is a Senior Data Scientist at Wipro and has extensive experience in big data and machine learning. With a strong command of Apache Spark, Sandeep has designed and implemented cutting-edge cloud solutions that optimize data processing and drive efficiency. His expertise in using AWS services and best practices, combined with his deep knowledge of data management and automation, has enabled him to lead successful projects that meet complex technical challenges and deliver high-impact results.



 Leo Ramsamy is a Platform Architect specializing in data and analytics for ANZ’s Institutional division. He focuses on modern data practices, including Data Mesh architecture, data governance, quality management, and observability. His work aligns data strategies with business goals, improving accessibility and enabling better decision-making across ANZ.
Leo Ramsamy is a Platform Architect specializing in data and analytics for ANZ’s Institutional division. He focuses on modern data practices, including Data Mesh architecture, data governance, quality management, and observability. His work aligns data strategies with business goals, improving accessibility and enabling better decision-making across ANZ. Srinivasan Kuppusamy is a Senior Cloud Architect – Data at AWS ProServe, where he helps customers solve their business problems using the power of AWS Cloud technology. His areas of interests are data and analytics, data governance, and AI/ML.
Srinivasan Kuppusamy is a Senior Cloud Architect – Data at AWS ProServe, where he helps customers solve their business problems using the power of AWS Cloud technology. His areas of interests are data and analytics, data governance, and AI/ML. Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.
Rada Stanic is a Chief Technologist at Amazon Web Services, where she helps ANZ customers across different segments solve their business problems using AWS Cloud technologies. Her special areas of interest are data analytics, machine learning/AI, and application modernization.
 Hernan Garcia is a Senior Solutions Architect at AWS based in the Netherlands. He works in the financial services industry, supporting enterprises in their cloud adoption. He is passionate about serverless technologies, security, and compliance. He enjoys spending time with family and friends, and trying out new dishes from different cuisines.
Hernan Garcia is a Senior Solutions Architect at AWS based in the Netherlands. He works in the financial services industry, supporting enterprises in their cloud adoption. He is passionate about serverless technologies, security, and compliance. He enjoys spending time with family and friends, and trying out new dishes from different cuisines.


 Hernan Garcia is a Senior Solutions Architect at AWS based out of Amsterdam. He has worked in the financial services industry since 2018, specializing in application modernization and supporting customers in their adoption of the cloud with a focus on serverless technologies.
Hernan Garcia is a Senior Solutions Architect at AWS based out of Amsterdam. He has worked in the financial services industry since 2018, specializing in application modernization and supporting customers in their adoption of the cloud with a focus on serverless technologies.



 Tim Wilhoit is a Sr. Solutions Architect for the Department of Defense at AWS. Tim has over 20 years of enterprise IT experience. His areas of interest are serverless computing and ML/AI. In his spare time, Tim enjoys spending time at the lake and rooting on the Oklahoma State Cowboys. Go Pokes!
Tim Wilhoit is a Sr. Solutions Architect for the Department of Defense at AWS. Tim has over 20 years of enterprise IT experience. His areas of interest are serverless computing and ML/AI. In his spare time, Tim enjoys spending time at the lake and rooting on the Oklahoma State Cowboys. Go Pokes!

 Abhishek Pan is a Sr. Specialist SA-Data working with AWS India Public sector customers. He engages with customers to define data-driven strategy, provide deep dive sessions on analytics use cases, and design scalable and performant analytical applications. He has 12 years of experience and is passionate about databases, analytics, and AI/ML. He is an avid traveler and tries to capture the world through his lens.
Abhishek Pan is a Sr. Specialist SA-Data working with AWS India Public sector customers. He engages with customers to define data-driven strategy, provide deep dive sessions on analytics use cases, and design scalable and performant analytical applications. He has 12 years of experience and is passionate about databases, analytics, and AI/ML. He is an avid traveler and tries to capture the world through his lens. Gourang Harhare is a Senior Solutions Architect at AWS based in Pune, India. With a robust background in large-scale design and implementation of enterprise systems, application modernization, and cloud native architectures, he specializes in AI/ML, serverless, and container technologies. He enjoys solving complex problems and helping customer be successful on AWS. In his free time, he likes to play table tennis, enjoy trekking, or read books
Gourang Harhare is a Senior Solutions Architect at AWS based in Pune, India. With a robust background in large-scale design and implementation of enterprise systems, application modernization, and cloud native architectures, he specializes in AI/ML, serverless, and container technologies. He enjoys solving complex problems and helping customer be successful on AWS. In his free time, he likes to play table tennis, enjoy trekking, or read books Kevin Phillips is a Neptune Specialist Solutions Architect working in the UK. He has 20 years of development and solutions architectural experience, which he uses to help support and guide customers. He has been enthusiastic about evangelizing graph databases since joining the Amazon Neptune team, and is happy to talk graph with anyone who will listen.
Kevin Phillips is a Neptune Specialist Solutions Architect working in the UK. He has 20 years of development and solutions architectural experience, which he uses to help support and guide customers. He has been enthusiastic about evangelizing graph databases since joining the Amazon Neptune team, and is happy to talk graph with anyone who will listen. Sandeep Varma is a principal in ZS’s Pune, India, office with over 25 years of technology consulting experience, which includes architecting and delivering innovative solutions for complex business problems leveraging AI and technology. Sandeep has been critical in driving various large-scale programs at ZS Associates. He was the founding member the Big Data Analytics Centre of Excellence in ZS and currently leads the Enterprise Service Center of Excellence. Sandeep is a thought leader and has served as chief architect of multiple large-scale enterprise big data platforms. He specializes in rapidly building high-performance teams focused on cutting-edge technologies and high-quality delivery.
Sandeep Varma is a principal in ZS’s Pune, India, office with over 25 years of technology consulting experience, which includes architecting and delivering innovative solutions for complex business problems leveraging AI and technology. Sandeep has been critical in driving various large-scale programs at ZS Associates. He was the founding member the Big Data Analytics Centre of Excellence in ZS and currently leads the Enterprise Service Center of Excellence. Sandeep is a thought leader and has served as chief architect of multiple large-scale enterprise big data platforms. He specializes in rapidly building high-performance teams focused on cutting-edge technologies and high-quality delivery.


 Hemant Aggarwal is a senior Data Engineer at Kaplan India Pvt Ltd, helping in developing and managing ETL pipelines leveraging AWS and process/strategy development for the team.
Hemant Aggarwal is a senior Data Engineer at Kaplan India Pvt Ltd, helping in developing and managing ETL pipelines leveraging AWS and process/strategy development for the team. Naveen Kambhoji is a Senior Manager at Kaplan Inc. He works with Data Engineers at Kaplan for building data lakes using AWS Services. He is the facilitator for the entire migration process. His passion is building scalable distributed systems for efficiently managing data on cloud.Outside work, he enjoys travelling with his family and exploring new places.
Naveen Kambhoji is a Senior Manager at Kaplan Inc. He works with Data Engineers at Kaplan for building data lakes using AWS Services. He is the facilitator for the entire migration process. His passion is building scalable distributed systems for efficiently managing data on cloud.Outside work, he enjoys travelling with his family and exploring new places. Jimy Matthews is an AWS Solutions Architect, with expertise in AI/ML tech. Jimy is based out of Boston and works with enterprise customers as they transform their business by adopting the cloud and helps them build efficient and sustainable solutions. He is passionate about his family, cars and Mixed martial arts.
Jimy Matthews is an AWS Solutions Architect, with expertise in AI/ML tech. Jimy is based out of Boston and works with enterprise customers as they transform their business by adopting the cloud and helps them build efficient and sustainable solutions. He is passionate about his family, cars and Mixed martial arts.
 Retina Satish is a Solutions Architect at AWS, bringing her expertise in data analytics and generative AI. She collaborates with customers to understand business challenges and architect innovative, data-driven solutions using cutting-edge technologies. She is dedicated to delivering secure, scalable, and cost-effective solutions that drive digital transformation.
Retina Satish is a Solutions Architect at AWS, bringing her expertise in data analytics and generative AI. She collaborates with customers to understand business challenges and architect innovative, data-driven solutions using cutting-edge technologies. She is dedicated to delivering secure, scalable, and cost-effective solutions that drive digital transformation. Jeetendra Vaidya is a Senior Solutions Architect at AWS, bringing his expertise to the realms of AI/ML, serverless, and data analytics domains. He is passionate about assisting customers in architecting secure, scalable, reliable, and cost-effective solutions.
Jeetendra Vaidya is a Senior Solutions Architect at AWS, bringing his expertise to the realms of AI/ML, serverless, and data analytics domains. He is passionate about assisting customers in architecting secure, scalable, reliable, and cost-effective solutions.