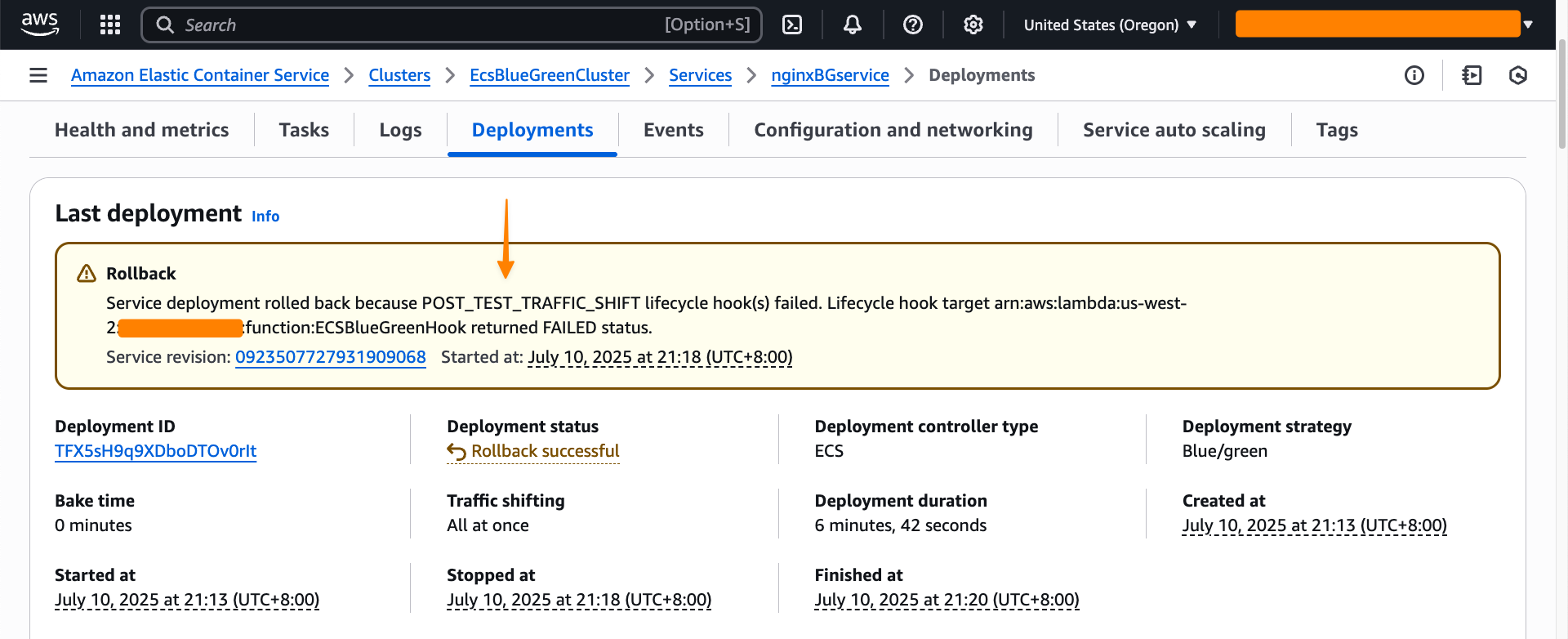
Post Syndicated from aostan original https://aws.amazon.com/blogs/compute/hosting-containers-at-the-edge-using-amazon-ecs-and-aws-outposts-server/
This post is written by Craig Warburton, Hybrid Cloud Senior Solutions Architect and Sedji Gaouaou, Hybrid Cloud Senior Solutions Architect
In today’s fast-paced digital landscape, businesses are increasingly looking to process data and run applications closer to the source, at the edge of the network. For those seeking to use the power of containerized workloads in edge environments, AWS Outposts servers offer a compelling solution. This fully managed service brings the AWS infrastructure, services, APIs, and tools to virtually any on-premises or edge location, allowing users to run container-based applications seamlessly across their distributed environments. In this post, we explore how Outposts servers can empower organizations to deploy and manage containerized workloads at the edge, bringing cloud-native capabilities closer to where they’re needed most.
Solution overview
Amazon Elastic Container Service (Amazon ECS) is a fully managed container orchestration service that can be used with Outposts servers. This combination allows users to run containerized applications at the edge with the same ease and flexibility as in the AWS cloud.
By using Outposts server with Amazon ECS, users can effectively extend their container-based workloads to the edge, enabling new use cases and improving application performance for latency-sensitive operations.
The following diagram illustrates an example architecture where a user is looking to deploy a microservices based PHP web application and instance based MySQL database. Furthermore, a container based load balancer appliance is used to receive and distribute traffic to the web application container. The example application writes its data to a MySQL database, which is hosted on an external storage array. The application is deployed on the Outpost server, and can communicate with the database across the user data center network.
In this post we will show how users can deploy an example microservice based application. Each section of this post walks through Steps 1 through 4 shown in the following diagram.

Figure 1: Solution overview
Walkthrough
Prerequisites
Before deploying the sample application, you must have ordered, received, and successfully installed an Outposts server. The server is operational and visible in the AWS Management Console.
This walkthrough assumes you have access to Amazon Elastic Container Registry (Amazon ECR) that is used for the container repository.
You need the following AWS Identity and Access Management (IAM) role provisioned with the necessary permissions included in the policy to permit the load balancer to read the required Amazon ECS attributes. Refer to the user guide Create a role to delegate permissions to an IAM user section to help you through creating an IAM role and associated policy. The Amazon ECS task IAM role needs the following policy configuration to read the necessary Amazon ECS information:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "LoadBalancerECSReadAccess",
"Effect": "Allow",
"Action": [
"ecs:ListClusters",
"ecs:DescribeClusters",
"ecs:ListTasks",
"ecs:DescribeTasks",
"ecs:DescribeContainerInstances",
"ecs:DescribeTaskDefinition",
"ec2:DescribeInstances",
"ssm:DescribeInstanceInformation"
],
"Resource": [
"*"
]
}
]
}
You also need the Amazon ECS task execution IAM role (ecsTaskExecutionRole) that will grant the Amazon ECS container service the necessary permissions to make AWS API calls on your behalf.
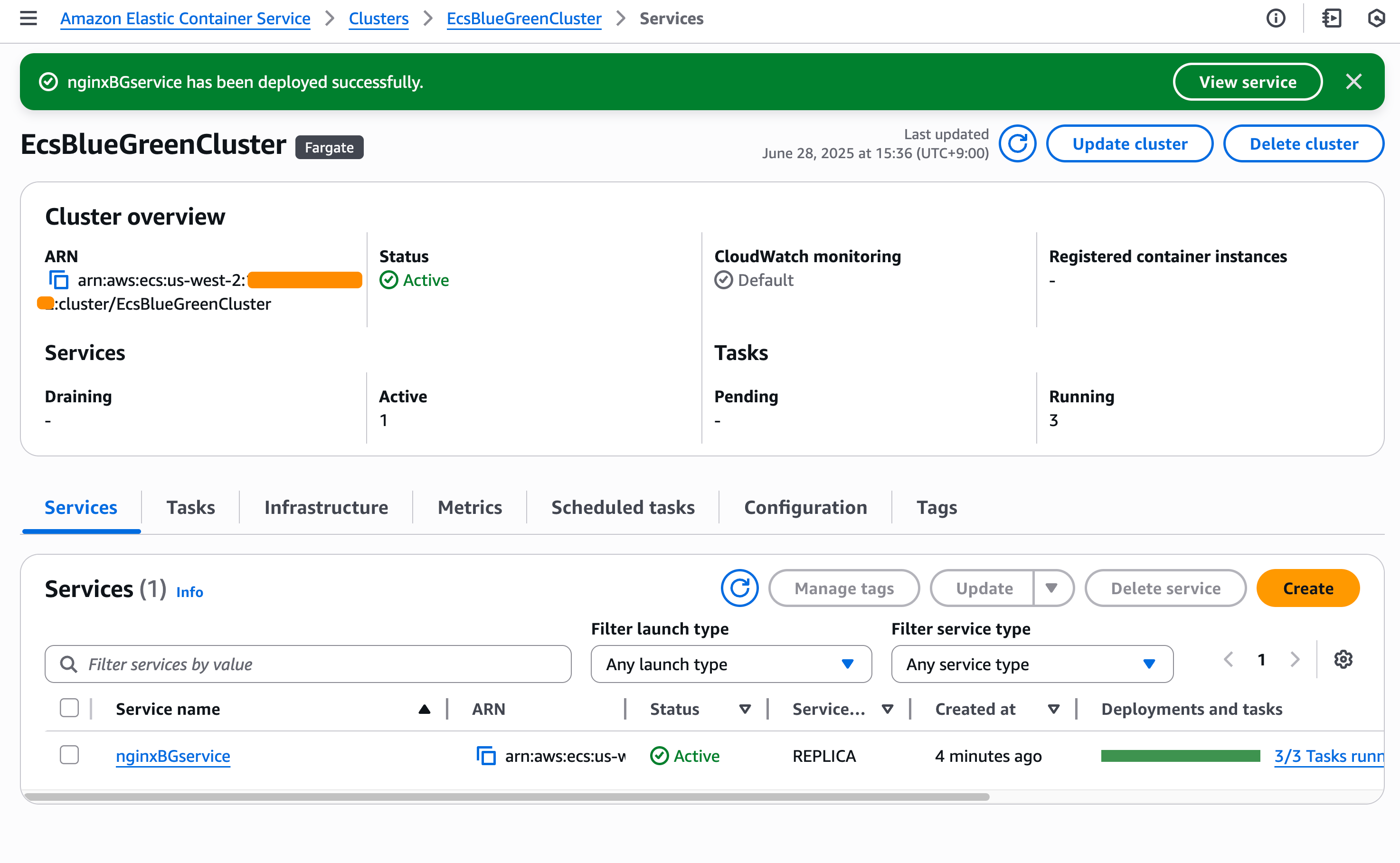
Step 1: Setting up Amazon ECS on Outposts server
Amazon ECS is used in this walkthrough to deploy our container workloads to the Outposts server. Before deploying workloads, an ECS cluster on Outposts needs to be created.
In this configuration, the Amazon ECS cluster targets the private subnets (10.0.1.0/24 and 10.0.2.0/24) and the Amazon Elastic Compute Cloud Amazon (EC2) instances configured on the Outpost server for deployments.
To assist in targeting the deployment of our Amazon ECS services to specific instances with an attached Local Network Interface (LNI), our Amazon EC2 instances are assigned a logical role using custom Amazon ECS container instance attributes. Custom attributes are used to configure task placement constraints, as shown in the following figure.

Figure 2: Amazon ECS container instances used for tasks
One of the container instances is assigned the role of loadbalancer, as shown in the following figure. Follow the developer guide section to Define which container instances Amazon ECS uses for tasks, and add the following custom attribute to one of your instances:
- Name = role, Value = loadbalancer

Figure 3: Instance with the Custom Attibutes – loadbalancer
The other container instance is assigned the role of webserver, as shown in the following figure. Add the following custom attribute to each of the remaining instance:
- Name = role, Value = webserver

Figure 4: Instance with the Custom Attributes – webserver
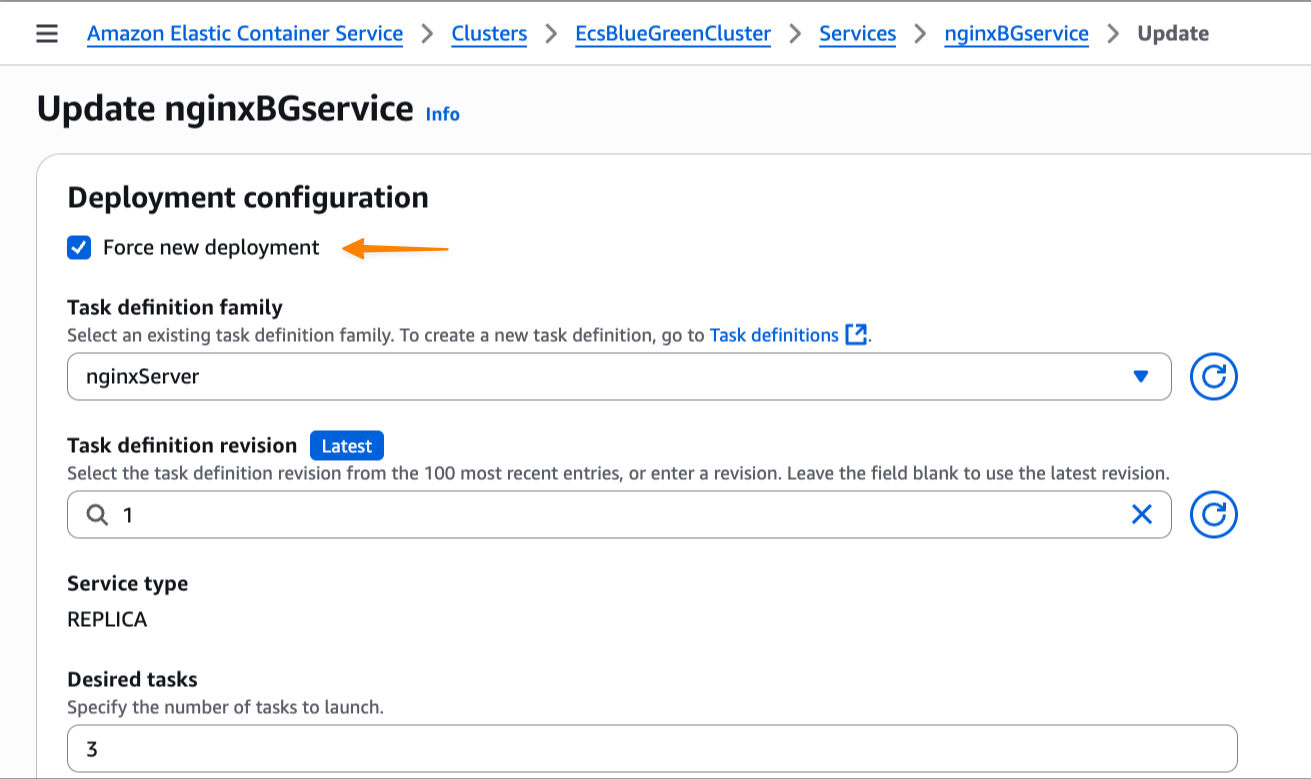
Step 2: Deploying a load balancer with host mode to use LNI
In this section, you deploy a task for the load balancer as seen in Step 2 of the Solution overview.
First, you must enable the private subnet, where your load balancer is deployed, for LNIs:
aws ec2 modify-subnet-attribute \
--subnet-id subnet-1a2b3c4d \
--enable-lni-at-device-index 1
Now add an LNI to the container instance with the attibute “loadbalancer”. This instance can now access your local network.
To deploy the load balancer, create an Amazon ECS task definition named “task-definition-loadbalancer.json”, which describes the container configuration to implement the load balancer as followed:
{
"containerDefinitions": [
{
"name": "loadbalancer",
"image": "traefik:latest",
"cpu": 0,
"portMappings": [
{
"containerPort": 80,
"hostPort": 80,
"protocol": "tcp"
},
{
"containerPort": 8080,
"hostPort": 8080,
"protocol": "tcp"
}
],
"essential": true,
"command": [
"--api.dashboard=true",
"--api.insecure=true",
"--accesslog=true",
"--providers.ecs.ecsAnywhere=false",
"--providers.ecs.region=<AWS_REGION>",
"--providers.ecs.autoDiscoverClusters=true",
"--providers.ecs.clusters=<YOUR_CLUSTER_NAME>",
"--providers.ecs.exposedByDefault=true"
],
"environment": [],
"mountPoints": [],
"volumesFrom": [],
"systemControls": []
}
],
"family": "loadbalancer",
"taskRoleArn": <TASK_ROLE_ARN>,
"executionRoleArn": <EXECUTION_ROLE_ARN>,
"networkMode": "host",
"volumes": [],
"placementConstraints": [
{
"type": "memberOf",
"expression": "attribute:role == loadbalancer"
}
],
"requiresCompatibilities": [
"EC2"
],
"cpu": "256",
"memory": "128",
"tags": []
}
Replace the string <TASK_ROLE_ARN> with the Amazon Resource Name (ARN) of the IAM role configured with the LoadBalancerECSReadAccess policy and the string <EXECUTION_ROLE_ARN> with the ARN of the IAM role configured with the ecsTaskExecutionRole policy as configured in the Prerequisites section, <AWS_REGION> with the AWS Region where you deployed your ECS cluster, <YOUR_CLUSTER_NAME> with your cluster name.
Some points to consider:
- The Amazon ECS Network mode is set to “host”. The load balancer task uses the host’s network to access the LNI.
- The task definition includes the placement constraint matching the loadbalancer custom attribute value.
Lastly, register the task definition with your cluster and create the loadbalancer service using the following AWS Command Line Interface (AWS CLI) command:
aws ecs register-task-definition --cli-input-json file://task-definition-loadbalancer.json
aws ecs create-service--cluster <CLUSTER_NAME> --service-name loadbalancer --task-definition loadbalancer:1 --desired-count 1
Replace the string <CLUSTER_NAME> with the target Amazon ECS cluster name.
The load balancer is now running.
Connecting to the Amazon EC2 instance with the attibute loadbalancer using Session Manager, you can get the following LNI IP address:

Figure 5: Getting the LNI IP
You can access the web user interface by browsing to the URL from your local network:
http://<HOST_IP>:8080/dashboard/
Replace the string <HOST_IP> with the Amazon EC2 instance host LNI IP address, or DNS hostname.
Step 3: Deploying sample web application in awsvpc mode
First, make sure that the AWSVPC Trunking is turned on, as shown in the following figure:

Figure 6: Enabling AWSVPC Trunking
Create an Amazon ECS task definition for our application named “task-definition-webapp.json”, which describes the container configuration to implement the example web application as followed:
Replace the <PLACEHOLDER> values for your application.
{
"containerDefinitions": [
{
"name": "whoami",
"image": "<CONTAINER-IMAGE>:latest",
"cpu": 0,
"portMappings": [
{
"name": "<WEBAPP>",
"containerPort": 80,
"hostPort": 80,
"protocol": "tcp"
}
],
"essential": true,
"environment": [],
"mountPoints": [],
"volumesFrom": [],
"dockerLabels": {
"traefik.http.routers.<WEBAPP>-host.rule": "Host(`<WEBAPP>.domain.com`)",
"traefik.http.routers.<WEBAPP>-path.rule": "Path(`/<WEBAPP>`)",
"traefik.http.services.<WEBAPP>.loadbalancer.server.port": "80"
},
"systemControls": []
}
],
"family": "<WEBAPP>",
"networkMode": "awsvpc",
"volumes": [],
"placementConstraints": [
{
"type": "memberOf",
"expression": "attribute:role == webserver"
}
],
"requiresCompatibilities": [
"EC2"
],
"cpu": "256",
"memory": "128",
"tags": []
}
In the task-definition-webapp.json, consider the following:
- The task definition includes the placement constraint matching the webserver custom attribute value.
- Docker label traefik.http.routers is used to configure host and path based routing rules.
- As the example web application container exposes the single TCP port 80, Docker label traefik.http.services.
<WEBAPP> is used to configure this port for private communication with the Traefik load balancer.
Register the task definition with your cluster and create the loadbalancer service using the following AWS CLI command:
aws ecs register-task-definition --cli-input-json file://task-definition-webapp.json
aws ecs create-service--cluster <CLUSTER_NAME> --service-name <WEBAPP> --task-definition <WEBAPP>:1 --desired-count 1
Replace the string <CLUSTER_NAME> with the target Amazon ECS cluster name and the string <WEBAPP> with your application.
You can access the whoami application by browsing to the URL from your local network:
http://<HOST_IP>/<WEBAPP>
Step 4: Provision DB instance and attach an external storage
The web application has been successfully deployed, so we will move on to the deployment and configuration of the database server next. First, deploy an Amazon EC2 instance to host a MySQL database. As shown in the following screenshot, use the AWS Console to choose an instance type (this is dependent on your Outposts server instance capacity configuration) and configure its network settings to target the correct VPC and the subnet deployed to the Outposts server.

Figure 7: Provisioning a database instance
When the instance is available, deploy MySQL following a standard documented approach to install on a Linux host from the vendor. After successfully installing MySQL, configure users and tables necessary for the application. The sample application configuration file can now be updated to allow the PHP web server container to connect to the MySQL database, as well as create a user and list the users, as shown in the following figures.

Figure 8: Updating the application config file to use the database instance

Figure 9: Sample application connected to database
For the database instance, make sure that the data associated with the application is stored on an existing storage array in the user data center. To do this, you must complete the following:
(a) Enable connectivity to the user network through the LNI.
(b) Mount the iSCSI volume in the EC2 instance.
(c) Configure MySQL to use this iSCSI volume.
To enable connectivity, follow the same process described in step 2 of this post to add an Elastic Network Interface (ENI) with the correct device index to present the LNI to the instance. The following screenshots show a second ENI configured on the instance and associated with the LNI along with the interface and address configuration of the instance that shows two addresses (VPC and user network addresses).

Figure 10: Network interface configuration
Now that connectivity has been established to the user network, you can configure the storage array to present an ISCSI volume to the database instance and mount that volume. The following screenshot shows the /mnt mountpoint being used with iSCSI multi-path across four volumes.

Figure 11: iSCSI volume mount
Finally, configure MySQL to use the iSCSI volume to store data by stopping the MySQL service, updating the default configuration file /etc/my.cnf, and restarting MySQL, as shown in the following figure.

Figure 12: MySQL configuration
Clean up:
Please follow the below instructions to clean up after testing:
- Delete the
<WEBAPP> service
- Delete the loadbalancer service
- Delete your Amazon ECS cluster
- Delete the MySQL Database EC2 instance
- Delete all VPCs
Conclusion
This post has demonstrated how to deploy a sample container-based web application while connecting to the user network, allowing access to the application and connecting to existing storage appliances.
AWS Outposts server allows users to run containers at the edge, addressing challenges related to low latency, local data processing, and data residency. Amazon ECS allows you to deploy consistently, whether in-Region or at the edge, allowing users to develop once and deploy many times.
Get started with Outposts servers by visiting the Outposts servers webpage and learn more about Amazon ECS to begin deploying your containarized workloads at the edge!




































































































{kind=link}