Post Syndicated from Chris Shepherd original https://blog.cloudflare.com/intelligent-automatic-restarts-for-unhealthy-kafka-consumers/
At Cloudflare, we take steps to ensure we are resilient against failure at all levels of our infrastructure. This includes Kafka, which we use for critical workflows such as sending time-sensitive emails and alerts.
We learned a lot about keeping our applications that leverage Kafka healthy, so they can always be operational. Application health checks are notoriously hard to implement: What determines an application as healthy? How can we keep services operational at all times?
These can be implemented in many ways. We’ll talk about an approach that allows us to considerably reduce incidents with unhealthy applications while requiring less manual intervention.
Kafka at Cloudflare
Cloudflare is a big adopter of Kafka. We use Kafka as a way to decouple services due to its asynchronous nature and reliability. It allows different teams to work effectively without creating dependencies on one another. You can also read more about how other teams at Cloudflare use Kafka in this post.
Kafka is used to send and receive messages. Messages represent some kind of event like a credit card payment or details of a new user created in your platform. These messages can be represented in multiple ways: JSON, Protobuf, Avro and so on.
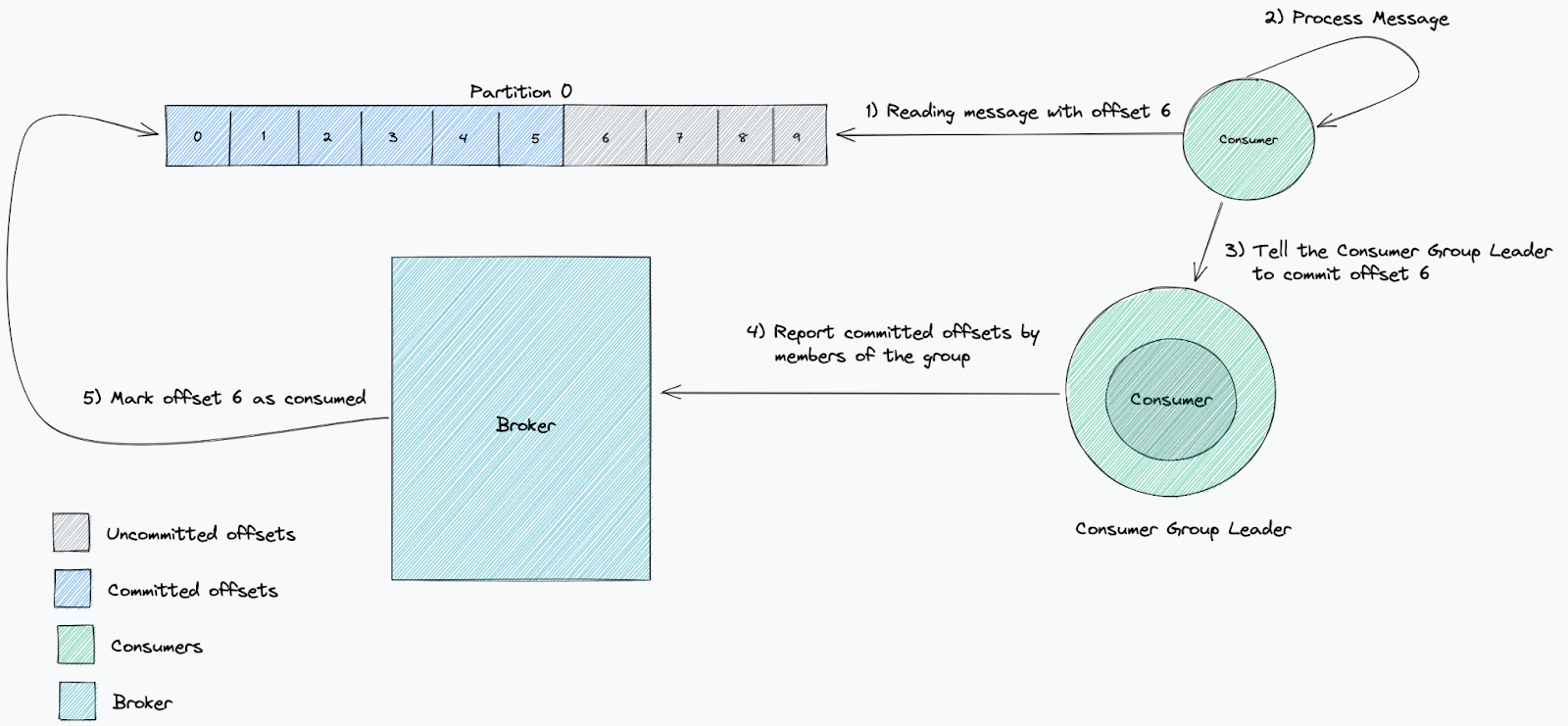
Kafka organises messages in topics. A topic is an ordered log of events in which each message is marked with a progressive offset. When an event is written by an external system, that is appended to the end of that topic. These events are not deleted from the topic by default (retention can be applied).
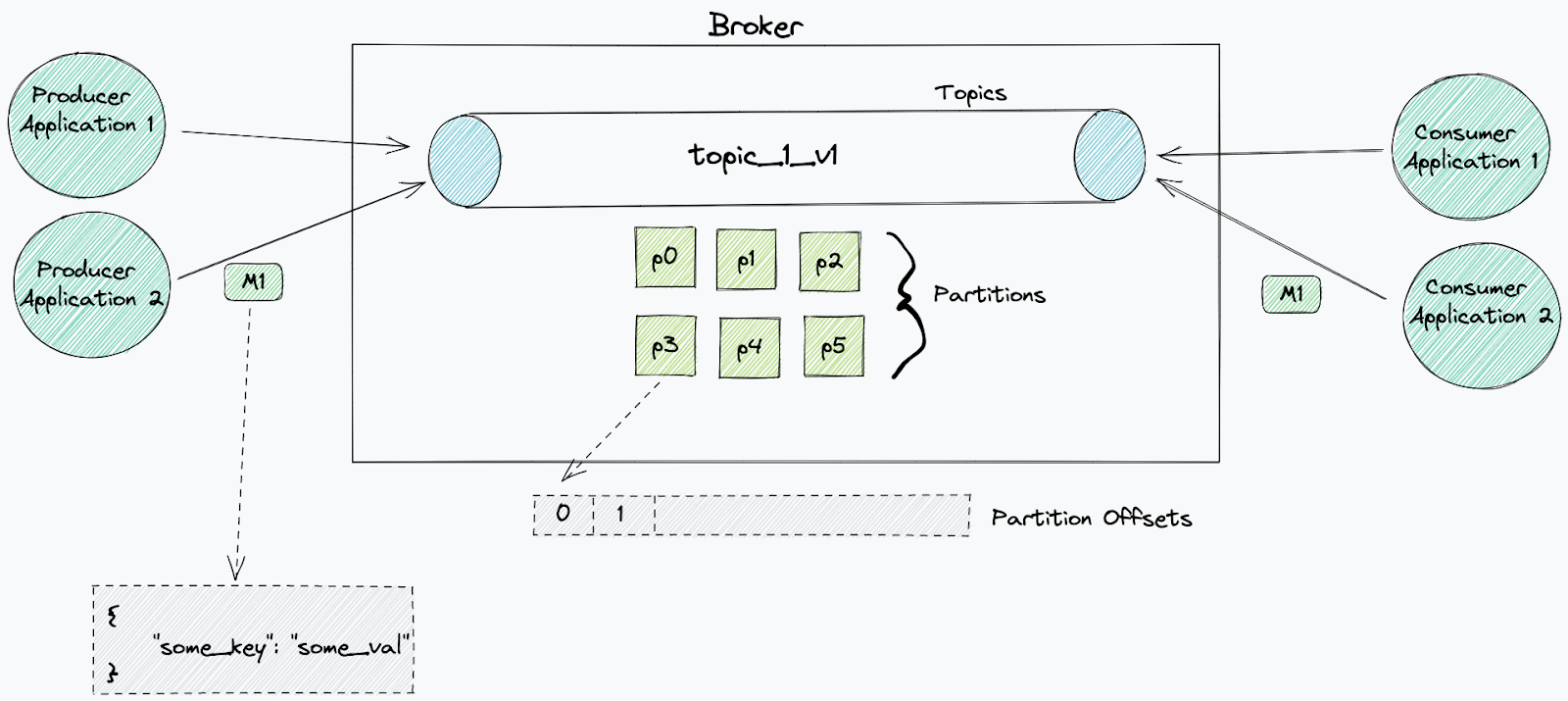
Topics are stored as log files on disk, which are finite in size. Partitions are a systematic way of breaking the one topic log file into many logs, each of which can be hosted on separate servers–enabling to scale topics.
Topics are managed by brokers–nodes in a Kafka cluster. These are responsible for writing new events to partitions, serving reads and replicating partitions among themselves.
Messages can be consumed by individual consumers or co-ordinated groups of consumers, known as consumer groups.
Consumers use a unique id (consumer id) that allows them to be identified by the broker as an application which is consuming from a specific topic.
Each topic can be read by an infinite number of different consumers, as long as they use a different id. Each consumer can replay the same messages as many times as they want.
When a consumer starts consuming from a topic, it will process all messages, starting from a selected offset, from each partition. With a consumer group, the partitions are divided amongst each consumer in the group. This division is determined by the consumer group leader. This leader will receive information about the other consumers in the group and will decide which consumers will receive messages from which partitions (partition strategy).
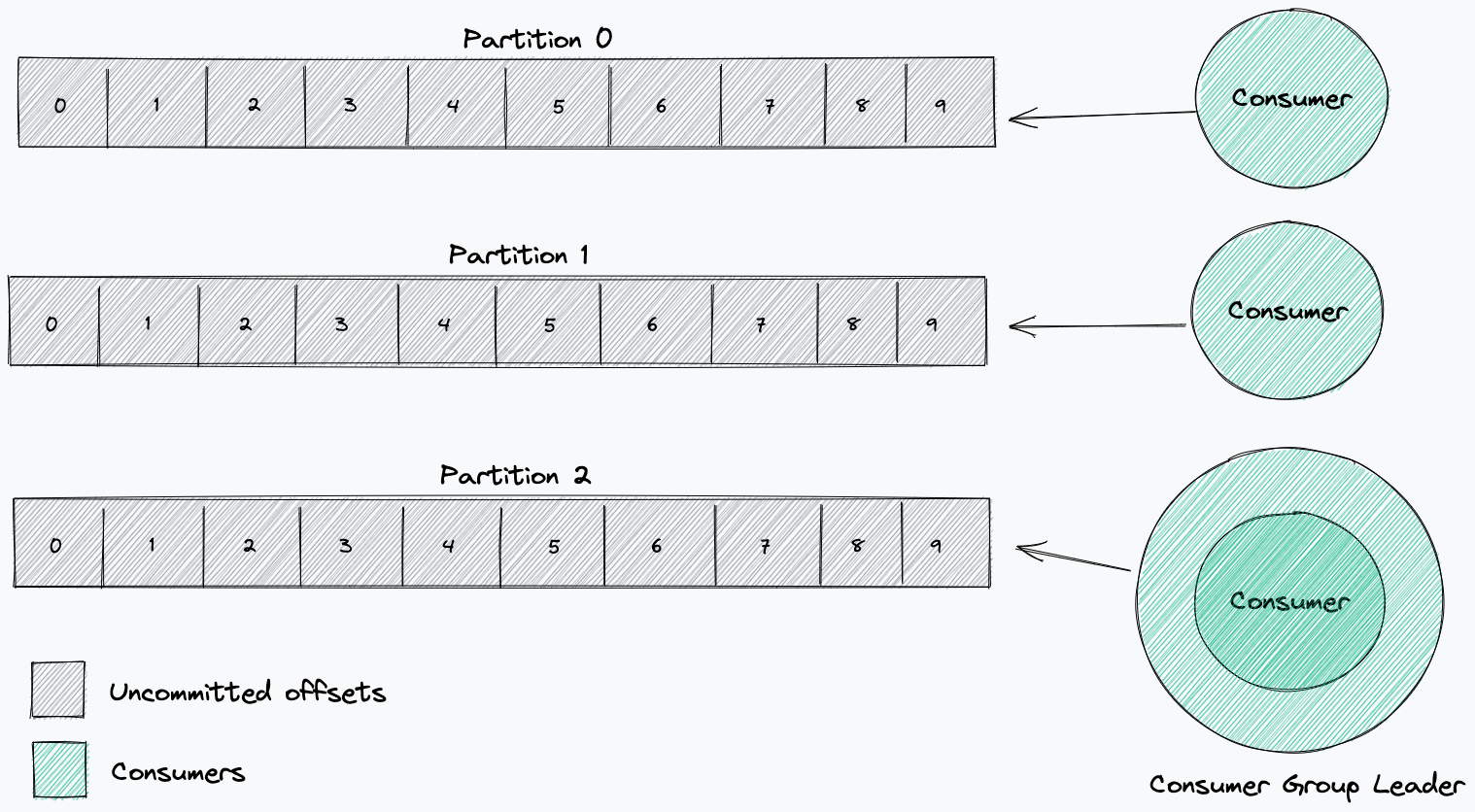
The offset of a consumer’s commit can demonstrate whether the consumer is working as expected. Committing a processed offset is the way a consumer and its consumer group report to the broker that they have processed a particular message.
A standard measurement of whether a consumer is processing fast enough is lag. We use this to measure how far behind the newest message we are. This tracks time elapsed between messages being written to and read from a topic. When a service is lagging behind, it means that the consumption is at a slower rate than new messages being produced.
Due to Cloudflare’s scale, message rates typically end up being very large and a lot of requests are time-sensitive so monitoring this is vital.
At Cloudflare, our applications using Kafka are deployed as microservices on Kubernetes.
Health checks for Kubernetes apps
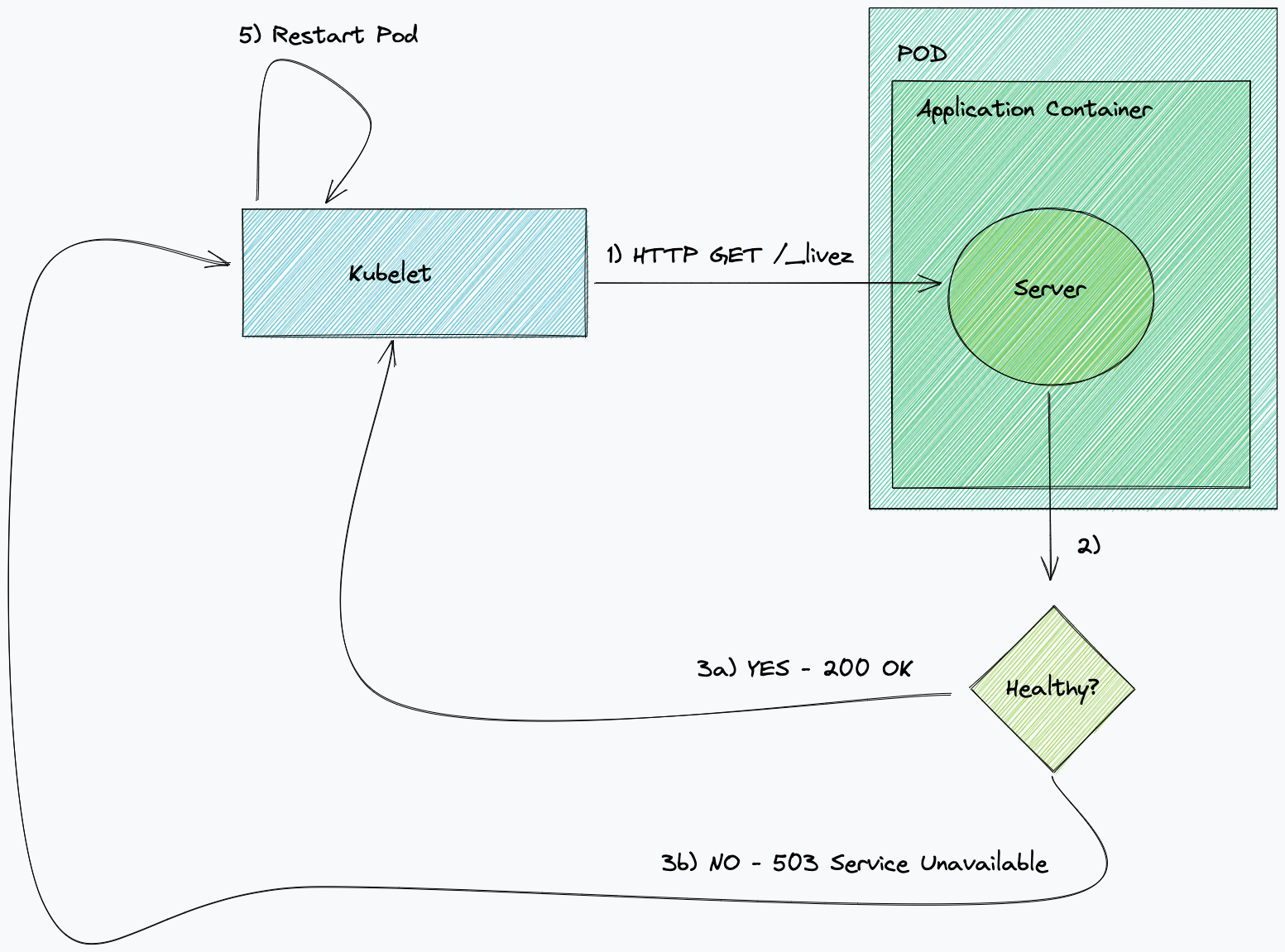
Kubernetes uses probes to understand if a service is healthy and is ready to receive traffic or to run. When a liveness probe fails and the bounds for retrying are exceeded, Kubernetes restarts the services.
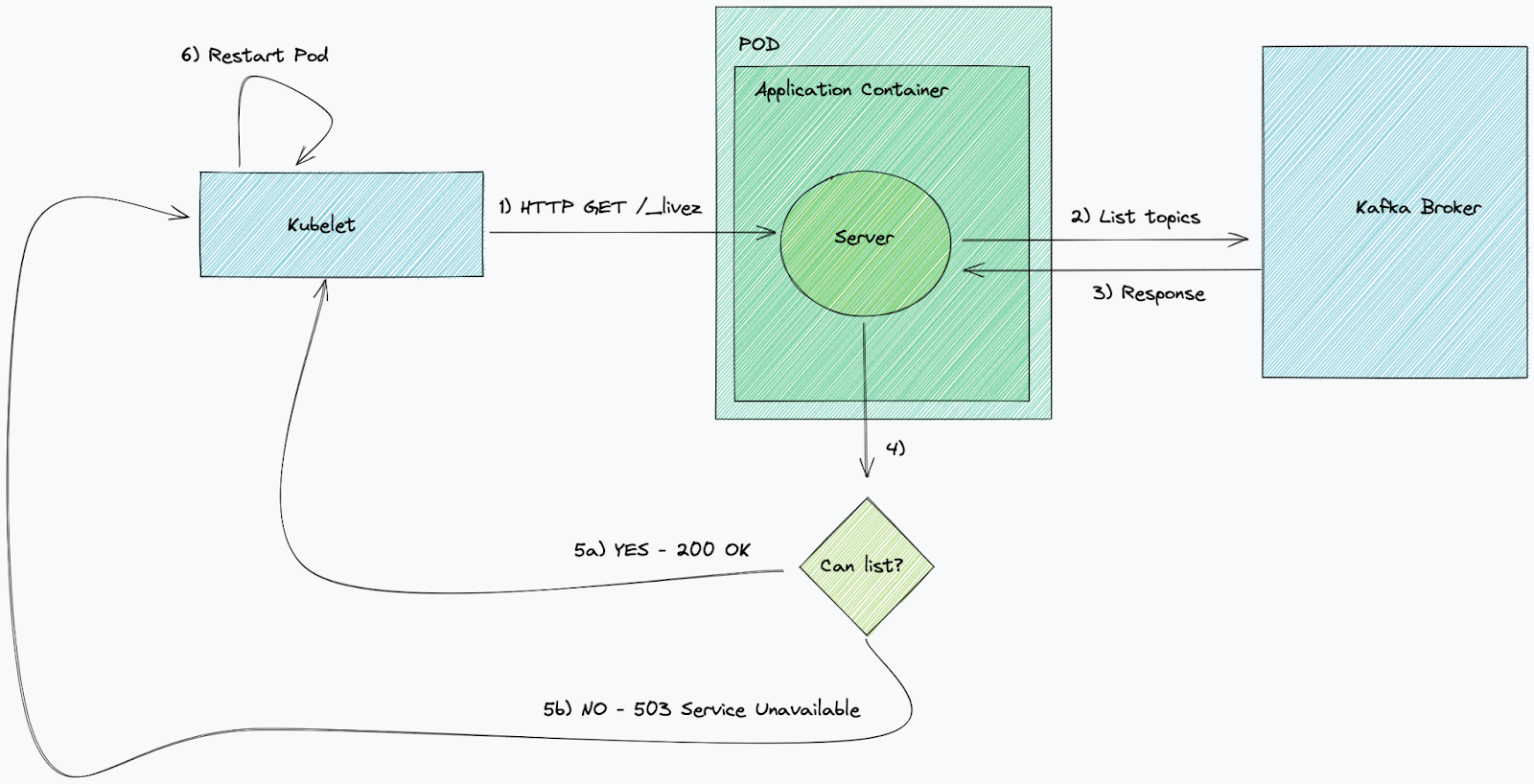
When a readiness probe fails and the bounds for retrying are exceeded, it stops sending HTTP traffic to the targeted pods. In the case of Kafka applications this is not relevant as they don’t run an http server. For this reason, we’ll cover only liveness checks.
A classic Kafka liveness check done on a consumer checks the status of the connection with the broker. It’s often best practice to keep these checks simple and perform some basic operations – in this case, something like listing topics. If, for any reason, this check fails consistently, for instance the broker returns a TLS error, Kubernetes terminates the service and starts a new pod of the same service, therefore forcing a new connection. Simple Kafka liveness checks do a good job of understanding when the connection with the broker is unhealthy.
Problems with Kafka health checks
Due to Cloudflare’s scale, a lot of our Kafka topics are divided into multiple partitions (in some cases this can be hundreds!) and in many cases the replica count of our consuming service doesn’t necessarily match the number of partitions on the Kafka topic. This can mean that in a lot of scenarios this simple approach to health checking is not quite enough!
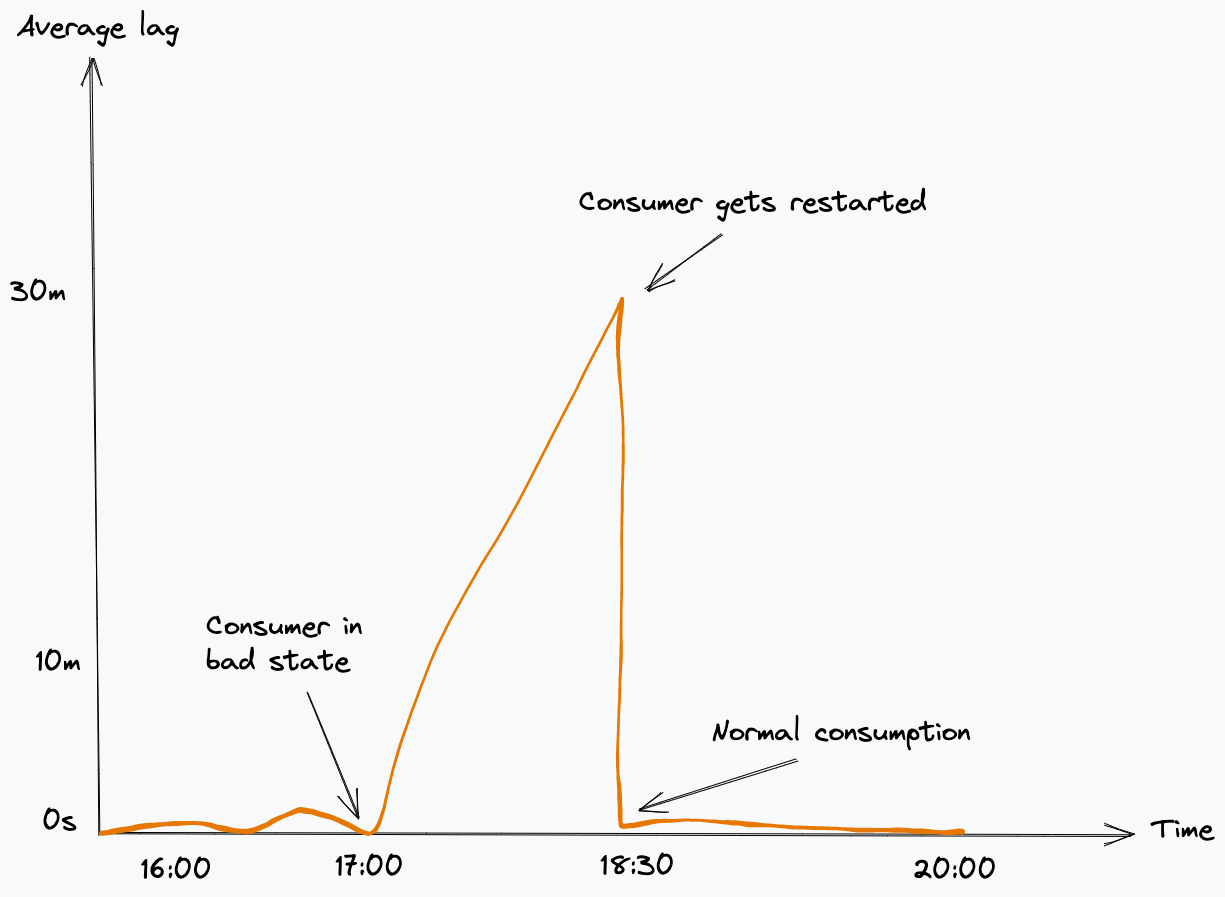
Microservices that consume from Kafka topics are healthy if they are consuming and committing offsets at regular intervals when messages are being published to a topic. When such services are not committing offsets as expected, it means that the consumer is in a bad state, and it will start accumulating lag. An approach we often take is to manually terminate and restart the service in Kubernetes, this will cause a reconnection and rebalance.
When a consumer joins or leaves a consumer group, a rebalance is triggered and the consumer group leader must re-assign which consumers will read from which partitions.
When a rebalance happens, each consumer is notified to stop consuming. Some consumers might get their assigned partitions taken away and re-assigned to another consumer. We noticed when this happened within our library implementation; if the consumer doesn’t acknowledge this command, it will wait indefinitely for new messages to be consumed from a partition that it’s no longer assigned to, ultimately leading to a deadlock. Usually a manual restart of the faulty client-side app is needed to resume processing.
Intelligent health checks
As we were seeing consumers reporting as “healthy” but sitting idle, it occurred to us that maybe we were focusing on the wrong thing in our health checks. Just because the service is connected to the Kafka broker and can read from the topic, it does not mean the consumer is actively processing messages.
Therefore, we realised we should be focused on message ingestion, using the offset values to ensure that forward progress was being made.
The PagerDuty approach
PagerDuty wrote an excellent blog on this topic which we used as inspiration when coming up with our approach.
Their approach used the current (latest) offset and the committed offset values. The current offset signifies the last message that was sent to the topic, while the committed offset is the last message that was processed by the consumer.
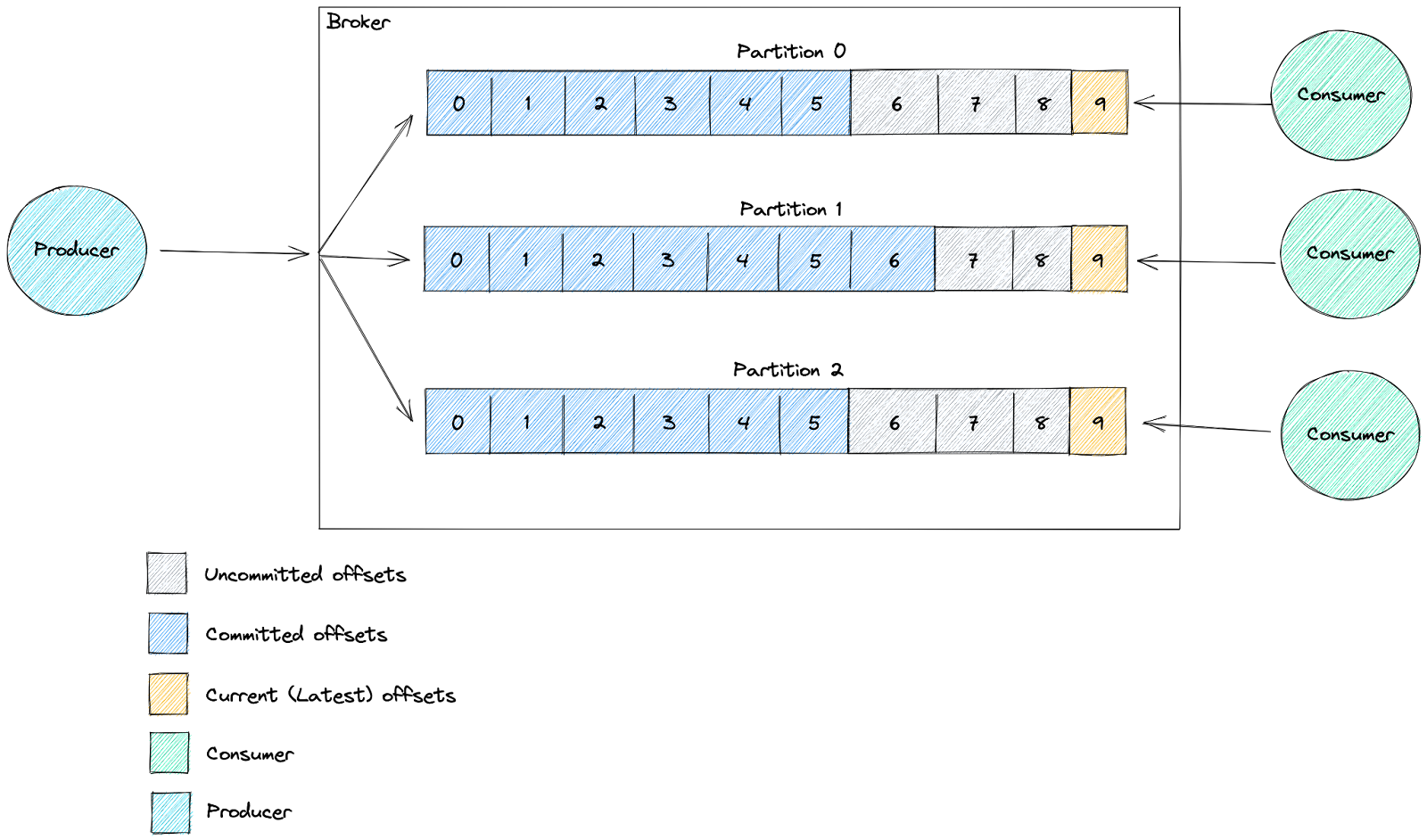
Checking the consumer is moving forwards, by ensuring that the latest offset was changing (receiving new messages) and the committed offsets were changing as well (processing the new messages).
Therefore, the solution we came up with:
- If we cannot read the current offset, fail liveness probe.
- If we cannot read the committed offset, fail liveness probe.
- If the committed offset == the current offset, pass liveness probe.
- If the value for the committed offset has not changed since the last run of the health check, fail liveness probe.
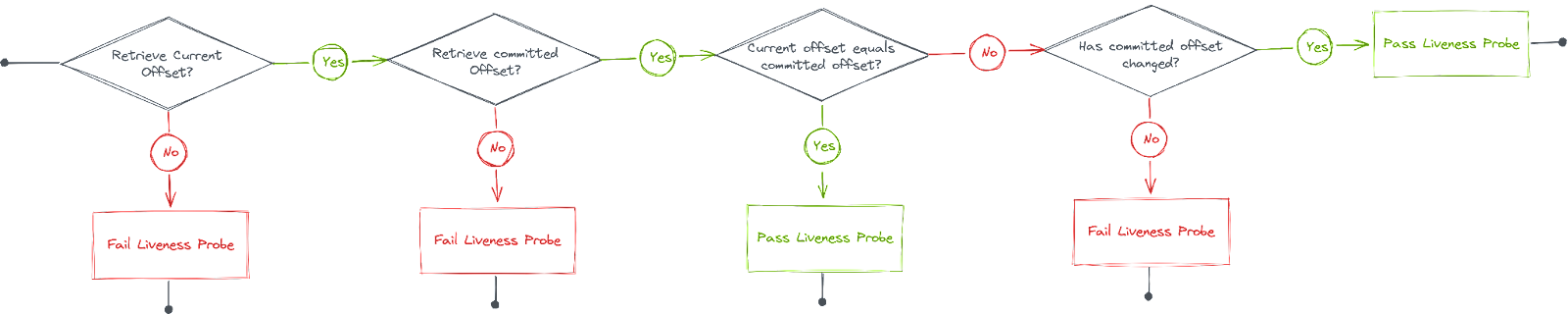
To measure if the committed offset is changing, we need to store the value of the previous run, we do this using an in-memory map where partition number is the key. This means each instance of our service only has a view of the partitions it is currently consuming from and will run the health check for each.
Problems
When we first rolled out our smart health checks we started to notice cascading failures some time after release. After initial investigations we realised this was happening when a rebalance happens. It would initially affect one replica then quickly result in the others reporting as unhealthy.
What we observed was due to us storing the previous value of the committed offset in-memory, when a rebalance happens the service may get re-assigned a different partition. When this happened it meant our service was incorrectly assuming that the committed offset for that partition had not changed (as this specific replica was no longer updating the latest value), therefore it would start to report the service as unhealthy. The failing liveness probe would then cause it to restart which would in-turn trigger another rebalancing in Kafka causing other replicas to face the same issue.
Solution
To fix this issue we needed to ensure that each replica only kept track of the offsets for the partitions it was consuming from at that moment. Luckily, the Shopify Sarama library, which we use internally, has functionality to observe when a rebalancing happens. This meant we could use it to rebuild the in-memory map of offsets so that it would only include the relevant partition values.
This is handled by receiving the signal from the session context channel:
for {
select {
case message, ok := <-claim.Messages(): // <-- Message received
// Store latest received offset in-memory
offsetMap[message.Partition] = message.Offset
// Handle message
handleMessage(ctx, message)
// Commit message offset
session.MarkMessage(message, "")
case <-session.Context().Done(): // <-- Rebalance happened
// Remove rebalanced partition from in-memory map
delete(offsetMap, claim.Partition())
}
}
Verifying this solution was straightforward, we just needed to trigger a rebalance. To test this worked in all possible scenarios we spun up a single replica of a service consuming from multiple partitions, then proceeded to scale up the number of replicas until it matched the partition count, then scaled back down to a single replica. By doing this we verified that the health checks could safely handle new partitions being assigned as well as partitions being taken away.
Takeaways
Probes in Kubernetes are very easy to set up and can be a powerful tool to ensure your application is running as expected. Well implemented probes can often be the difference between engineers being called out to fix trivial issues (sometimes outside of working hours) and a service which is self-healing.
However, without proper thought, “dumb” health checks can also lead to a false sense of security that a service is running as expected even when it’s not. One thing we have learnt from this was to think more about the specific behaviour of the service and decide what being unhealthy means in each instance, instead of just ensuring that dependent services are connected.