Post Syndicated from Lotfi Mouhib original https://aws.amazon.com/blogs/big-data/design-considerations-for-amazon-emr-on-eks-in-a-multi-tenant-amazon-eks-environment/
Many AWS customers use Amazon Elastic Kubernetes Service (Amazon EKS) in order to take advantage of Kubernetes without the burden of managing the Kubernetes control plane. With Kubernetes, you can centrally manage your workloads and offer administrators a multi-tenant environment where they can create, update, scale, and secure workloads using a single API. Kubernetes also allows you to improve resource utilization, reduce cost, and simplify infrastructure management to support different application deployments. This model is beneficial for those running Apache Spark workloads, for several reasons. For example, it allows you to have multiple Spark environments running concurrently with different configurations and dependencies that are segregated from each other through Kubernetes multi-tenancy features. In addition, the same cluster can be used for various workloads like machine learning (ML), host applications, data streaming and thereby reducing operational overhead of managing multiple clusters.
AWS offers Amazon EMR on EKS, a managed service that enables you to run your Apache Spark workloads on Amazon EKS. This service uses the Amazon EMR runtime for Apache Spark, which increases the performance of your Spark jobs so that they run faster and cost less. When you run Spark jobs on EMR on EKS and not on self-managed Apache Spark on Kubernetes, you can take advantage of automated provisioning, scaling, faster runtimes, and the development and debugging tools that Amazon EMR provides
In this post, we show how to configure and run EMR on EKS in a multi-tenant EKS cluster that can used by your various teams. We tackle multi-tenancy through four topics: network, resource management, cost management, and security.
Concepts
Throughout this post, we use terminology that is either specific to EMR on EKS, Spark, or Kubernetes:
- Multi-tenancy – Multi-tenancy in Kubernetes can come in three forms: hard multi-tenancy, soft multi-tenancy and sole multi-tenancy. Hard multi-tenancy means each business unit or group of applications gets a dedicated Kubernetes; there is no sharing of the control plane. This model is out of scope for this post. Soft multi-tenancy is where pods might share the same underlying compute resource (node) and are logically separated using Kubernetes constructs through namespaces, resource quotas, or network policies. A second way to achieve multi-tenancy in Kubernetes is to assign pods to specific nodes that are pre-provisioned and allocated to a specific team. In this case, we talk about sole multi-tenancy. Unless your security posture requires you to use hard or sole multi-tenancy, you would want to consider using soft multi-tenancy for the following reasons:
- Soft multi-tenancy avoids underutilization of resources and waste of compute resources.
- There is a limited number of managed node groups that can be used by Amazon EKS, so for large deployments, this limit can quickly become a limiting factor.
- In sole multi-tenancy there is high chance of ghost nodes with no pods scheduled on them due to misconfiguration as we force pods into dedicated nodes with label, taints and tolerance and anti-affinity rules.
- Namespace – Namespaces are core in Kubernetes and a pillar to implement soft multi-tenancy. With namespaces, you can divide the cluster into logical partitions. These partitions are then referenced in quotas, network policies, service accounts, and other constructs that help isolate environments in Kubernetes.
- Virtual cluster – An EMR virtual cluster is mapped to a Kubernetes namespace that Amazon EMR is registered with. Amazon EMR uses virtual clusters to run jobs and host endpoints. Multiple virtual clusters can be backed by the same physical cluster. However, each virtual cluster maps to one namespace on an EKS cluster. Virtual clusters don’t create any active resources that contribute to your bill or require lifecycle management outside the service.
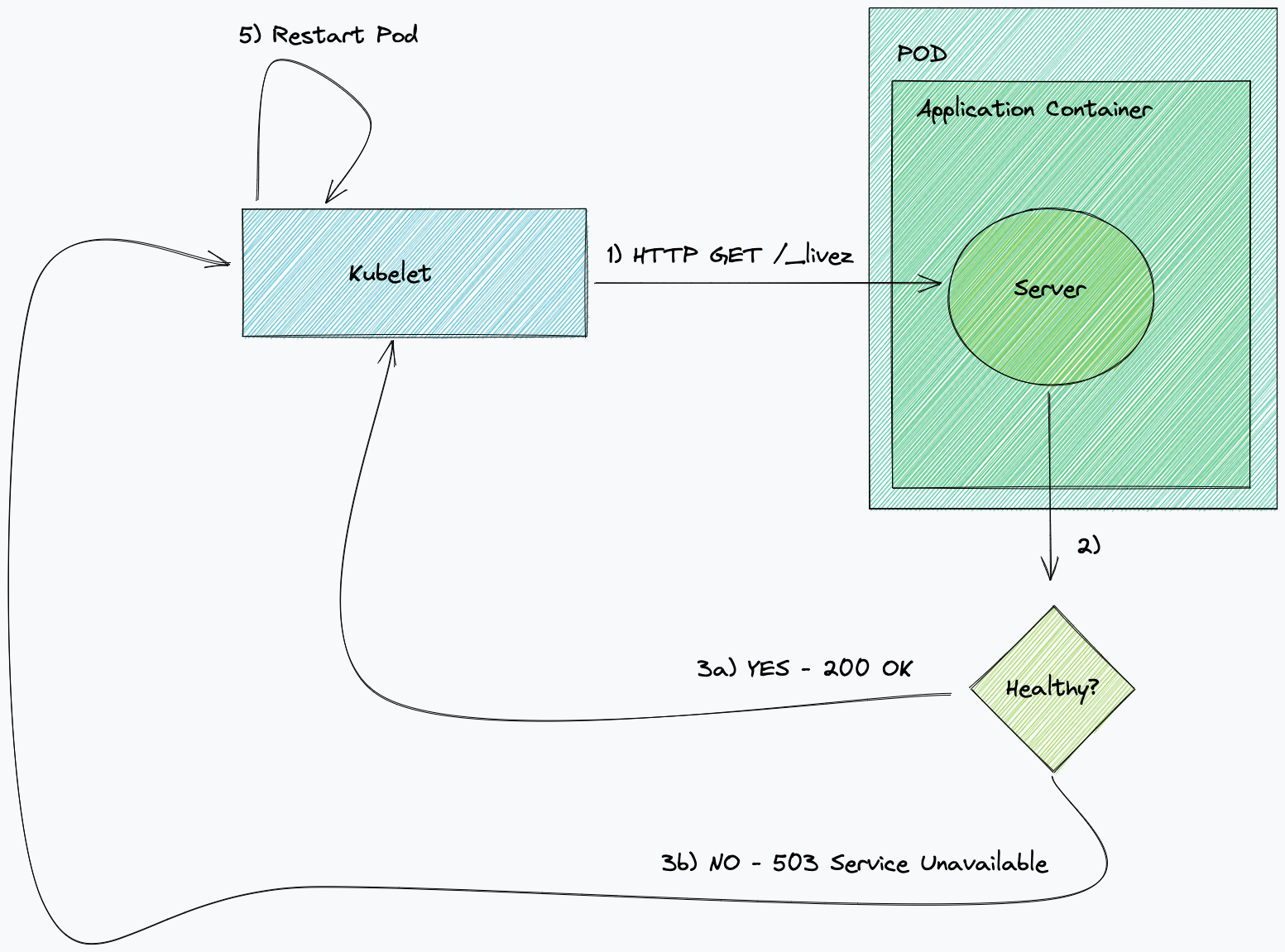
- Pod template – In EMR on EKS, you can provide a pod template to control pod placement, or define a sidecar container. This pod template can be defined for executor pods and driver pods, and stored in an Amazon Simple Storage Service (Amazon S3) bucket. The S3 locations are then submitted as part of the applicationConfiguration object that is part of configurationOverrides, as defined in the EMR on EKS job submission API.
Security considerations
In this section, we address security from different angles. We first discuss how to protect IAM role that is used for running the job. Then address how to protect secrets use in jobs and finally we discuss how you can protect data while it is processed by Spark.
IAM role protection
A job submitted to EMR on EKS needs an AWS Identity and Access Management (IAM) execution role to interact with AWS resources, for example with Amazon S3 to get data, with Amazon CloudWatch Logs to publish logs, or use an encryption key in AWS Key Management Service (AWS KMS). It’s a best practice in AWS to apply least privilege for IAM roles. In Amazon EKS, this is achieved through IRSA (IAM Role for Service Accounts). This mechanism allows a pod to assume an IAM role at the pod level and not at the node level, while using short-term credentials that are provided through the EKS OIDC.
IRSA creates a trust relationship between the EKS OIDC provider and the IAM role. This method allows only pods with a service account (annotated with an IAM role ARN) to assume a role that has a trust policy with the EKS OIDC provider. However, this isn’t enough, because it would allow any pod with a service account within the EKS cluster that is annotated with a role ARN to assume the execution role. This must be further scoped down using conditions on the role trust policy. This condition allows the assume role to happen only if the calling service account is the one used for running a job associated with the virtual cluster. The following code shows the structure of the condition to add to the trust policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": <OIDC provider ARN >
},
"Action": "sts:AssumeRoleWithWebIdentity"
"Condition": { "StringLike": { “<OIDC_PROVIDER>:sub": "system:serviceaccount:<NAMESPACE>:emr-containers-sa-*-*-<AWS_ACCOUNT_ID>-<BASE36_ENCODED_ROLE_NAME>”} }
}
]
}
To scope down the trust policy using the service account condition, you need to run the following the command with AWS CLI:
aws emr-containers update-role-trust-policy \
–cluster-name cluster \
–namespace namespace \
–role-name iam_role_name_for_job_execution
The command will the add the service account that will be used by the spark client, Jupyter Enterprise Gateway, Spark kernel, driver or executor. The service accounts name have the following structure emr-containers-sa-*-*-<AWS_ACCOUNT_ID>-<BASE36_ENCODED_ROLE_NAME>.
In addition to the role segregation offered by IRSA, we recommend blocking access to instance metadata because a pod can still inherit the rights of the instance profile assigned to the worker node. For more information about how you can block access to metadata, refer to Restrict access to the instance profile assigned to the worker node.
Secret protection
Sometime a Spark job needs to consume data stored in a database or from APIs. Most of the time, these are protected with a password or access key. The most common way to pass these secrets is through environment variables. However, in a multi-tenant environment, this means any user with access to the Kubernetes API can potentially access the secrets in the environment variables if this access isn’t scoped well to the namespaces the user has access to.
To overcome this challenge, we recommend using a Secrets store like AWS Secrets Manager that can be mounted through the Secret Store CSI Driver. The benefit of using Secrets Manager is the ability to use IRSA and allow only the role assumed by the pod access to the given secret, thereby improving your security posture. You can refer to the best practices guide for sample code showing the use of Secrets Manager with EMR on EKS.
Spark data encryption
When a Spark application is running, the driver and executors produce intermediate data. This data is written to the node local storage. Anyone who is able to exec into the pods would be able to read this data. Spark supports encryption of this data, and it can be enabled by passing --conf spark.io.encryption.enabled=true. Because this configuration adds performance penalty, we recommend enabling data encryption only for workloads that store and access highly sensitive data and in untrusted environments.
Network considerations
In this section we discuss how to manage networking within the cluster as well as outside the cluster. We first address how Spark handle cross executors and driver communication and how to secure it. Then we discuss how to restrict network traffic between pods in the EKS cluster and allow only traffic destined to EMR on EKS. Last, we discuss how to restrict traffic of executors and driver pods to external AWS service traffic using security groups.
Network encryption
The communication between the driver and executor uses RPC protocol and is not encrypted. Starting with Spark 3 in the Kubernetes backed cluster, Spark offers a mechanism to encrypt communication using AES encryption.
The driver generates a key and shares it with executors through the environment variable. Because the key is shared through the environment variable, potentially any user with access to the Kubernetes API (kubectl) can read the key. We recommend securing access so that only authorized users can have access to the EMR virtual cluster. In addition, you should set up Kubernetes role-based access control in such a way that the pod spec in the namespace where the EMR virtual cluster runs is granted to only a few selected service accounts. This method of passing secrets through the environment variable would change in the future with a proposal to use Kubernetes secrets.
To enable encryption, RPC authentication must also be enabled in your Spark configuration. To enable encryption in-transit in Spark, you should use the following parameters in your Spark config:
--conf spark.authenticate=true
--conf spark.network.crypto.enabled=true
Note that these are the minimal parameters to set; refer to Encryption from the complete list of parameters.
Additionally, applying encryption in Spark has a negative impact on processing speed. You should only apply it when there is a compliance or regulation need.
Securing Network traffic within the cluster
In Kubernetes, by default pods can communicate over the network across different namespaces in the same cluster. This behavior is not always desirable in a multi-tenant environment. In some instances, for example in regulated industries, to be compliant you want to enforce strict control over the network and send and receive traffic only from the namespace that you’re interacting with. For EMR on EKS, it would be the namespace associated to the EMR virtual cluster. Kubernetes offers constructs that allow you to implement network policies and define fine-grained control over the pod-to-pod communication. These policies are implemented by the CNI plugin; in Amazon EKS, the default plugin would be the VPC CNI. A policy is defined as follows and is applied with kubectl:
Kind: NetworkPolicy
metadata:
name: default-np-ns1
namespace: <EMR-VC-NAMESPACE>
spec:
podSelector: {}
policyTypes:
- Ingress
- Egress
ingress:
- from:
- namespaceSelector:
matchLabels:
nsname: <EMR-VC-NAMESPACE>
Network traffic outside the cluster
In Amazon EKS, when you deploy pods on Amazon Elastic Compute Cloud (Amazon EC2) instances, all the pods use the security group associated with the node. This can be an issue if your pods (executor pods) are accessing a data source (namely a database) that allows traffic based on the source security group. Database servers often restrict network access only from where they are expecting it. In the case of a multi-tenant EKS cluster, this means pods from other teams that shouldn’t have access to the database servers, would be able to send traffic to it.
To overcome this challenge, you can use security groups for pods. This feature allows you to assign a specific security group to your pods, thereby controlling the network traffic to your database server or data source. You can also refer to the best practices guide for a reference implementation.
Cost management and chargeback
In a multi-tenant environment, cost management is a critical subject. You have multiple users from various business units, and you need to be able to precisely chargeback the cost of the compute resource they have used. At the beginning of the post, we introduced three models of multi-tenancy in Amazon EKS: hard multi-tenancy, soft multi-tenancy, and sole multi-tenancy. Hard multi-tenancy is out of scope because the cost tracking is trivial; all the resources are dedicated to the team using the cluster, which is not the case for sole multi-tenancy and soft multi-tenancy. In the next sections, we discuss these two methods to track the cost for each of model.
Soft multi-tenancy
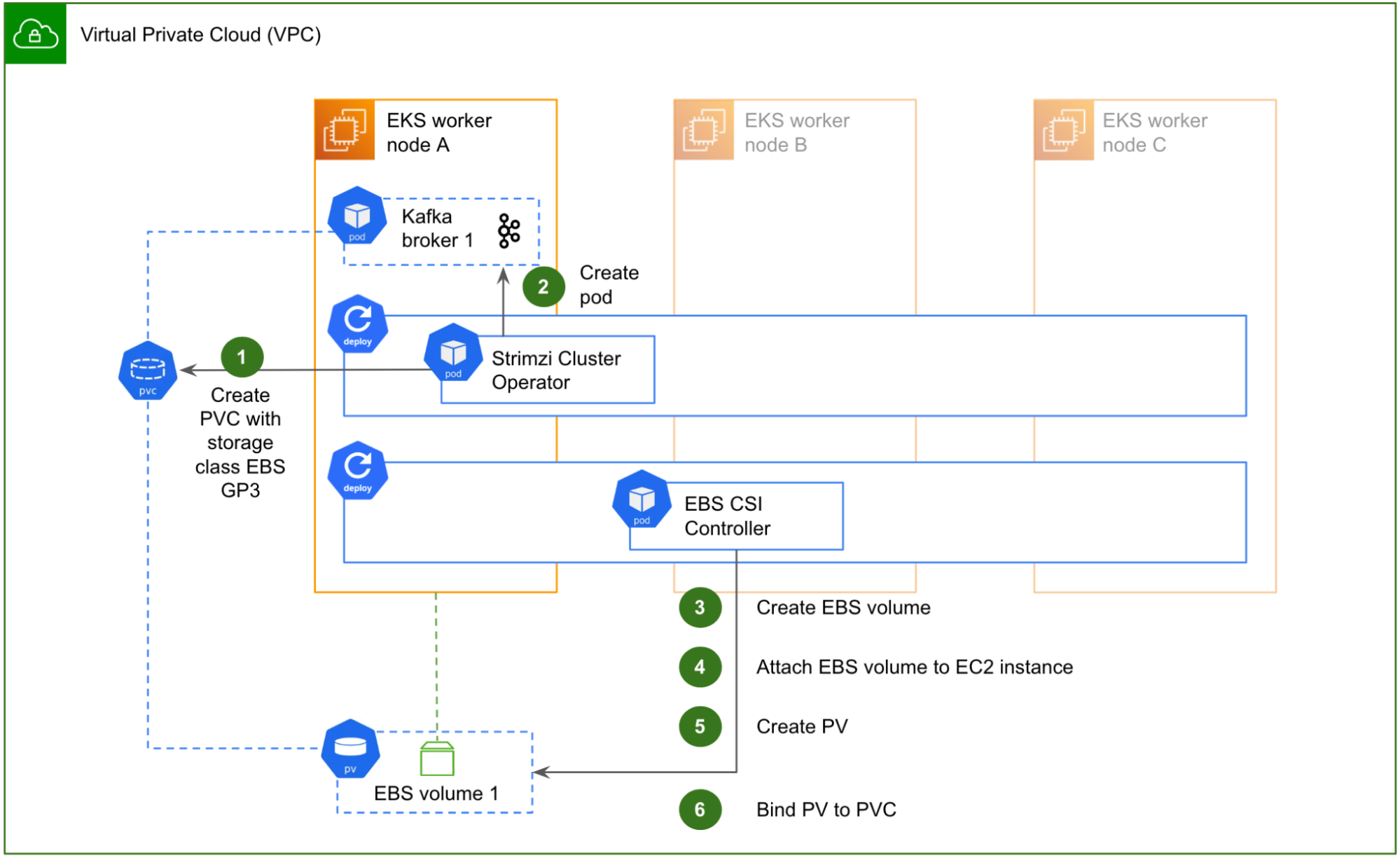
In a soft multi-tenant environment, you can perform chargeback to your data engineering teams based on the resources they consumed and not the nodes allocated. In this method, you use the namespaces associated with the EMR virtual cluster to track how much resources were used for processing jobs. The following diagram illustrates an example.

Diagram -1 Soft multi-tenancy
Tracking resources based on the namespace isn’t an easy task because jobs are transient in nature and fluctuate in their duration. However, there are partner tools available that allow you to keep track of the resources used, such as Kubecost, CloudZero, Vantage, and many others. For instructions on using Kubecost on Amazon EKS, refer to this blog post on cost monitoring for EKS customers.
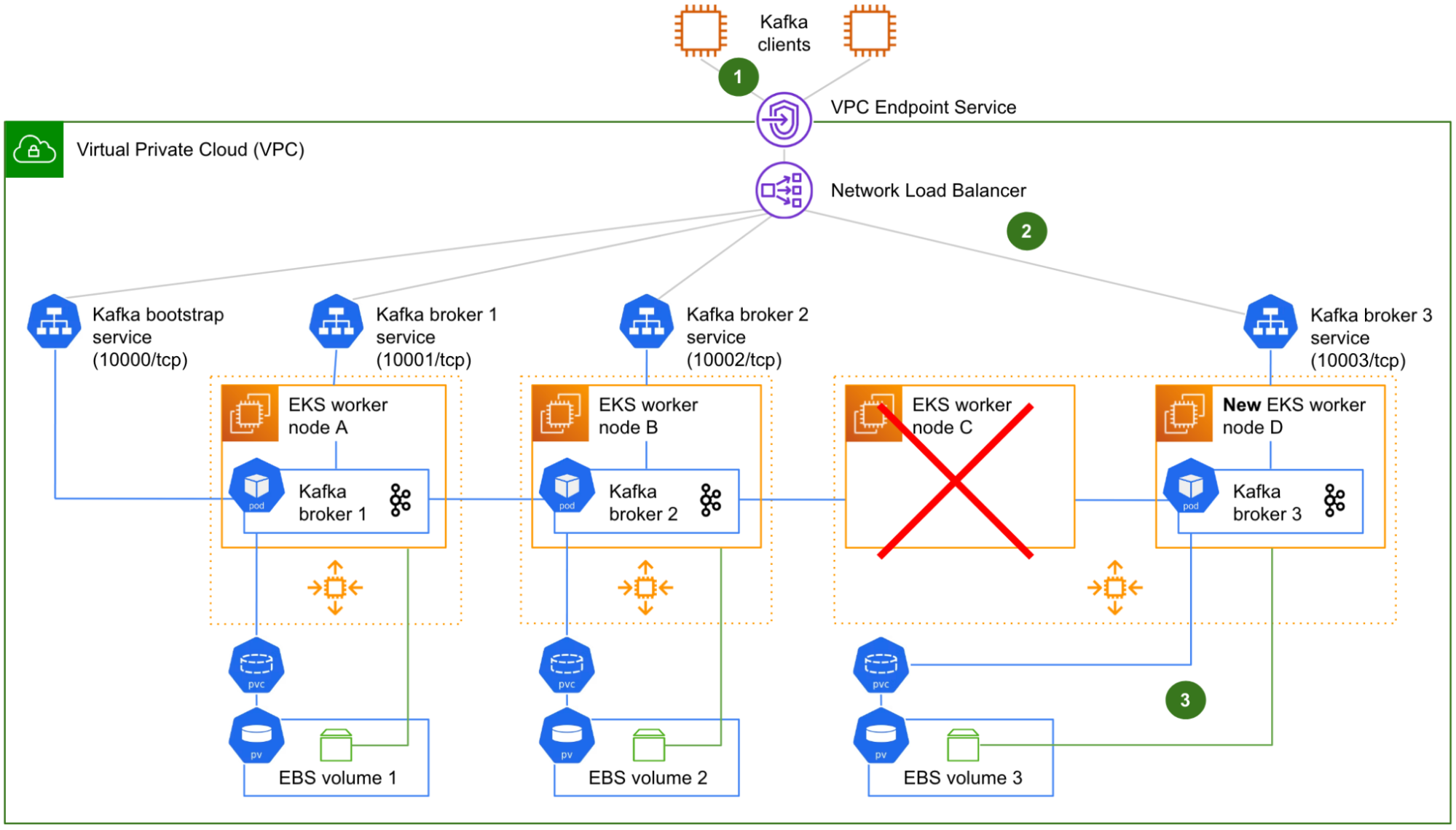
Sole multi-tenancy
For sole multi-tenancy, the chargeback is done at the instance (node) level. Each member on your team uses a specific set of nodes that are dedicated to it. These nodes aren’t always running, and are spun up using the Kubernetes auto scaling mechanism. The following diagram illustrates an example.
Diagram -2 Sole tenancy
With sole multi-tenancy, you use a cost allocation tag, which is an AWS mechanism that allows you to track how much each resource has consumed. Although the method of sole multi-tenancy isn’t efficient in terms of resource utilization, it provides a simplified strategy for chargebacks. With the cost allocation tag, you can chargeback a team based on all the resources they used, like Amazon S3, Amazon DynamoDB, and other AWS resources. The chargeback mechanism based on the cost allocation tag can be augmented using the recently launched AWS Billing Conductor, which allows you to issue bills internally for your team.
Resource management
In this section, we discuss considerations regarding resource management in multi-tenant clusters. We briefly discuss topics like sharing resources graciously, setting guard rails on resource consumption, techniques for ensuring resources for time sensitive and/or critical jobs, meeting quick resource scaling requirements and finally cost optimization practices with node selectors.
Sharing resources
In a multi-tenant environment, the goal is to share resources like compute and memory for better resource utilization. However, this requires careful capacity management and resource allocation to make sure each tenant gets their fair share. In Kubernetes, resource allocation is controlled and enforced by using ResourceQuota and LimitRange. ResourceQuota limits resources on the namespace level, and LimitRange allows you to make sure that all the containers are submitted with a resource requirement and a limit. In this section, we demonstrate how a data engineer or Kubernetes administrator can set up ResourceQuota as a LimitRange configuration.
The administrator creates one ResourceQuota per namespace that provides constraints for aggregate resource consumption:
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-resources
namespace: teamA
spec:
hard:
requests.cpu: "1000"
requests.memory: 4000Gi
limits.cpu: "2000"
limits.memory: 6000Gi
For LimitRange, the administrator can review the following sample configuration. We recommend using default and defaultRequest to enforce the limit and request field on containers. Lastly, from a data engineer perspective while submitting the EMR on EKS jobs, you need to make sure the Spark parameters of resource requirements are within the range of the defined LimitRange. For example, in the following configuration, the request for spark.executor.cores=7 will fail because the max limit for CPU is 6 per container:
apiVersion: v1
kind: LimitRange
metadata:
name: cpu-min-max
namespace: teamA
spec:
limits:
- max:
cpu: "6"
min:
cpu: "100m"
default:
cpu: "500m"
defaultRequest:
cpu: "100m"
type: Container
Priority-based resource allocation

Diagram – 3 Illustrates an example of resource allocation with priority.
As all the EMR virtual clusters share the same EKS computing platform with limited resources, there will be scenarios in which you need to prioritize jobs in a sensitive timeline. In this case, high-priority jobs can utilize the resources and finish the job, whereas low-priority jobs that are running gets stopped and any new pods must wait in the queue. EMR on EKS can achieve this with the help of pod templates, where you specify a priority class for the given job.
When a pod priority is enabled, the Kubernetes scheduler orders pending pods by their priority and places them in the scheduling queue. As a result, the higher-priority pod may be scheduled sooner than pods with lower priority if its scheduling requirements are met. If this pod can’t be scheduled, the scheduler continues and tries to schedule other lower-priority pods.
The preemptionPolicy field on the PriorityClass defaults to PreemptLowerPriority, and the pods of that PriorityClass can preempt lower-priority pods. If preemptionPolicy is set to Never, pods of that PriorityClass are non-preempting. In other words, they can’t preempt any other pods. When lower-priority pods are preempted, the victim pods get a grace period to finish their work and exit. If the pod doesn’t exit within that grace period, that pod is stopped by the Kubernetes scheduler. Therefore, there is usually a time gap between the point when the scheduler preempts victim pods and the time that a higher-priority pod is scheduled. If you want to minimize this gap, you can set a deletion grace period of lower-priority pods to zero or a small number. You can do this by setting the terminationGracePeriodSeconds option in the victim Pod YAML.
See the following code samples for priority class:
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 100
globalDefault: false
description: " High-priority Pods and for Driver Pods."
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: low-priority
value: 50
globalDefault: false
description: " Low-priority Pods."
One of the key considerations while templatizing the driver pods, especially for low-priority jobs, is to avoid the same low-priority class for both driver and executor. This will save the driver pods from getting evicted and lose the progress of all its executors in a resource congestion scenario. In this low-priority job example, we have used a high-priority class for driver pod templates and low-priority classes only for executor templates. This way, we can ensure the driver pods are safe during the eviction process of low-priority jobs. In this case, only executors will be evicted, and the driver can bring back the evicted executor pods as the resource becomes freed. See the following code:
apiVersion: v1
kind: Pod
spec:
priorityClassName: "high-priority"
nodeSelector:
eks.amazonaws.com/capacityType: ON_DEMAND
containers:
- name: spark-kubernetes-driver # This will be interpreted as Spark driver container
apiVersion: v1
kind: Pod
spec:
priorityClassName: "low-priority"
nodeSelector:
eks.amazonaws.com/capacityType: SPOT
containers:
- name: spark-kubernetes-executors # This will be interpreted as Spark executor container
Overprovisioning with priority

Diagram – 4 Illustrates an example of overprovisioning with priority.
As pods wait in a pending state due to resource availability, additional capacity can be added to the cluster with Amazon EKS auto scaling. The time it takes to scale the cluster by adding new nodes for deployment has to be considered for time-sensitive jobs. Overprovisioning is an option to mitigate the auto scaling delay using temporary pods with negative priority. These pods occupy space in the cluster. When pods with high priority are unschedulable, the temporary pods are preempted to make the room. This causes the auto scaler to scale out new nodes due to overprovisioning. Be aware that this is a trade-off because it adds higher cost while minimizing scheduling latency. For more information about overprovisioning best practices, refer to Overprovisioning.
Node selectors
EKS clusters can span multiple Availability Zones in a VPC. A Spark application whose driver and executor pods are distributed across multiple Availability Zones can incur inter- Availability Zone data transfer costs. To minimize or eliminate the data transfer cost, you should configure the job to run on a specific Availability Zone or even specific node type with the help of node labels. Amazon EKS places a set of default labels to identify capacity type (On-Demand or Spot Instance), Availability Zone, instance type, and more. In addition, we can use custom labels to meet workload-specific node affinity.
EMR on EKS allows you to choose specific nodes in two ways:
- At the job level. Refer to EKS Node Placement for more details.
- In the driver and executor level using pod templates.
When using pod templates, we recommend using on demand instances for driver pods. You can also consider including spot instances for executor pods for workloads that are tolerant of occasional periods when the target capacity is not completely available. Leveraging spot instances allow you to save cost for jobs that are not critical and can be terminated. Please refer Define a NodeSelector in PodTemplates.
Conclusion
In this post, we provided guidance on how to design and deploy EMR on EKS in a multi-tenant EKS environment through different lenses: network, security, cost management, and resource management. For any deployment, we recommend the following:
- Use IRSA with a condition scoped on the EMR on EKS service account
- Use a secret manager to store credentials and the Secret Store CSI Driver to access them in your Spark application
- Use
ResourceQuota and LimitRange to specify the resources that each of your data engineering teams can use and avoid compute resource abuse and starvation
- Implement a network policy to segregate network traffic between pods
Lastly, if you are considering migrating your spark workload to EMR on EKS you can further learn about design patterns to manage Apache Spark workload in EMR on EKS in this blog and about migrating your EMR transient cluster to EMR on EKS in this blog.
About the Authors
 Lotfi Mouhib is a Senior Solutions Architect working for the Public Sector team with Amazon Web Services. He helps public sector customers across EMEA realize their ideas, build new services, and innovate for citizens. In his spare time, Lotfi enjoys cycling and running.
Lotfi Mouhib is a Senior Solutions Architect working for the Public Sector team with Amazon Web Services. He helps public sector customers across EMEA realize their ideas, build new services, and innovate for citizens. In his spare time, Lotfi enjoys cycling and running.
 Ajeeb Peter is a Senior Solutions Architect with Amazon Web Services based in Charlotte, North Carolina, where he guides global financial services customers to build highly secure, scalable, reliable, and cost-efficient applications on the cloud. He brings over 20 years of technology experience on Software Development, Architecture and Analytics from industries like finance and telecom.
Ajeeb Peter is a Senior Solutions Architect with Amazon Web Services based in Charlotte, North Carolina, where he guides global financial services customers to build highly secure, scalable, reliable, and cost-efficient applications on the cloud. He brings over 20 years of technology experience on Software Development, Architecture and Analytics from industries like finance and telecom.