Post Syndicated from Nevi Shah original https://blog.cloudflare.com/workers-tracing-now-in-open-beta/
When your Worker slows down or starts throwing errors, finding the root cause shouldn’t require hours of log analysis and trial-and-error debugging. You should have clear visibility into what’s happening at every step of your application’s request flow. This is feedback we’ve heard loud and clear from developers using Workers, and today we’re excited to announce an Open Beta for tracing on Cloudflare Workers! You can now:
-
Get automatic instrumentation for applications on the Workers platform: No manual setup, complex instrumentation, or code changes. It works out of the box.
-
Explore and investigate traces in the Cloudflare dashboard: Your traces are processed and available in the Workers Observability dashboard alongside your existing logs.
-
Export logs and traces to OpenTelemetry-compatible providers: Send OpenTelemetry traces (and correlated logs) to your observability provider of choice.
In 2024, we set out to build the best first-party observability of any cloud platform. We launched a new metrics dashboard to give better insights into how your Worker is performing, Workers Logs to automatically ingest and store logs for your Workers, a query builder to explore your data across any dimension and real-time logs to stream your logs in real time with advanced filtering capabilities. Starting today, you can get an even deeper understanding of your Workers applications by enabling automatic tracing!
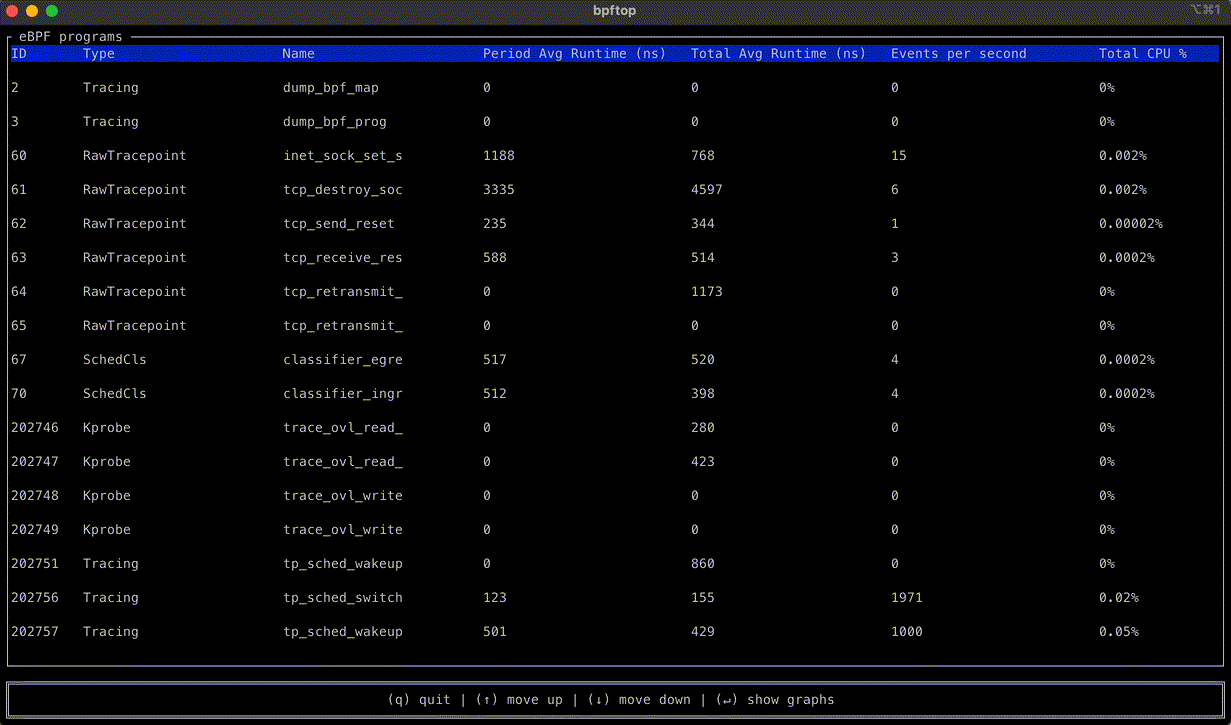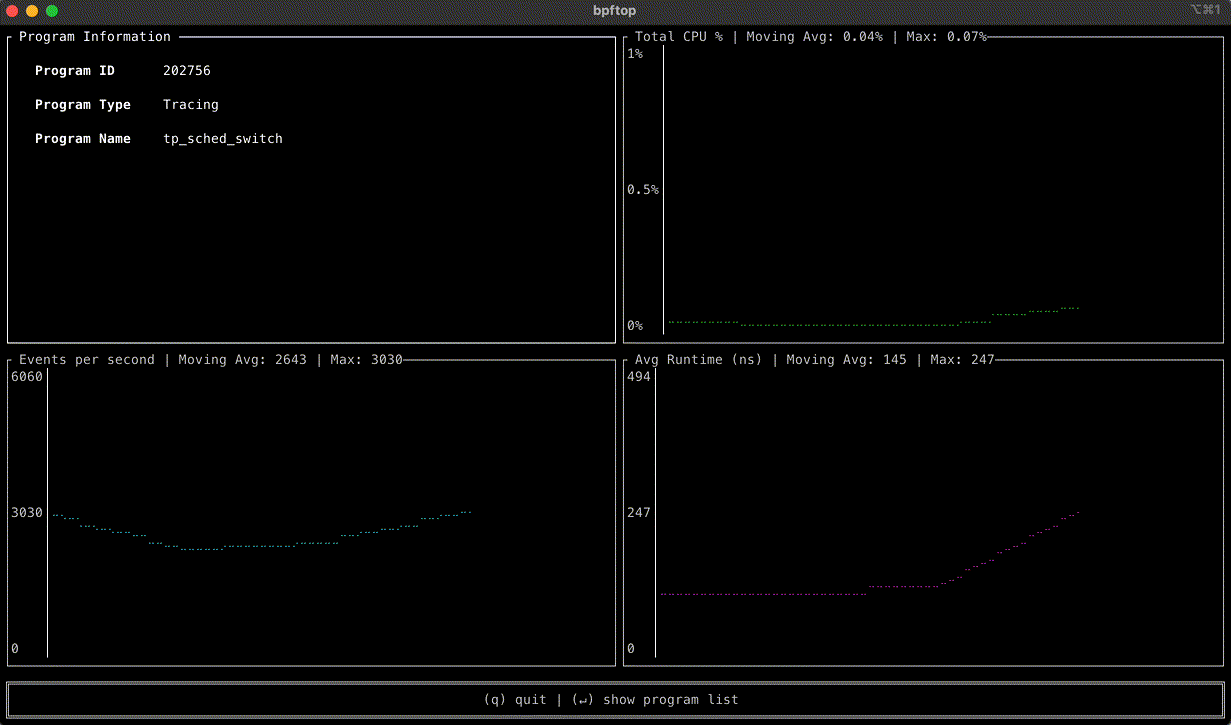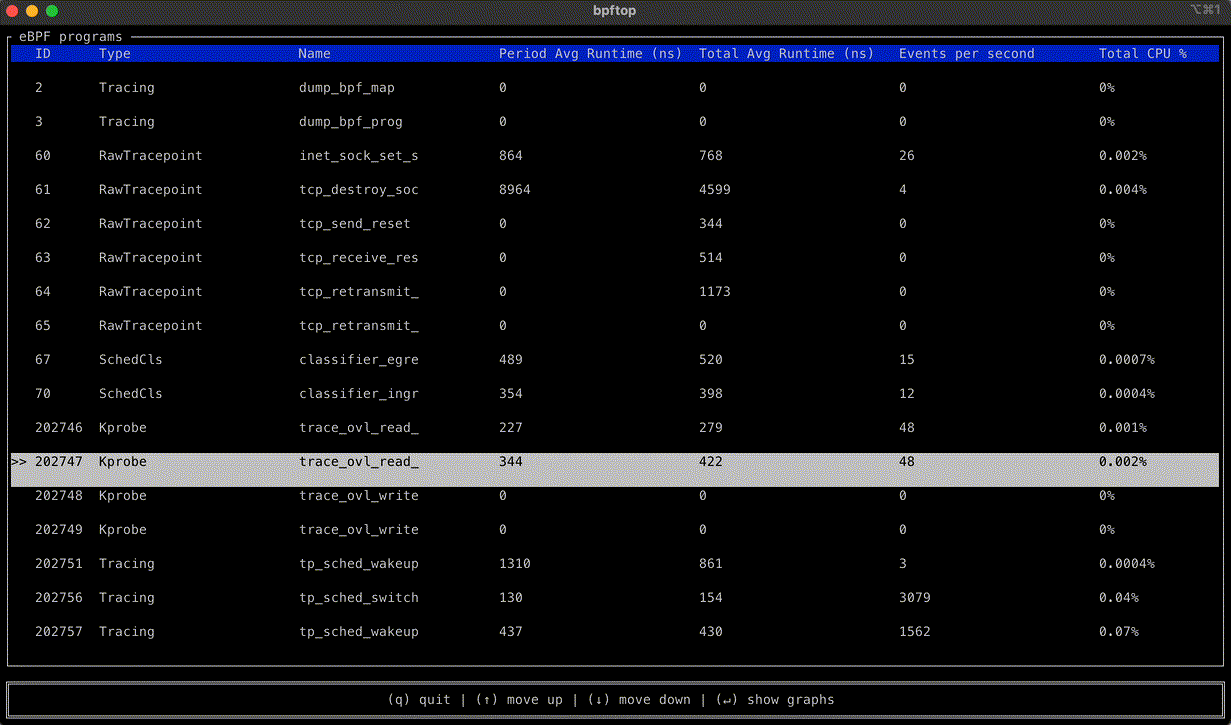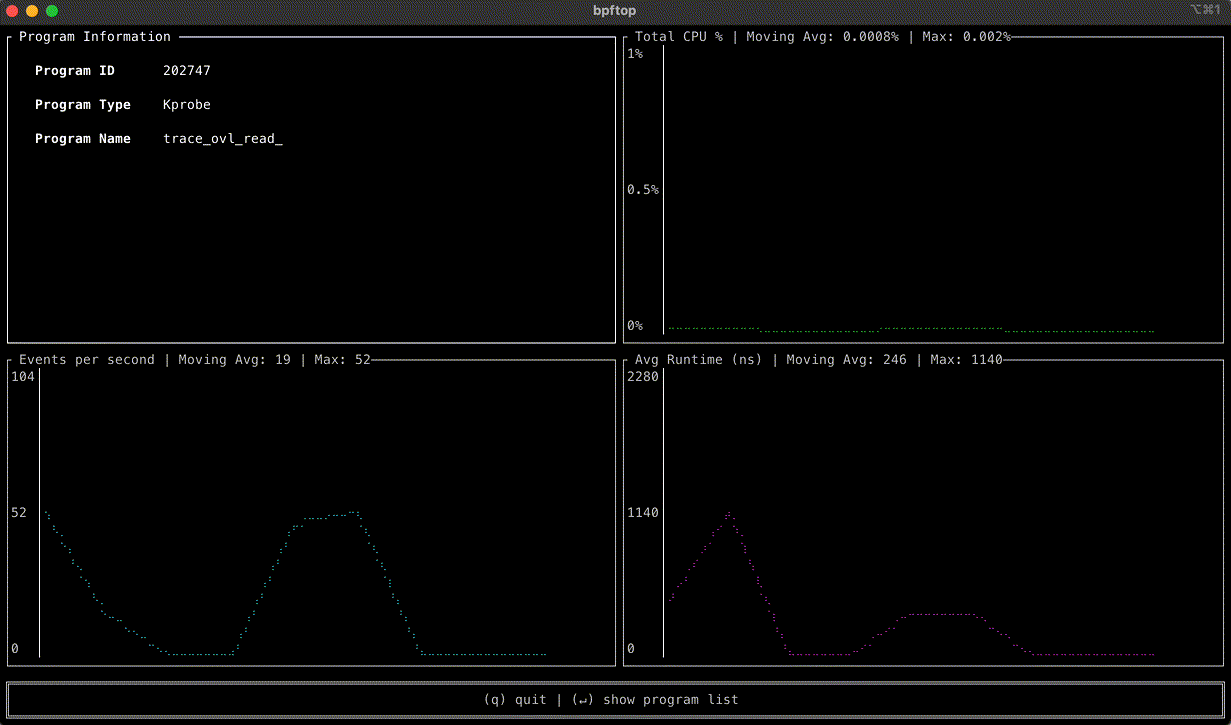
Workers traces capture and emit OpenTelemetry-compliant spans to show you detailed metadata and timing information on every operation your Worker performs. It helps you identify performance bottlenecks, resolve errors, and understand how your Worker interacts with other services on the Workers platform. You can now answer questions like:
-
Which calls are slowing down my application?
-
Which queries to my database take the longest?
-
What happened within a request that resulted in an error?
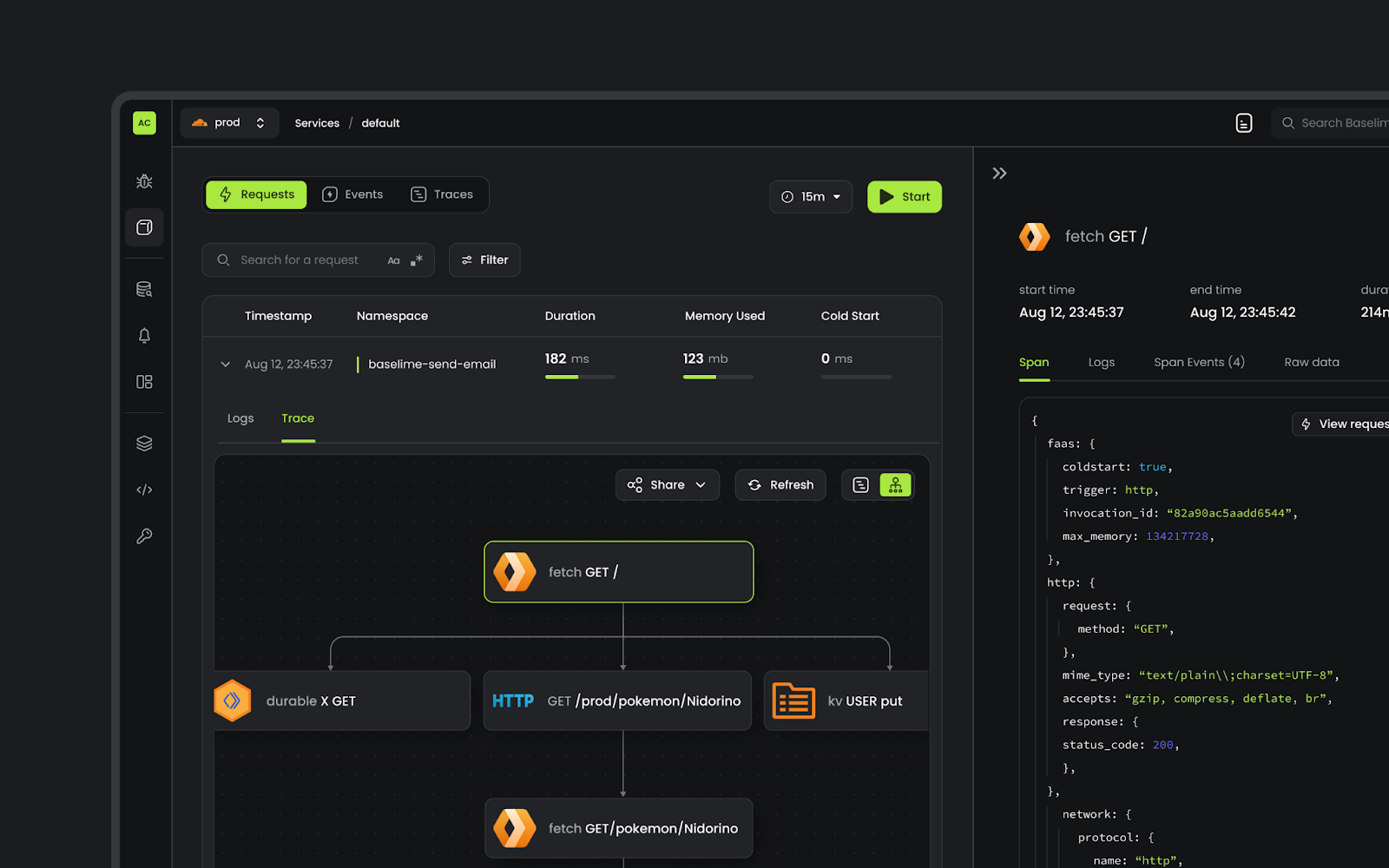
Tracing provides a visualization of each invocation’s journey through various operations. Each operation is captured as a span, a timed segment that shows what happened and how long it took. Child spans nest within parent spans to show sub-operations and dependencies, creating a hierarchical view of your invocation’s execution flow. Each span can include contextual metadata or attributes that provide details for debugging and filtering events.

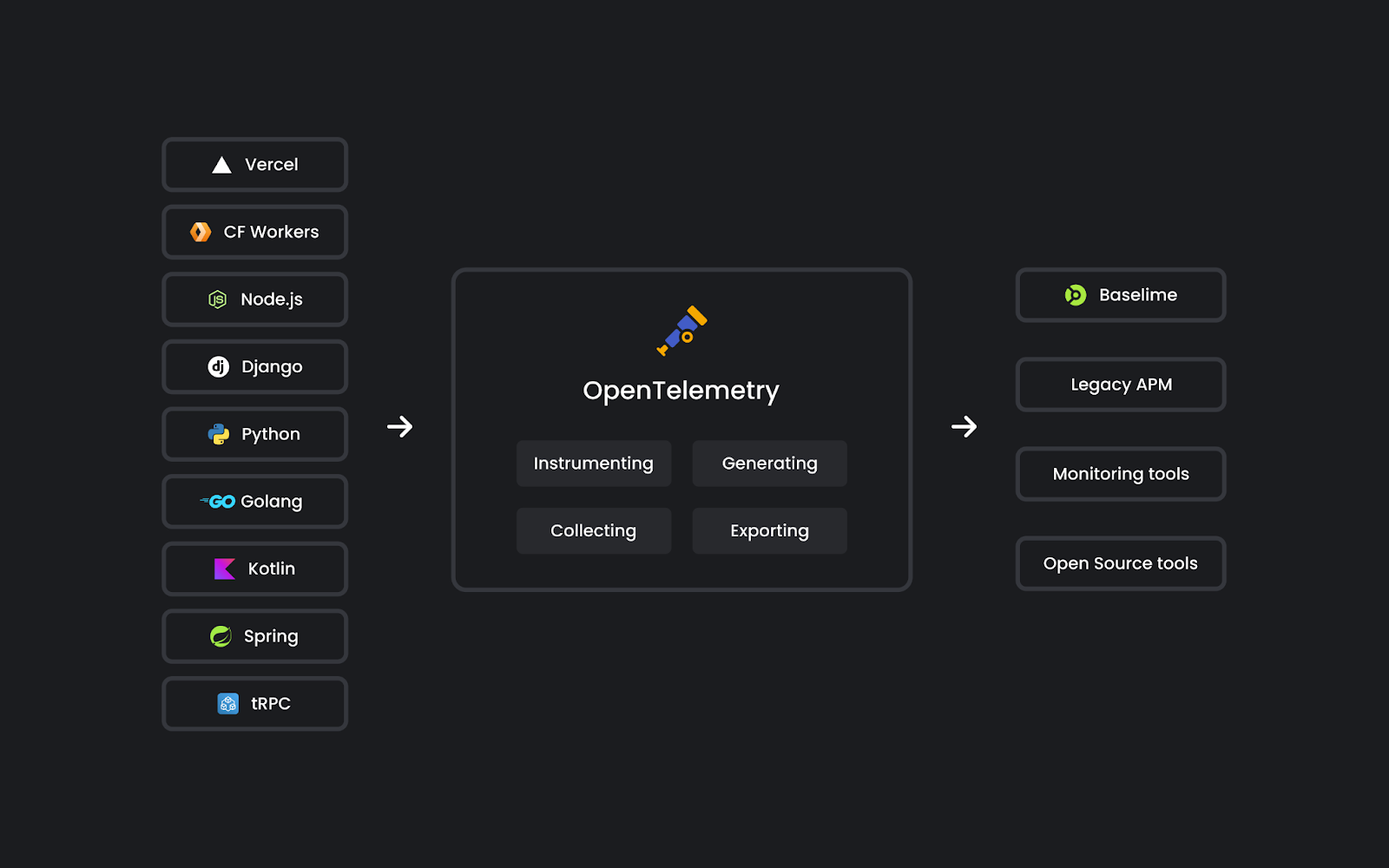
Previously, instrumenting your application typically required an understanding of the OpenTelemetry spec, multiple OTel libraries, and how they related to each other. Implementation was tedious and bloated your codebase with instrumentation code that obfuscated your application logic.
Setting up tracing typically meant spending hours integrating third-party SDKs, wrapping every database call and API request with instrumentation code, and debugging complex config files before you saw a single trace. This implementation overhead often makes observability an afterthought, leaving you without full visibility in production when issues arise.
What makes Workers Tracing truly magical is it’s completely automatic – no set up, no code changes, no wasted time. We took the approach of automatically instrumenting every I/O operation in your Workers, through a deep integration in workerd, our runtime, enabling us to capture the full extent of data flows through every invocation of your Workers.
You focus on your application logic. We take care of the instrumentation.
The operations covered today are:
-
Binding calls: Interactions with various Worker bindings. KV reads and writes, R2 object storage operations, Durable Object invocations, and many more binding calls are automatically traced. This gives you complete visibility into how your Worker uses other services.
-
Fetch calls: All outbound HTTP requests are automatically instrumented, capturing timing, status codes, and request metadata. This enables you to quickly identify which external dependencies are affecting your application’s performance.
-
Handler calls: Methods on a Worker that can receive and process external inputs, such as fetch handlers, scheduled handlers, and queue handlers. This gives you visibility into performance of how your Worker is being invoked.
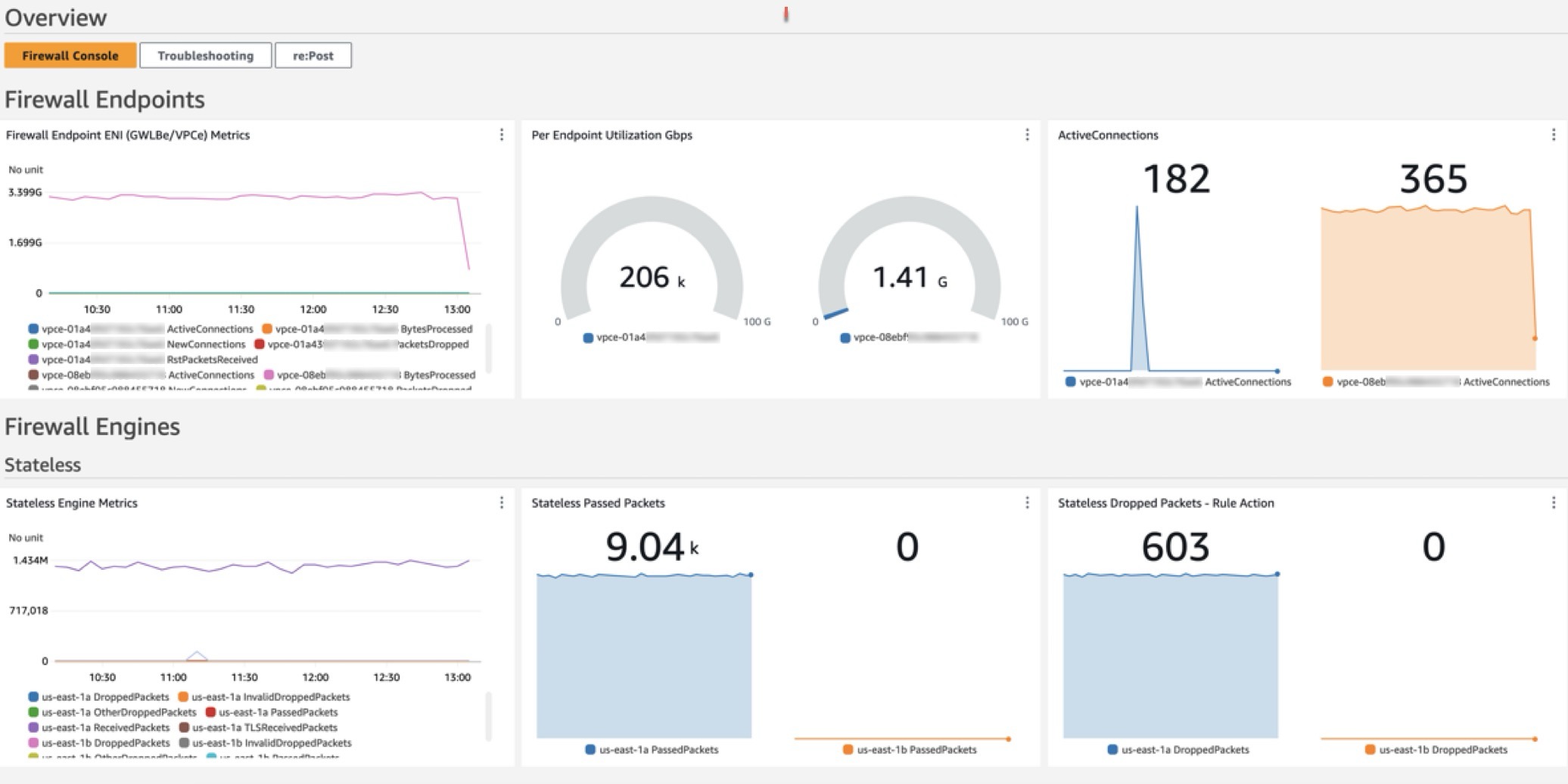
Our automated instrumentation captures each operation as a span. For example, a span generated by an R2 binding call (like a get or put operation) will automatically contain any available attributes, such as the operation type, the error if applicable, the object key, and duration. These detailed attributes provide the context you need to answer precise questions about your application without needing to manually log every detail.

We will continue to add more detailed attributes to spans and add the ability to trace an invocation across multiple Workers or external services. Our documentation contains a complete list of all instrumented spans and their attributes.
You can easily view traces directly within a specific Worker application in the Cloudflare dashboard, giving you immediate visibility into your application’s performance. You’ll find a list of all trace events within your desired time frame and a trace visualization of each invocation including duration of each call and any available attributes. You can also query across all Workers on your account, letting you pinpoint issues occurring on multiple applications.

To get started viewing traces on your Workers application, you can set:

Or if you already have observability.enabled=true configured, traces will be automatically emitted alongside your logs.

However, we realize that some development teams need Workers data to live alongside other telemetry data in the tools they are already using. That’s why we’re also adding tracing exports, letting your team send, visualize and query data with your existing observability stack! Starting today, you can export traces directly to providers like Honeycomb, Grafana or any other OpenTelemetry Protocol (OTLP) provider with an available endpoint.

We also support exporting OTLP-formatted logs that share the same trace ID, enabling third-party platforms to automatically correlate log entries with their corresponding traces. This lets you easily jump between spans and related log messages.
To start sending events to your destination of choice, first, configure your OTLP endpoint destination in the Cloudflare dashboard. For every destination you can specify a custom name and set custom headers to include API keys or app configuration.
Once you have your destination set up (e.g. honeycomb-tracing), set the following in your wrangler.jsonc and deploy:

This is just the beginning of Workers providing the workflows and tools to get you the telemetry data you want, where you want it. We’re improving our support both for native tracing in the dashboard and for exporting other types of telemetry to 3rd parties. In the upcoming months we’ll be launching:
-
Support for more spans and attributes: We are adding more automatic traces for every part of the Workers platform. While our first goal is to give you visibility into the duration of every operation within your request, we also want to add detailed attributes. Your feedback on what’s missing will be extremely valuable here.
-
Trace context propagation: When building distributed applications, ensuring your traces connect across all of your services (even those outside of Cloudflare), automatically linking spans together to create complete, end-to-end visibility is critical. For example, a trace from Workers could be nested from a parent service or vice versa. When fully implemented, our automatic trace context propagation will follow W3C standards to ensure compatibility across your existing tools and services.
-
Support for custom spans and attributes: While automatic instrumentation gives you visibility into what’s happening within the Workers platform, we know you need visibility into your own application logic too. So, we’ll give you the ability to manually add your own spans as well.
-
Ability to export metrics: Today, metrics, logs and traces are available for you to monitor and view within the Workers dashboard. But the final missing piece is giving you the ability to export both infrastructure metrics (like request volume, error rates, and execution duration) and custom application metrics to your preferred observability provider.
Today, at the start of beta, viewing traces in the Cloudflare dashboard and exporting traces to a 3rd party provider are both free. On January 15, 2026, tracing and log events will be charged the following pricing:
Viewing Workers traces in the Cloudflare dashboard
To view traces in the Cloudflare dashboard, you can do so on a Workers Free and Paid plan at the pricing shown below:
| Workers Free | Workers Paid | |
|---|---|---|
| Included Volume | 200K events per day | 20M events per month |
| Additional Events | N/A | $0.60 per million logs |
| Retention | 3 days | 7 days |
Exporting traces and logs
To export traces to a 3rd-party OTLP-compatible destination, you will need a Workers Paid subscription. Pricing is based on total span or log events with the following inclusions:
| Workers Free | Workers Paid | |
|---|---|---|
| Events | Not available | 10 million events per month |
| Additional events | $0.05 per million batched events |
Ready to get started with tracing on your Workers application?
-
Check out our documentation: Learn how to get set up, read about current limitations and discover more about what’s coming up.
-
Join the chatter in our GitHub discussion: Your feedback will be extremely valuable in our beta period on our automatic instrumentation, tracing dashboard, and OpenTelemetry export flow. Head to our GitHub discussion to raise issues, put in feature requests and get in touch with us!